 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
VideoDex: Learning Dexterity from Internet Videos
Dec 08, 2022
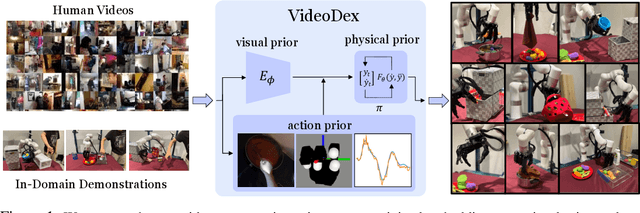
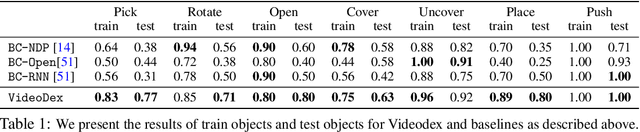

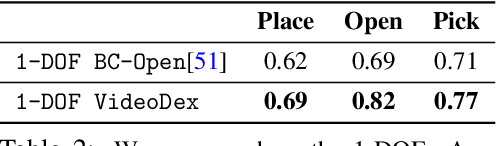
To build general robotic agents that can operate in many environments, it is often imperative for the robot to collect experience in the real world. However, this is often not feasible due to safety, time, and hardware restrictions. We thus propose leveraging the next best thing as real-world experience: internet videos of humans using their hands. Visual priors, such as visual features, are often learned from videos, but we believe that more information from videos can be utilized as a stronger prior. We build a learning algorithm, VideoDex, that leverages visual, action, and physical priors from human video datasets to guide robot behavior. These actions and physical priors in the neural network dictate the typical human behavior for a particular robot task. We test our approach on a robot arm and dexterous hand-based system and show strong results on various manipulation tasks, outperforming various state-of-the-art methods. Videos at https://video-dex.github.io
Learning Video Representations from Large Language Models
Dec 08, 2022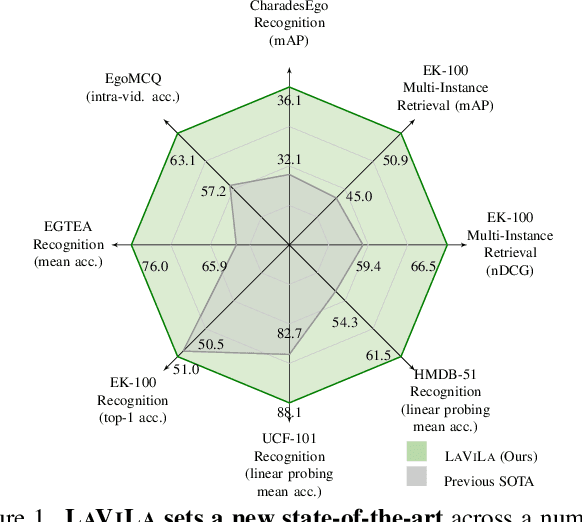
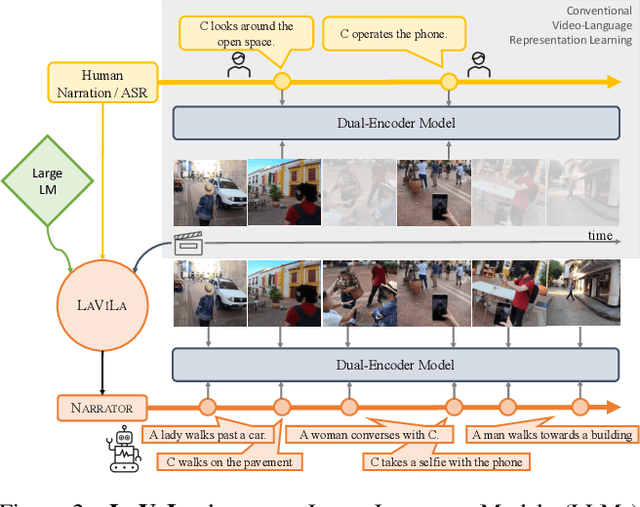
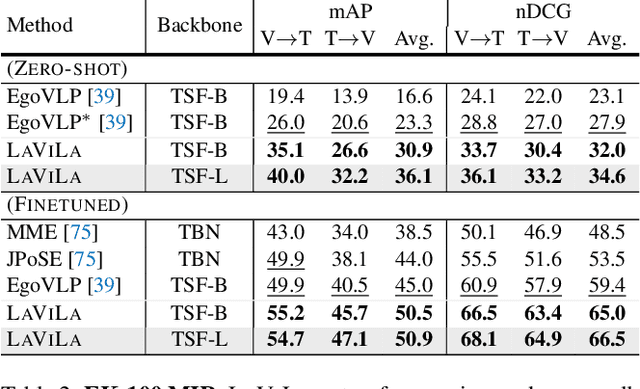
We introduce LaViLa, a new approach to learning video-language representations by leveraging Large Language Models (LLMs). We repurpose pre-trained LLMs to be conditioned on visual input, and finetune them to create automatic video narrators. Our auto-generated narrations offer a number of advantages, including dense coverage of long videos, better temporal synchronization of the visual information and text, and much higher diversity of text. The video-text embedding learned contrastively with these additional auto-generated narrations outperforms the previous state-of-the-art on multiple first-person and third-person video tasks, both in zero-shot and finetuned setups. Most notably, LaViLa obtains an absolute gain of 10.1% on EGTEA classification and 5.9% Epic-Kitchens-100 multi-instance retrieval benchmarks. Furthermore, LaViLa trained with only half the narrations from the Ego4D dataset outperforms baseline models trained on the full set, and shows positive scaling behavior on increasing pre-training data and model size.
A Comprehensive Survey on Multi-hop Machine Reading Comprehension Approaches
Dec 08, 2022
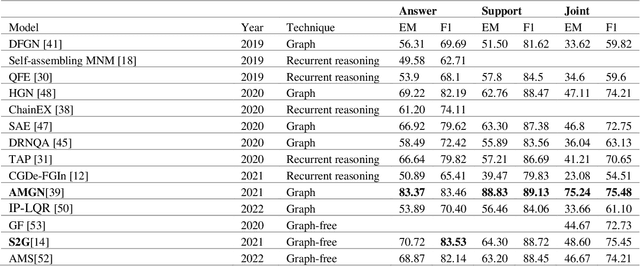

Machine reading comprehension (MRC) is a long-standing topic in natural language processing (NLP). The MRC task aims to answer a question based on the given context. Recently studies focus on multi-hop MRC which is a more challenging extension of MRC, which to answer a question some disjoint pieces of information across the context are required. Due to the complexity and importance of multi-hop MRC, a large number of studies have been focused on this topic in recent years, therefore, it is necessary and worth reviewing the related literature. This study aims to investigate recent advances in the multi-hop MRC approaches based on 31 studies from 2018 to 2022. In this regard, first, the multi-hop MRC problem definition will be introduced, then 31 models will be reviewed in detail with a strong focus on their multi-hop aspects. They also will be categorized based on their main techniques. Finally, a fine-grain comprehensive comparison of the models and techniques will be presented.
A Comprehensive Survey on Multi-hop Machine Reading Comprehension Datasets and Metrics
Dec 08, 2022
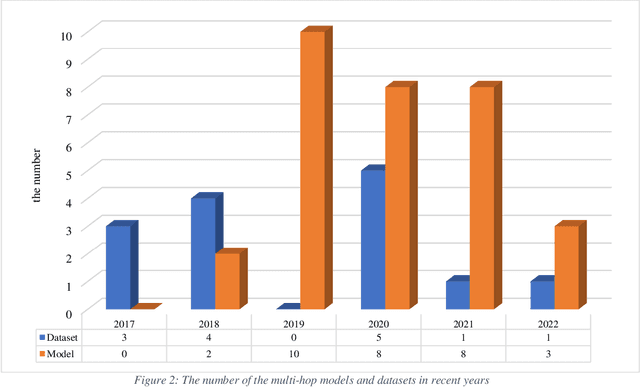

Multi-hop Machine reading comprehension is a challenging task with aim of answering a question based on disjoint pieces of information across the different passages. The evaluation metrics and datasets are a vital part of multi-hop MRC because it is not possible to train and evaluate models without them, also, the proposed challenges by datasets often are an important motivation for improving the existing models. Due to increasing attention to this field, it is necessary and worth reviewing them in detail. This study aims to present a comprehensive survey on recent advances in multi-hop MRC evaluation metrics and datasets. In this regard, first, the multi-hop MRC problem definition will be presented, then the evaluation metrics based on their multi-hop aspect will be investigated. Also, 15 multi-hop datasets have been reviewed in detail from 2017 to 2022, and a comprehensive analysis has been prepared at the end. Finally, open issues in this field have been discussed.
Strong identifiability and parameter learning in regression with heterogeneous response
Dec 08, 2022
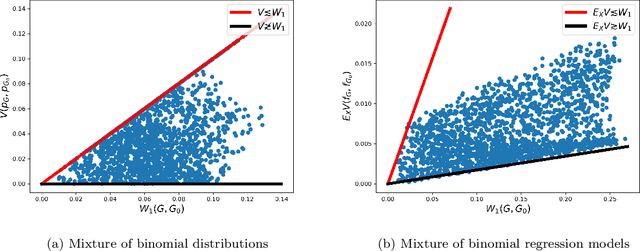
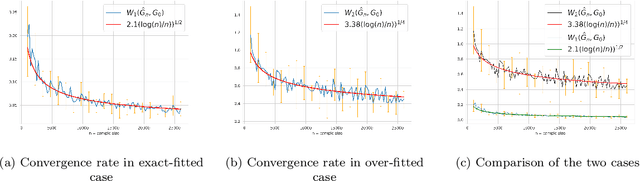
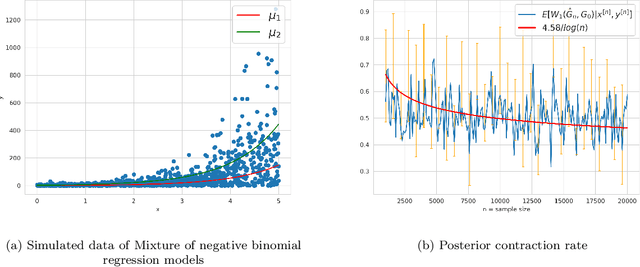
Mixtures of regression are a powerful class of models for regression learning with respect to a highly uncertain and heterogeneous response variable of interest. In addition to being a rich predictive model for the response given some covariates, the parameters in this model class provide useful information about the heterogeneity in the data population, which is represented by the conditional distributions for the response given the covariates associated with a number of distinct but latent subpopulations. In this paper, we investigate conditions of strong identifiability, rates of convergence for conditional density and parameter estimation, and the Bayesian posterior contraction behavior arising in finite mixture of regression models, under exact-fitted and over-fitted settings and when the number of components is unknown. This theory is applicable to common choices of link functions and families of conditional distributions employed by practitioners. We provide simulation studies and data illustrations, which shed some light on the parameter learning behavior found in several popular regression mixture models reported in the literature.
Quantum-Inspired Approximations to Constraint Satisfaction Problems
Dec 08, 2022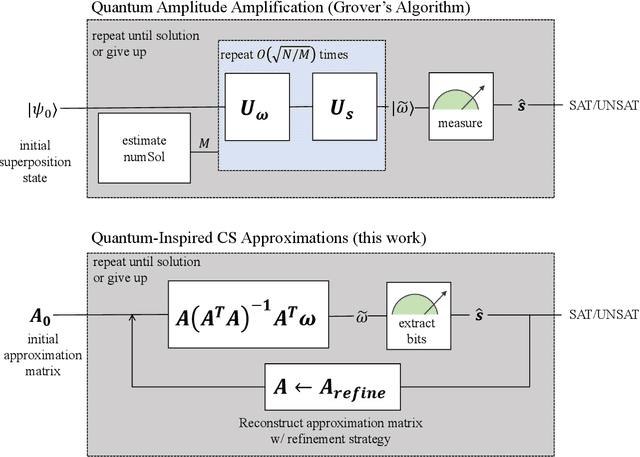
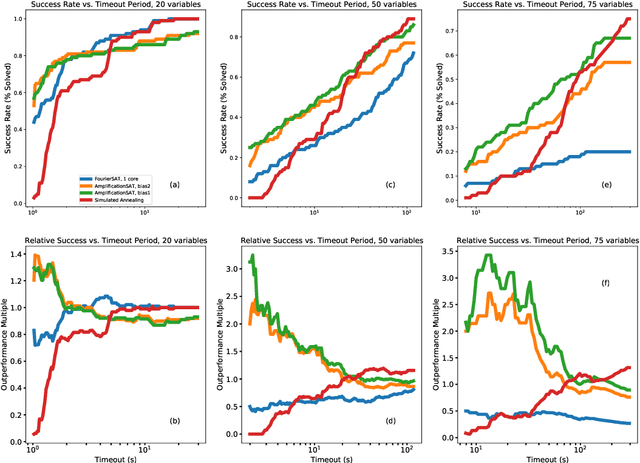
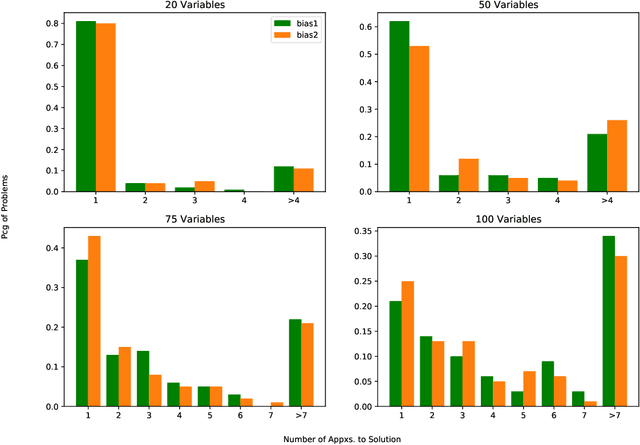
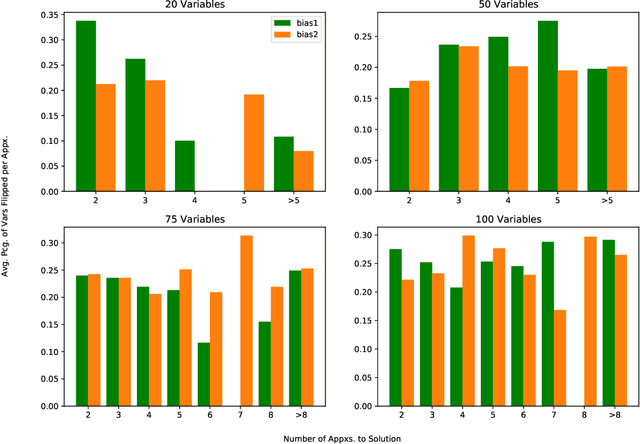
Two contrasting algorithmic paradigms for constraint satisfaction problems are successive local explorations of neighboring configurations versus producing new configurations using global information about the problem (e.g. approximating the marginals of the probability distribution which is uniform over satisfying configurations). This paper presents new algorithms for the latter framework, ultimately producing estimates for satisfying configurations using methods from Boolean Fourier analysis. The approach is broadly inspired by the quantum amplitude amplification algorithm in that it maximally increases the amplitude of the approximation function over satisfying configurations given sequential refinements. We demonstrate that satisfying solutions may be retrieved in a process analogous to quantum measurement made efficient by sparsity in the Fourier domain, and present a complete solver construction using this novel approximation. Freedom in the refinement strategy invites further opportunities to design solvers in an evolutionary computing framework. Results demonstrate competitive performance against local solvers for the Boolean satisfiability (SAT) problem, encouraging future work in understanding the connections between Boolean Fourier analysis and constraint satisfaction.
XRand: Differentially Private Defense against Explanation-Guided Attacks
Dec 08, 2022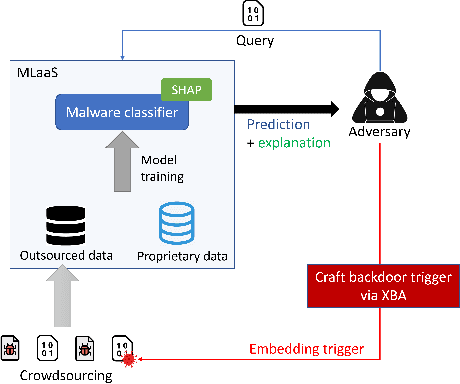
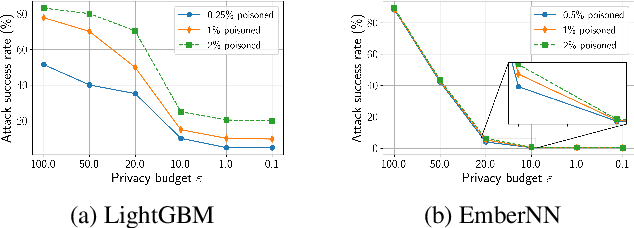
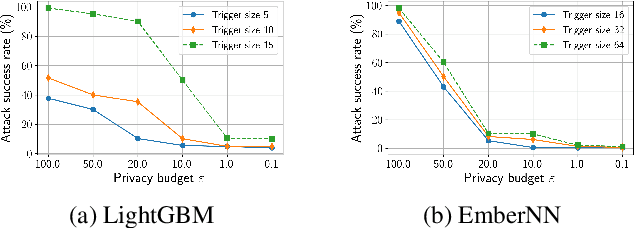
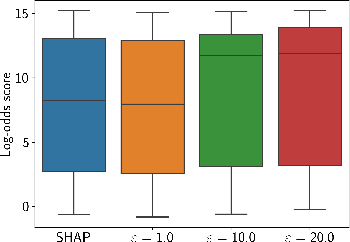
Recent development in the field of explainable artificial intelligence (XAI) has helped improve trust in Machine-Learning-as-a-Service (MLaaS) systems, in which an explanation is provided together with the model prediction in response to each query. However, XAI also opens a door for adversaries to gain insights into the black-box models in MLaaS, thereby making the models more vulnerable to several attacks. For example, feature-based explanations (e.g., SHAP) could expose the top important features that a black-box model focuses on. Such disclosure has been exploited to craft effective backdoor triggers against malware classifiers. To address this trade-off, we introduce a new concept of achieving local differential privacy (LDP) in the explanations, and from that we establish a defense, called XRand, against such attacks. We show that our mechanism restricts the information that the adversary can learn about the top important features, while maintaining the faithfulness of the explanations.
Simulation of Attacker Defender Interaction in a Noisy Security Game
Dec 08, 2022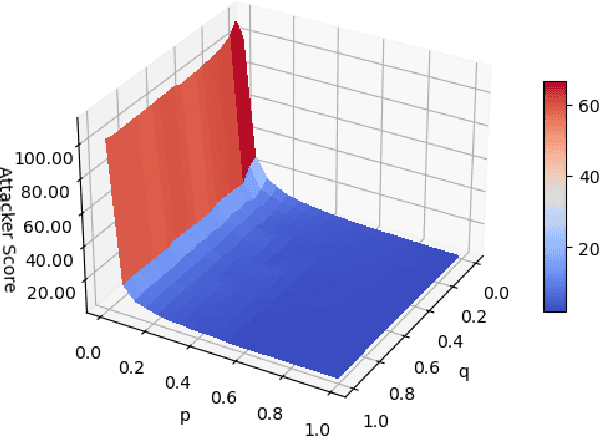
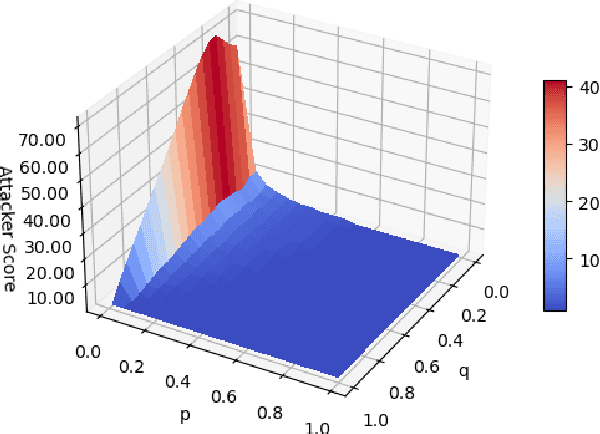
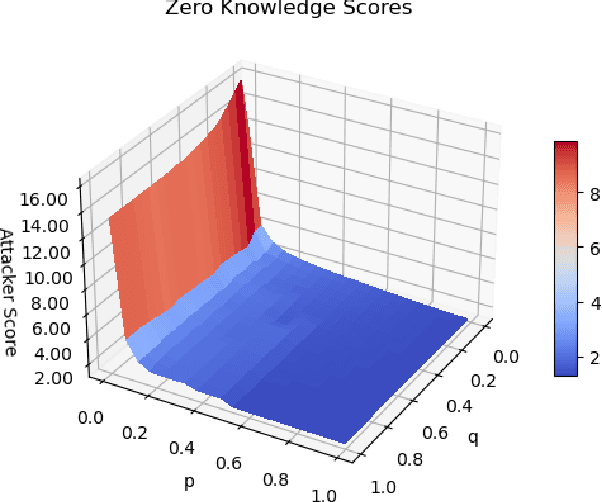
In the cybersecurity setting, defenders are often at the mercy of their detection technologies and subject to the information and experiences that individual analysts have. In order to give defenders an advantage, it is important to understand an attacker's motivation and their likely next best action. As a first step in modeling this behavior, we introduce a security game framework that simulates interplay between attackers and defenders in a noisy environment, focusing on the factors that drive decision making for attackers and defenders in the variants of the game with full knowledge and observability, knowledge of the parameters but no observability of the state (``partial knowledge''), and zero knowledge or observability (``zero knowledge''). We demonstrate the importance of making the right assumptions about attackers, given significant differences in outcomes. Furthermore, there is a measurable trade-off between false-positives and true-positives in terms of attacker outcomes, suggesting that a more false-positive prone environment may be acceptable under conditions where true-positives are also higher.
Semantic-SuPer: A Semantic-aware Surgical Perception Framework for Endoscopic Tissue Classification, Reconstruction, and Tracking
Oct 29, 2022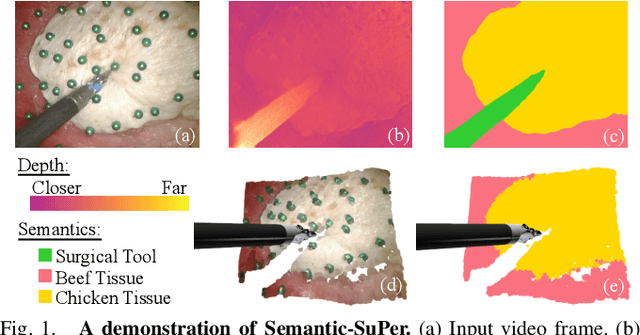
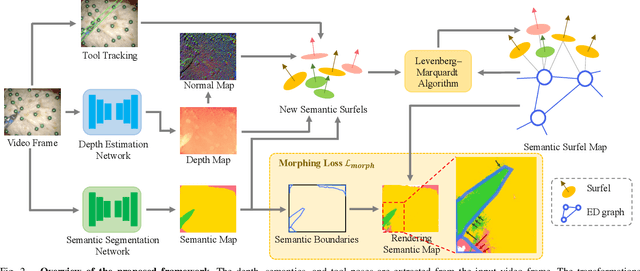


Accurate and robust tracking and reconstruction of the surgical scene is a critical enabling technology toward autonomous robotic surgery. Existing algorithms for 3D perception in surgery mainly rely on geometric information, while we propose to also leverage semantic information inferred from the endoscopic video using image segmentation algorithms. In this paper, we present a novel, comprehensive surgical perception framework, Semantic-SuPer, that integrates geometric and semantic information to facilitate data association, 3D reconstruction, and tracking of endoscopic scenes, benefiting downstream tasks like surgical navigation. The proposed framework is demonstrated on challenging endoscopic data with deforming tissue, showing its advantages over our baseline and several other state-of the-art approaches. Our code and dataset will be available at https://github.com/ucsdarclab/Python-SuPer.
DATID-3D: Diversity-Preserved Domain Adaptation Using Text-to-Image Diffusion for 3D Generative Model
Nov 29, 2022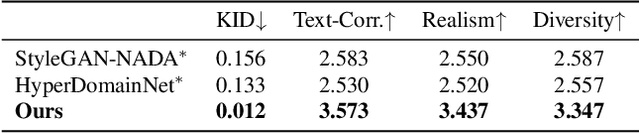
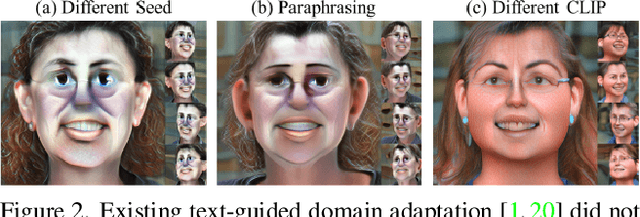
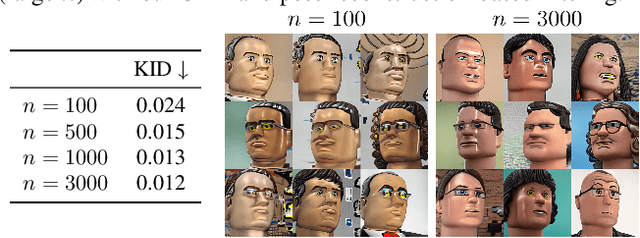
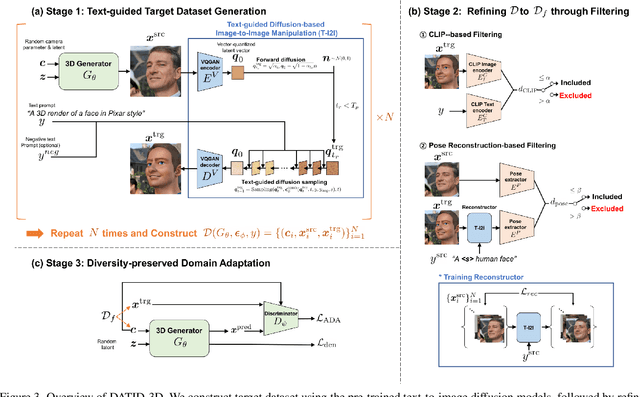
Recent 3D generative models have achieved remarkable performance in synthesizing high resolution photorealistic images with view consistency and detailed 3D shapes, but training them for diverse domains is challenging since it requires massive training images and their camera distribution information. Text-guided domain adaptation methods have shown impressive performance on converting the 2D generative model on one domain into the models on other domains with different styles by leveraging the CLIP (Contrastive Language-Image Pre-training), rather than collecting massive datasets for those domains. However, one drawback of them is that the sample diversity in the original generative model is not well-preserved in the domain-adapted generative models due to the deterministic nature of the CLIP text encoder. Text-guided domain adaptation will be even more challenging for 3D generative models not only because of catastrophic diversity loss, but also because of inferior text-image correspondence and poor image quality. Here we propose DATID-3D, a domain adaptation method tailored for 3D generative models using text-to-image diffusion models that can synthesize diverse images per text prompt without collecting additional images and camera information for the target domain. Unlike 3D extensions of prior text-guided domain adaptation methods, our novel pipeline was able to fine-tune the state-of-the-art 3D generator of the source domain to synthesize high resolution, multi-view consistent images in text-guided targeted domains without additional data, outperforming the existing text-guided domain adaptation methods in diversity and text-image correspondence. Furthermore, we propose and demonstrate diverse 3D image manipulations such as one-shot instance-selected adaptation and single-view manipulated 3D reconstruction to fully enjoy diversity in text.