 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
EarSpy: Spying Caller Speech and Identity through Tiny Vibrations of Smartphone Ear Speakers
Dec 23, 2022
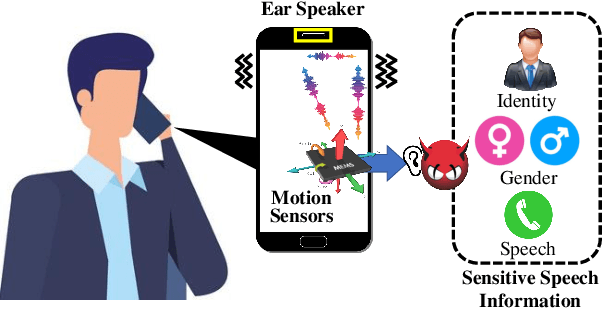
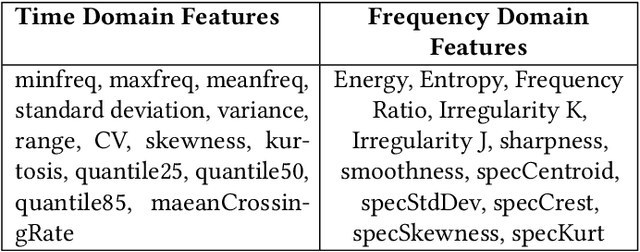
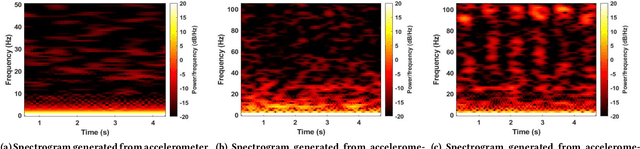
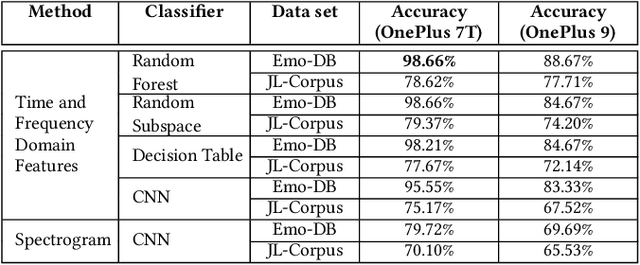
Eavesdropping from the user's smartphone is a well-known threat to the user's safety and privacy. Existing studies show that loudspeaker reverberation can inject speech into motion sensor readings, leading to speech eavesdropping. While more devastating attacks on ear speakers, which produce much smaller scale vibrations, were believed impossible to eavesdrop with zero-permission motion sensors. In this work, we revisit this important line of reach. We explore recent trends in smartphone manufacturers that include extra/powerful speakers in place of small ear speakers, and demonstrate the feasibility of using motion sensors to capture such tiny speech vibrations. We investigate the impacts of these new ear speakers on built-in motion sensors and examine the potential to elicit private speech information from the minute vibrations. Our designed system EarSpy can successfully detect word regions, time, and frequency domain features and generate a spectrogram for each word region. We train and test the extracted data using classical machine learning algorithms and convolutional neural networks. We found up to 98.66% accuracy in gender detection, 92.6% detection in speaker detection, and 56.42% detection in digit detection (which is 5X more significant than the random selection (10%)). Our result unveils the potential threat of eavesdropping on phone conversations from ear speakers using motion sensors.
A learning-based approach to multi-agent decision-making
Dec 23, 2022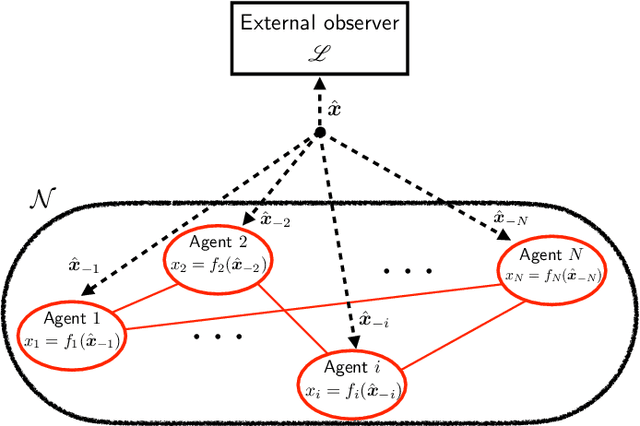
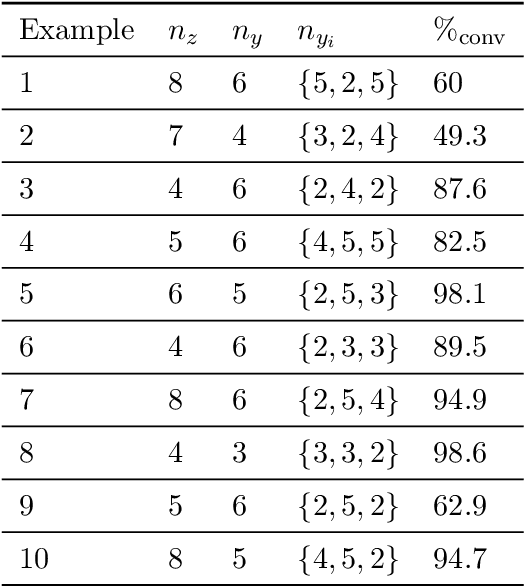
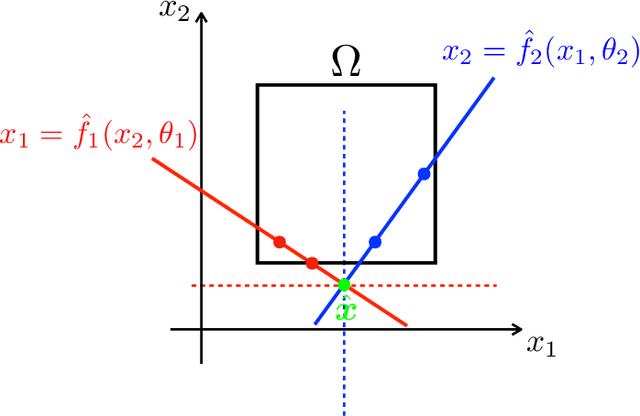
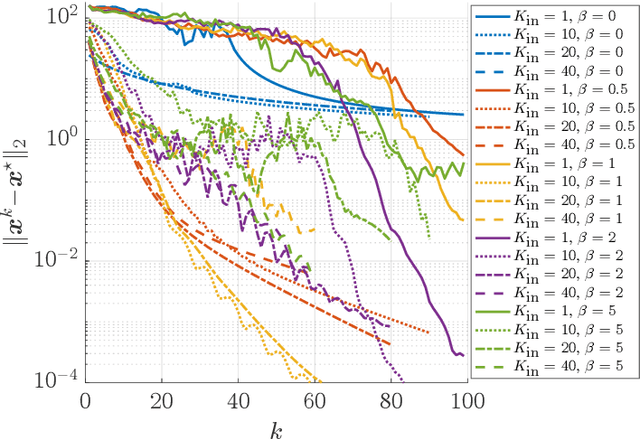
We propose a learning-based methodology to reconstruct private information held by a population of interacting agents in order to predict an exact outcome of the underlying multi-agent interaction process, here identified as a stationary action profile. We envision a scenario where an external observer, endowed with a learning procedure, is allowed to make queries and observe the agents' reactions through private action-reaction mappings, whose collective fixed point corresponds to a stationary profile. By adopting a smart query process to iteratively collect sensible data and update parametric estimates, we establish sufficient conditions to assess the asymptotic properties of the proposed learning-based methodology so that, if convergence happens, it can only be towards a stationary action profile. This fact yields two main consequences: i) learning locally-exact surrogates of the action-reaction mappings allows the external observer to succeed in its prediction task, and ii) working with assumptions so general that a stationary profile is not even guaranteed to exist, the established sufficient conditions hence act also as certificates for the existence of such a desirable profile. Extensive numerical simulations involving typical competitive multi-agent control and decision making problems illustrate the practical effectiveness of the proposed learning-based approach.
A Spreader Ranking Algorithm for Extremely Low-budget Influence Maximization in Social Networks using Community Bridge Nodes
Nov 17, 2022
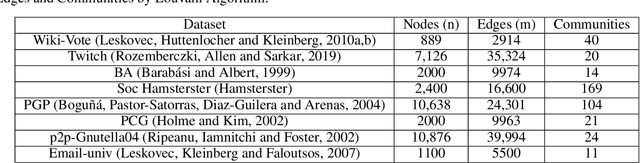
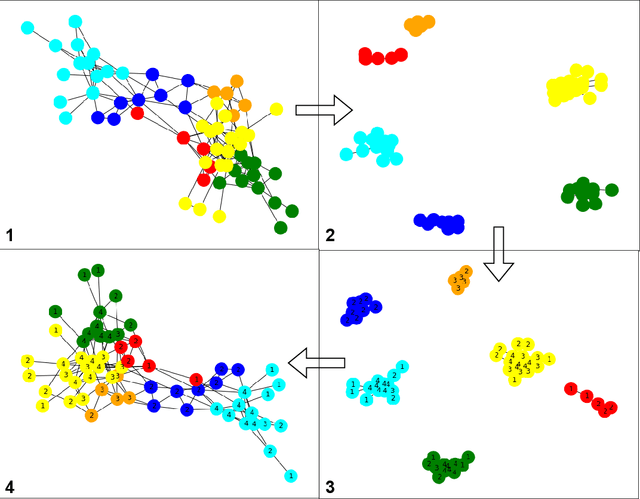
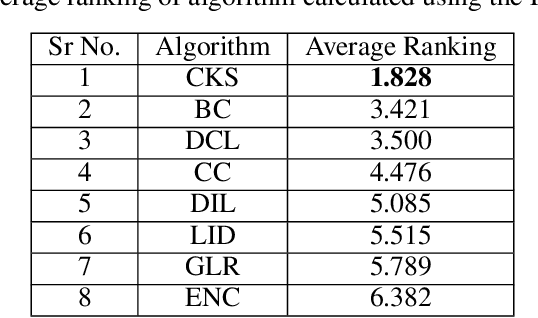
In recent years, social networking platforms have gained significant popularity among the masses like connecting with people and propagating ones thoughts and opinions. This has opened the door to user-specific advertisements and recommendations on these platforms, bringing along a significant focus on Influence Maximisation (IM) on social networks due to its wide applicability in target advertising, viral marketing, and personalized recommendations. The aim of IM is to identify certain nodes in the network which can help maximize the spread of certain information through a diffusion cascade. While several works have been proposed for IM, most were inefficient in exploiting community structures to their full extent. In this work, we propose a community structures-based approach, which employs a K-Shell algorithm in order to generate a score for the connections between seed nodes and communities for low-budget scenarios. Further, our approach employs entropy within communities to ensure the proper spread of information within the communities. We choose the Independent Cascade (IC) model to simulate information spread and evaluate it on four evaluation metrics. We validate our proposed approach on eight publicly available networks and find that it significantly outperforms the baseline approaches on these metrics, while still being relatively efficient.
Perturbation-Recovery Method for Recommendation
Nov 17, 2022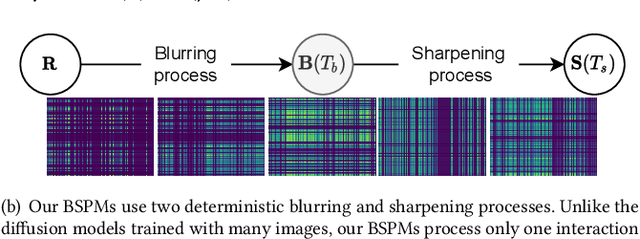

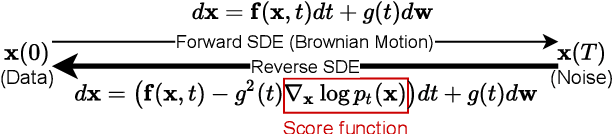

Collaborative filtering is one of the most influential recommender system types. Various methods have been proposed for collaborative filtering, ranging from matrix factorization to graph convolutional methods. Being inspired by recent successes of GF-CF and diffusion models, we present a novel concept of blurring-sharpening process model (BSPM). Diffusion models and BSPMs share the same processing philosophy in that new information is discovered (e.g., a new image is generated in the case of diffusion models) while original information is first perturbed and then recovered to its original form. However, diffusion models and our BSPMs deal with different types of information, and their optimal perturbation and recovery processes have a fundamental discrepancy. Therefore, our BSPMs have different forms from diffusion models. In addition, our concept not only theoretically subsumes many existing collaborative filtering models but also outperforms them in terms of Recall and NDCG in the three benchmark datasets, Gowalla, Yelp2018, and Amazon-book. Our model marks the best accuracy in them. In addition, the processing time of our method is one of the shortest cases ever in collaborative filtering. Our proposed concept has much potential in the future to be enhanced by designing better blurring (i.e., perturbation) and sharpening (i.e., recovery) processes than what we use in this paper.
Learning Visualization Policies of Augmented Reality for Human-Robot Collaboration
Nov 13, 2022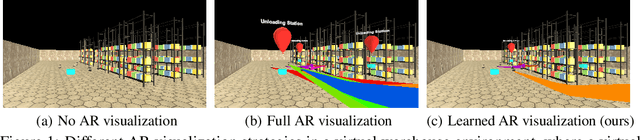
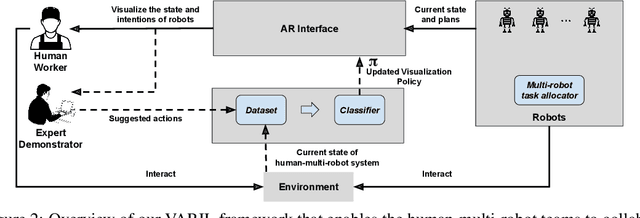
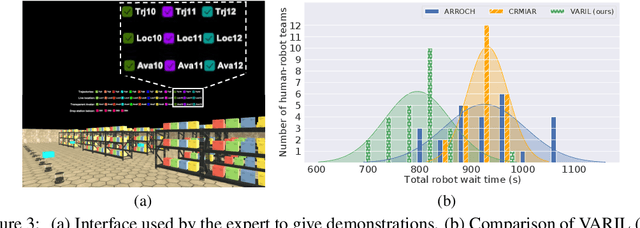

In human-robot collaboration domains, augmented reality (AR) technologies have enabled people to visualize the state of robots. Current AR-based visualization policies are designed manually, which requires a lot of human efforts and domain knowledge. When too little information is visualized, human users find the AR interface not useful; when too much information is visualized, they find it difficult to process the visualized information. In this paper, we develop a framework, called VARIL, that enables AR agents to learn visualization policies (what to visualize, when, and how) from demonstrations. We created a Unity-based platform for simulating warehouse environments where human-robot teammates collaborate on delivery tasks. We have collected a dataset that includes demonstrations of visualizing robots' current and planned behaviors. Results from experiments with real human participants show that, compared with competitive baselines from the literature, our learned visualization strategies significantly increase the efficiency of human-robot teams, while reducing the distraction level of human users. VARIL has been demonstrated in a built-in-lab mock warehouse.
Location analysis of players in UEFA EURO 2020 and 2022 using generalized valuation of defense by estimating probabilities
Nov 30, 2022
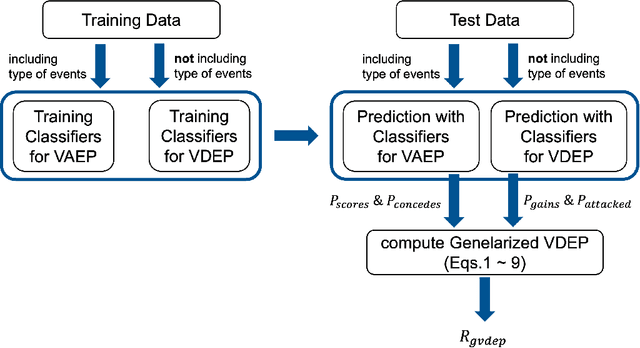
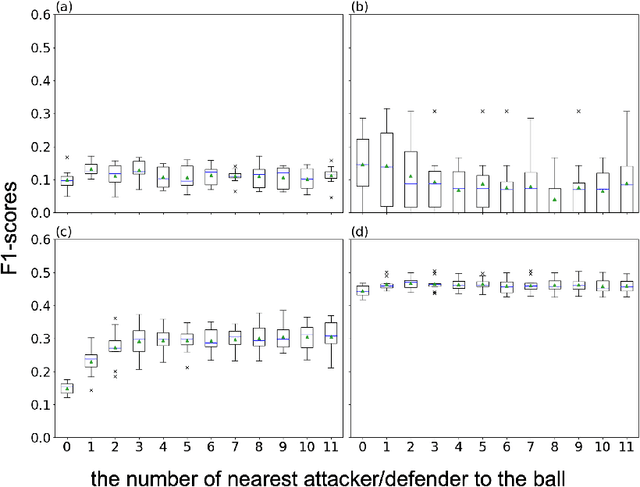
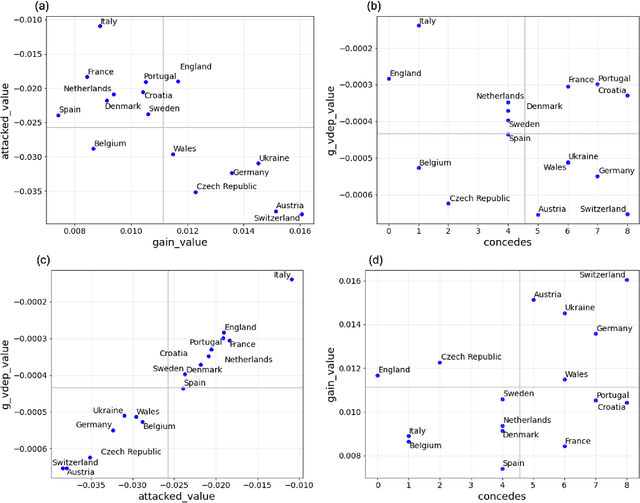
Analyzing defenses in team sports is generally challenging because of the limited event data. Researchers have previously proposed methods to evaluate football team defense by predicting the events of ball gain and being attacked using locations of all players and the ball. However, they did not consider the importance of the events, assumed the perfect observation of all 22 players, and did not fully investigated the influence of the diversity (e.g., nationality and sex). Here, we propose a generalized valuation method of defensive teams by score-scaling the predicted probabilities of the events. Using the open-source location data of all players in broadcast video frames in football games of men's Euro 2020 and women's Euro 2022, we investigated the effect of the number of players on the prediction and validated our approach by analyzing the games. Results show that for the predictions of being attacked, scoring, and conceding, all players' information was not necessary, while that of ball gain required information on three to four offensive and defensive players. With game analyses we explained the excellence in defense of finalist teams in Euro 2020. Our approach might be applicable to location data from broadcast video frames in football games.
DeFT-AN: Dense Frequency-Time Attentive Network for Multichannel Speech Enhancement
Dec 15, 2022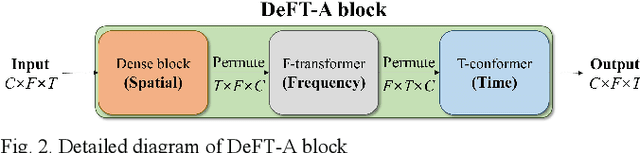
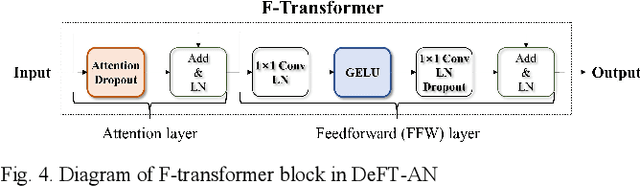
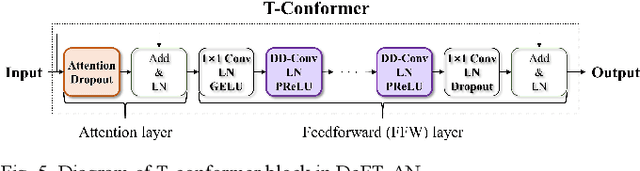
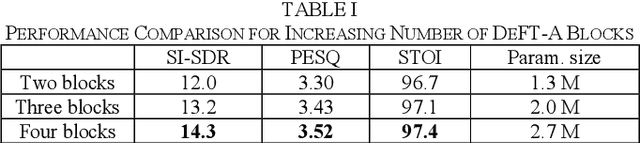
In this study, we propose a dense frequency-time attentive network (DeFT-AN) for multichannel speech enhancement. DeFT-AN is a mask estimation network that predicts a complex spectral masking pattern for suppressing the noise and reverberation embedded in the short-time Fourier transform (STFT) of an input signal. The proposed mask estimation network incorporates three different types of blocks for aggregating information in the spatial, spectral, and temporal dimensions. It utilizes a spectral transformer with a modified feed-forward network and a temporal conformer with sequential dilated convolutions. The use of dense blocks and transformers dedicated to the three different characteristics of audio signals enables more comprehensive denoising and dereverberation. The remarkable performance of DeFT-AN over state-of-the-art multichannel models is demonstrated based on two popular noisy and reverberant datasets in terms of various metrics for speech quality and intelligibility.
VieCap4H-VLSP 2021: ObjectAoA -- Enhancing performance of Object Relation Transformer with Attention on Attention for Vietnamese image captioning
Nov 12, 2022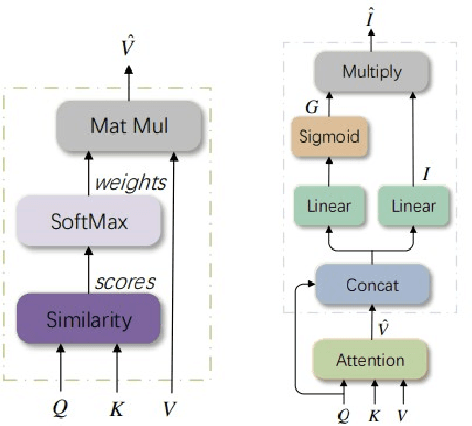

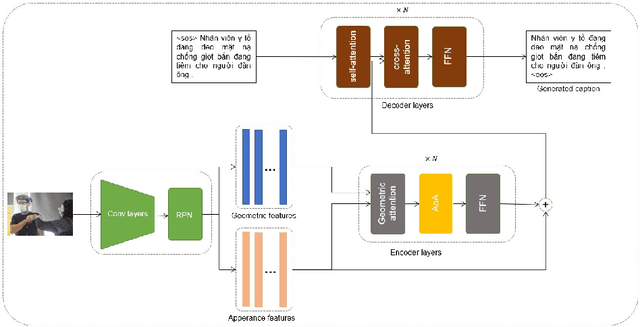

Image captioning is currently a challenging task that requires the ability to both understand visual information and use human language to describe this visual information in the image. In this paper, we propose an efficient way to improve the image understanding ability of transformer-based method by extending Object Relation Transformer architecture with Attention on Attention mechanism. Experiments on the VieCap4H dataset show that our proposed method significantly outperforms its original structure on both the public test and private test of the Image Captioning shared task held by VLSP.
FlowGrad: Using Motion for Visual Sound Source Localization
Nov 15, 2022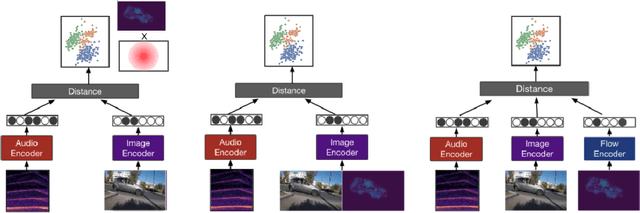
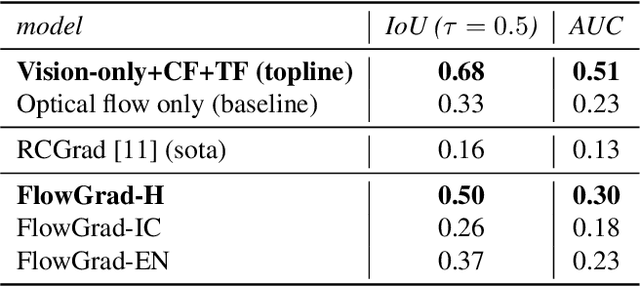
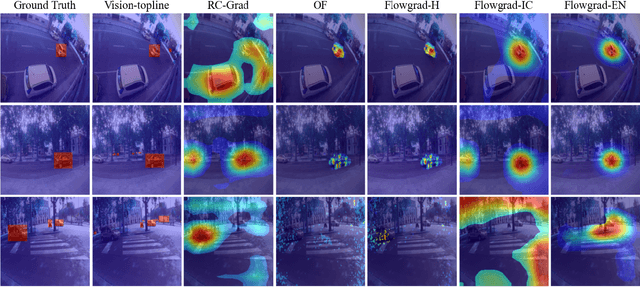
Most recent work in visual sound source localization relies on semantic audio-visual representations learned in a self-supervised manner, and by design excludes temporal information present in videos. While it proves to be effective for widely used benchmark datasets, the method falls short for challenging scenarios like urban traffic. This work introduces temporal context into the state-of-the-art methods for sound source localization in urban scenes using optical flow as a means to encode motion information. An analysis of the strengths and weaknesses of our methods helps us better understand the problem of visual sound source localization and sheds light on open challenges for audio-visual scene understanding.
SufrinNet: Toward Sufficient Cross-View Interaction for Stereo Image Enhancement in The Dark
Nov 04, 2022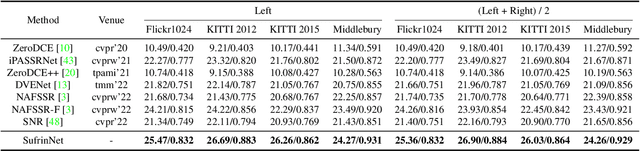
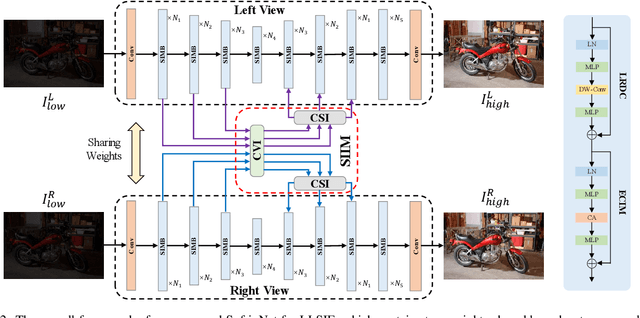
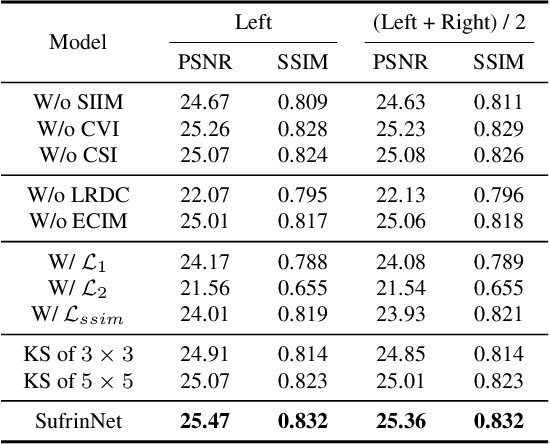
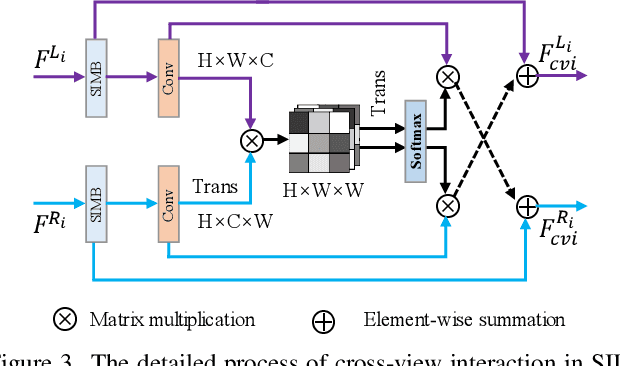
Low-light stereo image enhancement (LLSIE) is a relatively new task to enhance the quality of visually unpleasant stereo images captured in dark conditions. So far, very few studies on deep LLSIE have been explored due to certain challenging issues, i.e., the task has not been well addressed, and current methods clearly suffer from two shortages: 1) insufficient cross-view interaction; 2) lacking long-range dependency for intra-view learning. In this paper, we therefore propose a novel LLSIE model, termed \underline{Suf}ficient C\underline{r}oss-View \underline{In}teraction Network (SufrinNet). To be specific, we present sufficient inter-view interaction module (SIIM) to enhance the information exchange across views. SIIM not only discovers the cross-view correlations at different scales, but also explores the cross-scale information interaction. Besides, we present a spatial-channel information mining block (SIMB) for intra-view feature extraction, and the benefits are twofold. One is the long-range dependency capture to build spatial long-range relationship, and the other is expanded channel information refinement that enhances information flow in channel dimension. Extensive experiments on Flickr1024, KITTI 2012, KITTI 2015 and Middlebury datasets show that our method obtains better illumination adjustment and detail recovery, and achieves SOTA performance compared to other related methods. Our codes, datasets and models will be publicly available.