 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Graph Augmentation Clustering Network
Nov 19, 2022
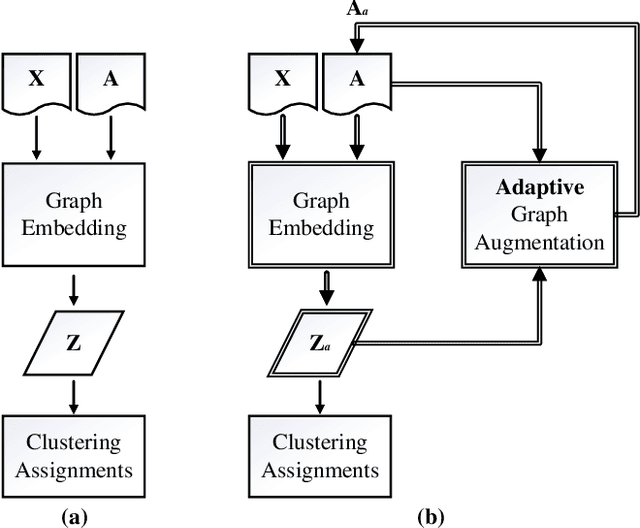
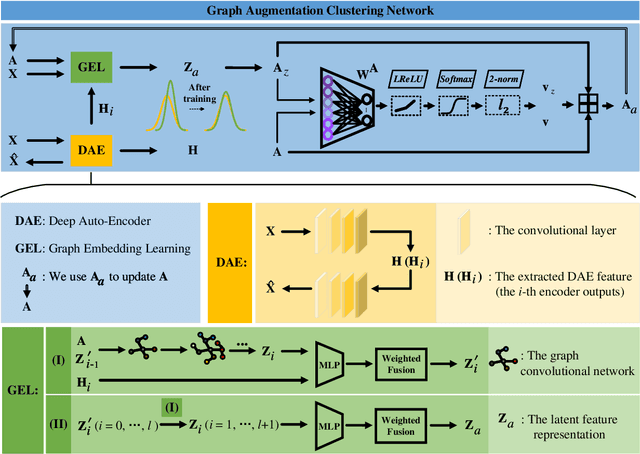

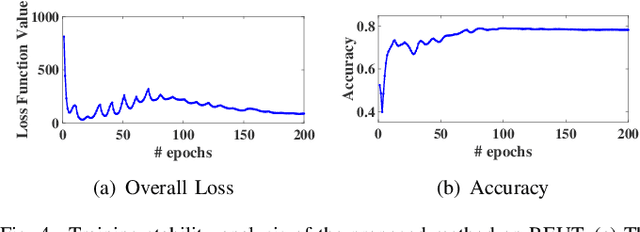
Existing graph clustering networks heavily rely on a predefined graph and may fail if the initial graph is of low quality. To tackle this issue, we propose a novel graph augmentation clustering network capable of adaptively enhancing the initial graph to achieve better clustering performance. Specifically, we first integrate the node attribute and topology structure information to learn the latent feature representation. Then, we explore the local geometric structure information on the embedding space to construct an adjacency graph and subsequently develop an adaptive graph augmentation architecture to fuse that graph with the initial one dynamically. Finally, we minimize the Jeffreys divergence between multiple derived distributions to conduct network training in an unsupervised fashion. Extensive experiments on six commonly used benchmark datasets demonstrate that the proposed method consistently outperforms several state-of-the-art approaches. In particular, our method improves the ARI by more than 9.39\% over the best baseline on DBLP. The source codes and data have been submitted to the appendix.
Latent Graph Representations for Critical View of Safety Assessment
Dec 08, 2022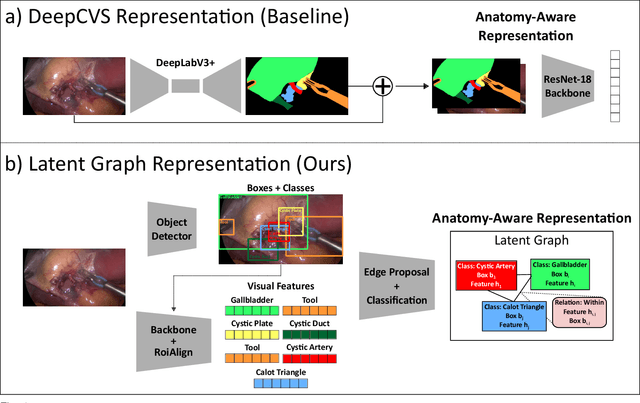
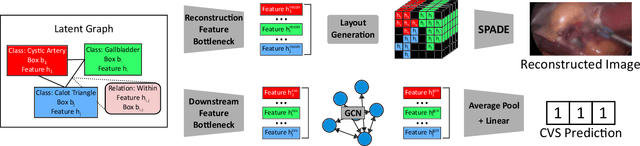
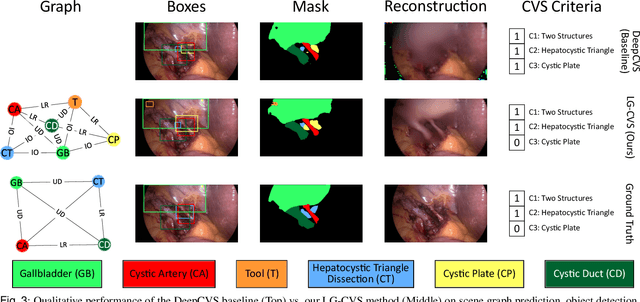
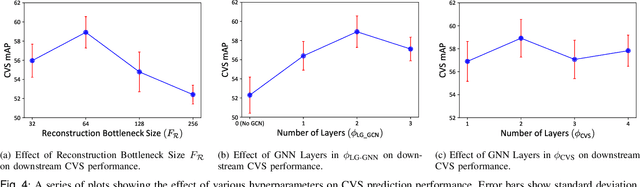
Assessing the critical view of safety in laparoscopic cholecystectomy requires accurate identification and localization of key anatomical structures, reasoning about their geometric relationships to one another, and determining the quality of their exposure. In this work, we propose to capture each of these aspects by modeling the surgical scene with a disentangled latent scene graph representation, which we can then process using a graph neural network. Unlike previous approaches using graph representations, we explicitly encode in our graphs semantic information such as object locations and shapes, class probabilities and visual features. We also incorporate an auxiliary image reconstruction objective to help train the latent graph representations. We demonstrate the value of these components through comprehensive ablation studies and achieve state-of-the-art results for critical view of safety prediction across multiple experimental settings.
Non-parallel Accent Conversion using Pseudo Siamese Disentanglement Network
Dec 12, 2022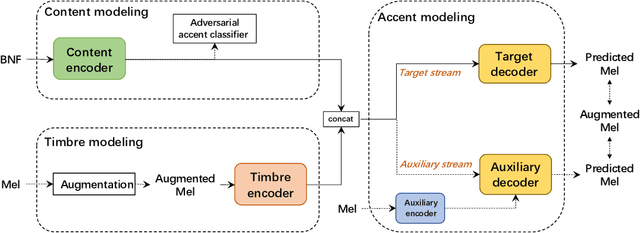
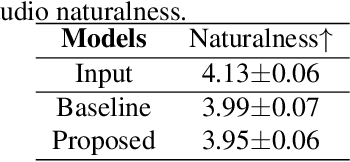
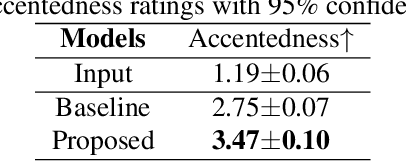
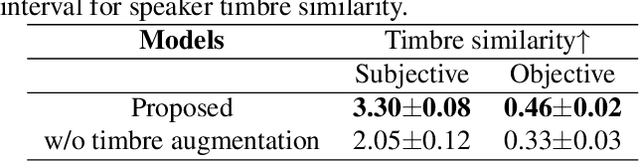
The main goal of accent conversion (AC) is to convert the accent of speech into the target accent while preserving the content and timbre. Previous reference-based methods rely on reference utterances in the inference phase, which limits their practical application. What's more, previous reference-free methods mostly require parallel data in the training phase. In this paper, we propose a reference-free method based on non-parallel data from the perspective of feature disentanglement. Pseudo Siamese Disentanglement Network (PSDN) is proposed to disentangle the accent information from the content representation and model the target accent. Besides, a timbre augmentation method is proposed to enhance the ability of timbre retaining for speakers without target-accent data. Experimental results show that the proposed system can convert the accent of native American English speech into Indian accent with higher accentedness (3.47) than the baseline (2.75) and input (1.19). The naturalness of converted speech is also comparable to that of the input.
Earthquake Impact Analysis Based on Text Mining and Social Media Analytics
Dec 12, 2022
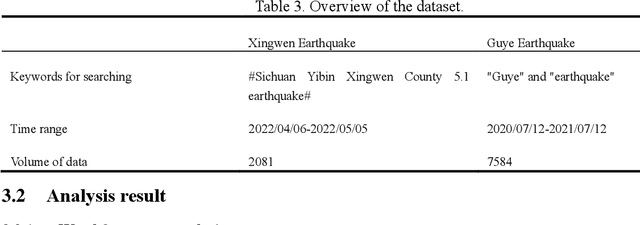
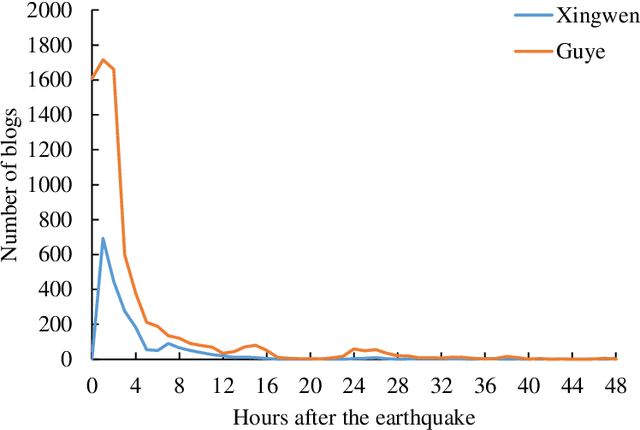
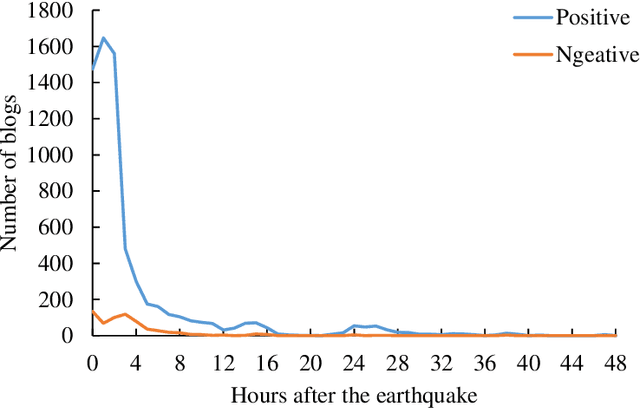
Earthquakes have a deep impact on wide areas, and emergency rescue operations may benefit from social media information about the scope and extent of the disaster. Therefore, this work presents a text miningbased approach to collect and analyze social media data for early earthquake impact analysis. First, disasterrelated microblogs are collected from the Sina microblog based on crawler technology. Then, after data cleaning a series of analyses are conducted including (1) the hot words analysis, (2) the trend of the number of microblogs, (3) the trend of public opinion sentiment, and (4) a keyword and rule-based text classification for earthquake impact analysis. Finally, two recent earthquakes with the same magnitude and focal depth in China are analyzed to compare their impacts. The results show that the public opinion trend analysis and the trend of public opinion sentiment can estimate the earthquake's social impact at an early stage, which will be helpful to decision-making and rescue management.
MMD-B-Fair: Learning Fair Representations with Statistical Testing
Nov 15, 2022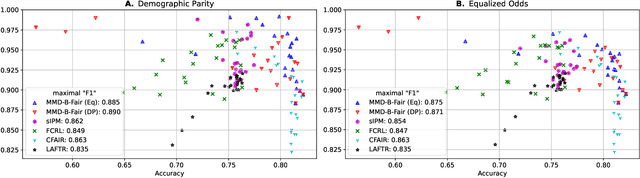
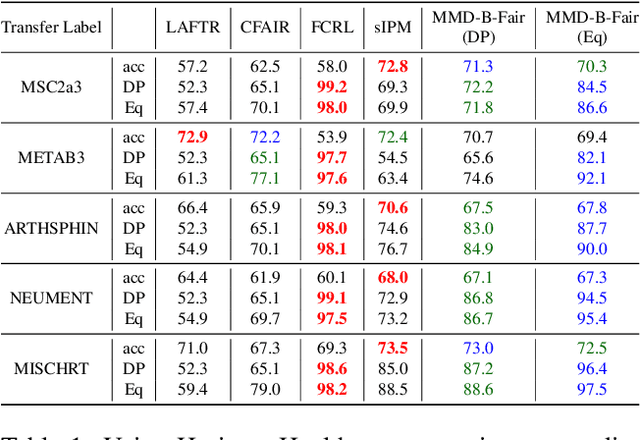
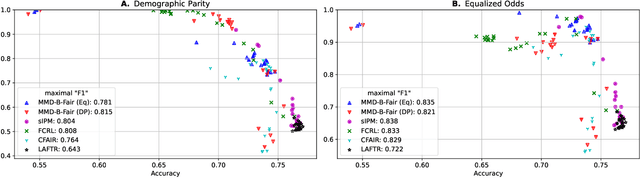
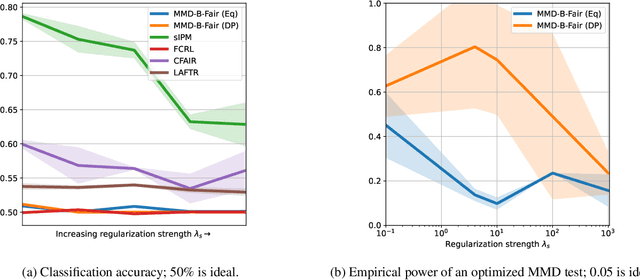
We introduce a method, MMD-B-Fair, to learn fair representations of data via kernel two-sample testing. We find neural features of our data where a maximum mean discrepancy (MMD) test cannot distinguish between different values of sensitive attributes, while preserving information about the target. Minimizing the power of an MMD test is more difficult than maximizing it (as done in previous work), because the test threshold's complex behavior cannot be simply ignored. Our method exploits the simple asymptotics of block testing schemes to efficiently find fair representations without requiring the complex adversarial optimization or generative modelling schemes widely used by existing work on fair representation learning. We evaluate our approach on various datasets, showing its ability to "hide" information about sensitive attributes, and its effectiveness in downstream transfer tasks.
Transfer and Marginalize: Explaining Away Label Noise with Privileged Information
Feb 18, 2022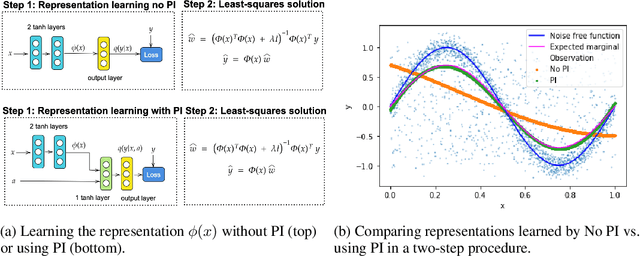
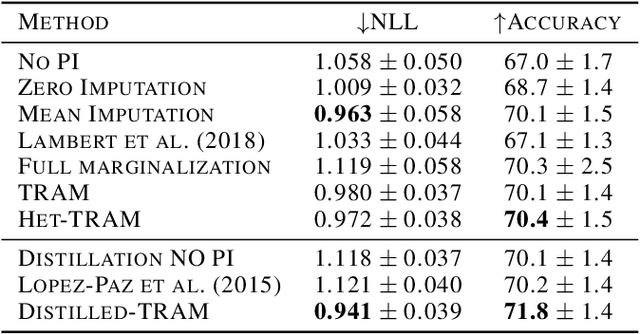
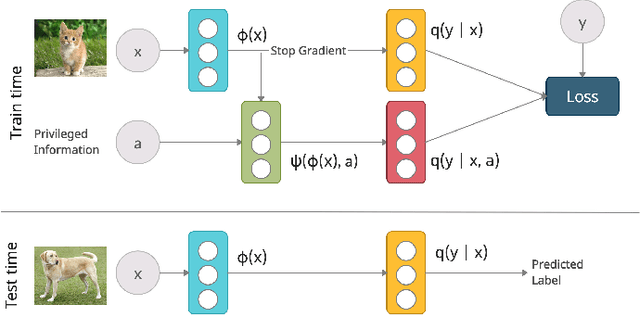
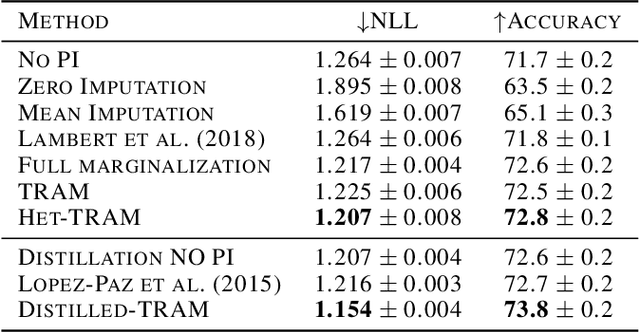
Supervised learning datasets often have privileged information, in the form of features which are available at training time but are not available at test time e.g. the ID of the annotator that provided the label. We argue that privileged information is useful for explaining away label noise, thereby reducing the harmful impact of noisy labels. We develop a simple and efficient method for supervised neural networks: it transfers via weight sharing the knowledge learned with privileged information and approximately marginalizes over privileged information at test time. Our method, TRAM (TRansfer and Marginalize), has minimal training time overhead and has the same test time cost as not using privileged information. TRAM performs strongly on CIFAR-10H, ImageNet and Civil Comments benchmarks.
An Empirical Evaluation of Various Information Gain Criteria for Active Tactile Action Selection for Pose Estimation
May 10, 2022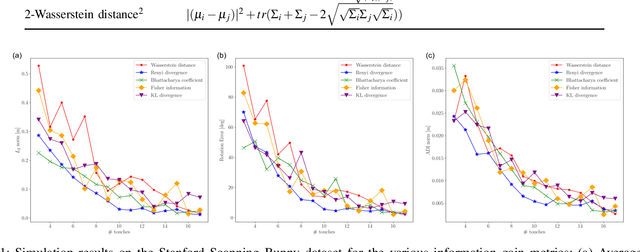
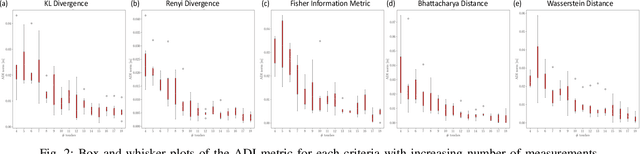
Accurate object pose estimation using multi-modal perception such as visual and tactile sensing have been used for autonomous robotic manipulators in literature. Due to variation in density of visual and tactile data, we previously proposed a novel probabilistic Bayesian filter-based approach termed translation-invariant Quaternion filter (TIQF) for pose estimation. As tactile data collection is time consuming, active tactile data collection is preferred by reasoning over multiple potential actions for maximal expected information gain. In this paper, we empirically evaluate various information gain criteria for action selection in the context of object pose estimation. We demonstrate the adaptability and effectiveness of our proposed TIQF pose estimation approach with various information gain criteria. We find similar performance in terms of pose accuracy with sparse measurements across all the selected criteria.
OSIC: A New One-Stage Image Captioner Coined
Nov 04, 2022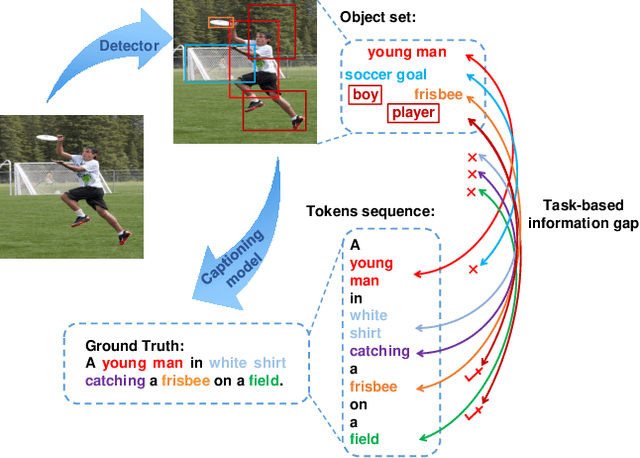
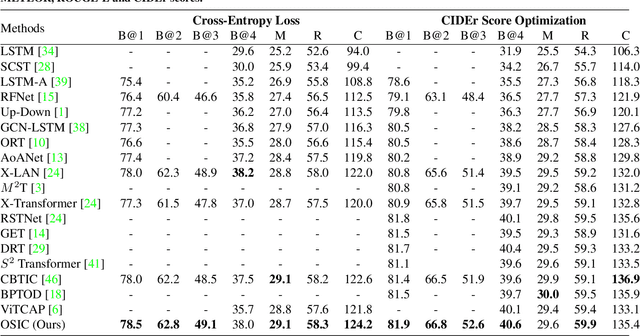
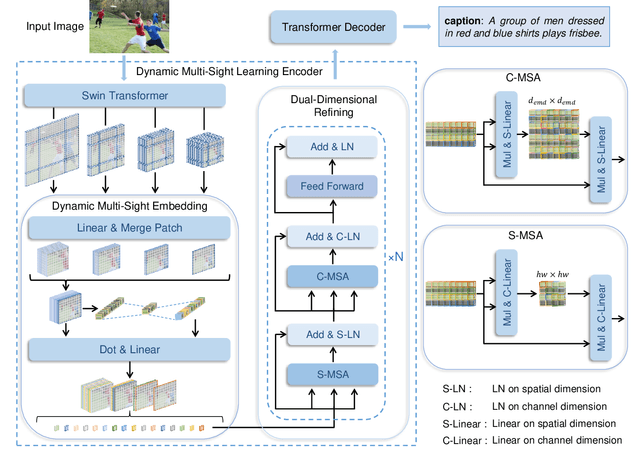
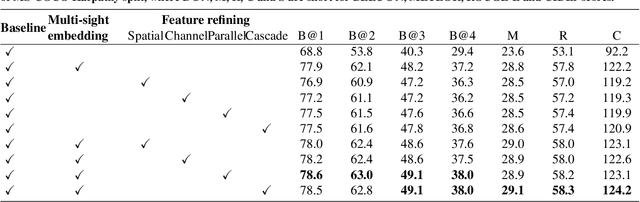
Mainstream image caption models are usually two-stage captioners, i.e., calculating object features by pre-trained detector, and feeding them into a language model to generate text descriptions. However, such an operation will cause a task-based information gap to decrease the performance, since the object features in detection task are suboptimal representation and cannot provide all necessary information for subsequent text generation. Besides, object features are usually represented by the last layer features that lose the local details of input images. In this paper, we propose a novel One-Stage Image Captioner (OSIC) with dynamic multi-sight learning, which directly transforms input image into descriptive sentences in one stage. As a result, the task-based information gap can be greatly reduced. To obtain rich features, we use the Swin Transformer to calculate multi-level features, and then feed them into a novel dynamic multi-sight embedding module to exploit both global structure and local texture of input images. To enhance the global modeling of encoder for caption, we propose a new dual-dimensional refining module to non-locally model the interaction of the embedded features. Finally, OSIC can obtain rich and useful information to improve the image caption task. Extensive comparisons on benchmark MS-COCO dataset verified the superior performance of our method.
Confidence-Aware Paced-Curriculum Learning by Label Smoothing for Surgical Scene Understanding
Dec 22, 2022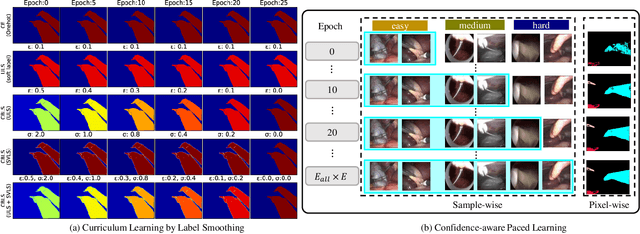
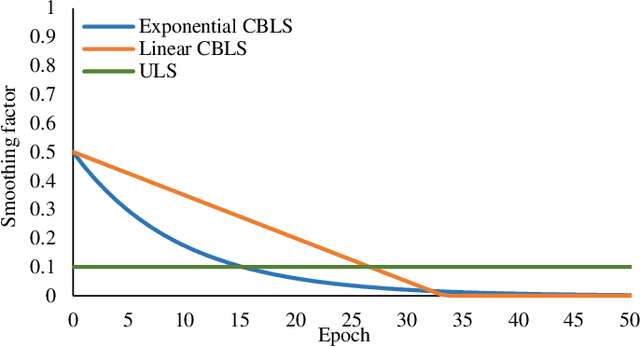
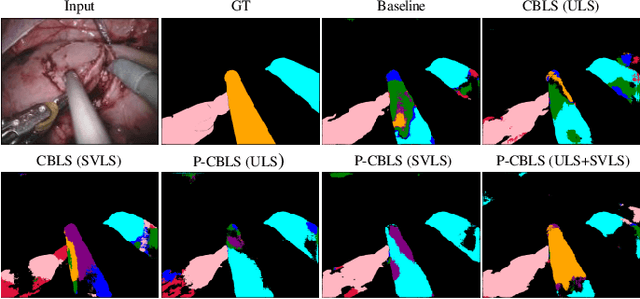
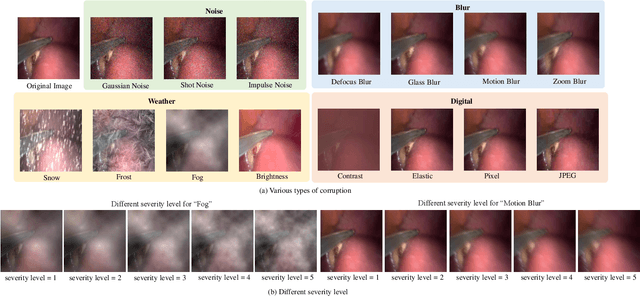
Curriculum learning and self-paced learning are the training strategies that gradually feed the samples from easy to more complex. They have captivated increasing attention due to their excellent performance in robotic vision. Most recent works focus on designing curricula based on difficulty levels in input samples or smoothing the feature maps. However, smoothing labels to control the learning utility in a curriculum manner is still unexplored. In this work, we design a paced curriculum by label smoothing (P-CBLS) using paced learning with uniform label smoothing (ULS) for classification tasks and fuse uniform and spatially varying label smoothing (SVLS) for semantic segmentation tasks in a curriculum manner. In ULS and SVLS, a bigger smoothing factor value enforces a heavy smoothing penalty in the true label and limits learning less information. Therefore, we design the curriculum by label smoothing (CBLS). We set a bigger smoothing value at the beginning of training and gradually decreased it to zero to control the model learning utility from lower to higher. We also designed a confidence-aware pacing function and combined it with our CBLS to investigate the benefits of various curricula. The proposed techniques are validated on four robotic surgery datasets of multi-class, multi-label classification, captioning, and segmentation tasks. We also investigate the robustness of our method by corrupting validation data into different severity levels. Our extensive analysis shows that the proposed method improves prediction accuracy and robustness.
* 12 pages
Localising In-Domain Adaptation of Transformer-Based Biomedical Language Models
Dec 22, 2022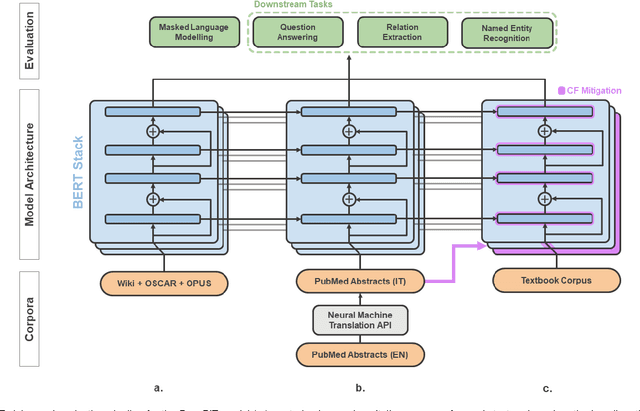
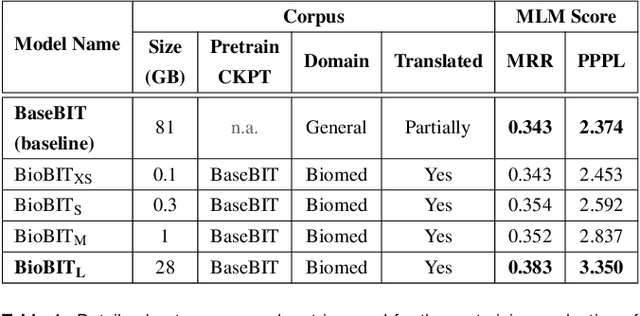
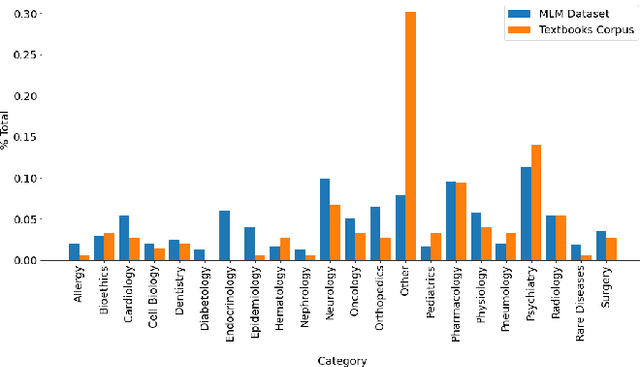
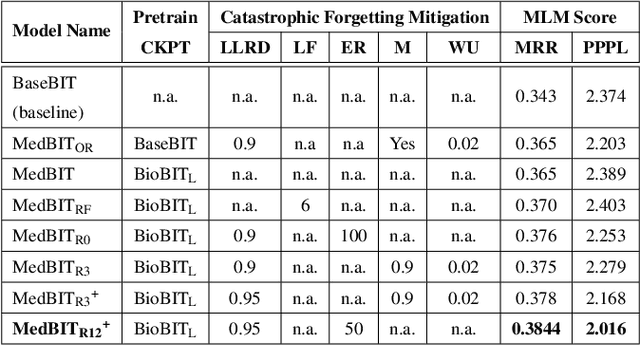
In the era of digital healthcare, the huge volumes of textual information generated every day in hospitals constitute an essential but underused asset that could be exploited with task-specific, fine-tuned biomedical language representation models, improving patient care and management. For such specialized domains, previous research has shown that fine-tuning models stemming from broad-coverage checkpoints can largely benefit additional training rounds over large-scale in-domain resources. However, these resources are often unreachable for less-resourced languages like Italian, preventing local medical institutions to employ in-domain adaptation. In order to reduce this gap, our work investigates two accessible approaches to derive biomedical language models in languages other than English, taking Italian as a concrete use-case: one based on neural machine translation of English resources, favoring quantity over quality; the other based on a high-grade, narrow-scoped corpus natively written in Italian, thus preferring quality over quantity. Our study shows that data quantity is a harder constraint than data quality for biomedical adaptation, but the concatenation of high-quality data can improve model performance even when dealing with relatively size-limited corpora. The models published from our investigations have the potential to unlock important research opportunities for Italian hospitals and academia. Finally, the set of lessons learned from the study constitutes valuable insights towards a solution to build biomedical language models that are generalizable to other less-resourced languages and different domain settings.