 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Timing-Based Backpropagation in Spiking Neural Networks Without Single-Spike Restrictions
Nov 29, 2022
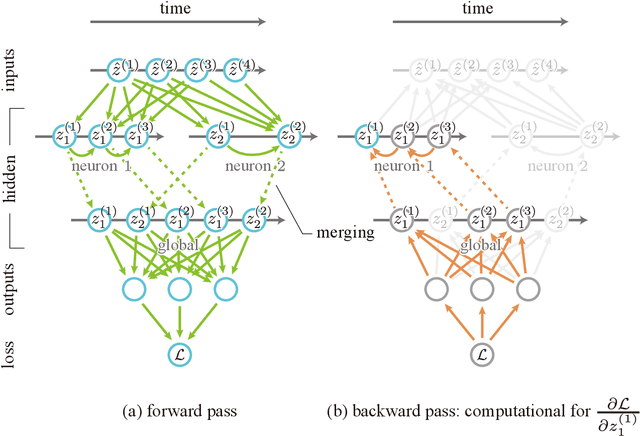
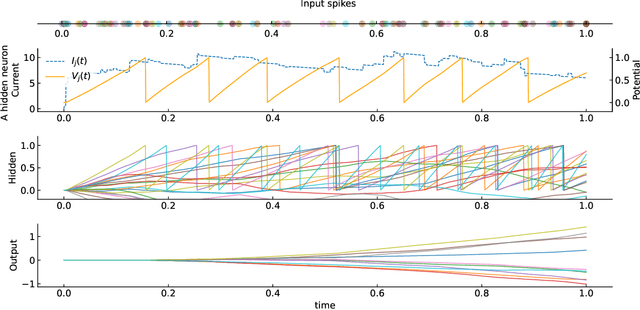
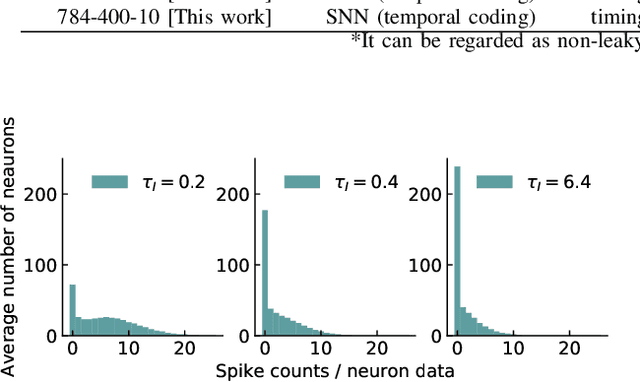
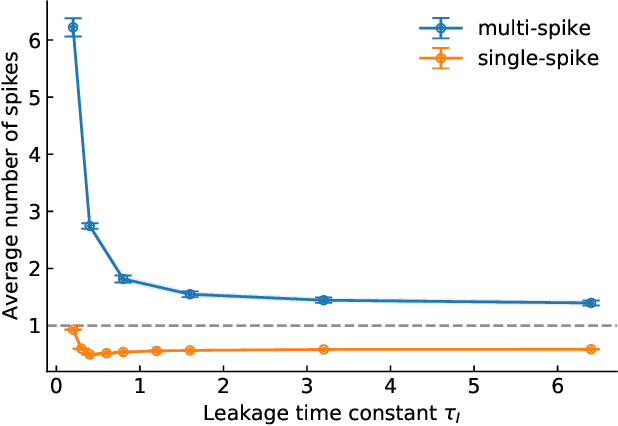
We propose a novel backpropagation algorithm for training spiking neural networks (SNNs) that encodes information in the relative multiple spike timing of individual neurons without single-spike restrictions. The proposed algorithm inherits the advantages of conventional timing-based methods in that it computes accurate gradients with respect to spike timing, which promotes ideal temporal coding. Unlike conventional methods where each neuron fires at most once, the proposed algorithm allows each neuron to fire multiple times. This extension naturally improves the computational capacity of SNNs. Our SNN model outperformed comparable SNN models and achieved as high accuracy as non-convolutional artificial neural networks. The spike count property of our networks was altered depending on the time constant of the postsynaptic current and the membrane potential. Moreover, we found that there existed the optimal time constant with the maximum test accuracy. That was not seen in conventional SNNs with single-spike restrictions on time-to-fast-spike (TTFS) coding. This result demonstrates the computational properties of SNNs that biologically encode information into the multi-spike timing of individual neurons. Our code would be publicly available.
Every Node Counts: Improving the Training of Graph Neural Networks on Node Classification
Nov 29, 2022
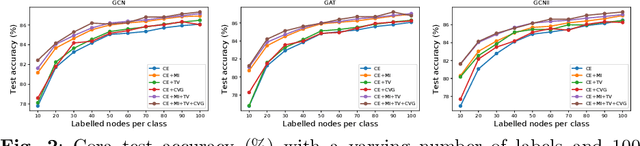

Graph Neural Networks (GNNs) are prominent in handling sparse and unstructured data efficiently and effectively. Specifically, GNNs were shown to be highly effective for node classification tasks, where labelled information is available for only a fraction of the nodes. Typically, the optimization process, through the objective function, considers only labelled nodes while ignoring the rest. In this paper, we propose novel objective terms for the training of GNNs for node classification, aiming to exploit all the available data and improve accuracy. Our first term seeks to maximize the mutual information between node and label features, considering both labelled and unlabelled nodes in the optimization process. Our second term promotes anisotropic smoothness in the prediction maps. Lastly, we propose a cross-validating gradients approach to enhance the learning from labelled data. Our proposed objectives are general and can be applied to various GNNs and require no architectural modifications. Extensive experiments demonstrate our approach using popular GNNs like GCN, GAT and GCNII, reading a consistent and significant accuracy improvement on 10 real-world node classification datasets.
Bayesian data fusion with shared priors
Dec 14, 2022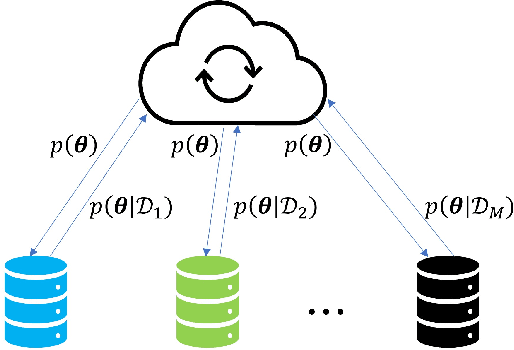

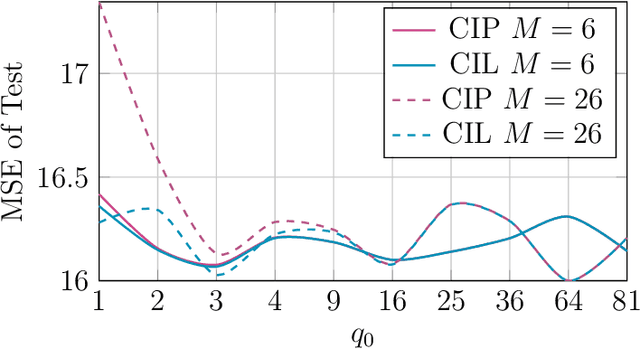
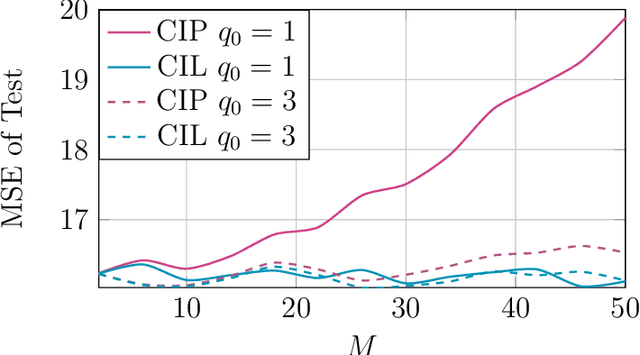
The integration of data and knowledge from several sources is known as data fusion. When data is available in a distributed fashion or when different sensors are used to infer a quantity of interest, data fusion becomes essential. In Bayesian settings, a priori information of the unknown quantities is available and, possibly, shared among the distributed estimators. When the local estimates are fused, such prior might be overused unless it is accounted for. This paper explores the effects of shared priors in Bayesian data fusion contexts, providing fusion rules and analysis to understand the performance of such fusion as a function of the number of collaborative agents and the uncertainty of the priors. Analytical results are corroborated through experiments in a variety of estimation and classification problems.
Building Multilingual Corpora for a Complex Named Entity Recognition and Classification Hierarchy using Wikipedia and DBpedia
Dec 14, 2022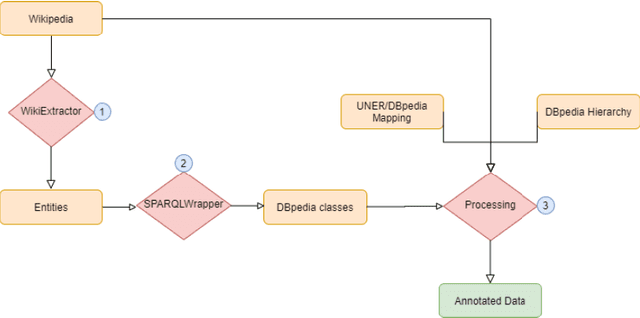
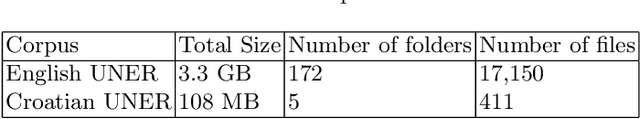
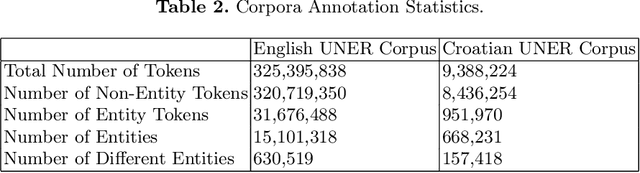
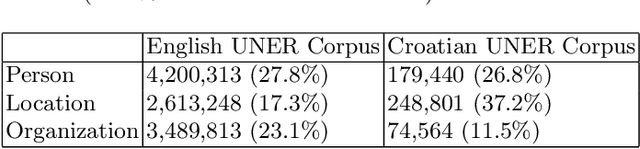
With the ever-growing popularity of the field of NLP, the demand for datasets in low resourced-languages follows suit. Following a previously established framework, in this paper, we present the UNER dataset, a multilingual and hierarchical parallel corpus annotated for named-entities. We describe in detail the developed procedure necessary to create this type of dataset in any language available on Wikipedia with DBpedia information. The three-step procedure extracts entities from Wikipedia articles, links them to DBpedia, and maps the DBpedia sets of classes to the UNER labels. This is followed by a post-processing procedure that significantly increases the number of identified entities in the final results. The paper concludes with a statistical and qualitative analysis of the resulting dataset.
NeighborTrack: Improving Single Object Tracking by Bipartite Matching with Neighbor Tracklets
Nov 12, 2022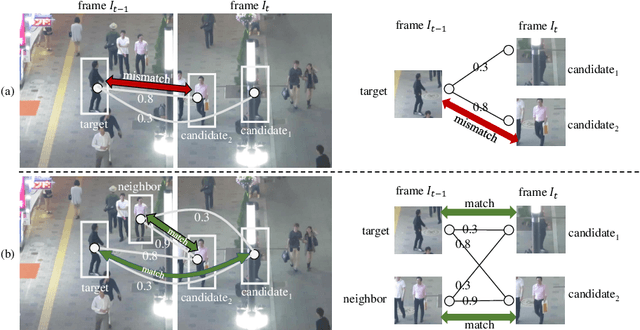

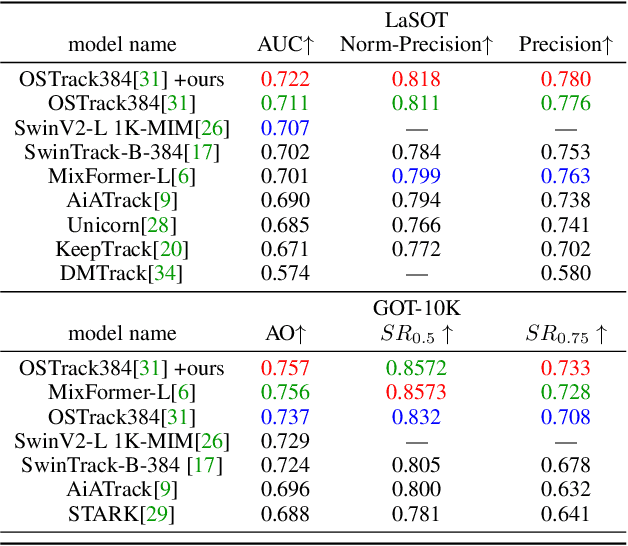
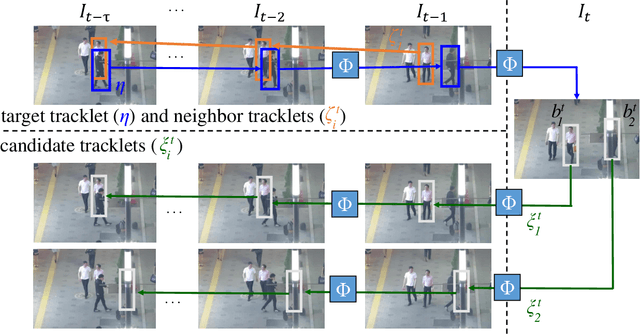
We propose a post-processor, called NeighborTrack, that leverages neighbor information of the tracking target to validate and improve single-object tracking (SOT) results. It requires no additional data or retraining. Instead, it uses the confidence score predicted by the backbone SOT network to automatically derive neighbor information and then uses this information to improve the tracking results. When tracking an occluded target, its appearance features are untrustworthy. However, a general siamese network often cannot tell whether the tracked object is occluded by reading the confidence score alone, because it could be misled by neighbors with high confidence scores. Our proposed NeighborTrack takes advantage of unoccluded neighbors' information to reconfirm the tracking target and reduces false tracking when the target is occluded. It not only reduces the impact caused by occlusion, but also fixes tracking problems caused by object appearance changes. NeighborTrack is agnostic to SOT networks and post-processing methods. For the VOT challenge dataset commonly used in short-term object tracking, we improve three famous SOT networks, Ocean, TransT, and OSTrack, by an average of ${1.92\%}$ EAO and ${2.11\%}$ robustness. For the mid- and long-term tracking experiments based on OSTrack, we achieve state-of-the-art ${72.25\%}$ AUC on LaSOT and ${75.7\%}$ AO on GOT-10K.
STN: a new tensor network method to identify stimulus category from brain activity pattern
Nov 03, 2022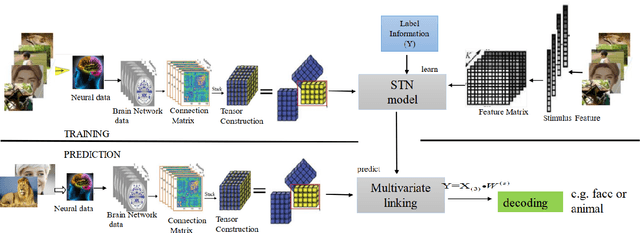
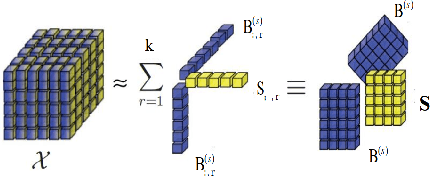

Neural decoding is still a challenge and hot topic in neurocomputing science. Recently, many studies have shown that brain network pattern containing rich spatial and temporal structure information, which represented the activation information of brain under external stimuli. The traditional method is to extract brain network features directly from the common machine learning method, then put these features into the classifier, and realize to decode external stimuli. However, this method cannot effectively extract the multi-dimensional structural information, which is hidden in the brain network. The tensor researchers show that the tensor decomposition model can fully mine unique spatio-temporal structure characteristics in multi-dimensional structure data. This research proposed a stimulus constrain tensor brain model(STN), which involved the tensor decomposition idea and stimulus category constraint information. The model was verified on the real neuroimaging data sets (MEG and fMRI). The experimental results show that the STN model achieved more 11.06% and 18.46% compared with others methods on two modal data sets. These results imply the superiority of extracting discriminative characteristics about STN model, especially for decoding object stimuli with semantic information.
Polarimetric Multi-View Inverse Rendering
Dec 24, 2022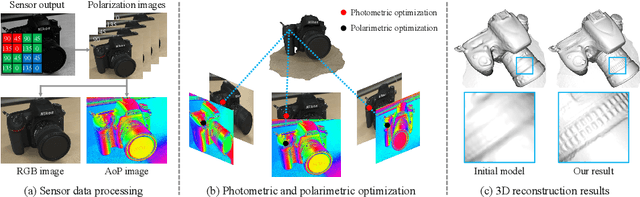
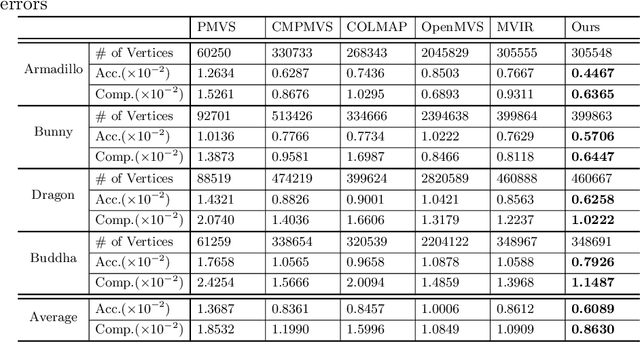
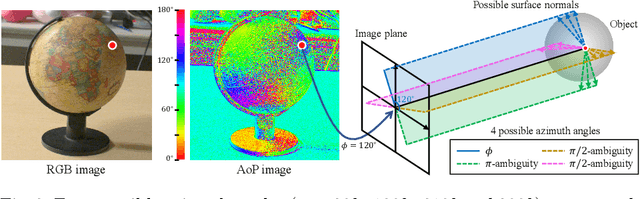
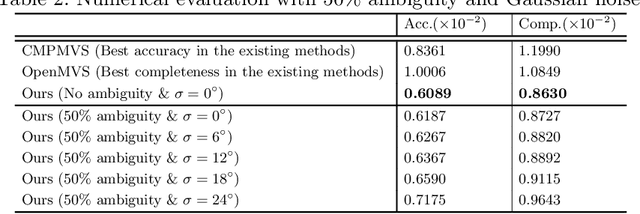
A polarization camera has great potential for 3D reconstruction since the angle of polarization (AoP) and the degree of polarization (DoP) of reflected light are related to an object's surface normal. In this paper, we propose a novel 3D reconstruction method called Polarimetric Multi-View Inverse Rendering (Polarimetric MVIR) that effectively exploits geometric, photometric, and polarimetric cues extracted from input multi-view color-polarization images. We first estimate camera poses and an initial 3D model by geometric reconstruction with a standard structure-from-motion and multi-view stereo pipeline. We then refine the initial model by optimizing photometric rendering errors and polarimetric errors using multi-view RGB, AoP, and DoP images, where we propose a novel polarimetric cost function that enables an effective constraint on the estimated surface normal of each vertex, while considering four possible ambiguous azimuth angles revealed from the AoP measurement. The weight for the polarimetric cost is effectively determined based on the DoP measurement, which is regarded as the reliability of polarimetric information. Experimental results using both synthetic and real data demonstrate that our Polarimetric MVIR can reconstruct a detailed 3D shape without assuming a specific surface material and lighting condition.
A Large-scale Friend Suggestion Architecture
Dec 24, 2022
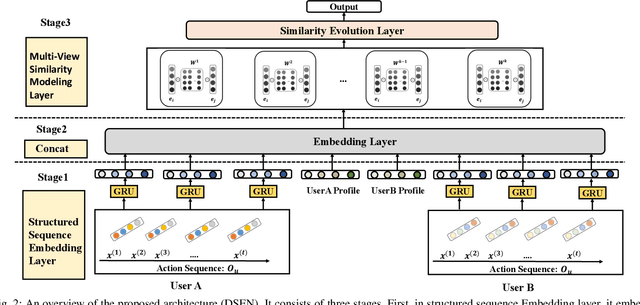
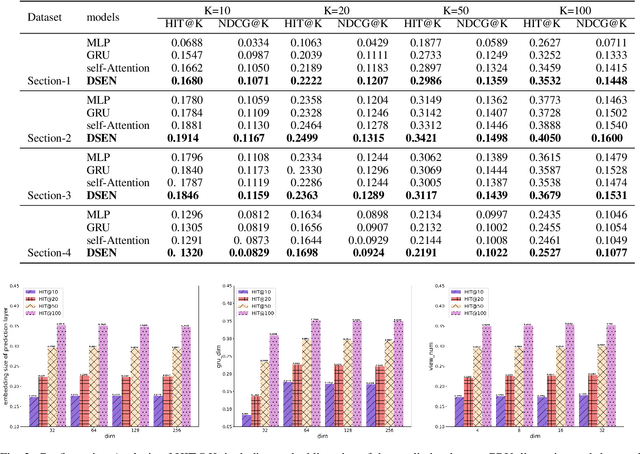
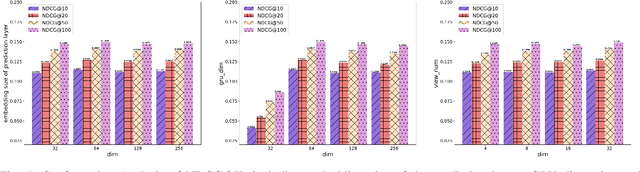
Online social as an extension of traditional life plays an important role in our daily lives. Users often seek out new friends that have significant similarities such as interests and habits, motivating us to exploit such online information to suggest friends to users. In this work, we focus on friend suggestion in online game platforms because in-game social quality significantly correlates with player engagement, determining game experience. Unlike a typical recommendation system that depends on item-user interactions, in our setting, user-user interactions do not depend on each other. Meanwhile, user preferences change rapidly due to fast changing game environment. There has been little work on designing friend suggestion when facing these difficulties, and for the first time we aim to tackle this in large scale online games. Motivated by the fast changing online game environment, we formulate this problem as friend ranking by modeling the evolution of similarity among users, exploiting the long-term and short-term feature of users in games. Our experiments on large-scale game datasets with several million users demonstrate that our proposed model achieves superior performance over other competing baselines.
Risk assessment and mitigation of e-scooter crashes with naturalistic driving data
Dec 24, 2022


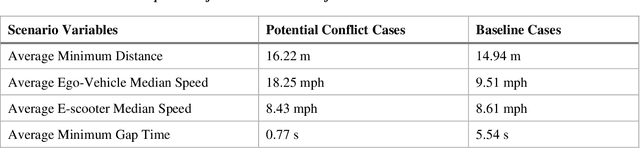
Recently, e-scooter-involved crashes have increased significantly but little information is available about the behaviors of on-road e-scooter riders. Most existing e-scooter crash research was based on retrospectively descriptive media reports, emergency room patient records, and crash reports. This paper presents a naturalistic driving study with a focus on e-scooter and vehicle encounters. The goal is to quantitatively measure the behaviors of e-scooter riders in different encounters to help facilitate crash scenario modeling, baseline behavior modeling, and the potential future development of in-vehicle mitigation algorithms. The data was collected using an instrumented vehicle and an e-scooter rider wearable system, respectively. A three-step data analysis process is developed. First, semi-automatic data labeling extracts e-scooter rider images and non-rider human images in similar environments to train an e-scooter-rider classifier. Then, a multi-step scene reconstruction pipeline generates vehicle and e-scooter trajectories in all encounters. The final step is to model e-scooter rider behaviors and e-scooter-vehicle encounter scenarios. A total of 500 vehicle to e-scooter interactions are analyzed. The variables pertaining to the same are also discussed in this paper.
Nothing Stands Alone: Relational Fake News Detection with Hypergraph Neural Networks
Dec 24, 2022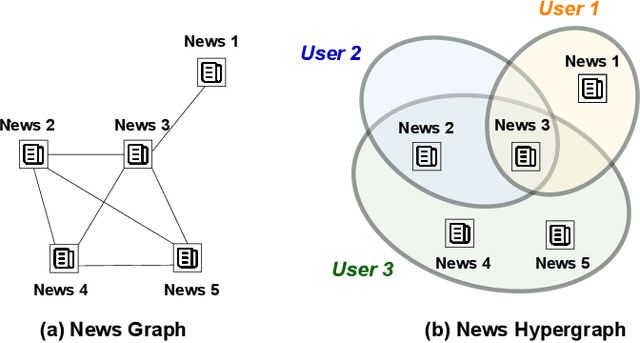
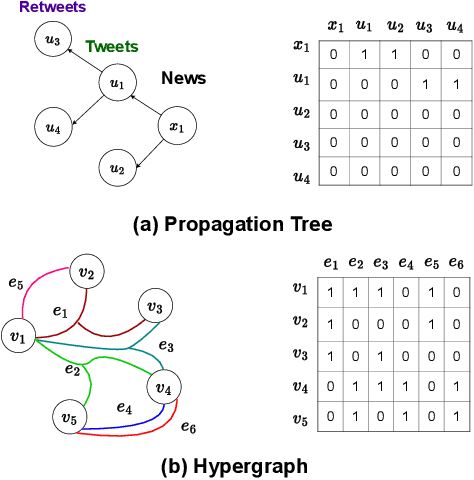
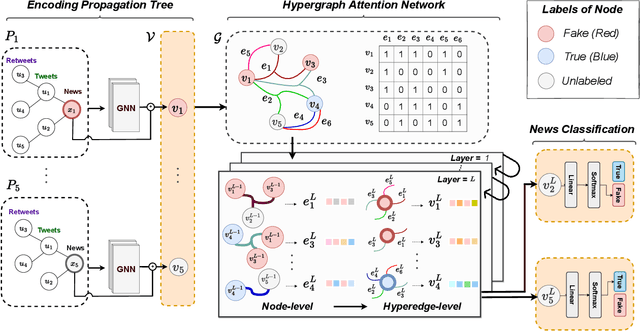
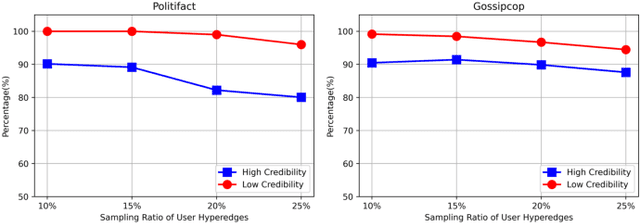
Nowadays, fake news easily propagates through online social networks and becomes a grand threat to individuals and society. Assessing the authenticity of news is challenging due to its elaborately fabricated contents, making it difficult to obtain large-scale annotations for fake news data. Due to such data scarcity issues, detecting fake news tends to fail and overfit in the supervised setting. Recently, graph neural networks (GNNs) have been adopted to leverage the richer relational information among both labeled and unlabeled instances. Despite their promising results, they are inherently focused on pairwise relations between news, which can limit the expressive power for capturing fake news that spreads in a group-level. For example, detecting fake news can be more effective when we better understand relations between news pieces shared among susceptible users. To address those issues, we propose to leverage a hypergraph to represent group-wise interaction among news, while focusing on important news relations with its dual-level attention mechanism. Experiments based on two benchmark datasets show that our approach yields remarkable performance and maintains the high performance even with a small subset of labeled news data.