 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Generalizing Multimodal Variational Methods to Sets
Dec 19, 2022

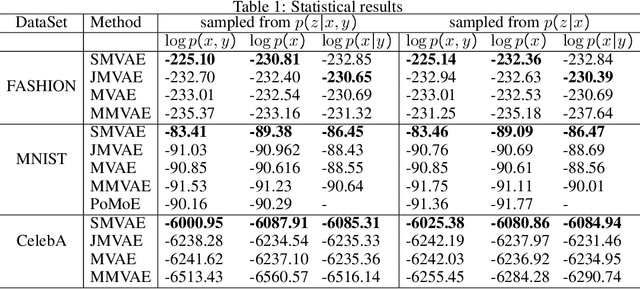
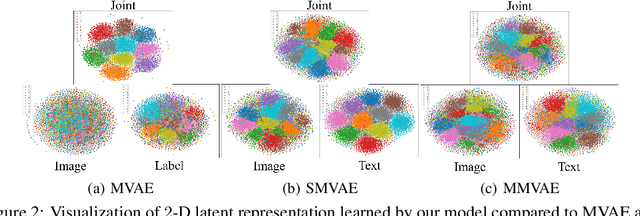

Making sense of multiple modalities can yield a more comprehensive description of real-world phenomena. However, learning the co-representation of diverse modalities is still a long-standing endeavor in emerging machine learning applications and research. Previous generative approaches for multimodal input approximate a joint-modality posterior by uni-modality posteriors as product-of-experts (PoE) or mixture-of-experts (MoE). We argue that these approximations lead to a defective bound for the optimization process and loss of semantic connection among modalities. This paper presents a novel variational method on sets called the Set Multimodal VAE (SMVAE) for learning a multimodal latent space while handling the missing modality problem. By modeling the joint-modality posterior distribution directly, the proposed SMVAE learns to exchange information between multiple modalities and compensate for the drawbacks caused by factorization. In public datasets of various domains, the experimental results demonstrate that the proposed method is applicable to order-agnostic cross-modal generation while achieving outstanding performance compared to the state-of-the-art multimodal methods. The source code for our method is available online https://anonymous.4open.science/r/SMVAE-9B3C/.
Improving Depression estimation from facial videos with face alignment, training optimization and scheduling
Dec 13, 2022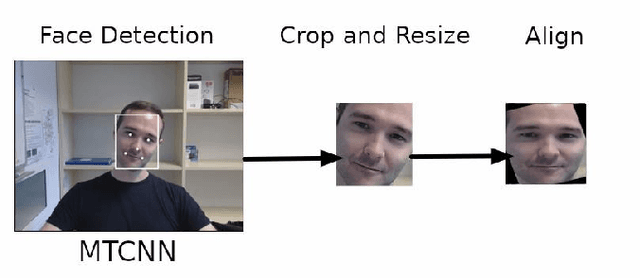
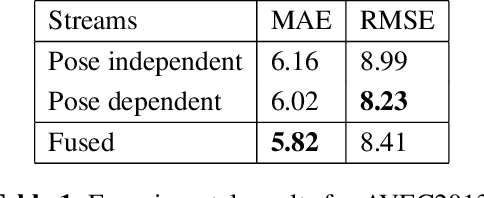
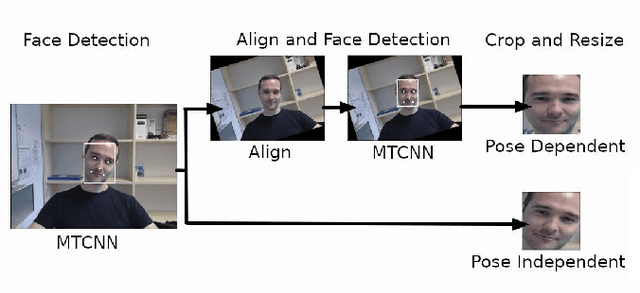
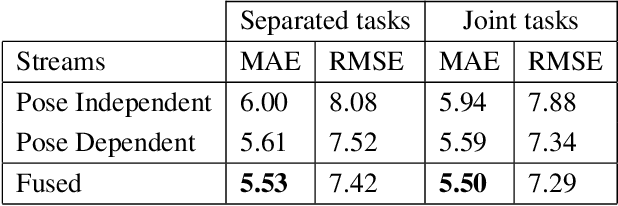
Deep learning models have shown promising results in recognizing depressive states using video-based facial expressions. While successful models typically leverage using 3D-CNNs or video distillation techniques, the different use of pretraining, data augmentation, preprocessing, and optimization techniques across experiments makes it difficult to make fair architectural comparisons. We propose instead to enhance two simple models based on ResNet-50 that use only static spatial information by using two specific face alignment methods and improved data augmentation, optimization, and scheduling techniques. Our extensive experiments on benchmark datasets obtain similar results to sophisticated spatio-temporal models for single streams, while the score-level fusion of two different streams outperforms state-of-the-art methods. Our findings suggest that specific modifications in the preprocessing and training process result in noticeable differences in the performance of the models and could hide the actual originally attributed to the use of different neural network architectures.
InferEM: Inferring the Speaker's Intention for Empathetic Dialogue Generation
Dec 13, 2022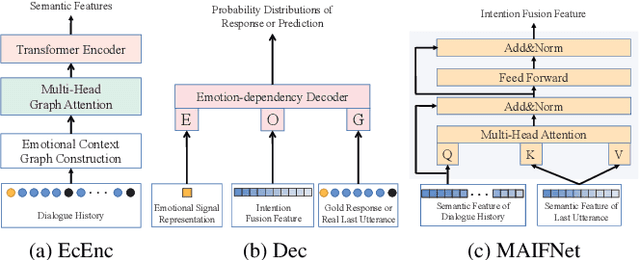
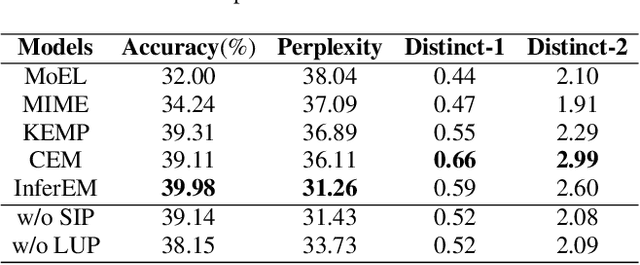
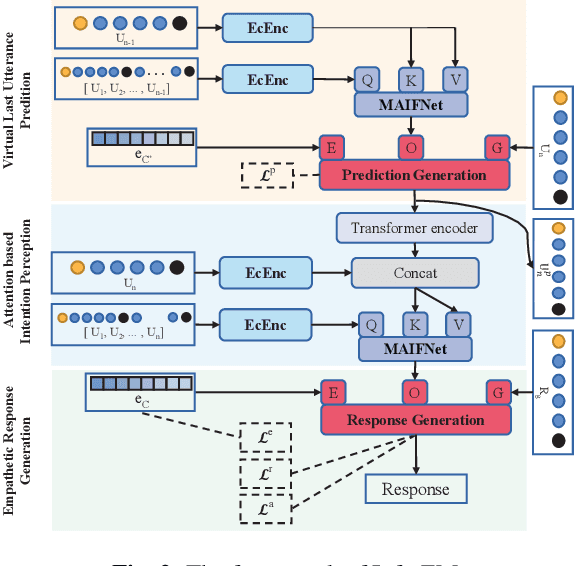
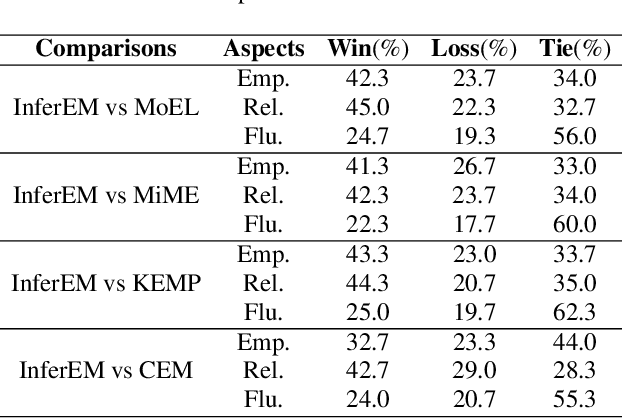
Current approaches to empathetic response generation typically encode the entire dialogue history directly and put the output into a decoder to generate friendly feedback. These methods focus on modelling contextual information but neglect capturing the direct intention of the speaker. We argue that the last utterance in the dialogue empirically conveys the intention of the speaker. Consequently, we propose a novel model named InferEM for empathetic response generation. We separately encode the last utterance and fuse it with the entire dialogue through multi-head attention based intention fusion module to capture the speaker's intention. Besides, we utilize previous utterances to predict the last utterance, which simulates human's psychology to guess what the interlocutor may speak in advance. To balance the optimizing rates of the utterance prediction and response generation, a multi-task learning strategy is designed for InferEM. Experimental results demonstrate the plausibility and validity of InferEM in improving empathetic expression.
Trajectory Adaptive Prediction for Moving Objects in Uncertain Environment
Dec 13, 2022The existing methods for trajectory prediction are difficult to describe trajectory of moving objects in complex and uncertain environment accurately. In order to solve this problem, this paper proposes an adaptive trajectory prediction method for moving objects based on variation Gaussian mixture model (VGMM) in dynamic environment (ESATP). Firstly, based on the traditional mixture Gaussian model, we use the approximate variational Bayesian inference method to process the mixture Gaussian distribution in model training procedure. Secondly, variational Bayesian expectation maximization iterative is used to learn the model parameters and prior information is used to get a more precise prediction model. Finally, for the input trajectories, parameter adaptive selection algorithm is used automatically to adjust the combination of parameters. Experiment results perform that the ESATP method in the experiment showed high predictive accuracy, and maintain a high time efficiency. This model can be used in products of mobile vehicle positioning.
Over-The-Air Federated Learning Over Scalable Cell-free Massive MIMO
Dec 13, 2022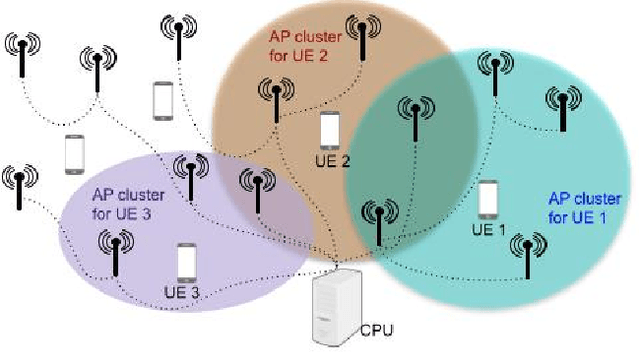
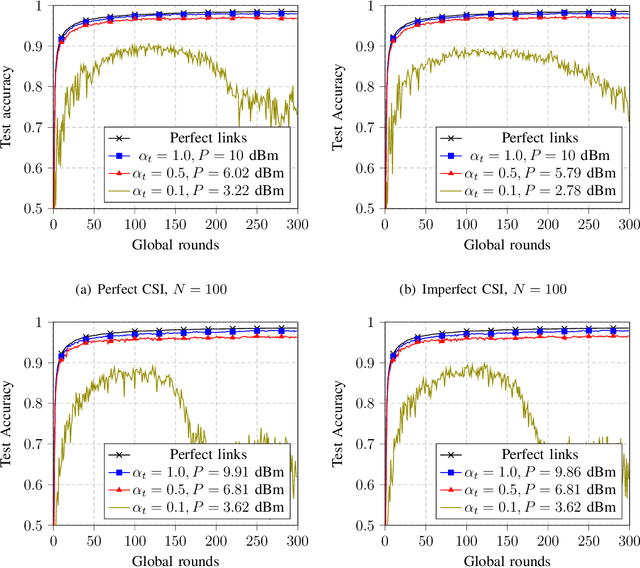
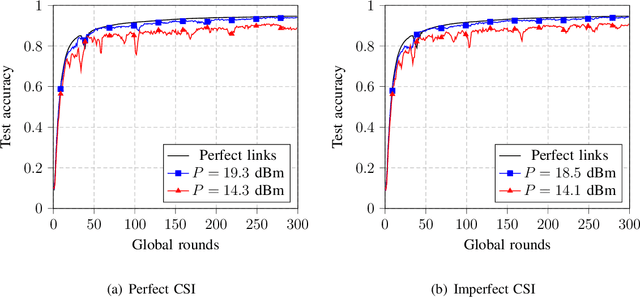
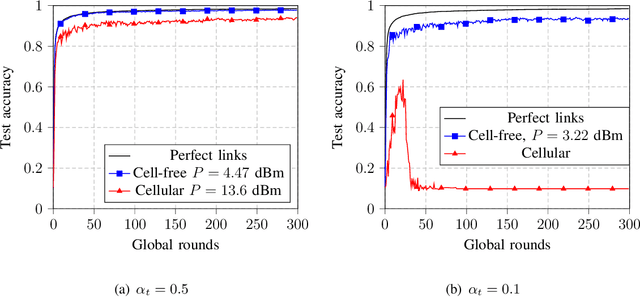
Cell-free massive MIMO is emerging as a promising technology for future wireless communication systems, which is expected to offer uniform coverage and high spectral efficiency compared to classical cellular systems. We study in this paper how cell-free massive MIMO can support federated edge learning. Taking advantage of the additive nature of the wireless multiple access channel, over-the-air computation is exploited, where the clients send their local updates simultaneously over the same communication resource. This approach, known as over-the-air federated learning (OTA-FL), is proven to alleviate the communication overhead of federated learning over wireless networks. Considering channel correlation and only imperfect channel state information available at the central server, we propose a practical implementation of OTA-FL over cell-free massive MIMO. The convergence of the proposed implementation is studied analytically and experimentally, confirming the benefits of cell-free massive MIMO for OTA-FL.
Training language models for deeper understanding improves brain alignment
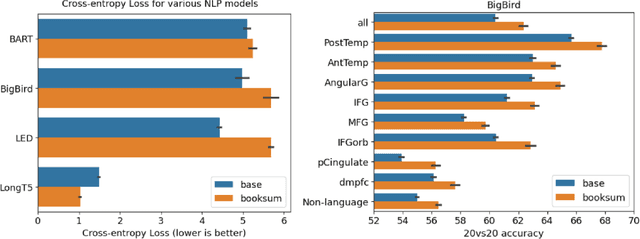
Dec 21, 2022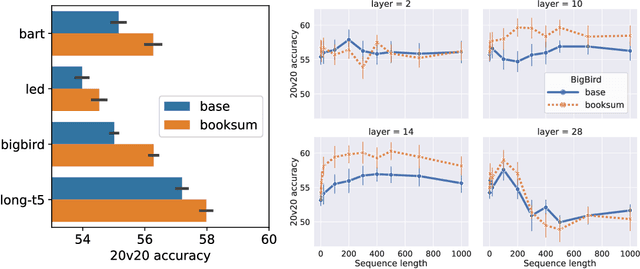

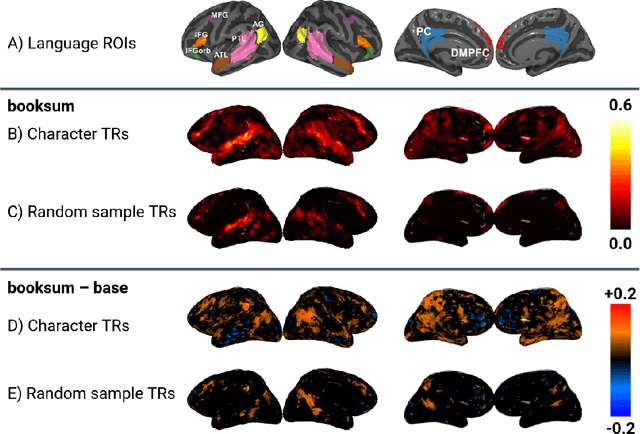
Building systems that achieve a deeper understanding of language is one of the central goals of natural language processing (NLP). Towards this goal, recent works have begun to train language models on narrative datasets which require extracting the most critical information by integrating across long contexts. However, it is still an open question whether these models are learning a deeper understanding of the text, or if the models are simply learning a heuristic to complete the task. This work investigates this further by turning to the one language processing system that truly understands complex language: the human brain. We show that training language models for deeper narrative understanding results in richer representations that have improved alignment to human brain activity. We further find that the improvements in brain alignment are larger for character names than for other discourse features, which indicates that these models are learning important narrative elements. Taken together, these results suggest that this type of training can indeed lead to deeper language understanding. These findings have consequences both for cognitive neuroscience by revealing some of the significant factors behind brain-NLP alignment, and for NLP by highlighting that understanding of long-range context can be improved beyond language modeling.
Knowledge-driven Scene Priors for Semantic Audio-Visual Embodied Navigation
Dec 21, 2022
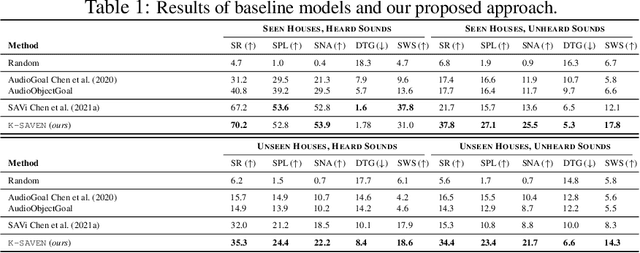
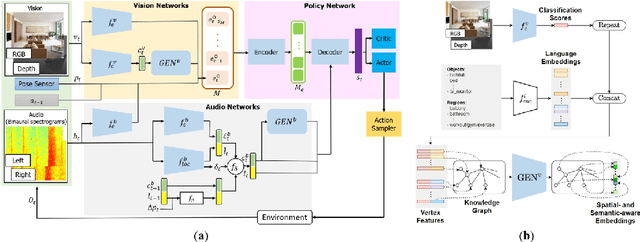
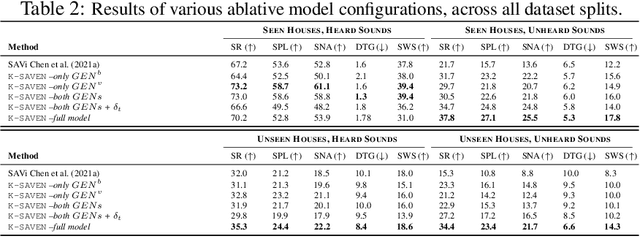
Generalisation to unseen contexts remains a challenge for embodied navigation agents. In the context of semantic audio-visual navigation (SAVi) tasks, the notion of generalisation should include both generalising to unseen indoor visual scenes as well as generalising to unheard sounding objects. However, previous SAVi task definitions do not include evaluation conditions on truly novel sounding objects, resorting instead to evaluating agents on unheard sound clips of known objects; meanwhile, previous SAVi methods do not include explicit mechanisms for incorporating domain knowledge about object and region semantics. These weaknesses limit the development and assessment of models' abilities to generalise their learned experience. In this work, we introduce the use of knowledge-driven scene priors in the semantic audio-visual embodied navigation task: we combine semantic information from our novel knowledge graph that encodes object-region relations, spatial knowledge from dual Graph Encoder Networks, and background knowledge from a series of pre-training tasks -- all within a reinforcement learning framework for audio-visual navigation. We also define a new audio-visual navigation sub-task, where agents are evaluated on novel sounding objects, as opposed to unheard clips of known objects. We show improvements over strong baselines in generalisation to unseen regions and novel sounding objects, within the Habitat-Matterport3D simulation environment, under the SoundSpaces task.
Similarity Contrastive Estimation for Image and Video Soft Contrastive Self-Supervised Learning
Dec 21, 2022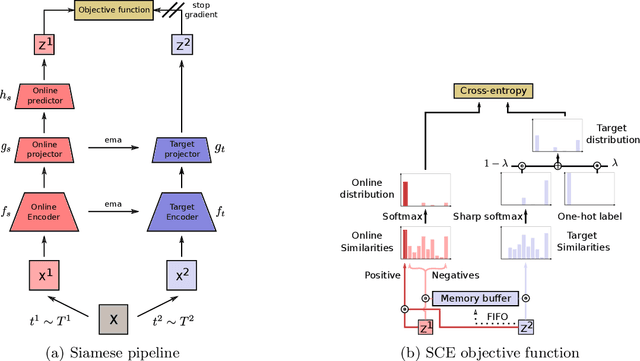
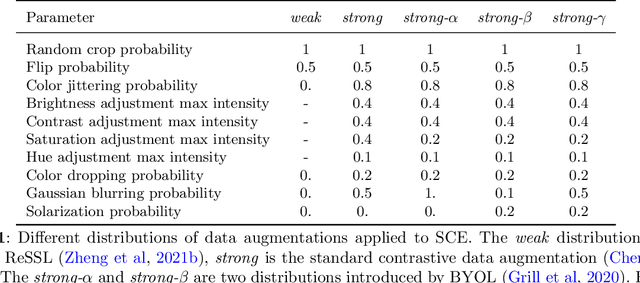

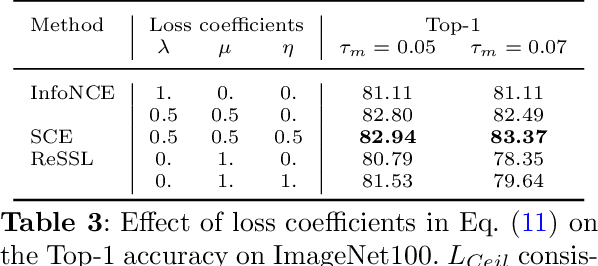
Contrastive representation learning has proven to be an effective self-supervised learning method for images and videos. Most successful approaches are based on Noise Contrastive Estimation (NCE) and use different views of an instance as positives that should be contrasted with other instances, called negatives, that are considered as noise. However, several instances in a dataset are drawn from the same distribution and share underlying semantic information. A good data representation should contain relations between the instances, or semantic similarity and dissimilarity, that contrastive learning harms by considering all negatives as noise. To circumvent this issue, we propose a novel formulation of contrastive learning using semantic similarity between instances called Similarity Contrastive Estimation (SCE). Our training objective is a soft contrastive one that brings the positives closer and estimates a continuous distribution to push or pull negative instances based on their learned similarities. We validate empirically our approach on both image and video representation learning. We show that SCE performs competitively with the state of the art on the ImageNet linear evaluation protocol for fewer pretraining epochs and that it generalizes to several downstream image tasks. We also show that SCE reaches state-of-the-art results for pretraining video representation and that the learned representation can generalize to video downstream tasks.
Online Statistical Inference for Matrix Contextual Bandit
Dec 21, 2022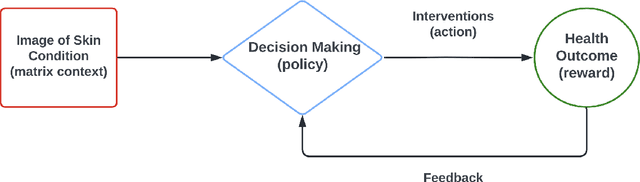
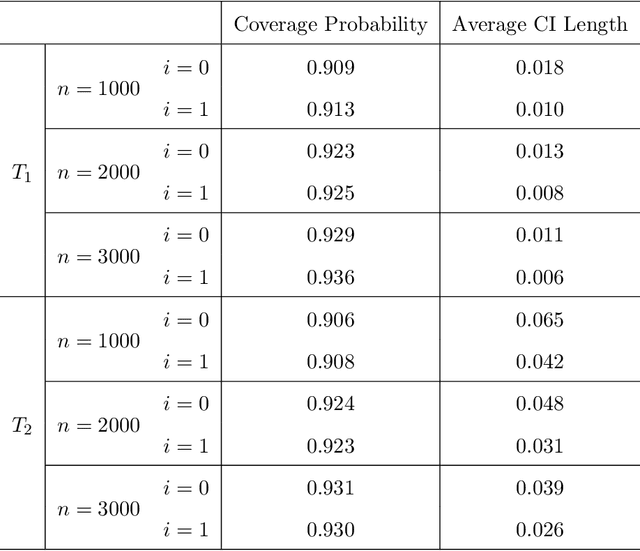
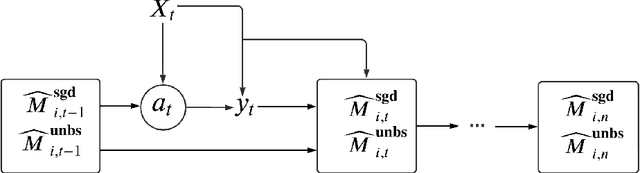
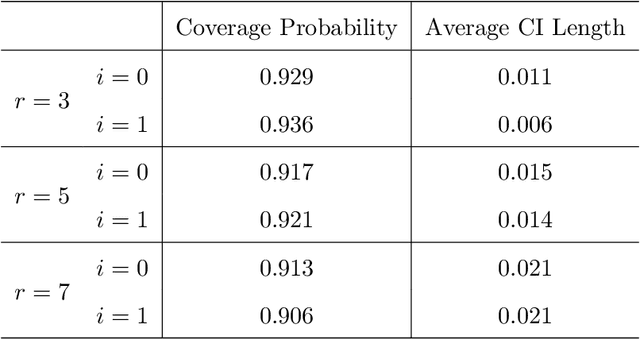
Contextual bandit has been widely used for sequential decision-making based on the current contextual information and historical feedback data. In modern applications, such context format can be rich and can often be formulated as a matrix. Moreover, while existing bandit algorithms mainly focused on reward-maximization, less attention has been paid to the statistical inference. To fill in these gaps, in this work we consider a matrix contextual bandit framework where the true model parameter is a low-rank matrix, and propose a fully online procedure to simultaneously make sequential decision-making and conduct statistical inference. The low-rank structure of the model parameter and the adaptivity nature of the data collection process makes this difficult: standard low-rank estimators are not fully online and are biased, while existing inference approaches in bandit algorithms fail to account for the low-rankness and are also biased. To address these, we introduce a new online doubly-debiasing inference procedure to simultaneously handle both sources of bias. In theory, we establish the asymptotic normality of the proposed online doubly-debiased estimator and prove the validity of the constructed confidence interval. Our inference results are built upon a newly developed low-rank stochastic gradient descent estimator and its non-asymptotic convergence result, which is also of independent interest.
Transformer-based Hand Gesture Recognition via High-Density EMG Signals: From Instantaneous Recognition to Fusion of Motor Unit Spike Trains
Dec 07, 2022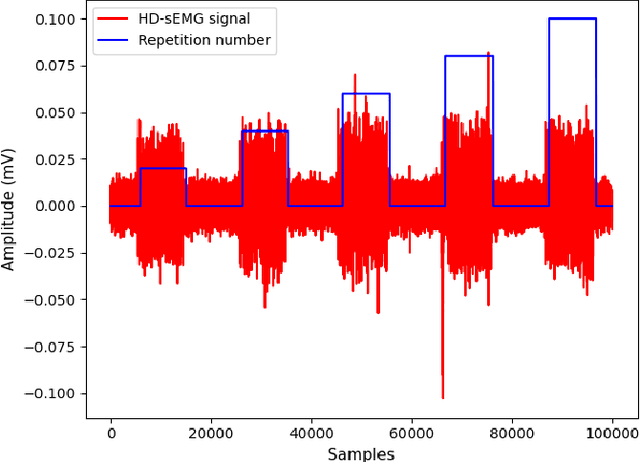
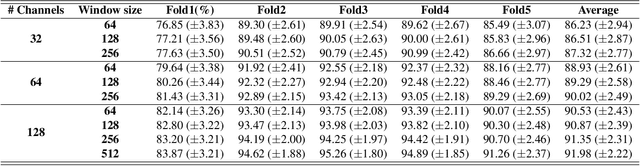

Designing efficient and labor-saving prosthetic hands requires powerful hand gesture recognition algorithms that can achieve high accuracy with limited complexity and latency. In this context, the paper proposes a compact deep learning framework referred to as the CT-HGR, which employs a vision transformer network to conduct hand gesture recognition using highdensity sEMG (HD-sEMG) signals. The attention mechanism in the proposed model identifies similarities among different data segments with a greater capacity for parallel computations and addresses the memory limitation problems while dealing with inputs of large sequence lengths. CT-HGR can be trained from scratch without any need for transfer learning and can simultaneously extract both temporal and spatial features of HD-sEMG data. Additionally, the CT-HGR framework can perform instantaneous recognition using sEMG image spatially composed from HD-sEMG signals. A variant of the CT-HGR is also designed to incorporate microscopic neural drive information in the form of Motor Unit Spike Trains (MUSTs) extracted from HD-sEMG signals using Blind Source Separation (BSS). This variant is combined with its baseline version via a hybrid architecture to evaluate potentials of fusing macroscopic and microscopic neural drive information. The utilized HD-sEMG dataset involves 128 electrodes that collect the signals related to 65 isometric hand gestures of 20 subjects. The proposed CT-HGR framework is applied to 31.25, 62.5, 125, 250 ms window sizes of the above-mentioned dataset utilizing 32, 64, 128 electrode channels. The average accuracy over all the participants using 32 electrodes and a window size of 31.25 ms is 86.23%, which gradually increases till reaching 91.98% for 128 electrodes and a window size of 250 ms. The CT-HGR achieves accuracy of 89.13% for instantaneous recognition based on a single frame of HD-sEMG image.