 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
CultureBERT: Fine-Tuning Transformer-Based Language Models for Corporate Culture
Dec 01, 2022
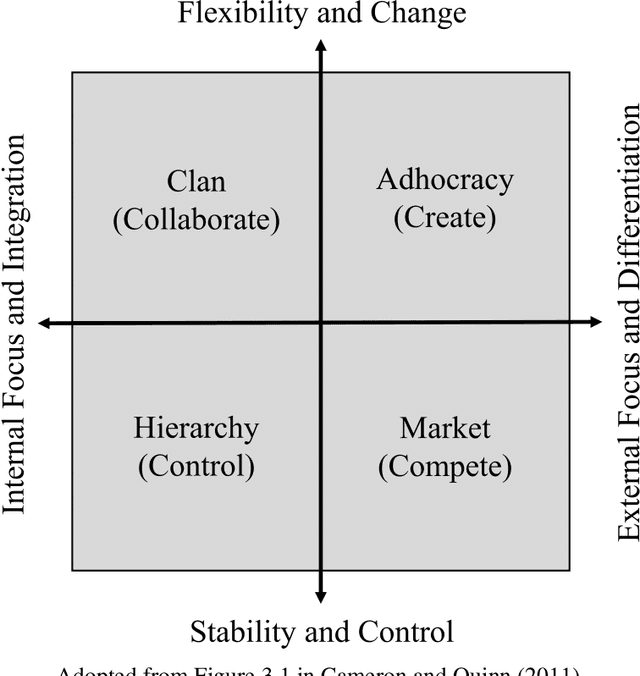
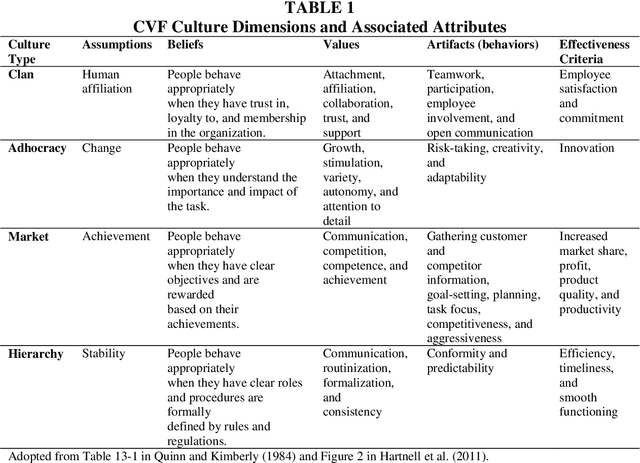
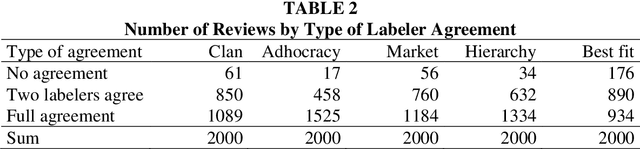

This paper introduces supervised machine learning to the literature measuring corporate culture from text documents. We compile a unique data set of employee reviews that were labeled by human evaluators with respect to the information the reviews reveal about the firms' corporate culture. Using this data set, we fine-tune state-of-the-art transformer-based language models to perform the same classification task. In out-of-sample predictions, our language models classify 16 to 28 percent points more of employee reviews in line with human evaluators than traditional approaches of text classification.
An Empirical Evaluation of Various Information Gain Criteria for Active Tactile Action Selection for Pose Estimation
May 10, 2022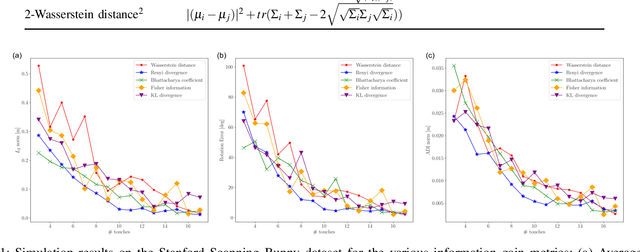
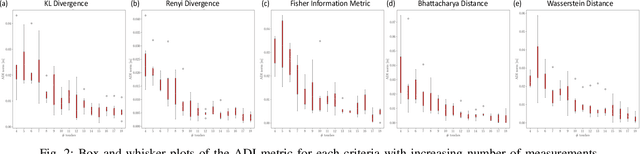
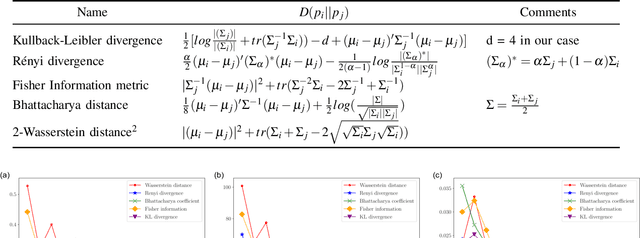
Accurate object pose estimation using multi-modal perception such as visual and tactile sensing have been used for autonomous robotic manipulators in literature. Due to variation in density of visual and tactile data, we previously proposed a novel probabilistic Bayesian filter-based approach termed translation-invariant Quaternion filter (TIQF) for pose estimation. As tactile data collection is time consuming, active tactile data collection is preferred by reasoning over multiple potential actions for maximal expected information gain. In this paper, we empirically evaluate various information gain criteria for action selection in the context of object pose estimation. We demonstrate the adaptability and effectiveness of our proposed TIQF pose estimation approach with various information gain criteria. We find similar performance in terms of pose accuracy with sparse measurements across all the selected criteria.
Camelira: An Arabic Multi-Dialect Morphological Disambiguator
Nov 30, 2022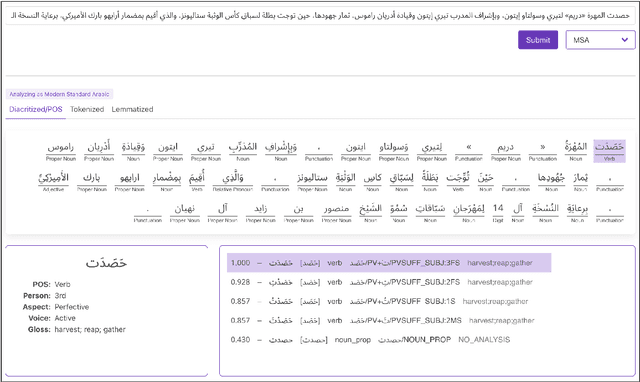
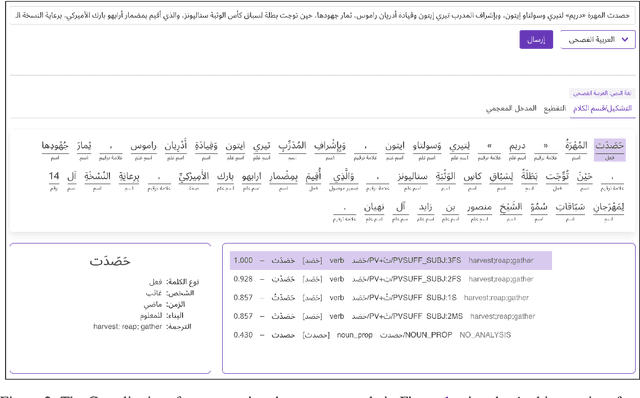

We present Camelira, a web-based Arabic multi-dialect morphological disambiguation tool that covers four major variants of Arabic: Modern Standard Arabic, Egyptian, Gulf, and Levantine. Camelira offers a user-friendly web interface that allows researchers and language learners to explore various linguistic information, such as part-of-speech, morphological features, and lemmas. Our system also provides an option to automatically choose an appropriate dialect-specific disambiguator based on the prediction of a dialect identification component. Camelira is publicly accessible at http://camelira.camel-lab.com.
Accelerated structured matrix factorization
Dec 13, 2022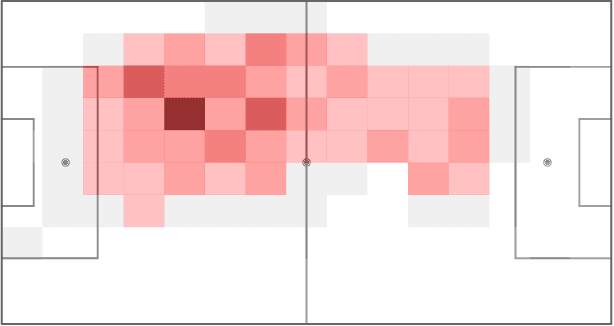
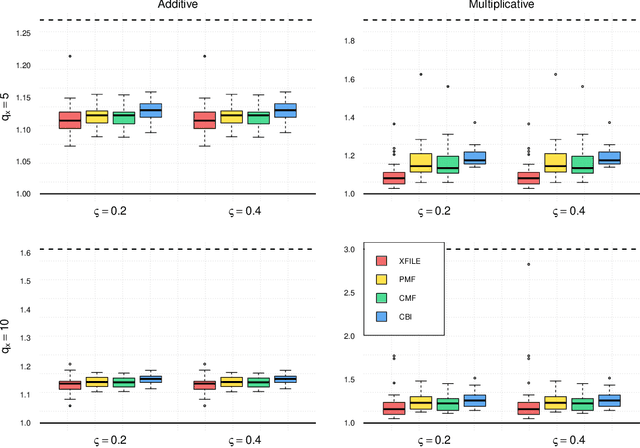
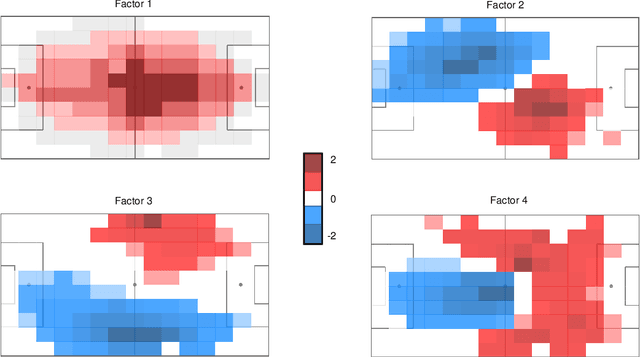
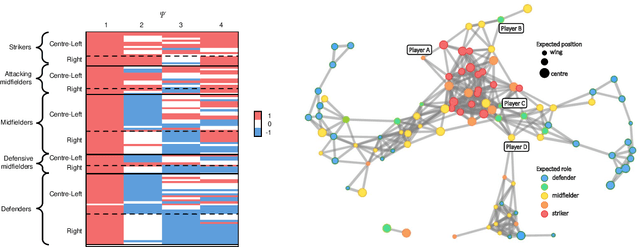
Matrix factorization exploits the idea that, in complex high-dimensional data, the actual signal typically lies in lower-dimensional structures. These lower dimensional objects provide useful insight, with interpretability favored by sparse structures. Sparsity, in addition, is beneficial in terms of regularization and, thus, to avoid over-fitting. By exploiting Bayesian shrinkage priors, we devise a computationally convenient approach for high-dimensional matrix factorization. The dependence between row and column entities is modeled by inducing flexible sparse patterns within factors. The availability of external information is accounted for in such a way that structures are allowed while not imposed. Inspired by boosting algorithms, we pair the the proposed approach with a numerical strategy relying on a sequential inclusion and estimation of low-rank contributions, with data-driven stopping rule. Practical advantages of the proposed approach are demonstrated by means of a simulation study and the analysis of soccer heatmaps obtained from new generation tracking data.
Shape-Aware Fine-Grained Classification of Erythroid Cells
Dec 28, 2022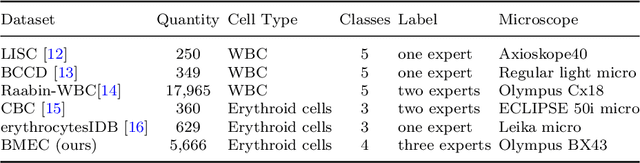
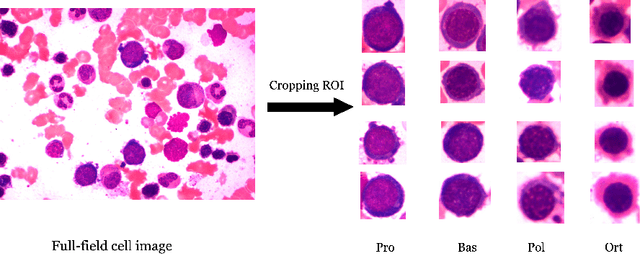
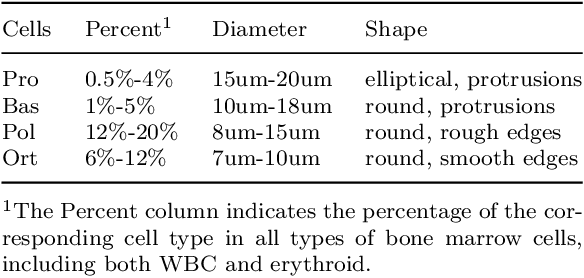
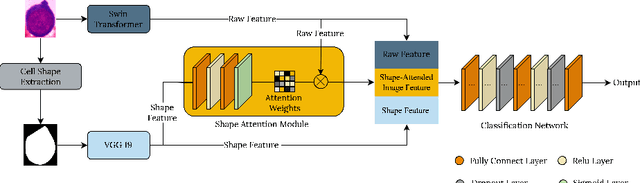
Fine-grained classification and counting of bone marrow erythroid cells are vital for evaluating the health status and formulating therapeutic schedules for leukemia or hematopathy. Due to the subtle visual differences between different types of erythroid cells, it is challenging to apply existing image-based deep learning models for fine-grained erythroid cell classification. Moreover, there is no large open-source datasets on erythroid cells to support the model training. In this paper, we introduce BMEC (Bone Morrow Erythroid Cells), the first large fine-grained image dataset of erythroid cells, to facilitate more deep learning research on erythroid cells. BMEC contains 5,666 images of individual erythroid cells, each of which is extracted from the bone marrow erythroid cell smears and professionally annotated to one of the four types of erythroid cells. To distinguish the erythroid cells, one key indicator is the cell shape which is closely related to the cell growth and maturation. Therefore, we design a novel shape-aware image classification network for fine-grained erythroid cell classification. The shape feature is extracted from the shape mask image and aggregated to the raw image feature with a shape attention module. With the shape-attended image feature, our network achieved superior classification performance (81.12\% top-1 accuracy) on the BMEC dataset comparing to the baseline methods. Ablation studies also demonstrate the effectiveness of incorporating the shape information for the fine-grained cell classification. To further verify the generalizability of our method, we tested our network on two additional public white blood cells (WBC) datasets and the results show our shape-aware method can generally outperform recent state-of-the-art works on classifying the WBC. The code and BMEC dataset can be found on https://github.com/wangye8899/BMEC.
Planning with Large Language Models via Corrective Re-prompting
Nov 17, 2022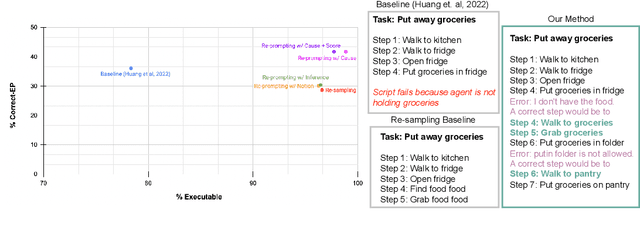
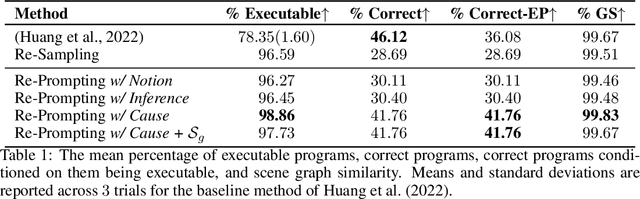
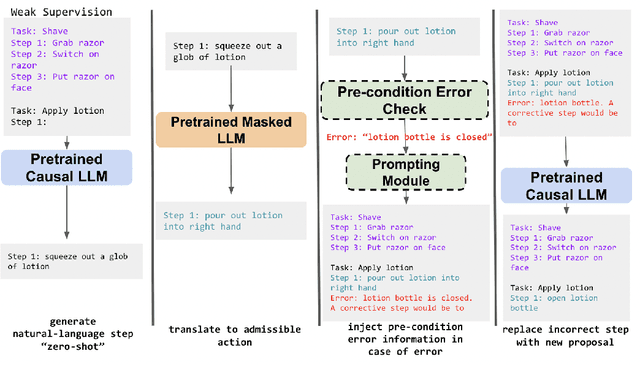
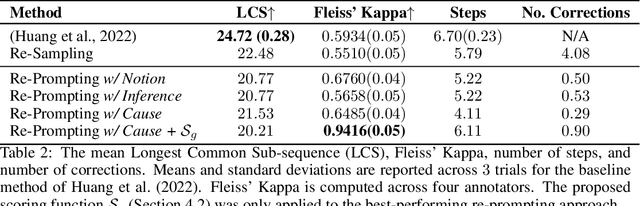
Extracting the common sense knowledge present in Large Language Models (LLMs) offers a path to designing intelligent, embodied agents. Related works have queried LLMs with a wide-range of contextual information, such as goals, sensor observations and scene descriptions, to generate high-level action plans for specific tasks; however these approaches often involve human intervention or additional machinery to enable sensor-motor interactions. In this work, we propose a prompting-based strategy for extracting executable plans from an LLM, which leverages a novel and readily-accessible source of information: precondition errors. Our approach assumes that actions are only afforded execution in certain contexts, i.e., implicit preconditions must be met for an action to execute (e.g., a door must be unlocked to open it), and that the embodied agent has the ability to determine if the action is/is not executable in the current context (e.g., detect if a precondition error is present). When an agent is unable to execute an action, our approach re-prompts the LLM with precondition error information to extract an executable corrective action to achieve the intended goal in the current context. We evaluate our approach in the VirtualHome simulation environment on 88 different tasks and 7 scenes. We evaluate different prompt templates and compare to methods that naively re-sample actions from the LLM. Our approach, using precondition errors, improves executability and semantic correctness of plans, while also reducing the number of re-prompts required when querying actions.
Research on Domain Information Mining and Theme Evolution of Scientific Papers
Apr 18, 2022In recent years, with the increase of social investment in scientific research, the number of research results in various fields has increased significantly. Cross-disciplinary research results have gradually become an emerging frontier research direction. There is a certain dependence between a large number of research results. It is difficult to effectively analyze today's scientific research results when looking at a single research field in isolation. How to effectively use the huge number of scientific papers to help researchers becomes a challenge. This paper introduces the research status at home and abroad in terms of domain information mining and topic evolution law of scientific and technological papers from three aspects: the semantic feature representation learning of scientific and technological papers, the field information mining of scientific and technological papers, and the mining and prediction of research topic evolution rules of scientific and technological papers.
Analyzing Process-Aware Information System Updates Using Digital Twins of Organizations
Mar 24, 2022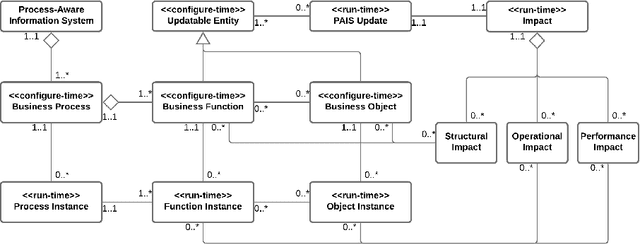
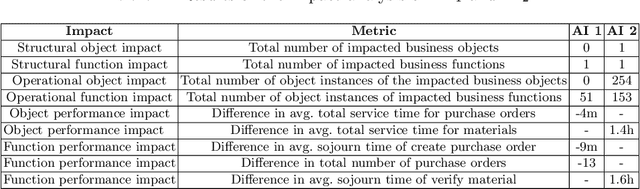

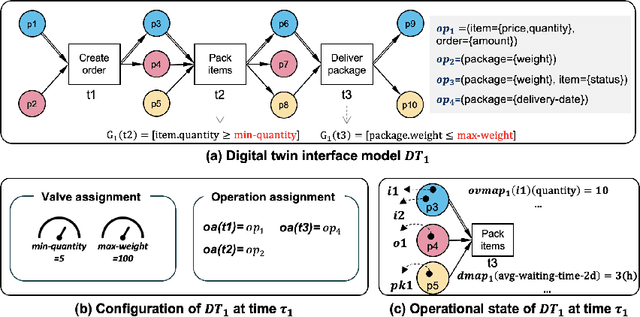
Digital transformation often entails small-scale changes to information systems supporting the execution of business processes. These changes may increase the operational frictions in process execution, which decreases the process performance. The contributions in the literature providing support to the tracking and impact analysis of small-scale changes are limited in scope and functionality. In this paper, we use the recently developed Digital Twins of Organizations (DTOs) to assess the impact of (process-aware) information systems updates. More in detail, we model the updates using the configuration of DTOs and quantitatively assess different types of impacts of information system updates (structural, operational, and performance-related). We implemented a prototype of the proposed approach. Moreover, we discuss a case study involving a standard ERP procure-to-pay business process.
Explainable Machine Learning for Hydrocarbon Prospect Risking
Dec 15, 2022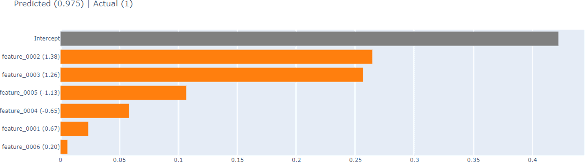
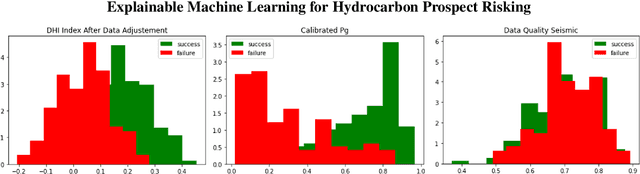
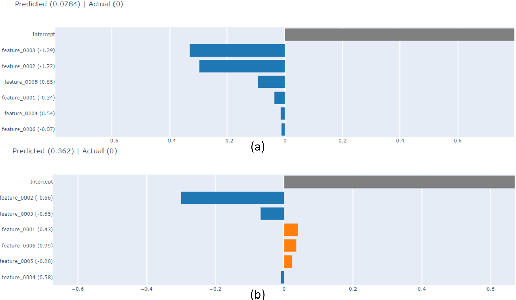
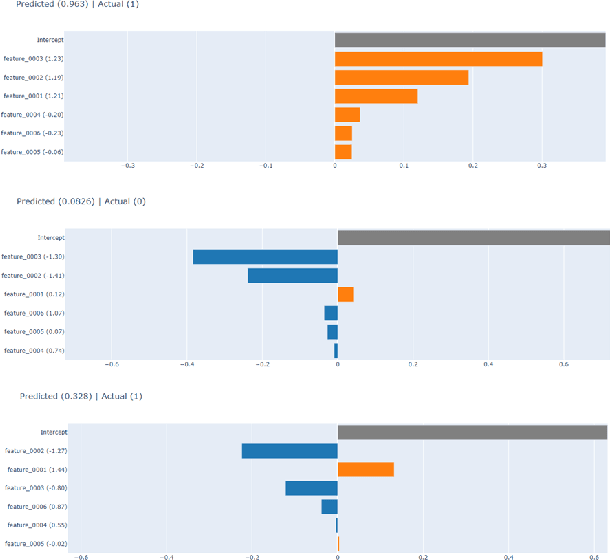
Hydrocarbon prospect risking is a critical application in geophysics predicting well outcomes from a variety of data including geological, geophysical, and other information modalities. Traditional routines require interpreters to go through a long process to arrive at the probability of success of specific outcomes. AI has the capability to automate the process but its adoption has been limited thus far owing to a lack of transparency in the way complicated, black box models generate decisions. We demonstrate how LIME -- a model-agnostic explanation technique -- can be used to inject trust in model decisions by uncovering the model's reasoning process for individual predictions. It generates these explanations by fitting interpretable models in the local neighborhood of specific datapoints being queried. On a dataset of well outcomes and corresponding geophysical attribute data, we show how LIME can induce trust in model's decisions by revealing the decision-making process to be aligned to domain knowledge. Further, it has the potential to debug mispredictions made due to anomalous patterns in the data or faulty training datasets.
Gaussian Process Mapping of Uncertain Building Models with GMM as Prior
Dec 15, 2022
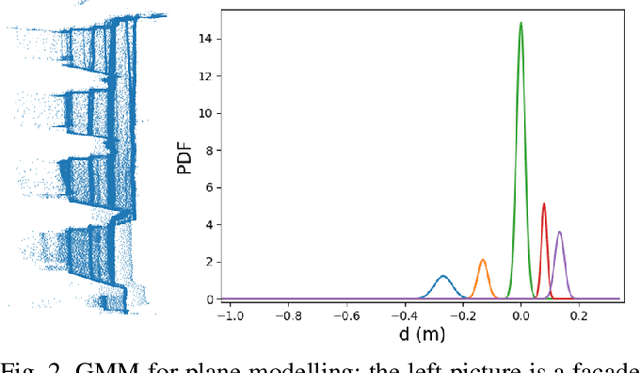
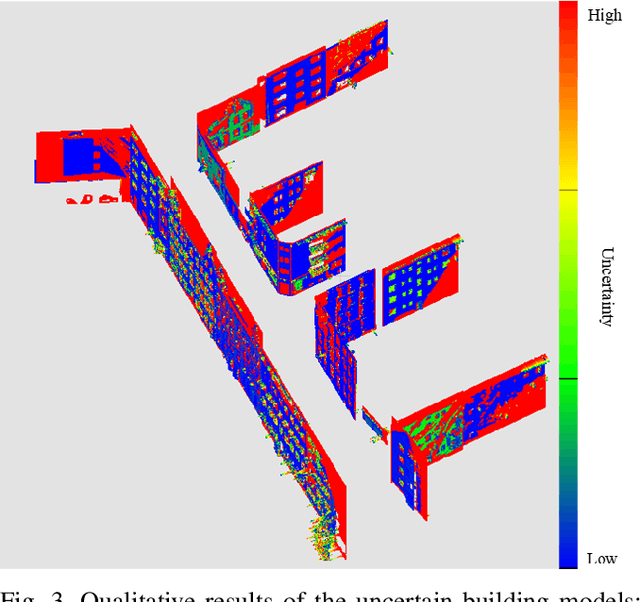
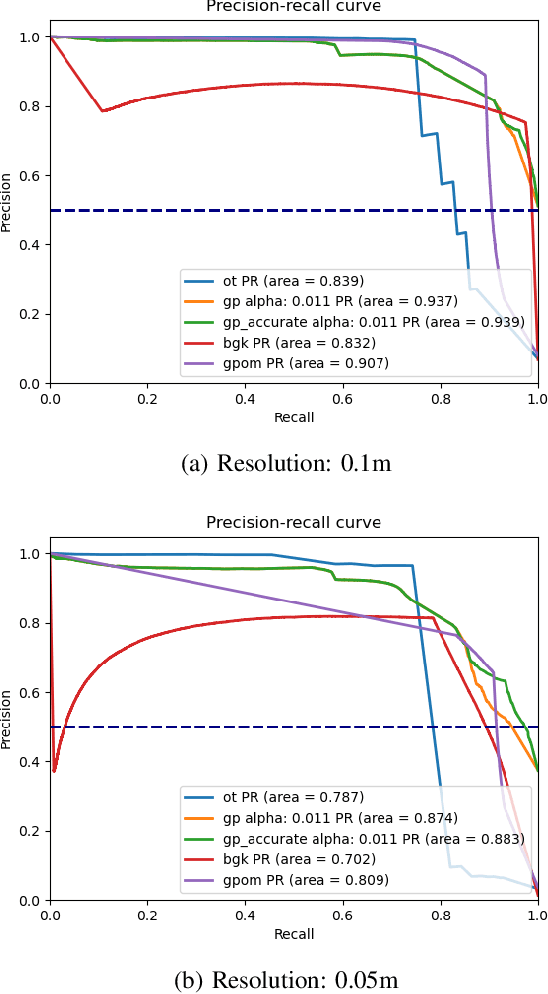
Mapping with uncertainty representation is required in many research domains, such as localization and sensor fusion. Although there are many uncertainty explorations in pose estimation of an ego-robot with map information, the quality of the reference maps is often neglected. To avoid the potential problems caused by the errors of maps and a lack of the uncertainty quantification, an adequate uncertainty measure for the maps is required. In this paper, uncertain building models with abstract map surface using Gaussian Process (GP) is proposed to measure the map uncertainty in a probabilistic way. To reduce the redundant computation for simple planar objects, extracted facets from a Gaussian Mixture Model (GMM) are combined with the implicit GP map while local GP-block techniques are used as well. The proposed method is evaluated on LiDAR point clouds of city buildings collected by a mobile mapping system. Compared to the performances of other methods such like Octomap, Gaussian Process Occupancy Map (GPOM) and Bayersian Generalized Kernel Inference (BGKOctomap), our method has achieved higher Precision-Recall AUC for evaluated buildings.