 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Motion-Guided Dual-Camera Tracker for Low-Cost Skill Evaluation of Gastric Endoscopy
Mar 08, 2024
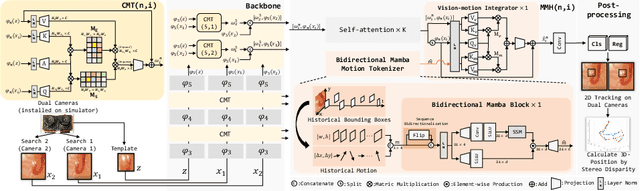
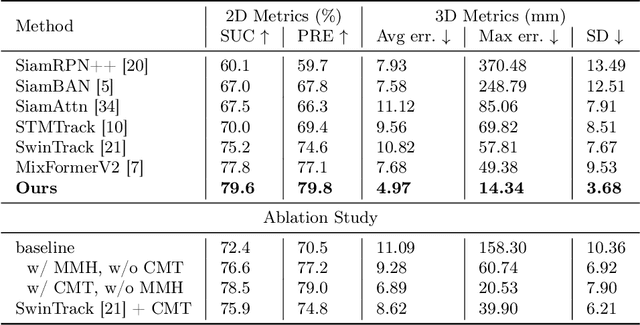
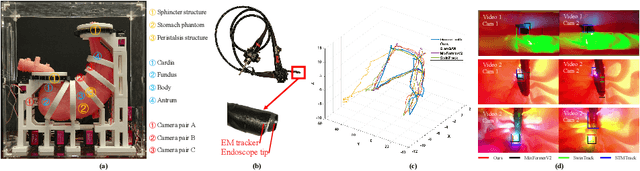
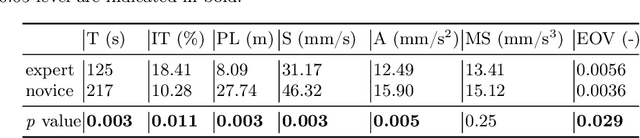
Gastric simulators with objective educational feedback have been proven useful for endoscopy training. Existing electronic simulators with feedback are however not commonly adopted due to their high cost. In this work, a motion-guided dual-camera tracker is proposed to provide reliable endoscope tip position feedback at a low cost inside a mechanical simulator for endoscopy skill evaluation, tackling several unique challenges. To address the issue of significant appearance variation of the endoscope tip while keeping dual-camera tracking consistency, the cross-camera mutual template strategy (CMT) is proposed to introduce dynamic transient mutual templates to dual-camera tracking. To alleviate disturbance from large occlusion and distortion by the light source from the endoscope tip, the Mamba-based motion-guided prediction head (MMH) is presented to aggregate visual tracking with historical motion information modeled by the state space model. The proposed tracker was evaluated on datasets captured by low-cost camera pairs during endoscopy procedures performed inside the mechanical simulator. The tracker achieves SOTA performance with robust and consistent tracking on dual cameras. Further downstream evaluation proves that the 3D tip position determined by the proposed tracker enables reliable skill differentiation. The code and dataset will be released upon acceptance.
GraphEdit: Large Language Models for Graph Structure Learning
Mar 05, 2024Graph Structure Learning (GSL) focuses on capturing intrinsic dependencies and interactions among nodes in graph-structured data by generating novel graph structures. Graph Neural Networks (GNNs) have emerged as promising GSL solutions, utilizing recursive message passing to encode node-wise inter-dependencies. However, many existing GSL methods heavily depend on explicit graph structural information as supervision signals, leaving them susceptible to challenges such as data noise and sparsity. In this work, we propose GraphEdit, an approach that leverages large language models (LLMs) to learn complex node relationships in graph-structured data. By enhancing the reasoning capabilities of LLMs through instruction-tuning over graph structures, we aim to overcome the limitations associated with explicit graph structural information and enhance the reliability of graph structure learning. Our approach not only effectively denoises noisy connections but also identifies node-wise dependencies from a global perspective, providing a comprehensive understanding of the graph structure. We conduct extensive experiments on multiple benchmark datasets to demonstrate the effectiveness and robustness of GraphEdit across various settings. We have made our model implementation available at: https://github.com/HKUDS/GraphEdit.
AI Insights: A Case Study on Utilizing ChatGPT Intelligence for Research Paper Analysis
Mar 05, 2024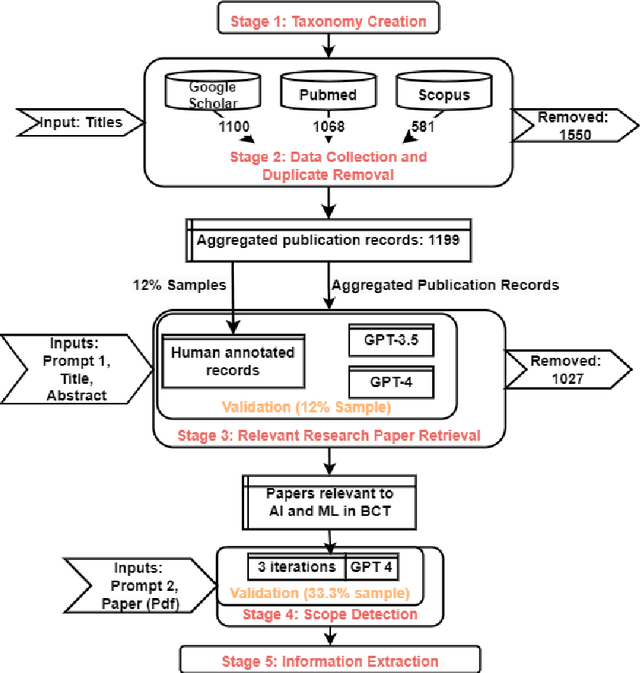

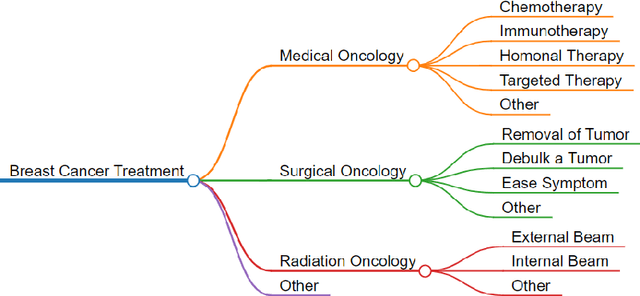
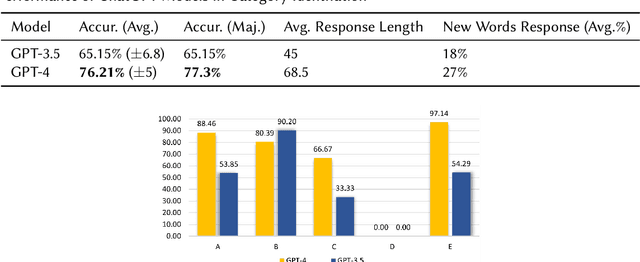
This paper discusses the effectiveness of leveraging Chatbot: Generative Pre-trained Transformer (ChatGPT) versions 3.5 and 4 for analyzing research papers for effective writing of scientific literature surveys. The study selected the \textit{Application of Artificial Intelligence in Breast Cancer Treatment} as the research topic. Research papers related to this topic were collected from three major publication databases Google Scholar, Pubmed, and Scopus. ChatGPT models were used to identify the category, scope, and relevant information from the research papers for automatic identification of relevant papers related to Breast Cancer Treatment (BCT), organization of papers according to scope, and identification of key information for survey paper writing. Evaluations performed using ground truth data annotated using subject experts reveal, that GPT-4 achieves 77.3\% accuracy in identifying the research paper categories and 50\% of the papers were correctly identified by GPT-4 for their scopes. Further, the results demonstrate that GPT-4 can generate reasons for its decisions with an average of 27\% new words, and 67\% of the reasons given by the model were completely agreeable to the subject experts.
Exploring ChatGPT for Next-generation Information Retrieval: Opportunities and Challenges
Feb 17, 2024The rapid advancement of artificial intelligence (AI) has highlighted ChatGPT as a pivotal technology in the field of information retrieval (IR). Distinguished from its predecessors, ChatGPT offers significant benefits that have attracted the attention of both the industry and academic communities. While some view ChatGPT as a groundbreaking innovation, others attribute its success to the effective integration of product development and market strategies. The emergence of ChatGPT, alongside GPT-4, marks a new phase in Generative AI, generating content that is distinct from training examples and exceeding the capabilities of the prior GPT-3 model by OpenAI. Unlike the traditional supervised learning approach in IR tasks, ChatGPT challenges existing paradigms, bringing forth new challenges and opportunities regarding text quality assurance, model bias, and efficiency. This paper seeks to examine the impact of ChatGPT on IR tasks and offer insights into its potential future developments.
* Survey Paper
Causal Disentanglement for Regulating Social Influence Bias in Social Recommendation
Mar 06, 2024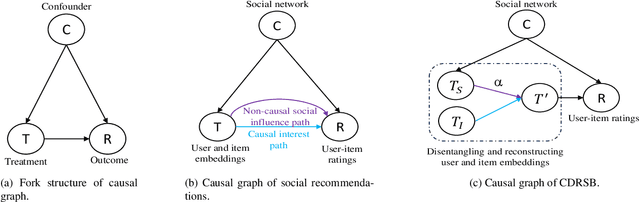

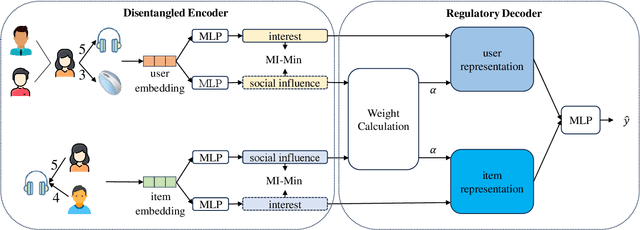
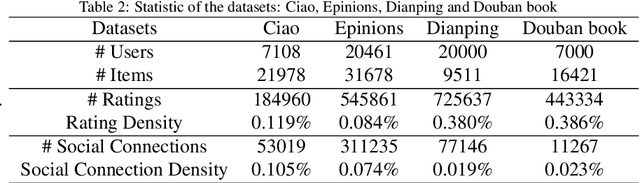
Social recommendation systems face the problem of social influence bias, which can lead to an overemphasis on recommending items that friends have interacted with. Addressing this problem is crucial, and existing methods often rely on techniques such as weight adjustment or leveraging unbiased data to eliminate this bias. However, we argue that not all biases are detrimental, i.e., some items recommended by friends may align with the user's interests. Blindly eliminating such biases could undermine these positive effects, potentially diminishing recommendation accuracy. In this paper, we propose a Causal Disentanglement-based framework for Regulating Social influence Bias in social recommendation, named CDRSB, to improve recommendation performance. From the perspective of causal inference, we find that the user social network could be regarded as a confounder between the user and item embeddings (treatment) and ratings (outcome). Due to the presence of this social network confounder, two paths exist from user and item embeddings to ratings: a non-causal social influence path and a causal interest path. Building upon this insight, we propose a disentangled encoder that focuses on disentangling user and item embeddings into interest and social influence embeddings. Mutual information-based objectives are designed to enhance the distinctiveness of these disentangled embeddings, eliminating redundant information. Additionally, a regulatory decoder that employs a weight calculation module to dynamically learn the weights of social influence embeddings for effectively regulating social influence bias has been designed. Experimental results on four large-scale real-world datasets Ciao, Epinions, Dianping, and Douban book demonstrate the effectiveness of CDRSB compared to state-of-the-art baselines.
Gradient-free neural topology optimization
Mar 07, 2024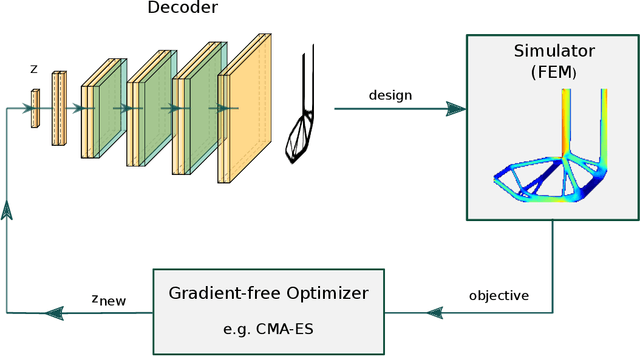
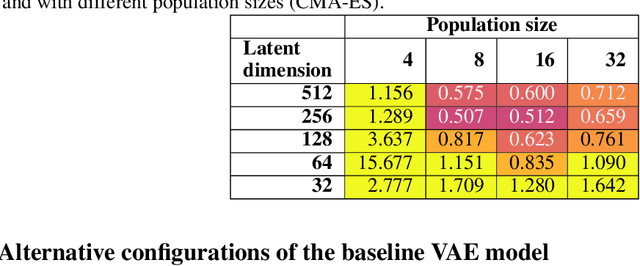
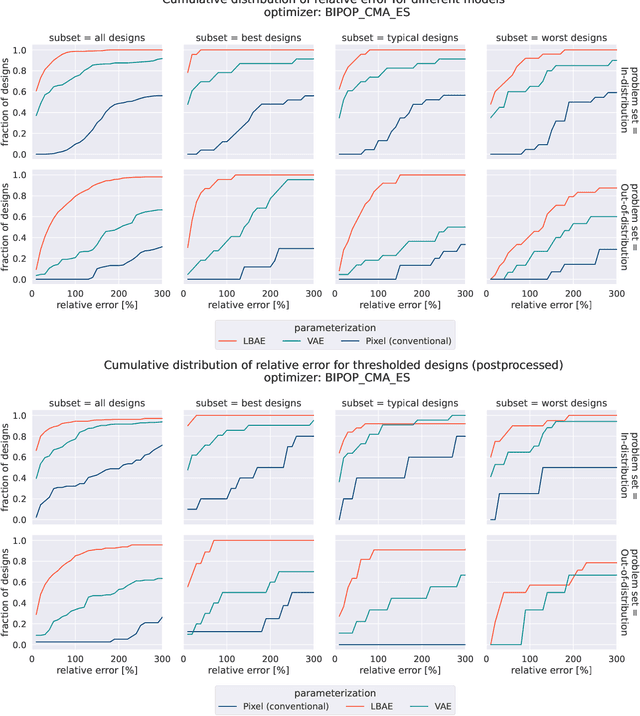
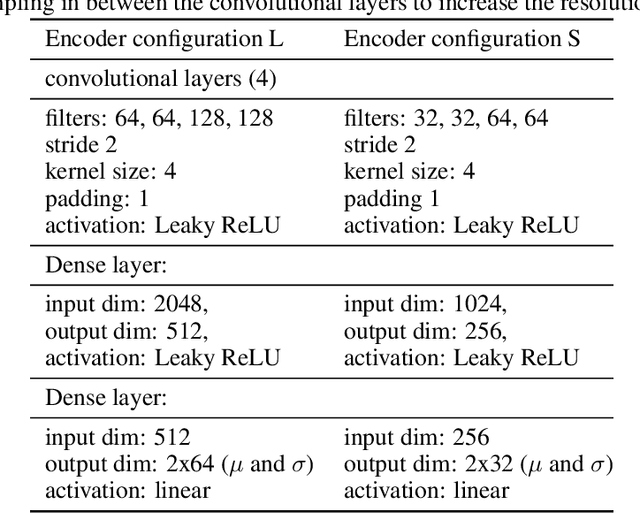
Gradient-free optimizers allow for tackling problems regardless of the smoothness or differentiability of their objective function, but they require many more iterations to converge when compared to gradient-based algorithms. This has made them unviable for topology optimization due to the high computational cost per iteration and high dimensionality of these problems. We propose a pre-trained neural reparameterization strategy that leads to at least one order of magnitude decrease in iteration count when optimizing the designs in latent space, as opposed to the conventional approach without latent reparameterization. We demonstrate this via extensive computational experiments in- and out-of-distribution with the training data. Although gradient-based topology optimization is still more efficient for differentiable problems, such as compliance optimization of structures, we believe this work will open up a new path for problems where gradient information is not readily available (e.g. fracture).
Fundamental limits of Non-Linear Low-Rank Matrix Estimation
Mar 07, 2024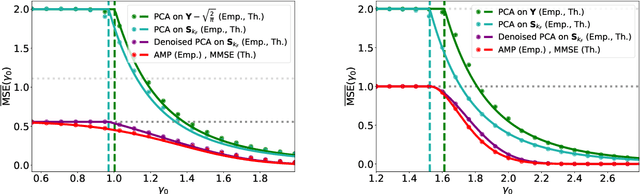
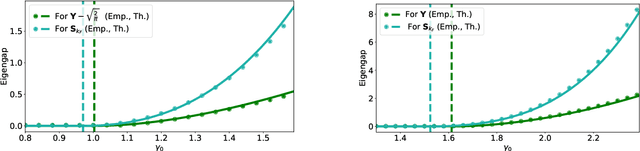
We consider the task of estimating a low-rank matrix from non-linear and noisy observations. We prove a strong universality result showing that Bayes-optimal performances are characterized by an equivalent Gaussian model with an effective prior, whose parameters are entirely determined by an expansion of the non-linear function. In particular, we show that to reconstruct the signal accurately, one requires a signal-to-noise ratio growing as $N^{\frac 12 (1-1/k_F)}$, where $k_F$ is the first non-zero Fisher information coefficient of the function. We provide asymptotic characterization for the minimal achievable mean squared error (MMSE) and an approximate message-passing algorithm that reaches the MMSE under conditions analogous to the linear version of the problem. We also provide asymptotic errors achieved by methods such as principal component analysis combined with Bayesian denoising, and compare them with Bayes-optimal MMSE.
A Modular Approach for Multimodal Summarization of TV Shows
Mar 07, 2024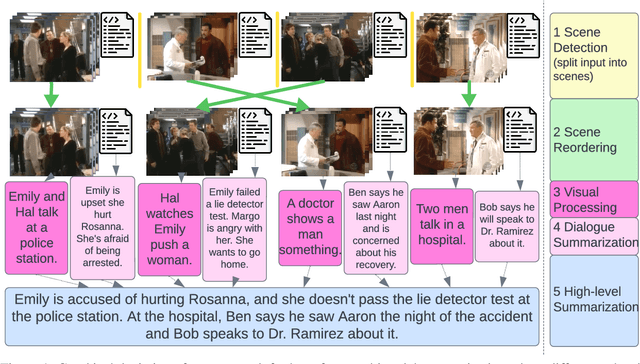
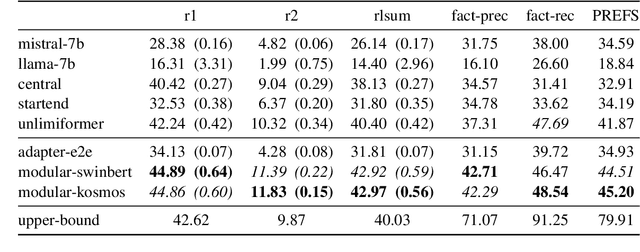
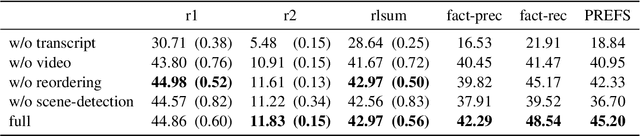

In this paper we address the task of summarizing television shows, which touches key areas in AI research: complex reasoning, multiple modalities, and long narratives. We present a modular approach where separate components perform specialized sub-tasks which we argue affords greater flexibility compared to end-to-end methods. Our modules involve detecting scene boundaries, reordering scenes so as to minimize the number of cuts between different events, converting visual information to text, summarizing the dialogue in each scene, and fusing the scene summaries into a final summary for the entire episode. We also present a new metric, PREFS (Precision and Recall Evaluation of Summary FactS), to measure both precision and recall of generated summaries, which we decompose into atomic facts. Tested on the recently released SummScreen3D dataset Papalampidi and Lapata (2023), our method produces higher quality summaries than comparison models, as measured with ROUGE and our new fact-based metric.
Privacy Amplification for the Gaussian Mechanism via Bounded Support
Mar 07, 2024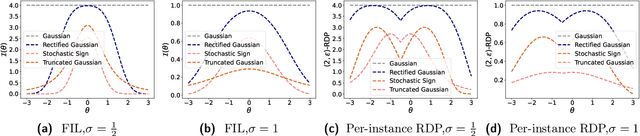

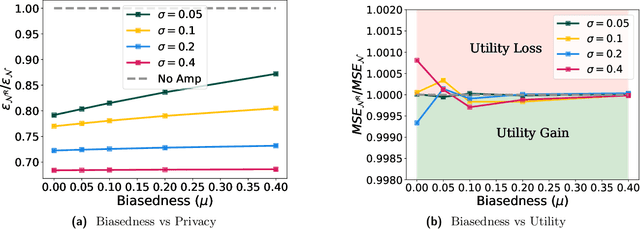

Data-dependent privacy accounting frameworks such as per-instance differential privacy (pDP) and Fisher information loss (FIL) confer fine-grained privacy guarantees for individuals in a fixed training dataset. These guarantees can be desirable compared to vanilla DP in real world settings as they tightly upper-bound the privacy leakage for a $\textit{specific}$ individual in an $\textit{actual}$ dataset, rather than considering worst-case datasets. While these frameworks are beginning to gain popularity, to date, there is a lack of private mechanisms that can fully leverage advantages of data-dependent accounting. To bridge this gap, we propose simple modifications of the Gaussian mechanism with bounded support, showing that they amplify privacy guarantees under data-dependent accounting. Experiments on model training with DP-SGD show that using bounded support Gaussian mechanisms can provide a reduction of the pDP bound $\epsilon$ by as much as 30% without negative effects on model utility.
Combined optimization ghost imaging based on random speckle field
Mar 06, 2024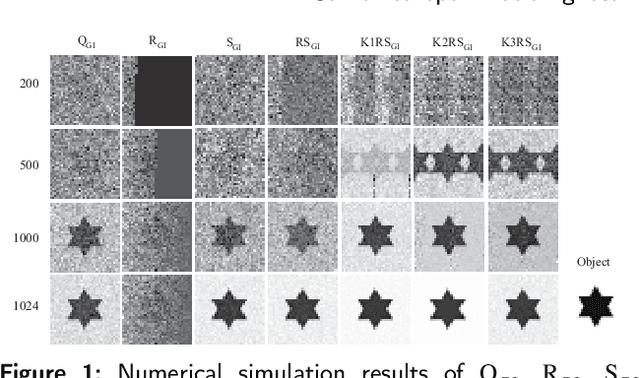

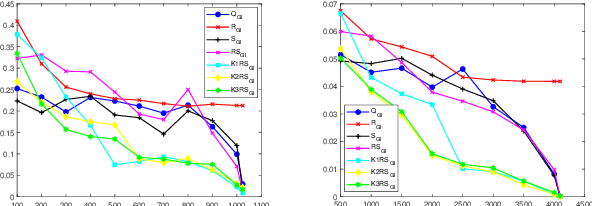
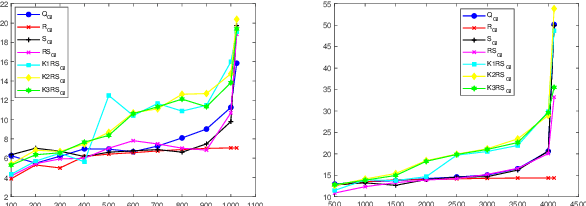
Ghost imaging is a non local imaging technology, which can obtain target information by measuring the second-order intensity correlation between the reference light field and the target detection light field. However, the current imaging environment requires a large number of measurement data, and the imaging results also have the problems of low image resolution and long reconstruction time. Therefore, using orthogonal methods such as QR decomposition, a variety of optimization methods for speckle patterns are designed combined with Kronecker product,which can help to shorten the imaging time, improve the imaging quality and image noise resistance.