 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Sharing Linkable Learning Objects with the use of Metadata and a Taxonomy Assistant for Categorization
Dec 09, 2022
In this work, a re-design of the Moodledata module functionalities is presented to share learning objects between e-learning content platforms, e.g., Moodle and G-Lorep, in a linkable object format. The e-learning courses content of the Drupal-based Content Management System G-Lorep for academic learning is exchanged designing an object incorporating metadata to support the reuse and the classification in its context. In such an Artificial Intelligence environment, the exchange of Linkable Learning Objects can be used for dialogue between Learning Systems to obtain information, especially with the use of semantic or structural similarity measures to enhance the existent Taxonomy Assistant for advanced automated classification.
MAViL: Masked Audio-Video Learners
Dec 15, 2022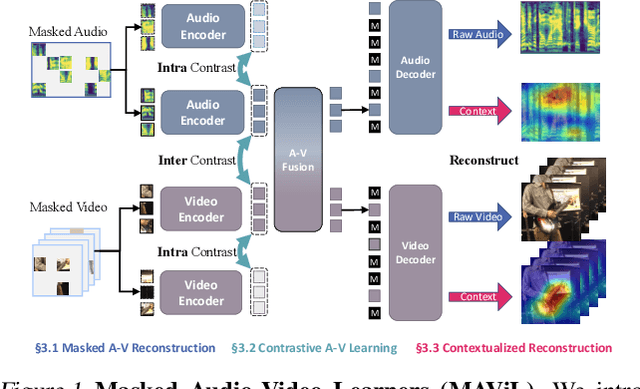



We present Masked Audio-Video Learners (MAViL) to train audio-visual representations. Our approach learns with three complementary forms of self-supervision: (1) reconstruction of masked audio and video input data, (2) intra- and inter-modal contrastive learning with masking, and (3) self-training by reconstructing joint audio-video contextualized features learned from the first two objectives. Pre-training with MAViL not only enables the model to perform well in audio-visual classification and retrieval tasks but also improves representations of each modality in isolation, without using information from the other modality for fine-tuning or inference. Empirically, MAViL sets a new state-of-the-art on AudioSet (53.1 mAP) and VGGSound (67.1% accuracy). For the first time, a self-supervised audio-visual model outperforms ones that use external supervision on these benchmarks. Code will be available soon.
Ungeneralizable Contextual Logistic Bandit in Credit Scoring
Dec 15, 2022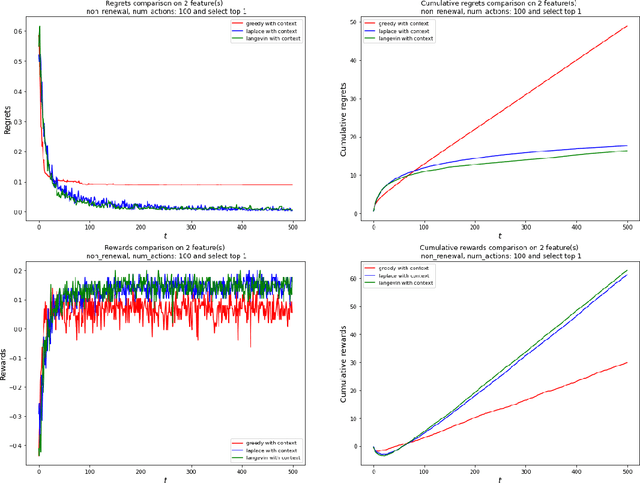
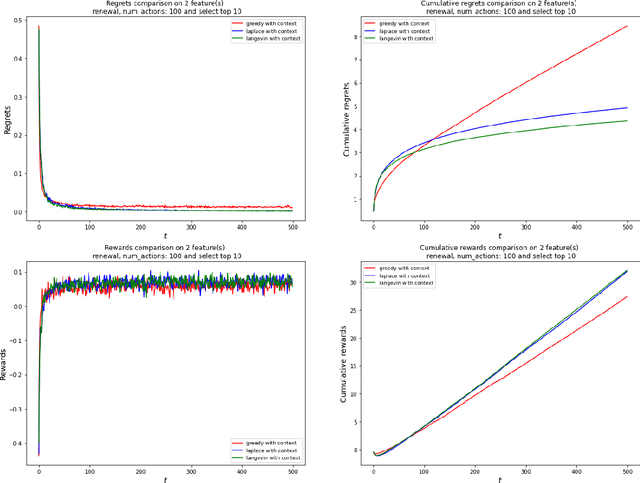
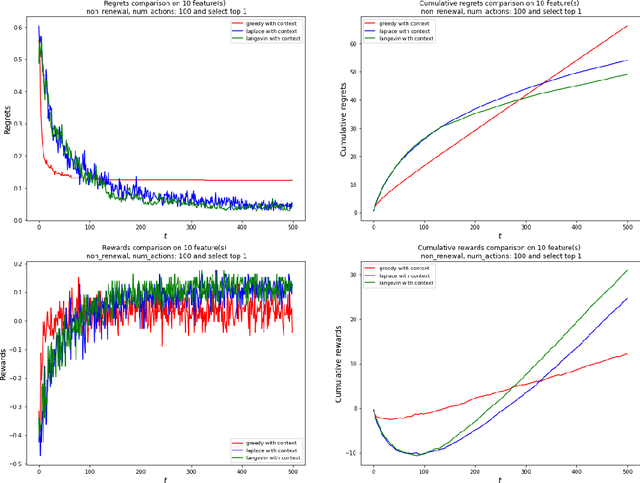
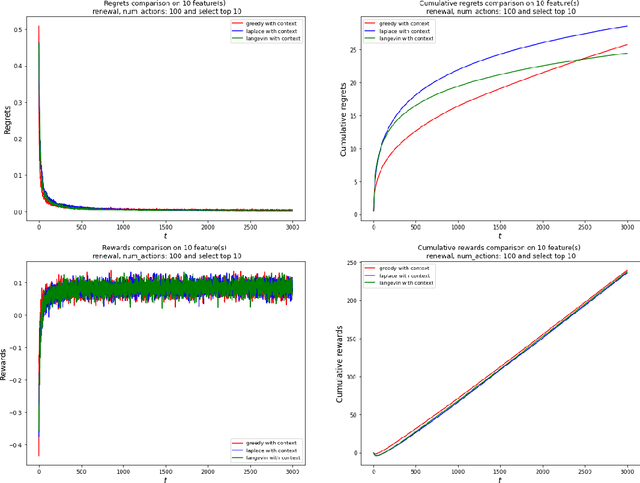
The application of reinforcement learning in credit scoring has created a unique setting for contextual logistic bandit that does not conform to the usual exploration-exploitation tradeoff but rather favors exploration-free algorithms. Through sufficient randomness in a pool of observable contexts, the reinforcement learning agent can simultaneously exploit an action with the highest reward while still learning more about the structure governing that environment. Thus, it is the case that greedy algorithms consistently outperform algorithms with efficient exploration, such as Thompson sampling. However, in a more pragmatic scenario in credit scoring, lenders can, to a degree, classify each borrower as a separate group, and learning about the characteristics of each group does not infer any information to another group. Through extensive simulations, we show that Thompson sampling dominates over greedy algorithms given enough timesteps which increase with the complexity of underlying features.
Multi-Level Association Rule Mining for Wireless Network Time Series Data
Dec 15, 2022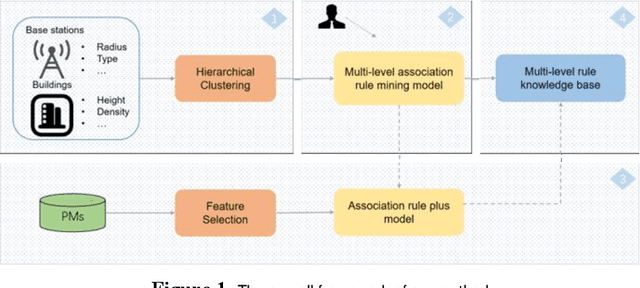
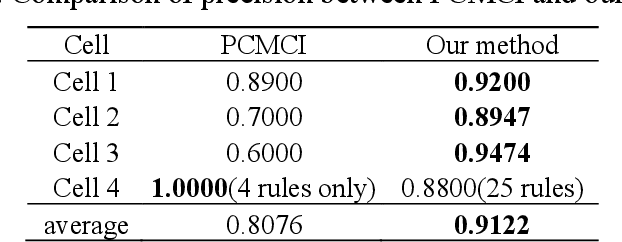
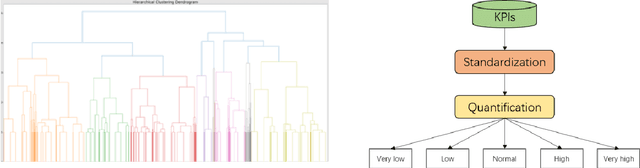
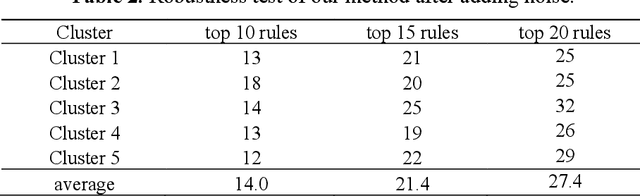
Key performance indicators(KPIs) are of great significance in the monitoring of wireless network service quality. The network service quality can be improved by adjusting relevant configuration parameters(CPs) of the base station. However, there are numerous CPs and different cells may affect each other, which bring great challenges to the association analysis of wireless network data. In this paper, we propose an adjustable multi-level association rule mining framework, which can quantitatively mine association rules at each level with environmental information, including engineering parameters and performance management(PMs), and it has interpretability at each level. Specifically, We first cluster similar cells, then quantify KPIs and CPs, and integrate expert knowledge into the association rule mining model, which improve the robustness of the model. The experimental results in real world dataset prove the effectiveness of our method.
DUIDD: Deep-Unfolded Interleaved Detection and Decoding for MIMO Wireless Systems
Dec 15, 2022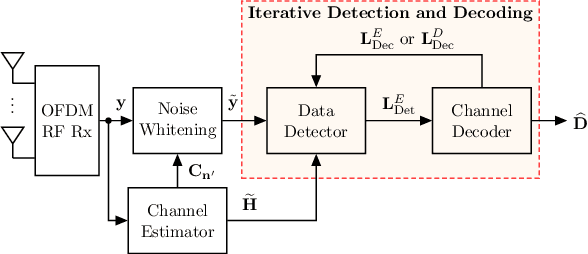
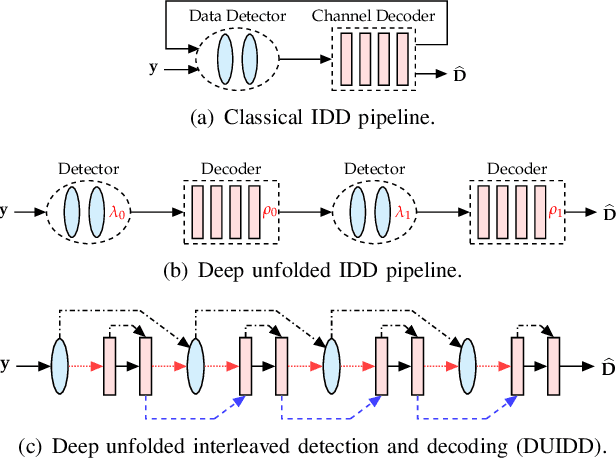
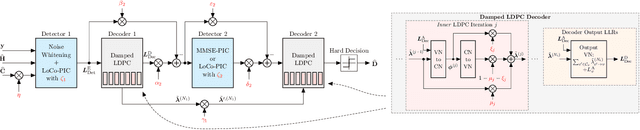
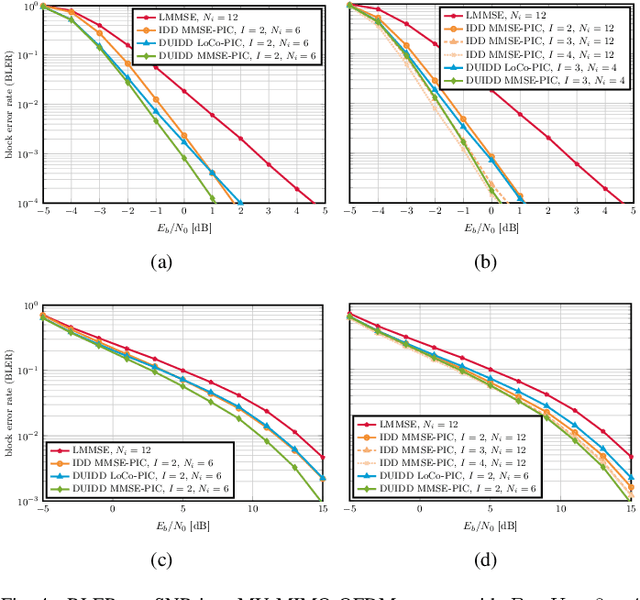
Iterative detection and decoding (IDD) is known to achieve near-capacity performance in multi-antenna wireless systems. We propose deep-unfolded interleaved detection and decoding (DUIDD), a new paradigm that reduces the complexity of IDD while achieving even lower error rates. DUIDD interleaves the inner stages of the data detector and channel decoder, which expedites convergence and reduces complexity. Furthermore, DUIDD applies deep unfolding to automatically optimize algorithmic hyperparameters, soft-information exchange, message damping, and state forwarding. We demonstrate the efficacy of DUIDD using NVIDIA's Sionna link-level simulator in a 5G-near multi-user MIMO-OFDM wireless system with a novel low-complexity soft-input soft-output data detector, an optimized low-density parity-check decoder, and channel vectors from a commercial ray-tracer. Our results show that DUIDD outperforms classical IDD both in terms of block error rate and computational complexity.
One Embedder, Any Task: Instruction-Finetuned Text Embeddings
Dec 20, 2022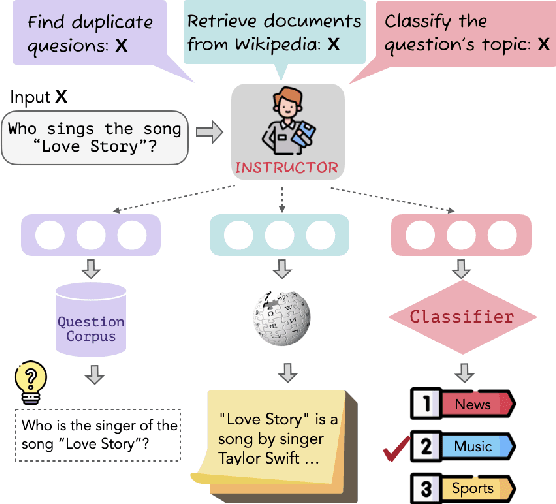
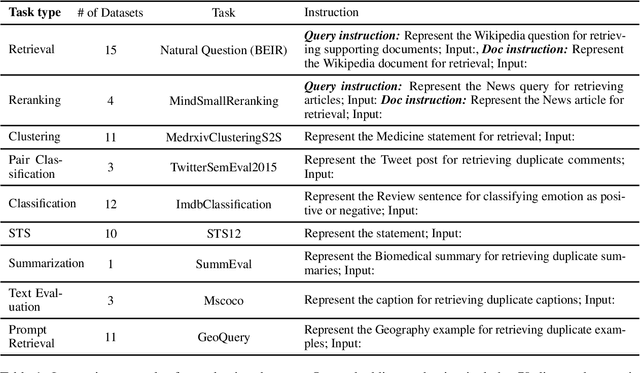
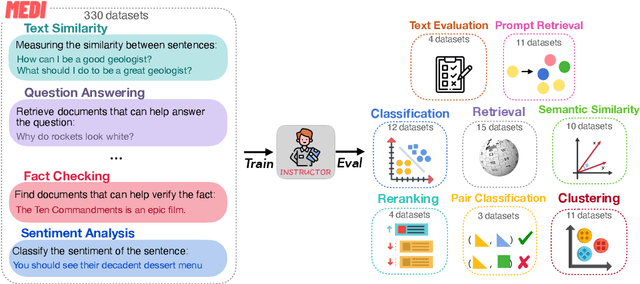
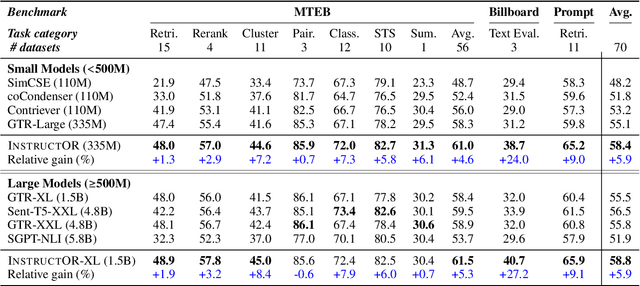
We introduce INSTRUCTOR, a new method for computing text embeddings given task instructions: every text input is embedded together with instructions explaining the use case (e.g., task and domain descriptions). Unlike encoders from prior work that are more specialized, INSTRUCTOR is a single embedder that can generate text embeddings tailored to different downstream tasks and domains, without any further training. We first annotate instructions for 330 diverse tasks and train INSTRUCTOR on this multitask mixture with a contrastive loss. We evaluate INSTRUCTOR on 70 embedding evaluation tasks (66 of which are unseen during training), ranging from classification and information retrieval to semantic textual similarity and text generation evaluation. INSTRUCTOR, while having an order of magnitude fewer parameters than the previous best model, achieves state-of-the-art performance, with an average improvement of 3.4% compared to the previous best results on the 70 diverse datasets. Our analysis suggests that INSTRUCTOR is robust to changes in instructions, and that instruction finetuning mitigates the challenge of training a single model on diverse datasets. Our model, code, and data are available at https://instructor-embedding.github.io.
On-the-fly Denoising for Data Augmentation in Natural Language Understanding
Dec 20, 2022
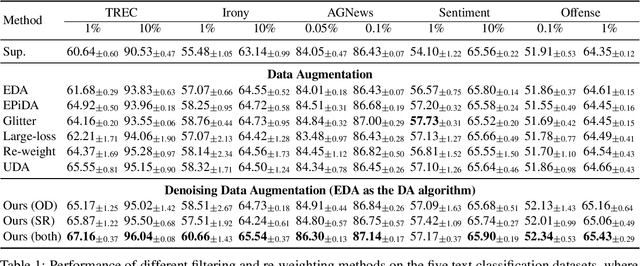
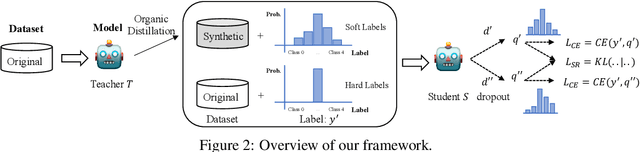
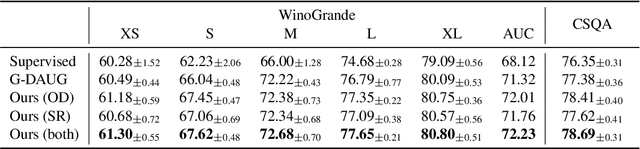
Data Augmentation (DA) is frequently used to automatically provide additional training data without extra human annotation. However, data augmentation may introduce noisy data that impairs training. To guarantee the quality of augmented data, existing methods either assume no noise exists in the augmented data and adopt consistency training or use simple heuristics such as training loss and diversity constraints to filter out ``noisy'' data. However, those filtered examples may still contain useful information, and dropping them completely causes loss of supervision signals. In this paper, based on the assumption that the original dataset is cleaner than the augmented data, we propose an on-the-fly denoising technique for data augmentation that learns from soft augmented labels provided by an organic teacher model trained on the cleaner original data. A simple self-regularization module is applied to force the model prediction to be consistent across two distinct dropouts to further prevent overfitting on noisy labels. Our method can be applied to augmentation techniques in general and can consistently improve the performance on both text classification and question-answering tasks.
Self-Pair: Synthesizing Changes from Single Source for Object Change Detection in Remote Sensing Imagery
Dec 20, 2022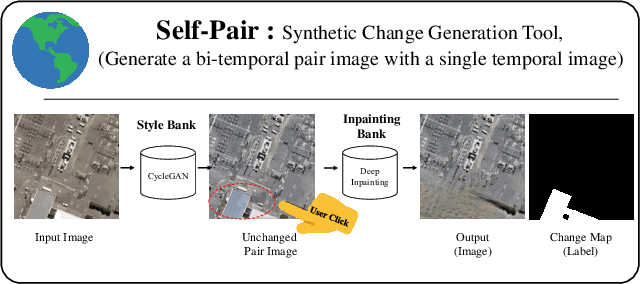
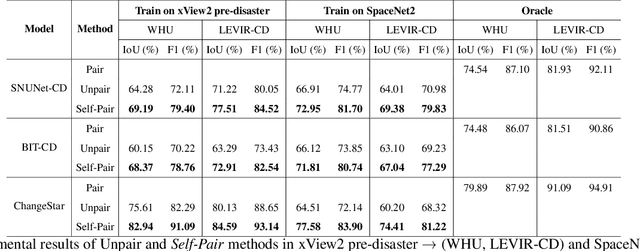
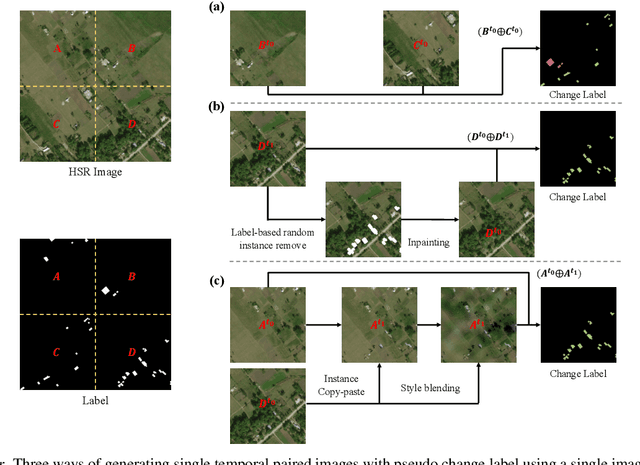
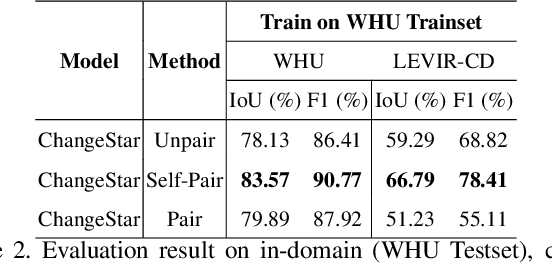
For change detection in remote sensing, constructing a training dataset for deep learning models is difficult due to the requirements of bi-temporal supervision. To overcome this issue, single-temporal supervision which treats change labels as the difference of two semantic masks has been proposed. This novel method trains a change detector using two spatially unrelated images with corresponding semantic labels such as building. However, training on unpaired datasets could confuse the change detector in the case of pixels that are labeled unchanged but are visually significantly different. In order to maintain the visual similarity in unchanged area, in this paper, we emphasize that the change originates from the source image and show that manipulating the source image as an after-image is crucial to the performance of change detection. Extensive experiments demonstrate the importance of maintaining visual information between pre- and post-event images, and our method outperforms existing methods based on single-temporal supervision. code is available at https://github.com/seominseok0429/Self-Pair-for-Change-Detection.
CoCoMIC: Code Completion By Jointly Modeling In-file and Cross-file Context
Dec 20, 2022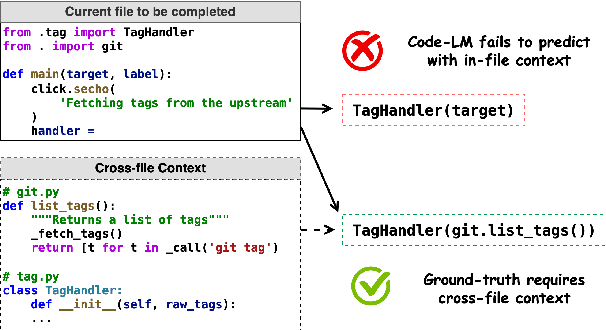
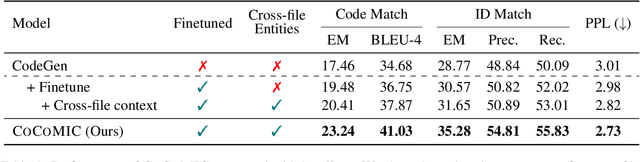
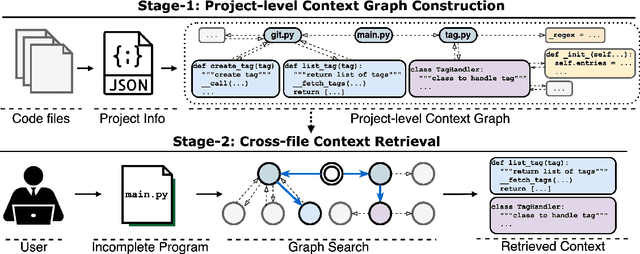
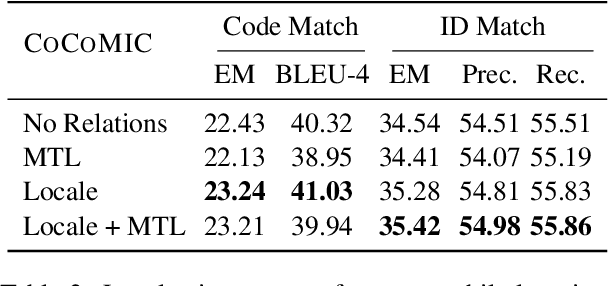
While pre-trained language models (LM) for code have achieved great success in code completion, they generate code conditioned only on the contents within the file, i.e., in-file context, but ignore the rich semantics in other files within the same project, i.e., cross-file context, a critical source of information that is especially useful in modern modular software development. Such overlooking constrains code language models' capacity in code completion, leading to unexpected behaviors such as generating hallucinated class member functions or function calls with unexpected arguments. In this work, we develop a cross-file context finder tool, CCFINDER, that effectively locates and retrieves the most relevant cross-file context. We propose CoCoMIC, a framework that incorporates cross-file context to learn the in-file and cross-file context jointly on top of pretrained code LMs. CoCoMIC successfully improves the existing code LM with a 19.30% relative increase in exact match and a 15.41% relative increase in identifier matching for code completion when the cross-file context is provided.
DialGuide: Aligning Dialogue Model Behavior with Developer Guidelines
Dec 20, 2022
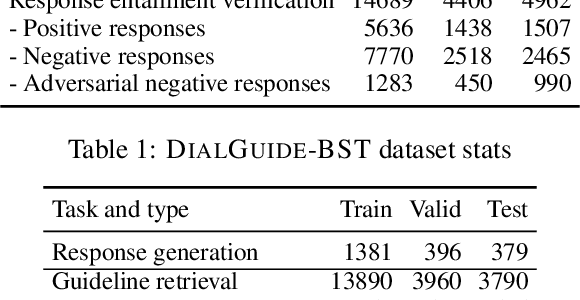
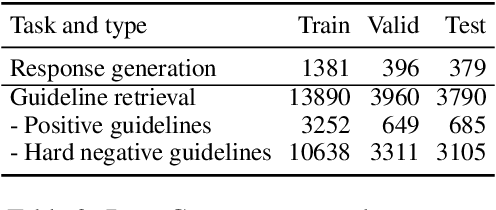
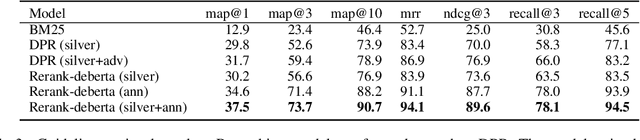
Dialogue models are able to generate coherent and fluent responses, but they can still be challenging to control and may produce non-engaging, unsafe results. This unpredictability diminishes user trust and can hinder the use of the models in the real world. To address this, we introduce DialGuide, a novel framework for controlling dialogue model behavior using natural language rules, or guidelines. These guidelines provide information about the context they are applicable to and what should be included in the response, allowing the models to generate responses that are more closely aligned with the developer's expectations and intent. We evaluate DialGuide on three tasks in open-domain dialogue response generation: guideline selection, response generation, and response entailment verification. Our dataset contains 10,737 positive and 15,467 negative dialogue context-response-guideline triplets across two domains - chit-chat and safety. We provide baseline models for the tasks and benchmark their performance. We also demonstrate that DialGuide is effective in the dialogue safety domain, producing safe and engaging responses that follow developer guidelines.