 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Variational Factorization Machines for Preference Elicitation in Large-Scale Recommender Systems
Dec 20, 2022
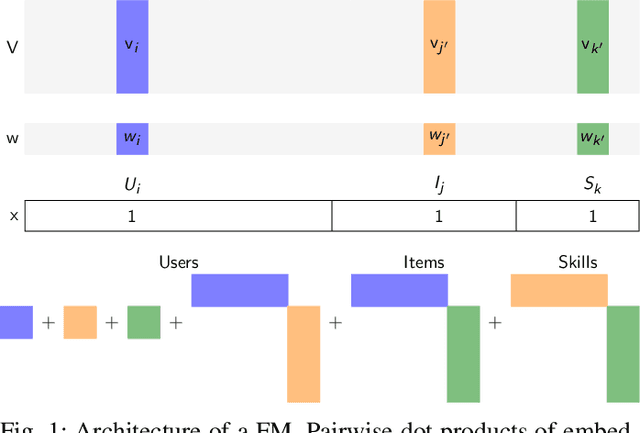
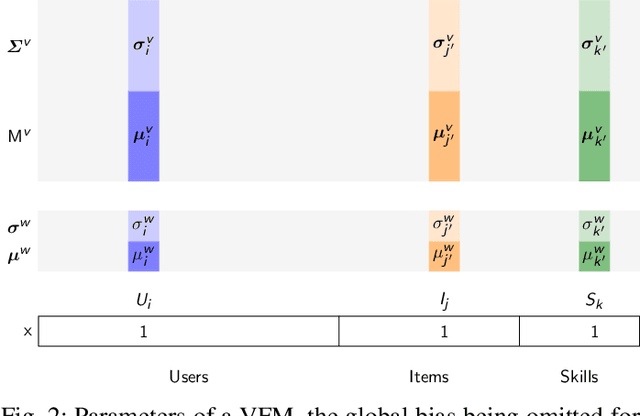
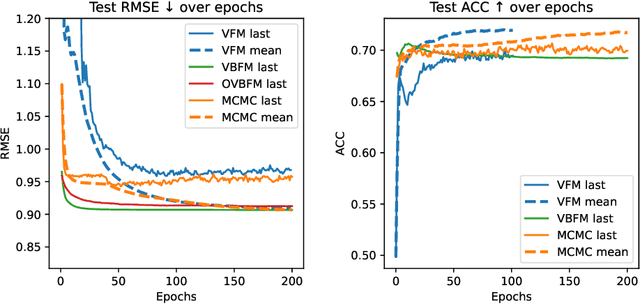
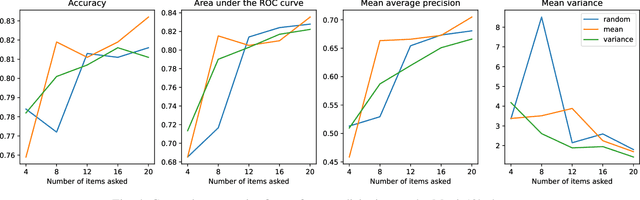
Factorization machines (FMs) are a powerful tool for regression and classification in the context of sparse observations, that has been successfully applied to collaborative filtering, especially when side information over users or items is available. Bayesian formulations of FMs have been proposed to provide confidence intervals over the predictions made by the model, however they usually involve Markov-chain Monte Carlo methods that require many samples to provide accurate predictions, resulting in slow training in the context of large-scale data. In this paper, we propose a variational formulation of factorization machines that allows us to derive a simple objective that can be easily optimized using standard mini-batch stochastic gradient descent, making it amenable to large-scale data. Our algorithm learns an approximate posterior distribution over the user and item parameters, which leads to confidence intervals over the predictions. We show, using several datasets, that it has comparable or better performance than existing methods in terms of prediction accuracy, and provide some applications in active learning strategies, e.g., preference elicitation techniques.
A Recursively Recurrent Neural Network (R2N2) Architecture for Learning Iterative Algorithms
Nov 22, 2022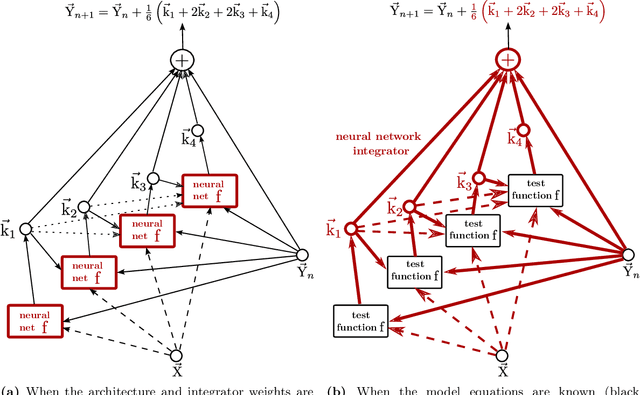
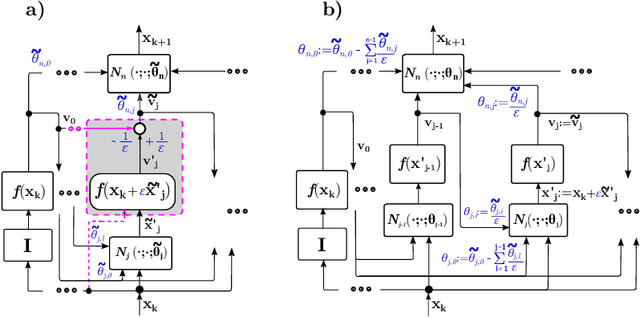
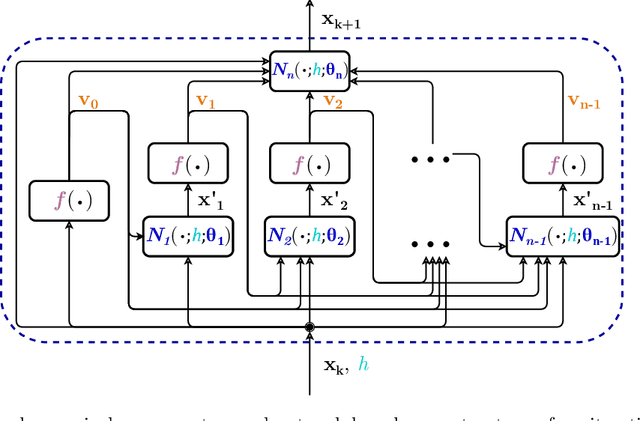
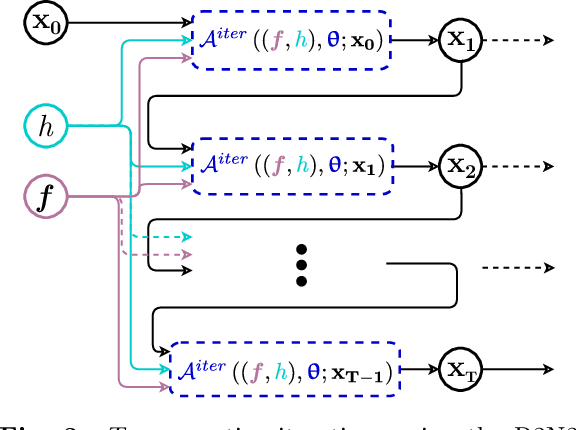
Meta-learning of numerical algorithms for a given task consist of the data-driven identification and adaptation of an algorithmic structure and the associated hyperparameters. To limit the complexity of the meta-learning problem, neural architectures with a certain inductive bias towards favorable algorithmic structures can, and should, be used. We generalize our previously introduced Runge-Kutta neural network to a recursively recurrent neural network (R2N2) superstructure for the design of customized iterative algorithms. In contrast to off-the-shelf deep learning approaches, it features a distinct division into modules for generation of information and for the subsequent assembly of this information towards a solution. Local information in the form of a subspace is generated by subordinate, inner, iterations of recurrent function evaluations starting at the current outer iterate. The update to the next outer iterate is computed as a linear combination of these evaluations, reducing the residual in this space, and constitutes the output of the network. We demonstrate that regular training of the weight parameters inside the proposed superstructure on input/output data of various computational problem classes yields iterations similar to Krylov solvers for linear equation systems, Newton-Krylov solvers for nonlinear equation systems, and Runge-Kutta integrators for ordinary differential equations. Due to its modularity, the superstructure can be readily extended with functionalities needed to represent more general classes of iterative algorithms traditionally based on Taylor series expansions.
Direct Speech-to-speech Translation without Textual Annotation using Bottleneck Features
Dec 12, 2022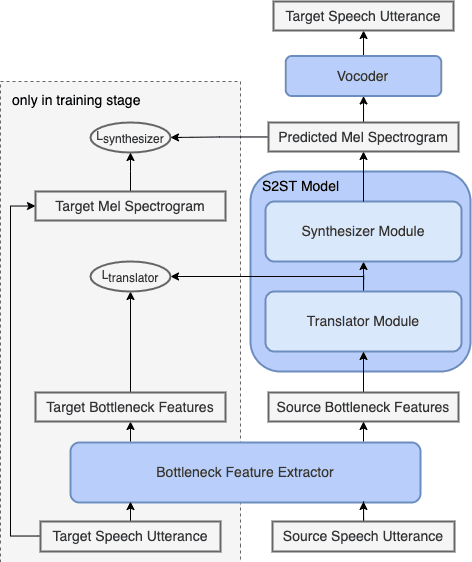

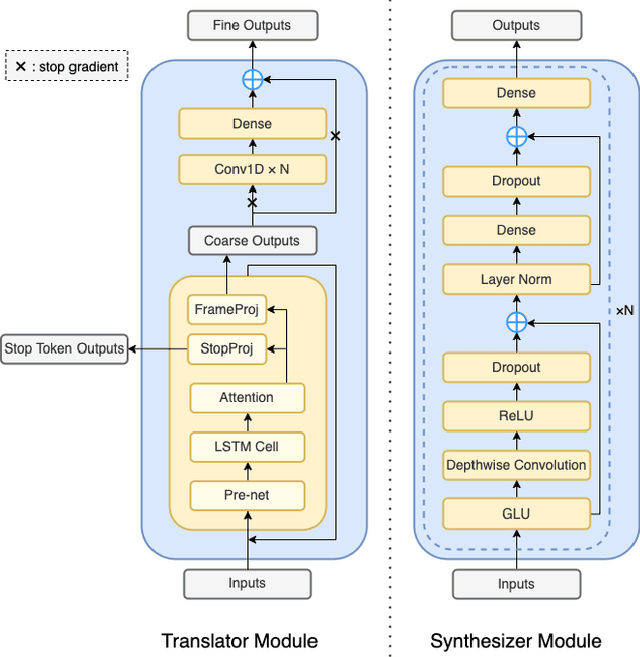

Speech-to-speech translation directly translates a speech utterance to another between different languages, and has great potential in tasks such as simultaneous interpretation. State-of-art models usually contains an auxiliary module for phoneme sequences prediction, and this requires textual annotation of the training dataset. We propose a direct speech-to-speech translation model which can be trained without any textual annotation or content information. Instead of introducing an auxiliary phoneme prediction task in the model, we propose to use bottleneck features as intermediate training objectives for our model to ensure the translation performance of the system. Experiments on Mandarin-Cantonese speech translation demonstrate the feasibility of the proposed approach and the performance can match a cascaded system with respect of translation and synthesis qualities.
SMMix: Self-Motivated Image Mixing for Vision Transformers
Dec 26, 2022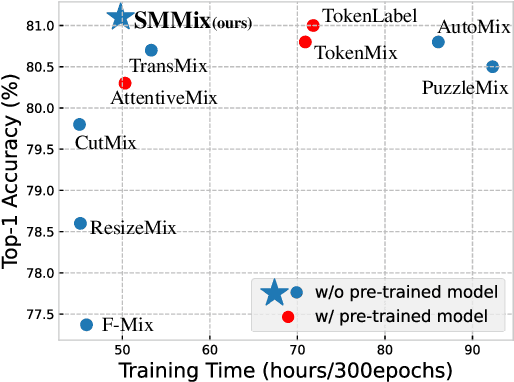
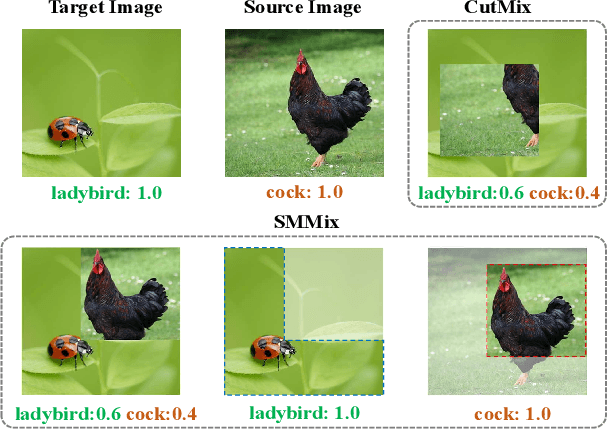
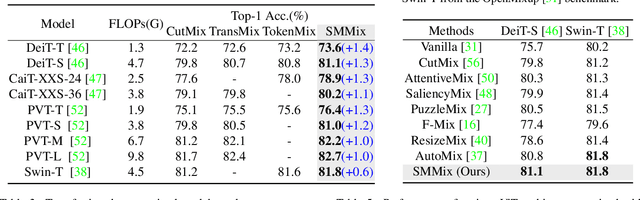
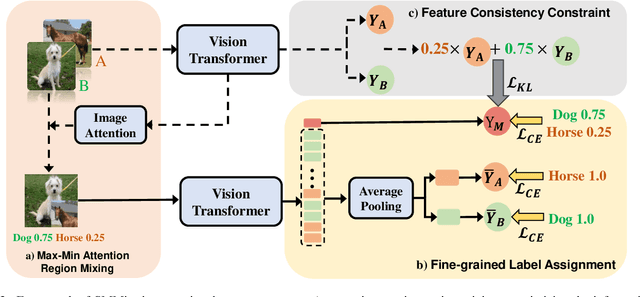
CutMix is a vital augmentation strategy that determines the performance and generalization ability of vision transformers (ViTs). However, the inconsistency between the mixed images and the corresponding labels harms its efficacy. Existing CutMix variants tackle this problem by generating more consistent mixed images or more precise mixed labels, but inevitably introduce heavy training overhead or require extra information, undermining ease of use. To this end, we propose an efficient and effective Self-Motivated image Mixing method (SMMix), which motivates both image and label enhancement by the model under training itself. Specifically, we propose a max-min attention region mixing approach that enriches the attention-focused objects in the mixed images. Then, we introduce a fine-grained label assignment technique that co-trains the output tokens of mixed images with fine-grained supervision. Moreover, we devise a novel feature consistency constraint to align features from mixed and unmixed images. Due to the subtle designs of the self-motivated paradigm, our SMMix is significant in its smaller training overhead and better performance than other CutMix variants. In particular, SMMix improves the accuracy of DeiT-T/S, CaiT-XXS-24/36, and PVT-T/S/M/L by more than +1% on ImageNet-1k. The generalization capability of our method is also demonstrated on downstream tasks and out-of-distribution datasets. Code of this project is available at https://github.com/ChenMnZ/SMMix.
Packing Privacy Budget Efficiently
Dec 26, 2022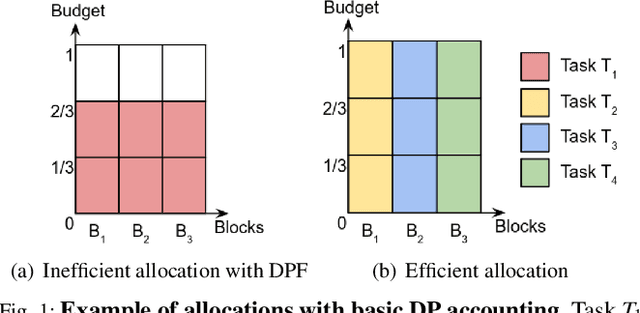
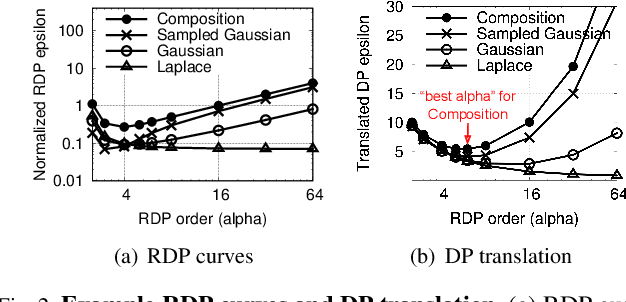
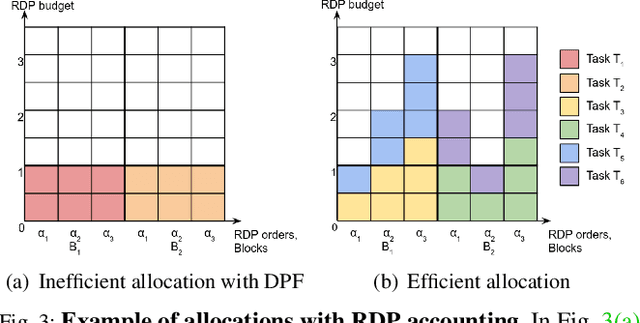
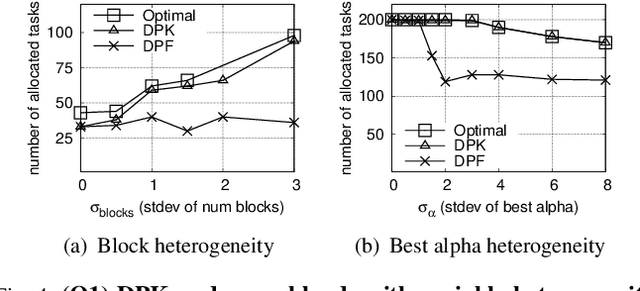
Machine learning (ML) models can leak information about users, and differential privacy (DP) provides a rigorous way to bound that leakage under a given budget. This DP budget can be regarded as a new type of compute resource in workloads of multiple ML models training on user data. Once it is used, the DP budget is forever consumed. Therefore, it is crucial to allocate it most efficiently to train as many models as possible. This paper presents the scheduler for privacy that optimizes for efficiency. We formulate privacy scheduling as a new type of multidimensional knapsack problem, called privacy knapsack, which maximizes DP budget efficiency. We show that privacy knapsack is NP-hard, hence practical algorithms are necessarily approximate. We develop an approximation algorithm for privacy knapsack, DPK, and evaluate it on microbenchmarks and on a new, synthetic private-ML workload we developed from the Alibaba ML cluster trace. We show that DPK: (1) often approaches the efficiency-optimal schedule, (2) consistently schedules more tasks compared to a state-of-the-art privacy scheduling algorithm that focused on fairness (1.3-1.7x in Alibaba, 1.0-2.6x in microbenchmarks), but (3) sacrifices some level of fairness for efficiency. Therefore, using DPK, DP ML operators should be able to train more models on the same amount of user data while offering the same privacy guarantee to their users.
TypeFormer: Transformers for Mobile Keystroke Biometrics
Dec 26, 2022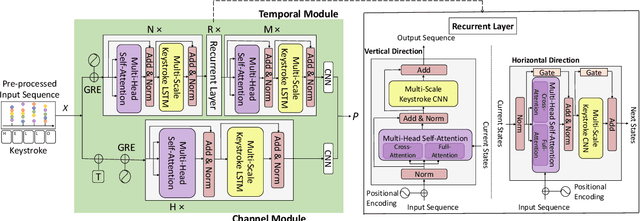
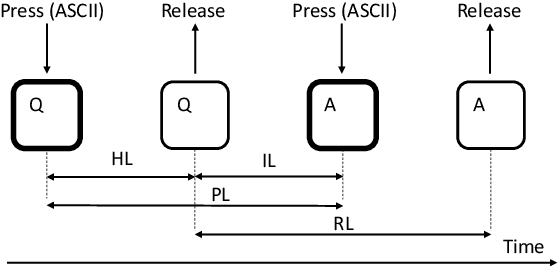
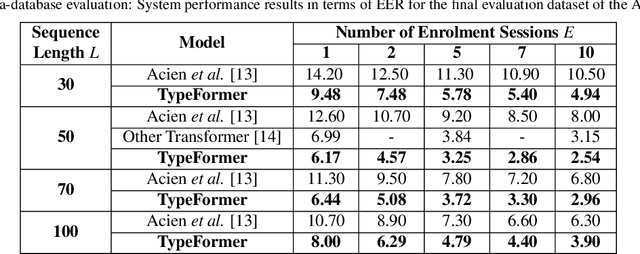
The broad usage of mobile devices nowadays, the sensitiveness of the information contained in them, and the shortcomings of current mobile user authentication methods are calling for novel, secure, and unobtrusive solutions to verify the users' identity. In this article, we propose TypeFormer, a novel Transformer architecture to model free-text keystroke dynamics performed on mobile devices for the purpose of user authentication. The proposed model consists in Temporal and Channel Modules enclosing two Long Short-Term Memory (LSTM) recurrent layers, Gaussian Range Encoding (GRE), a multi-head Self-Attention mechanism, and a Block-Recurrent structure. Experimenting on one of the largest public databases to date, the Aalto mobile keystroke database, TypeFormer outperforms current state-of-the-art systems achieving Equal Error Rate (EER) values of 3.25% using only 5 enrolment sessions of 50 keystrokes each. In such way, we contribute to reducing the traditional performance gap of the challenging mobile free-text scenario with respect to its desktop and fixed-text counterparts. Additionally, we analyse the behaviour of the model with different experimental configurations such as the length of the keystroke sequences and the amount of enrolment sessions, showing margin for improvement with more enrolment data. Finally, a cross-database evaluation is carried out, demonstrating the robustness of the features extracted by TypeFormer in comparison with existing approaches.
A Topic Modeling Approach to Classifying Open Street Map Health Clinics and Schools in Sub-Saharan Africa
Dec 22, 2022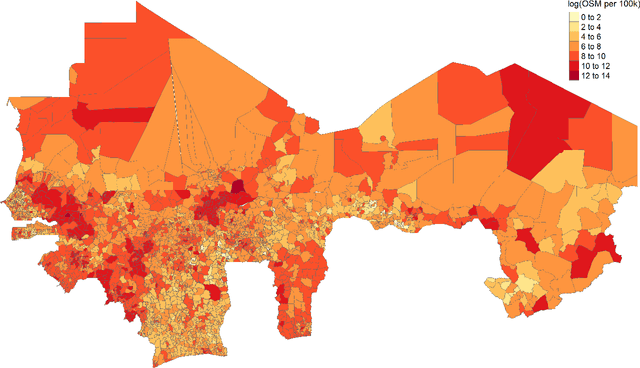
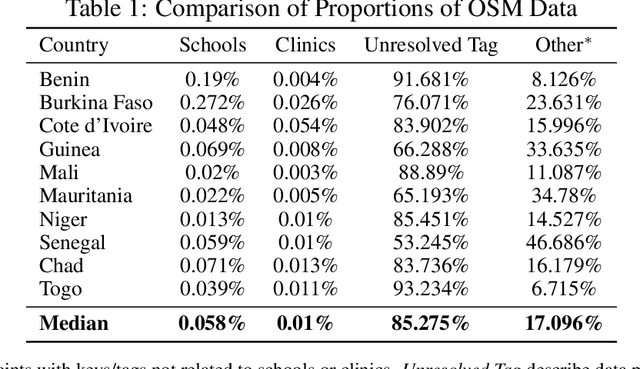
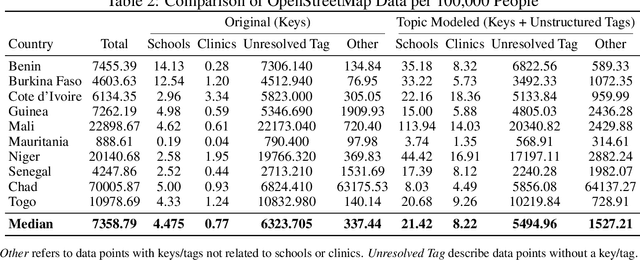
Data deprivation, or the lack of easily available and actionable information on the well-being of individuals, is a significant challenge for the developing world and an impediment to the design and operationalization of policies intended to alleviate poverty. In this paper we explore the suitability of data derived from OpenStreetMap to proxy for the location of two crucial public services: schools and health clinics. Thanks to the efforts of thousands of digital humanitarians, online mapping repositories such as OpenStreetMap contain millions of records on buildings and other structures, delineating both their location and often their use. Unfortunately much of this data is locked in complex, unstructured text rendering it seemingly unsuitable for classifying schools or clinics. We apply a scalable, unsupervised learning method to unlabeled OpenStreetMap building data to extract the location of schools and health clinics in ten countries in Africa. We find the topic modeling approach greatly improves performance versus reliance on structured keys alone. We validate our results by comparing schools and clinics identified by our OSM method versus those identified by the WHO, and describe OSM coverage gaps more broadly.
Realizing Molecular Machine Learning through Communications for Biological AI: Future Directions and Challenges
Dec 22, 2022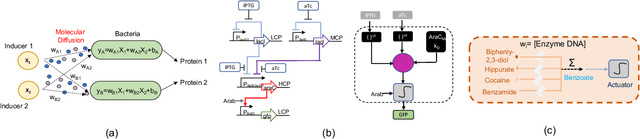
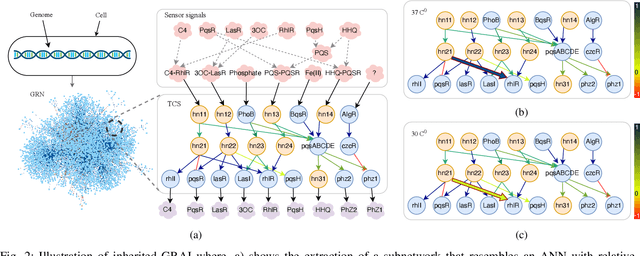
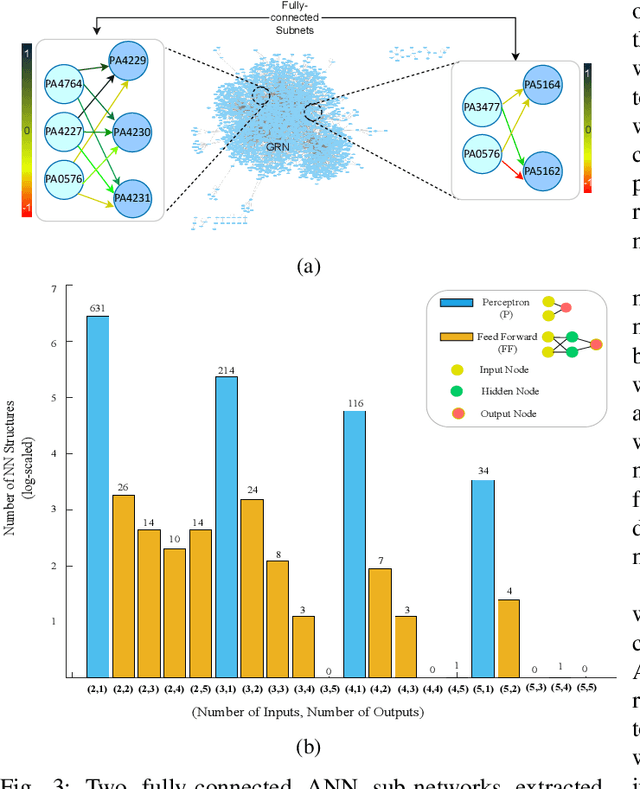
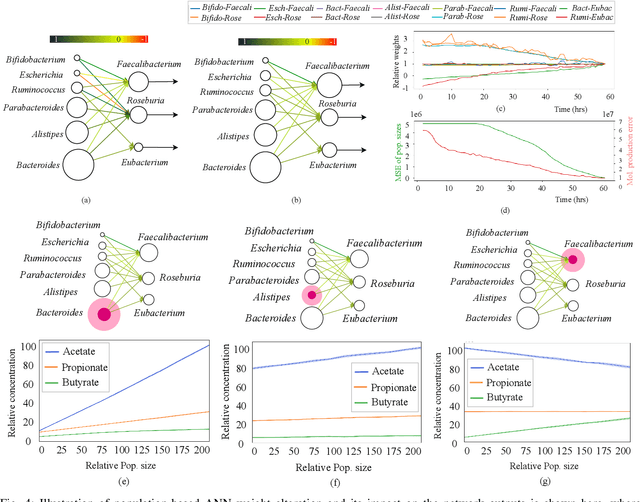
Artificial Intelligence (AI) and Machine Learning (ML) are weaving their way into the fabric of society, where they are playing a crucial role in numerous facets of our lives. As we witness the increased deployment of AI and ML in various types of devices, we benefit from their use into energy-efficient algorithms for low powered devices. In this paper, we investigate a scale and medium that is far smaller than conventional devices as we move towards molecular systems that can be utilized to perform machine learning functions, i.e., Molecular Machine Learning (MML). Fundamental to the operation of MML is the transport, processing, and interpretation of information propagated by molecules through chemical reactions. We begin by reviewing the current approaches that have been developed for MML, before we move towards potential new directions that rely on gene regulatory networks inside biological organisms as well as their population interactions to create neural networks. We then investigate mechanisms for training machine learning structures in biological cells based on calcium signaling and demonstrate their application to build an Analog to Digital Converter (ADC). Lastly, we look at potential future directions as well as challenges that this area could solve.
Efficient Induction of Language Models Via Probabilistic Concept Formation
Dec 22, 2022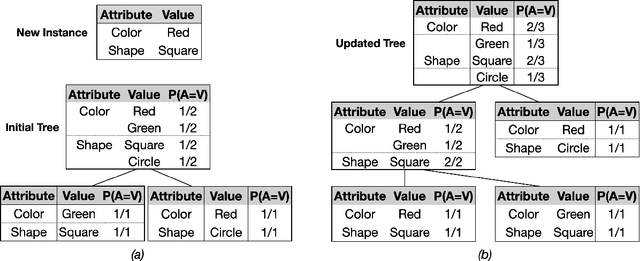

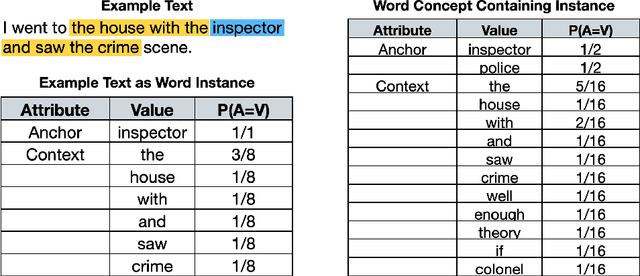

This paper presents a novel approach to the acquisition of language models from corpora. The framework builds on Cobweb, an early system for constructing taxonomic hierarchies of probabilistic concepts that used a tabular, attribute-value encoding of training cases and concepts, making it unsuitable for sequential input like language. In response, we explore three new extensions to Cobweb -- the Word, Leaf, and Path variants. These systems encode each training case as an anchor word and surrounding context words, and they store probabilistic descriptions of concepts as distributions over anchor and context information. As in the original Cobweb, a performance element sorts a new instance downward through the hierarchy and uses the final node to predict missing features. Learning is interleaved with performance, updating concept probabilities and hierarchy structure as classification occurs. Thus, the new approaches process training cases in an incremental, online manner that it very different from most methods for statistical language learning. We examine how well the three variants place synonyms together and keep homonyms apart, their ability to recall synonyms as a function of training set size, and their training efficiency. Finally, we discuss related work on incremental learning and directions for further research.
Progressively Dual Prior Guided Few-shot Semantic Segmentation
Nov 20, 2022
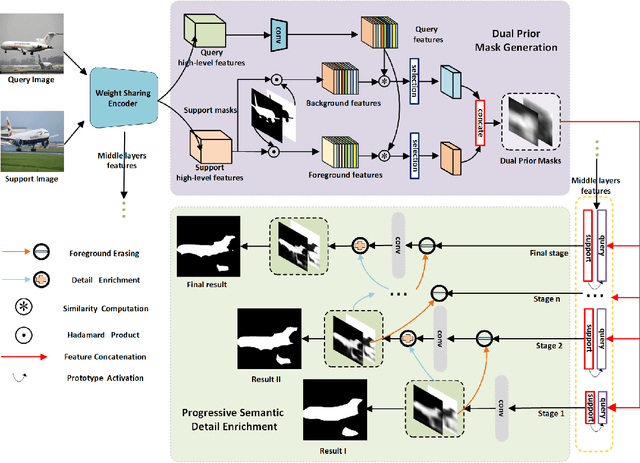
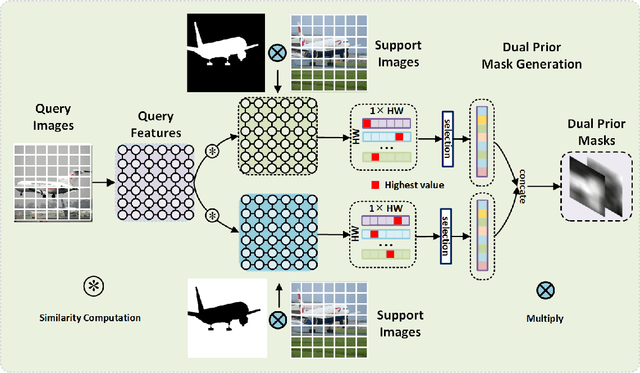
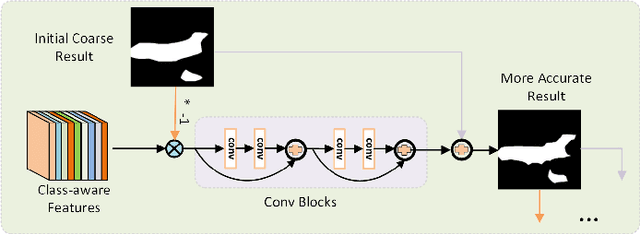
Few-shot semantic segmentation task aims at performing segmentation in query images with a few annotated support samples. Currently, few-shot segmentation methods mainly focus on leveraging foreground information without fully utilizing the rich background information, which could result in wrong activation of foreground-like background regions with the inadaptability to dramatic scene changes of support-query image pairs. Meanwhile, the lack of detail mining mechanism could cause coarse parsing results without some semantic components or edge areas since prototypes have limited ability to cope with large object appearance variance. To tackle these problems, we propose a progressively dual prior guided few-shot semantic segmentation network. Specifically, a dual prior mask generation (DPMG) module is firstly designed to suppress the wrong activation in foreground-background comparison manner by regarding background as assisted refinement information. With dual prior masks refining the location of foreground area, we further propose a progressive semantic detail enrichment (PSDE) module which forces the parsing model to capture the hidden semantic details by iteratively erasing the high-confidence foreground region and activating details in the rest region with a hierarchical structure. The collaboration of DPMG and PSDE formulates a novel few-shot segmentation network that can be learned in an end-to-end manner. Comprehensive experiments on PASCAL-5i and MS COCO powerfully demonstrate that our proposed algorithm achieves the great performance.