 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Task Preferences across Languages on Community Question Answering Platforms
Dec 18, 2022
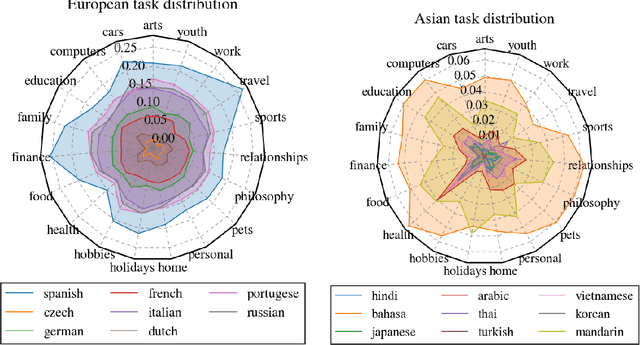
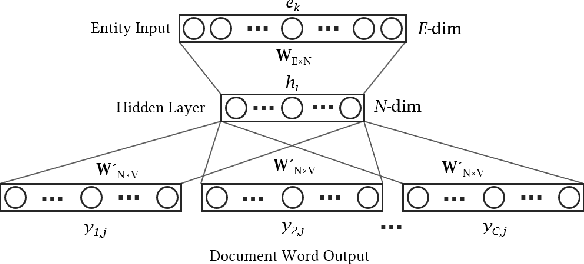
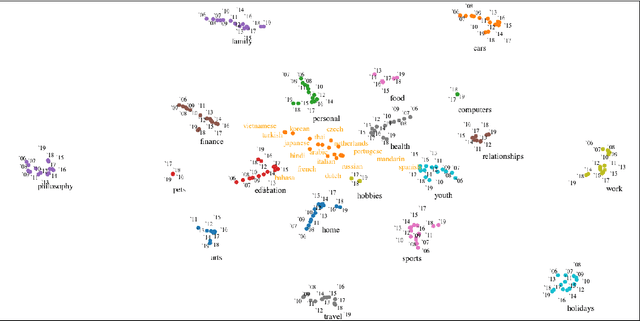
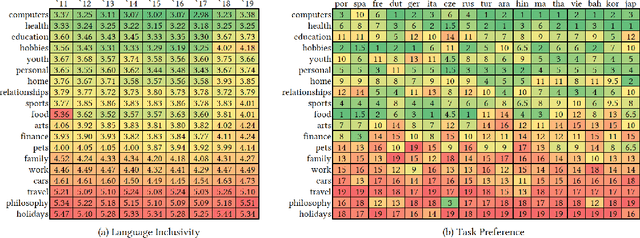
With the steady emergence of community question answering (CQA) platforms like Quora, StackExchange, and WikiHow, users now have an unprecedented access to information on various kind of queries and tasks. Moreover, the rapid proliferation and localization of these platforms spanning geographic and linguistic boundaries offer a unique opportunity to study the task requirements and preferences of users in different socio-linguistic groups. In this study, we implement an entity-embedding model trained on a large longitudinal dataset of multi-lingual and task-oriented question-answer pairs to uncover and quantify the (i) prevalence and distribution of various online tasks across linguistic communities, and (ii) emerging and receding trends in task popularity over time in these communities. Our results show that there exists substantial variance in task preference as well as popularity trends across linguistic communities on the platform. Findings from this study will help Q&A platforms better curate and personalize content for non-English users, while also offering valuable insights to businesses looking to target non-English speaking communities online.
Learning Dual-Fused Modality-Aware Representations for RGBD Tracking
Nov 06, 2022
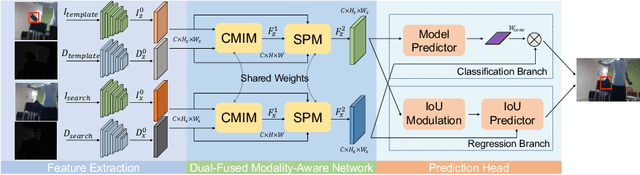
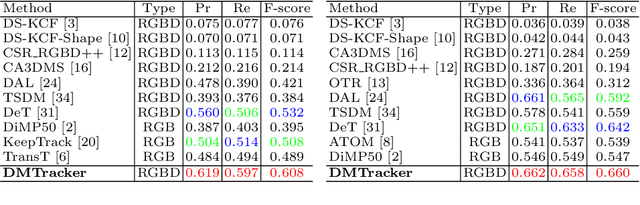

With the development of depth sensors in recent years, RGBD object tracking has received significant attention. Compared with the traditional RGB object tracking, the addition of the depth modality can effectively solve the target and background interference. However, some existing RGBD trackers use the two modalities separately and thus some particularly useful shared information between them is ignored. On the other hand, some methods attempt to fuse the two modalities by treating them equally, resulting in the missing of modality-specific features. To tackle these limitations, we propose a novel Dual-fused Modality-aware Tracker (termed DMTracker) which aims to learn informative and discriminative representations of the target objects for robust RGBD tracking. The first fusion module focuses on extracting the shared information between modalities based on cross-modal attention. The second aims at integrating the RGB-specific and depth-specific information to enhance the fused features. By fusing both the modality-shared and modality-specific information in a modality-aware scheme, our DMTracker can learn discriminative representations in complex tracking scenes. Experiments show that our proposed tracker achieves very promising results on challenging RGBD benchmarks. Code is available at \url{https://github.com/ShangGaoG/DMTracker}.
Understanding ME? Multimodal Evaluation for Fine-grained Visual Commonsense
Nov 10, 2022
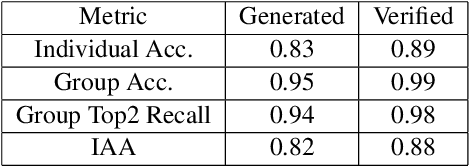
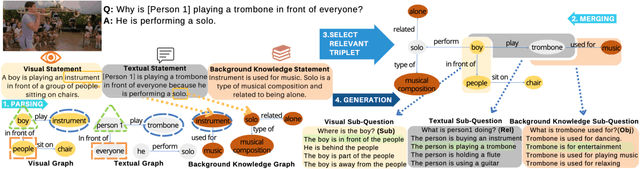
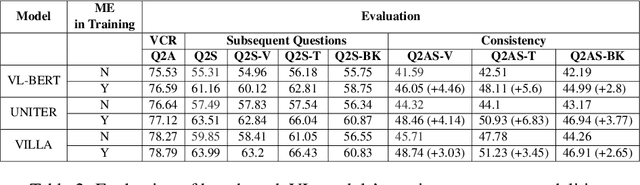
Visual commonsense understanding requires Vision Language (VL) models to not only understand image and text but also cross-reference in-between to fully integrate and achieve comprehension of the visual scene described. Recently, various approaches have been developed and have achieved high performance on visual commonsense benchmarks. However, it is unclear whether the models really understand the visual scene and underlying commonsense knowledge due to limited evaluation data resources. To provide an in-depth analysis, we present a Multimodal Evaluation (ME) pipeline to automatically generate question-answer pairs to test models' understanding of the visual scene, text, and related knowledge. We then take a step further to show that training with the ME data boosts the model's performance in standard VCR evaluation. Lastly, our in-depth analysis and comparison reveal interesting findings: (1) semantically low-level information can assist the learning of high-level information but not the opposite; (2) visual information is generally under utilization compared with text.
Analyzing Wrap-Up Effects through an Information-Theoretic Lens
Mar 31, 2022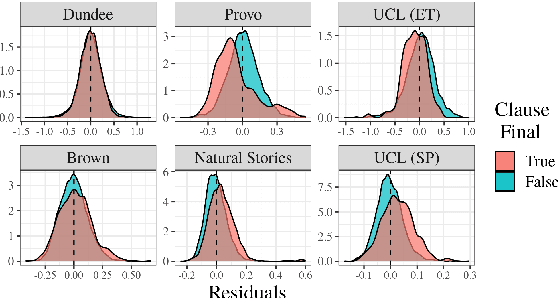
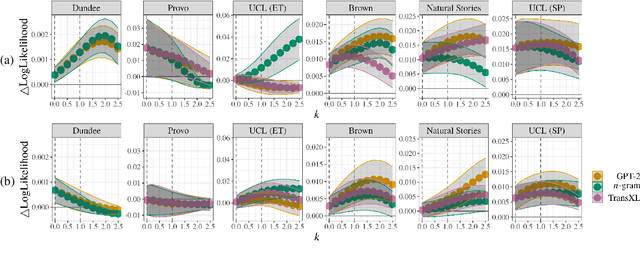
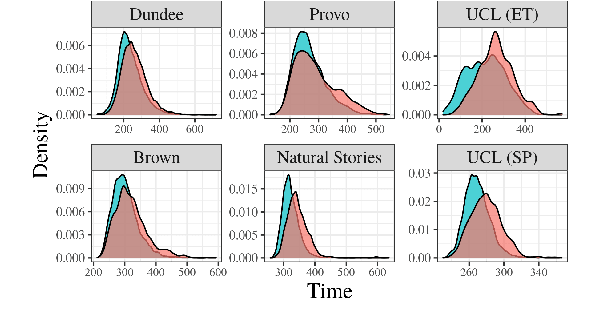
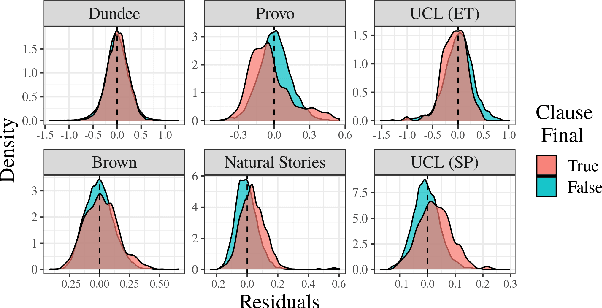
Numerous analyses of reading time (RT) data have been implemented -- all in an effort to better understand the cognitive processes driving reading comprehension. However, data measured on words at the end of a sentence -- or even at the end of a clause -- is often omitted due to the confounding factors introduced by so-called "wrap-up effects," which manifests as a skewed distribution of RTs for these words. Consequently, the understanding of the cognitive processes that might be involved in these wrap-up effects is limited. In this work, we attempt to learn more about these processes by examining the relationship between wrap-up effects and information-theoretic quantities, such as word and context surprisals. We find that the distribution of information in prior contexts is often predictive of sentence- and clause-final RTs (while not of sentence-medial RTs). This lends support to several prior hypotheses about the processes involved in wrap-up effects.
A Comparison of Audio Preprocessing Techniques and Deep Learning Algorithms for Raga Recognition
Dec 10, 2022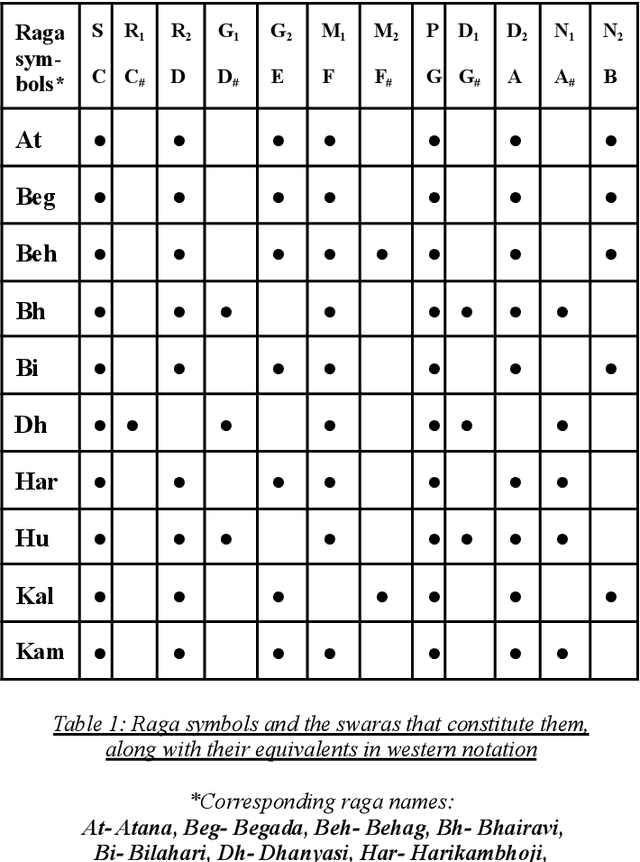
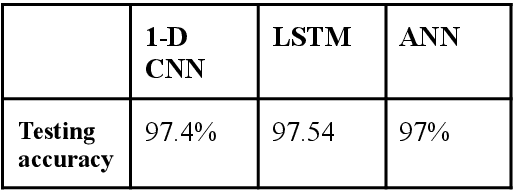
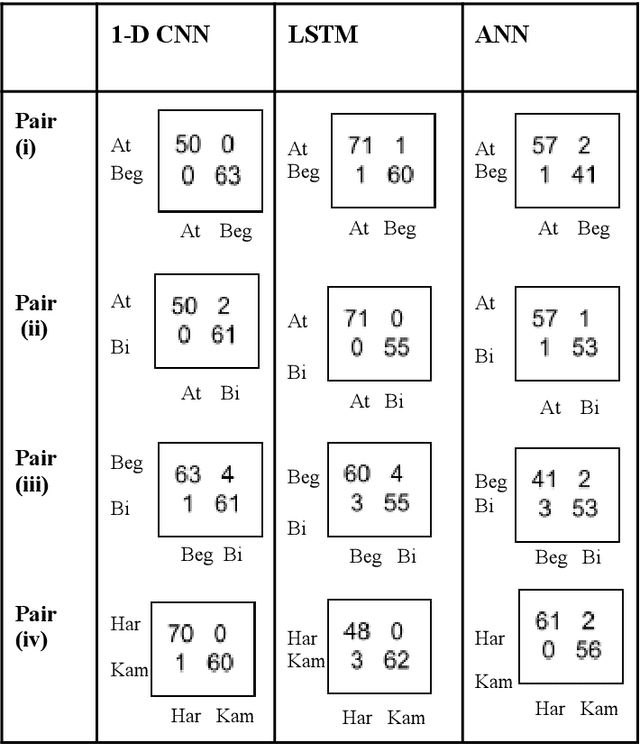
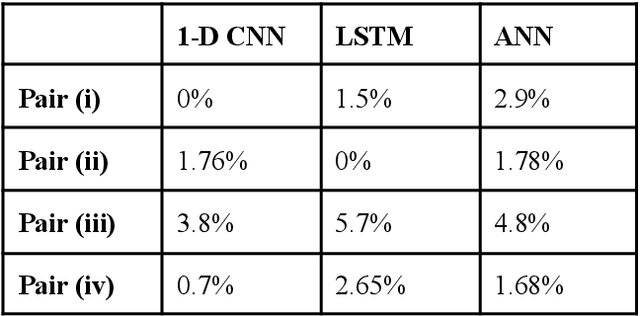
Ragas form the foundation for Indian Classical Music. The task of Raga Recognition has gained traction in the Music Information Retrieval community in the recent past, which can be attributed to the nuances of Indian Classical Music that have resulted in a plethora of research problems in Computing. In this work, we used two different digital audio signal processing techniques to preprocess audio samples of Carnatic classical ragas that were then processed by various Deep Learning models. Their results were compared in order to infer which DASP technique is better suited to the task of raga recognition. We obtained state of the art results, with our best model reaching a testing accuracy of 98.1%. We also compared each model ability to distinguish between similar ragas.
Syntax-Aware On-the-Fly Code Completion
Nov 09, 2022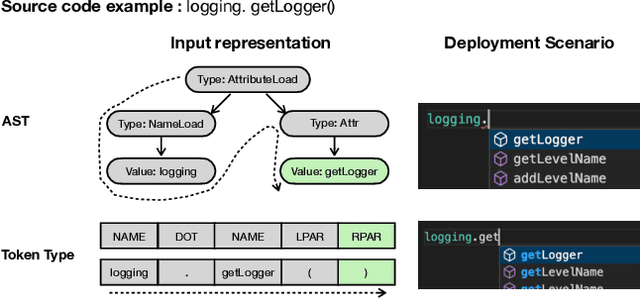
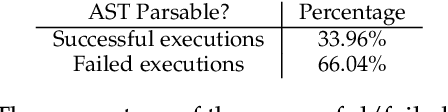
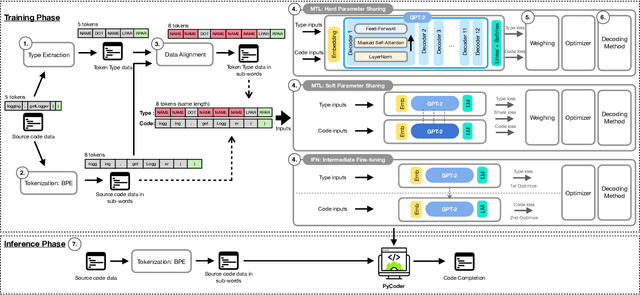

Code completion aims to help improve developers' productivity by suggesting the next code tokens from a given context. Various approaches have been proposed to incorporate abstract syntax tree (AST) information for model training, ensuring that code completion is aware of the syntax of the programming languages. However, existing syntax-aware code completion approaches are not on-the-fly, as we found that for every two-thirds of characters that developers type, AST fails to be extracted because it requires the syntactically correct source code, limiting its practicality in real-world scenarios. On the other hand, existing on-the-fly code completion does not consider syntactic information yet. In this paper, we propose PyCoder to leverage token types, a kind of lightweight syntactic information, which is readily available and aligns with the natural order of source code. Our PyCoder is trained in a multi-task training manner so that by learning the supporting task of predicting token types during the training phase, the models achieve better performance on predicting tokens and lines of code without the need for token types in the inference phase. Comprehensive experiments show that PyCoder achieves the first rank on the CodeXGLUE leaderboard with an accuracy of 77.12% for the token-level predictions, which is 0.43%-24.25% more accurate than baselines. In addition, PyCoder achieves an exact match of 43.37% for the line-level predictions, which is 3.63%-84.73% more accurate than baselines. These results lead us to conclude that token type information (an alternative to syntactic information) that is rarely used in the past can greatly improve the performance of code completion approaches, without requiring the syntactically correct source code like AST-based approaches do. Our PyCoder is publicly available on HuggingFace.
Decouple-and-Sample: Protecting sensitive information in task agnostic data release
Mar 17, 2022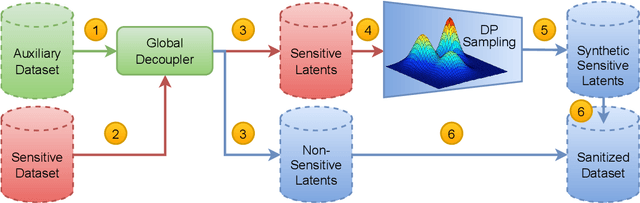
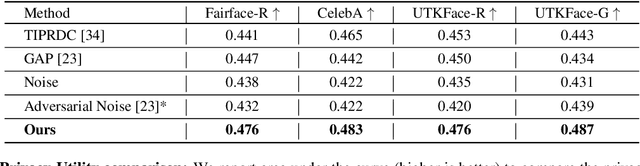
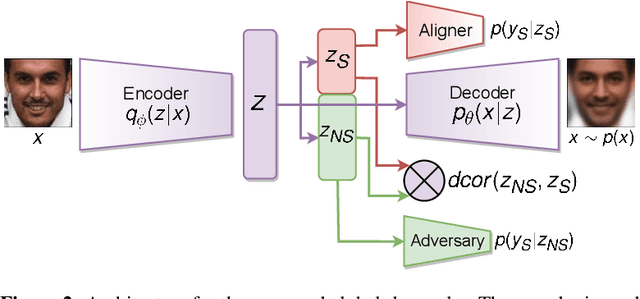
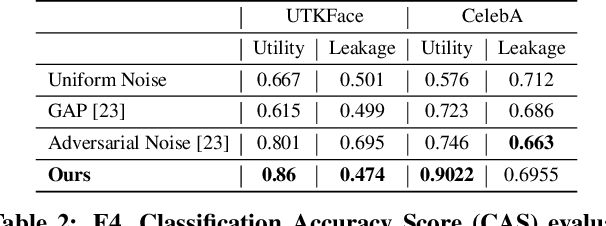
We propose sanitizer, a framework for secure and task-agnostic data release. While releasing datasets continues to make a big impact in various applications of computer vision, its impact is mostly realized when data sharing is not inhibited by privacy concerns. We alleviate these concerns by sanitizing datasets in a two-stage process. First, we introduce a global decoupling stage for decomposing raw data into sensitive and non-sensitive latent representations. Secondly, we design a local sampling stage to synthetically generate sensitive information with differential privacy and merge it with non-sensitive latent features to create a useful representation while preserving the privacy. This newly formed latent information is a task-agnostic representation of the original dataset with anonymized sensitive information. While most algorithms sanitize data in a task-dependent manner, a few task-agnostic sanitization techniques sanitize data by censoring sensitive information. In this work, we show that a better privacy-utility trade-off is achieved if sensitive information can be synthesized privately. We validate the effectiveness of the sanitizer by outperforming state-of-the-art baselines on the existing benchmark tasks and demonstrating tasks that are not possible using existing techniques.
Trajectory Smoothing Using GNSS/PDR Integration Via Factor Graph Optimization in Urban Canyons
Dec 29, 2022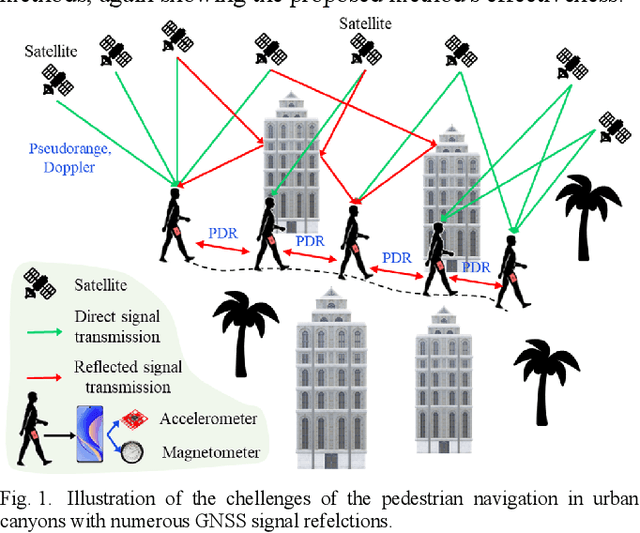

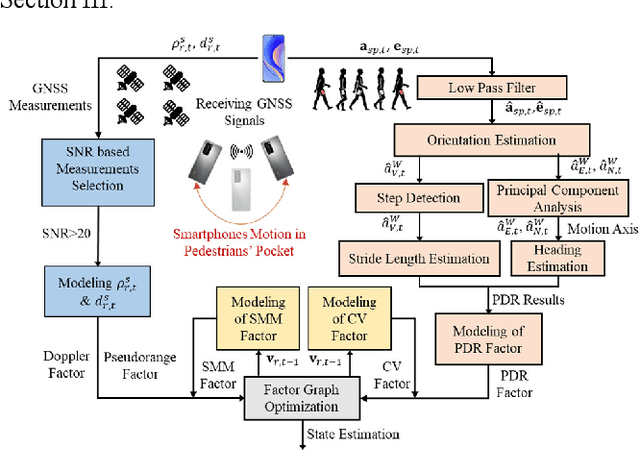
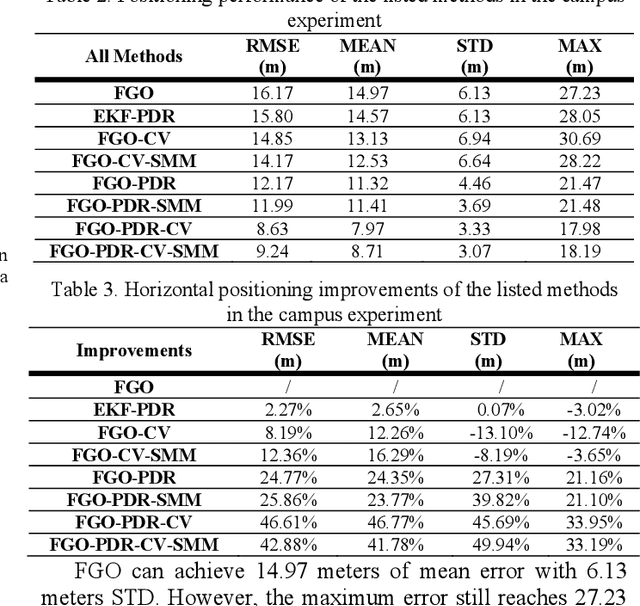
Accurate and smooth global navigation satellite system (GNSS) positioning for pedestrians in urban canyons is still a challenge due to the multipath effects and the non-light-of-sight (NLOS) receptions caused by the reflections from surrounding buildings. The recently developed factor graph optimization (FGO) based GNSS positioning method opened a new window for improving urban GNSS positioning by effectively exploiting the measurement redundancy from the historical information to resist the outlier measurements. Unfortunately, the FGO-based GNSS standalone positioning is still challenged in highly urbanized areas. As an extension of the previous FGO-based GNSS positioning method, this paper exploits the potential of the pedestrian dead reckoning (PDR) model in FGO to improve the GNSS standalone positioning performance in urban canyons. Specifically, the relative motion of the pedestrian is estimated based on the raw acceleration measurements from the onboard smartphone inertial measurement unit (IMU) via the PDR algorithm. Then the raw GNSS pseudorange, Doppler measurements, and relative motion from PDR are integrated using the FGO. Given the context of pedestrian navigation with a small acceleration most of the time, a novel soft motion model is proposed to smooth the states involved in the factor graph model. The effectiveness of the proposed method is verified step-by-step through two datasets collected in dense urban canyons of Hong Kong using smartphone-level GNSS receivers. The comparison between the conventional extended Kalman filter, several existing methods, and FGO-based integration is presented. The results reveal that the existing FGO-based GNSS standalone positioning is highly complementary to the PDR's relative motion estimation. Both improved positioning accuracy and trajectory smoothness are obtained with the help of the proposed method.
BEV-Locator: An End-to-end Visual Semantic Localization Network Using Multi-View Images
Nov 27, 2022
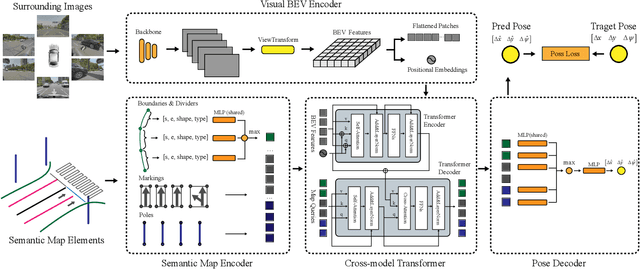
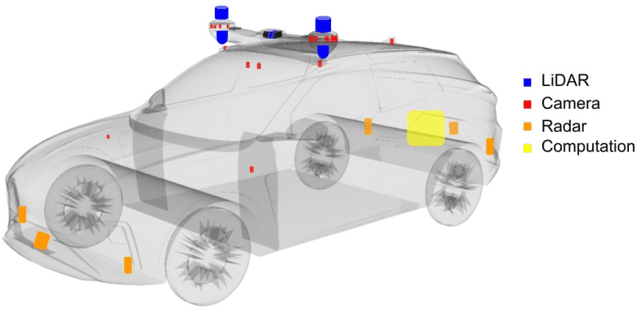
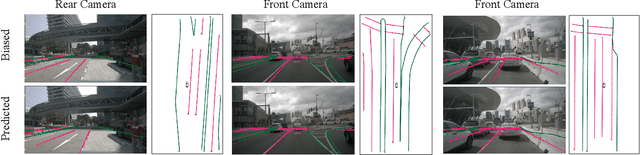
Accurate localization ability is fundamental in autonomous driving. Traditional visual localization frameworks approach the semantic map-matching problem with geometric models, which rely on complex parameter tuning and thus hinder large-scale deployment. In this paper, we propose BEV-Locator: an end-to-end visual semantic localization neural network using multi-view camera images. Specifically, a visual BEV (Birds-Eye-View) encoder extracts and flattens the multi-view images into BEV space. While the semantic map features are structurally embedded as map queries sequence. Then a cross-model transformer associates the BEV features and semantic map queries. The localization information of ego-car is recursively queried out by cross-attention modules. Finally, the ego pose can be inferred by decoding the transformer outputs. We evaluate the proposed method in large-scale nuScenes and Qcraft datasets. The experimental results show that the BEV-locator is capable to estimate the vehicle poses under versatile scenarios, which effectively associates the cross-model information from multi-view images and global semantic maps. The experiments report satisfactory accuracy with mean absolute errors of 0.052m, 0.135m and 0.251$^\circ$ in lateral, longitudinal translation and heading angle degree.
Constrained Pure Exploration Multi-Armed Bandits with a Fixed Budget
Nov 27, 2022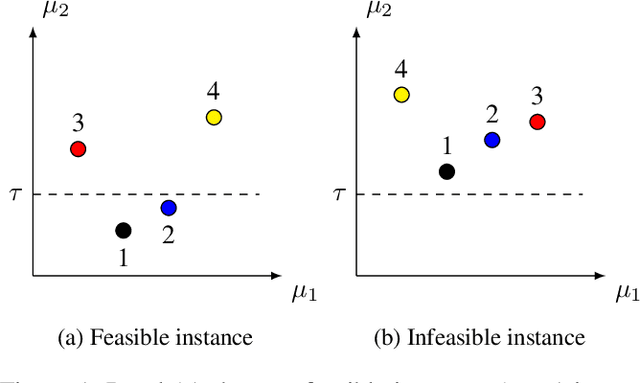
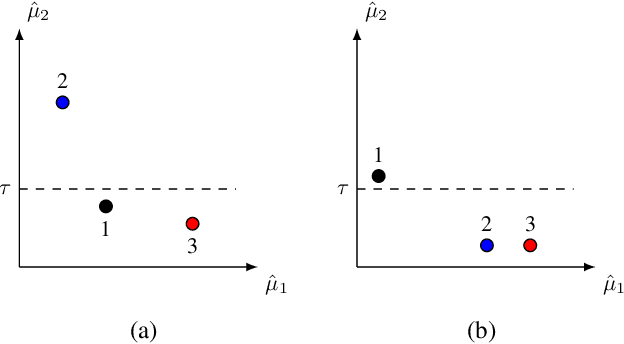
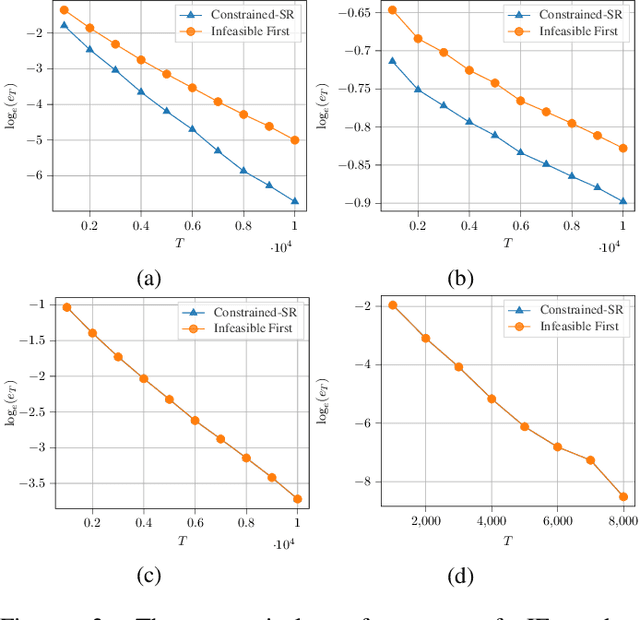
We consider a constrained, pure exploration, stochastic multi-armed bandit formulation under a fixed budget. Each arm is associated with an unknown, possibly multi-dimensional distribution and is described by multiple attributes that are a function of this distribution. The aim is to optimize a particular attribute subject to user-defined constraints on the other attributes. This framework models applications such as financial portfolio optimization, where it is natural to perform risk-constrained maximization of mean return. We assume that the attributes can be estimated using samples from the arms' distributions and that these estimators satisfy suitable concentration inequalities. We propose an algorithm called \textsc{Constrained-SR} based on the Successive Rejects framework, which recommends an optimal arm and flags the instance as being feasible or infeasible. A key feature of this algorithm is that it is designed on the basis of an information theoretic lower bound for two-armed instances. We characterize an instance-dependent upper bound on the probability of error under \textsc{Constrained-SR}, that decays exponentially with respect to the budget. We further show that the associated decay rate is nearly optimal relative to an information theoretic lower bound in certain special cases.