 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
TextMonkey: An OCR-Free Large Multimodal Model for Understanding Document
Mar 07, 2024
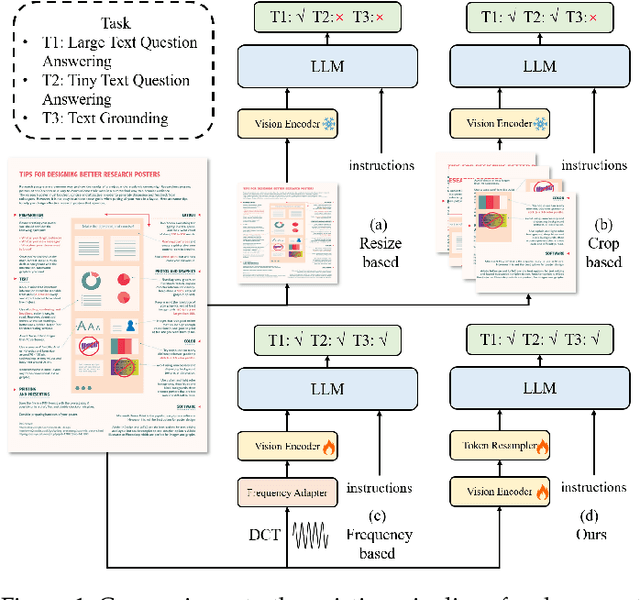
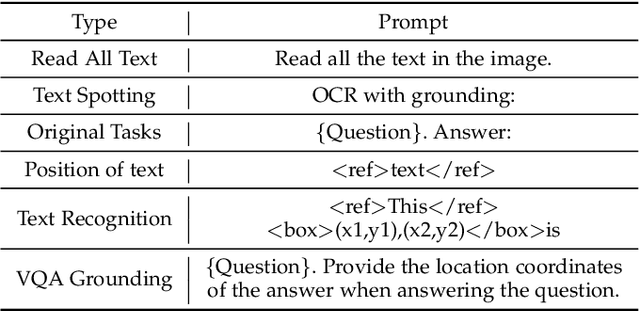
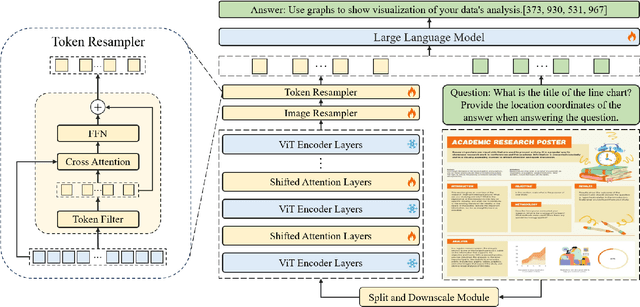
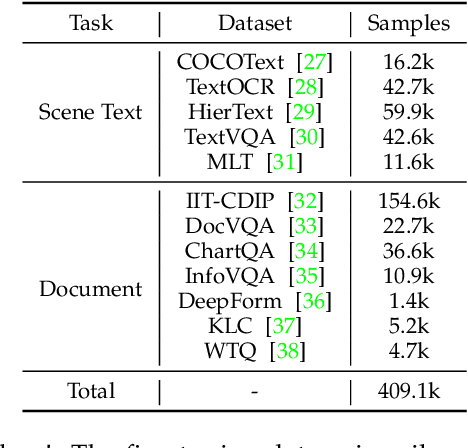
We present TextMonkey, a large multimodal model (LMM) tailored for text-centric tasks, including document question answering (DocVQA) and scene text analysis. Our approach introduces enhancement across several dimensions: by adopting Shifted Window Attention with zero-initialization, we achieve cross-window connectivity at higher input resolutions and stabilize early training; We hypothesize that images may contain redundant tokens, and by using similarity to filter out significant tokens, we can not only streamline the token length but also enhance the model's performance. Moreover, by expanding our model's capabilities to encompass text spotting and grounding, and incorporating positional information into responses, we enhance interpretability and minimize hallucinations. Additionally, TextMonkey can be finetuned to gain the ability to comprehend commands for clicking screenshots. Overall, our method notably boosts performance across various benchmark datasets, achieving increases of 5.2%, 6.9%, and 2.8% in Scene Text-Centric VQA, Document Oriented VQA, and KIE, respectively, especially with a score of 561 on OCRBench, surpassing prior open-sourced large multimodal models for document understanding. Code will be released at https://github.com/Yuliang-Liu/Monkey.
That's My Point: Compact Object-centric LiDAR Pose Estimation for Large-scale Outdoor Localisation
Mar 07, 2024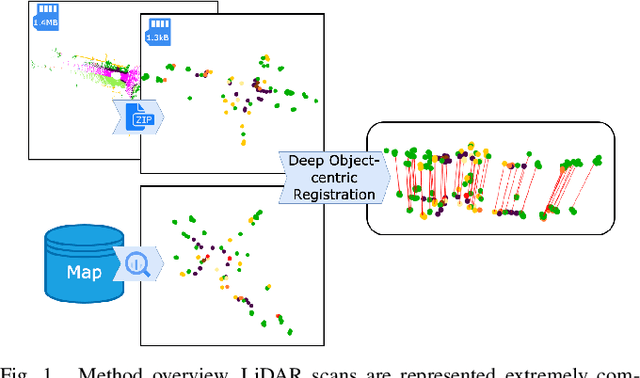
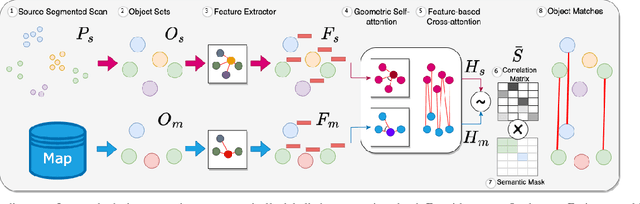
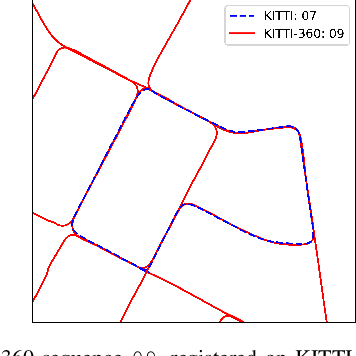
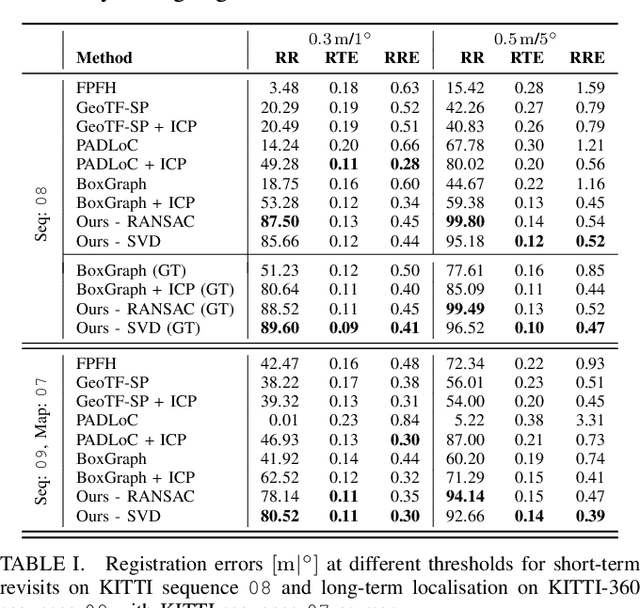
This paper is about 3D pose estimation on LiDAR scans with extremely minimal storage requirements to enable scalable mapping and localisation. We achieve this by clustering all points of segmented scans into semantic objects and representing them only with their respective centroid and semantic class. In this way, each LiDAR scan is reduced to a compact collection of four-number vectors. This abstracts away important structural information from the scenes, which is crucial for traditional registration approaches. To mitigate this, we introduce an object-matching network based on self- and cross-correlation that captures geometric and semantic relationships between entities. The respective matches allow us to recover the relative transformation between scans through weighted Singular Value Decomposition (SVD) and RANdom SAmple Consensus (RANSAC). We demonstrate that such representation is sufficient for metric localisation by registering point clouds taken under different viewpoints on the KITTI dataset, and at different periods of time localising between KITTI and KITTI-360. We achieve accurate metric estimates comparable with state-of-the-art methods with almost half the representation size, specifically 1.33 kB on average.
Debiasing Large Visual Language Models
Mar 08, 2024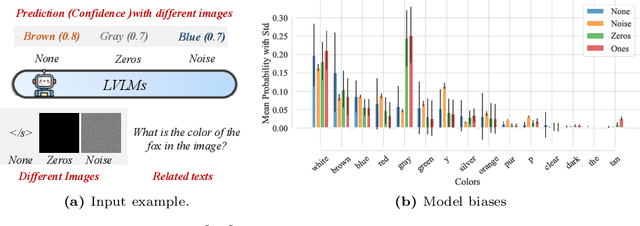
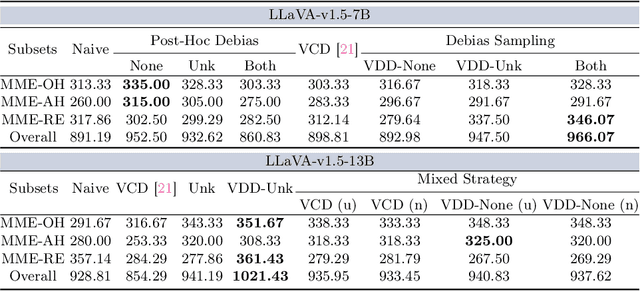
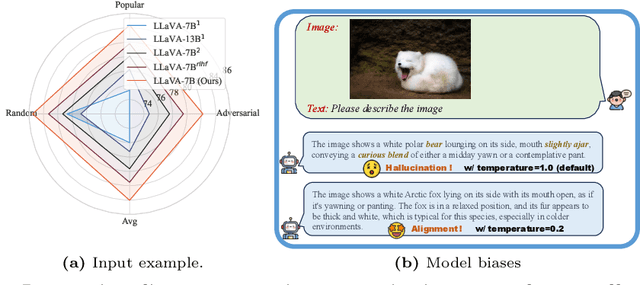
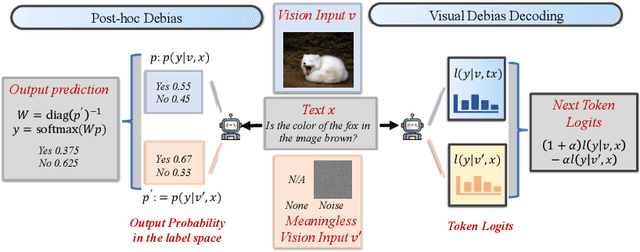
In the realms of computer vision and natural language processing, Large Vision-Language Models (LVLMs) have become indispensable tools, proficient in generating textual descriptions based on visual inputs. Despite their advancements, our investigation reveals a noteworthy bias in the generated content, where the output is primarily influenced by the underlying Large Language Models (LLMs) prior rather than the input image. Our empirical experiments underscore the persistence of this bias, as LVLMs often provide confident answers even in the absence of relevant images or given incongruent visual input. To rectify these biases and redirect the model's focus toward vision information, we introduce two simple, training-free strategies. Firstly, for tasks such as classification or multi-choice question-answering (QA), we propose a ``calibration'' step through affine transformation to adjust the output distribution. This ``Post-Hoc debias'' approach ensures uniform scores for each answer when the image is absent, serving as an effective regularization technique to alleviate the influence of LLM priors. For more intricate open-ended generation tasks, we extend this method to ``Debias sampling'', drawing inspirations from contrastive decoding methods. Furthermore, our investigation sheds light on the instability of LVLMs across various decoding configurations. Through systematic exploration of different settings, we significantly enhance performance, surpassing reported results and raising concerns about the fairness of existing evaluations. Comprehensive experiments substantiate the effectiveness of our proposed strategies in mitigating biases. These strategies not only prove beneficial in minimizing hallucinations but also contribute to the generation of more helpful and precise illustrations.
Federated Learning Method for Preserving Privacy in Face Recognition System
Mar 08, 2024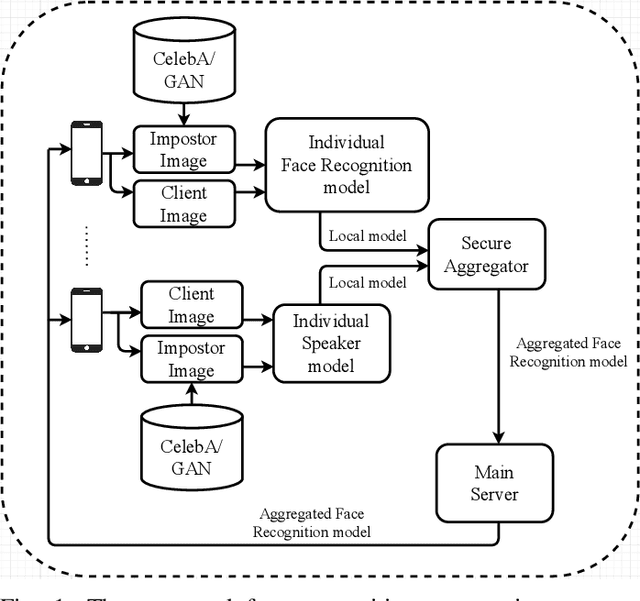
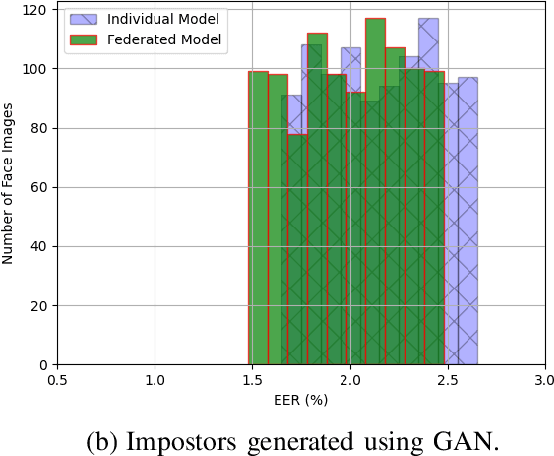
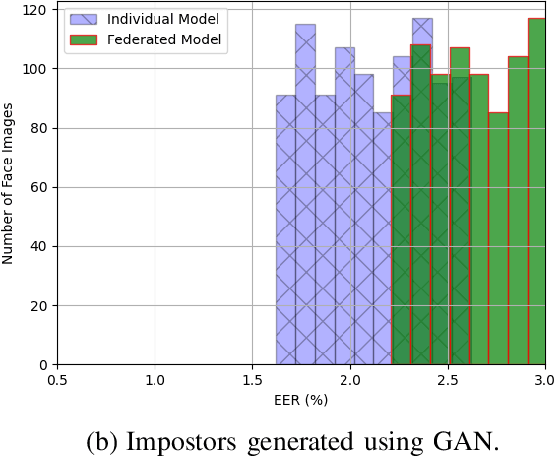
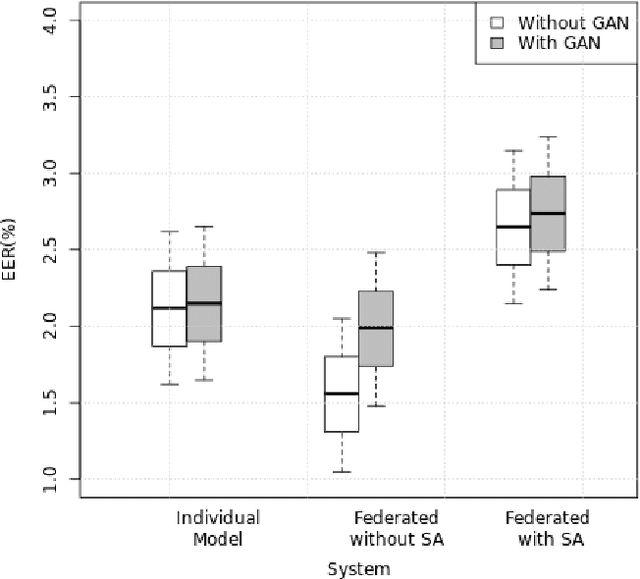
The state-of-the-art face recognition systems are typically trained on a single computer, utilizing extensive image datasets collected from various number of users. However, these datasets often contain sensitive personal information that users may hesitate to disclose. To address potential privacy concerns, we explore the application of federated learning, both with and without secure aggregators, in the context of both supervised and unsupervised face recognition systems. Federated learning facilitates the training of a shared model without necessitating the sharing of individual private data, achieving this by training models on decentralized edge devices housing the data. In our proposed system, each edge device independently trains its own model, which is subsequently transmitted either to a secure aggregator or directly to the central server. To introduce diverse data without the need for data transmission, we employ generative adversarial networks to generate imposter data at the edge. Following this, the secure aggregator or central server combines these individual models to construct a global model, which is then relayed back to the edge devices. Experimental findings based on the CelebA datasets reveal that employing federated learning in both supervised and unsupervised face recognition systems offers dual benefits. Firstly, it safeguards privacy since the original data remains on the edge devices. Secondly, the experimental results demonstrate that the aggregated model yields nearly identical performance compared to the individual models, particularly when the federated model does not utilize a secure aggregator. Hence, our results shed light on the practical challenges associated with privacy-preserving face image training, particularly in terms of the balance between privacy and accuracy.
Towards a Psychology of Machines: Large Language Models Predict Human Memory
Mar 08, 2024
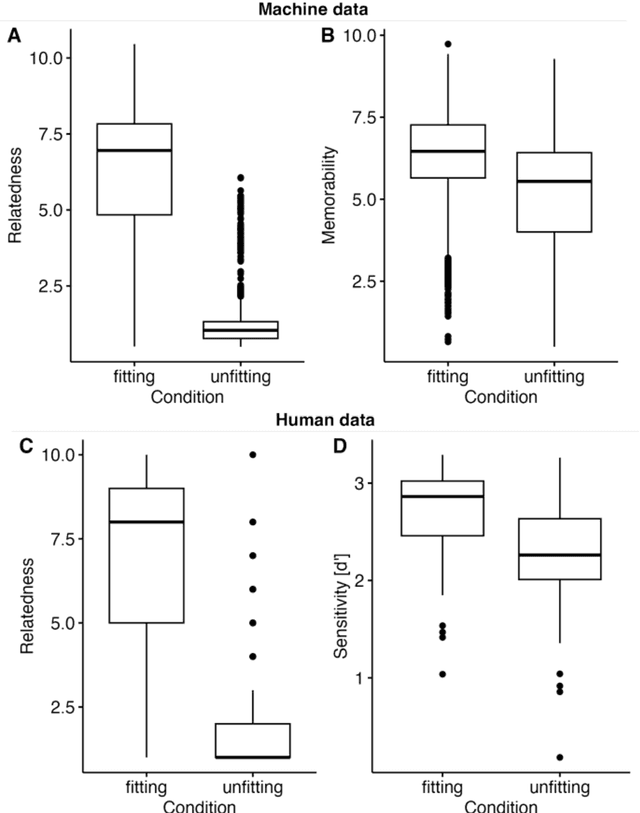
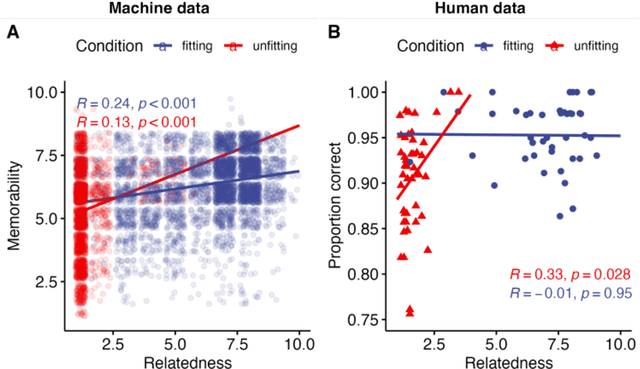
Large language models (LLMs) are demonstrating remarkable capabilities across various tasks despite lacking a foundation in human cognition. This raises the question: can these models, beyond simply mimicking human language patterns, offer insights into the mechanisms underlying human cognition? This study explores the ability of ChatGPT to predict human performance in a language-based memory task. Building upon theories of text comprehension, we hypothesize that recognizing ambiguous sentences (e.g., "Because Bill drinks wine is never kept in the house") is facilitated by preceding them with contextually relevant information. Participants, both human and ChatGPT, were presented with pairs of sentences. The second sentence was always a garden-path sentence designed to be inherently ambiguous, while the first sentence either provided a fitting (e.g., "Bill has chronic alcoholism") or an unfitting context (e.g., "Bill likes to play golf"). We measured both human's and ChatGPT's ratings of sentence relatedness, ChatGPT's memorability ratings for the garden-path sentences, and humans' spontaneous memory for the garden-path sentences. The results revealed a striking alignment between ChatGPT's assessments and human performance. Sentences deemed more related and assessed as being more memorable by ChatGPT were indeed better remembered by humans, even though ChatGPT's internal mechanisms likely differ significantly from human cognition. This finding, which was confirmed with a robustness check employing synonyms, underscores the potential of generative AI models to predict human performance accurately. We discuss the broader implications of these findings for leveraging LLMs in the development of psychological theories and for gaining a deeper understanding of human cognition.
Theoretical Insights for Diffusion Guidance: A Case Study for Gaussian Mixture Models
Mar 03, 2024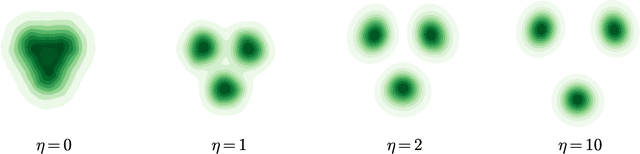
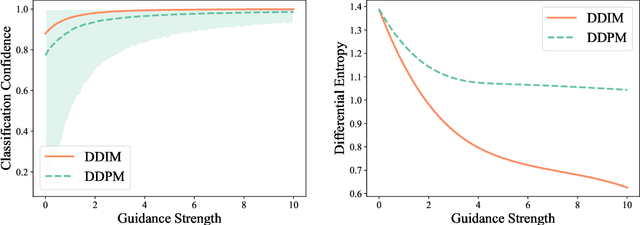
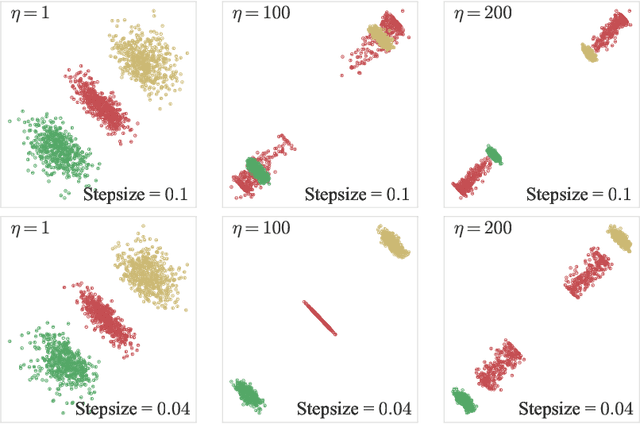
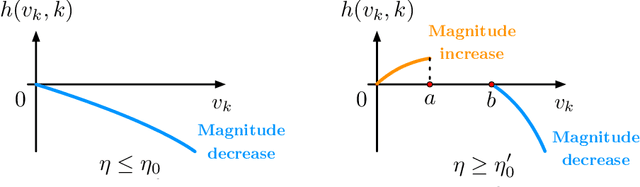
Diffusion models benefit from instillation of task-specific information into the score function to steer the sample generation towards desired properties. Such information is coined as guidance. For example, in text-to-image synthesis, text input is encoded as guidance to generate semantically aligned images. Proper guidance inputs are closely tied to the performance of diffusion models. A common observation is that strong guidance promotes a tight alignment to the task-specific information, while reducing the diversity of the generated samples. In this paper, we provide the first theoretical study towards understanding the influence of guidance on diffusion models in the context of Gaussian mixture models. Under mild conditions, we prove that incorporating diffusion guidance not only boosts classification confidence but also diminishes distribution diversity, leading to a reduction in the differential entropy of the output distribution. Our analysis covers the widely adopted sampling schemes including DDPM and DDIM, and leverages comparison inequalities for differential equations as well as the Fokker-Planck equation that characterizes the evolution of probability density function, which may be of independent theoretical interest.
SGD with Partial Hessian for Deep Neural Networks Optimization
Mar 05, 2024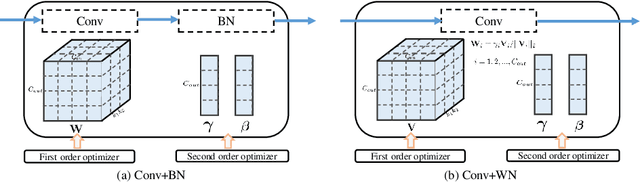
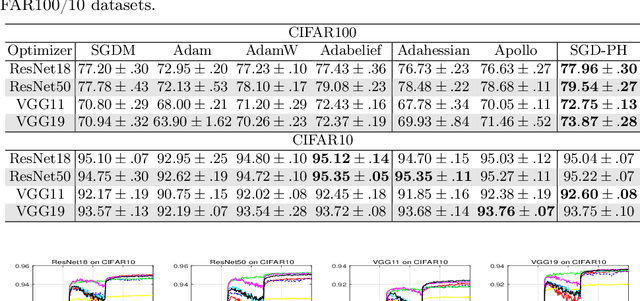
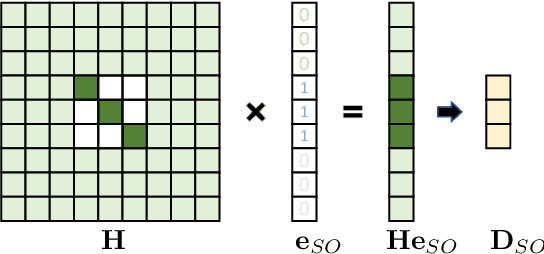

Due to the effectiveness of second-order algorithms in solving classical optimization problems, designing second-order optimizers to train deep neural networks (DNNs) has attracted much research interest in recent years. However, because of the very high dimension of intermediate features in DNNs, it is difficult to directly compute and store the Hessian matrix for network optimization. Most of the previous second-order methods approximate the Hessian information imprecisely, resulting in unstable performance. In this work, we propose a compound optimizer, which is a combination of a second-order optimizer with a precise partial Hessian matrix for updating channel-wise parameters and the first-order stochastic gradient descent (SGD) optimizer for updating the other parameters. We show that the associated Hessian matrices of channel-wise parameters are diagonal and can be extracted directly and precisely from Hessian-free methods. The proposed method, namely SGD with Partial Hessian (SGD-PH), inherits the advantages of both first-order and second-order optimizers. Compared with first-order optimizers, it adopts a certain amount of information from the Hessian matrix to assist optimization, while compared with the existing second-order optimizers, it keeps the good generalization performance of first-order optimizers. Experiments on image classification tasks demonstrate the effectiveness of our proposed optimizer SGD-PH. The code is publicly available at \url{https://github.com/myingysun/SGDPH}.
Enhancing Retinal Vascular Structure Segmentation in Images With a Novel Design Two-Path Interactive Fusion Module Model
Mar 03, 2024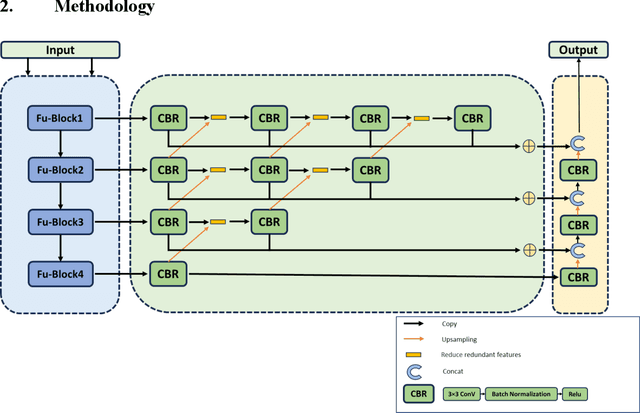
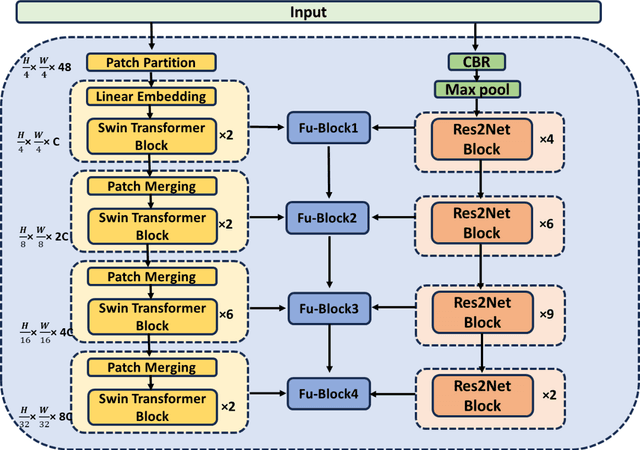
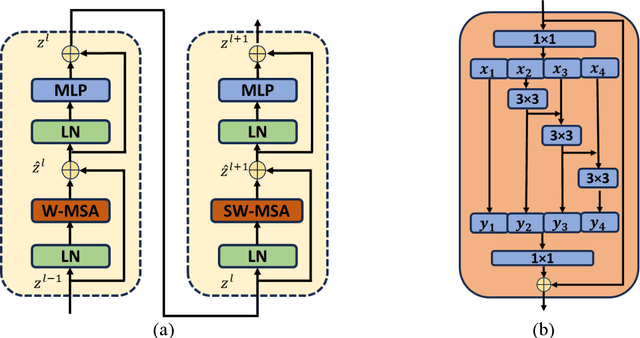
Precision in identifying and differentiating micro and macro blood vessels in the retina is crucial for the diagnosis of retinal diseases, although it poses a significant challenge. Current autoencoding-based segmentation approaches encounter limitations as they are constrained by the encoder and undergo a reduction in resolution during the encoding stage. The inability to recover lost information in the decoding phase further impedes these approaches. Consequently, their capacity to extract the retinal microvascular structure is restricted. To address this issue, we introduce Swin-Res-Net, a specialized module designed to enhance the precision of retinal vessel segmentation. Swin-Res-Net utilizes the Swin transformer which uses shifted windows with displacement for partitioning, to reduce network complexity and accelerate model convergence. Additionally, the model incorporates interactive fusion with a functional module in the Res2Net architecture. The Res2Net leverages multi-scale techniques to enlarge the receptive field of the convolutional kernel, enabling the extraction of additional semantic information from the image. This combination creates a new module that enhances the localization and separation of micro vessels in the retina. To improve the efficiency of processing vascular information, we've added a module to eliminate redundant information between the encoding and decoding steps. Our proposed architecture produces outstanding results, either meeting or surpassing those of other published models. The AUC reflects significant enhancements, achieving values of 0.9956, 0.9931, and 0.9946 in pixel-wise segmentation of retinal vessels across three widely utilized datasets: CHASE-DB1, DRIVE, and STARE, respectively. Moreover, Swin-Res-Net outperforms alternative architectures, demonstrating superior performance in both IOU and F1 measure metrics.
Robust Wake Word Spotting With Frame-Level Cross-Modal Attention Based Audio-Visual Conformer
Mar 04, 2024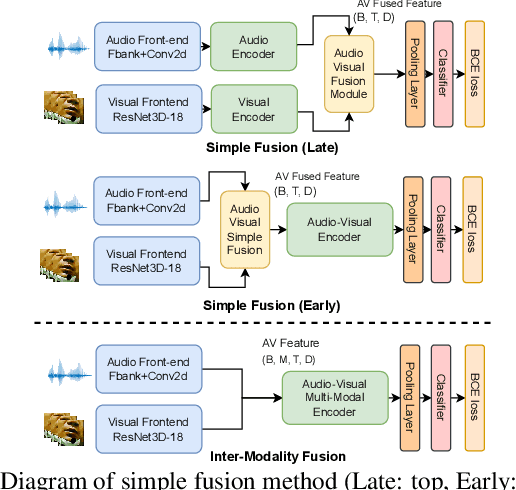
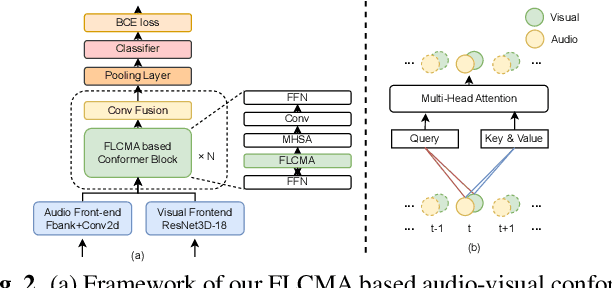
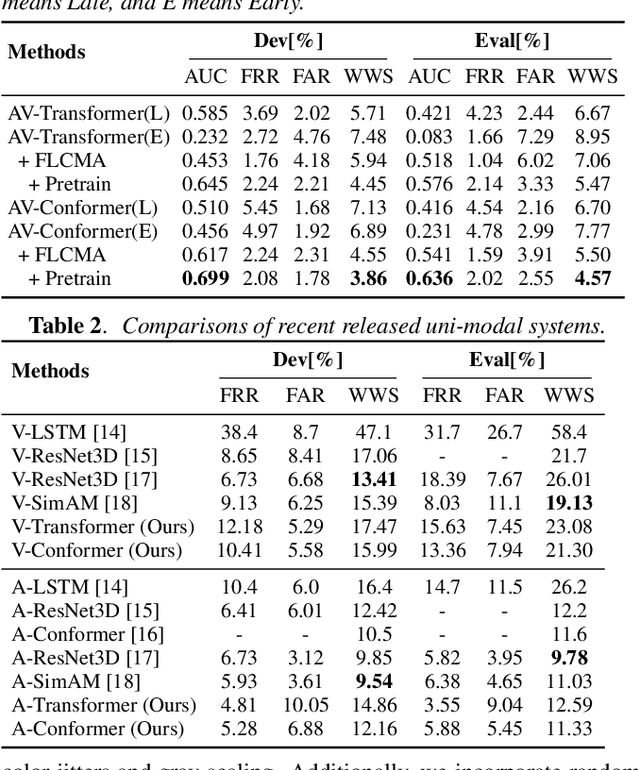
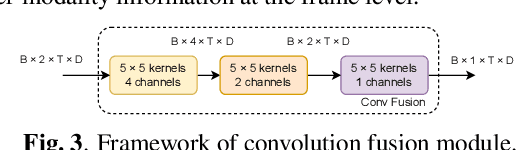
In recent years, neural network-based Wake Word Spotting achieves good performance on clean audio samples but struggles in noisy environments. Audio-Visual Wake Word Spotting (AVWWS) receives lots of attention because visual lip movement information is not affected by complex acoustic scenes. Previous works usually use simple addition or concatenation for multi-modal fusion. The inter-modal correlation remains relatively under-explored. In this paper, we propose a novel module called Frame-Level Cross-Modal Attention (FLCMA) to improve the performance of AVWWS systems. This module can help model multi-modal information at the frame-level through synchronous lip movements and speech signals. We train the end-to-end FLCMA based Audio-Visual Conformer and further improve the performance by fine-tuning pre-trained uni-modal models for the AVWWS task. The proposed system achieves a new state-of-the-art result (4.57% WWS score) on the far-field MISP dataset.
SSTKG: Simple Spatio-Temporal Knowledge Graph for Intepretable and Versatile Dynamic Information Embedding
Feb 19, 2024Knowledge graphs (KGs) have been increasingly employed for link prediction and recommendation using real-world datasets. However, the majority of current methods rely on static data, neglecting the dynamic nature and the hidden spatio-temporal attributes of real-world scenarios. This often results in suboptimal predictions and recommendations. Although there are effective spatio-temporal inference methods, they face challenges such as scalability with large datasets and inadequate semantic understanding, which impede their performance. To address these limitations, this paper introduces a novel framework - Simple Spatio-Temporal Knowledge Graph (SSTKG), for constructing and exploring spatio-temporal KGs. To integrate spatial and temporal data into KGs, our framework exploited through a new 3-step embedding method. Output embeddings can be used for future temporal sequence prediction and spatial information recommendation, providing valuable insights for various applications such as retail sales forecasting and traffic volume prediction. Our framework offers a simple but comprehensive way to understand the underlying patterns and trends in dynamic KG, thereby enhancing the accuracy of predictions and the relevance of recommendations. This work paves the way for more effective utilization of spatio-temporal data in KGs, with potential impacts across a wide range of sectors.