 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
DWRSeg: Dilation-wise Residual Network for Real-time Semantic Segmentation
Dec 02, 2022

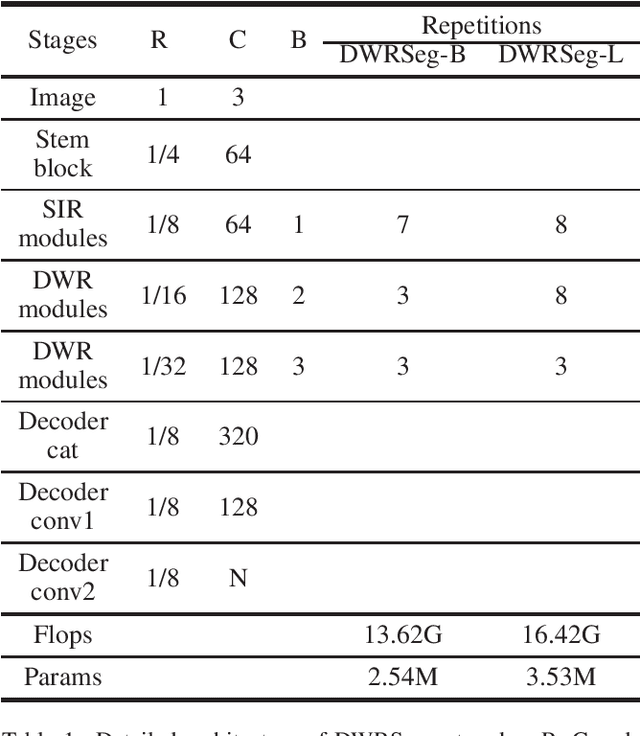
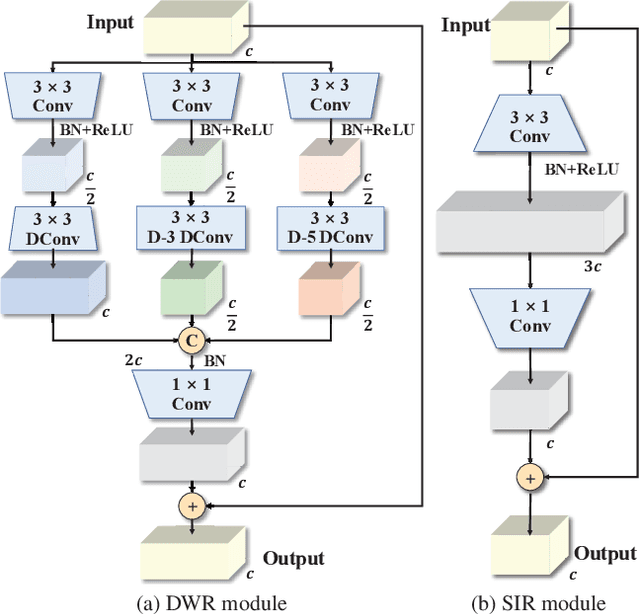
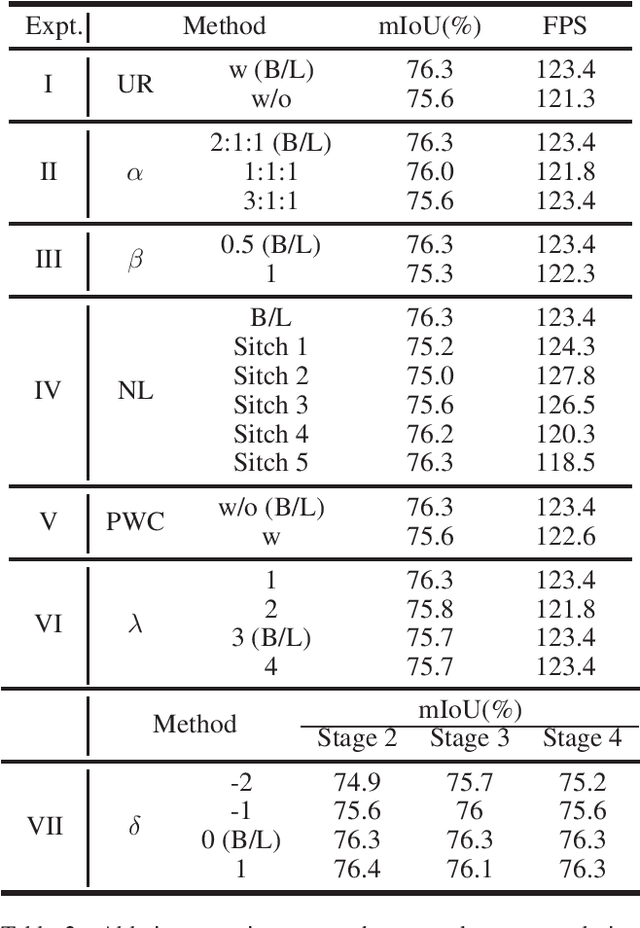
Real-time semantic segmentation has played an important role in intelligent vehicle scenarios. Recently, numerous networks have incorporated information from multi-size receptive fields to facilitate feature extraction in real-time semantic segmentation tasks. However, these methods preferentially adopt massive receptive fields to elicit more contextual information, which may result in inefficient feature extraction. We believe that the elaborated receptive fields are crucial, considering the demand for efficient feature extraction in real-time tasks. Therefore, we propose an effective and efficient architecture termed Dilation-wise Residual segmentation (DWRSeg), which possesses different sets of receptive field sizes within different stages. The architecture involves (i) a Dilation-wise Residual (DWR) module for extracting features based on different scales of receptive fields in the high level of the network; (ii) a Simple Inverted Residual (SIR) module that uses an inverted bottleneck structure to extract features from the low stage; and (iii) a simple fully convolutional network (FCN)-like decoder for aggregating multiscale feature maps to generate the prediction. Extensive experiments on the Cityscapes and CamVid datasets demonstrate the effectiveness of our method by achieving a state-of-the-art trade-off between accuracy and inference speed, in addition to being lighter weight. Without using pretraining or resorting to any training trick, we achieve 72.7% mIoU on the Cityscapes test set at a speed of 319.5 FPS on one NVIDIA GeForce GTX 1080 Ti card, which is significantly faster than existing methods. The code and trained models are publicly available.
UniKGQA: Unified Retrieval and Reasoning for Solving Multi-hop Question Answering Over Knowledge Graph
Dec 02, 2022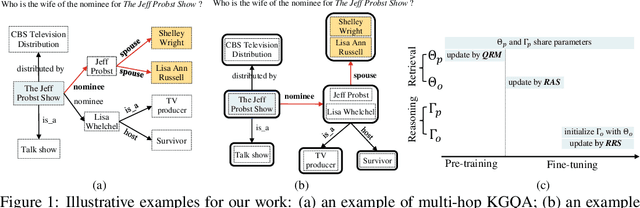
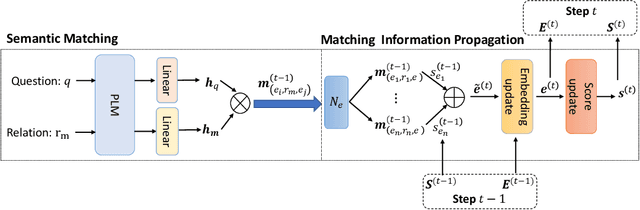
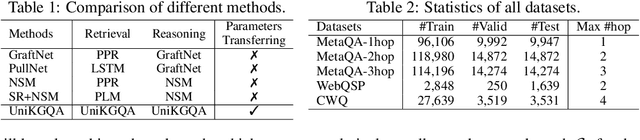
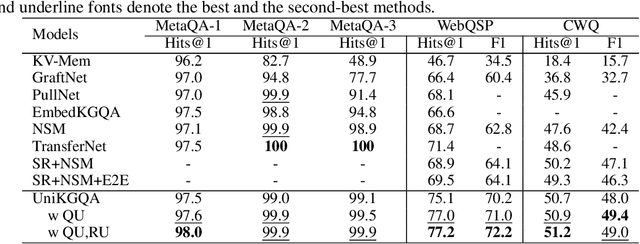
Multi-hop Question Answering over Knowledge Graph~(KGQA) aims to find the answer entities that are multiple hops away from the topic entities mentioned in a natural language question on a large-scale Knowledge Graph (KG). To cope with the vast search space, existing work usually adopts a two-stage approach: it firstly retrieves a relatively small subgraph related to the question and then performs the reasoning on the subgraph to accurately find the answer entities. Although these two stages are highly related, previous work employs very different technical solutions for developing the retrieval and reasoning models, neglecting their relatedness in task essence. In this paper, we propose UniKGQA, a novel approach for multi-hop KGQA task, by unifying retrieval and reasoning in both model architecture and parameter learning. For model architecture, UniKGQA consists of a semantic matching module based on a pre-trained language model~(PLM) for question-relation semantic matching, and a matching information propagation module to propagate the matching information along the edges on KGs. For parameter learning, we design a shared pre-training task based on question-relation matching for both retrieval and reasoning models, and then propose retrieval- and reasoning-oriented fine-tuning strategies. Compared with previous studies, our approach is more unified, tightly relating the retrieval and reasoning stages. Extensive experiments on three benchmark datasets have demonstrated the effectiveness of our method on the multi-hop KGQA task. Our codes and data are publicly available at https://github.com/RUCAIBox/UniKGQA.
"World Knowledge" in Multiple Choice Reading Comprehension
Nov 13, 2022
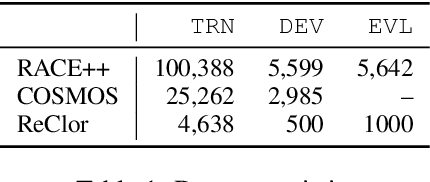
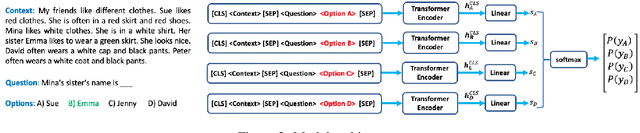
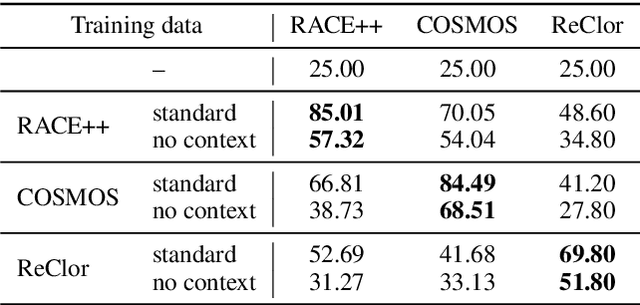
Recently it has been shown that without any access to the contextual passage, multiple choice reading comprehension (MCRC) systems are able to answer questions significantly better than random on average. These systems use their accumulated "world knowledge" to directly answer questions, rather than using information from the passage. This paper examines the possibility of exploiting this observation as a tool for test designers to ensure that the use of "world knowledge" is acceptable for a particular set of questions. We propose information-theory based metrics that enable the level of "world knowledge" exploited by systems to be assessed. Two metrics are described: the expected number of options, which measures whether a passage-free system can identify the answer a question using world knowledge; and the contextual mutual information, which measures the importance of context for a given question. We demonstrate that questions with low expected number of options, and hence answerable by the shortcut system, are often similarly answerable by humans without context. This highlights that the general knowledge 'shortcuts' could be equally used by exam candidates, and that our proposed metrics may be helpful for future test designers to monitor the quality of questions.
Lung-Net: A deep learning framework for lung tissue segmentation in three-dimensional thoracic CT images
Dec 28, 2022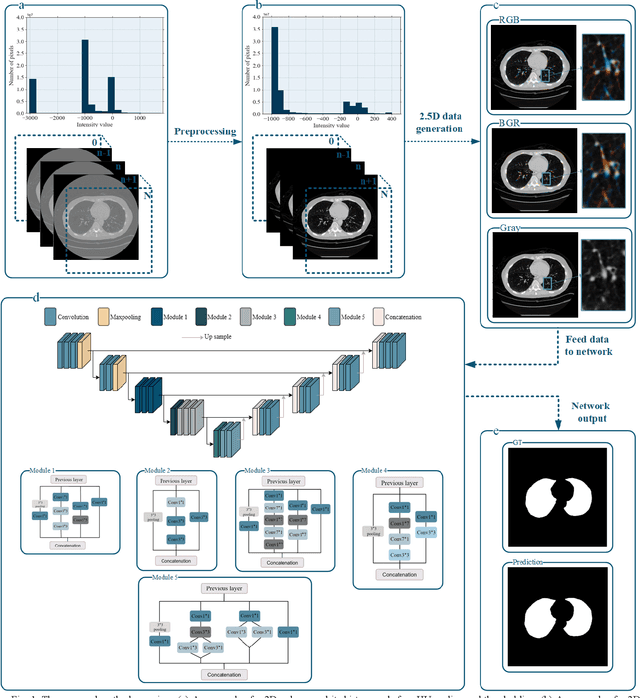
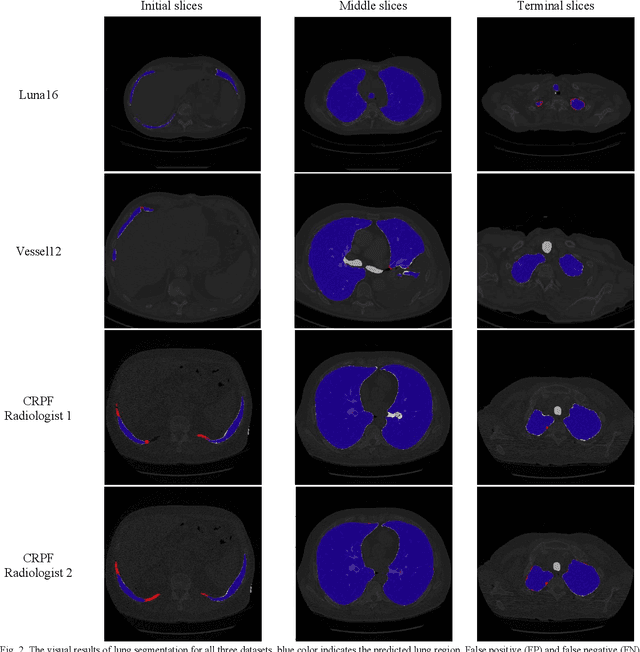
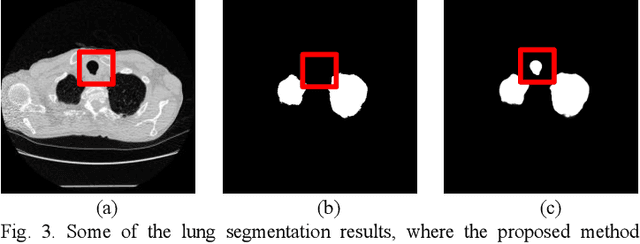
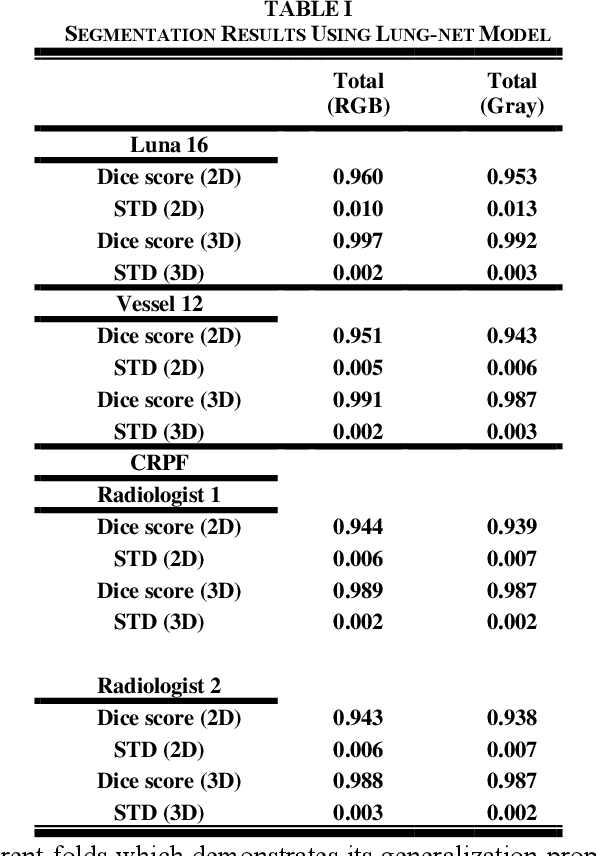
Segmentation of lung tissue in computed tomography (CT) images is a precursor to most pulmonary image analysis applications. Semantic segmentation methods using deep learning have exhibited top-tier performance in recent years. This paper presents a fully automatic method for identifying the lungs in three-dimensional (3D) pulmonary CT images, which we call it Lung-Net. We conjectured that a significant deeper network with inceptionV3 units can achieve a better feature representation of lung CT images without increasing the model complexity in terms of the number of trainable parameters. The method has three main advantages. First, a U-Net architecture with InceptionV3 blocks is developed to resolve the problem of performance degradation and parameter overload. Then, using information from consecutive slices, a new data structure is created to increase generalization potential, allowing more discriminating features to be extracted by making data representation as efficient as possible. Finally, the robustness of the proposed segmentation framework was quantitatively assessed using one public database to train and test the model (LUNA16) and two public databases (ISBI VESSEL12 challenge and CRPF dataset) only for testing the model; each database consists of 700, 23, and 40 CT images, respectively, that were acquired with a different scanner and protocol. Based on the experimental results, the proposed method achieved competitive results over the existing techniques with Dice coefficient of 99.7, 99.1, and 98.8 for LUNA16, VESSEL12, and CRPF datasets, respectively. For segmenting lung tissue in CT images, the proposed model is efficient in terms of time and parameters and outperforms other state-of-the-art methods. Additionally, this model is publicly accessible via a graphical user interface.
Learning to Reduce Information Bottleneck for Object Detection in Aerial Images
Apr 05, 2022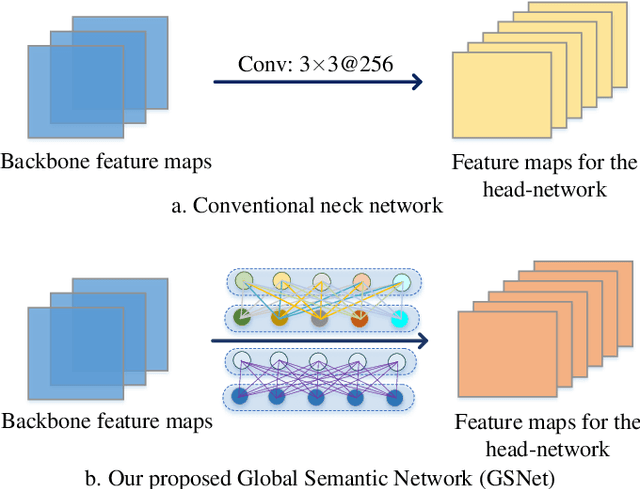
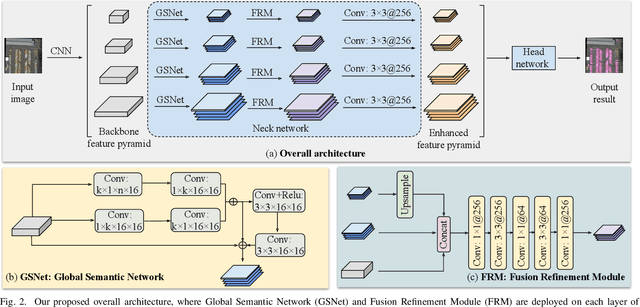
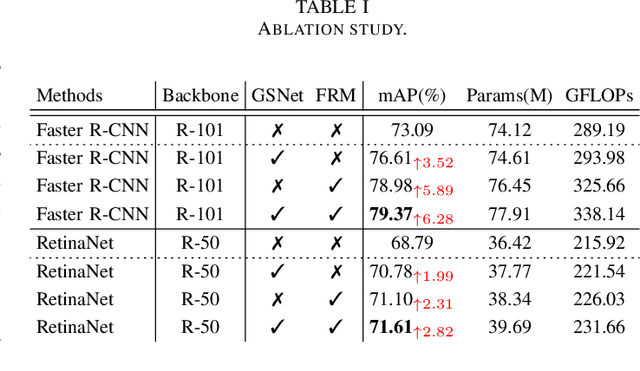
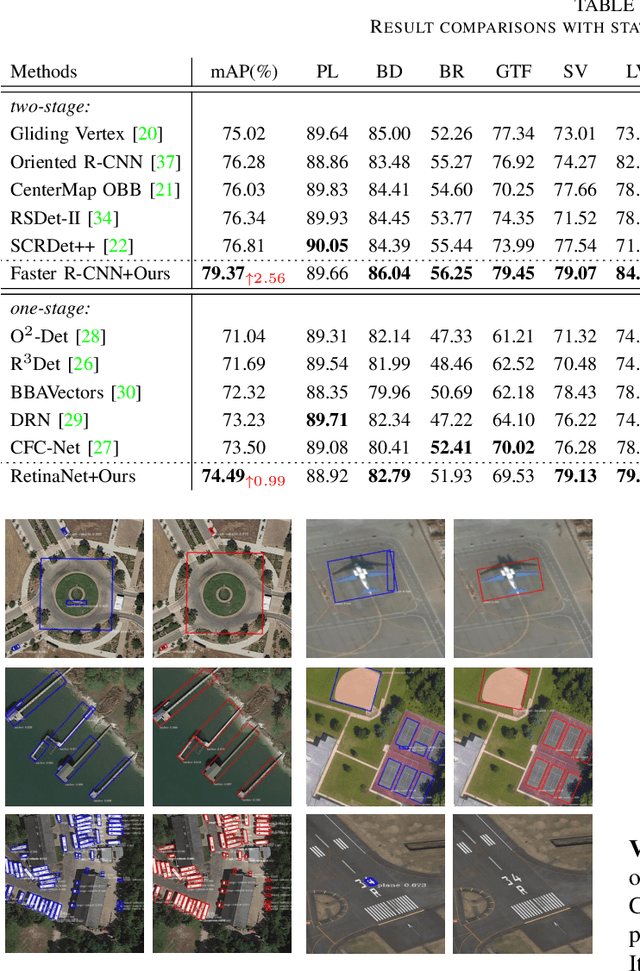
Object detection in aerial images is a fundamental research topic in the domain of geoscience and remote sensing. However, advanced progresses on this topic are mainly focused on the designment of backbone networks or header networks, but surprisingly ignored the neck ones. In this letter, we first analyse the importance of the neck network in object detection frameworks from the theory of information bottleneck. Then, to alleviate the information loss problem in the current neck network, we propose a global semantic network, which acts as a bridge from the backbone to the head network in a bidirectional global convolution manner. Compared to the existing neck networks, our method has advantages of capturing rich detailed information and less computational costs. Moreover, we further propose a fusion refinement module, which is used for feature fusion with rich details from different scales. To demonstrate the effectiveness and efficiency of our method, experiments are carried out on two challenging datasets (i.e., DOTA and HRSC2016). Results in terms of accuracy and computational complexity both can verify the superiority of our method.
Understanding Sinusoidal Neural Networks
Dec 04, 2022
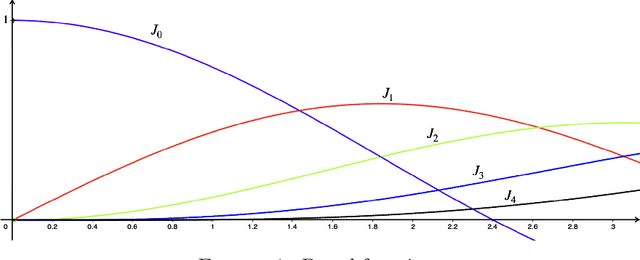
In this work, we investigate the representation capacity of multilayer perceptron networks that use the sine as activation function - sinusoidal neural networks. We show that the layer composition in such networks compacts information. For this, we prove that the composition of sinusoidal layers expands as a sum of sines consisting of a large number of new frequencies given by linear combinations of the weights of the network's first layer. We provide the expression of the corresponding amplitudes in terms of the Bessel functions and give an upper bound for them that can be used to control the resulting approximation.
VieCap4H - VLSP 2021: ObjectAoA -- Enhancing performance of Object Relation Transformer with Attention on Attention for Vietnamese image captioning
Nov 10, 2022

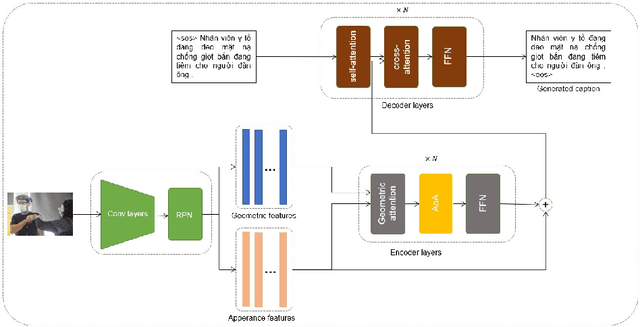

Image captioning is currently a challenging task that requires the ability to both understand visual information and use human language to describe this visual information in the image. In this paper, we propose an efficient way to improve the image understanding ability of transformer-based method by extending Object Relation Transformer architecture with Attention on Attention mechanism. Experiments on the VieCap4H dataset show that our proposed method significantly outperforms its original structure on both the public test and private test of the Image Captioning shared task held by VLSP.
RGMIM: Region-Guided Masked Image Modeling for COVID-19 Detection
Nov 01, 2022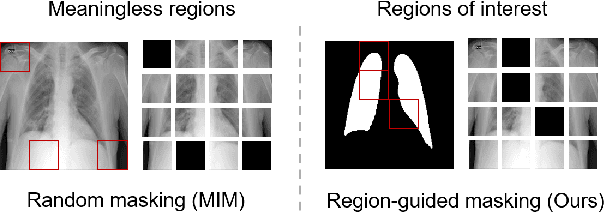
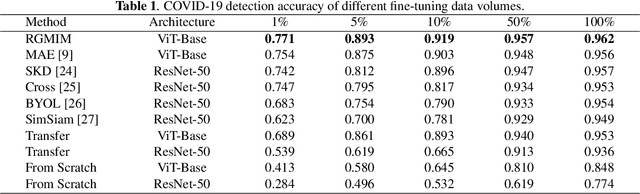
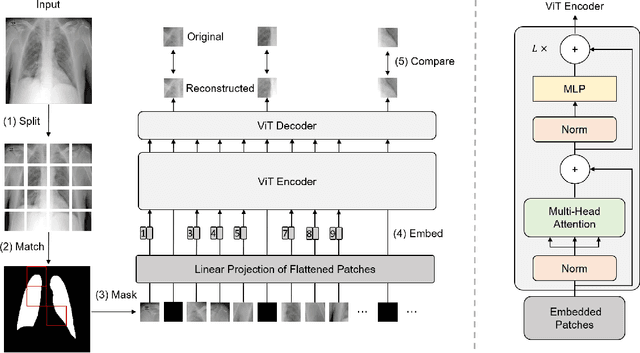
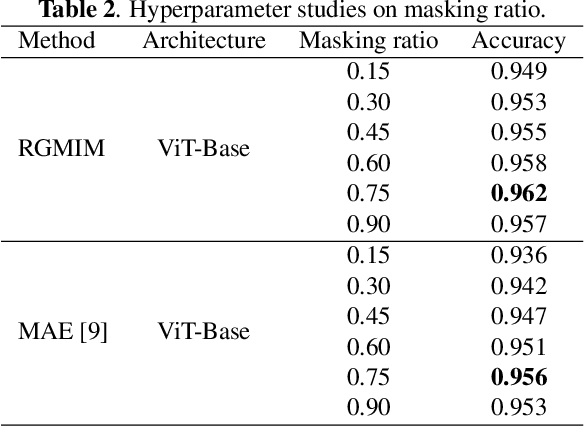
Self-supervised learning has developed rapidly and also advances computer-aided diagnosis in the medical field. Masked image modeling (MIM) is one of the self-supervised learning methods that masks a portion of input pixels and tries to predict the masked pixels. Traditional MIM methods often use a random masking strategy. However, medical images often have a small region of interest for disease detection compared to ordinary images. For example, the regions outside the lung do not contain the information for decision, which may cause the random masking strategy not to learn enough information for COVID-19 detection. Hence, we propose a novel region-guided masked image modeling method (RGMIM) for COVID-19 detection in this paper. In our method, we design a new masking strategy that uses lung mask information to locate valid regions to learn more helpful information for COVID-19 detection. Experimental results show that RGMIM can outperform other state-of-the-art self-supervised learning methods on an open COVID-19 radiography dataset.
Information Compression and Performance Evaluation of Tic-Tac-Toe's Evaluation Function Using Singular Value Decomposition
Jul 07, 2022
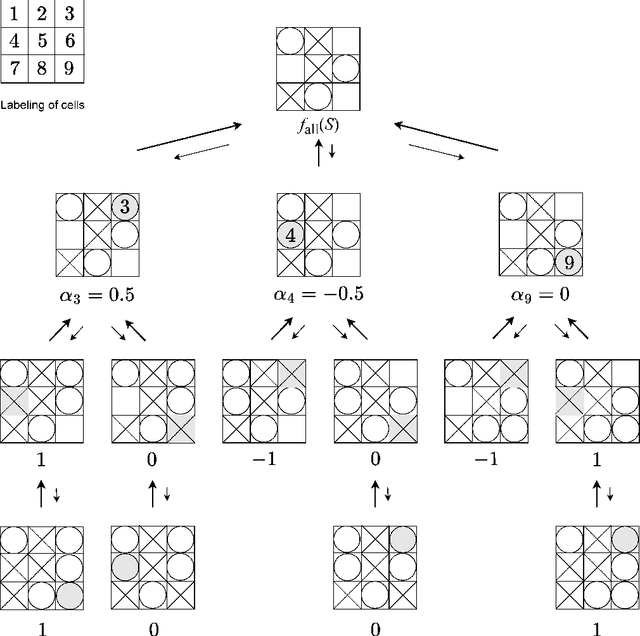
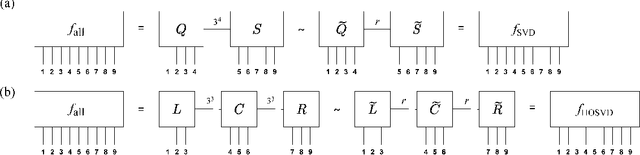
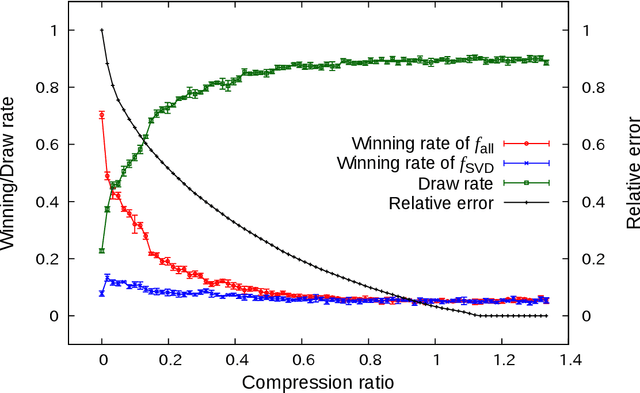
We approximated the evaluation function for the game Tic-Tac-Toe by singular value decomposition (SVD) and investigated the effect of approximation accuracy on winning rate. We first prepared the perfect evaluation function of Tic-Tac-Toe and performed low-rank approximation by considering the evaluation function as a ninth-order tensor. We found that we can reduce the amount of information of the evaluation function by 70% without significantly degrading the performance. Approximation accuracy and winning rate were strongly correlated but not perfectly proportional. We also investigated how the decomposition method of the evaluation function affects the performance. We considered two decomposition methods: simple SVD regarding the evaluation function as a matrix and the Tucker decomposition by higher-order SVD (HOSVD). At the same compression ratio, the strategy with the approximated evaluation function obtained by HOSVD exhibited a significantly higher winning rate than that obtained by SVD. These results suggest that SVD can effectively compress board game strategies and an optimal compression method that depends on the game exists.
Generalized Category Discovery with Decoupled Prototypical Network
Nov 28, 2022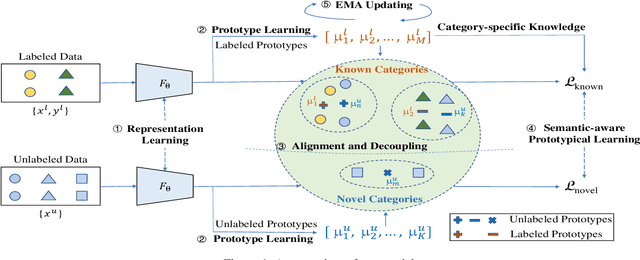

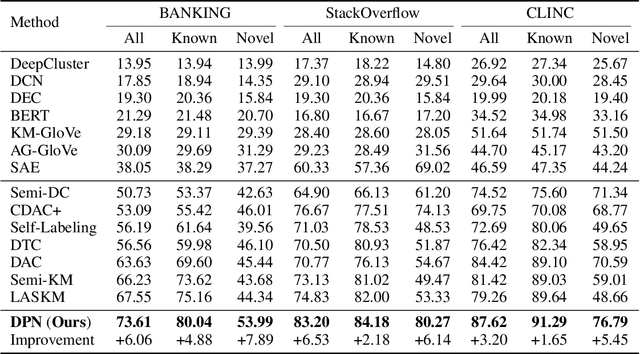
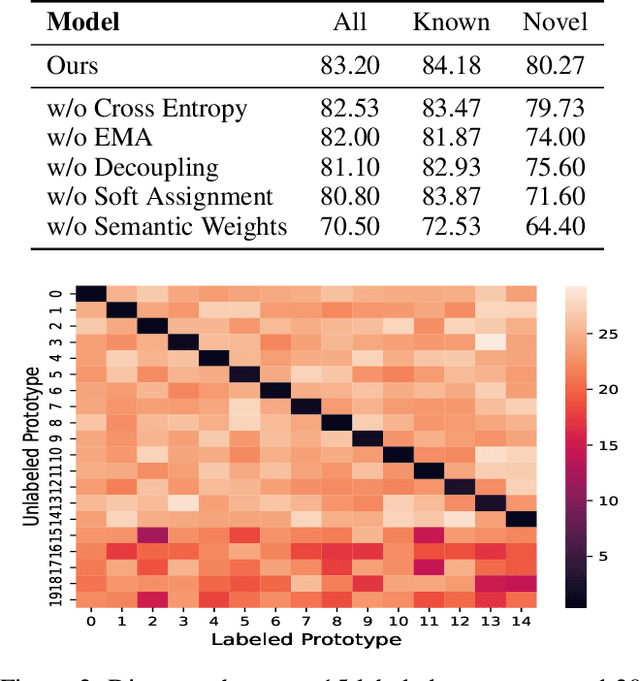
Generalized Category Discovery (GCD) aims to recognize both known and novel categories from a set of unlabeled data, based on another dataset labeled with only known categories. Without considering differences between known and novel categories, current methods learn about them in a coupled manner, which can hurt model's generalization and discriminative ability. Furthermore, the coupled training approach prevents these models transferring category-specific knowledge explicitly from labeled data to unlabeled data, which can lose high-level semantic information and impair model performance. To mitigate above limitations, we present a novel model called Decoupled Prototypical Network (DPN). By formulating a bipartite matching problem for category prototypes, DPN can not only decouple known and novel categories to achieve different training targets effectively, but also align known categories in labeled and unlabeled data to transfer category-specific knowledge explicitly and capture high-level semantics. Furthermore, DPN can learn more discriminative features for both known and novel categories through our proposed Semantic-aware Prototypical Learning (SPL). Besides capturing meaningful semantic information, SPL can also alleviate the noise of hard pseudo labels through semantic-weighted soft assignment. Extensive experiments show that DPN outperforms state-of-the-art models by a large margin on all evaluation metrics across multiple benchmark datasets. Code and data are available at https://github.com/Lackel/DPN.