 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Scope Sensitive and Result Attentive Model for Multi-Intent Spoken Language Understanding
Nov 22, 2022
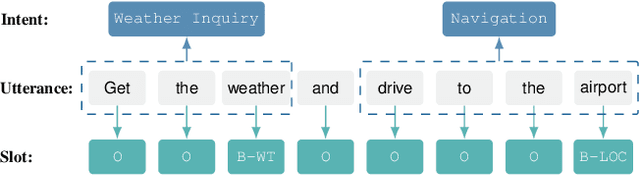
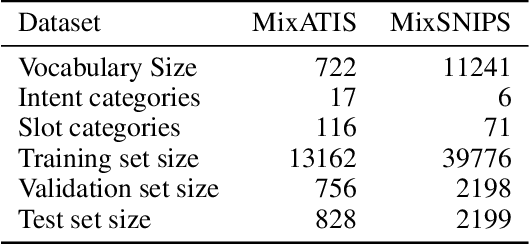
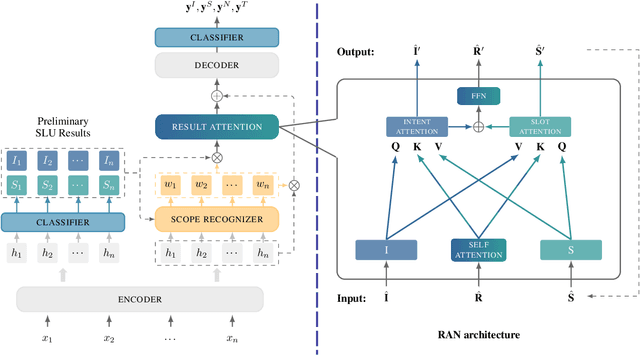
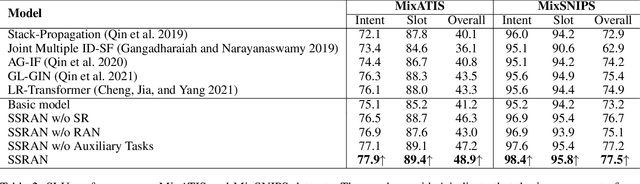
Multi-Intent Spoken Language Understanding (SLU), a novel and more complex scenario of SLU, is attracting increasing attention. Unlike traditional SLU, each intent in this scenario has its specific scope. Semantic information outside the scope even hinders the prediction, which tremendously increases the difficulty of intent detection. More seriously, guiding slot filling with these inaccurate intent labels suffers error propagation problems, resulting in unsatisfied overall performance. To solve these challenges, in this paper, we propose a novel Scope-Sensitive Result Attention Network (SSRAN) based on Transformer, which contains a Scope Recognizer (SR) and a Result Attention Network (RAN). Scope Recognizer assignments scope information to each token, reducing the distraction of out-of-scope tokens. Result Attention Network effectively utilizes the bidirectional interaction between results of slot filling and intent detection, mitigating the error propagation problem. Experiments on two public datasets indicate that our model significantly improves SLU performance (5.4\% and 2.1\% on Overall accuracy) over the state-of-the-art baseline.
PESE: Event Structure Extraction using Pointer Network based Encoder-Decoder Architecture
Nov 22, 2022
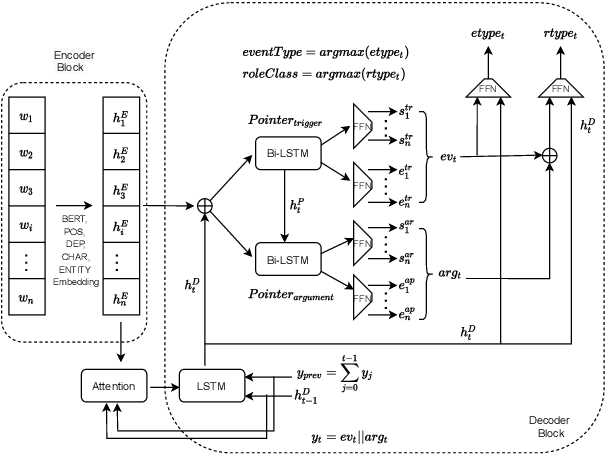
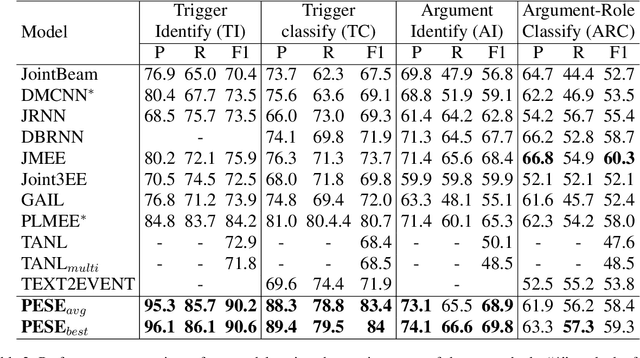
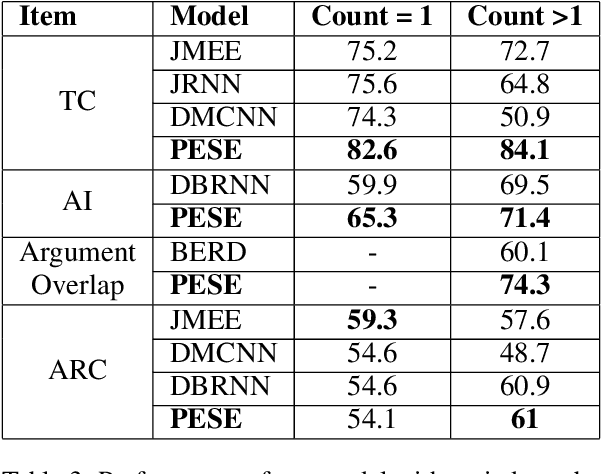
The task of event extraction (EE) aims to find the events and event-related argument information from the text and represent them in a structured format. Most previous works try to solve the problem by separately identifying multiple substructures and aggregating them to get the complete event structure. The problem with the methods is that it fails to identify all the interdependencies among the event participants (event-triggers, arguments, and roles). In this paper, we represent each event record in a unique tuple format that contains trigger phrase, trigger type, argument phrase, and corresponding role information. Our proposed pointer network-based encoder-decoder model generates an event tuple in each time step by exploiting the interactions among event participants and presenting a truly end-to-end solution to the EE task. We evaluate our model on the ACE2005 dataset, and experimental results demonstrate the effectiveness of our model by achieving competitive performance compared to the state-of-the-art methods.
Lung-Net: A deep learning framework for lung tissue segmentation in three-dimensional thoracic CT images
Dec 28, 2022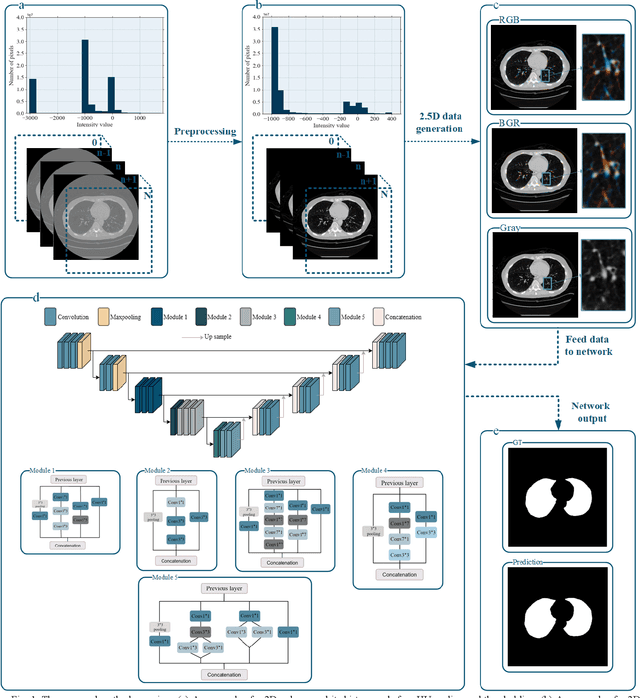
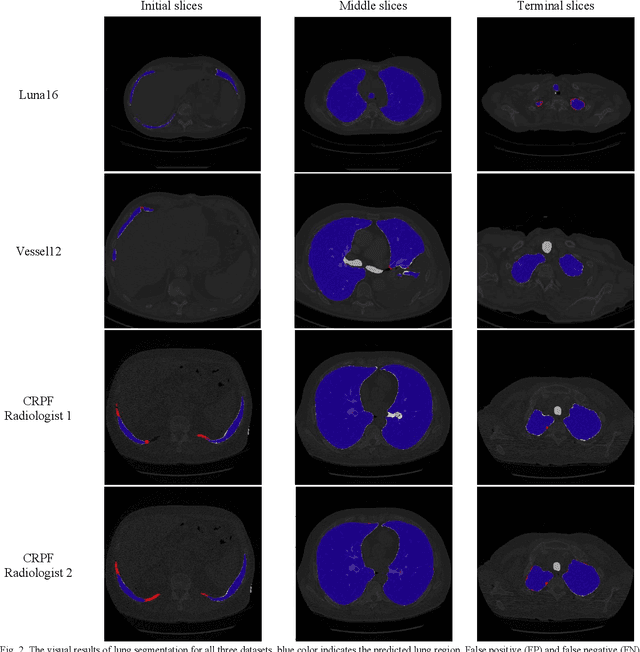
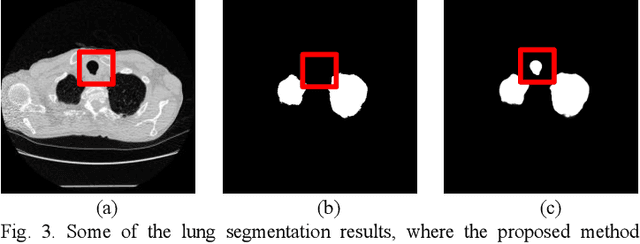
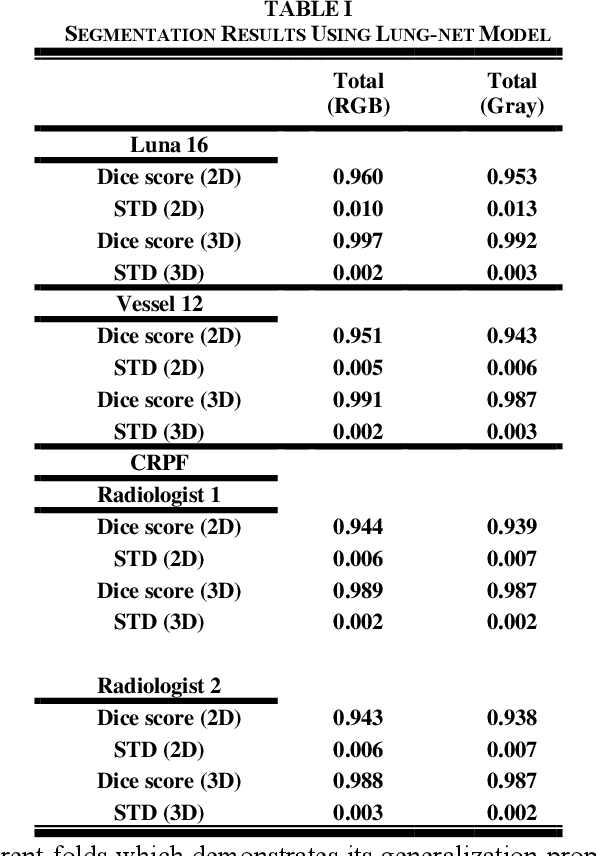
Segmentation of lung tissue in computed tomography (CT) images is a precursor to most pulmonary image analysis applications. Semantic segmentation methods using deep learning have exhibited top-tier performance in recent years. This paper presents a fully automatic method for identifying the lungs in three-dimensional (3D) pulmonary CT images, which we call it Lung-Net. We conjectured that a significant deeper network with inceptionV3 units can achieve a better feature representation of lung CT images without increasing the model complexity in terms of the number of trainable parameters. The method has three main advantages. First, a U-Net architecture with InceptionV3 blocks is developed to resolve the problem of performance degradation and parameter overload. Then, using information from consecutive slices, a new data structure is created to increase generalization potential, allowing more discriminating features to be extracted by making data representation as efficient as possible. Finally, the robustness of the proposed segmentation framework was quantitatively assessed using one public database to train and test the model (LUNA16) and two public databases (ISBI VESSEL12 challenge and CRPF dataset) only for testing the model; each database consists of 700, 23, and 40 CT images, respectively, that were acquired with a different scanner and protocol. Based on the experimental results, the proposed method achieved competitive results over the existing techniques with Dice coefficient of 99.7, 99.1, and 98.8 for LUNA16, VESSEL12, and CRPF datasets, respectively. For segmenting lung tissue in CT images, the proposed model is efficient in terms of time and parameters and outperforms other state-of-the-art methods. Additionally, this model is publicly accessible via a graphical user interface.
On Analyzing the Role of Image for Visual-enhanced Relation Extraction
Nov 14, 2022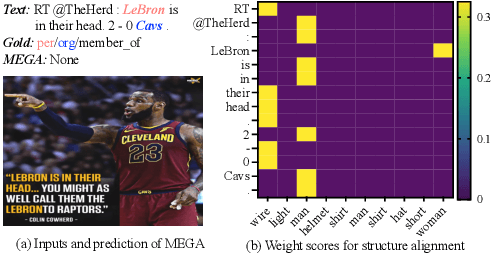

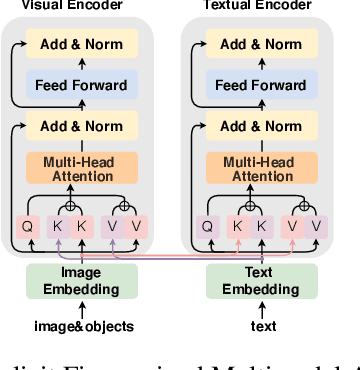
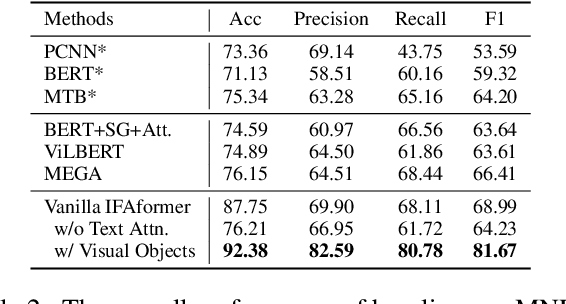
Multimodal relation extraction is an essential task for knowledge graph construction. In this paper, we take an in-depth empirical analysis that indicates the inaccurate information in the visual scene graph leads to poor modal alignment weights, further degrading performance. Moreover, the visual shuffle experiments illustrate that the current approaches may not take full advantage of visual information. Based on the above observation, we further propose a strong baseline with an implicit fine-grained multimodal alignment based on Transformer for multimodal relation extraction. Experimental results demonstrate the better performance of our method. Codes are available at https://github.com/zjunlp/DeepKE/tree/main/example/re/multimodal.
Joint Spatio-Temporal Modeling for the Semantic Change Detection in Remote Sensing Images
Dec 17, 2022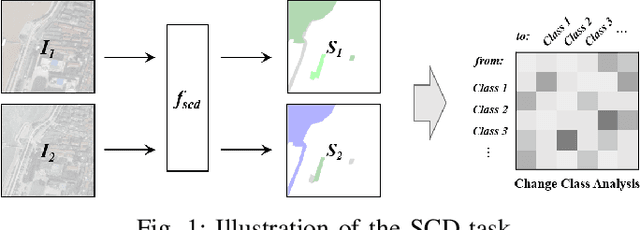
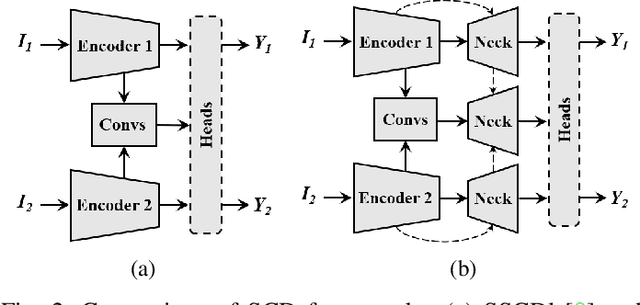
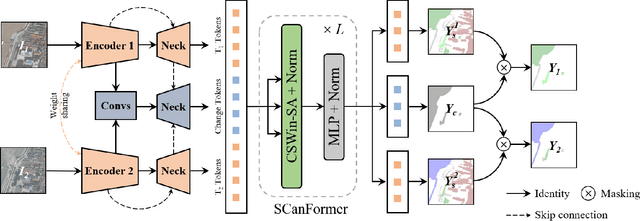
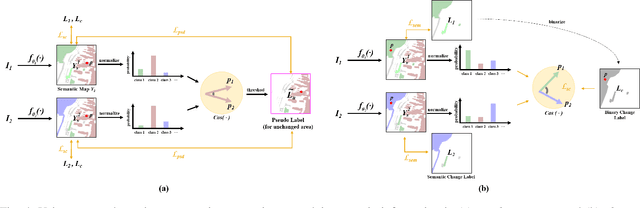
Semantic Change Detection (SCD) refers to the task of simultaneously extracting the changed areas and the semantic categories (before and after the changes) in Remote Sensing Images (RSIs). This is more meaningful than Binary Change Detection (BCD) since it enables detailed change analysis in the observed areas. Previous works established triple-branch Convolutional Neural Network (CNN) architectures as the paradigm for SCD. However, it remains challenging to exploit semantic information with a limited amount of change samples. In this work, we investigate to jointly consider the spatio-temporal dependencies to improve the accuracy of SCD. First, we propose a Semantic Change Transformer (SCanFormer) to explicitly model the 'from-to' semantic transitions between the bi-temporal RSIs. Then, we introduce a semantic learning scheme to leverage the spatio-temporal constraints, which are coherent to the SCD task, to guide the learning of semantic changes. The resulting network (SCanNet) significantly outperforms the baseline method in terms of both detection of critical semantic changes and semantic consistency in the obtained bi-temporal results. It achieves the SOTA accuracy on two benchmark datasets for the SCD.
Neuromorphic Computing and Sensing in Space
Dec 17, 2022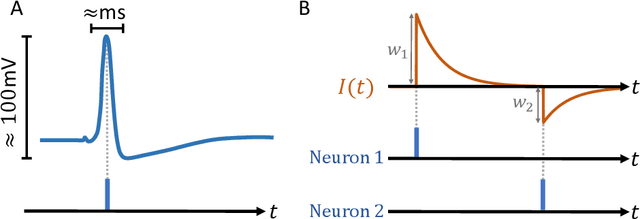
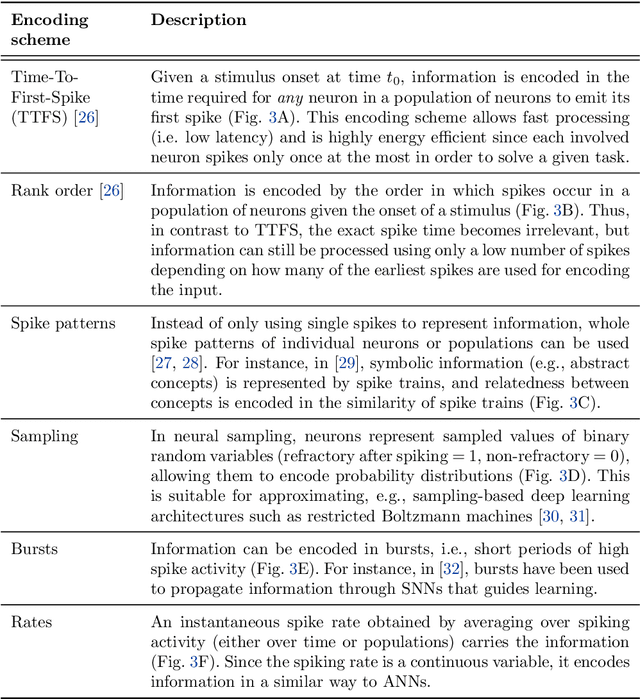
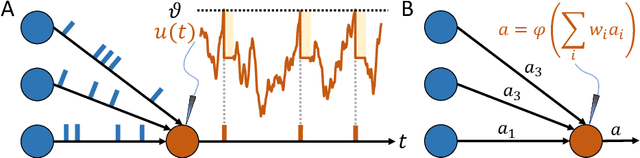
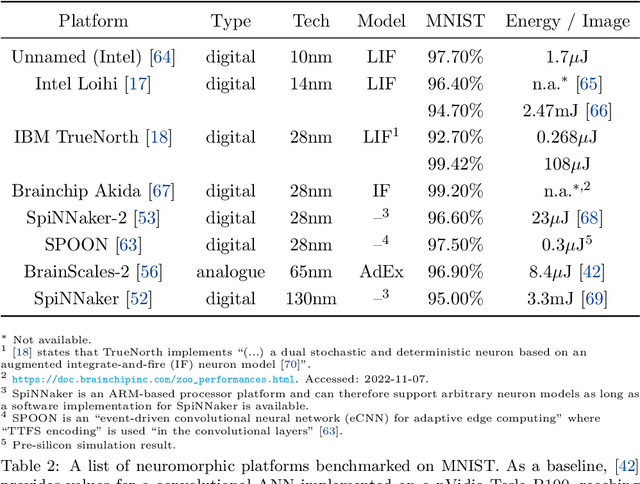
The term ``neuromorphic'' refers to systems that are closely resembling the architecture and/or the dynamics of biological neural networks. Typical examples are novel computer chips designed to mimic the architecture of a biological brain, or sensors that get inspiration from, e.g., the visual or olfactory systems in insects and mammals to acquire information about the environment. This approach is not without ambition as it promises to enable engineered devices able to reproduce the level of performance observed in biological organisms -- the main immediate advantage being the efficient use of scarce resources, which translates into low power requirements. The emphasis on low power and energy efficiency of neuromorphic devices is a perfect match for space applications. Spacecraft -- especially miniaturized ones -- have strict energy constraints as they need to operate in an environment which is scarce with resources and extremely hostile. In this work we present an overview of early attempts made to study a neuromorphic approach in a space context at the European Space Agency's (ESA) Advanced Concepts Team (ACT).
Cascaded Compositional Residual Learning for Complex Interactive Behaviors
Dec 17, 2022
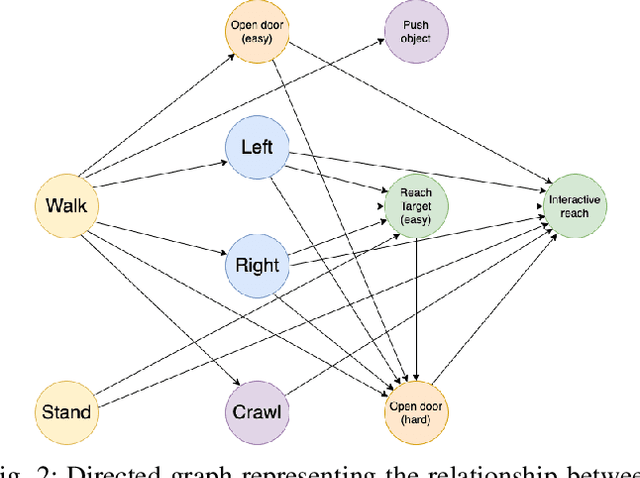
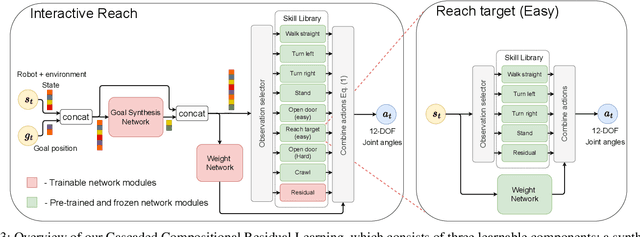

Real-world autonomous missions often require rich interaction with nearby objects, such as doors or switches, along with effective navigation. However, such complex behaviors are difficult to learn because they involve both high-level planning and low-level motor control. We present a novel framework, Cascaded Compositional Residual Learning (CCRL), which learns composite skills by recursively leveraging a library of previously learned control policies. Our framework learns multiplicative policy composition, task-specific residual actions, and synthetic goal information simultaneously while freezing the prerequisite policies. We further explicitly control the style of the motion by regularizing residual actions. We show that our framework learns joint-level control policies for a diverse set of motor skills ranging from basic locomotion to complex interactive navigation, including navigating around obstacles, pushing objects, crawling under a table, pushing a door open with its leg, and holding it open while walking through it. The proposed CCRL framework leads to policies with consistent styles and lower joint torques, which we successfully transfer to a real Unitree A1 robot without any additional fine-tuning.
Claim Optimization in Computational Argumentation
Dec 17, 2022
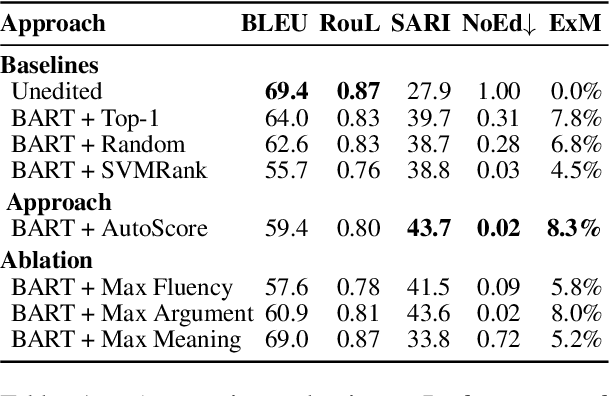
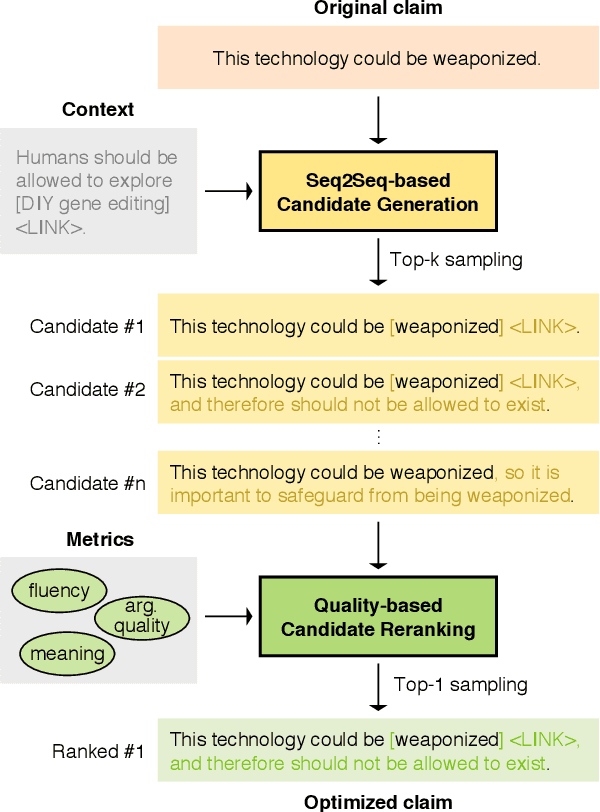
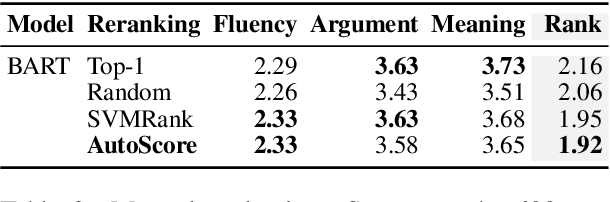
An optimal delivery of arguments is key to persuasion in any debate, both for humans and for AI systems. This requires the use of clear and fluent claims relevant to the given debate. Prior work has studied the automatic assessment of argument quality extensively. Yet, no approach actually improves the quality so far. Our work is the first step towards filling this gap. We propose the task of claim optimization: to rewrite argumentative claims to optimize their delivery. As an initial approach, we first generate a candidate set of optimized claims using a sequence-to-sequence model, such as BART, while taking into account contextual information. Our key idea is then to rerank generated candidates with respect to different quality metrics to find the best optimization. In automatic and human evaluation, we outperform different reranking baselines on an English corpus, improving 60% of all claims (worsening 16% only). Follow-up analyses reveal that, beyond copy editing, our approach often specifies claims with details, whereas it adds less evidence than humans do. Moreover, its capabilities generalize well to other domains, such as instructional texts.
Training Robots to Evaluate Robots: Example-Based Interactive Reward Functions for Policy Learning
Dec 17, 2022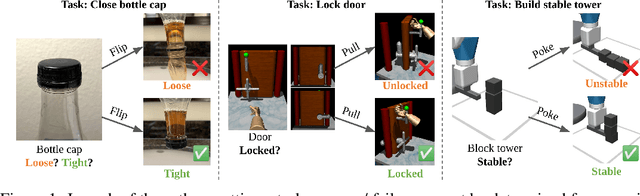

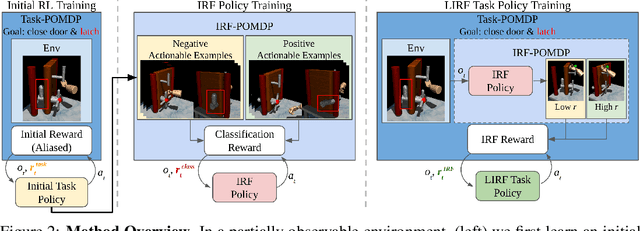

Physical interactions can often help reveal information that is not readily apparent. For example, we may tug at a table leg to evaluate whether it is built well, or turn a water bottle upside down to check that it is watertight. We propose to train robots to acquire such interactive behaviors automatically, for the purpose of evaluating the result of an attempted robotic skill execution. These evaluations in turn serve as "interactive reward functions" (IRFs) for training reinforcement learning policies to perform the target skill, such as screwing the table leg tightly. In addition, even after task policies are fully trained, IRFs can serve as verification mechanisms that improve online task execution. For any given task, our IRFs can be conveniently trained using only examples of successful outcomes, and no further specification is needed to train the task policy thereafter. In our evaluations on door locking and weighted block stacking in simulation, and screw tightening on a real robot, IRFs enable large performance improvements, even outperforming baselines with access to demonstrations or carefully engineered rewards. Project website: https://sites.google.com/view/lirf-corl-2022/
Controlling Styles in Neural Machine Translation with Activation Prompt
Dec 17, 2022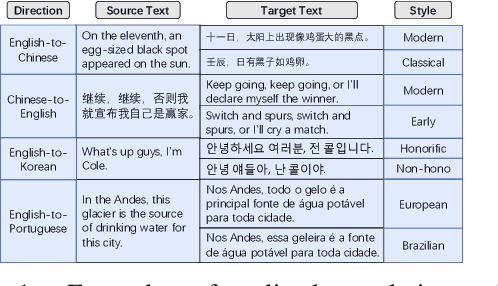

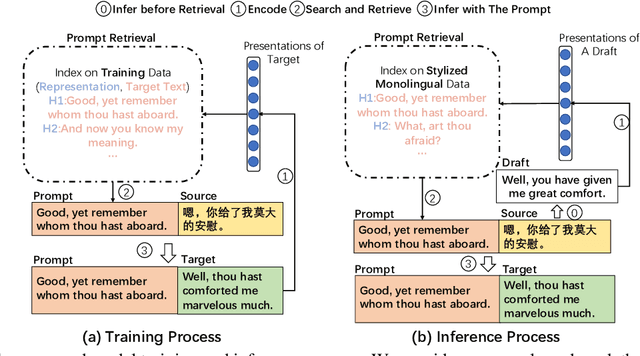

Neural machine translation(NMT) has aroused wide attention due to its impressive quality. Beyond quality, controlling translation styles is also an important demand for many languages. Previous related studies mainly focus on controlling formality and gain some improvements. However, they still face two challenges. The first is the evaluation limitation. Style contains abundant information including lexis, syntax, etc. But only formality is well studied. The second is the heavy reliance on iterative fine-tuning when new styles are required. Correspondingly, this paper contributes in terms of the benchmark and approach. First, we re-visit this task and propose a multiway stylized machine translation (MSMT) benchmark, which includes multiple categories of styles in four language directions to push the boundary of this task. Second, we propose a method named style activation prompt (StyleAP) by retrieving prompts from stylized monolingual corpus, which needs no extra fine-tuning. Experiments show that StyleAP could effectively control the style of translation and achieve remarkable performance. All of our data and code are released at https://github.com/IvanWang0730/StyleAP.