 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
IPProtect: protecting the intellectual property of visual datasets during data valuation
Dec 22, 2022
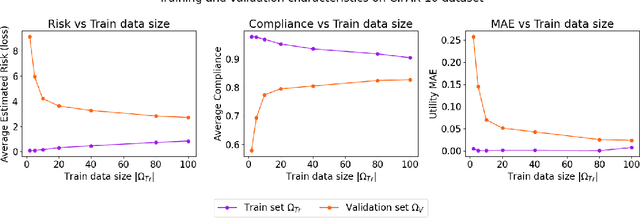
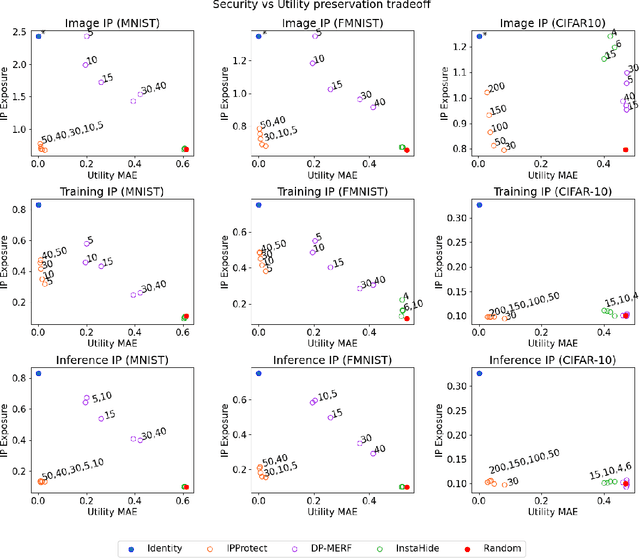
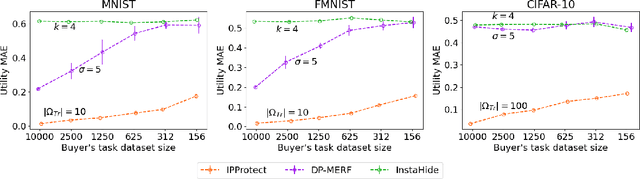
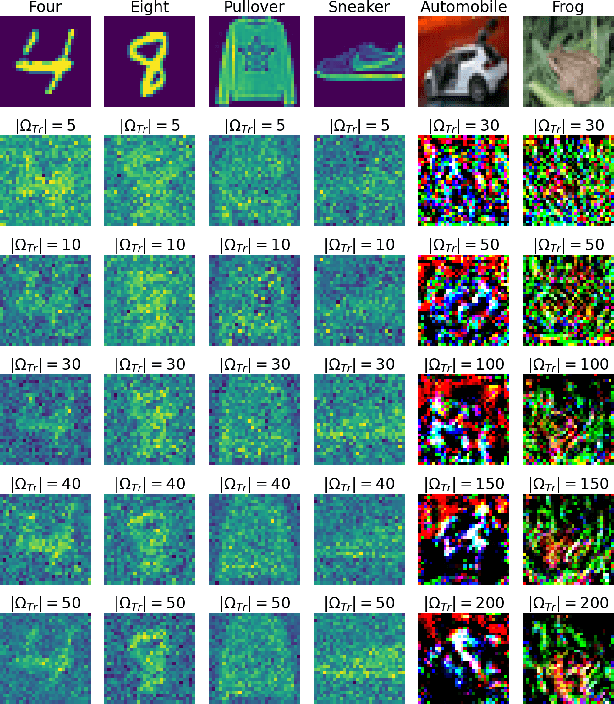
Data trading is essential to accelerate the development of data-driven machine learning pipelines. The central problem in data trading is to estimate the utility of a seller's dataset with respect to a given buyer's machine learning task, also known as data valuation. Typically, data valuation requires one or more participants to share their raw dataset with others, leading to potential risks of intellectual property (IP) violations. In this paper, we tackle the novel task of preemptively protecting the IP of datasets that need to be shared during data valuation. First, we identify and formalize two kinds of novel IP risks in visual datasets: data-item (image) IP and statistical (dataset) IP. Then, we propose a novel algorithm to convert the raw dataset into a sanitized version, that provides resistance to IP violations, while at the same time allowing accurate data valuation. The key idea is to limit the transfer of information from the raw dataset to the sanitized dataset, thereby protecting against potential intellectual property violations. Next, we analyze our method for the likely existence of a solution and immunity against reconstruction attacks. Finally, we conduct extensive experiments on three computer vision datasets demonstrating the advantages of our method in comparison to other baselines.
Vehicle in Virtual Environment (VVE) Method
Dec 22, 2022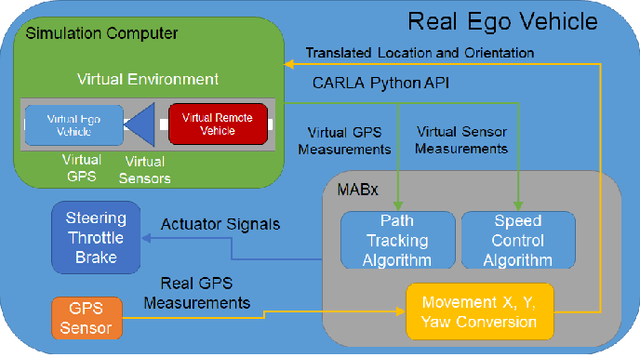

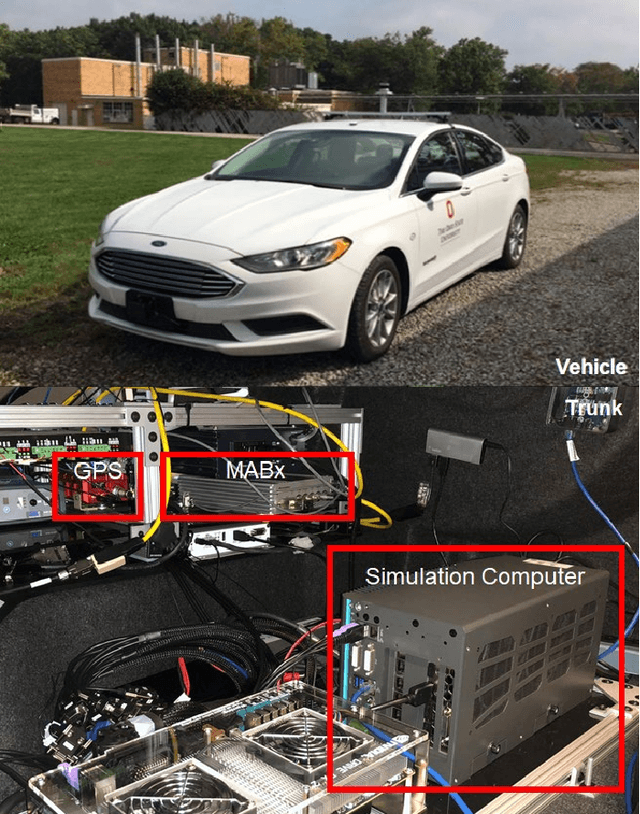
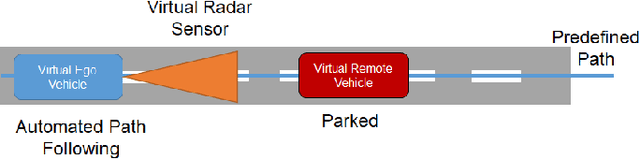
Autonomous vehicle (AV) algorithms need to be tested extensively in order to make sure the vehicle and the passengers will be safe while using it after the implementation. Testing these algorithms in real world create another important safety critical point. Real world testing is also subjected to limitations such as logistic limitations to carry or drive the vehicle to a certain location. For this purpose, hardware in the loop (HIL) simulations as well as virtual environments such as CARLA and LG SVL are used widely. This paper discusses a method that combines the real vehicle with the virtual world, called vehicle in virtual environment (VVE). This method projects the vehicle location and heading into a virtual world for desired testing, and transfers back the information from sensors in the virtual world to the vehicle. As a result, while vehicle is moving in the real world, it simultaneously moves in the virtual world and obtains the situational awareness via multiple virtual sensors. This would allow testing in a safe environment with the real vehicle while providing some additional benefits on vehicle dynamics fidelity, logistics limitations and passenger experience testing. The paper also demonstrates an example case study where path following and the virtual sensors are utilized to test a radar based stopping algorithm.
MIST: a Large-Scale Annotated Resource and Neural Models for Functions of Modal Verbs in English Scientific Text
Dec 14, 2022
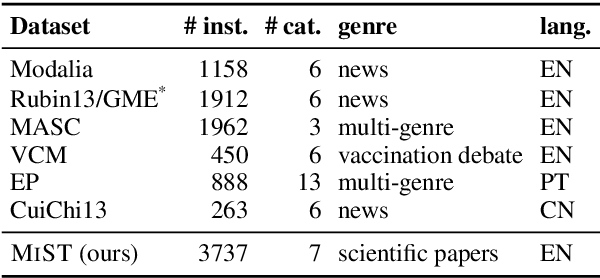
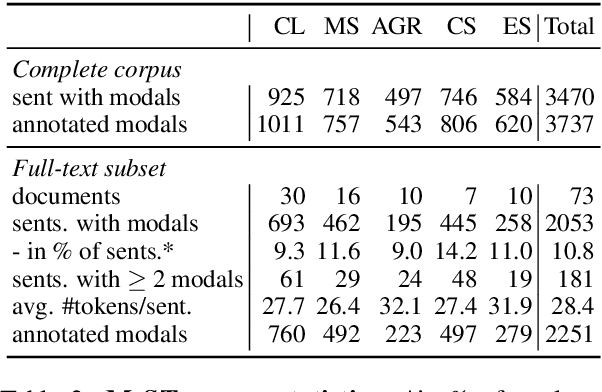
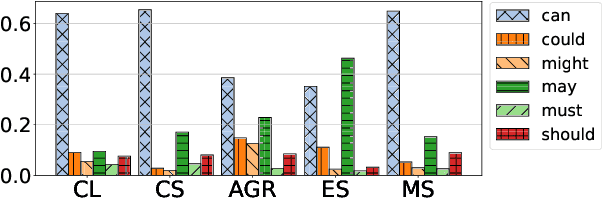
Modal verbs (e.g., "can", "should", or "must") occur highly frequently in scientific articles. Decoding their function is not straightforward: they are often used for hedging, but they may also denote abilities and restrictions. Understanding their meaning is important for various NLP tasks such as writing assistance or accurate information extraction from scientific text. To foster research on the usage of modals in this genre, we introduce the MIST (Modals In Scientific Text) dataset, which contains 3737 modal instances in five scientific domains annotated for their semantic, pragmatic, or rhetorical function. We systematically evaluate a set of competitive neural architectures on MIST. Transfer experiments reveal that leveraging non-scientific data is of limited benefit for modeling the distinctions in MIST. Our corpus analysis provides evidence that scientific communities differ in their usage of modal verbs, yet, classifiers trained on scientific data generalize to some extent to unseen scientific domains.
Synthesis of Adversarial DDOS Attacks Using Tabular Generative Adversarial Networks
Dec 14, 2022
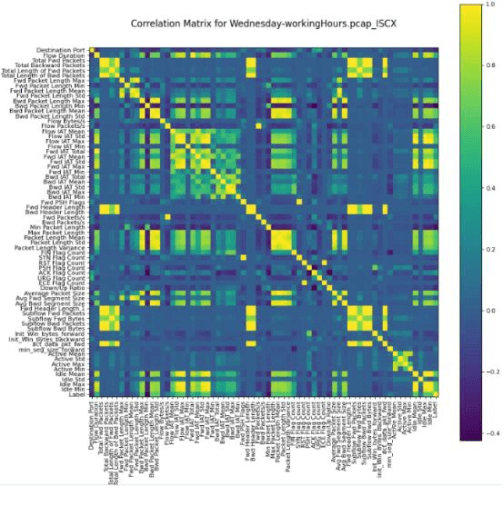
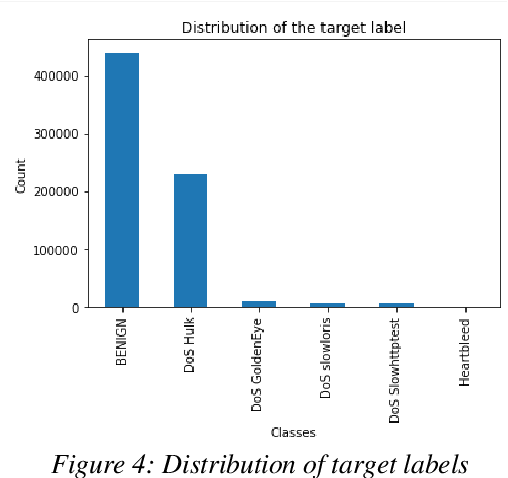
Network Intrusion Detection Systems (NIDS) are tools or software that are widely used to maintain the computer networks and information systems keeping them secure and preventing malicious traffics from penetrating into them, as they flag when somebody is trying to break into the system. Best effort has been set up on these systems, and the results achieved so far are quite satisfying, however, new types of attacks stand out as the technology of attacks keep evolving, one of these attacks are the attacks based on Generative Adversarial Networks (GAN) that can evade machine learning IDS leaving them vulnerable. This project investigates the impact of the Adversarial Attacks synthesized using real DDoS attacks generated using GANs on the IDS. The objective is to discover how will these systems react towards synthesized attacks. marking the vulnerability and weakness points of these systems so we could fix them.
On Analyzing the Role of Image for Visual-enhanced Relation Extraction
Nov 14, 2022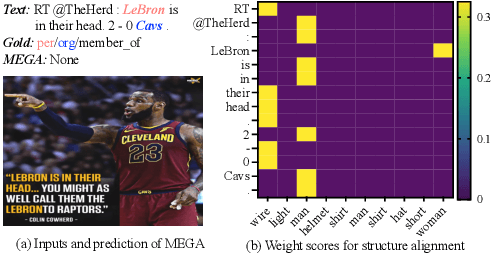

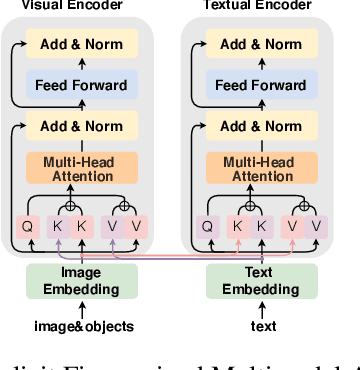
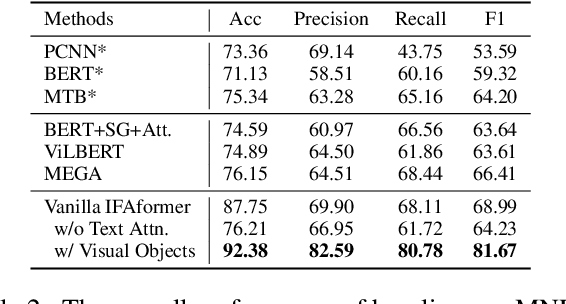
Multimodal relation extraction is an essential task for knowledge graph construction. In this paper, we take an in-depth empirical analysis that indicates the inaccurate information in the visual scene graph leads to poor modal alignment weights, further degrading performance. Moreover, the visual shuffle experiments illustrate that the current approaches may not take full advantage of visual information. Based on the above observation, we further propose a strong baseline with an implicit fine-grained multimodal alignment based on Transformer for multimodal relation extraction. Experimental results demonstrate the better performance of our method. Codes are available at https://github.com/zjunlp/DeepKE/tree/main/example/re/multimodal.
Are All Edges Necessary? A Unified Framework for Graph Purification
Nov 09, 2022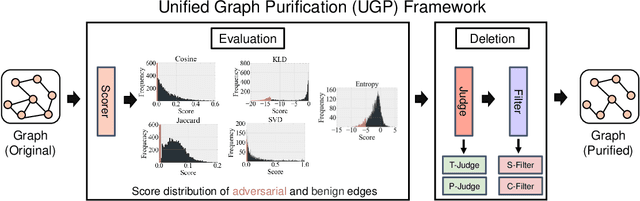
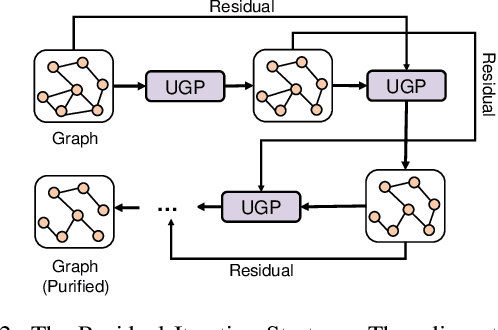

Graph Neural Networks (GNNs) as deep learning models working on graph-structure data have achieved advanced performance in many works. However, it has been proved repeatedly that, not all edges in a graph are necessary for the training of machine learning models. In other words, some of the connections between nodes may bring redundant or even misleading information to downstream tasks. In this paper, we try to provide a method to drop edges in order to purify the graph data from a new perspective. Specifically, it is a framework to purify graphs with the least loss of information, under which the core problems are how to better evaluate the edges and how to delete the relatively redundant edges with the least loss of information. To address the above two problems, we propose several measurements for the evaluation and different judges and filters for the edge deletion. We also introduce a residual-iteration strategy and a surrogate model for measurements requiring unknown information. The experimental results show that our proposed measurements for KL divergence with constraints to maintain the connectivity of the graph and delete edges in an iterative way can find out the most edges while keeping the performance of GNNs. What's more, further experiments show that this method also achieves the best defense performance against adversarial attacks.
A Scope Sensitive and Result Attentive Model for Multi-Intent Spoken Language Understanding
Nov 22, 2022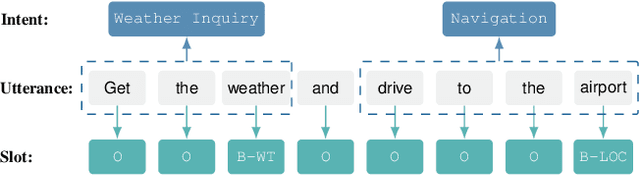
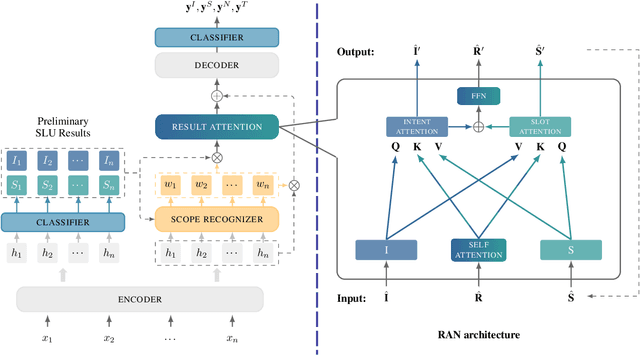
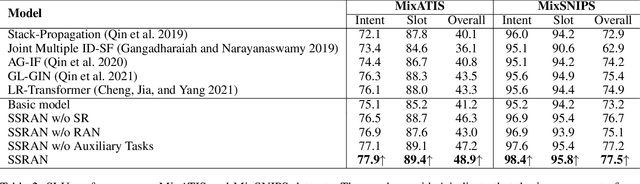
Multi-Intent Spoken Language Understanding (SLU), a novel and more complex scenario of SLU, is attracting increasing attention. Unlike traditional SLU, each intent in this scenario has its specific scope. Semantic information outside the scope even hinders the prediction, which tremendously increases the difficulty of intent detection. More seriously, guiding slot filling with these inaccurate intent labels suffers error propagation problems, resulting in unsatisfied overall performance. To solve these challenges, in this paper, we propose a novel Scope-Sensitive Result Attention Network (SSRAN) based on Transformer, which contains a Scope Recognizer (SR) and a Result Attention Network (RAN). Scope Recognizer assignments scope information to each token, reducing the distraction of out-of-scope tokens. Result Attention Network effectively utilizes the bidirectional interaction between results of slot filling and intent detection, mitigating the error propagation problem. Experiments on two public datasets indicate that our model significantly improves SLU performance (5.4\% and 2.1\% on Overall accuracy) over the state-of-the-art baseline.
PESE: Event Structure Extraction using Pointer Network based Encoder-Decoder Architecture
Nov 22, 2022
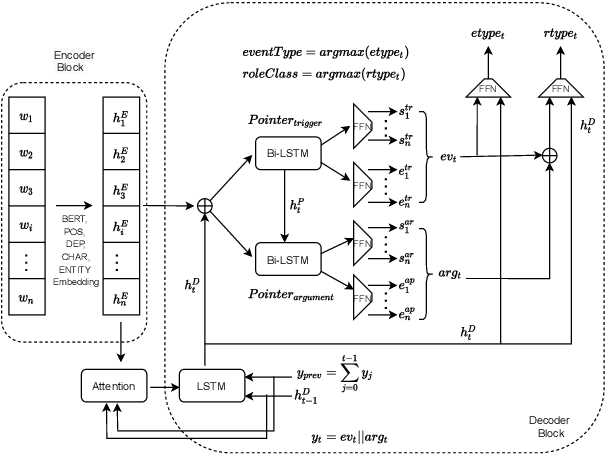
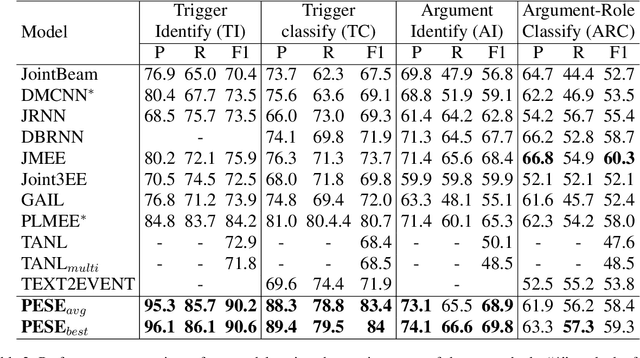
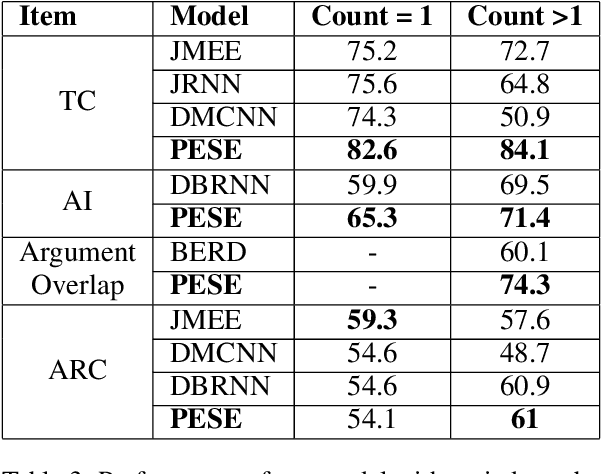
The task of event extraction (EE) aims to find the events and event-related argument information from the text and represent them in a structured format. Most previous works try to solve the problem by separately identifying multiple substructures and aggregating them to get the complete event structure. The problem with the methods is that it fails to identify all the interdependencies among the event participants (event-triggers, arguments, and roles). In this paper, we represent each event record in a unique tuple format that contains trigger phrase, trigger type, argument phrase, and corresponding role information. Our proposed pointer network-based encoder-decoder model generates an event tuple in each time step by exploiting the interactions among event participants and presenting a truly end-to-end solution to the EE task. We evaluate our model on the ACE2005 dataset, and experimental results demonstrate the effectiveness of our model by achieving competitive performance compared to the state-of-the-art methods.
Prune and distill: similar reformatting of image information along rat visual cortex and deep neural networks
May 27, 2022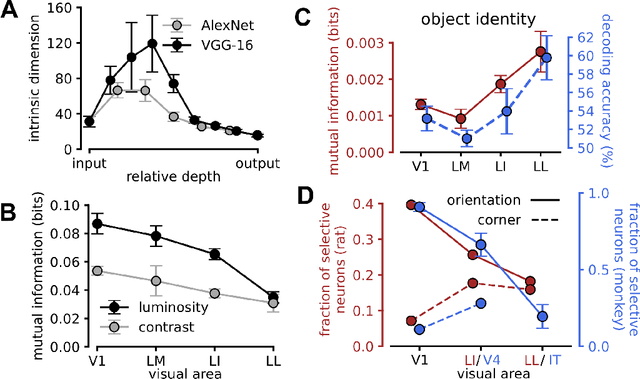
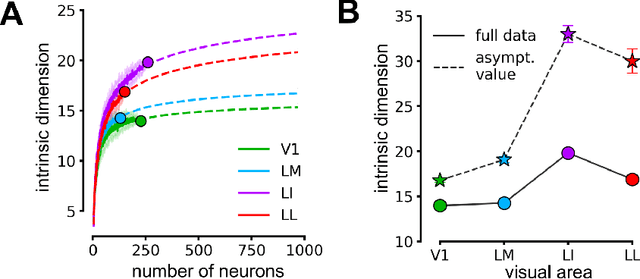
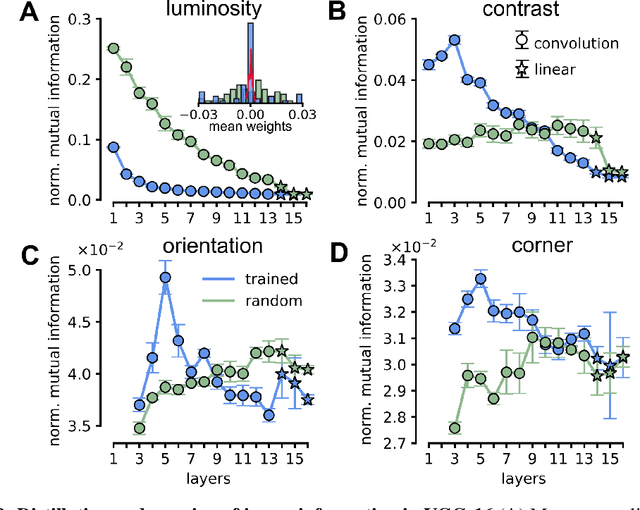
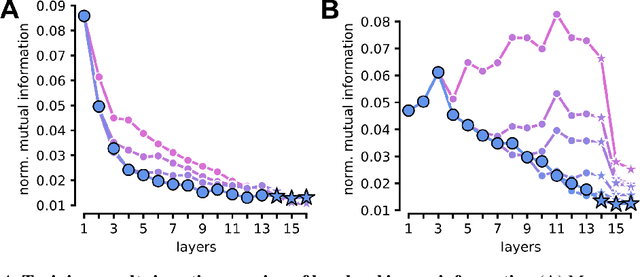
Visual object recognition has been extensively studied in both neuroscience and computer vision. Recently, the most popular class of artificial systems for this task, deep convolutional neural networks (CNNs), has been shown to provide excellent models for its functional analogue in the brain, the ventral stream in visual cortex. This has prompted questions on what, if any, are the common principles underlying the reformatting of visual information as it flows through a CNN or the ventral stream. Here we consider some prominent statistical patterns that are known to exist in the internal representations of either CNNs or the visual cortex and look for them in the other system. We show that intrinsic dimensionality (ID) of object representations along the rat homologue of the ventral stream presents two distinct expansion-contraction phases, as previously shown for CNNs. Conversely, in CNNs, we show that training results in both distillation and active pruning (mirroring the increase in ID) of low- to middle-level image information in single units, as representations gain the ability to support invariant discrimination, in agreement with previous observations in rat visual cortex. Taken together, our findings suggest that CNNs and visual cortex share a similarly tight relationship between dimensionality expansion/reduction of object representations and reformatting of image information.
A Unified Approach to Differentially Private Bayes Point Estimation
Nov 18, 2022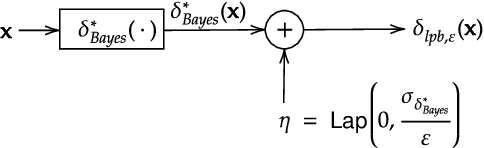
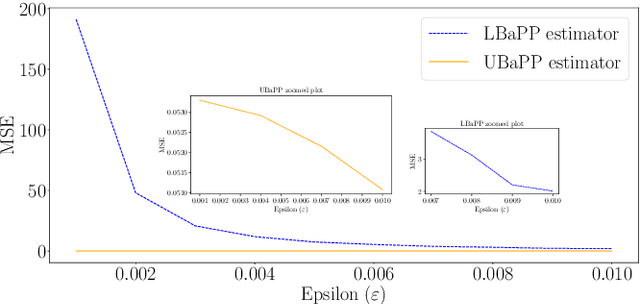
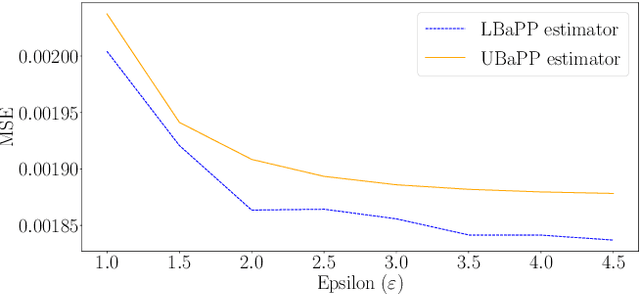
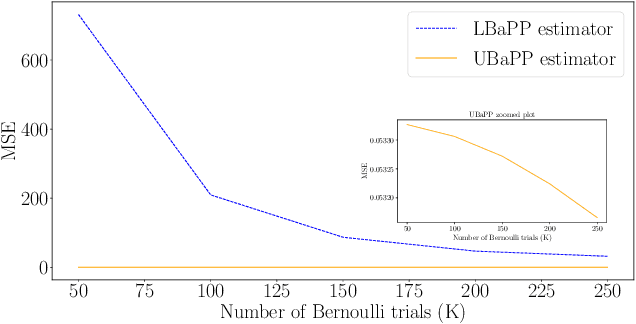
Parameter estimation in statistics and system identification relies on data that may contain sensitive information. To protect this sensitive information, the notion of \emph{differential privacy} (DP) has been proposed, which enforces confidentiality by introducing randomization in the estimates. Standard algorithms for differentially private estimation are based on adding an appropriate amount of noise to the output of a traditional point estimation method. This leads to an accuracy-privacy trade off, as adding more noise reduces the accuracy while increasing privacy. In this paper, we propose a new Unified Bayes Private Point (UBaPP) approach to Bayes point estimation of the unknown parameters of a data generating mechanism under a DP constraint, that achieves a better accuracy-privacy trade off than traditional approaches. We verify the performance of our approach on a simple numerical example.