 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Machine Learning and Thermography Applied to the Detection and Classification of Cracks in Building
Dec 30, 2022
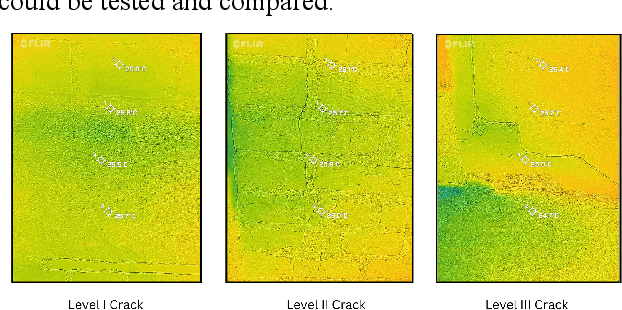

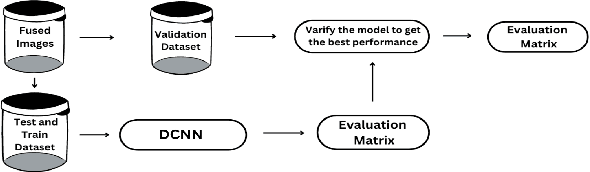
Due to the environmental impacts caused by the construction industry, repurposing existing buildings and making them more energy-efficient has become a high-priority issue. However, a legitimate concern of land developers is associated with the buildings' state of conservation. For that reason, infrared thermography has been used as a powerful tool to characterize these buildings' state of conservation by detecting pathologies, such as cracks and humidity. Thermal cameras detect the radiation emitted by any material and translate it into temperature-color-coded images. Abnormal temperature changes may indicate the presence of pathologies, however, reading thermal images might not be quite simple. This research project aims to combine infrared thermography and machine learning (ML) to help stakeholders determine the viability of reusing existing buildings by identifying their pathologies and defects more efficiently and accurately. In this particular phase of this research project, we've used an image classification machine learning model of Convolutional Neural Networks (DCNN) to differentiate three levels of cracks in one particular building. The model's accuracy was compared between the MSX and thermal images acquired from two distinct thermal cameras and fused images (formed through multisource information) to test the influence of the input data and network on the detection results.
How would Stance Detection Techniques Evolve after the Launch of ChatGPT?
Dec 30, 2022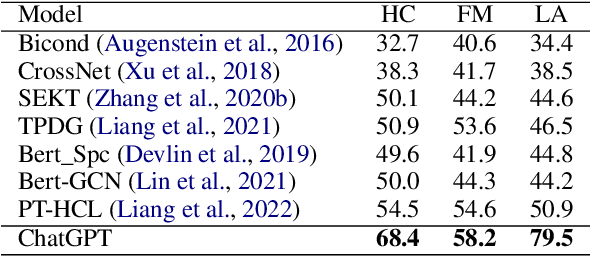
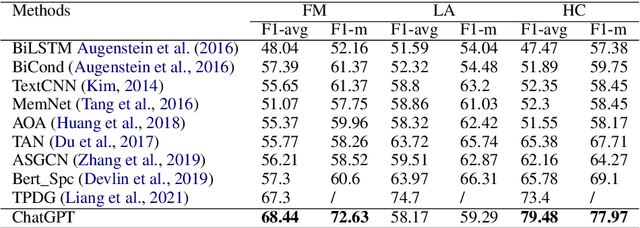
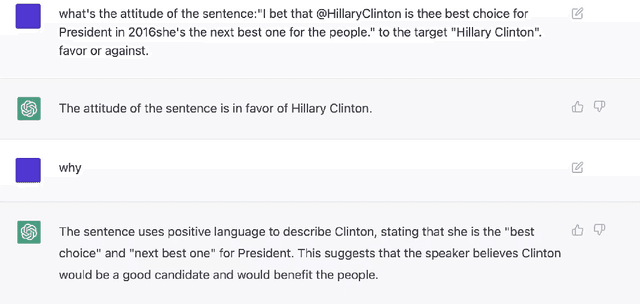
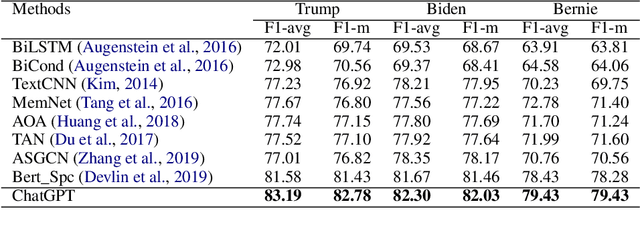
Stance detection refers to the task of extracting the standpoint (Favor, Against or Neither) towards a target in given texts. Such research gains increasing attention with the proliferation of social media contents. The conventional framework of handling stance detection is converting it into text classification tasks. Deep learning models have already replaced rule-based models and traditional machine learning models in solving such problems. Current deep neural networks are facing two main challenges which are insufficient labeled data and information in social media posts and the unexplainable nature of deep learning models. A new pre-trained language model chatGPT was launched on Nov 30, 2022. For the stance detection tasks, our experiments show that ChatGPT can achieve SOTA or similar performance for commonly used datasets including SemEval-2016 and P-Stance. At the same time, ChatGPT can provide explanation for its own prediction, which is beyond the capability of any existing model. The explanations for the cases it cannot provide classification results are especially useful. ChatGPT has the potential to be the best AI model for stance detection tasks in NLP, or at least change the research paradigm of this field. ChatGPT also opens up the possibility of building explanatory AI for stance detection.
Reliable extrapolation of deep neural operators informed by physics or sparse observations
Dec 13, 2022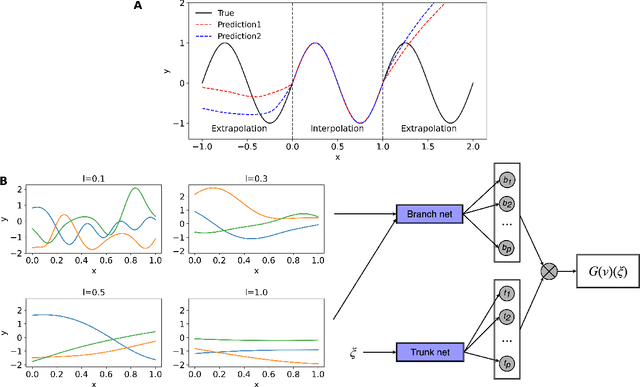
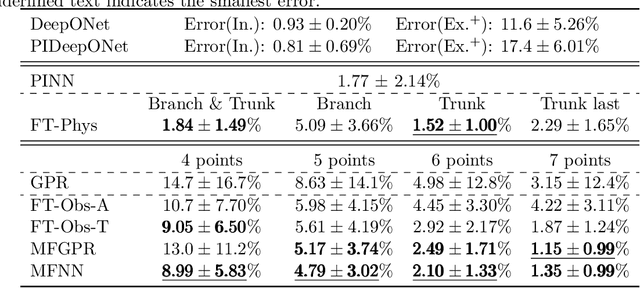
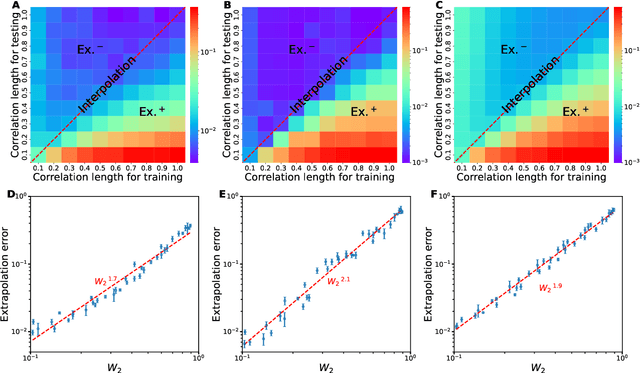
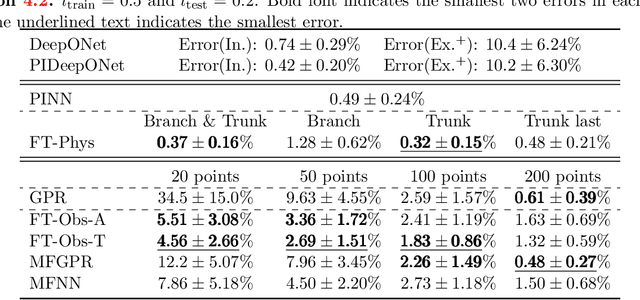
Deep neural operators can learn nonlinear mappings between infinite-dimensional function spaces via deep neural networks. As promising surrogate solvers of partial differential equations (PDEs) for real-time prediction, deep neural operators such as deep operator networks (DeepONets) provide a new simulation paradigm in science and engineering. Pure data-driven neural operators and deep learning models, in general, are usually limited to interpolation scenarios, where new predictions utilize inputs within the support of the training set. However, in the inference stage of real-world applications, the input may lie outside the support, i.e., extrapolation is required, which may result to large errors and unavoidable failure of deep learning models. Here, we address this challenge of extrapolation for deep neural operators. First, we systematically investigate the extrapolation behavior of DeepONets by quantifying the extrapolation complexity via the 2-Wasserstein distance between two function spaces and propose a new behavior of bias-variance trade-off for extrapolation with respect to model capacity. Subsequently, we develop a complete workflow, including extrapolation determination, and we propose five reliable learning methods that guarantee a safe prediction under extrapolation by requiring additional information -- the governing PDEs of the system or sparse new observations. The proposed methods are based on either fine-tuning a pre-trained DeepONet or multifidelity learning. We demonstrate the effectiveness of the proposed framework for various types of parametric PDEs. Our systematic comparisons provide practical guidelines for selecting a proper extrapolation method depending on the available information, desired accuracy, and required inference speed.
Measuring the Mixing of Contextual Information in the Transformer
Mar 14, 2022
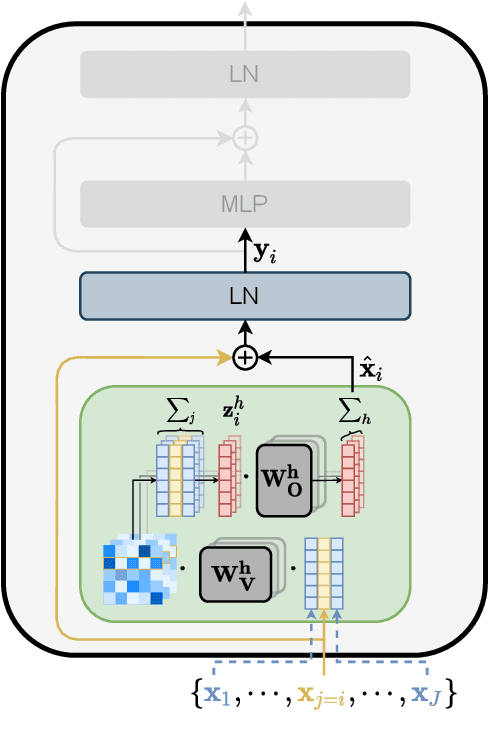
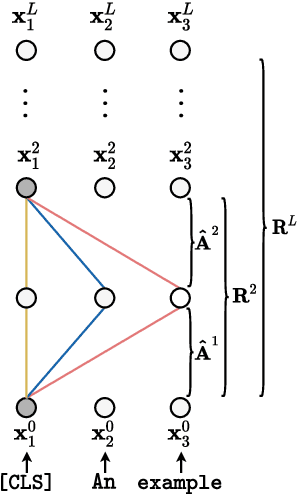

The Transformer architecture aggregates input information through the self-attention mechanism, but there is no clear understanding of how this information is mixed across the entire model. Additionally, recent works have demonstrated that attention weights alone are not enough to describe the flow of information. In this paper, we consider the whole attention block -- multi-head attention, residual connection, and layer normalization -- and define a metric to measure token-to-token interactions within each layer, considering the characteristics of the representation space. Then, we aggregate layer-wise interpretations to provide input attribution scores for model predictions. Experimentally, we show that our method, ALTI (Aggregation of Layer-wise Token-to-token Interactions), provides faithful explanations and outperforms similar aggregation methods.
Mimicking non-ideal instrument behavior for hologram processing using neural style translation
Jan 07, 2023

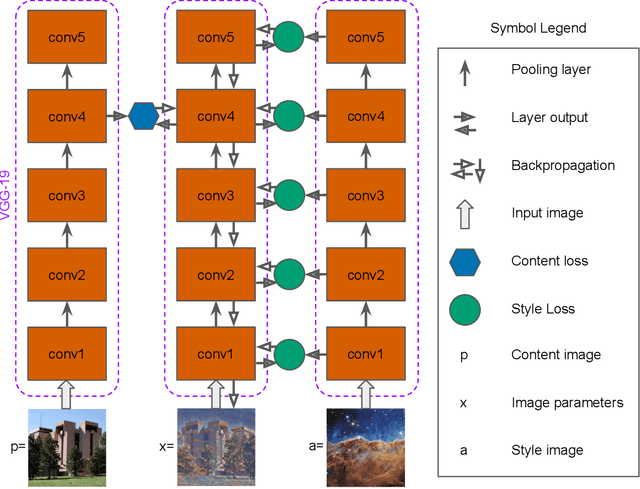
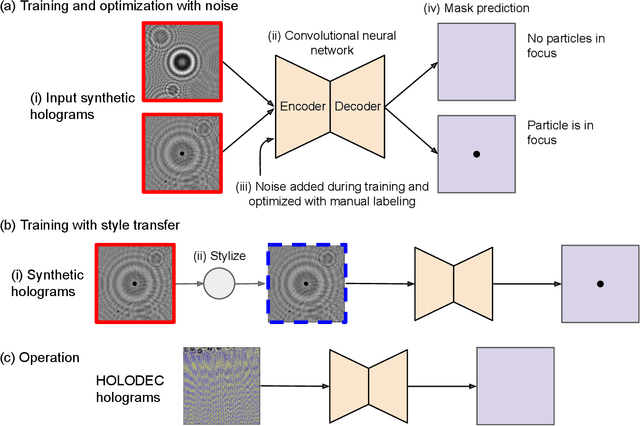
Holographic cloud probes provide unprecedented information on cloud particle density, size and position. Each laser shot captures particles within a large volume, where images can be computationally refocused to determine particle size and shape. However, processing these holograms, either with standard methods or with machine learning (ML) models, requires considerable computational resources, time and occasional human intervention. ML models are trained on simulated holograms obtained from the physical model of the probe since real holograms have no absolute truth labels. Using another processing method to produce labels would be subject to errors that the ML model would subsequently inherit. Models perform well on real holograms only when image corruption is performed on the simulated images during training, thereby mimicking non-ideal conditions in the actual probe (Schreck et. al, 2022). Optimizing image corruption requires a cumbersome manual labeling effort. Here we demonstrate the application of the neural style translation approach (Gatys et. al, 2016) to the simulated holograms. With a pre-trained convolutional neural network (VGG-19), the simulated holograms are ``stylized'' to resemble the real ones obtained from the probe, while at the same time preserving the simulated image ``content'' (e.g. the particle locations and sizes). Two image similarity metrics concur that the stylized images are more like real holograms than the synthetic ones. With an ML model trained to predict particle locations and shapes on the stylized data sets, we observed comparable performance on both simulated and real holograms, obviating the need to perform manual labeling. The described approach is not specific to hologram images and could be applied in other domains for capturing noise and imperfections in observational instruments to make simulated data more like real world observations.
Interactive Feature Embedding for Infrared and Visible Image Fusion
Nov 09, 2022
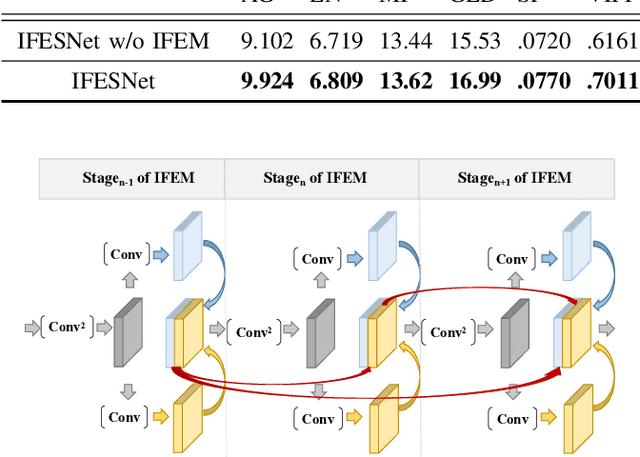
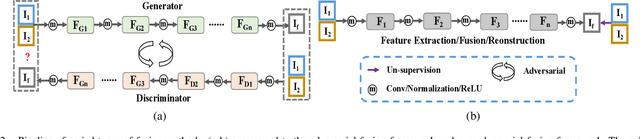
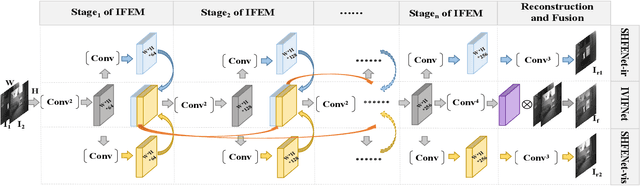
General deep learning-based methods for infrared and visible image fusion rely on the unsupervised mechanism for vital information retention by utilizing elaborately designed loss functions. However, the unsupervised mechanism depends on a well designed loss function, which cannot guarantee that all vital information of source images is sufficiently extracted. In this work, we propose a novel interactive feature embedding in self-supervised learning framework for infrared and visible image fusion, attempting to overcome the issue of vital information degradation. With the help of self-supervised learning framework, hierarchical representations of source images can be efficiently extracted. In particular, interactive feature embedding models are tactfully designed to build a bridge between the self-supervised learning and infrared and visible image fusion learning, achieving vital information retention. Qualitative and quantitative evaluations exhibit that the proposed method performs favorably against state-of-the-art methods.
CI-GNN: A Granger Causality-Inspired Graph Neural Network for Interpretable Brain Network-Based Psychiatric Diagnosis
Jan 04, 2023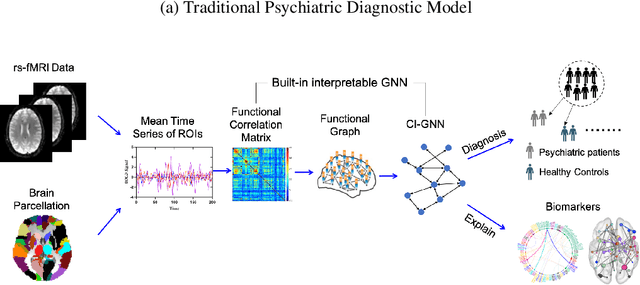
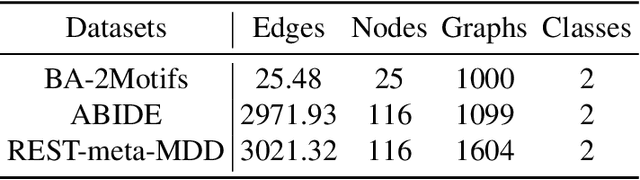
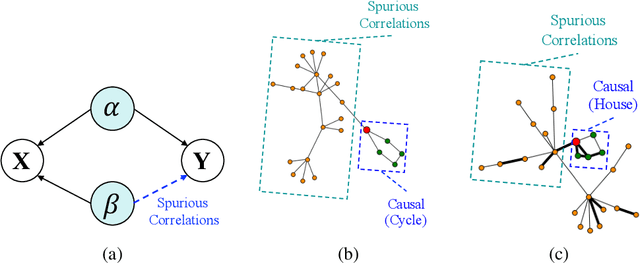
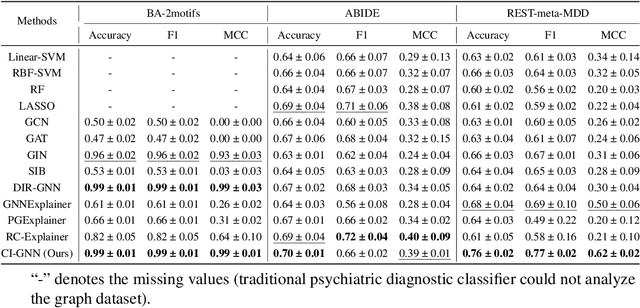
There is a recent trend to leverage the power of graph neural networks (GNNs) for brain-network based psychiatric diagnosis, which,in turn, also motivates an urgent need for psychiatrists to fully understand the decision behavior of the used GNNs. However, most of the existing GNN explainers are either post-hoc in which another interpretive model needs to be created to explain a well-trained GNN, or do not consider the causal relationship between the extracted explanation and the decision, such that the explanation itself contains spurious correlations and suffers from weak faithfulness. In this work, we propose a granger causality-inspired graph neural network (CI-GNN), a built-in interpretable model that is able to identify the most influential subgraph (i.e., functional connectivity within brain regions) that is causally related to the decision (e.g., major depressive disorder patients or healthy controls), without the training of an auxillary interpretive network. CI-GNN learns disentangled subgraph-level representations {\alpha} and \b{eta} that encode, respectively, the causal and noncausal aspects of original graph under a graph variational autoencoder framework, regularized by a conditional mutual information (CMI) constraint. We theoretically justify the validity of the CMI regulation in capturing the causal relationship. We also empirically evaluate the performance of CI-GNN against three baseline GNNs and four state-of-the-art GNN explainers on synthetic data and two large-scale brain disease datasets. We observe that CI-GNN achieves the best performance in a wide range of metrics and provides more reliable and concise explanations which have clinical evidence.
An Unpaired Cross-modality Segmentation Framework Using Data Augmentation and Hybrid Convolutional Networks for Segmenting Vestibular Schwannoma and Cochlea
Nov 28, 2022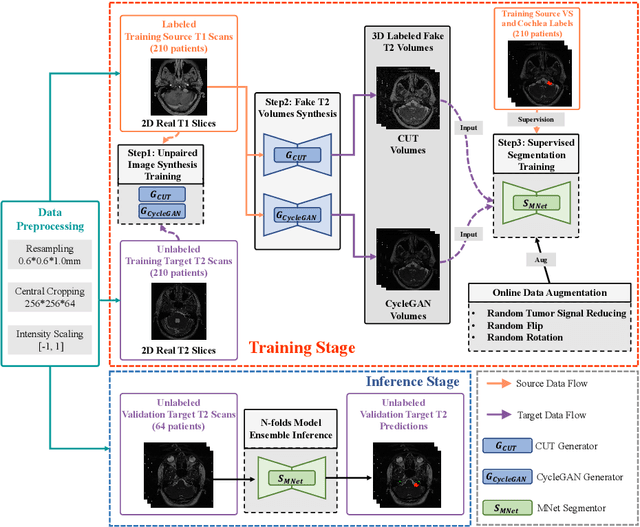
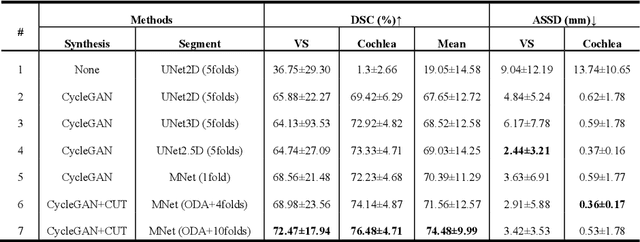
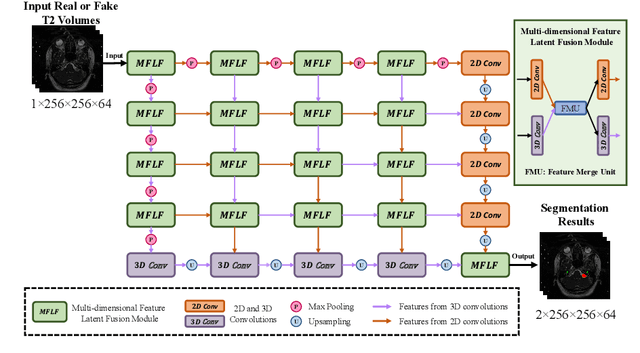
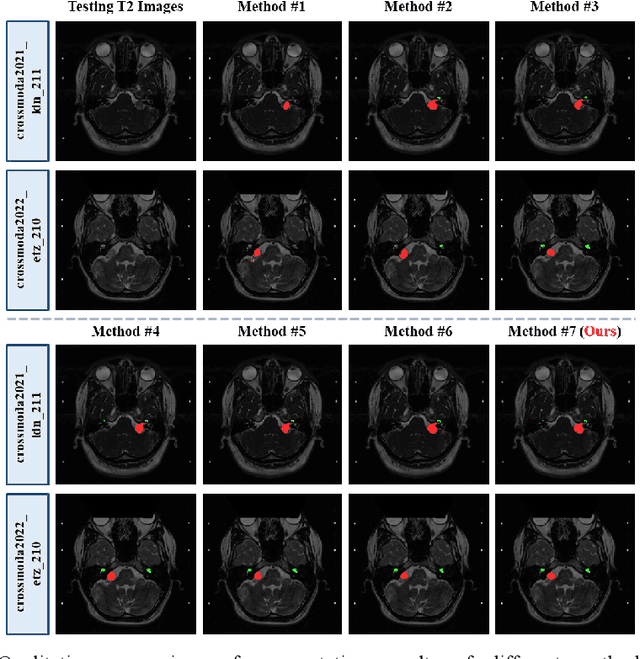
The crossMoDA challenge aims to automatically segment the vestibular schwannoma (VS) tumor and cochlea regions of unlabeled high-resolution T2 scans by leveraging labeled contrast-enhanced T1 scans. The 2022 edition extends the segmentation task by including multi-institutional scans. In this work, we proposed an unpaired cross-modality segmentation framework using data augmentation and hybrid convolutional networks. Considering heterogeneous distributions and various image sizes for multi-institutional scans, we apply the min-max normalization for scaling the intensities of all scans between -1 and 1, and use the voxel size resampling and center cropping to obtain fixed-size sub-volumes for training. We adopt two data augmentation methods for effectively learning the semantic information and generating realistic target domain scans: generative and online data augmentation. For generative data augmentation, we use CUT and CycleGAN to generate two groups of realistic T2 volumes with different details and appearances for supervised segmentation training. For online data augmentation, we design a random tumor signal reducing method for simulating the heterogeneity of VS tumor signals. Furthermore, we utilize an advanced hybrid convolutional network with multi-dimensional convolutions to adaptively learn sparse inter-slice information and dense intra-slice information for accurate volumetric segmentation of VS tumor and cochlea regions in anisotropic scans. On the crossMoDA2022 validation dataset, our method produces promising results and achieves the mean DSC values of 72.47% and 76.48% and ASSD values of 3.42 mm and 0.53 mm for VS tumor and cochlea regions, respectively.
A Novel Approach For Generating Customizable Light Field Datasets for Machine Learning
Dec 13, 2022
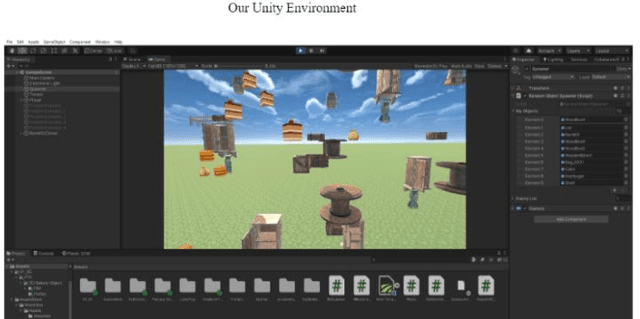

To train deep learning models, which often outperform traditional approaches, large datasets of a specified medium, e.g., images, are used in numerous areas. However, for light field-specific machine learning tasks, there is a lack of such available datasets. Therefore, we create our own light field datasets, which have great potential for a variety of applications due to the abundance of information in light fields compared to singular images. Using the Unity and C# frameworks, we develop a novel approach for generating large, scalable, and reproducible light field datasets based on customizable hardware configurations to accelerate light field deep learning research.
Leave Graphs Alone: Addressing Over-Squashing without Rewiring
Dec 13, 2022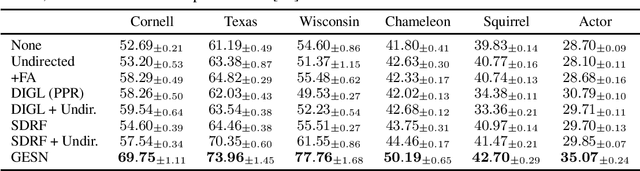
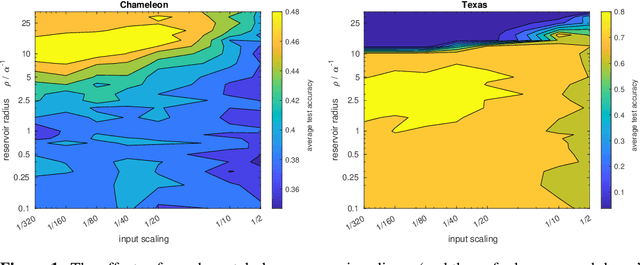
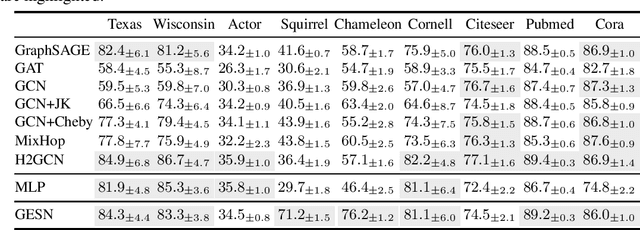
Recent works have investigated the role of graph bottlenecks in preventing long-range information propagation in message-passing graph neural networks, causing the so-called `over-squashing' phenomenon. As a remedy, graph rewiring mechanisms have been proposed as preprocessing steps. Graph Echo State Networks (GESNs) are a reservoir computing model for graphs, where node embeddings are recursively computed by an untrained message-passing function. In this paper, we show that GESNs can achieve a significantly better accuracy on six heterophilic node classification tasks without altering the graph connectivity, thus suggesting a different route for addressing the over-squashing problem.