 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Improving Chest X-Ray Classification by RNN-based Patient Monitoring
Oct 28, 2022
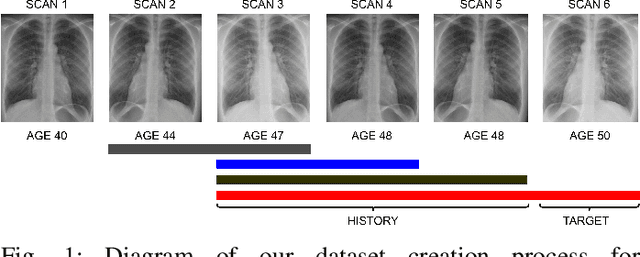
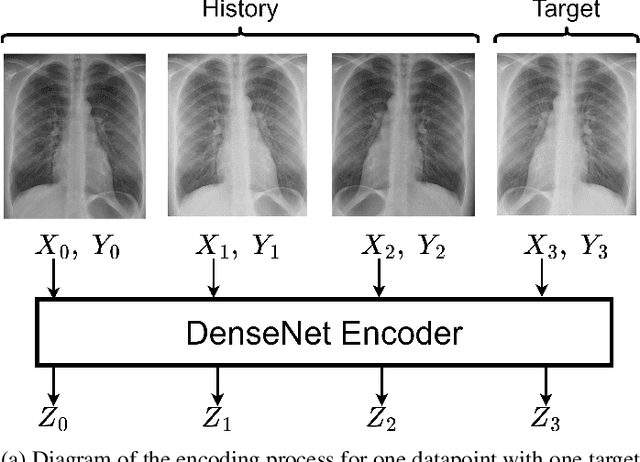
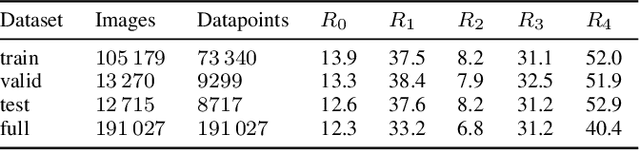

Chest X-Ray imaging is one of the most common radiological tools for detection of various pathologies related to the chest area and lung function. In a clinical setting, automated assessment of chest radiographs has the potential of assisting physicians in their decision making process and optimize clinical workflows, for example by prioritizing emergency patients. Most work analyzing the potential of machine learning models to classify chest X-ray images focuses on vision methods processing and predicting pathologies for one image at a time. However, many patients undergo such a procedure multiple times during course of a treatment or during a single hospital stay. The patient history, that is previous images and especially the corresponding diagnosis contain useful information that can aid a classification system in its prediction. In this study, we analyze how information about diagnosis can improve CNN-based image classification models by constructing a novel dataset from the well studied CheXpert dataset of chest X-rays. We show that a model trained on additional patient history information outperforms a model trained without the information by a significant margin. We provide code to replicate the dataset creation and model training.
Sparse Message Passing Network with Feature Integration for Online Multiple Object Tracking
Dec 06, 2022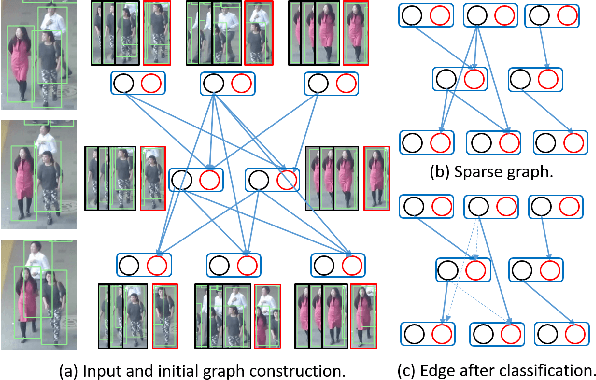
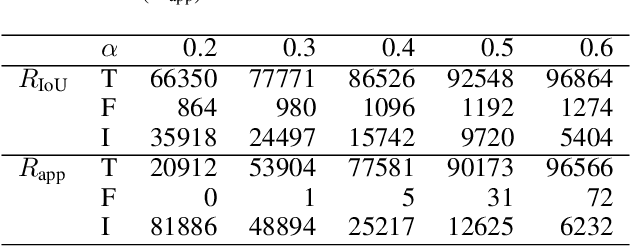
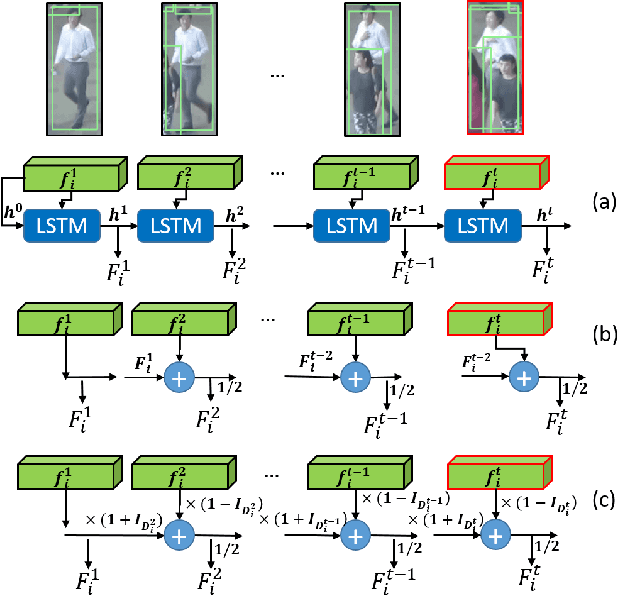
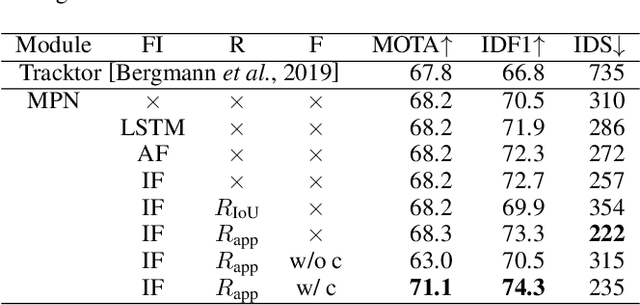
Existing Multiple Object Tracking (MOT) methods design complex architectures for better tracking performance. However, without a proper organization of input information, they still fail to perform tracking robustly and suffer from frequent identity switches. In this paper, we propose two novel methods together with a simple online Message Passing Network (MPN) to address these limitations. First, we explore different integration methods for the graph node and edge embeddings and put forward a new IoU (Intersection over Union) guided function, which improves long term tracking and handles identity switches. Second, we introduce a hierarchical sampling strategy to construct sparser graphs which allows to focus the training on more difficult samples. Experimental results demonstrate that a simple online MPN with these two contributions can perform better than many state-of-the-art methods. In addition, our association method generalizes well and can also improve the results of private detection based methods.
Data-Driven Sample Average Approximation with Covariate Information
Jul 27, 2022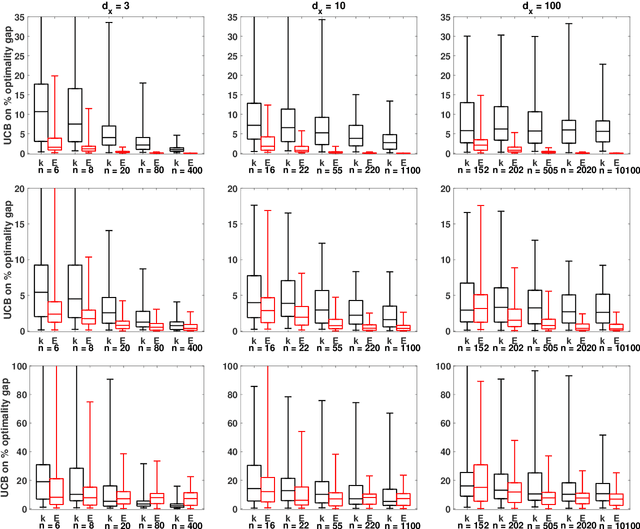
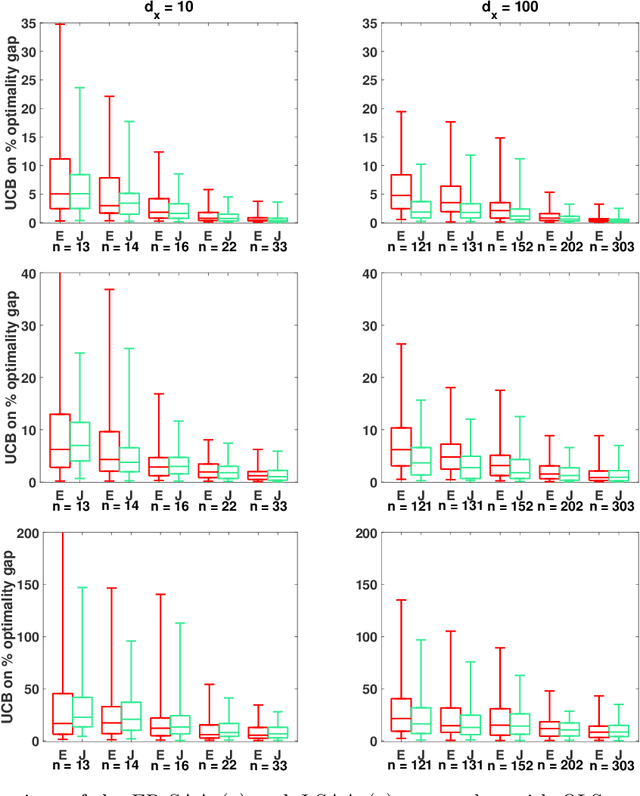
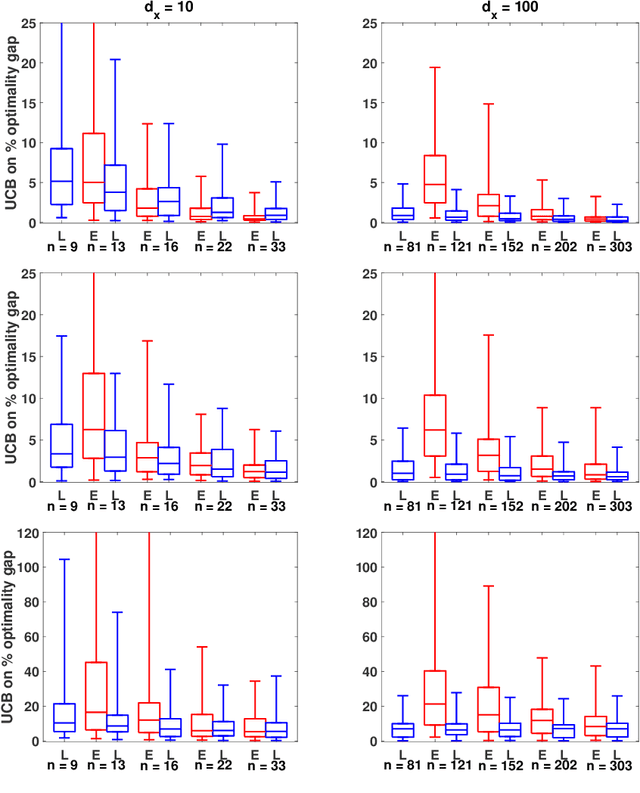
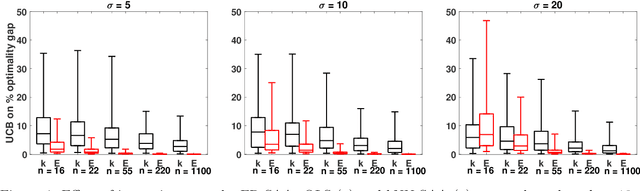
We study optimization for data-driven decision-making when we have observations of the uncertain parameters within the optimization model together with concurrent observations of covariates. Given a new covariate observation, the goal is to choose a decision that minimizes the expected cost conditioned on this observation. We investigate three data-driven frameworks that integrate a machine learning prediction model within a stochastic programming sample average approximation (SAA) for approximating the solution to this problem. Two of the SAA frameworks are new and use out-of-sample residuals of leave-one-out prediction models for scenario generation. The frameworks we investigate are flexible and accommodate parametric, nonparametric, and semiparametric regression techniques. We derive conditions on the data generation process, the prediction model, and the stochastic program under which solutions of these data-driven SAAs are consistent and asymptotically optimal, and also derive convergence rates and finite sample guarantees. Computational experiments validate our theoretical results, demonstrate the potential advantages of our data-driven formulations over existing approaches (even when the prediction model is misspecified), and illustrate the benefits of our new data-driven formulations in the limited data regime.
FRSUM: Towards Faithful Abstractive Summarization via Enhancing Factual Robustness
Nov 01, 2022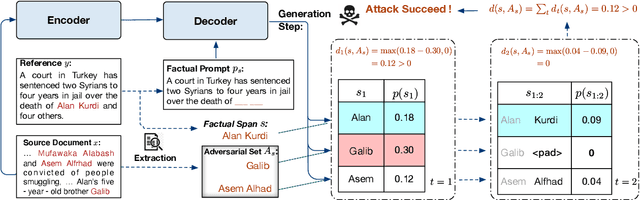
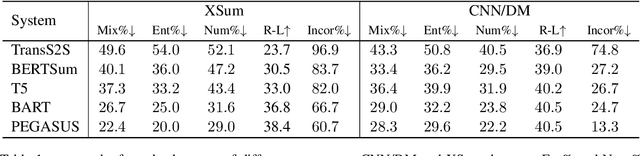
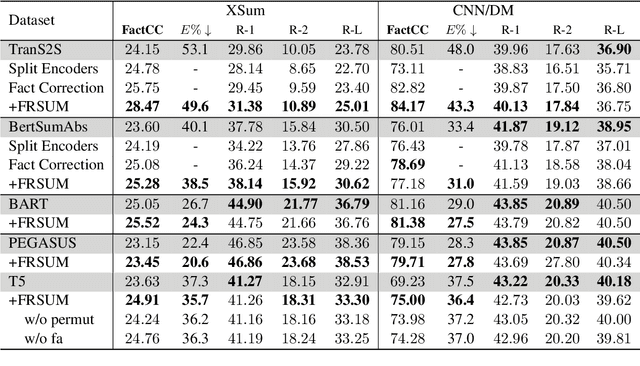
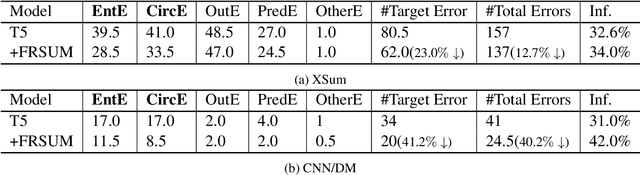
Despite being able to generate fluent and grammatical text, current Seq2Seq summarization models still suffering from the unfaithful generation problem. In this paper, we study the faithfulness of existing systems from a new perspective of factual robustness which is the ability to correctly generate factual information over adversarial unfaithful information. We first measure a model's factual robustness by its success rate to defend against adversarial attacks when generating factual information. The factual robustness analysis on a wide range of current systems shows its good consistency with human judgments on faithfulness. Inspired by these findings, we propose to improve the faithfulness of a model by enhancing its factual robustness. Specifically, we propose a novel training strategy, namely FRSUM, which teaches the model to defend against both explicit adversarial samples and implicit factual adversarial perturbations. Extensive automatic and human evaluation results show that FRSUM consistently improves the faithfulness of various Seq2Seq models, such as T5, BART.
Free-form 3D Scene Inpainting with Dual-stream GAN
Dec 16, 2022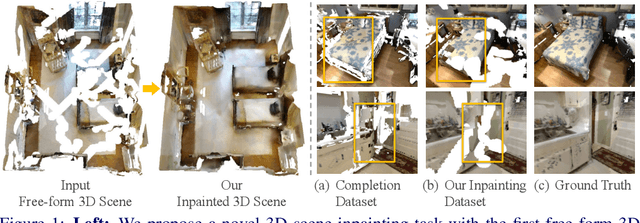
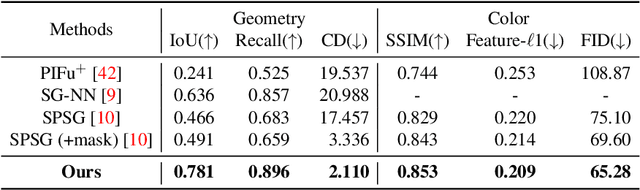
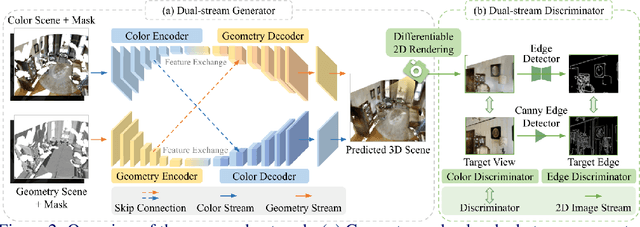
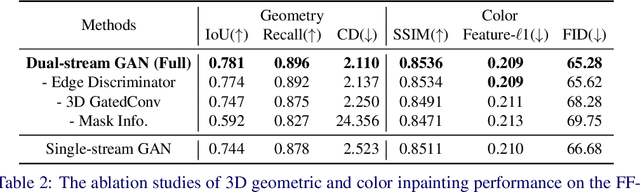
Nowadays, the need for user editing in a 3D scene has rapidly increased due to the development of AR and VR technology. However, the existing 3D scene completion task (and datasets) cannot suit the need because the missing regions in scenes are generated by the sensor limitation or object occlusion. Thus, we present a novel task named free-form 3D scene inpainting. Unlike scenes in previous 3D completion datasets preserving most of the main structures and hints of detailed shapes around missing regions, the proposed inpainting dataset, FF-Matterport, contains large and diverse missing regions formed by our free-form 3D mask generation algorithm that can mimic human drawing trajectories in 3D space. Moreover, prior 3D completion methods cannot perform well on this challenging yet practical task, simply interpolating nearby geometry and color context. Thus, a tailored dual-stream GAN method is proposed. First, our dual-stream generator, fusing both geometry and color information, produces distinct semantic boundaries and solves the interpolation issue. To further enhance the details, our lightweight dual-stream discriminator regularizes the geometry and color edges of the predicted scenes to be realistic and sharp. We conducted experiments with the proposed FF-Matterport dataset. Qualitative and quantitative results validate the superiority of our approach over existing scene completion methods and the efficacy of all proposed components.
Mystique: Accurate and Scalable Production AI Benchmarks Generation
Dec 16, 2022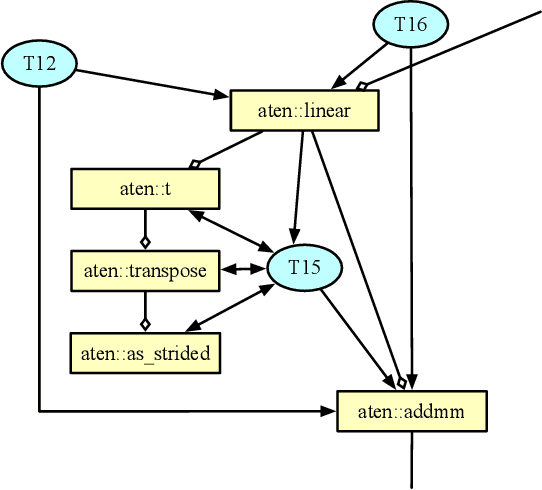
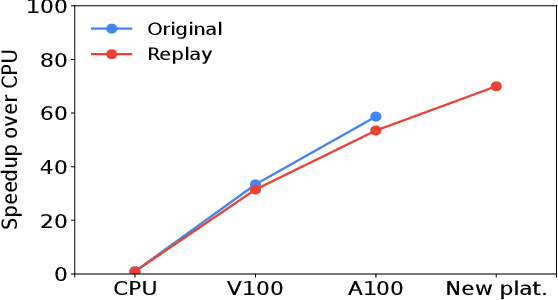
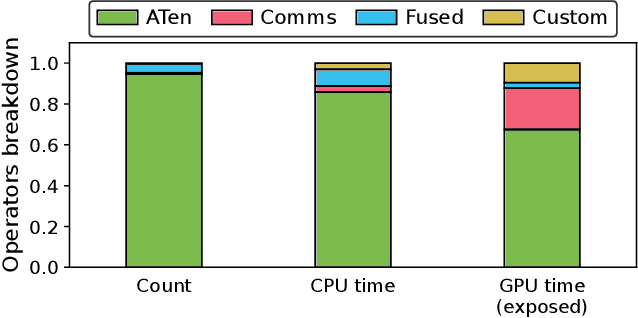
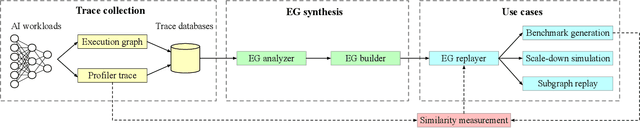
Building and maintaining large AI fleets to efficiently support the fast-growing DL workloads is an active research topic for modern cloud infrastructure providers. Generating accurate benchmarks plays an essential role in the design and evaluation of rapidly evoloving software and hardware solutions in this area. Two fundamental challenges to make this process scalable are (i) workload representativeness and (ii) the ability to quickly incorporate changes to the fleet into the benchmarks. To overcome these issues, we propose Mystique, an accurate and scalable framework for production AI benchmark generation. It leverages the PyTorch execution graph (EG), a new feature that captures the runtime information of AI models at the granularity of operators, in a graph format, together with their metadata. By sourcing EG traces from the fleet, we can build AI benchmarks that are portable and representative. Mystique is scalable, with its lightweight data collection, in terms of runtime overhead and user instrumentation efforts. It is also adaptive, as the expressiveness and composability of EG format allows flexible user control over benchmark creation. We evaluate our methodology on several production AI workloads, and show that benchmarks generated with Mystique closely resemble original AI models, both in execution time and system-level metrics. We also showcase the portability of the generated benchmarks across platforms, and demonstrate several use cases enabled by the fine-grained composability of the execution graph.
Unimodal and Multimodal Representation Training for Relation Extraction
Nov 11, 2022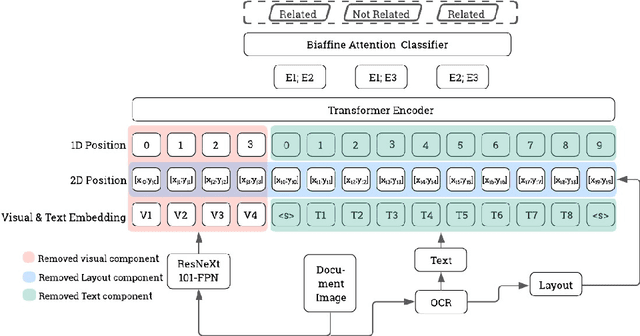
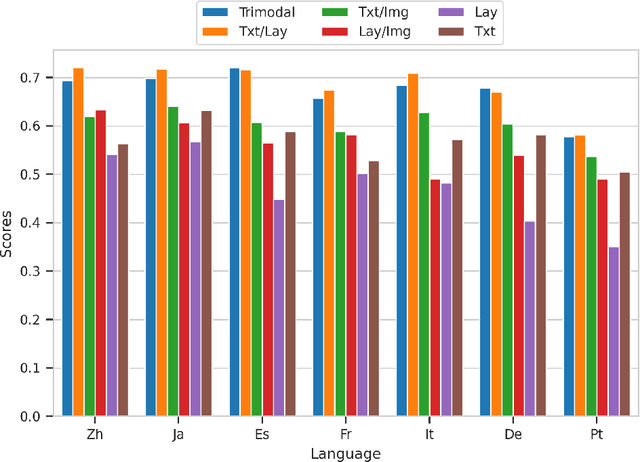
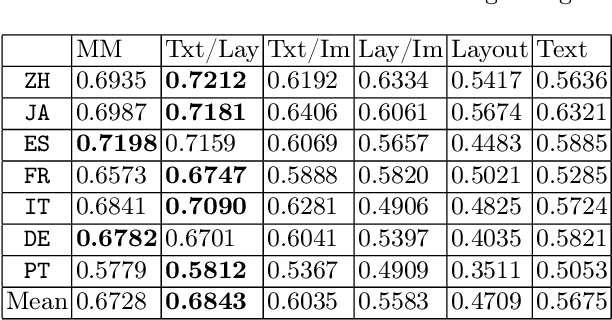
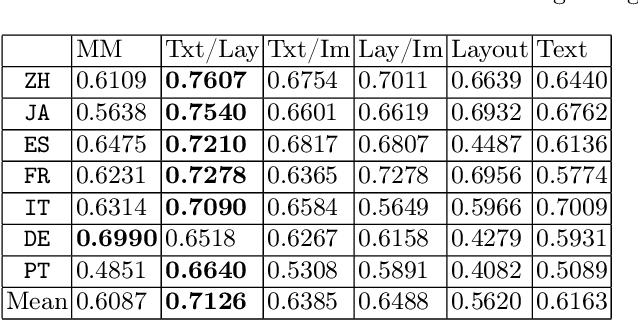
Multimodal integration of text, layout and visual information has achieved SOTA results in visually rich document understanding (VrDU) tasks, including relation extraction (RE). However, despite its importance, evaluation of the relative predictive capacity of these modalities is less prevalent. Here, we demonstrate the value of shared representations for RE tasks by conducting experiments in which each data type is iteratively excluded during training. In addition, text and layout data are evaluated in isolation. While a bimodal text and layout approach performs best (F1=0.684), we show that text is the most important single predictor of entity relations. Additionally, layout geometry is highly predictive and may even be a feasible unimodal approach. Despite being less effective, we highlight circumstances where visual information can bolster performance. In total, our results demonstrate the efficacy of training joint representations for RE.
Using dynamic circles and squares to visualize spatio-temporal variation
Nov 11, 2022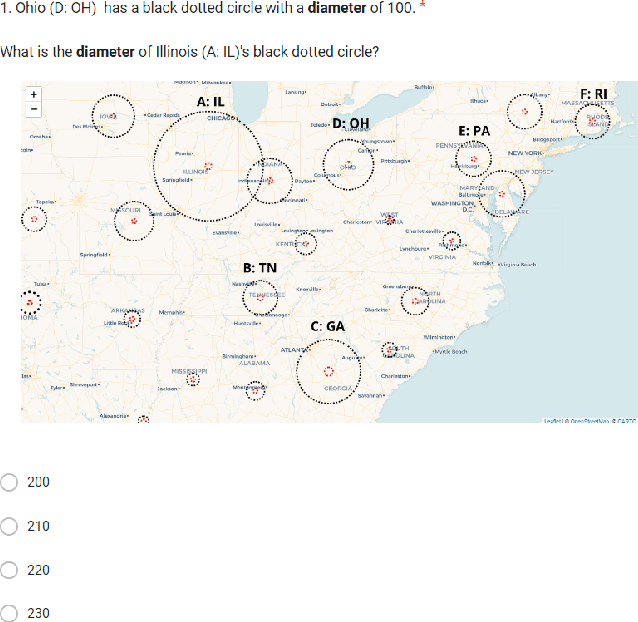
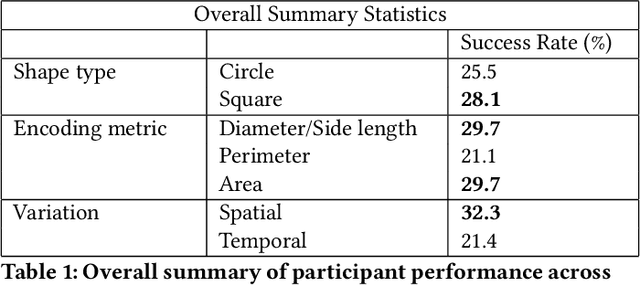
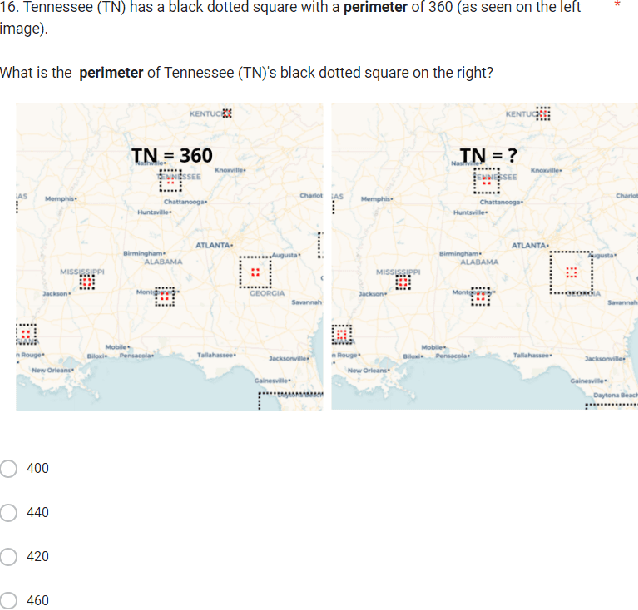
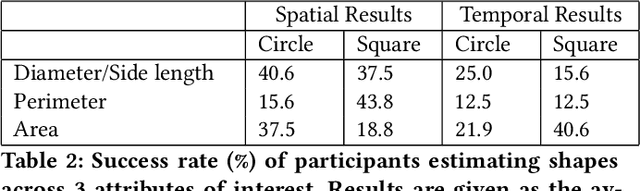
Visualizations such as bar charts, scatter plots, and objects on geographical maps often convey critical information, including exact and relative numeric values, using shapes. The choice of shape and method of encoding information is often arbitrarily, or based on convention. However, past studies have shown that the human eye can be fooled by visual representations. The Ebbinghaus illusion demonstrates that the perceived relative sizes of shapes depends on their configuration, which in turn can affect judgements, especially in visualizations like proportional symbol maps. In this study we evaluate the effects of varying the type of shapes and metrics for encoding data in visual representations on a spatio-temporal map interface. We find that some combinations of shape and metric are more conducive to accurate human judgements than others, and provide recommendations for applying these findings in future visualization designs.
Rate-Splitting Multiple Access for Uplink Massive MIMO With Electromagnetic Exposure Constraints
Dec 14, 2022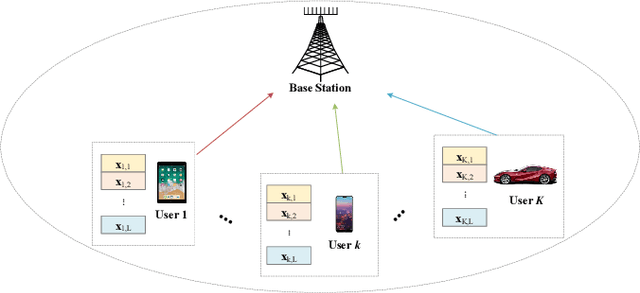
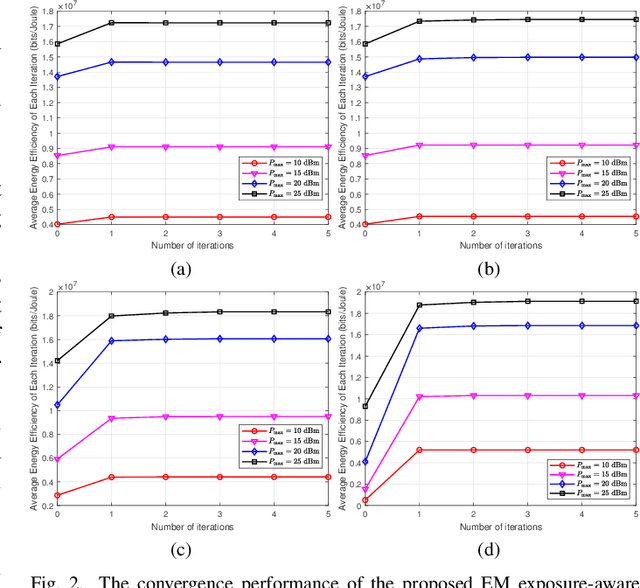
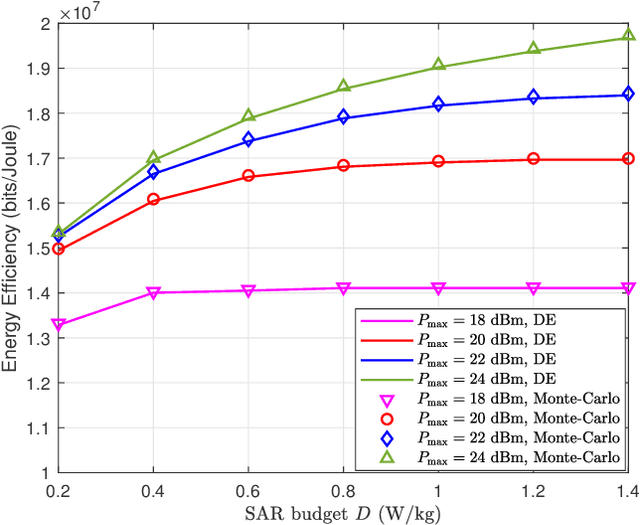
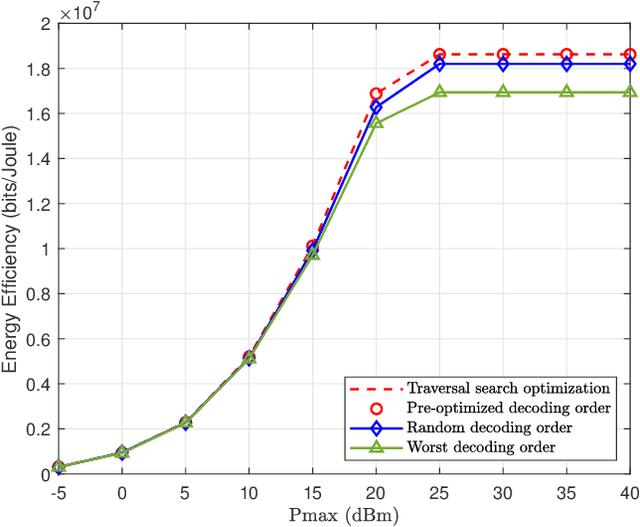
Over the past few years, the prevalence of wireless devices has become one of the essential sources of electromagnetic (EM) radiation to the public. Facing with the swift development of wireless communications, people are skeptical about the risks of long-term exposure to EM radiation. As EM exposure is required to be restricted at user terminals, it is inefficient to blindly decrease the transmit power, which leads to limited spectral efficiency and energy efficiency (EE). Recently, rate-splitting multiple access (RSMA) has been proposed as an effective way to provide higher wireless transmission performance, which is a promising technology for future wireless communications. To this end, we propose using RSMA to increase the EE of massive MIMO uplink while limiting the EM exposure of users. In particularly, we investigate the optimization of the transmit covariance matrices and decoding order using statistical channel state information (CSI). The problem is formulated as non-convex mixed integer program, which is in general difficult to handle. We first propose a modified water-filling scheme to obtain the transmit covariance matrices with fixed decoding order. Then, a greedy approach is proposed to obtain the decoding permutation. Numerical results verify the effectiveness of the proposed EM exposure-aware EE maximization scheme for uplink RSMA.
Hierarchical Strategies for Cooperative Multi-Agent Reinforcement Learning
Dec 14, 2022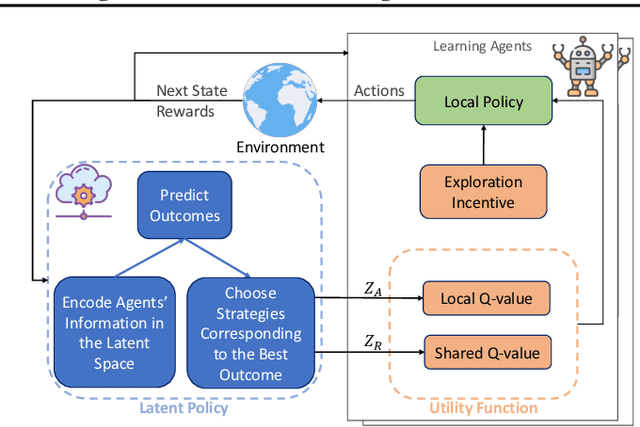
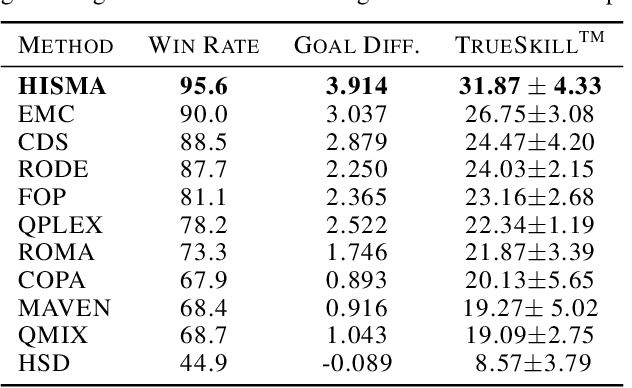
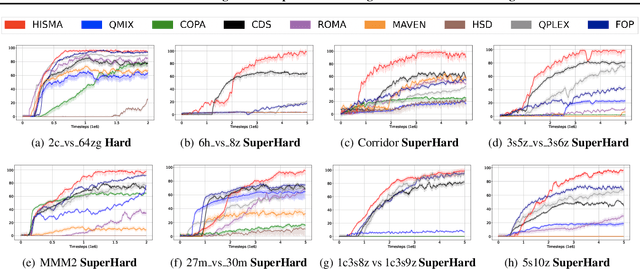

Adequate strategizing of agents behaviors is essential to solving cooperative MARL problems. One intuitively beneficial yet uncommon method in this domain is predicting agents future behaviors and planning accordingly. Leveraging this point, we propose a two-level hierarchical architecture that combines a novel information-theoretic objective with a trajectory prediction model to learn a strategy. To this end, we introduce a latent policy that learns two types of latent strategies: individual $z_A$, and relational $z_R$ using a modified Graph Attention Network module to extract interaction features. We encourage each agent to behave according to the strategy by conditioning its local $Q$ functions on $z_A$, and we further equip agents with a shared $Q$ function that conditions on $z_R$. Additionally, we introduce two regularizers to allow predicted trajectories to be accurate and rewarding. Empirical results on Google Research Football (GRF) and StarCraft (SC) II micromanagement tasks show that our method establishes a new state of the art being, to the best of our knowledge, the first MARL algorithm to solve all super hard SC II scenarios as well as the GRF full game with a win rate higher than $95\%$, thus outperforming all existing methods. Videos and brief overview of the methods and results are available at: https://sites.google.com/view/hier-strats-marl/home.