 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Trajectory Smoothing Using GNSS/PDR Integration Via Factor Graph Optimization in Urban Canyons
Dec 29, 2022
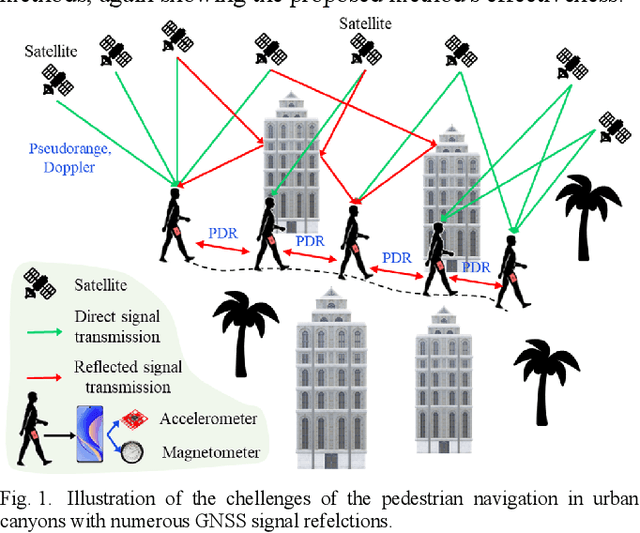

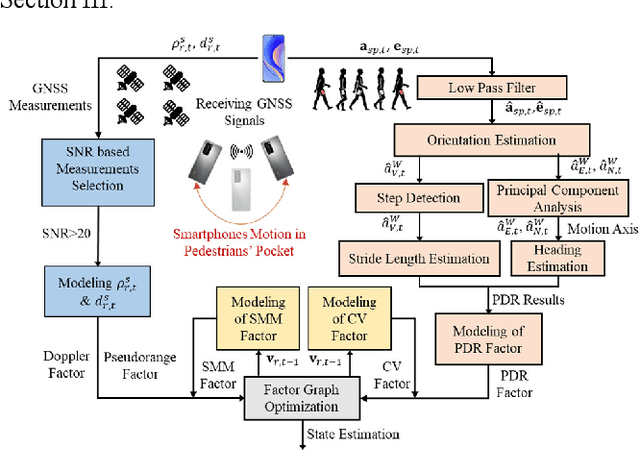
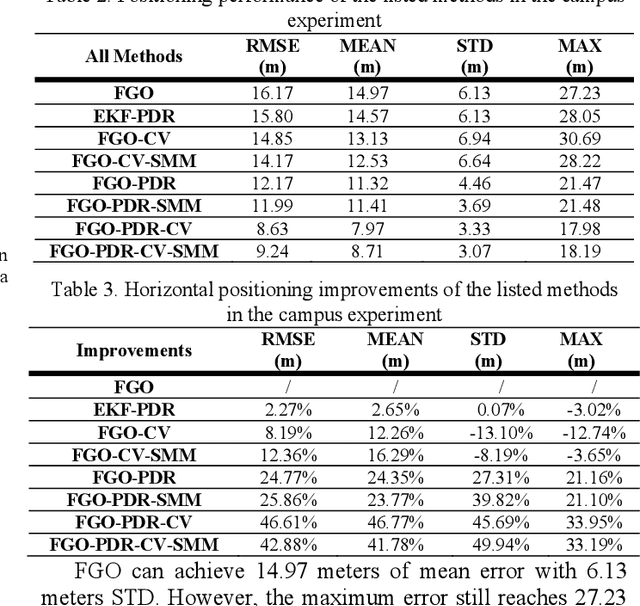
Accurate and smooth global navigation satellite system (GNSS) positioning for pedestrians in urban canyons is still a challenge due to the multipath effects and the non-light-of-sight (NLOS) receptions caused by the reflections from surrounding buildings. The recently developed factor graph optimization (FGO) based GNSS positioning method opened a new window for improving urban GNSS positioning by effectively exploiting the measurement redundancy from the historical information to resist the outlier measurements. Unfortunately, the FGO-based GNSS standalone positioning is still challenged in highly urbanized areas. As an extension of the previous FGO-based GNSS positioning method, this paper exploits the potential of the pedestrian dead reckoning (PDR) model in FGO to improve the GNSS standalone positioning performance in urban canyons. Specifically, the relative motion of the pedestrian is estimated based on the raw acceleration measurements from the onboard smartphone inertial measurement unit (IMU) via the PDR algorithm. Then the raw GNSS pseudorange, Doppler measurements, and relative motion from PDR are integrated using the FGO. Given the context of pedestrian navigation with a small acceleration most of the time, a novel soft motion model is proposed to smooth the states involved in the factor graph model. The effectiveness of the proposed method is verified step-by-step through two datasets collected in dense urban canyons of Hong Kong using smartphone-level GNSS receivers. The comparison between the conventional extended Kalman filter, several existing methods, and FGO-based integration is presented. The results reveal that the existing FGO-based GNSS standalone positioning is highly complementary to the PDR's relative motion estimation. Both improved positioning accuracy and trajectory smoothness are obtained with the help of the proposed method.
Mining Mathematical Documents for Question Answering via Unsupervised Formula Labeling
Nov 12, 2022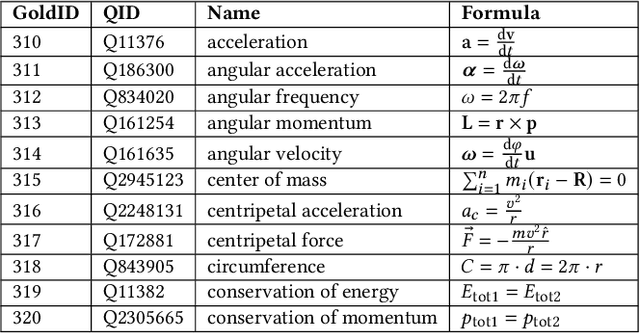
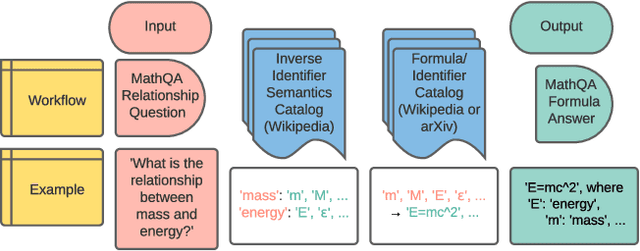
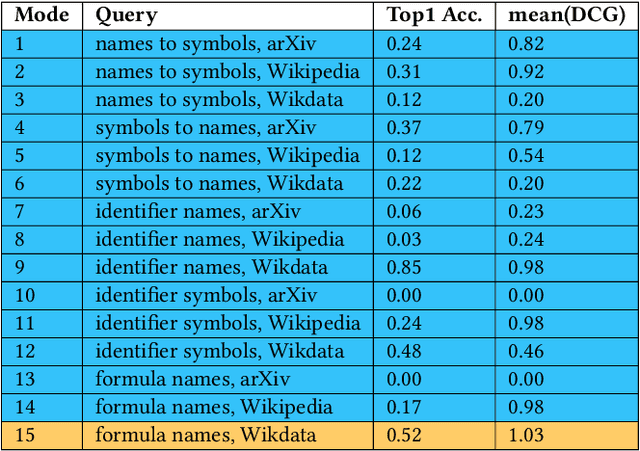
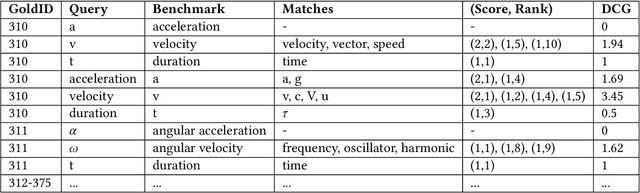
The increasing number of questions on Question Answering (QA) platforms like Math Stack Exchange (MSE) signifies a growing information need to answer math-related questions. However, there is currently very little research on approaches for an open data QA system that retrieves mathematical formulae using their concept names or querying formula identifier relationships from knowledge graphs. In this paper, we aim to bridge the gap by presenting data mining methods and benchmark results to employ Mathematical Entity Linking (MathEL) and Unsupervised Formula Labeling (UFL) for semantic formula search and mathematical question answering (MathQA) on the arXiv preprint repository, Wikipedia, and Wikidata, which is part of the Wikimedia ecosystem of free knowledge. Based on different types of information needs, we evaluate our system in 15 information need modes, assessing over 7,000 query results. Furthermore, we compare its performance to a commercial knowledge-base and calculation-engine (Wolfram Alpha) and search-engine (Google). The open source system is hosted by Wikimedia at https://mathqa.wmflabs.org. A demovideo is available at purl.org/mathqa.
Automated Gadget Discovery in Science
Dec 24, 2022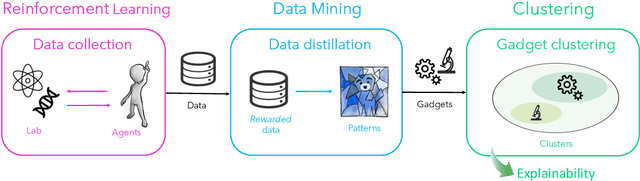

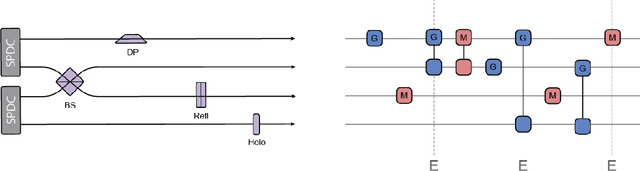

In recent years, reinforcement learning (RL) has become increasingly successful in its application to science and the process of scientific discovery in general. However, while RL algorithms learn to solve increasingly complex problems, interpreting the solutions they provide becomes ever more challenging. In this work, we gain insights into an RL agent's learned behavior through a post-hoc analysis based on sequence mining and clustering. Specifically, frequent and compact subroutines, used by the agent to solve a given task, are distilled as gadgets and then grouped by various metrics. This process of gadget discovery develops in three stages: First, we use an RL agent to generate data, then, we employ a mining algorithm to extract gadgets and finally, the obtained gadgets are grouped by a density-based clustering algorithm. We demonstrate our method by applying it to two quantum-inspired RL environments. First, we consider simulated quantum optics experiments for the design of high-dimensional multipartite entangled states where the algorithm finds gadgets that correspond to modern interferometer setups. Second, we consider a circuit-based quantum computing environment where the algorithm discovers various gadgets for quantum information processing, such as quantum teleportation. This approach for analyzing the policy of a learned agent is agent and environment agnostic and can yield interesting insights into any agent's policy.
Compressive Spectrum Sensing Using Blind-Block Orthogonal Least Squares
Nov 14, 2022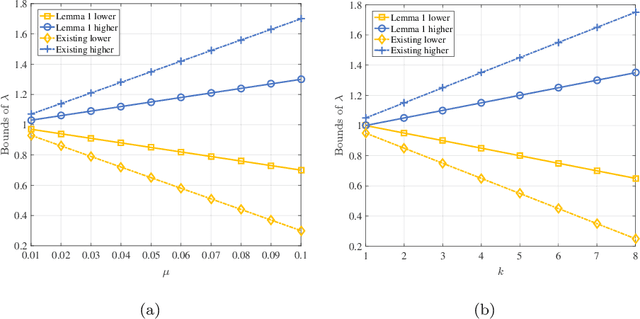
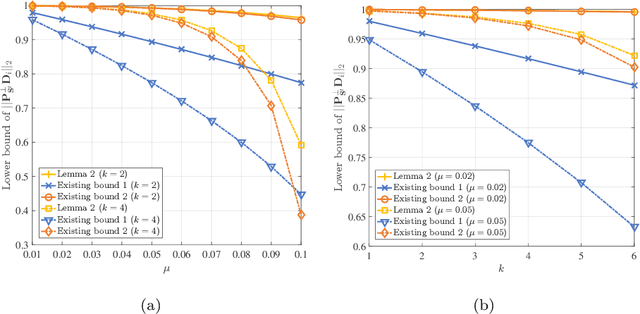
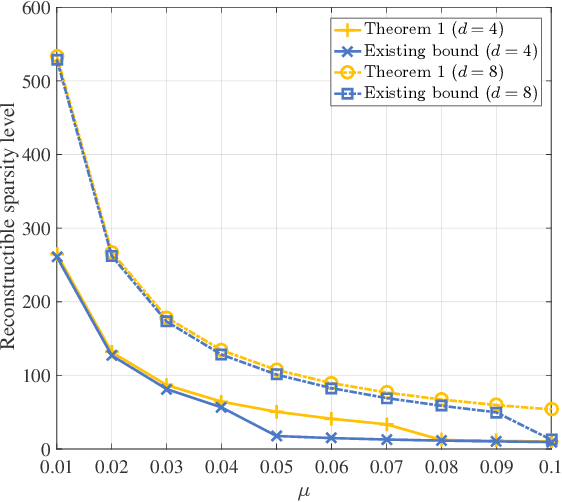
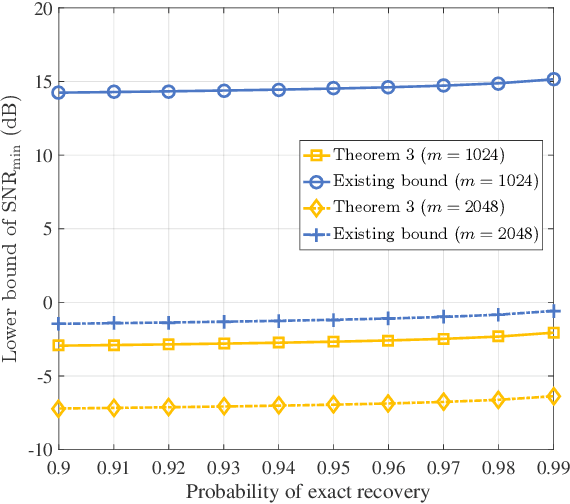
Compressive sensing (CS) has recently emerged as an extremely efficient technology of the wideband spectrum sensing. In compressive spectrum sensing (CSS), it is necessary to know the sparsity or the noise information in advance for reliable reconstruction. However, such information is usually absent in practical applications. In this paper, we propose a blind-block orthogonal least squares-based compressive spectrum sensing (B-BOLS-CSS) algorithm, which utilizes a novel blind stopping rule to cut the cords to these prior information. Specifically, we first present both the noiseless and noisy recovery guarantees for the BOLS algorithm based on the mutual incoherence property (MIP). Motivated by them, we then formulate the blind stopping rule, which exploits an $\ell_{2,\infty}$ sufficient statistic to blindly test the support atoms in the remaining measurement matrix. We further evaluate the theoretical performance analysis of the holistic B-BOLS-CSS algorithm by developing a lower bound of the signal-to-noise ratio (SNR) to ensure that the probability of exact recovery is no lower than a given threshold. Simulations not only demonstrate the improvement of our derived theoretical results, but also illustrate that B-BOLS-CSS works well in both low and high SNR environments.
The Best Path Algorithm automatic variables selection via High Dimensional Graphical Models
Nov 14, 2022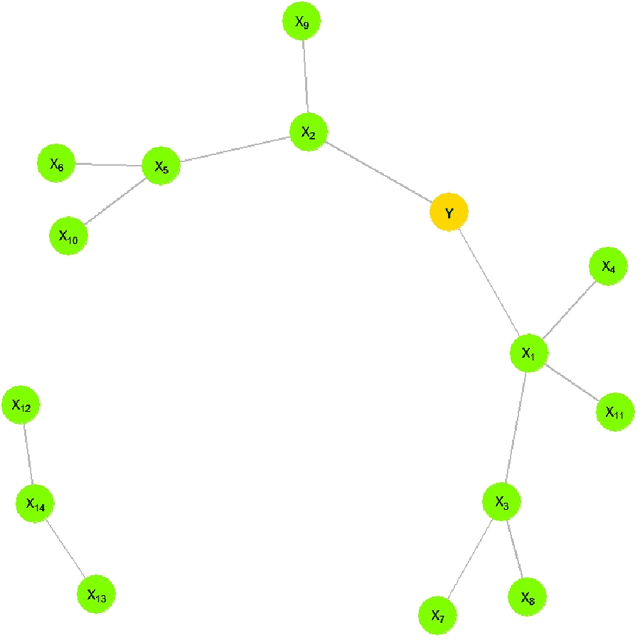
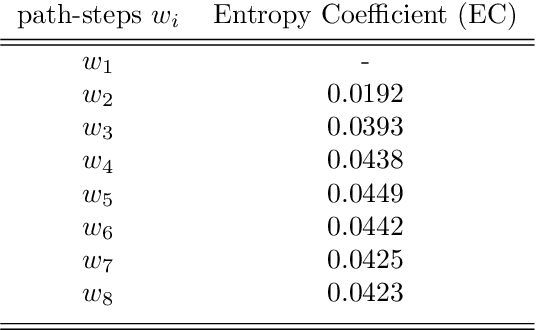
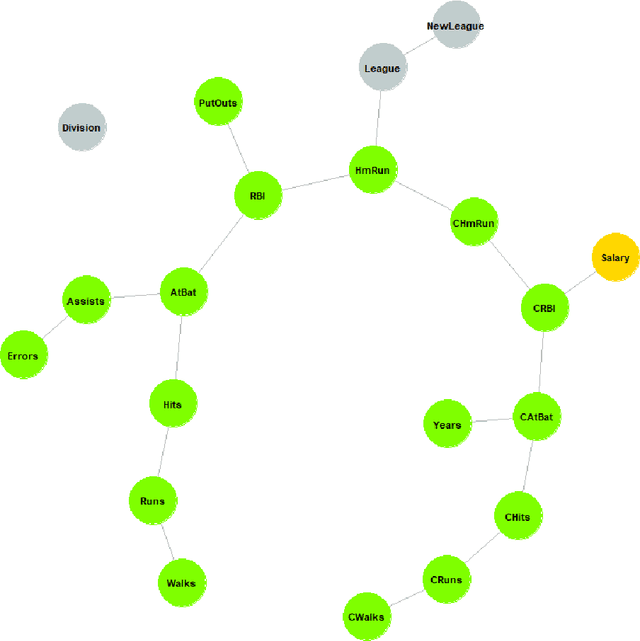

This paper proposes a new algorithm for an automatic variable selection procedure in High Dimensional Graphical Models. The algorithm selects the relevant variables for the node of interest on the basis of mutual information. Several contributions in literature have investigated the use of mutual information in selecting the appropriate number of relevant features in a large data-set, but most of them have focused on binary outcomes or required high computational effort. The algorithm here proposed overcomes these drawbacks as it is an extension of Chow and Liu's algorithm. Once, the probabilistic structure of a High Dimensional Graphical Model is determined via the said algorithm, the best path-step, including variables with the most explanatory/predictive power for a variable of interest, is determined via the computation of the entropy coefficient of determination. The latter, being based on the notion of (symmetric) Kullback-Leibler divergence, turns out to be closely connected to the mutual information of the involved variables. The application of the algorithm to a wide range of real-word and publicly data-sets has highlighted its potential and greater effectiveness compared to alternative extant methods.
Domain Generalization with Correlated Style Uncertainty
Dec 20, 2022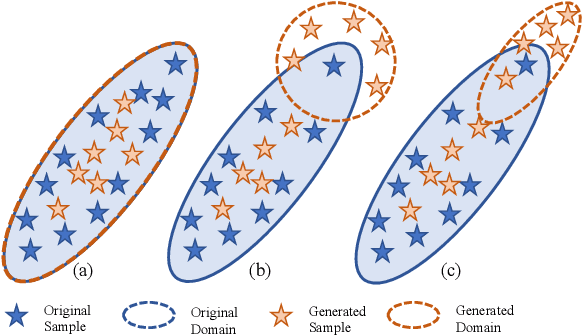
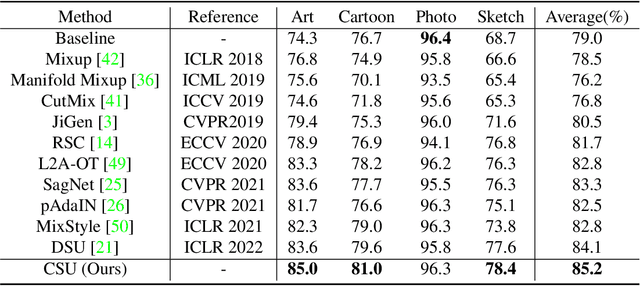
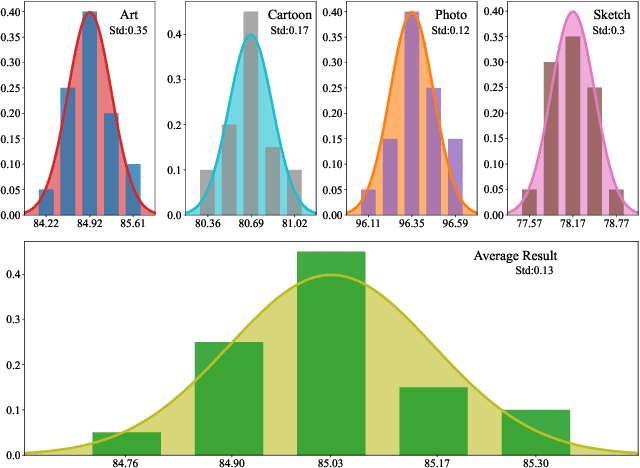
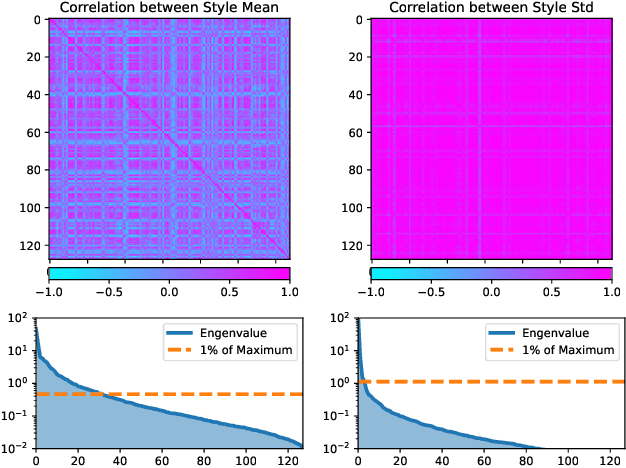
Though impressive success has been witnessed in computer vision, deep learning still suffers from the domain shift challenge when the target domain for testing and the source domain for training do not share an identical distribution. To address this, domain generalization approaches intend to extract domain invariant features that can lead to a more robust model. Hence, increasing the source domain diversity is a key component of domain generalization. Style augmentation takes advantage of instance-specific feature statistics containing informative style characteristics to synthetic novel domains. However, all previous works ignored the correlation between different feature channels or only limited the style augmentation through linear interpolation. In this work, we propose a novel augmentation method, called \textit{Correlated Style Uncertainty (CSU)}, to go beyond the linear interpolation of style statistic space while preserving the essential correlation information. We validate our method's effectiveness by extensive experiments on multiple cross-domain classification tasks, including widely used PACS, Office-Home, Camelyon17 datasets and the Duke-Market1501 instance retrieval task and obtained significant margin improvements over the state-of-the-art methods. The source code is available for public use.
FunkNN: Neural Interpolation for Functional Generation
Dec 20, 2022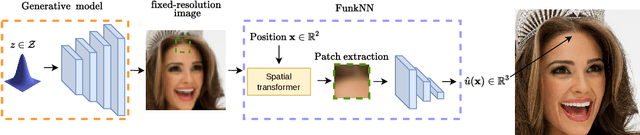
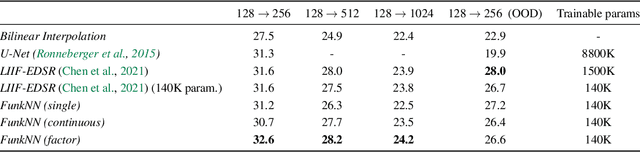
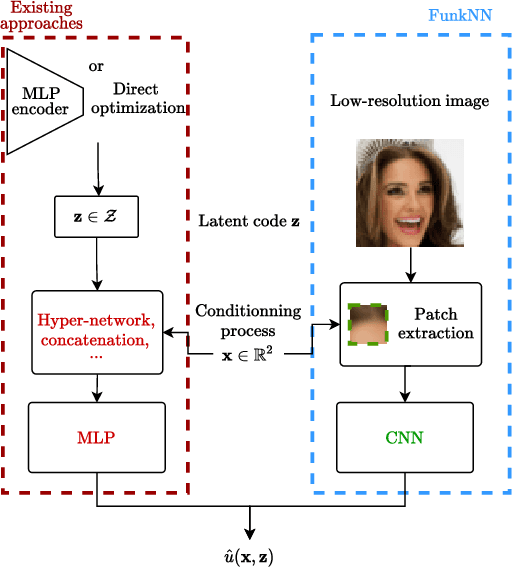
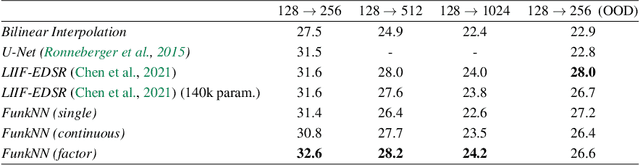
Can we build continuous generative models which generalize across scales, can be evaluated at any coordinate, admit calculation of exact derivatives, and are conceptually simple? Existing MLP-based architectures generate worse samples than the grid-based generators with favorable convolutional inductive biases. Models that focus on generating images at different scales do better, but employ complex architectures not designed for continuous evaluation of images and derivatives. We take a signal-processing perspective and treat continuous image generation as interpolation from samples. Indeed, correctly sampled discrete images contain all information about the low spatial frequencies. The question is then how to extrapolate the spectrum in a data-driven way while meeting the above design criteria. Our answer is FunkNN -- a new convolutional network which learns how to reconstruct continuous images at arbitrary coordinates and can be applied to any image dataset. Combined with a discrete generative model it becomes a functional generator which can act as a prior in continuous ill-posed inverse problems. We show that FunkNN generates high-quality continuous images and exhibits strong out-of-distribution performance thanks to its patch-based design. We further showcase its performance in several stylized inverse problems with exact spatial derivatives.
Generic Temporal Reasoning with Differential Analysis and Explanation
Dec 20, 2022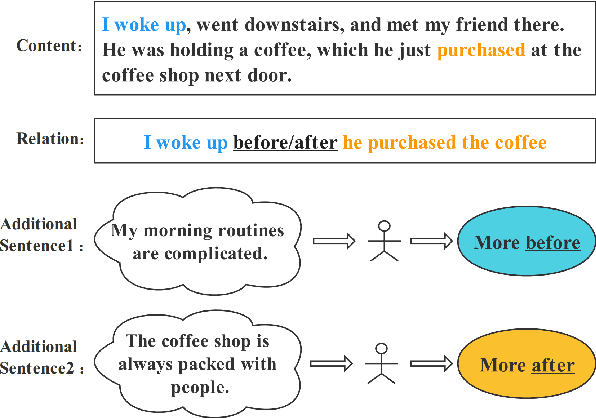

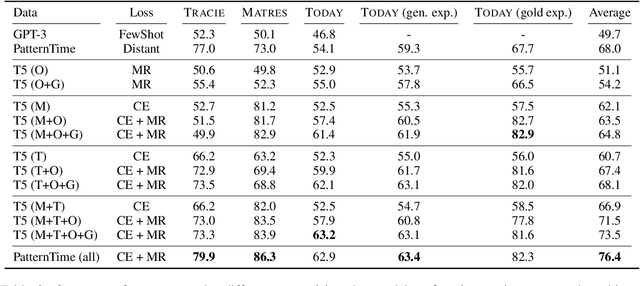

Temporal reasoning is the task of predicting temporal relations of event pairs with corresponding contexts. While some temporal reasoning models perform reasonably well on in-domain benchmarks, we have little idea of the systems' generalizability due to existing datasets' limitations. In this work, we introduce a novel task named TODAY that bridges this gap with temporal differential analysis, which as the name suggests, evaluates if systems can correctly understand the effect of incremental changes. Specifically, TODAY makes slight context changes for given event pairs, and systems need to tell how this subtle contextual change will affect temporal relation distributions. To facilitate learning, TODAY also annotates human explanations. We show that existing models, including GPT-3, drop to random guessing on TODAY, suggesting that they heavily rely on spurious information rather than proper reasoning for temporal predictions. On the other hand, we show that TODAY's supervision style and explanation annotations can be used in joint learning and encourage models to use more appropriate signals during training and outperform across several benchmarks. TODAY can also be used to train models to solicit incidental supervision from noisy sources such as GPT-3 and moves farther towards generic temporal reasoning systems.
Detecting and Mitigating Hallucinations in Machine Translation: Model Internal Workings Alone Do Well, Sentence Similarity Even Better
Dec 20, 2022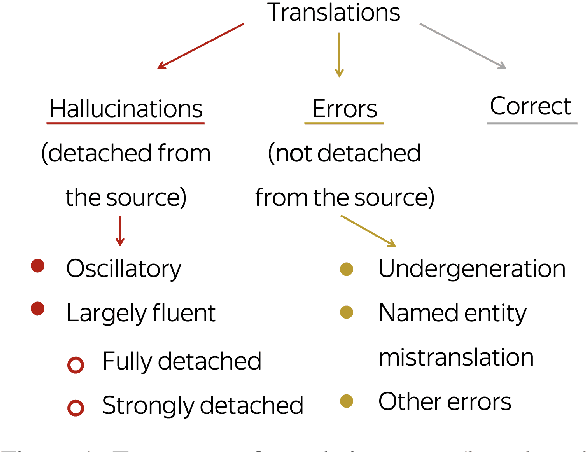
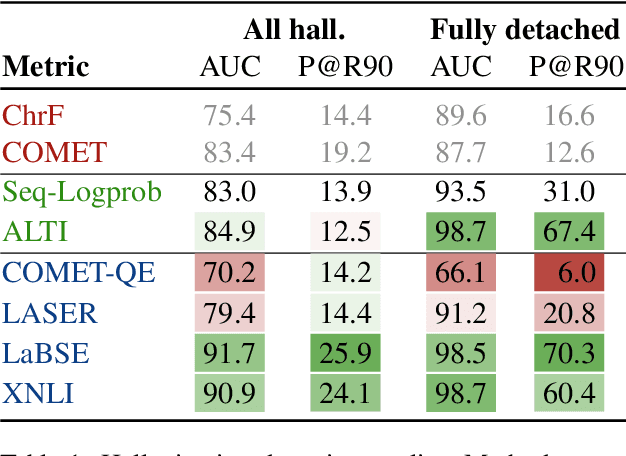
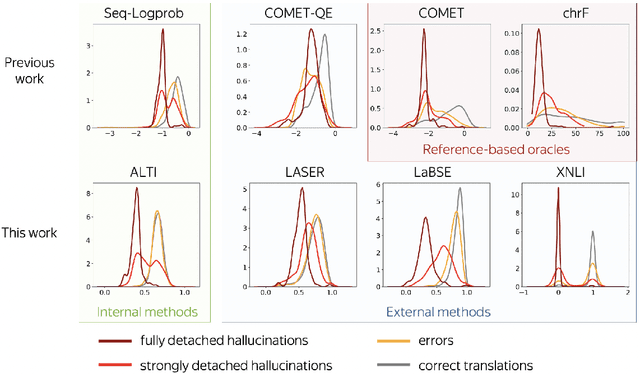
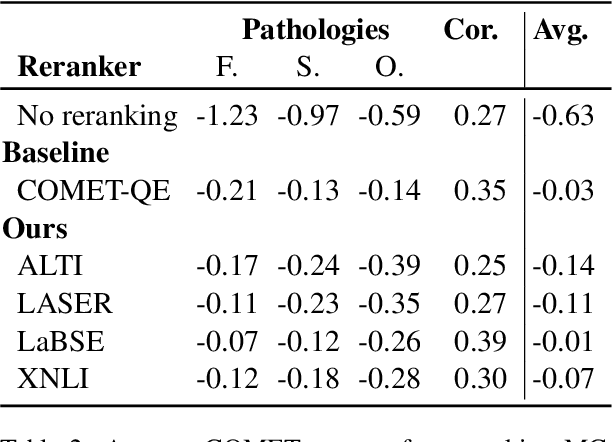
While the problem of hallucinations in neural machine translation has long been recognized, so far the progress on its alleviation is very little. Indeed, recently it turned out that without artificially encouraging models to hallucinate, previously existing methods fall short and even the standard sequence log-probability is more informative. It means that characteristics internal to the model can give much more information than we expect, and before using external models and measures, we first need to ask: how far can we go if we use nothing but the translation model itself ? We propose to use a method that evaluates the percentage of the source contribution to a generated translation. Intuitively, hallucinations are translations "detached" from the source, hence they can be identified by low source contribution. This method improves detection accuracy for the most severe hallucinations by a factor of 2 and is able to alleviate hallucinations at test time on par with the previous best approach that relies on external models. Next, if we move away from internal model characteristics and allow external tools, we show that using sentence similarity from cross-lingual embeddings further improves these results.
On Improving Summarization Factual Consistency from Natural Language Feedback
Dec 20, 2022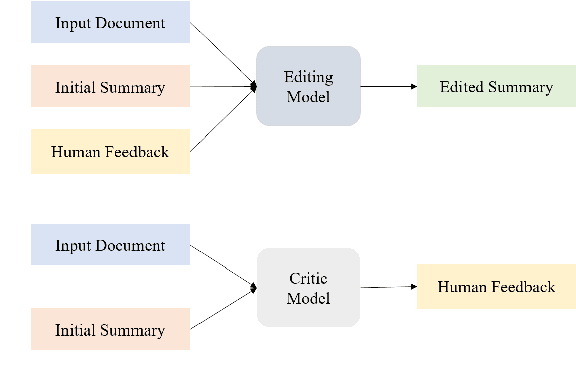

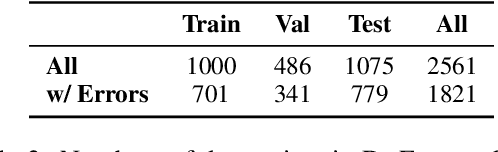
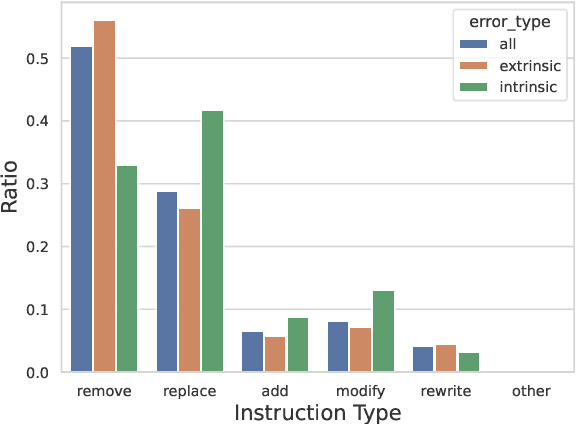
Despite the recent progress in language generation models, their outputs may not always meet user expectations. In this work, we study whether informational feedback in natural language can be leveraged to improve generation quality and user preference alignment. To this end, we consider factual consistency in summarization, the quality that the summary should only contain information supported by the input documents, for user preference alignment. We collect a high-quality dataset, DeFacto, containing human demonstrations and informational feedback in natural language consisting of corrective instructions, edited summaries, and explanations with respect to the factual consistency of the summary. Using our dataset, we study two natural language generation tasks: 1) editing a summary using the human feedback, and 2) generating human feedback from the original summary. Using the two tasks, we further evaluate if models can automatically correct factual inconsistencies in generated summaries. We show that the human-edited summaries we collected are more factually consistent, and pre-trained language models can leverage our dataset to improve the factual consistency of original system-generated summaries in our proposed generation tasks. We make the DeFacto dataset publicly available at https://github.com/microsoft/DeFacto.