 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Unsupervised Boundary-Aware Language Model Pretraining for Chinese Sequence Labeling
Oct 27, 2022
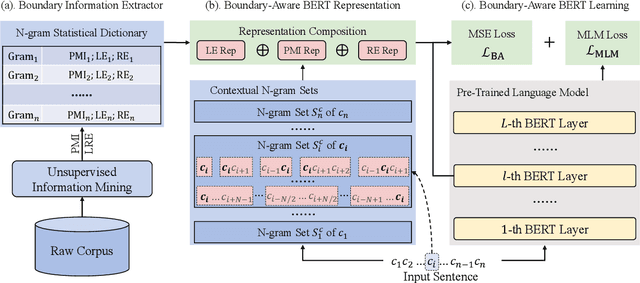
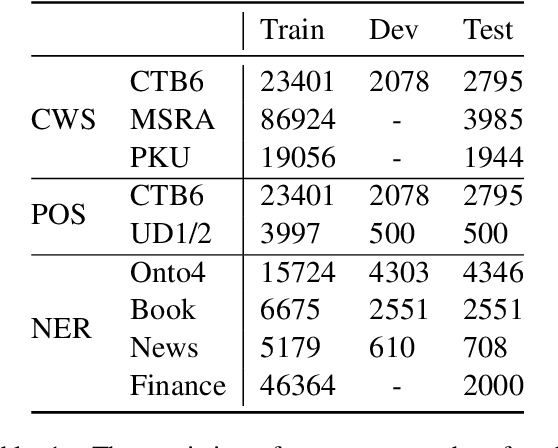
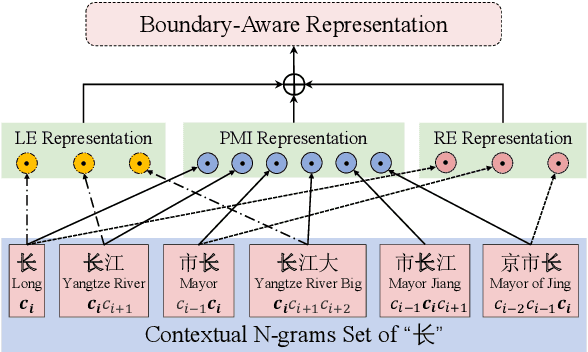
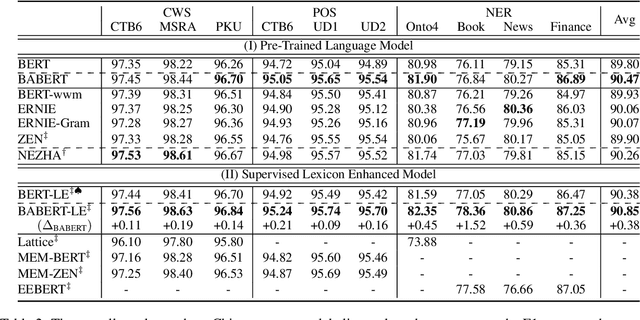
Boundary information is critical for various Chinese language processing tasks, such as word segmentation, part-of-speech tagging, and named entity recognition. Previous studies usually resorted to the use of a high-quality external lexicon, where lexicon items can offer explicit boundary information. However, to ensure the quality of the lexicon, great human effort is always necessary, which has been generally ignored. In this work, we suggest unsupervised statistical boundary information instead, and propose an architecture to encode the information directly into pre-trained language models, resulting in Boundary-Aware BERT (BABERT). We apply BABERT for feature induction of Chinese sequence labeling tasks. Experimental results on ten benchmarks of Chinese sequence labeling demonstrate that BABERT can provide consistent improvements on all datasets. In addition, our method can complement previous supervised lexicon exploration, where further improvements can be achieved when integrated with external lexicon information.
Knowledge-driven Scene Priors for Semantic Audio-Visual Embodied Navigation
Dec 21, 2022
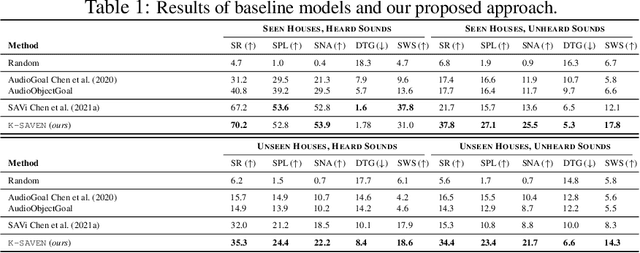
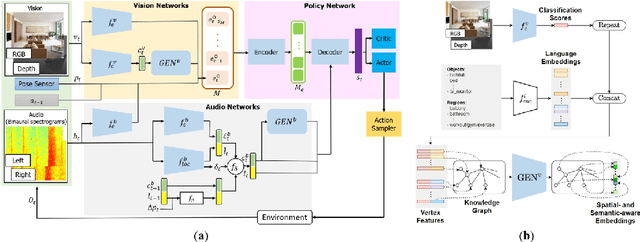
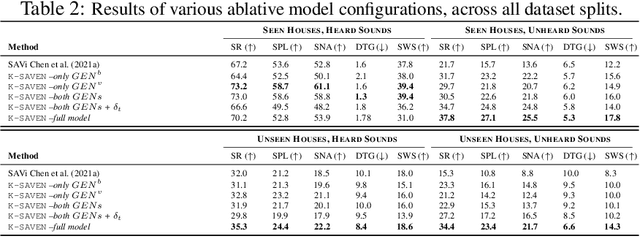
Generalisation to unseen contexts remains a challenge for embodied navigation agents. In the context of semantic audio-visual navigation (SAVi) tasks, the notion of generalisation should include both generalising to unseen indoor visual scenes as well as generalising to unheard sounding objects. However, previous SAVi task definitions do not include evaluation conditions on truly novel sounding objects, resorting instead to evaluating agents on unheard sound clips of known objects; meanwhile, previous SAVi methods do not include explicit mechanisms for incorporating domain knowledge about object and region semantics. These weaknesses limit the development and assessment of models' abilities to generalise their learned experience. In this work, we introduce the use of knowledge-driven scene priors in the semantic audio-visual embodied navigation task: we combine semantic information from our novel knowledge graph that encodes object-region relations, spatial knowledge from dual Graph Encoder Networks, and background knowledge from a series of pre-training tasks -- all within a reinforcement learning framework for audio-visual navigation. We also define a new audio-visual navigation sub-task, where agents are evaluated on novel sounding objects, as opposed to unheard clips of known objects. We show improvements over strong baselines in generalisation to unseen regions and novel sounding objects, within the Habitat-Matterport3D simulation environment, under the SoundSpaces task.
Similarity Contrastive Estimation for Image and Video Soft Contrastive Self-Supervised Learning
Dec 21, 2022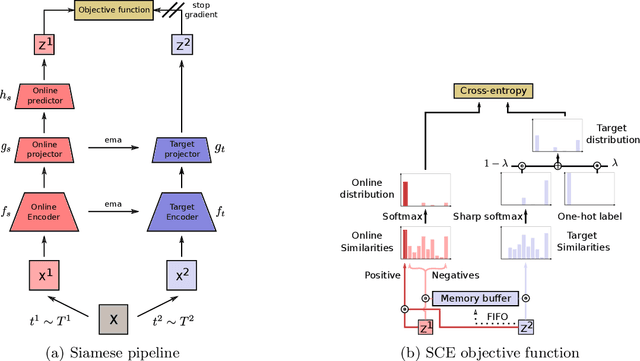
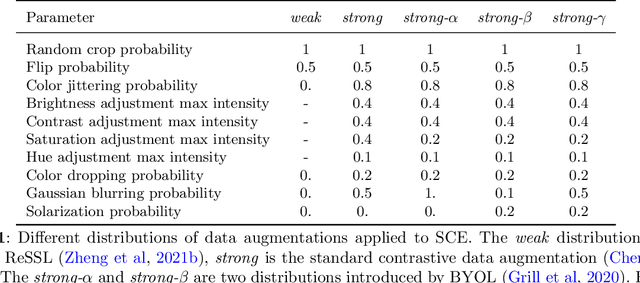

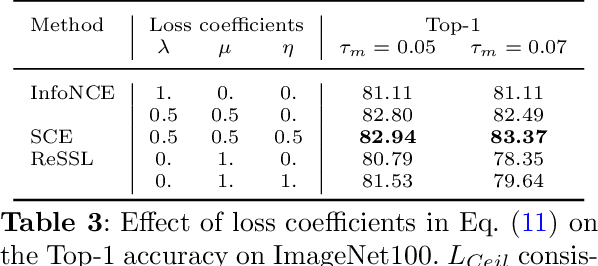
Contrastive representation learning has proven to be an effective self-supervised learning method for images and videos. Most successful approaches are based on Noise Contrastive Estimation (NCE) and use different views of an instance as positives that should be contrasted with other instances, called negatives, that are considered as noise. However, several instances in a dataset are drawn from the same distribution and share underlying semantic information. A good data representation should contain relations between the instances, or semantic similarity and dissimilarity, that contrastive learning harms by considering all negatives as noise. To circumvent this issue, we propose a novel formulation of contrastive learning using semantic similarity between instances called Similarity Contrastive Estimation (SCE). Our training objective is a soft contrastive one that brings the positives closer and estimates a continuous distribution to push or pull negative instances based on their learned similarities. We validate empirically our approach on both image and video representation learning. We show that SCE performs competitively with the state of the art on the ImageNet linear evaluation protocol for fewer pretraining epochs and that it generalizes to several downstream image tasks. We also show that SCE reaches state-of-the-art results for pretraining video representation and that the learned representation can generalize to video downstream tasks.
Online Statistical Inference for Matrix Contextual Bandit
Dec 21, 2022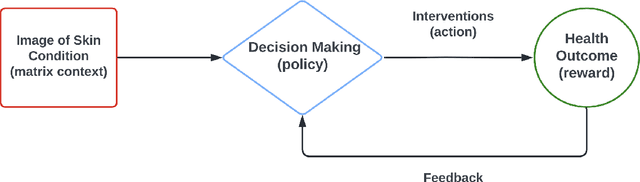
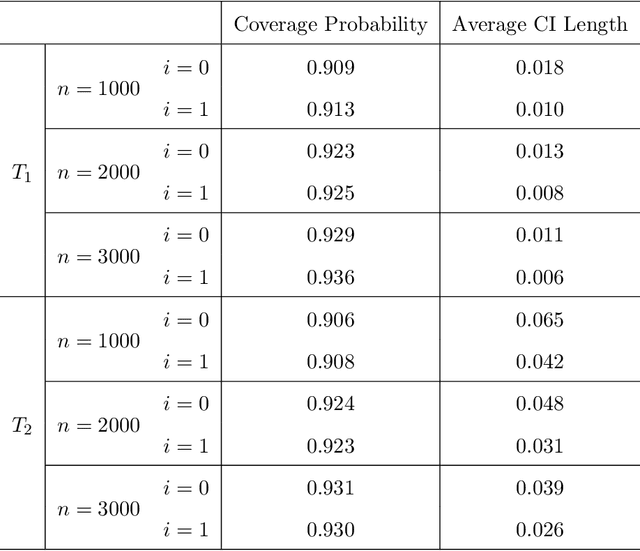
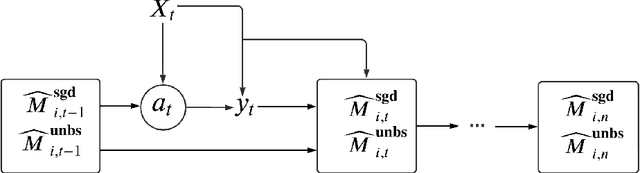
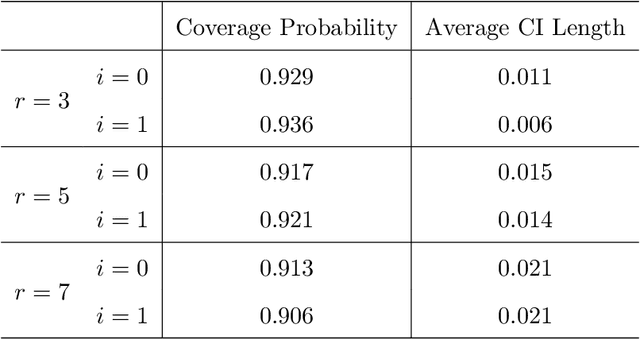
Contextual bandit has been widely used for sequential decision-making based on the current contextual information and historical feedback data. In modern applications, such context format can be rich and can often be formulated as a matrix. Moreover, while existing bandit algorithms mainly focused on reward-maximization, less attention has been paid to the statistical inference. To fill in these gaps, in this work we consider a matrix contextual bandit framework where the true model parameter is a low-rank matrix, and propose a fully online procedure to simultaneously make sequential decision-making and conduct statistical inference. The low-rank structure of the model parameter and the adaptivity nature of the data collection process makes this difficult: standard low-rank estimators are not fully online and are biased, while existing inference approaches in bandit algorithms fail to account for the low-rankness and are also biased. To address these, we introduce a new online doubly-debiasing inference procedure to simultaneously handle both sources of bias. In theory, we establish the asymptotic normality of the proposed online doubly-debiased estimator and prove the validity of the constructed confidence interval. Our inference results are built upon a newly developed low-rank stochastic gradient descent estimator and its non-asymptotic convergence result, which is also of independent interest.
Training language models for deeper understanding improves brain alignment
Dec 21, 2022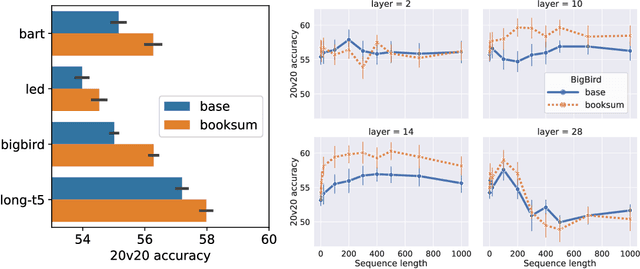
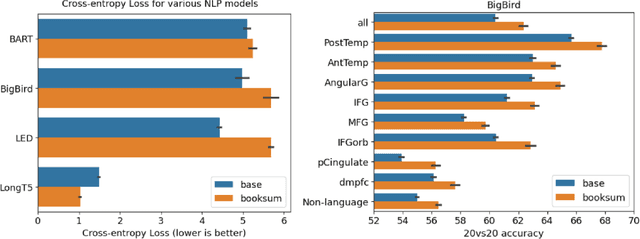

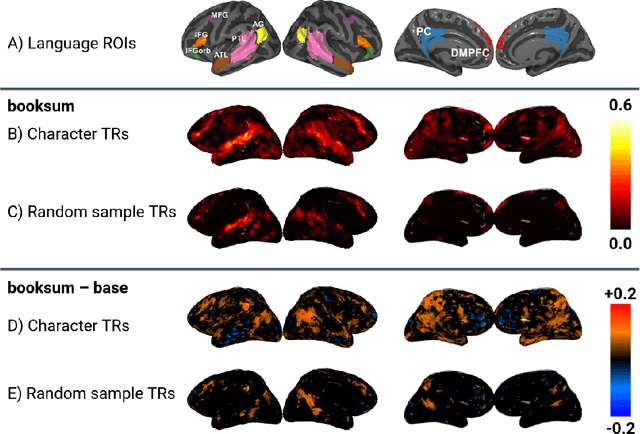
Building systems that achieve a deeper understanding of language is one of the central goals of natural language processing (NLP). Towards this goal, recent works have begun to train language models on narrative datasets which require extracting the most critical information by integrating across long contexts. However, it is still an open question whether these models are learning a deeper understanding of the text, or if the models are simply learning a heuristic to complete the task. This work investigates this further by turning to the one language processing system that truly understands complex language: the human brain. We show that training language models for deeper narrative understanding results in richer representations that have improved alignment to human brain activity. We further find that the improvements in brain alignment are larger for character names than for other discourse features, which indicates that these models are learning important narrative elements. Taken together, these results suggest that this type of training can indeed lead to deeper language understanding. These findings have consequences both for cognitive neuroscience by revealing some of the significant factors behind brain-NLP alignment, and for NLP by highlighting that understanding of long-range context can be improved beyond language modeling.
MouseGAN++: Unsupervised Disentanglement and Contrastive Representation for Multiple MRI Modalities Synthesis and Structural Segmentation of Mouse Brain
Dec 04, 2022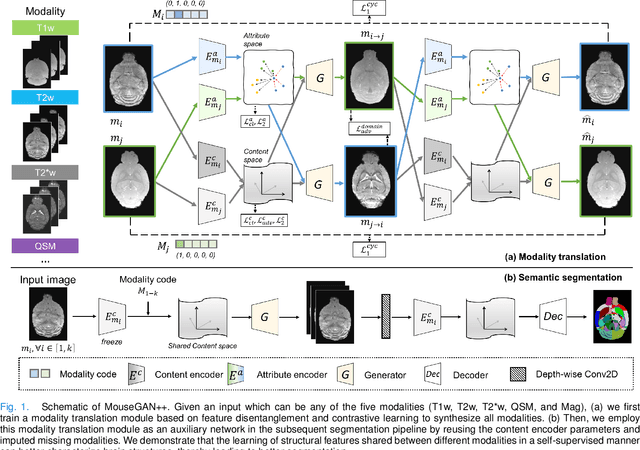
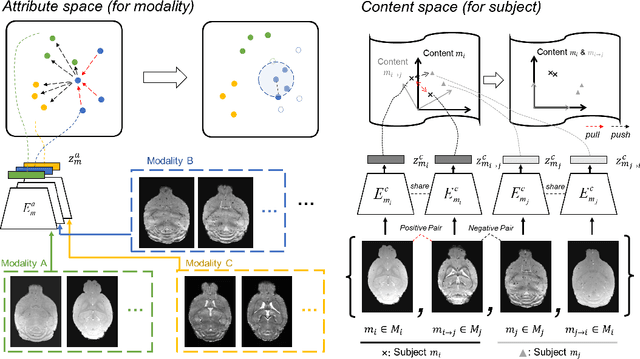
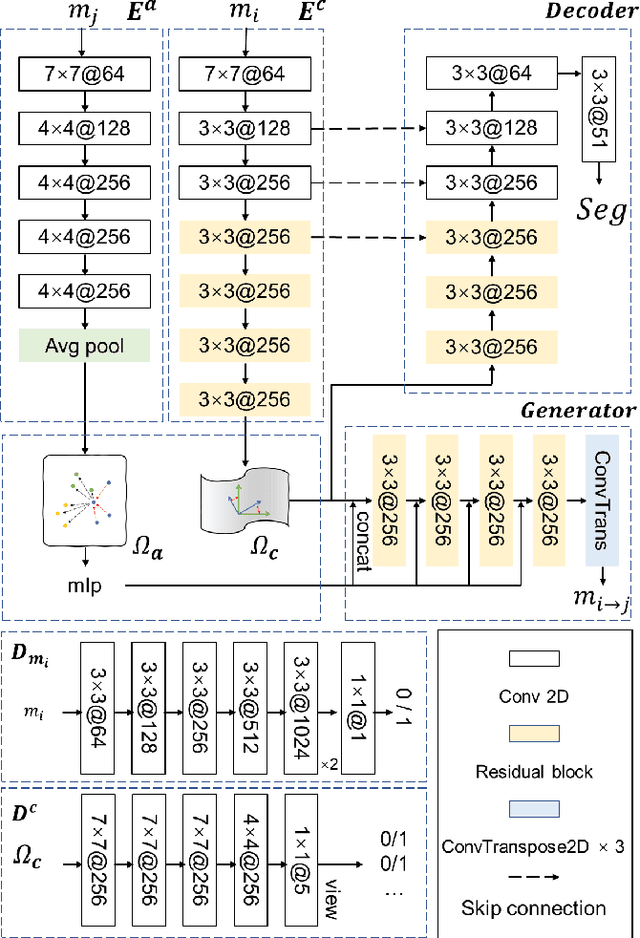
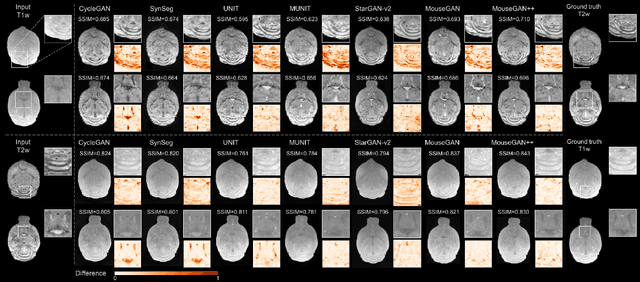
Segmenting the fine structure of the mouse brain on magnetic resonance (MR) images is critical for delineating morphological regions, analyzing brain function, and understanding their relationships. Compared to a single MRI modality, multimodal MRI data provide complementary tissue features that can be exploited by deep learning models, resulting in better segmentation results. However, multimodal mouse brain MRI data is often lacking, making automatic segmentation of mouse brain fine structure a very challenging task. To address this issue, it is necessary to fuse multimodal MRI data to produce distinguished contrasts in different brain structures. Hence, we propose a novel disentangled and contrastive GAN-based framework, named MouseGAN++, to synthesize multiple MR modalities from single ones in a structure-preserving manner, thus improving the segmentation performance by imputing missing modalities and multi-modality fusion. Our results demonstrate that the translation performance of our method outperforms the state-of-the-art methods. Using the subsequently learned modality-invariant information as well as the modality-translated images, MouseGAN++ can segment fine brain structures with averaged dice coefficients of 90.0% (T2w) and 87.9% (T1w), respectively, achieving around +10% performance improvement compared to the state-of-the-art algorithms. Our results demonstrate that MouseGAN++, as a simultaneous image synthesis and segmentation method, can be used to fuse cross-modality information in an unpaired manner and yield more robust performance in the absence of multimodal data. We release our method as a mouse brain structural segmentation tool for free academic usage at https://github.com/yu02019.
Decomposable Sparse Tensor on Tensor Regression
Dec 09, 2022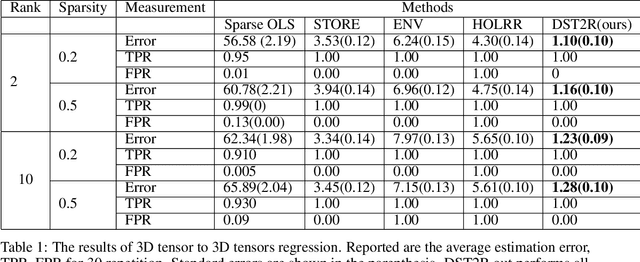
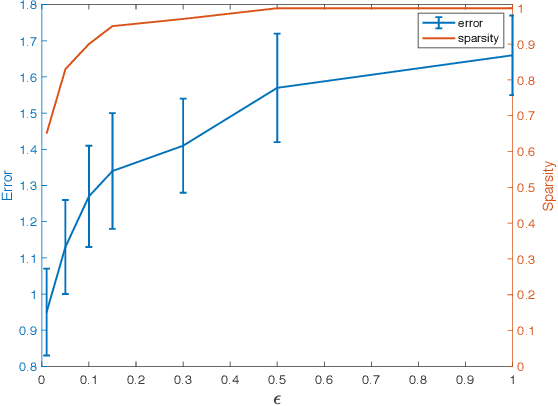
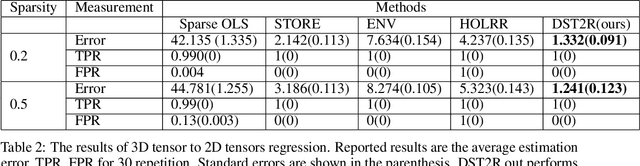
Most regularized tensor regression research focuses on tensors predictors with scalars responses or vectors predictors to tensors responses. We consider the sparse low rank tensor on tensor regression where predictors $\mathcal{X}$ and responses $\mathcal{Y}$ are both high-dimensional tensors. By demonstrating that the general inner product or the contracted product on a unit rank tensor can be decomposed into standard inner products and outer products, the problem can be simply transformed into a tensor to scalar regression followed by a tensor decomposition. So we propose a fast solution based on stagewise search composed by contraction part and generation part which are optimized alternatively. We successfully demonstrate our method can out perform current methods in terms of accuracy, predictors selection by effectively incorporating the structural information.
Robust convex biclustering with a tuning-free method
Dec 09, 2022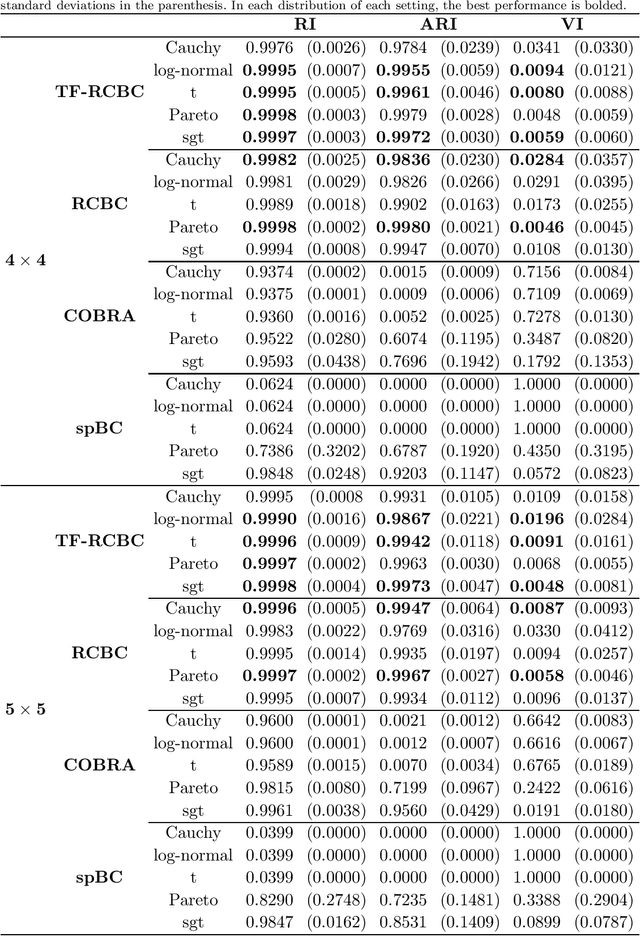
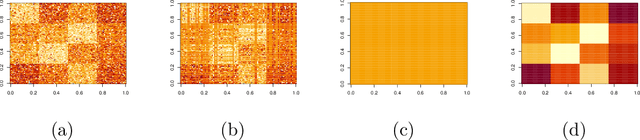
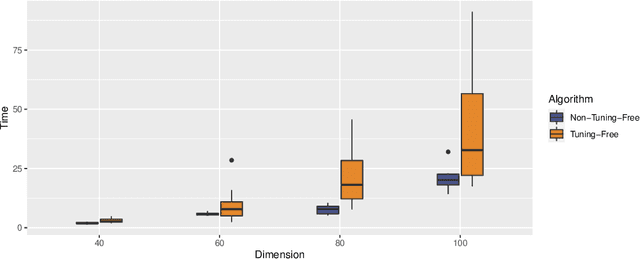
Biclustering is widely used in different kinds of fields including gene information analysis, text mining, and recommendation system by effectively discovering the local correlation between samples and features. However, many biclustering algorithms will collapse when facing heavy-tailed data. In this paper, we propose a robust version of convex biclustering algorithm with Huber loss. Yet, the newly introduced robustification parameter brings an extra burden to selecting the optimal parameters. Therefore, we propose a tuning-free method for automatically selecting the optimal robustification parameter with high efficiency. The simulation study demonstrates the more fabulous performance of our proposed method than traditional biclustering methods when encountering heavy-tailed noise. A real-life biomedical application is also presented. The R package RcvxBiclustr is available at https://github.com/YifanChen3/RcvxBiclustr.
Sampling with Attribute-Related Information for Controlling Language Models
May 12, 2022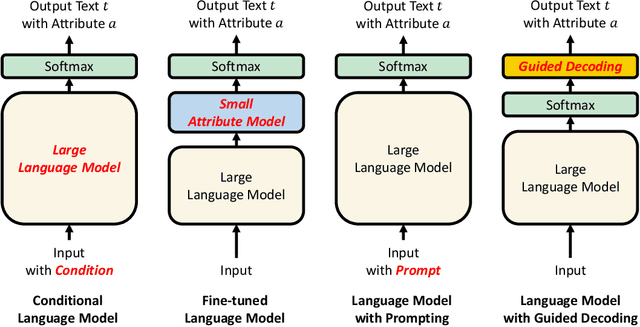
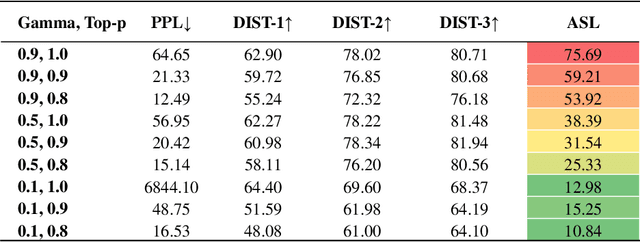

The dominant approaches for controlling language models are based on fine-tuning large language models or prompt engineering. However, these methods often require condition-specific data or considerable hand-crafting. We propose a new simple guided decoding method, Gamma Sampling, which does not require complex engineering and any extra data. Gamma Sampling introduces attribute-related information (provided by humans or language models themselves) into the sampling process to guide language models to generate texts with desired attributes. Experiments on controlling topics and sentiments of generated text show Gamma Sampling to be superior in diversity, attribute relevance and overall quality of generated samples while maintaining a fast generation speed. In addition, we successfully applied Gamma Sampling to control other attributes of language such as relatedness and repetition, which further demonstrates the versatility and effectiveness of this method. Gamma Sampling is now available in the python package samplings via import gamma sampling from samplings.
A Unified Object Counting Network with Object Occupation Prior
Dec 29, 2022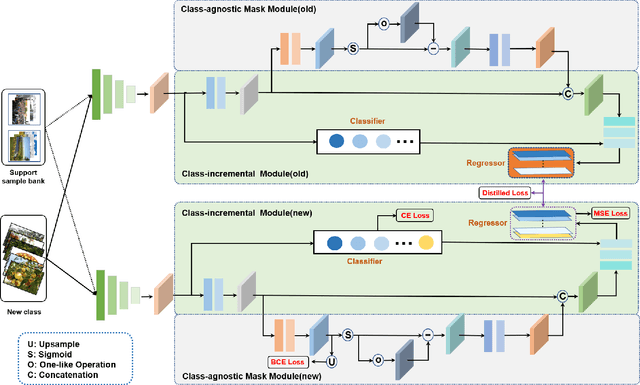

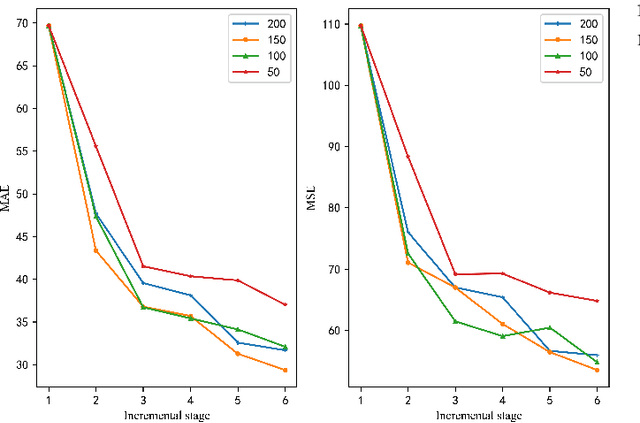
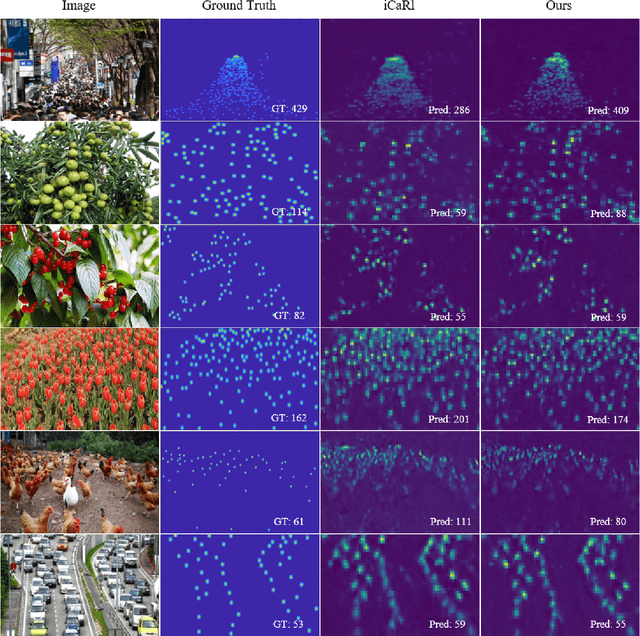
The counting task, which plays a fundamental rule in numerous applications (e.g., crowd counting, traffic statistics), aims to predict the number of objects with various densities. Existing object counting tasks are designed for a single object class. However, it is inevitable to encounter newly coming data with new classes in our real world. We name this scenario as \textit{evolving object counting}. In this paper, we build the first evolving object counting dataset and propose a unified object counting network as the first attempt to address this task. The proposed model consists of two key components: a class-agnostic mask module and a class-increment module. The class-agnostic mask module learns generic object occupation prior via predicting a class-agnostic binary mask (e.g., 1 denotes there exists an object at the considering position in an image and 0 otherwise). The class-increment module is used to handle new coming classes and provides discriminative class guidance for density map prediction. The combined outputs of class-agnostic mask module and image feature extractor are used to predict the final density map. When new classes come, we first add new neural nodes into the last regression and classification layers of this module. Then, instead of retraining the model from scratch, we utilize knowledge distilling to help the model remember what have already learned about previous object classes. We also employ a support sample bank to store a small number of typical training samples of each class, which are used to prevent the model from forgetting key information of old data. With this design, our model can efficiently and effectively adapt to new coming classes while keeping good performance on already seen data without large-scale retraining. Extensive experiments on the collected dataset demonstrate the favorable performance.