 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
An Ensemble Mobile-Cloud Computing Method for Affordable and Accurate Glucometer Readout
Jan 04, 2023
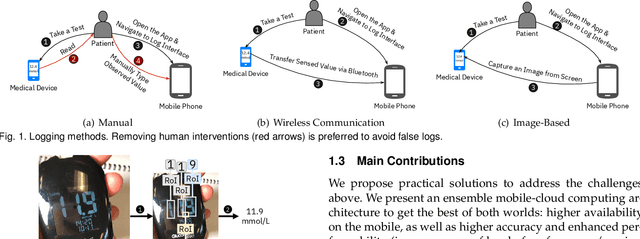

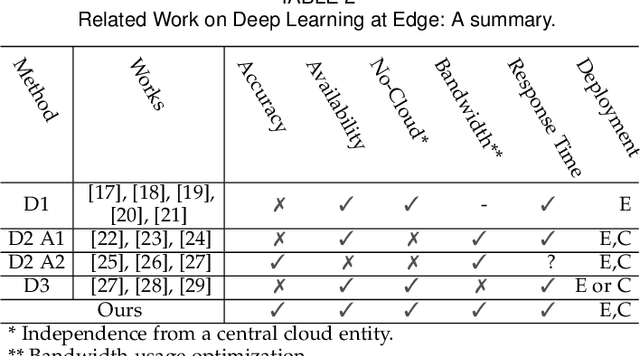
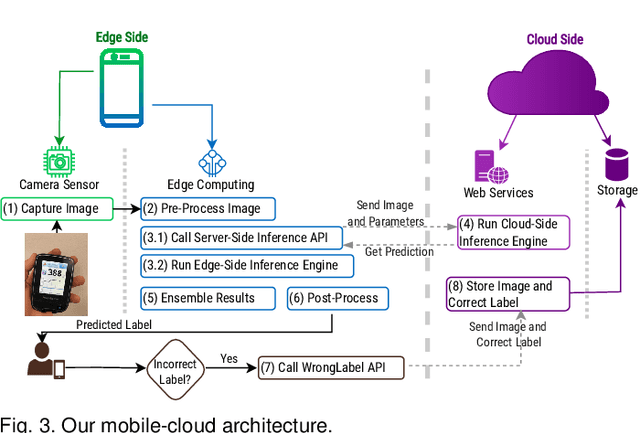
Despite essential efforts towards advanced wireless medical devices for regular monitoring of blood properties, many such devices are not available or not affordable for everyone in many countries. Alternatively using ordinary devices, patients ought to log data into a mobile health-monitoring manually. It causes several issues: (1) clients reportedly tend to enter unrealistic data; (2) typing values several times a day is bothersome and causes clients to leave the mobile app. Thus, there is a strong need to use now-ubiquitous smartphones, reducing error by capturing images from the screen of medical devices and extracting useful information automatically. Nevertheless, there are a few challenges in its development: (1) data scarcity has led to impractical methods with very low accuracy: to our knowledge, only small datasets are available in this case; (2) accuracy-availability tradeoff: one can execute a less accurate algorithm on a mobile phone to maintain higher availability, or alternatively deploy a more accurate and more compute-intensive algorithm on the cloud, however, at the cost of lower availability in poor/no connectivity situations. We present an ensemble learning algorithm, a mobile-cloud computing service architecture, and a simple compression technique to achieve higher availability and faster response time while providing higher accuracy by integrating cloud- and mobile-side predictions. Additionally, we propose an algorithm to generate synthetic training data which facilitates utilizing deep learning models to improve accuracy. Our proposed method achieves three main objectives: (1) 92.1% and 97.7% accuracy on two different datasets, improving previous methods by 40%, (2) reducing required bandwidth by 45x with 1% drop in accuracy, (3) and providing better availability compared to mobile-only, cloud-only, split computing, and early exit service models.
The R-algebra of Quasiknowledge and Convex Optimization
Dec 08, 2022This article develops a convex description of a classical or quantum learner's or agent's state of knowledge about its environment, presented as a convex subset of a commutative R-algebra. With caveats, this leads to a generalization of certain semidefinite programs in quantum information (such as those describing the universal query algorithm dual to the quantum adversary bound, related to optimal learning or control of the environment) to the classical and faulty-quantum setting, which would not be possible with a naive description via joint probability distributions over environment and internal memory. More philosophically, it also makes an interpretation of the set of reduced density matrices as "states of knowledge" of an observer of its environment, related to these techniques, more explicit. As another example, I describe and solve a formal differential equation of states of knowledge in that algebra, where an agent obtains experimental data in a Poissonian process, and its state of knowledge evolves as an exponential power series. However, this framework currently lacks impressive applications, and I post it in part to solicit feedback and collaboration on those. In particular, it may be possible to develop it into a new framework for the design of experiments, e.g. the problem of finding maximally informative questions to ask human labelers or the environment in machine-learning problems. The parts of the article not related to quantum information don't assume knowledge of it.
Improving Fairness in Image Classification via Sketching
Oct 31, 2022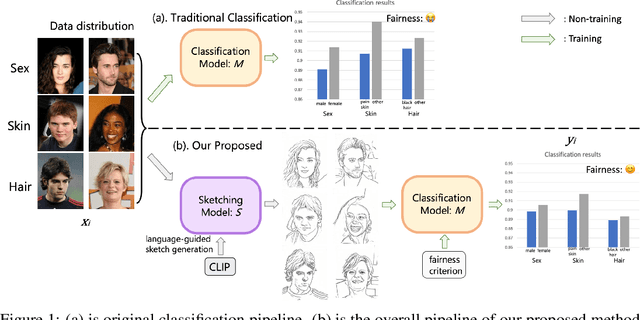


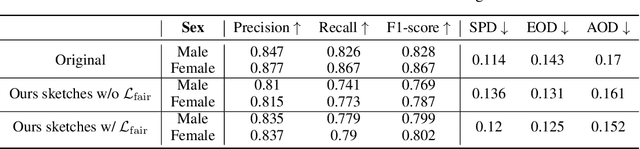
Fairness is a fundamental requirement for trustworthy and human-centered Artificial Intelligence (AI) system. However, deep neural networks (DNNs) tend to make unfair predictions when the training data are collected from different sub-populations with different attributes (i.e. color, sex, age), leading to biased DNN predictions. We notice that such a troubling phenomenon is often caused by data itself, which means that bias information is encoded to the DNN along with the useful information (i.e. class information, semantic information). Therefore, we propose to use sketching to handle this phenomenon. Without losing the utility of data, we explore the image-to-sketching methods that can maintain useful semantic information for the target classification while filtering out the useless bias information. In addition, we design a fair loss to further improve the model fairness. We evaluate our method through extensive experiments on both general scene dataset and medical scene dataset. Our results show that the desired image-to-sketching method improves model fairness and achieves satisfactory results among state-of-the-art.
MUSE: Feature Self-Distillation with Mutual Information and Self-Information
Oct 25, 2021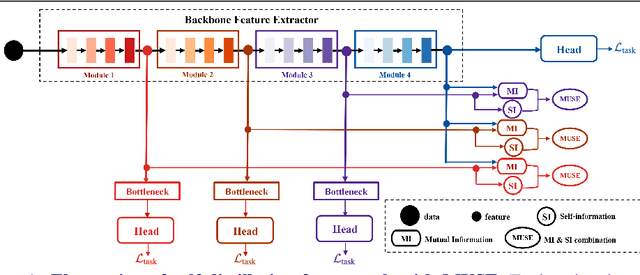
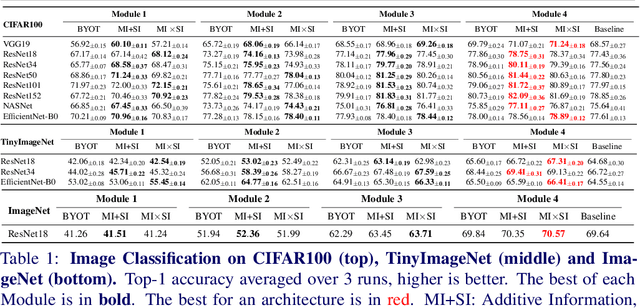

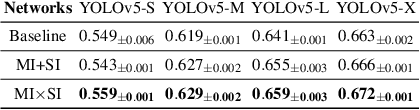
We present a novel information-theoretic approach to introduce dependency among features of a deep convolutional neural network (CNN). The core idea of our proposed method, called MUSE, is to combine MUtual information and SElf-information to jointly improve the expressivity of all features extracted from different layers in a CNN. We present two variants of the realization of MUSE -- Additive Information and Multiplicative Information. Importantly, we argue and empirically demonstrate that MUSE, compared to other feature discrepancy functions, is a more functional proxy to introduce dependency and effectively improve the expressivity of all features in the knowledge distillation framework. MUSE achieves superior performance over a variety of popular architectures and feature discrepancy functions for self-distillation and online distillation, and performs competitively with the state-of-the-art methods for offline distillation. MUSE is also demonstrably versatile that enables it to be easily extended to CNN-based models on tasks other than image classification such as object detection.
Federated Learning on Non-IID Graphs via Structural Knowledge Sharing
Nov 23, 2022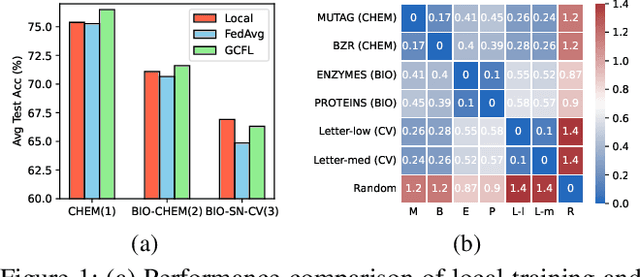
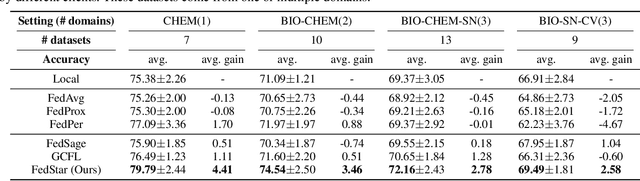
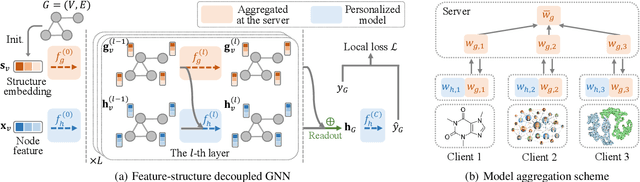
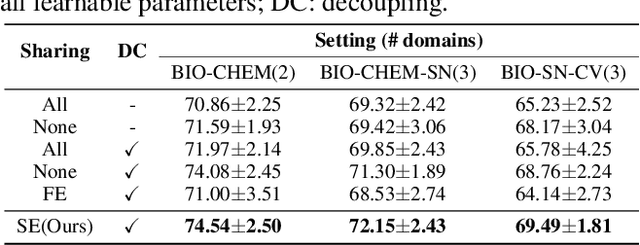
Graph neural networks (GNNs) have shown their superiority in modeling graph data. Owing to the advantages of federated learning, federated graph learning (FGL) enables clients to train strong GNN models in a distributed manner without sharing their private data. A core challenge in federated systems is the non-IID problem, which also widely exists in real-world graph data. For example, local data of clients may come from diverse datasets or even domains, e.g., social networks and molecules, increasing the difficulty for FGL methods to capture commonly shared knowledge and learn a generalized encoder. From real-world graph datasets, we observe that some structural properties are shared by various domains, presenting great potential for sharing structural knowledge in FGL. Inspired by this, we propose FedStar, an FGL framework that extracts and shares the common underlying structure information for inter-graph federated learning tasks. To explicitly extract the structure information rather than encoding them along with the node features, we define structure embeddings and encode them with an independent structure encoder. Then, the structure encoder is shared across clients while the feature-based knowledge is learned in a personalized way, making FedStar capable of capturing more structure-based domain-invariant information and avoiding feature misalignment issues. We perform extensive experiments over both cross-dataset and cross-domain non-IID FGL settings, demonstrating the superiority of FedStar.
Multimodal Tree Decoder for Table of Contents Extraction in Document Images
Dec 06, 2022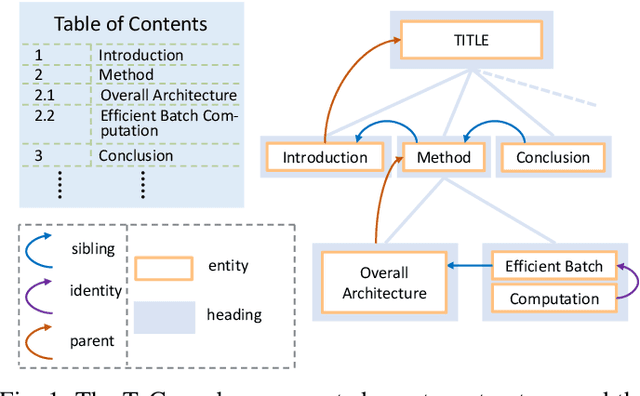

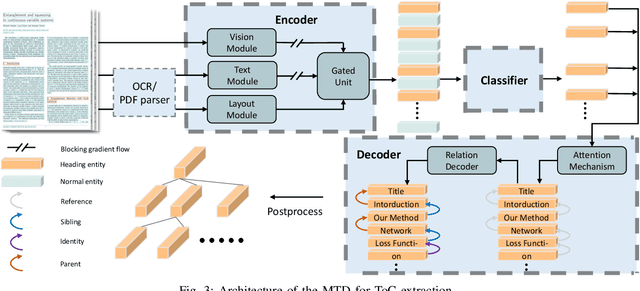
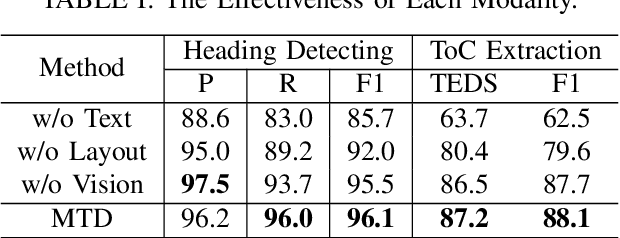
Table of contents (ToC) extraction aims to extract headings of different levels in documents to better understand the outline of the contents, which can be widely used for document understanding and information retrieval. Existing works often use hand-crafted features and predefined rule-based functions to detect headings and resolve the hierarchical relationship between headings. Both the benchmark and research based on deep learning are still limited. Accordingly, in this paper, we first introduce a standard dataset, HierDoc, including image samples from 650 documents of scientific papers with their content labels. Then we propose a novel end-to-end model by using the multimodal tree decoder (MTD) for ToC as a benchmark for HierDoc. The MTD model is mainly composed of three parts, namely encoder, classifier, and decoder. The encoder fuses the multimodality features of vision, text, and layout information for each entity of the document. Then the classifier recognizes and selects the heading entities. Next, to parse the hierarchical relationship between the heading entities, a tree-structured decoder is designed. To evaluate the performance, both the metric of tree-edit-distance similarity (TEDS) and F1-Measure are adopted. Finally, our MTD approach achieves an average TEDS of 87.2% and an average F1-Measure of 88.1% on the test set of HierDoc. The code and dataset will be released at: https://github.com/Pengfei-Hu/MTD.
FlowFace: Semantic Flow-guided Shape-aware Face Swapping
Dec 06, 2022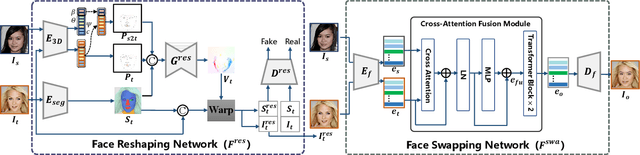
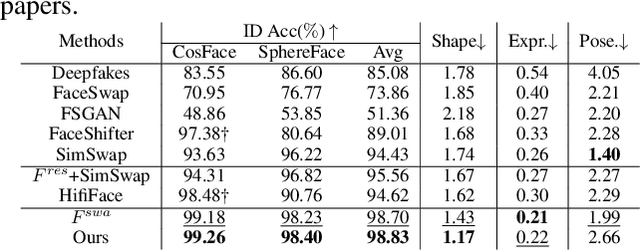


In this work, we propose a semantic flow-guided two-stage framework for shape-aware face swapping, namely FlowFace. Unlike most previous methods that focus on transferring the source inner facial features but neglect facial contours, our FlowFace can transfer both of them to a target face, thus leading to more realistic face swapping. Concretely, our FlowFace consists of a face reshaping network and a face swapping network. The face reshaping network addresses the shape outline differences between the source and target faces. It first estimates a semantic flow (i.e., face shape differences) between the source and the target face, and then explicitly warps the target face shape with the estimated semantic flow. After reshaping, the face swapping network generates inner facial features that exhibit the identity of the source face. We employ a pre-trained face masked autoencoder (MAE) to extract facial features from both the source face and the target face. In contrast to previous methods that use identity embedding to preserve identity information, the features extracted by our encoder can better capture facial appearances and identity information. Then, we develop a cross-attention fusion module to adaptively fuse inner facial features from the source face with the target facial attributes, thus leading to better identity preservation. Extensive quantitative and qualitative experiments on in-the-wild faces demonstrate that our FlowFace outperforms the state-of-the-art significantly.
Synthesize Boundaries: A Boundary-aware Self-consistent Framework for Weakly Supervised Salient Object Detection
Dec 04, 2022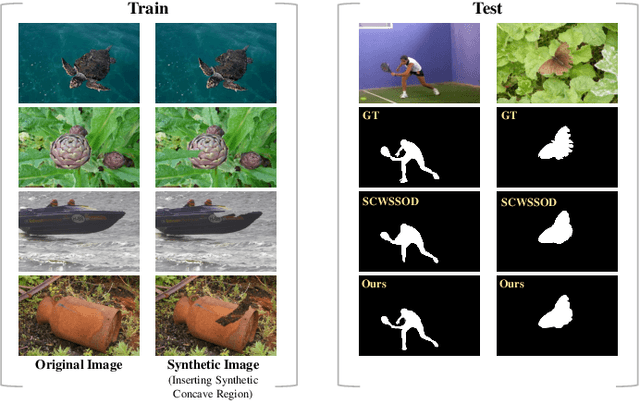
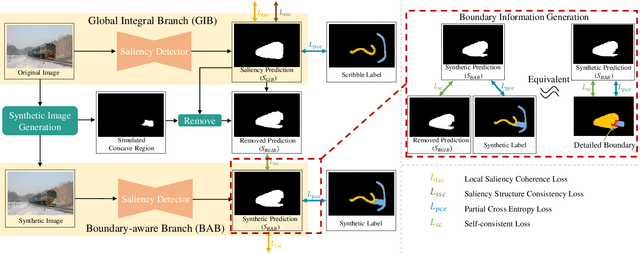
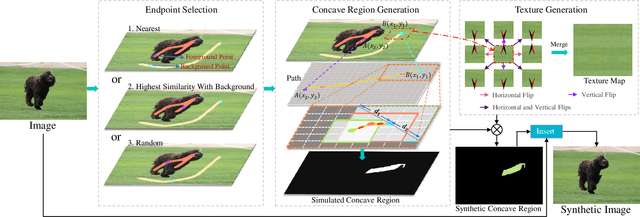
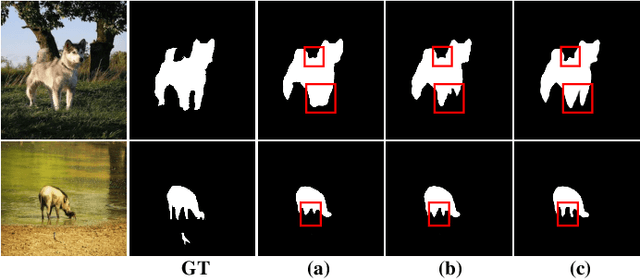
Fully supervised salient object detection (SOD) has made considerable progress based on expensive and time-consuming data with pixel-wise annotations. Recently, to relieve the labeling burden while maintaining performance, some scribble-based SOD methods have been proposed. However, learning precise boundary details from scribble annotations that lack edge information is still difficult. In this paper, we propose to learn precise boundaries from our designed synthetic images and labels without introducing any extra auxiliary data. The synthetic image creates boundary information by inserting synthetic concave regions that simulate the real concave regions of salient objects. Furthermore, we propose a novel self-consistent framework that consists of a global integral branch (GIB) and a boundary-aware branch (BAB) to train a saliency detector. GIB aims to identify integral salient objects, whose input is the original image. BAB aims to help predict accurate boundaries, whose input is the synthetic image. These two branches are connected through a self-consistent loss to guide the saliency detector to predict precise boundaries while identifying salient objects. Experimental results on five benchmarks demonstrate that our method outperforms the state-of-the-art weakly supervised SOD methods and further narrows the gap with the fully supervised methods.
Self adaptive global-local feature enhancement for radiology report generation
Nov 21, 2022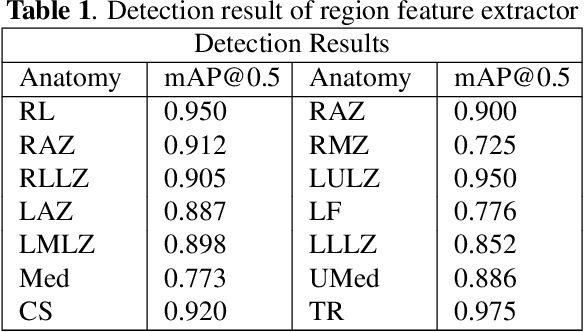
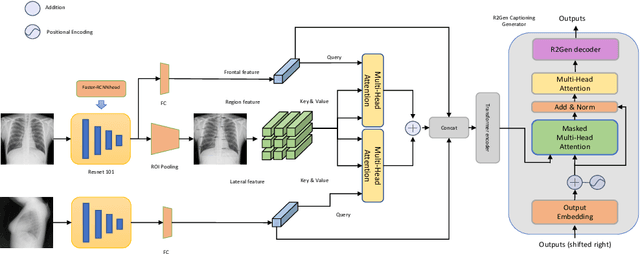
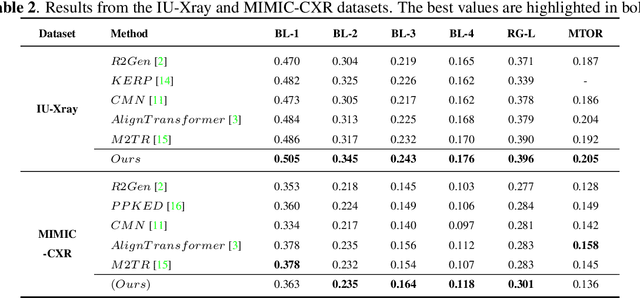
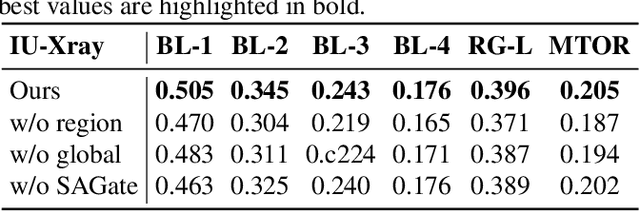
Automated radiology report generation aims at automatically generating a detailed description of medical images, which can greatly alleviate the workload of radiologists and provide better medical services to remote areas. Most existing works pay attention to the holistic impression of medical images, failing to utilize important anatomy information. However, in actual clinical practice, radiologists usually locate important anatomical structures, and then look for signs of abnormalities in certain structures and reason the underlying disease. In this paper, we propose a novel framework AGFNet to dynamically fuse the global and anatomy region feature to generate multi-grained radiology report. Firstly, we extract important anatomy region features and global features of input Chest X-ray (CXR). Then, with the region features and the global features as input, our proposed self-adaptive fusion gate module could dynamically fuse multi-granularity information. Finally, the captioning generator generates the radiology reports through multi-granularity features. Experiment results illustrate that our model achieved the state-of-the-art performance on two benchmark datasets including the IU X-Ray and MIMIC-CXR. Further analyses also prove that our model is able to leverage the multi-grained information from radiology images and texts so as to help generate more accurate reports.
Exploiting Personalized Invariance for Better Out-of-distribution Generalization in Federated Learning
Nov 21, 2022
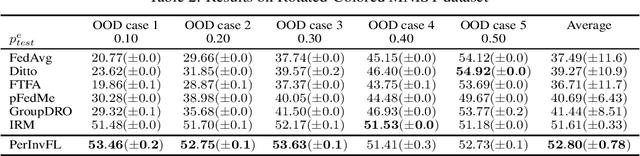
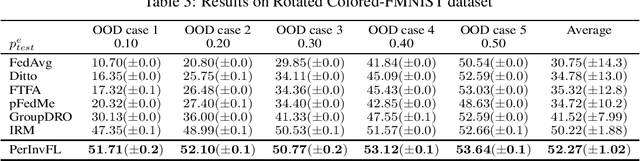
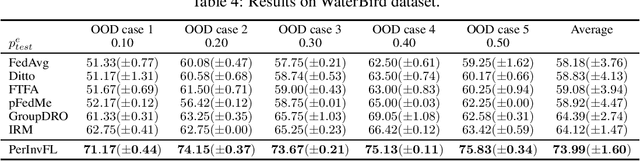
Recently, data heterogeneity among the training datasets on the local clients (a.k.a., Non-IID data) has attracted intense interest in Federated Learning (FL), and many personalized federated learning methods have been proposed to handle it. However, the distribution shift between the training dataset and testing dataset on each client is never considered in FL, despite it being general in real-world scenarios. We notice that the distribution shift (a.k.a., out-of-distribution generalization) problem under Non-IID federated setting becomes rather challenging due to the entanglement between personalized and spurious information. To tackle the above problem, we elaborate a general dual-regularized learning framework to explore the personalized invariance, compared with the exsiting personalized federated learning methods which are regularized by a single baseline (usually the global model). Utilizing the personalized invariant features, the developed personalized models can efficiently exploit the most relevant information and meanwhile eliminate spurious information so as to enhance the out-of-distribution generalization performance for each client. Both the theoretical analysis on convergence and OOD generalization performance and the results of extensive experiments demonstrate the superiority of our method over the existing federated learning and invariant learning methods, in diverse out-of-distribution and Non-IID data cases.