 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
xFBD: Focused Building Damage Dataset and Analysis
Jan 03, 2023
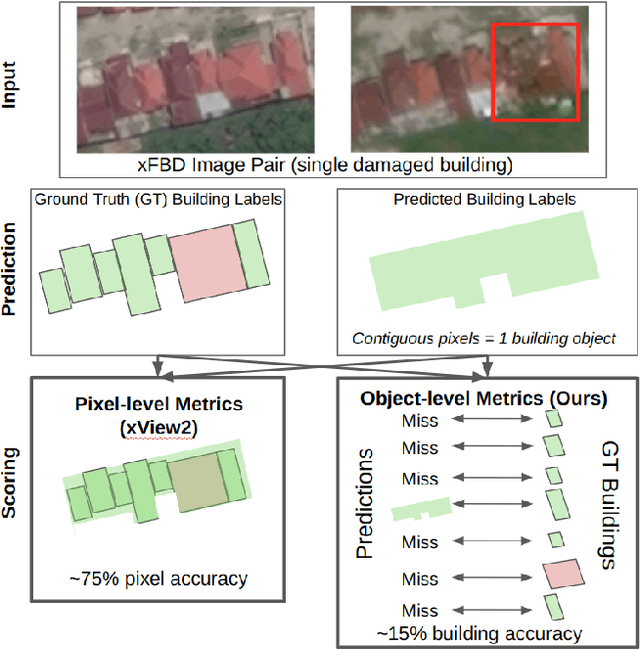


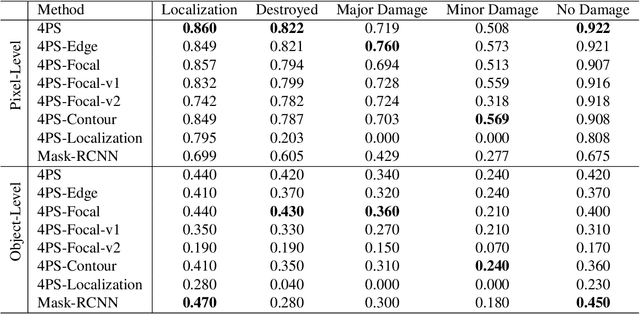
The xView2 competition and xBD dataset spurred significant advancements in overhead building damage detection, but the competition's pixel level scoring can lead to reduced solution performance in areas with tight clusters of buildings or uninformative context. We seek to advance automatic building damage assessment for disaster relief by proposing an auxiliary challenge to the original xView2 competition. This new challenge involves a new dataset and metrics indicating solution performance when damage is more local and limited than in xBD. Our challenge measures a network's ability to identify individual buildings and their damage level without excessive reliance on the buildings' surroundings. Methods that succeed on this challenge will provide more fine-grained, precise damage information than original xView2 solutions. The best-performing xView2 networks' performances dropped noticeably in our new limited/local damage detection task. The common causes of failure observed are that (1) building objects and their classifications are not separated well, and (2) when they are, the classification is strongly biased by surrounding buildings and other damage context. Thus, we release our augmented version of the dataset with additional object-level scoring metrics https://gitlab.kitware.com/dennis.melamed/xfbd to test independence and separability of building objects, alongside the pixel-level performance metrics of the original competition. We also experiment with new baseline models which improve independence and separability of building damage predictions. Our results indicate that building damage detection is not a fully-solved problem, and we invite others to use and build on our dataset augmentations and metrics.
Navigating the reporting guideline environment for computational pathology: A review
Jan 03, 2023
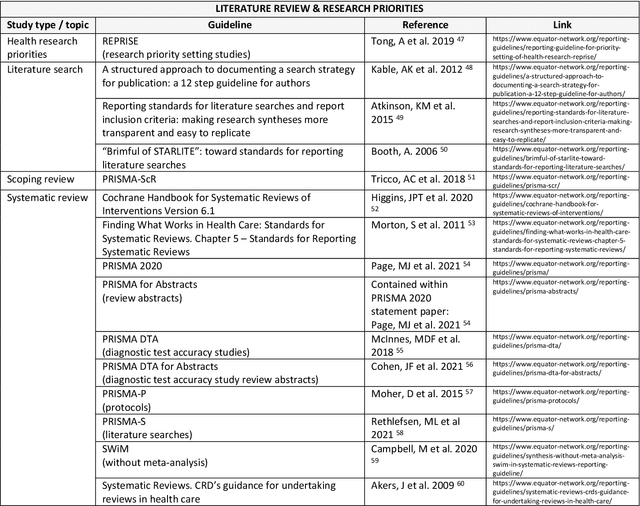
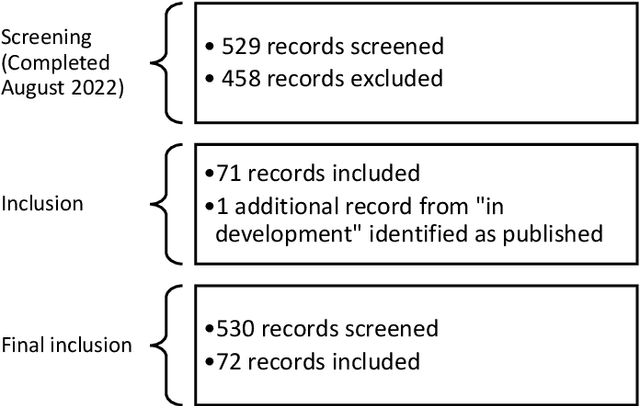
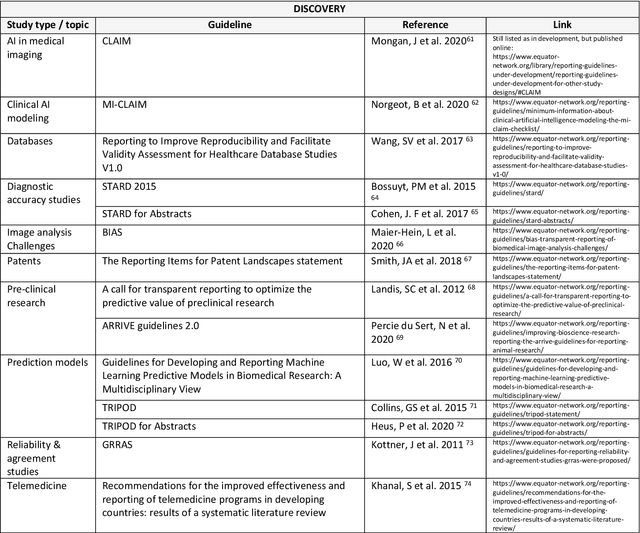
The application of new artificial intelligence (AI) discoveries is transforming healthcare research. However, the standards of reporting are variable in this still evolving field, leading to potential research waste. The aim of this work is to highlight resources and reporting guidelines available to researchers working in computational pathology. The EQUATOR Network library of reporting guidelines and extensions was systematically searched up to August 2022 to identify applicable resources. Inclusion and exclusion criteria were used and guidance was screened for utility at different stages of research and for a range of study types. Items were compiled to create a summary for easy identification of useful resources and guidance. Over 70 published resources applicable to pathology AI research were identified. Guidelines were divided into key categories, reflecting current study types and target areas for AI research: Literature & Research Priorities, Discovery, Clinical Trial, Implementation and Post-Implementation & Guidelines. Guidelines useful at multiple stages of research and those currently in development were also highlighted. Summary tables with links to guidelines for these groups were developed, to assist those working in cancer AI research with complete reporting of research. Issues with replication and research waste are recognised problems in AI research. Reporting guidelines can be used as templates to ensure the essential information needed to replicate research is included within journal articles and abstracts. Reporting guidelines are available and useful for many study types, but greater awareness is needed to encourage researchers to utilise them and for journals to adopt them. This review and summary of resources highlights guidance to researchers, aiming to improve completeness of reporting.
Faster Approximate Dynamic Programming by Freezing Slow States
Jan 03, 2023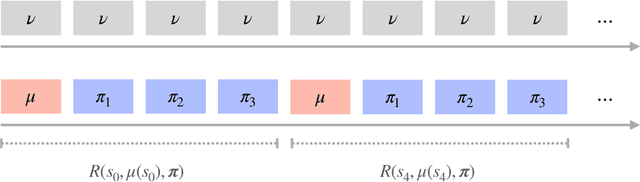

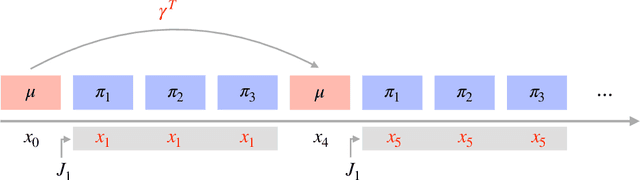
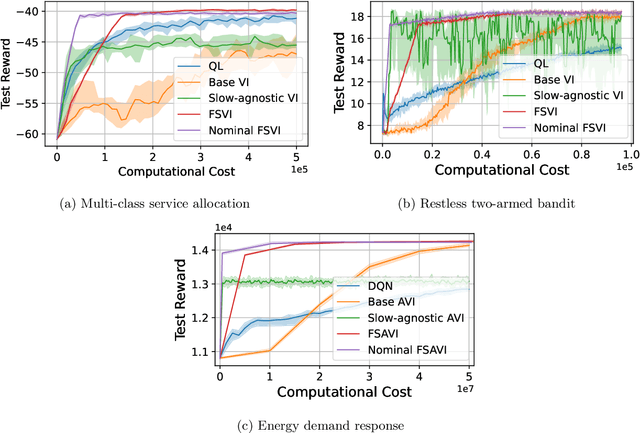
We consider infinite horizon Markov decision processes (MDPs) with fast-slow structure, meaning that certain parts of the state space move "fast" (and in a sense, are more influential) while other parts transition more "slowly." Such structure is common in real-world problems where sequential decisions need to be made at high frequencies, yet information that varies at a slower timescale also influences the optimal policy. Examples include: (1) service allocation for a multi-class queue with (slowly varying) stochastic costs, (2) a restless multi-armed bandit with an environmental state, and (3) energy demand response, where both day-ahead and real-time prices play a role in the firm's revenue. Models that fully capture these problems often result in MDPs with large state spaces and large effective time horizons (due to frequent decisions), rendering them computationally intractable. We propose an approximate dynamic programming algorithmic framework based on the idea of "freezing" the slow states, solving a set of simpler finite-horizon MDPs (the lower-level MDPs), and applying value iteration (VI) to an auxiliary MDP that transitions on a slower timescale (the upper-level MDP). We also extend the technique to a function approximation setting, where a feature-based linear architecture is used. On the theoretical side, we analyze the regret incurred by each variant of our frozen-state approach. Finally, we give empirical evidence that the frozen-state approach generates effective policies using just a fraction of the computational cost, while illustrating that simply omitting slow states from the decision modeling is often not a viable heuristic.
Silence is Sweeter Than Speech: Self-Supervised Model Using Silence to Store Speaker Information
May 08, 2022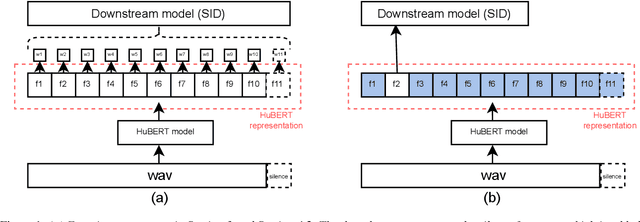
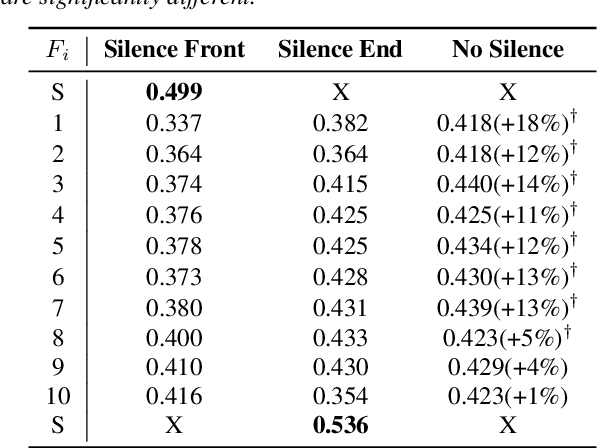
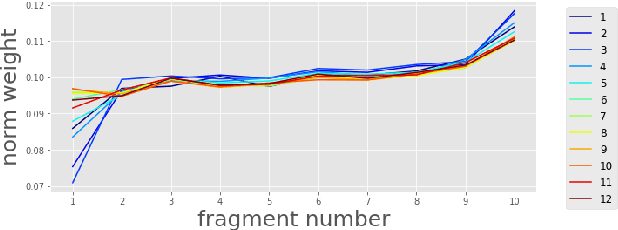
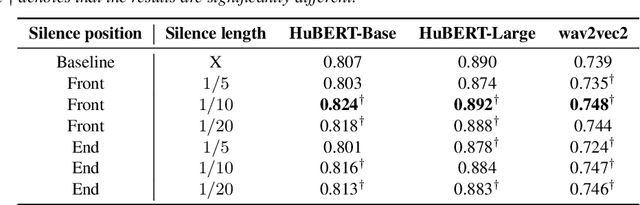
Self-Supervised Learning (SSL) has made great strides recently. SSL speech models achieve decent performance on a wide range of downstream tasks, suggesting that they extract different aspects of information from speech. However, how SSL models store various information in hidden representations without interfering is still poorly understood. Taking the recently successful SSL model, HuBERT, as an example, we explore how the SSL model processes and stores speaker information in the representation. We found that HuBERT stores speaker information in representations whose positions correspond to silences in a waveform. There are several pieces of evidence. (1) We find that the utterances with more silent parts in the waveforms have better Speaker Identification (SID) accuracy. (2) If we use the whole utterances for SID, the silence part always contributes more to the SID task. (3) If we only use the representation of a part of the utterance for SID, the silenced part has higher accuracy than the other parts. Our findings not only contribute to a better understanding of SSL models but also improve performance. By simply adding silence to the original waveform, HuBERT improved its accuracy on SID by nearly 2%.
Active Data Discovery: Mining Unknown Data using Submodular Information Measures
Jun 17, 2022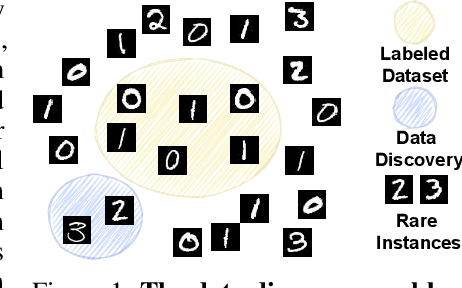
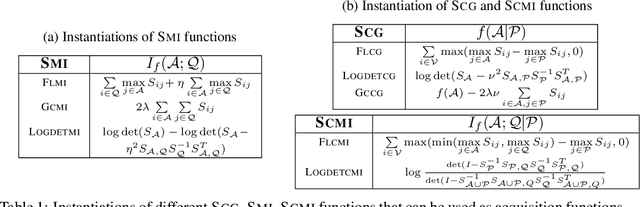
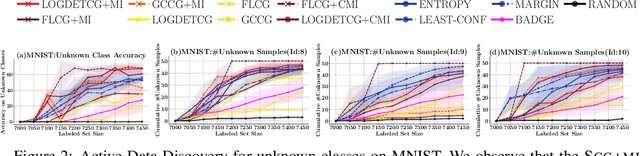
Active Learning is a very common yet powerful framework for iteratively and adaptively sampling subsets of the unlabeled sets with a human in the loop with the goal of achieving labeling efficiency. Most real world datasets have imbalance either in classes and slices, and correspondingly, parts of the dataset are rare. As a result, there has been a lot of work in designing active learning approaches for mining these rare data instances. Most approaches assume access to a seed set of instances which contain these rare data instances. However, in the event of more extreme rareness, it is reasonable to assume that these rare data instances (either classes or slices) may not even be present in the seed labeled set, and a critical need for the active learning paradigm is to efficiently discover these rare data instances. In this work, we provide an active data discovery framework which can mine unknown data slices and classes efficiently using the submodular conditional gain and submodular conditional mutual information functions. We provide a general algorithmic framework which works in a number of scenarios including image classification and object detection and works with both rare classes and rare slices present in the unlabeled set. We show significant accuracy and labeling efficiency gains with our approach compared to existing state-of-the-art active learning approaches for actively discovering these rare classes and slices.
Attacking and Defending Deep-Learning-Based Off-Device Wireless Positioning Systems
Nov 15, 2022
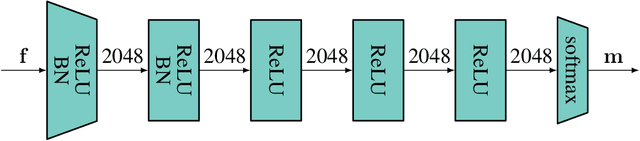
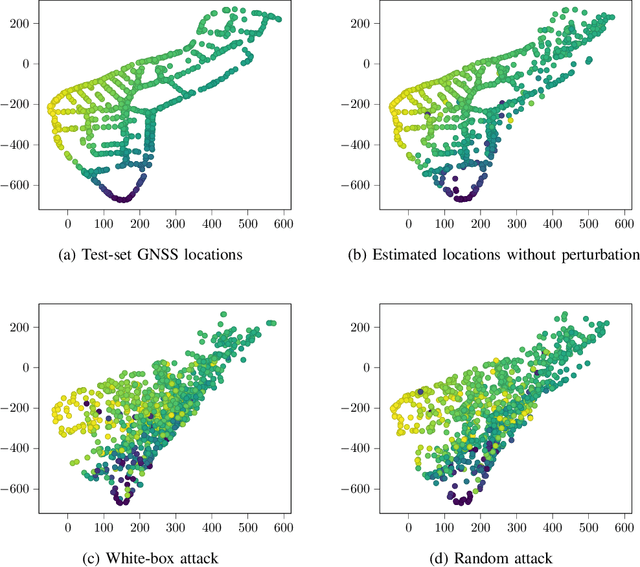
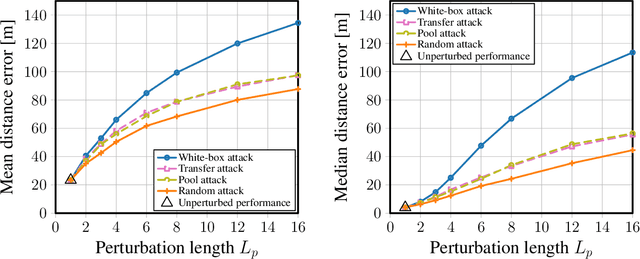
Localization services for wireless devices play an increasingly important role and a plethora of emerging services and applications already rely on precise position information. Widely used on-device positioning methods, such as the global positioning system, enable accurate outdoor positioning and provide the users with full control over what services are allowed to access location information. To provide accurate positioning indoors or in cluttered urban scenarios without line-of-sight satellite connectivity, powerful off-device positioning systems, which process channel state information (CSI) with deep neural networks, have emerged recently. Such off-device positioning systems inherently link a user's data transmission with its localization, since accurate CSI measurements are necessary for reliable wireless communication -- this not only prevents the users from controlling who can access this information but also enables virtually everyone in the device's range to estimate its location, resulting in serious privacy and security concerns. We propose on-device attacks against off-device wireless positioning systems in multi-antenna orthogonal frequency-division multiplexing systems while minimizing the impact on quality-of-service, and we demonstrate their efficacy using measured datasets for outdoor and indoor scenarios. We also investigate defenses to counter such attack mechanisms, and we discuss the limitations and implications on protecting location privacy in future wireless communication systems.
Whose Emotion Matters? Speaker Detection without Prior Knowledge
Dec 08, 2022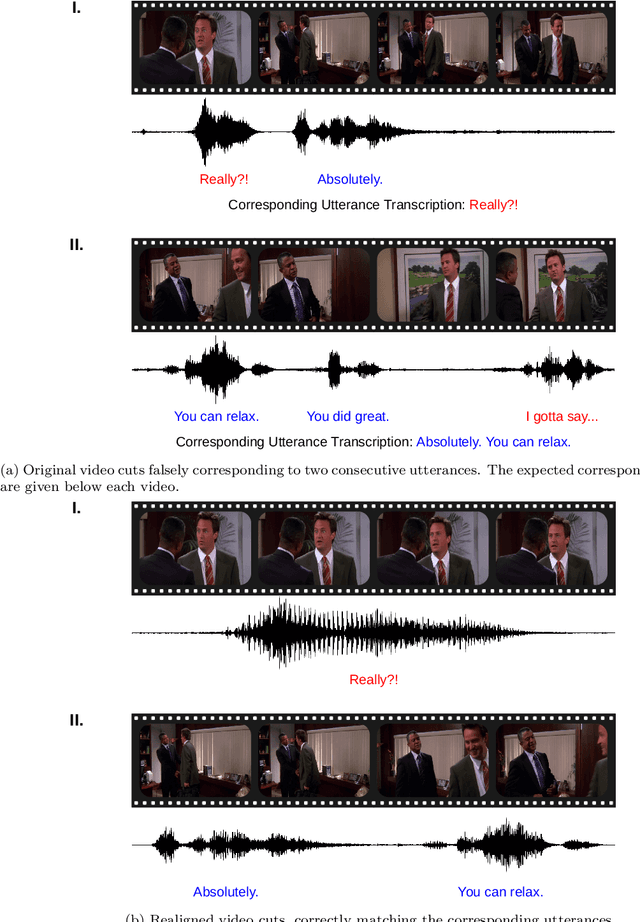

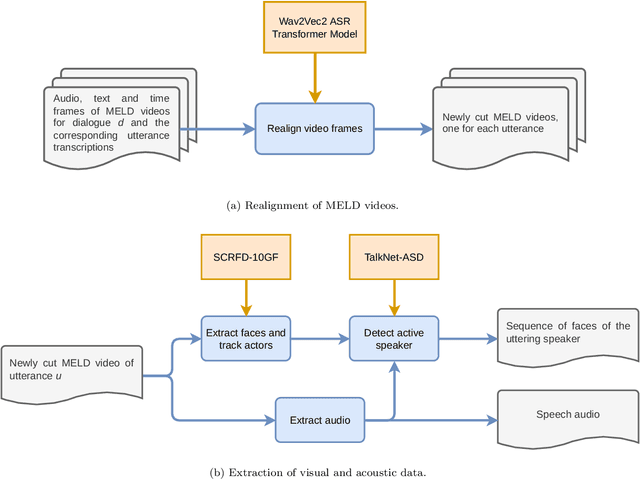
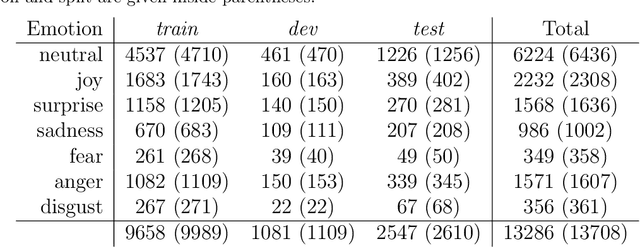
The task of emotion recognition in conversations (ERC) benefits from the availability of multiple modalities, as offered, for example, in the video-based MELD dataset. However, only a few research approaches use both acoustic and visual information from the MELD videos. There are two reasons for this: First, label-to-video alignments in MELD are noisy, making those videos an unreliable source of emotional speech data. Second, conversations can involve several people in the same scene, which requires the detection of the person speaking the utterance. In this paper we demonstrate that by using recent automatic speech recognition and active speaker detection models, we are able to realign the videos of MELD, and capture the facial expressions from uttering speakers in 96.92% of the utterances provided in MELD. Experiments with a self-supervised voice recognition model indicate that the realigned MELD videos more closely match the corresponding utterances offered in the dataset. Finally, we devise a model for emotion recognition in conversations trained on the face and audio information of the MELD realigned videos, which outperforms state-of-the-art models for ERC based on vision alone. This indicates that active speaker detection is indeed effective for extracting facial expressions from the uttering speakers, and that faces provide more informative visual cues than the visual features state-of-the-art models have been using so far.
Shakes on a Plane: Unsupervised Depth Estimation from Unstabilized Photography
Dec 22, 2022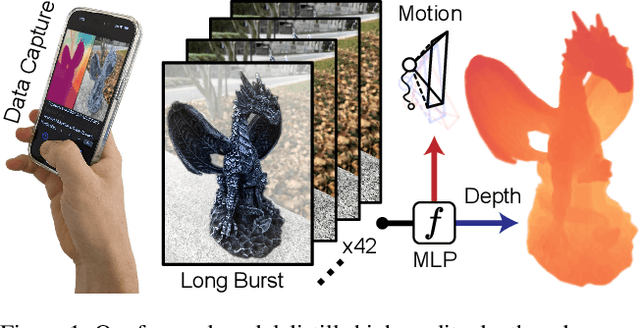
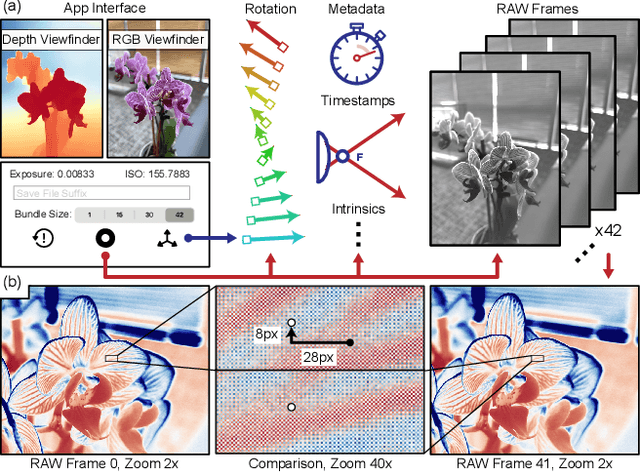
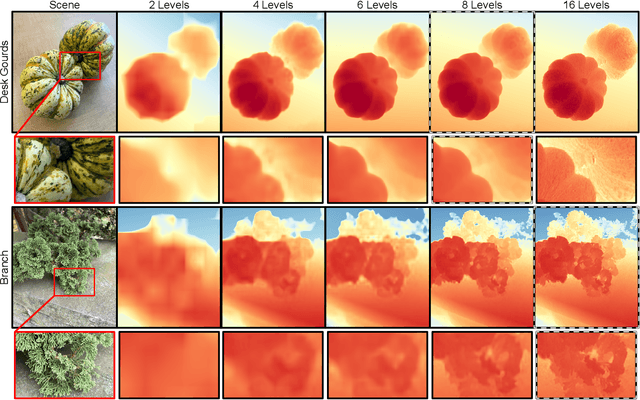
Modern mobile burst photography pipelines capture and merge a short sequence of frames to recover an enhanced image, but often disregard the 3D nature of the scene they capture, treating pixel motion between images as a 2D aggregation problem. We show that in a "long-burst", forty-two 12-megapixel RAW frames captured in a two-second sequence, there is enough parallax information from natural hand tremor alone to recover high-quality scene depth. To this end, we devise a test-time optimization approach that fits a neural RGB-D representation to long-burst data and simultaneously estimates scene depth and camera motion. Our plane plus depth model is trained end-to-end, and performs coarse-to-fine refinement by controlling which multi-resolution volume features the network has access to at what time during training. We validate the method experimentally, and demonstrate geometrically accurate depth reconstructions with no additional hardware or separate data pre-processing and pose-estimation steps.
Over-the-Air Federated Learning with Enhanced Privacy
Dec 22, 2022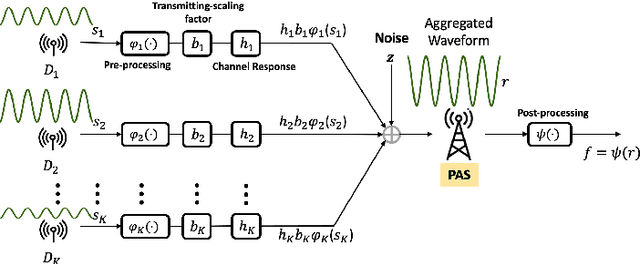
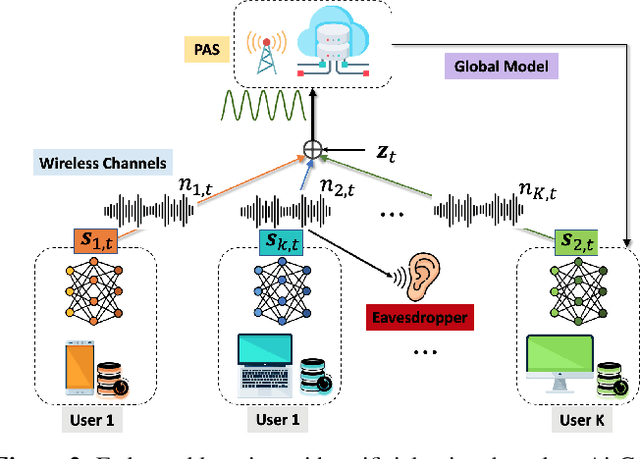
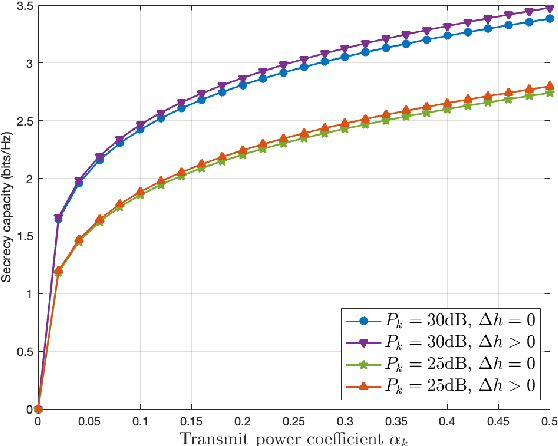
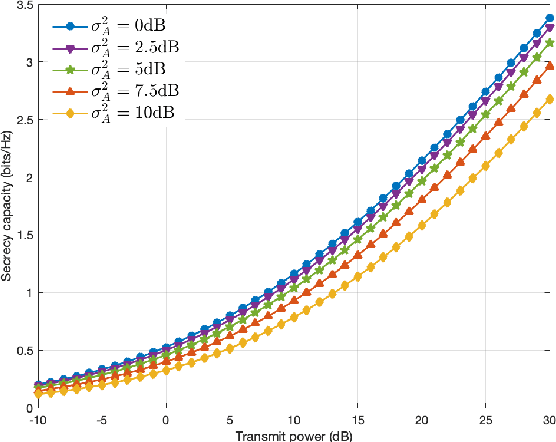
Federated learning (FL) has emerged as a promising learning paradigm in which only local model parameters (gradients) are shared. Private user data never leaves the local devices thus preserving data privacy. However, recent research has shown that even when local data is never shared by a user, exchanging model parameters without protection can also leak private information. Moreover, in wireless systems, the frequent transmission of model parameters can cause tremendous bandwidth consumption and network congestion when the model is large. To address this problem, we propose a new FL framework with efficient over-the-air parameter aggregation and strong privacy protection of both user data and models. We achieve this by introducing pairwise cancellable random artificial noises (PCR-ANs) on end devices. As compared to existing over-the-air computation (AirComp) based FL schemes, our design provides stronger privacy protection. We analytically show the secrecy capacity and the convergence rate of the proposed wireless FL aggregation algorithm.
Removing Objects From Neural Radiance Fields
Dec 22, 2022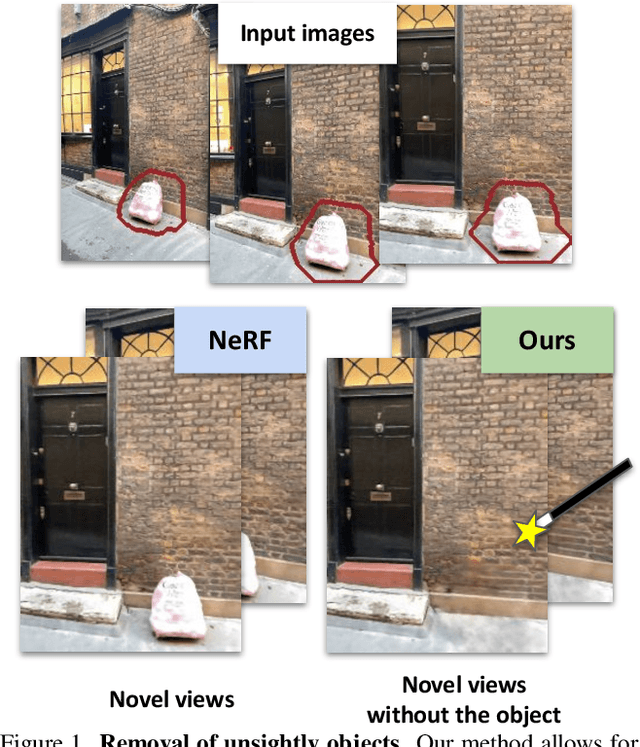
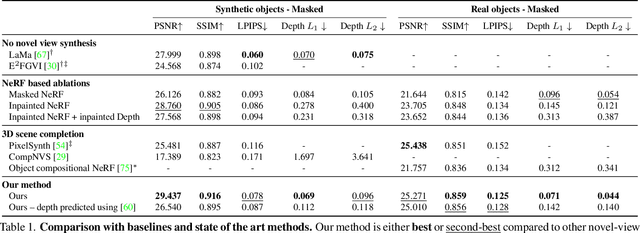

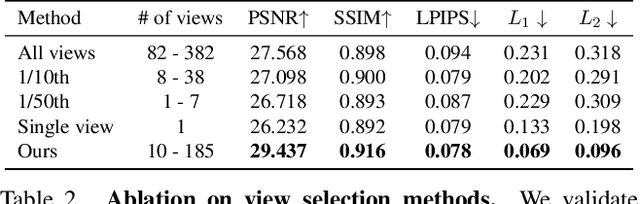
Neural Radiance Fields (NeRFs) are emerging as a ubiquitous scene representation that allows for novel view synthesis. Increasingly, NeRFs will be shareable with other people. Before sharing a NeRF, though, it might be desirable to remove personal information or unsightly objects. Such removal is not easily achieved with the current NeRF editing frameworks. We propose a framework to remove objects from a NeRF representation created from an RGB-D sequence. Our NeRF inpainting method leverages recent work in 2D image inpainting and is guided by a user-provided mask. Our algorithm is underpinned by a confidence based view selection procedure. It chooses which of the individual 2D inpainted images to use in the creation of the NeRF, so that the resulting inpainted NeRF is 3D consistent. We show that our method for NeRF editing is effective for synthesizing plausible inpaintings in a multi-view coherent manner. We validate our approach using a new and still-challenging dataset for the task of NeRF inpainting.