 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Removing Objects From Neural Radiance Fields
Dec 22, 2022
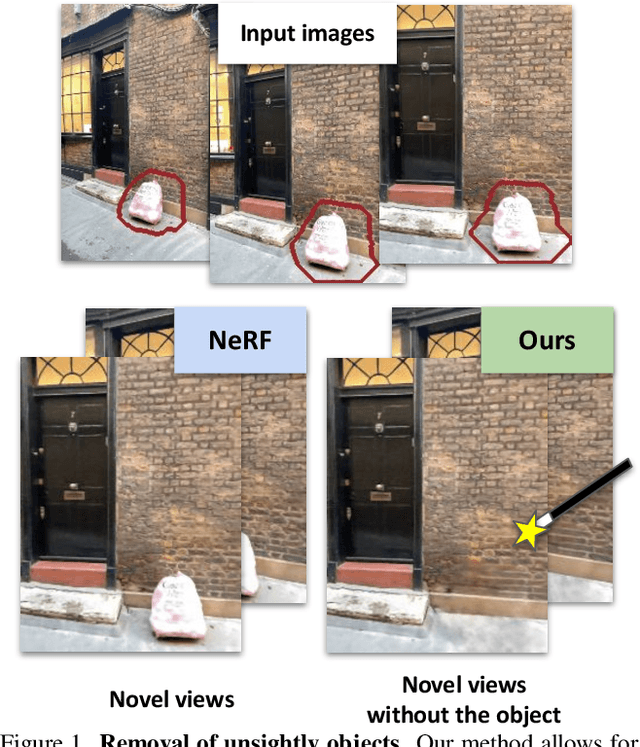
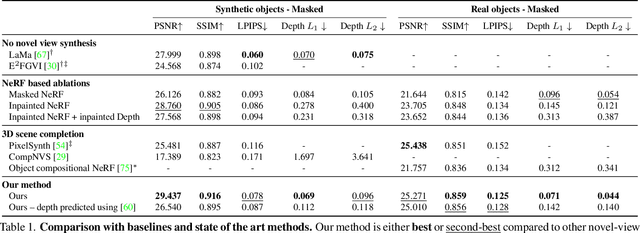

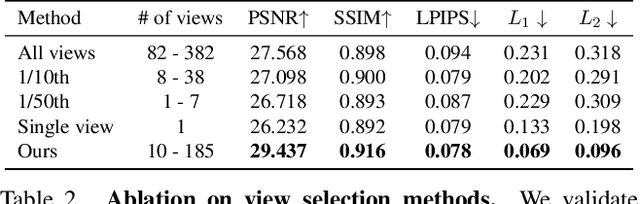
Neural Radiance Fields (NeRFs) are emerging as a ubiquitous scene representation that allows for novel view synthesis. Increasingly, NeRFs will be shareable with other people. Before sharing a NeRF, though, it might be desirable to remove personal information or unsightly objects. Such removal is not easily achieved with the current NeRF editing frameworks. We propose a framework to remove objects from a NeRF representation created from an RGB-D sequence. Our NeRF inpainting method leverages recent work in 2D image inpainting and is guided by a user-provided mask. Our algorithm is underpinned by a confidence based view selection procedure. It chooses which of the individual 2D inpainted images to use in the creation of the NeRF, so that the resulting inpainted NeRF is 3D consistent. We show that our method for NeRF editing is effective for synthesizing plausible inpaintings in a multi-view coherent manner. We validate our approach using a new and still-challenging dataset for the task of NeRF inpainting.
Secrecy Rate Maximization of RIS-assisted SWIPT Systems: A Two-Timescale Beamforming Design Approach
Nov 30, 2022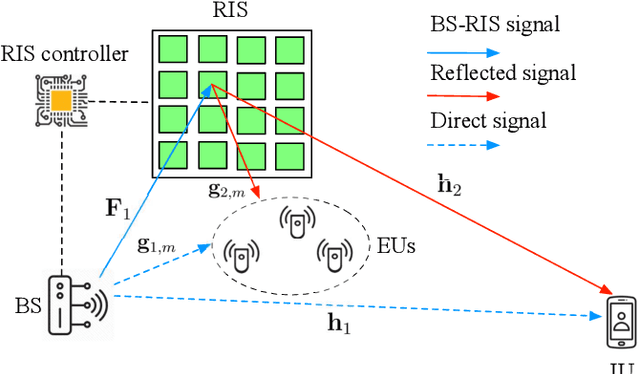
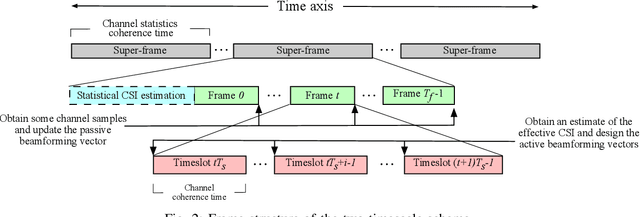
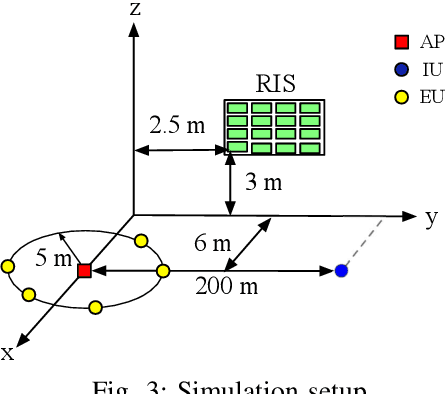
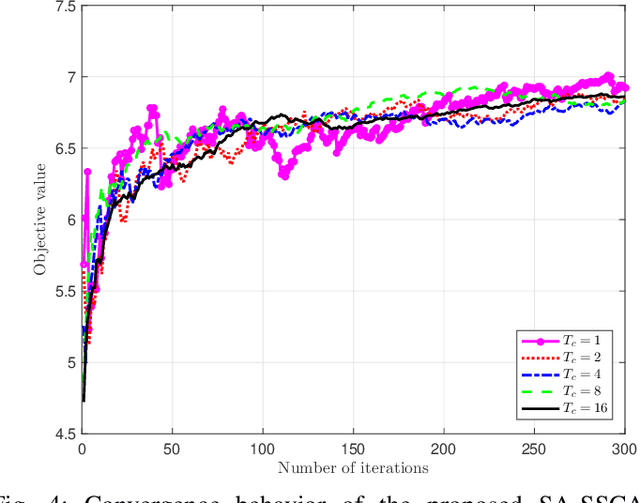
Reconfigurable intelligent surfaces (RISs) achieve high passive beamforming gains for signal enhancement or interference nulling by dynamically adjusting their reflection coefficients. Their employment is particularly appealing for improving both the wireless security and the efficiency of radio frequency (RF)-based wireless power transfer. Motivated by this, we conceive and investigate a RIS-assisted secure simultaneous wireless information and power transfer (SWIPT) system designed for information and power transfer from a base station (BS) to an information user (IU) and to multiple energy users (EUs), respectively. Moreover, the EUs are also potential eavesdroppers that may overhear the communication between the BS and IU. We adopt two-timescale transmission for reducing the signal processing complexity as well as channel training overhead, and aim for maximizing the average worst-case secrecy rate achieved by the IU. This is achieved by jointly optimizing the short-term transmit beamforming vectors at the BS as well as the long-term phase shifts at the RIS, under the energy harvesting constraints considered at the EUs and the power constraint at the BS. The stochastic optimization problem formulated is non-convex with intricately coupled variables, and is non-smooth due to the existence of multiple EUs/eavesdroppers. No standard optimization approach is available for this challenging scenario. To tackle this challenge, we propose a smooth approximation aided stochastic successive convex approximation (SA-SSCA) algorithm. Furthermore, a low-complexity heuristic algorithm is proposed for reducing the computational complexity without unduly eroding the performance. Simulation results show the efficiency of the RIS in securing SWIPT systems. The significant performance gains achieved by our proposed algorithms over the relevant benchmark schemes are also demonstrated.
Hidden State Approximation in Recurrent Neural Networks Using Continuous Particle Filtering
Dec 18, 2022
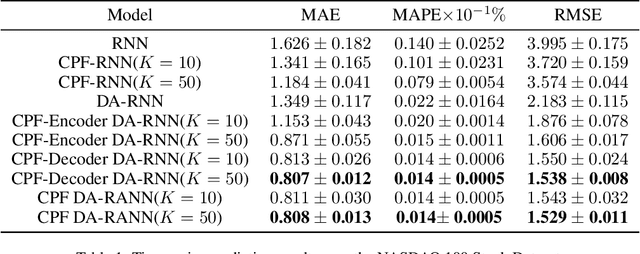
Using historical data to predict future events has many applications in the real world, such as stock price prediction; the robot localization. In the past decades, the Convolutional long short-term memory (LSTM) networks have achieved extraordinary success with sequential data in the related field. However, traditional recurrent neural networks (RNNs) keep the hidden states in a deterministic way. In this paper, we use the particles to approximate the distribution of the latent state and show how it can extend into a more complex form, i.e., the Encoder-Decoder mechanism. With the proposed continuous differentiable scheme, our model is capable of adaptively extracting valuable information and updating the latent state according to the Bayes rule. Our empirical studies demonstrate the effectiveness of our method in the prediction tasks.
LaSQuE: Improved Zero-Shot Classification from Explanations Through Quantifier Modeling and Curriculum Learning
Dec 18, 2022
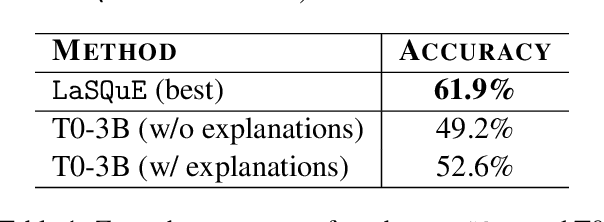
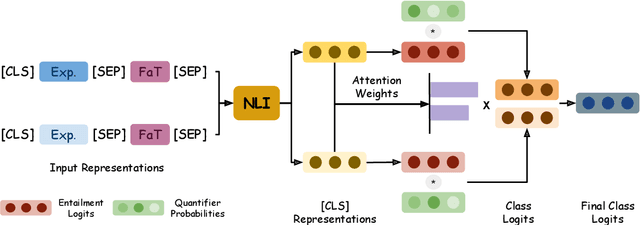

A hallmark of human intelligence is the ability to learn new concepts purely from language. Several recent approaches have explored training machine learning models via natural language supervision. However, these approaches fall short in leveraging linguistic quantifiers (such as 'always' or 'rarely') and mimicking humans in compositionally learning complex tasks. Here, we present LaSQuE, a method that can learn zero-shot classifiers from language explanations by using three new strategies - (1) modeling the semantics of linguistic quantifiers in explanations (including exploiting ordinal strength relationships, such as 'always' > 'likely'), (2) aggregating information from multiple explanations using an attention-based mechanism, and (3) model training via curriculum learning. With these strategies, LaSQuE outperforms prior work, showing an absolute gain of up to 7% in generalizing to unseen real-world classification tasks.
Solving 3D Radar Imaging Inverse Problems with a Multi-cognition Task-oriented Framework
Nov 28, 2022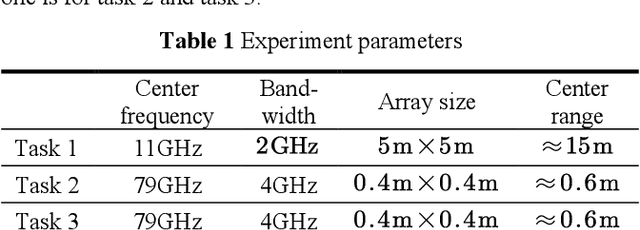
This work focuses on 3D Radar imaging inverse problems. Current methods obtain undifferentiated results that suffer task-depended information retrieval loss and thus don't meet the task's specific demands well. For example, biased scattering energy may be acceptable for screen imaging but not for scattering diagnosis. To address this issue, we propose a new task-oriented imaging framework. The imaging principle is task-oriented through an analysis phase to obtain task's demands. The imaging model is multi-cognition regularized to embed and fulfill demands. The imaging method is designed to be general-ized, where couplings between cognitions are decoupled and solved individually with approximation and variable-splitting techniques. Tasks include scattering diagnosis, person screen imaging, and parcel screening imaging are given as examples. Experiments on data from two systems indicate that the pro-posed framework outperforms the current ones in task-depended information retrieval.
Stereo Image Rain Removal via Dual-View Mutual Attention
Nov 18, 2022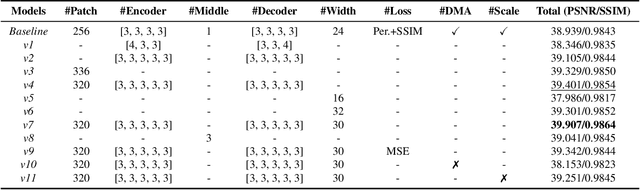

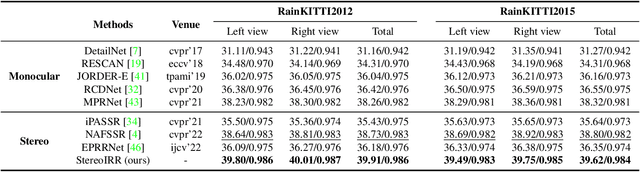
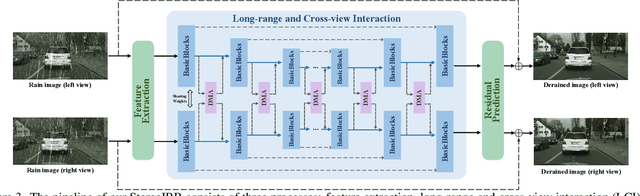
Stereo images, containing left and right view images with disparity, are utilized in solving low-vision tasks recently, e.g., rain removal and super-resolution. Stereo image restoration methods usually obtain better performance than monocular methods by learning the disparity between dual views either implicitly or explicitly. However, existing stereo rain removal methods still cannot make full use of the complementary information between two views, and we find it is because: 1) the rain streaks have more complex distributions in directions and densities, which severely damage the complementary information and pose greater challenges; 2) the disparity estimation is not accurate enough due to the imperfect fusion mechanism for the features between two views. To overcome such limitations, we propose a new \underline{Stereo} \underline{I}mage \underline{R}ain \underline{R}emoval method (StereoIRR) via sufficient interaction between two views, which incorporates: 1) a new Dual-view Mutual Attention (DMA) mechanism which generates mutual attention maps by taking left and right views as key information for each other to facilitate cross-view feature fusion; 2) a long-range and cross-view interaction, which is constructed with basic blocks and dual-view mutual attention, can alleviate the adverse effect of rain on complementary information to help the features of stereo images to get long-range and cross-view interaction and fusion. Notably, StereoIRR outperforms other related monocular and stereo image rain removal methods on several datasets. Our codes and datasets will be released.
Summarizing Community-based Question-Answer Pairs
Nov 17, 2022
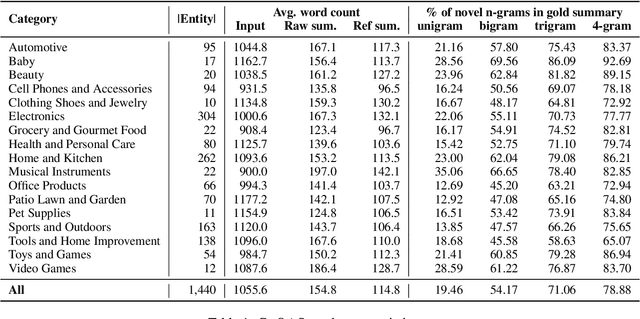
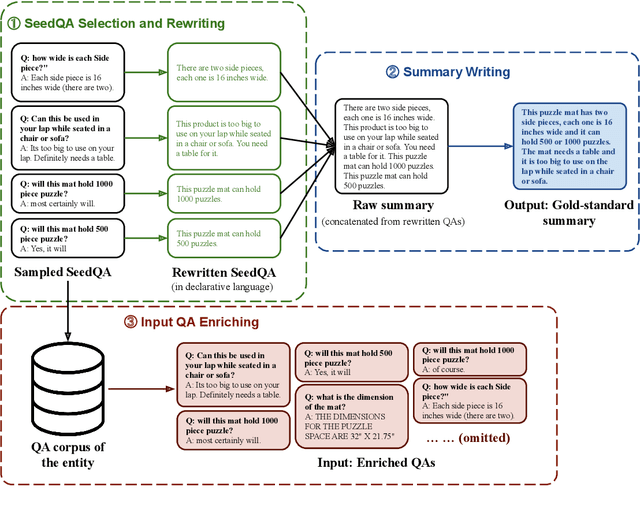
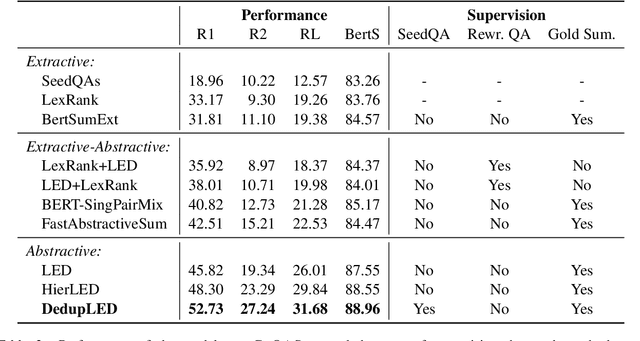
Community-based Question Answering (CQA), which allows users to acquire their desired information, has increasingly become an essential component of online services in various domains such as E-commerce, travel, and dining. However, an overwhelming number of CQA pairs makes it difficult for users without particular intent to find useful information spread over CQA pairs. To help users quickly digest the key information, we propose the novel CQA summarization task that aims to create a concise summary from CQA pairs. To this end, we first design a multi-stage data annotation process and create a benchmark dataset, CoQASUM, based on the Amazon QA corpus. We then compare a collection of extractive and abstractive summarization methods and establish a strong baseline approach DedupLED for the CQA summarization task. Our experiment further confirms two key challenges, sentence-type transfer and deduplication removal, towards the CQA summarization task. Our data and code are publicly available.
Merging Classification Predictions with Sequential Information for Lightweight Visual Place Recognition in Changing Environments
Oct 03, 2022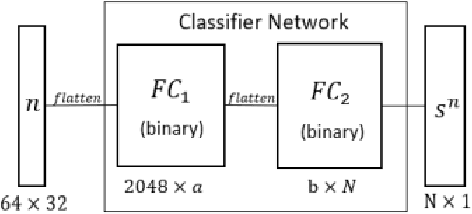
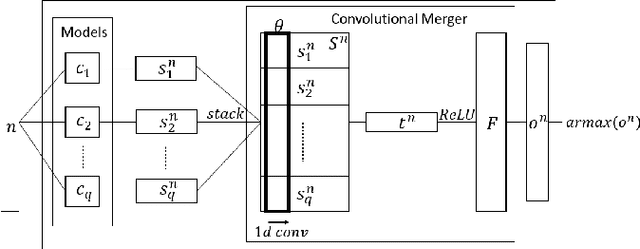
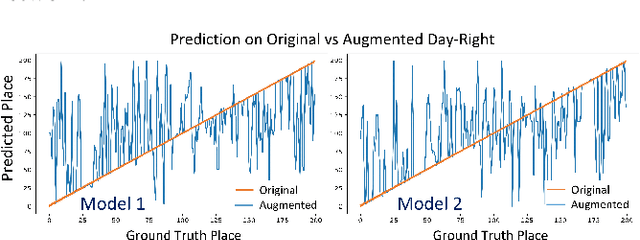
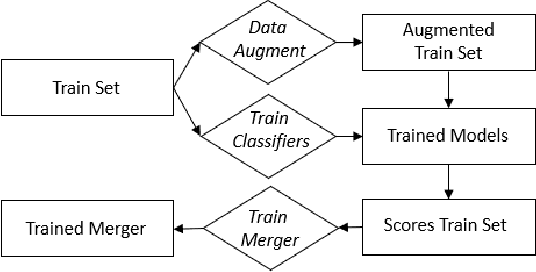
Low-overhead visual place recognition (VPR) is a highly active research topic. Mobile robotics applications often operate under low-end hardware, and even more hardware capable systems can still benefit from freeing up onboard system resources for other navigation tasks. This work addresses lightweight VPR by proposing a novel system based on the combination of binary-weighted classifier networks with a one-dimensional convolutional network, dubbed merger. Recent work in fusing multiple VPR techniques has mainly focused on increasing VPR performance, with computational efficiency not being highly prioritized. In contrast, we design our technique prioritizing low inference times, taking inspiration from the machine learning literature where the efficient combination of classifiers is a heavily researched topic. Our experiments show that the merger achieves inference times as low as 1 millisecond, being significantly faster than other well-established lightweight VPR techniques, while achieving comparable or superior VPR performance on several visual changes such as seasonal variations and viewpoint lateral shifts.
GhostNetV2: Enhance Cheap Operation with Long-Range Attention
Nov 23, 2022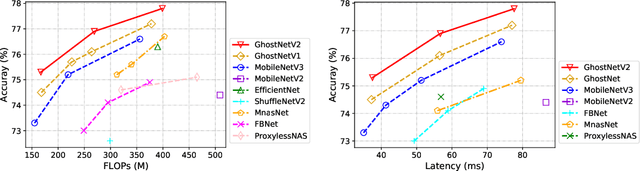
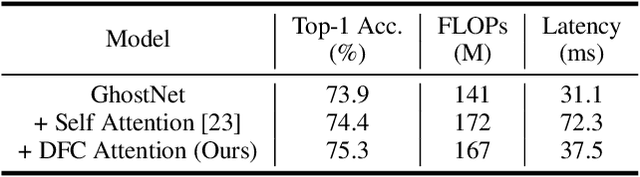
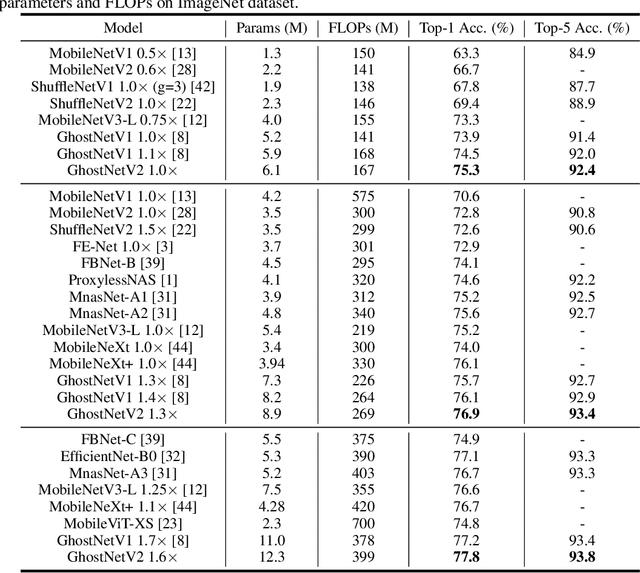
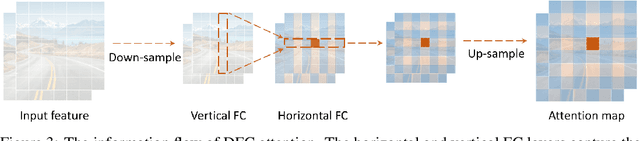
Light-weight convolutional neural networks (CNNs) are specially designed for applications on mobile devices with faster inference speed. The convolutional operation can only capture local information in a window region, which prevents performance from being further improved. Introducing self-attention into convolution can capture global information well, but it will largely encumber the actual speed. In this paper, we propose a hardware-friendly attention mechanism (dubbed DFC attention) and then present a new GhostNetV2 architecture for mobile applications. The proposed DFC attention is constructed based on fully-connected layers, which can not only execute fast on common hardware but also capture the dependence between long-range pixels. We further revisit the expressiveness bottleneck in previous GhostNet and propose to enhance expanded features produced by cheap operations with DFC attention, so that a GhostNetV2 block can aggregate local and long-range information simultaneously. Extensive experiments demonstrate the superiority of GhostNetV2 over existing architectures. For example, it achieves 75.3% top-1 accuracy on ImageNet with 167M FLOPs, significantly suppressing GhostNetV1 (74.5%) with a similar computational cost. The source code will be available at https://github.com/huawei-noah/Efficient-AI-Backbones/tree/master/ghostnetv2_pytorch and https://gitee.com/mindspore/models/tree/master/research/cv/ghostnetv2.
Wireless Sensing Data Collection and Processing for Metaverse Avatar Construction
Nov 23, 2022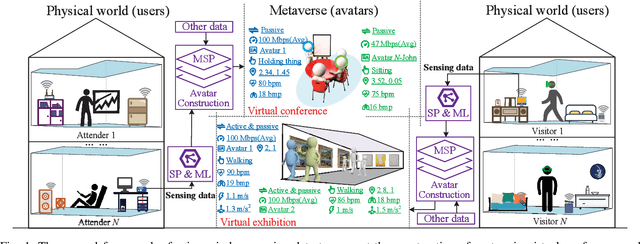
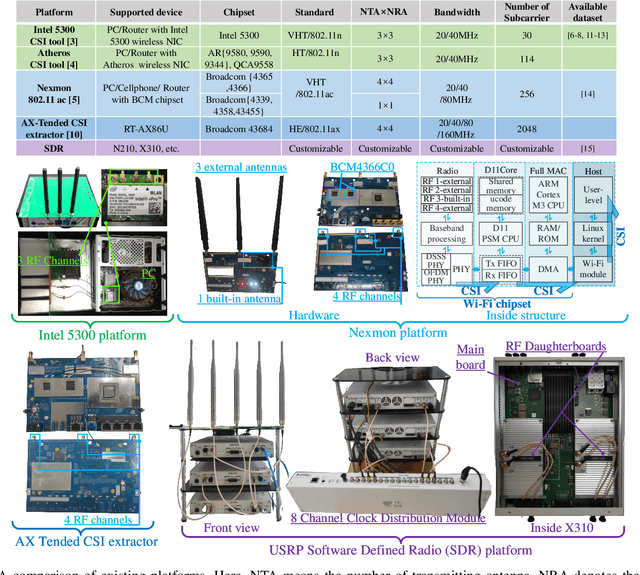
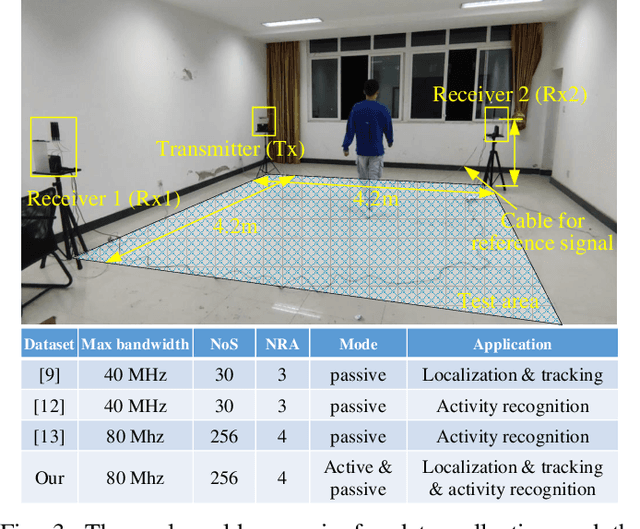
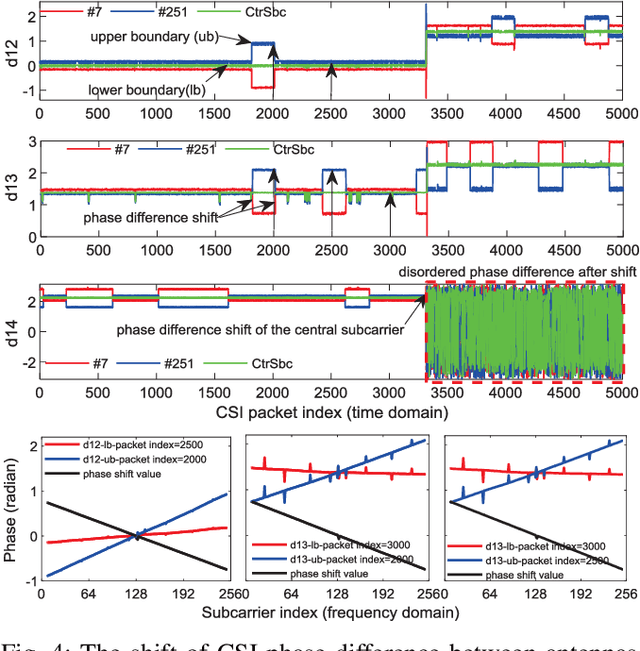
Recent advances in emerging technologies such as artificial intelligence and extended reality have pushed the Metaverse, a virtual, shared space, into reality. In Metaverse, users can customize virtual avatars to experience a different life. While impressive, avatar construction requires a lot of data that manifest users in the physical world from various perspectives, and wireless sensing data is one of them. For example, machine learning (ML) and signal processing can help extract information about user behavior from sensing data, thereby facilitating avatar behavior construction in the Metaverse. This article presents a wireless sensing dataset to support the emerging research on Metaverse avatar construction. Rigorously, the existing data collection platforms and datasets are analyzed first. On this basis, we introduce the platform used in this paper, as well as the data collection method and scenario. We observe that the collected sensing data, i.e., channel state information (CSI), suffers from a phase shift problem, which negatively affects the extraction of user information such as behavior and heartbeat and further deteriorates the avatar construction. Therefore, we propose to detect and correct this phase shift by a sliding window and phase compensation, respectively, and then validate the proposed scheme with the collected data. Finally, several research directions related to the avatar construction are given from the perspective of datasets.