 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
MolCPT: Molecule Continuous Prompt Tuning to Generalize Molecular Representation Learning
Dec 20, 2022
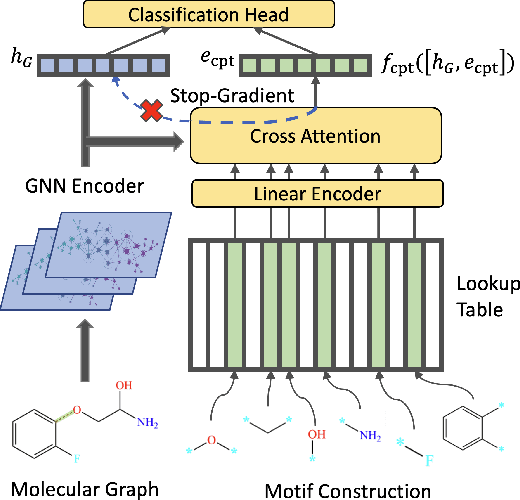
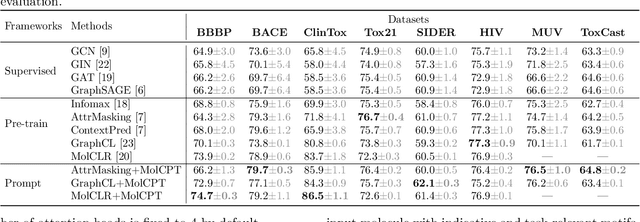
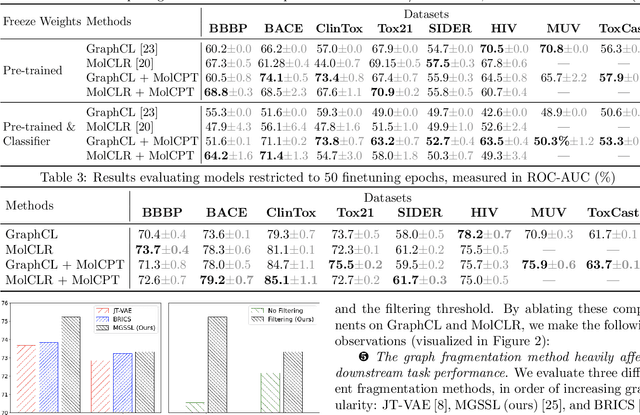

Molecular representation learning is crucial for the problem of molecular property prediction, where graph neural networks (GNNs) serve as an effective solution due to their structure modeling capabilities. Since labeled data is often scarce and expensive to obtain, it is a great challenge for GNNs to generalize in the extensive molecular space. Recently, the training paradigm of "pre-train, fine-tune" has been leveraged to improve the generalization capabilities of GNNs. It uses self-supervised information to pre-train the GNN, and then performs fine-tuning to optimize the downstream task with just a few labels. However, pre-training does not always yield statistically significant improvement, especially for self-supervised learning with random structural masking. In fact, the molecular structure is characterized by motif subgraphs, which are frequently occurring and influence molecular properties. To leverage the task-related motifs, we propose a novel paradigm of "pre-train, prompt, fine-tune" for molecular representation learning, named molecule continuous prompt tuning (MolCPT). MolCPT defines a motif prompting function that uses the pre-trained model to project the standalone input into an expressive prompt. The prompt effectively augments the molecular graph with meaningful motifs in the continuous representation space; this provides more structural patterns to aid the downstream classifier in identifying molecular properties. Extensive experiments on several benchmark datasets show that MolCPT efficiently generalizes pre-trained GNNs for molecular property prediction, with or without a few fine-tuning steps.
Sophisticated deep learning with on-chip optical diffractive tensor processing
Dec 20, 2022
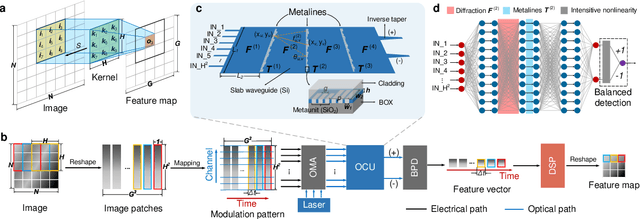
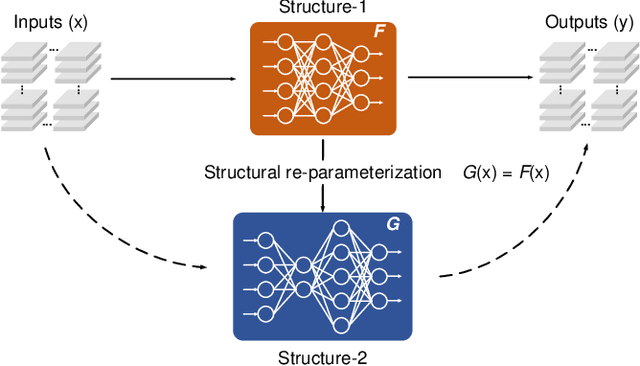
The ever-growing deep learning technologies are making revolutionary changes for modern life. However, conventional computing architectures are designed to process sequential and digital programs, being extremely burdened with performing massive parallel and adaptive deep learning applications. Photonic integrated circuits provide an efficient approach to mitigate bandwidth limitations and power-wall brought by its electronic counterparts, showing great potential in ultrafast and energy-free high-performance computing. Here, we propose an optical computing architecture enabled by on-chip diffraction to implement convolutional acceleration, termed optical convolution unit (OCU). We demonstrate that any real-valued convolution kernels can be exploited by OCU with a prominent computational throughput boosting via the concept of structral re-parameterization. With OCU as the fundamental unit, we build an optical convolutional neural network (oCNN) to implement two popular deep learning tasks: classification and regression. For classification, Fashion-MNIST and CIFAR-4 datasets are tested with accuracy of 91.63% and 86.25%, respectively. For regression, we build an optical denoising convolutional neural network (oDnCNN) to handle Gaussian noise in gray scale images with noise level {\sigma} = 10, 15, 20, resulting clean images with average PSNR of 31.70dB, 29.39dB and 27.72dB, respectively. The proposed OCU presents remarkable performance of low energy consumption and high information density due to its fully passive nature and compact footprint, providing a highly parallel while lightweight solution for future computing architecture to handle high dimensional tensors in deep learning.
Conditional variational autoencoder to improve neural audio synthesis for polyphonic music sound
Nov 16, 2022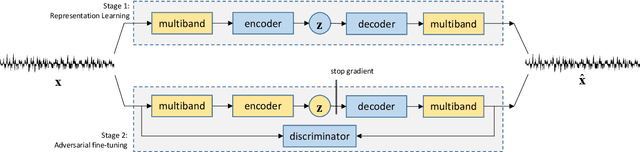
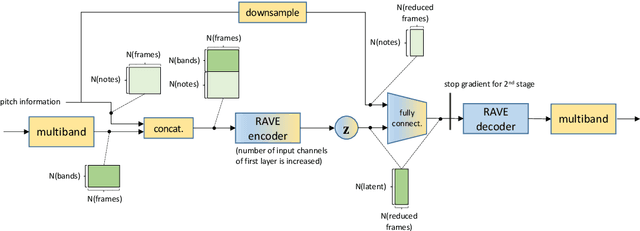
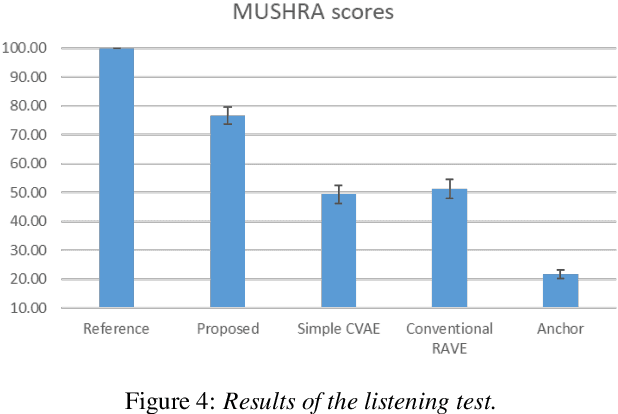
Deep generative models for audio synthesis have recently been significantly improved. However, the task of modeling raw-waveforms remains a difficult problem, especially for audio waveforms and music signals. Recently, the realtime audio variational autoencoder (RAVE) method was developed for high-quality audio waveform synthesis. The RAVE method is based on the variational autoencoder and utilizes the two-stage training strategy. Unfortunately, the RAVE model is limited in reproducing wide-pitch polyphonic music sound. Therefore, to enhance the reconstruction performance, we adopt the pitch activation data as an auxiliary information to the RAVE model. To handle the auxiliary information, we propose an enhanced RAVE model with a conditional variational autoencoder structure and an additional fully-connected layer. To evaluate the proposed structure, we conducted a listening experiment based on multiple stimulus tests with hidden references and an anchor (MUSHRA) with the MAESTRO. The obtained results indicate that the proposed model exhibits a more significant performance and stability improvement than the conventional RAVE model.
Semi-Supervised Clustering of Sparse Graphs: Crossing the Information-Theoretic Threshold
May 24, 2022
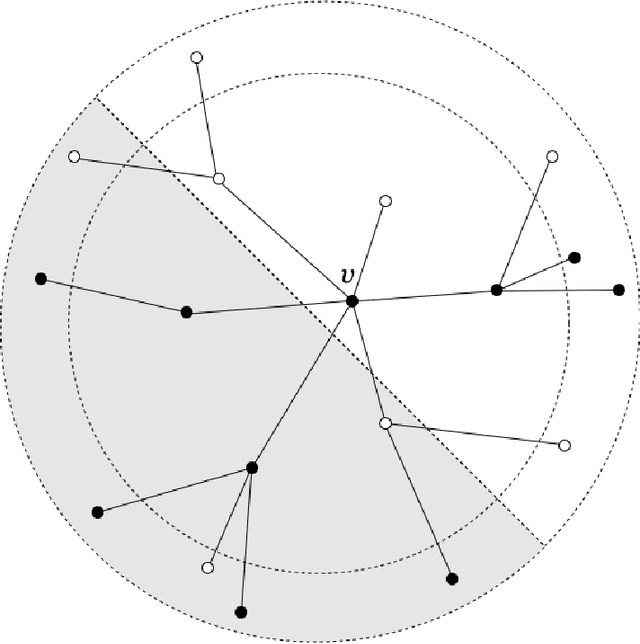
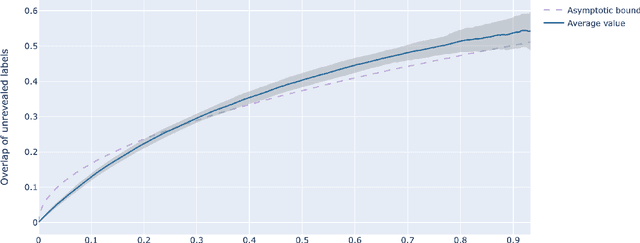
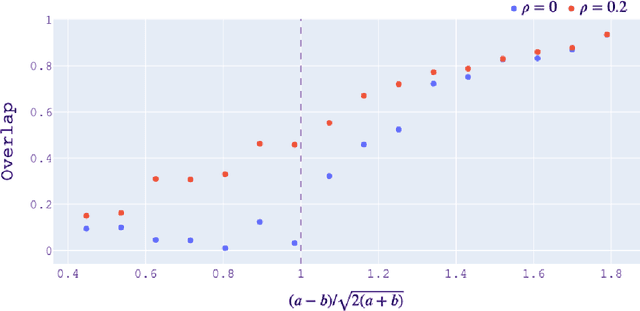
The stochastic block model is a canonical random graph model for clustering and community detection on network-structured data. Decades of extensive study on the problem have established many profound results, among which the phase transition at the Kesten-Stigum threshold is particularly interesting both from a mathematical and an applied standpoint. It states that no estimator based on the network topology can perform substantially better than chance on sparse graphs if the model parameter is below certain threshold. Nevertheless, if we slightly extend the horizon to the ubiquitous semi-supervised setting, such a fundamental limitation will disappear completely. We prove that with arbitrary fraction of the labels revealed, the detection problem is feasible throughout the parameter domain. Moreover, we introduce two efficient algorithms, one combinatorial and one based on optimization, to integrate label information with graph structures. Our work brings a new perspective to stochastic model of networks and semidefinite program research.
Sample Complexity versus Depth: An Information Theoretic Analysis
Apr 07, 2022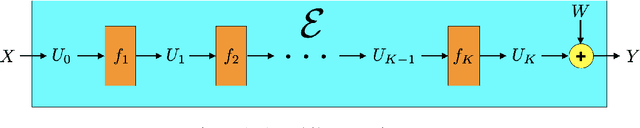
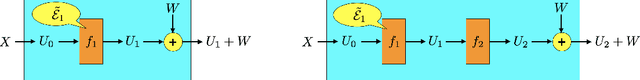
Deep learning has proven effective across a range of data sets. In light of this, a natural inquiry is: "for what data generating processes can deep learning succeed?" In this work, we study the sample complexity of learning multilayer data generating processes of a sort for which deep neural networks seem to be suited. We develop general and elegant information-theoretic tools that accommodate analysis of any data generating process -- shallow or deep, parametric or nonparametric, noiseless or noisy. We then use these tools to characterize the dependence of sample complexity on the depth of multilayer processes. Our results indicate roughly linear dependence on depth. This is in contrast to previous results that suggest exponential or high-order polynomial dependence.
Information Theory with Kernel Methods
Feb 17, 2022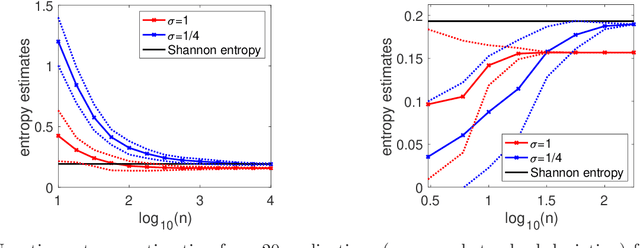
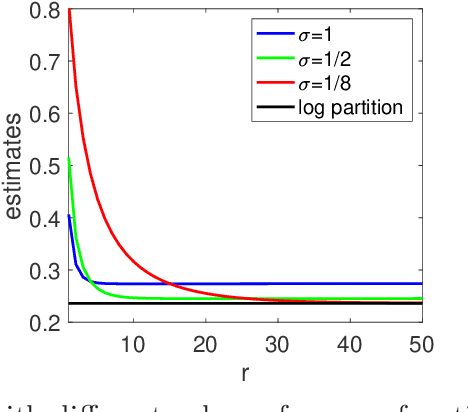
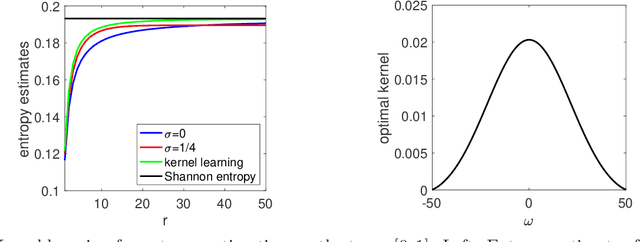
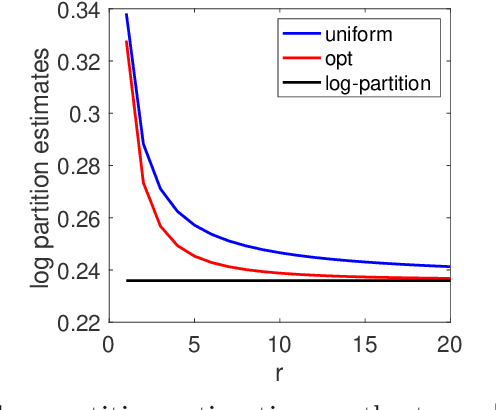
We consider the analysis of probability distributions through their associated covariance operators from reproducing kernel Hilbert spaces. We show that the von Neumann entropy and relative entropy of these operators are intimately related to the usual notions of Shannon entropy and relative entropy, and share many of their properties. They come together with efficient estimation algorithms from various oracles on the probability distributions. We also consider product spaces and show that for tensor product kernels, we can define notions of mutual information and joint entropies, which can then characterize independence perfectly, but only partially conditional independence. We finally show how these new notions of relative entropy lead to new upper-bounds on log partition functions, that can be used together with convex optimization within variational inference methods, providing a new family of probabilistic inference methods.
RAGO: Recurrent Graph Optimizer For Multiple Rotation Averaging
Dec 14, 2022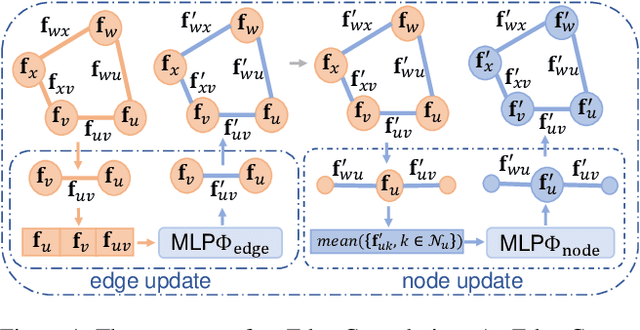
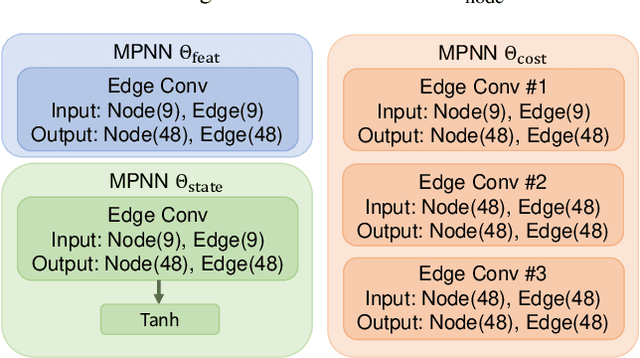
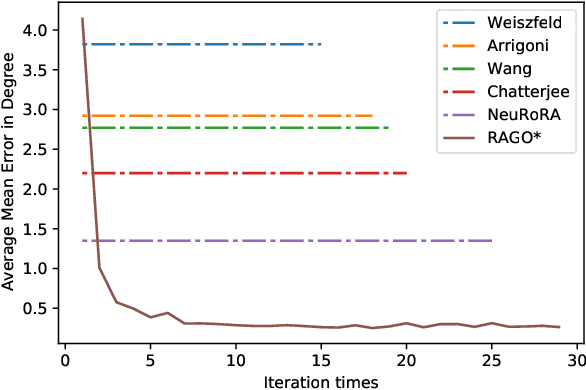
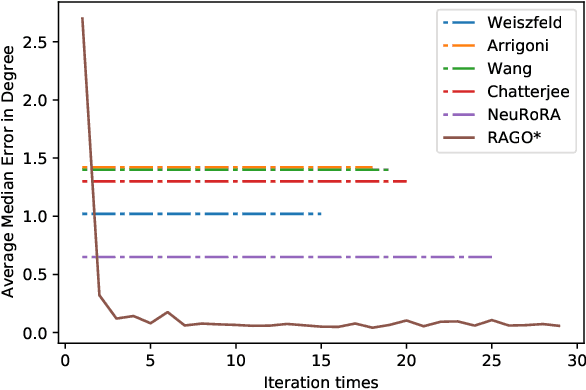
This paper proposes a deep recurrent Rotation Averaging Graph Optimizer (RAGO) for Multiple Rotation Averaging (MRA). Conventional optimization-based methods usually fail to produce accurate results due to corrupted and noisy relative measurements. Recent learning-based approaches regard MRA as a regression problem, while these methods are sensitive to initialization due to the gauge freedom problem. To handle these problems, we propose a learnable iterative graph optimizer minimizing a gauge-invariant cost function with an edge rectification strategy to mitigate the effect of inaccurate measurements. Our graph optimizer iteratively refines the global camera rotations by minimizing each node's single rotation objective function. Besides, our approach iteratively rectifies relative rotations to make them more consistent with the current camera orientations and observed relative rotations. Furthermore, we employ a gated recurrent unit to improve the result by tracing the temporal information of the cost graph. Our framework is a real-time learning-to-optimize rotation averaging graph optimizer with a tiny size deployed for real-world applications. RAGO outperforms previous traditional and deep methods on real-world and synthetic datasets. The code is available at https://github.com/sfu-gruvi-3dv/RAGO
* Accepted by CVPR 2022
DialogQAE: N-to-N Question Answer Pair Extraction from Customer Service Chatlog
Dec 14, 2022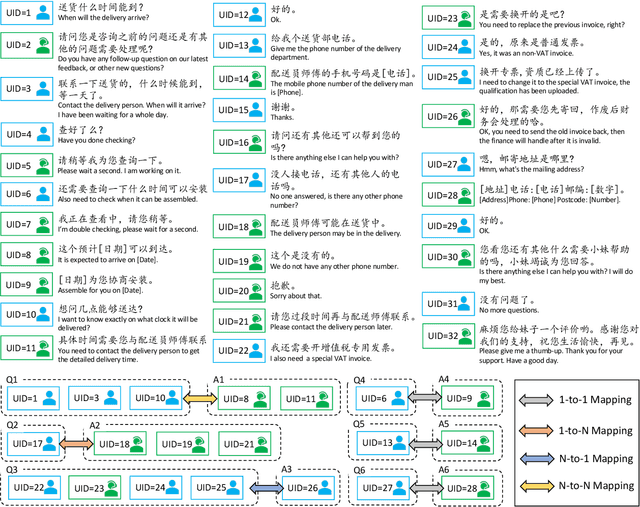
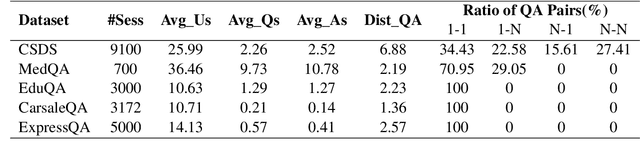

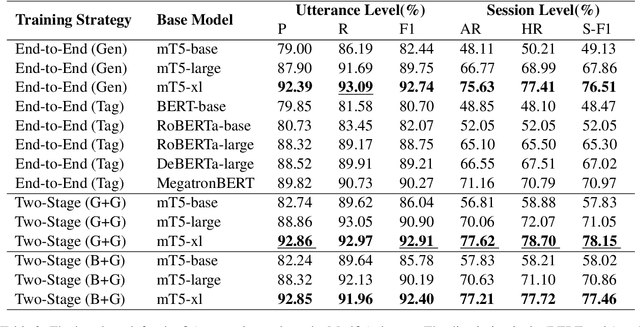
Harvesting question-answer (QA) pairs from customer service chatlog in the wild is an efficient way to enrich the knowledge base for customer service chatbots in the cold start or continuous integration scenarios. Prior work attempts to obtain 1-to-1 QA pairs from growing customer service chatlog, which fails to integrate the incomplete utterances from the dialog context for composite QA retrieval. In this paper, we propose N-to-N QA extraction task in which the derived questions and corresponding answers might be separated across different utterances. We introduce a suite of generative/discriminative tagging based methods with end-to-end and two-stage variants that perform well on 5 customer service datasets and for the first time setup a benchmark for N-to-N DialogQAE with utterance and session level evaluation metrics. With a deep dive into extracted QA pairs, we find that the relations between and inside the QA pairs can be indicators to analyze the dialogue structure, e.g. information seeking, clarification, barge-in and elaboration. We also show that the proposed models can adapt to different domains and languages, and reduce the labor cost of knowledge accumulation in the real-world product dialogue platform.
Multiclass classification utilising an estimated algorithmic probability prior
Dec 14, 2022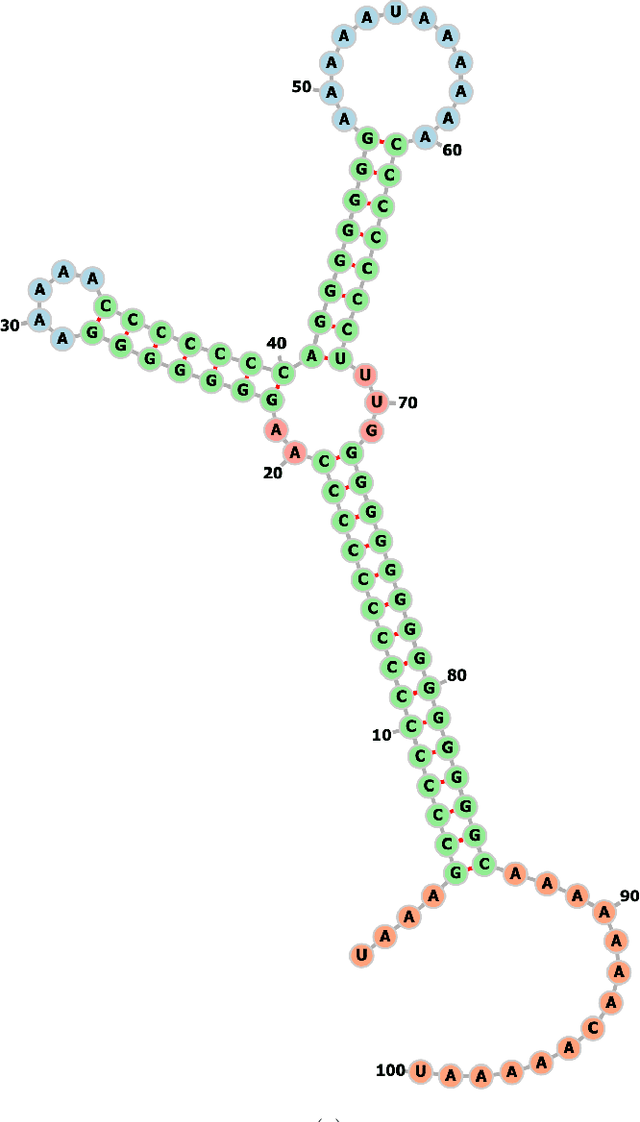
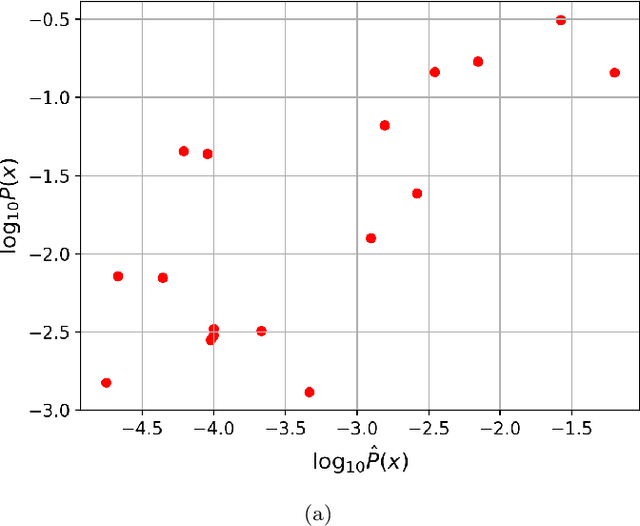
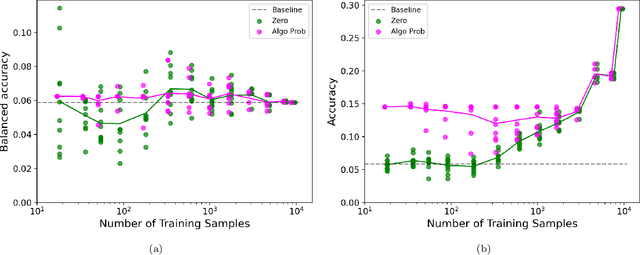
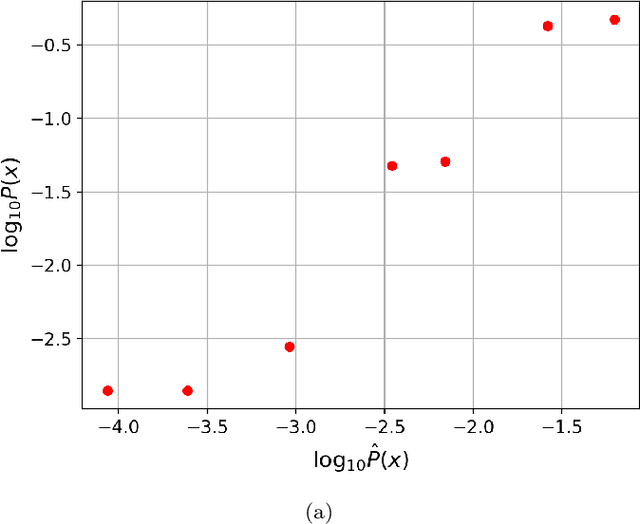
Methods of pattern recognition and machine learning are applied extensively in science, technology, and society. Hence, any advances in related theory may translate into large-scale impact. Here we explore how algorithmic information theory, especially algorithmic probability, may aid in a machine learning task. We study a multiclass supervised classification problem, namely learning the RNA molecule sequence-to-shape map, where the different possible shapes are taken to be the classes. The primary motivation for this work is a proof of concept example, where a concrete, well-motivated machine learning task can be aided by approximations to algorithmic probability. Our approach is based on directly estimating the class (i.e., shape) probabilities from shape complexities, and using the estimated probabilities as a prior in a Gaussian process learning problem. Naturally, with a large amount of training data, the prior has no significant influence on classification accuracy, but in the very small training data regime, we show that using the prior can substantially improve classification accuracy. To our knowledge, this work is one of the first to demonstrate how algorithmic probability can aid in a concrete, real-world, machine learning problem.
Learning useful representations for shifting tasks and distributions
Dec 14, 2022

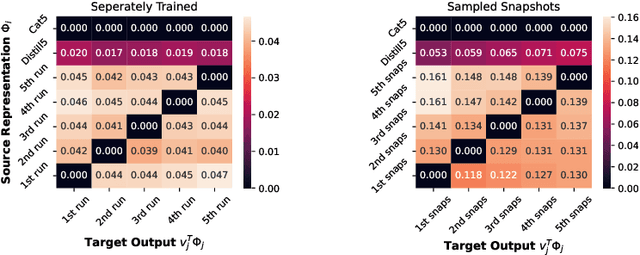
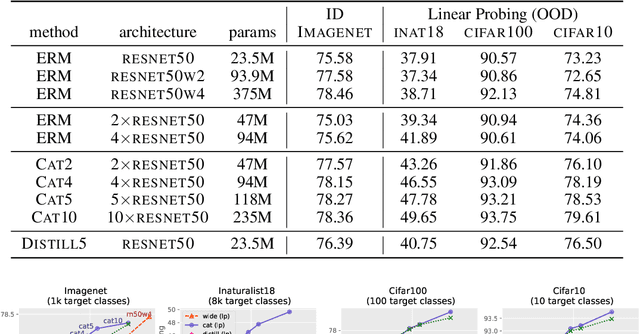
Does the dominant approach to learn representations (as a side effect of optimizing an expected cost for a single training distribution) remain a good approach when we are dealing with multiple distributions. Our thesis is that such scenarios are better served by representations that are "richer" than those obtained with a single optimization episode. This is supported by a collection of empirical results obtained with an apparently na\"ive ensembling technique: concatenating the representations obtained with multiple training episodes using the same data, model, algorithm, and hyper-parameters, but different random seeds. These independently trained networks perform similarly. Yet, in a number of scenarios involving new distributions, the concatenated representation performs substantially better than an equivalently sized network trained from scratch. This proves that the representations constructed by multiple training episodes are in fact different. Although their concatenation carries little additional information about the training task under the training distribution, it becomes substantially more informative when tasks or distributions change. Meanwhile, a single training episode is unlikely to yield such a redundant representation because the optimization process has no reason to accumulate features that do not incrementally improve the training performance.