 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Impact of visual assistance for automated audio captioning
Nov 18, 2022
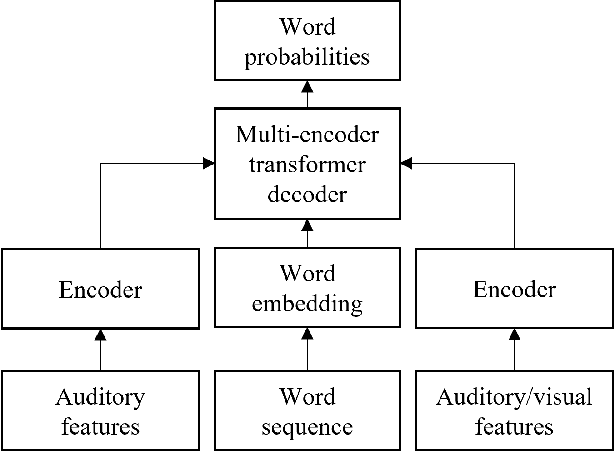
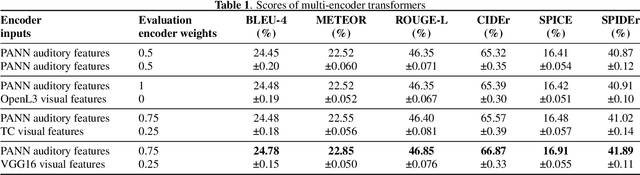
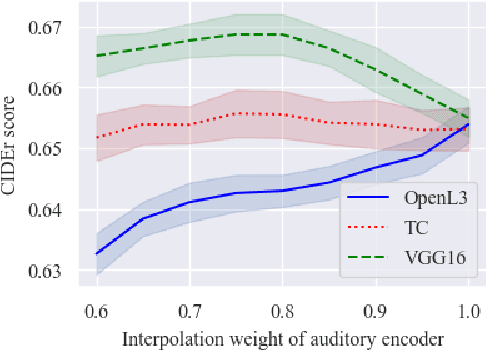
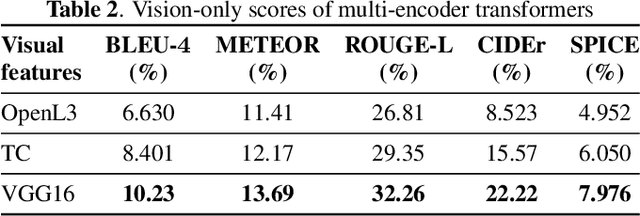
We study the impact of visual assistance for automated audio captioning. Utilizing multi-encoder transformer architectures, which have previously been employed to introduce vision-related information in the context of sound event detection, we analyze the usefulness of incorporating a variety of pretrained features. We perform experiments on a YouTube-based audiovisual data set and investigate the effect of applying the considered transfer learning technique in terms of a variety of captioning metrics. We find that only one of the considered kinds of pretrained features provides consistent improvements, while the others do not provide any noteworthy gains at all. Interestingly, the outcomes of prior research efforts indicate that the exact opposite is true in the case of sound event detection, leading us to conclude that the optimal choice of visual embeddings is strongly dependent on the task at hand. More specifically, visual features focusing on semantics appear appropriate in the context of automated audio captioning, while for sound event detection, time information seems to be more important.
Refined Semantic Enhancement towards Frequency Diffusion for Video Captioning
Dec 18, 2022
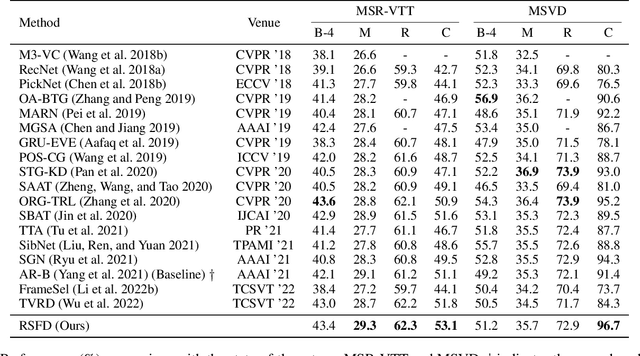
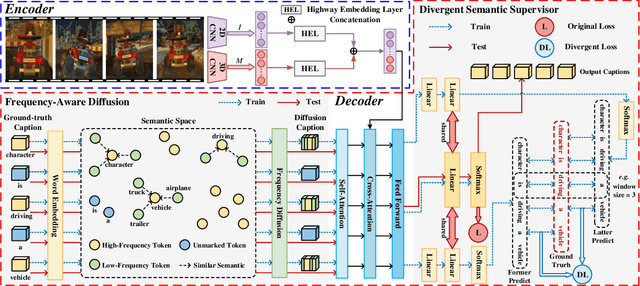
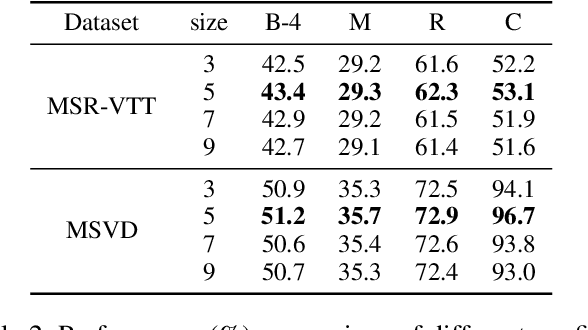
Video captioning aims to generate natural language sentences that describe the given video accurately. Existing methods obtain favorable generation by exploring richer visual representations in encode phase or improving the decoding ability. However, the long-tailed problem hinders these attempts at low-frequency tokens, which rarely occur but carry critical semantics, playing a vital role in the detailed generation. In this paper, we introduce a novel Refined Semantic enhancement method towards Frequency Diffusion (RSFD), a captioning model that constantly perceives the linguistic representation of the infrequent tokens. Concretely, a Frequency-Aware Diffusion (FAD) module is proposed to comprehend the semantics of low-frequency tokens to break through generation limitations. In this way, the caption is refined by promoting the absorption of tokens with insufficient occurrence. Based on FAD, we design a Divergent Semantic Supervisor (DSS) module to compensate for the information loss of high-frequency tokens brought by the diffusion process, where the semantics of low-frequency tokens is further emphasized to alleviate the long-tailed problem. Extensive experiments indicate that RSFD outperforms the state-of-the-art methods on two benchmark datasets, i.e., MSR-VTT and MSVD, demonstrate that the enhancement of low-frequency tokens semantics can obtain a competitive generation effect. Code is available at https://github.com/lzp870/RSFD.
DeepCut: Unsupervised Segmentation using Graph Neural Networks Clustering
Dec 18, 2022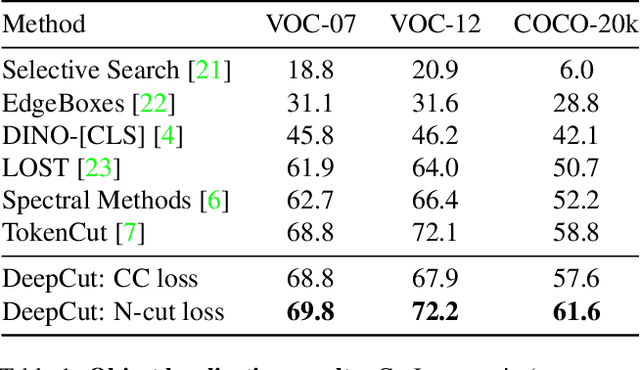
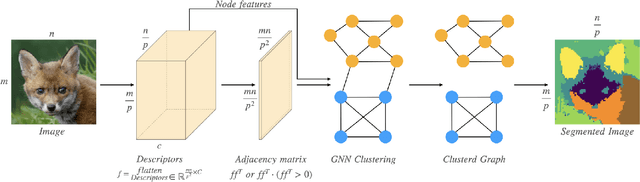
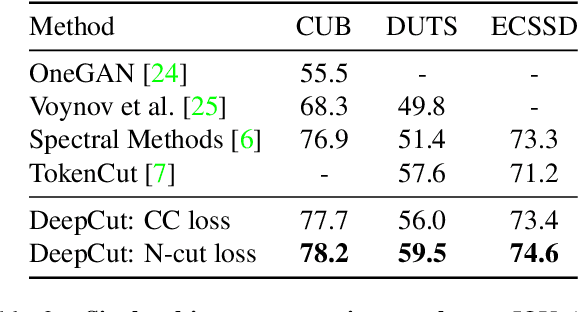

Image segmentation is a fundamental task in computer vision. Data annotation for training supervised methods can be labor-intensive, motivating unsupervised methods. Some existing approaches extract deep features from pre-trained networks and build a graph to apply classical clustering methods (e.g., $k$-means and normalized-cuts) as a post-processing stage. These techniques reduce the high-dimensional information encoded in the features to pair-wise scalar affinities. In this work, we replace classical clustering algorithms with a lightweight Graph Neural Network (GNN) trained to achieve the same clustering objective function. However, in contrast to existing approaches, we feed the GNN not only the pair-wise affinities between local image features but also the raw features themselves. Maintaining this connection between the raw feature and the clustering goal allows to perform part semantic segmentation implicitly, without requiring additional post-processing steps. We demonstrate how classical clustering objectives can be formulated as self-supervised loss functions for training our image segmentation GNN. Additionally, we use the Correlation-Clustering (CC) objective to perform clustering without defining the number of clusters ($k$-less clustering). We apply the proposed method for object localization, segmentation, and semantic part segmentation tasks, surpassing state-of-the-art performance on multiple benchmarks.
Curriculum Sampling for Dense Retrieval with Document Expansion
Dec 18, 2022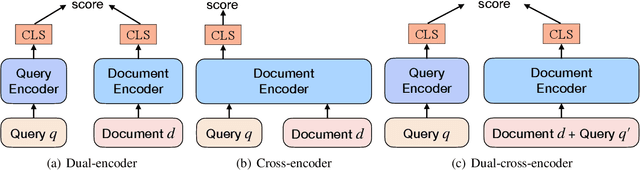
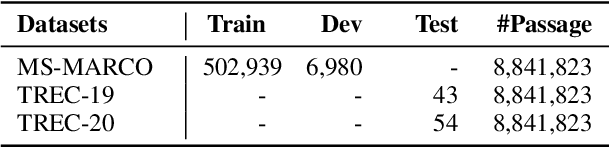
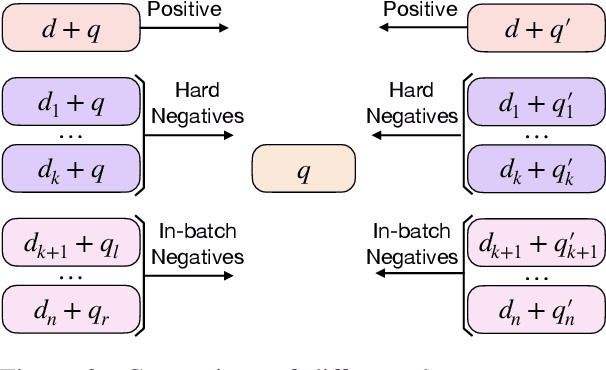
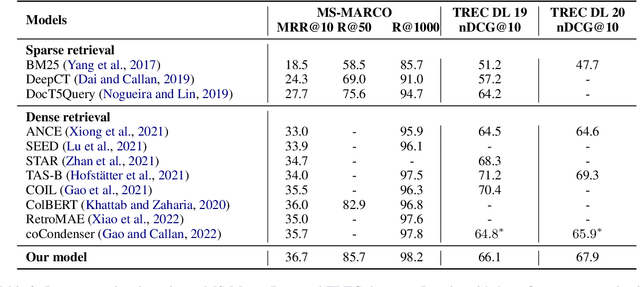
The dual-encoder has become the de facto architecture for dense retrieval. Typically, it computes the latent representations of the query and document independently, thus failing to fully capture the interactions between the query and document. To alleviate this, recent work expects to get query-informed representations of documents. During training, it expands the document with a real query, while replacing the real query with a generated pseudo query at inference. This discrepancy between training and inference makes the dense retrieval model pay more attention to the query information but ignore the document when computing the document representation. As a result, it even performs worse than the vanilla dense retrieval model, since its performance depends heavily on the relevance between the generated queries and the real query. In this paper, we propose a curriculum sampling strategy, which also resorts to the pseudo query at training and gradually increases the relevance of the generated query to the real query. In this way, the retrieval model can learn to extend its attention from the document only to both the document and query, hence getting high-quality query-informed document representations. Experimental results on several passage retrieval datasets show that our approach outperforms the previous dense retrieval methods1.
PoE: a Panel of Experts for Generalized Automatic Dialogue Assessment
Dec 18, 2022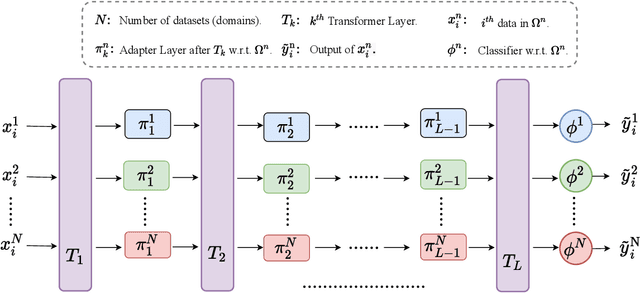
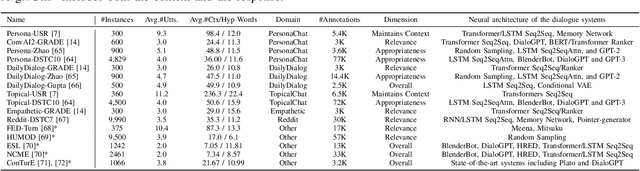
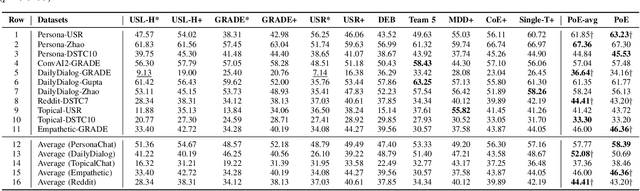
Chatbots are expected to be knowledgeable across multiple domains, e.g. for daily chit-chat, exchange of information, and grounding in emotional situations. To effectively measure the quality of such conversational agents, a model-based automatic dialogue evaluation metric (ADEM) is expected to perform well across multiple domains. Despite significant progress, an ADEM that works well in one domain does not necessarily generalize to another. This calls for a dedicated network architecture for domain generalization. To tackle the multi-domain dialogue evaluation task, we propose a Panel of Experts (PoE), a multitask network that consists of a shared transformer encoder and a collection of lightweight adapters. The shared encoder captures the general knowledge of dialogues across domains, while each adapter specializes in one specific domain and serves as a domain expert. To validate the idea, we construct a high-quality multi-domain dialogue dataset leveraging data augmentation and pseudo-labeling. The PoE network is comprehensively assessed on 16 dialogue evaluation datasets spanning a wide range of dialogue domains. It achieves state-of-the-art performance in terms of mean Spearman correlation over all the evaluation datasets. It exhibits better zero-shot generalization than existing state-of-the-art ADEMs and the ability to easily adapt to new domains with few-shot transfer learning.
Zero-shot Image Captioning by Anchor-augmented Vision-Language Space Alignment
Nov 14, 2022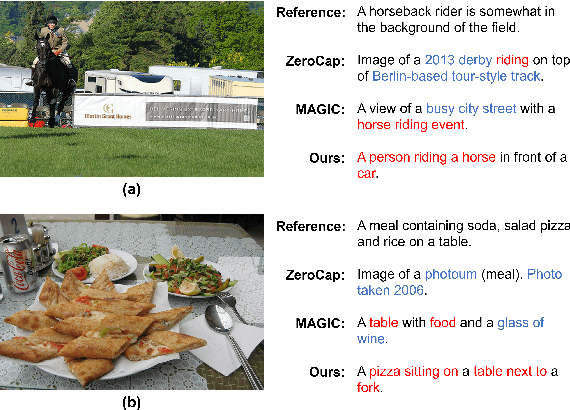
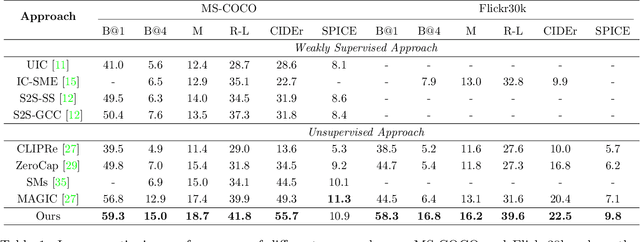
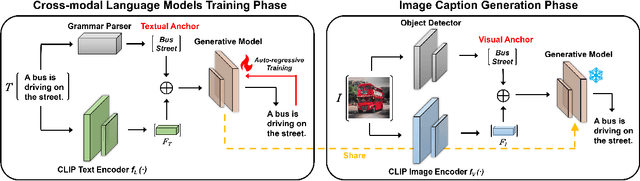

CLIP (Contrastive Language-Image Pre-Training) has shown remarkable zero-shot transfer capabilities in cross-modal correlation tasks such as visual classification and image retrieval. However, its performance in cross-modal generation tasks like zero-shot image captioning remains unsatisfied. In this work, we discuss that directly employing CLIP for zero-shot image captioning relies more on the textual modality in context and largely ignores the visual information, which we call \emph{contextual language prior}. To address this, we propose Cross-modal Language Models (CLMs) to facilitate unsupervised cross-modal learning. We further propose Anchor Augment to guide the generative model's attention to the fine-grained information in the representation of CLIP. Experiments on MS COCO and Flickr 30K validate the promising performance of proposed approach in both captioning quality and computational efficiency.
Noisy Group Testing with Side Information
Feb 24, 2022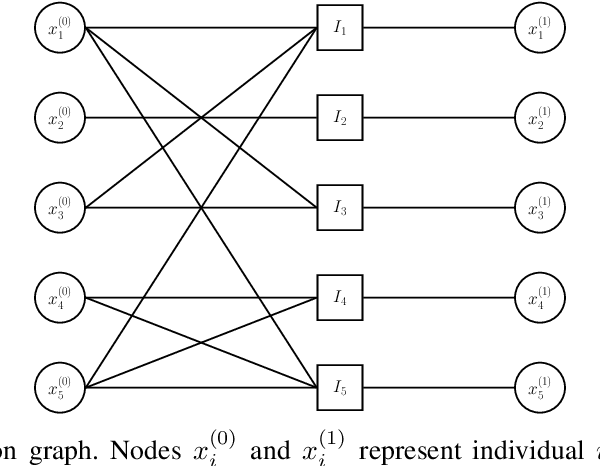
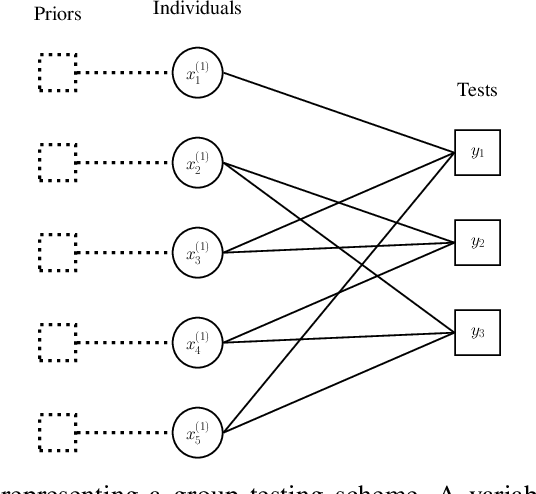
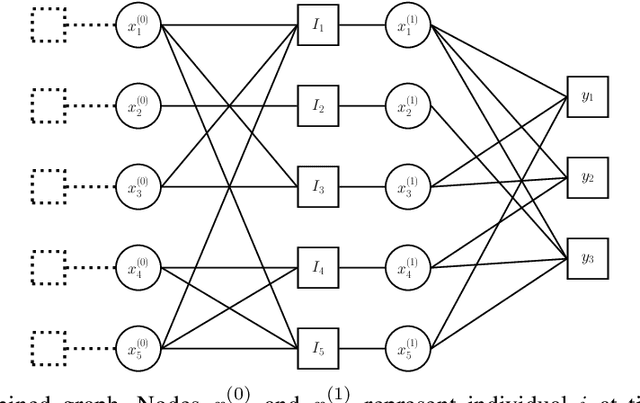
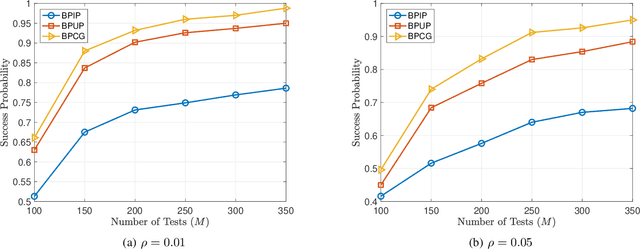
Group testing has recently attracted significant attention from the research community due to its applications in diagnostic virology. An instance of the group testing problem includes a ground set of individuals which includes a small subset of infected individuals. The group testing procedure consists of a number of tests, such that each test indicates whether or not a given subset of individuals includes one or more infected individuals. The goal of the group testing procedure is to identify the subset of infected individuals with the minimum number of tests. Motivated by practical scenarios, such as testing for viral diseases, this paper focuses on the following group testing settings: (i) the group testing procedure is noisy, i.e., the outcome of the group testing procedure can be flipped with a certain probability; (ii) there is a certain amount of side information on the distribution of the infected individuals available to the group testing algorithm. The paper makes the following contributions. First, we propose a probabilistic model, referred to as an interaction model, that captures the side information about the probability distribution of the infected individuals. Next, we present a decoding scheme, based on the belief propagation, that leverages the interaction model to improve the decoding accuracy. Our results indicate that the proposed algorithm achieves higher success probability and lower false-negative and false-positive rates when compared to the traditional belief propagation especially in the high noise regime.
Pivotal Role of Language Modeling in Recommender Systems: Enriching Task-specific and Task-agnostic Representation Learning
Dec 07, 2022
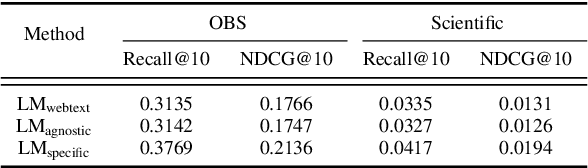

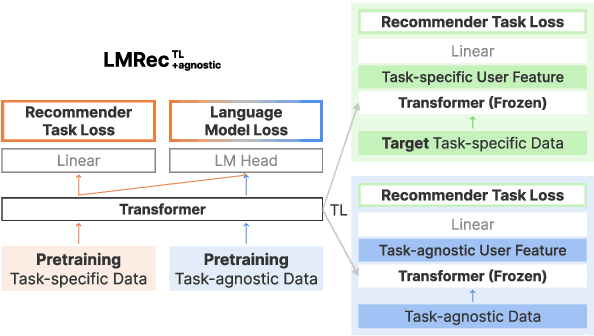
Recent studies have proposed a unified user modeling framework that leverages user behavior data from various applications. Most benefit from utilizing users' behavior sequences as plain texts, representing rich information in any domain or system without losing generality. Hence, a question arises: Can language modeling for user history corpus help improve recommender systems? While its versatile usability has been widely investigated in many domains, its applications to recommender systems still remain underexplored. We show that language modeling applied directly to task-specific user histories achieves excellent results on diverse recommendation tasks. Also, leveraging additional task-agnostic user histories delivers significant performance benefits. We further demonstrate that our approach can provide promising transfer learning capabilities for a broad spectrum of real-world recommender systems, even on unseen domains and services.
Span-based joint entity and relation extraction augmented with sequence tagging mechanism
Oct 23, 2022
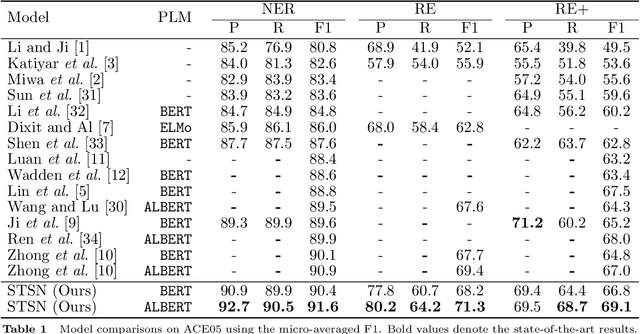
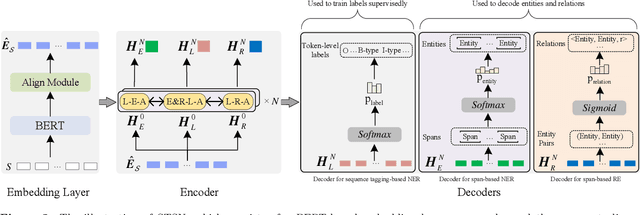
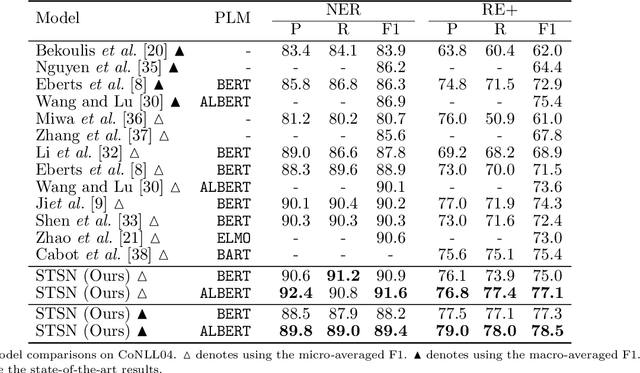
Span-based joint extraction simultaneously conducts named entity recognition (NER) and relation extraction (RE) in text span form. However, since previous span-based models rely on span-level classifications, they cannot benefit from token-level label information, which has been proven advantageous for the task. In this paper, we propose a Sequence Tagging augmented Span-based Network (STSN), a span-based joint model that can make use of token-level label information. In STSN, we construct a core neural architecture by deep stacking multiple attention layers, each of which consists of three basic attention units. On the one hand, the core architecture enables our model to learn token-level label information via the sequence tagging mechanism and then uses the information in the span-based joint extraction; on the other hand, it establishes a bi-directional information interaction between NER and RE. Experimental results on three benchmark datasets show that STSN consistently outperforms the strongest baselines in terms of F1, creating new state-of-the-art results.
A Unified Approach to Semantic Information and Communication based on Probabilistic Logic
May 02, 2022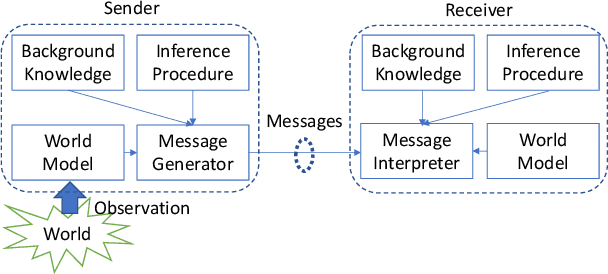
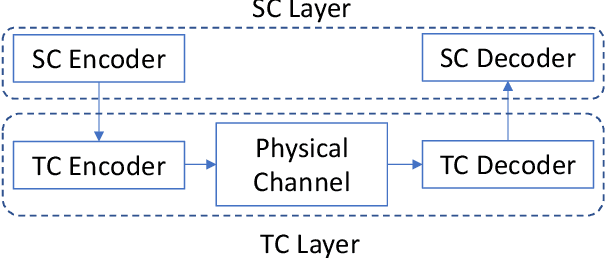
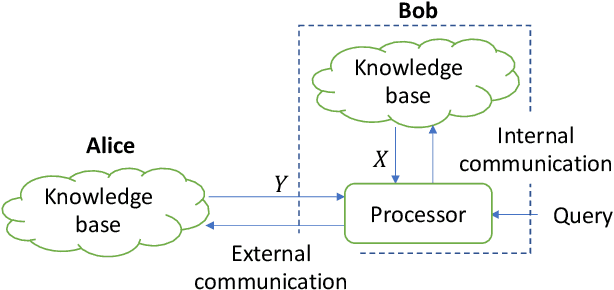
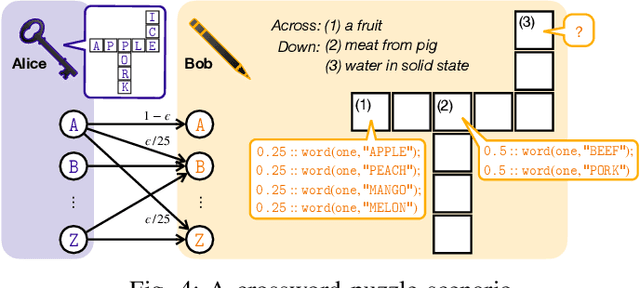
Traditionally, studies on technical communication (TC) are based on stochastic modeling and manipulation. This is not sufficient for semantic communication (SC) where semantic elements are logically connected, rather than stochastically correlated. To fill this void, by leveraging a logical programming language called probabilistic logic (ProbLog), we propose a unified approach to semantic information and communication through the interplay between TC and SC. On top of the well-established existing TC layer, we introduce a SC layer that utilizes knowledge bases of communicating parties for the exchange of semantic information. These knowledge bases are logically described, manipulated, and exploited using ProbLog. To make these SC and TC layers interact, we propose various measures based on the entropy of a clause in a knowledge base. These measures allow us to delineate various technical issues on SC such as a message selection problem for improving the knowledge base at a receiver. Extending this, we showcase selected examples in which SC and TC layers interact with each other while taking into account constraints on physical channels and efficiently utilizing channel resources.