 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Transformer and GAN Based Super-Resolution Reconstruction Network for Medical Images
Dec 26, 2022
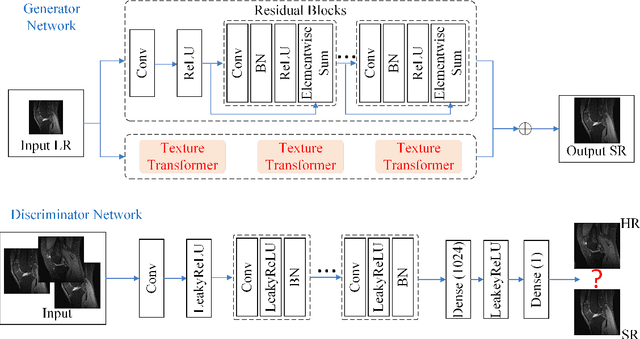
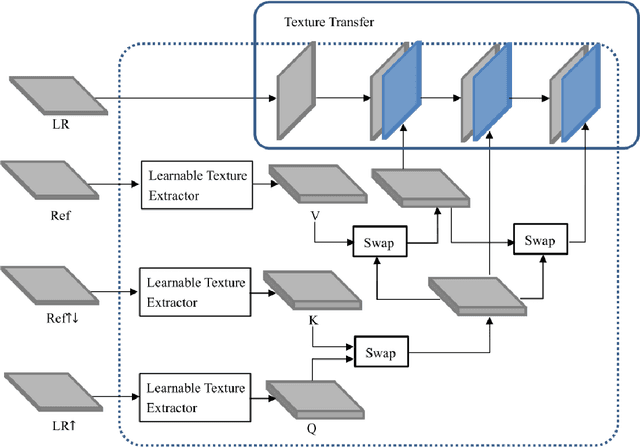
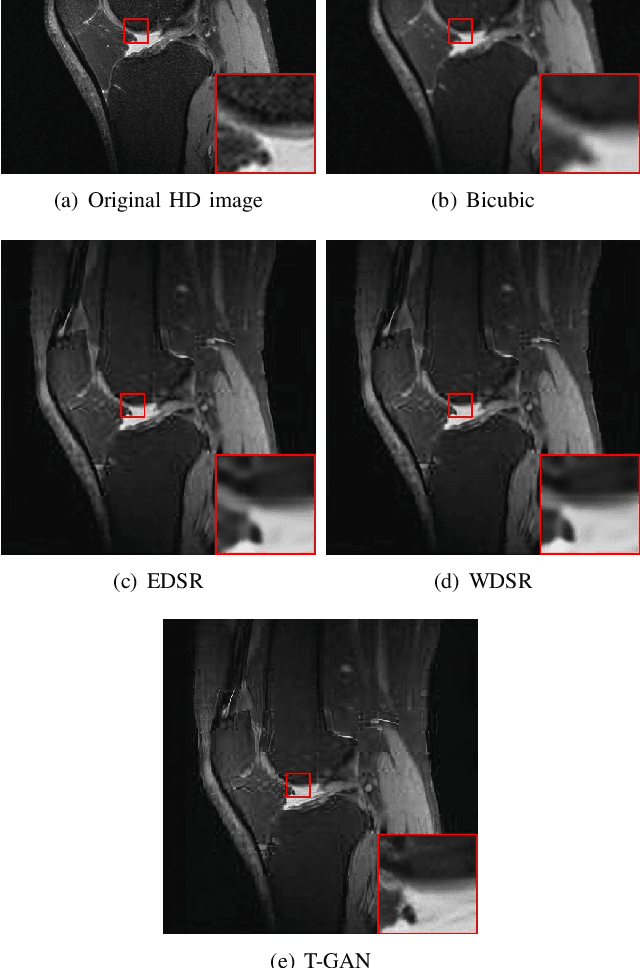
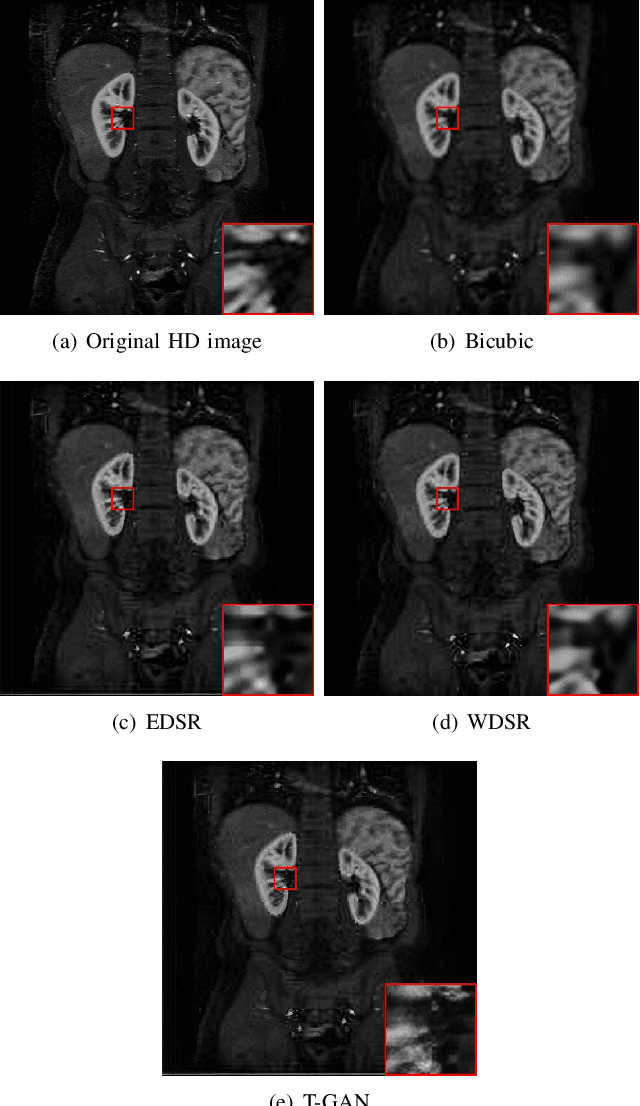
Because of the necessity to obtain high-quality images with minimal radiation doses, such as in low-field magnetic resonance imaging, super-resolution reconstruction in medical imaging has become more popular (MRI). However, due to the complexity and high aesthetic requirements of medical imaging, image super-resolution reconstruction remains a difficult challenge. In this paper, we offer a deep learning-based strategy for reconstructing medical images from low resolutions utilizing Transformer and Generative Adversarial Networks (T-GAN). The integrated system can extract more precise texture information and focus more on important locations through global image matching after successfully inserting Transformer into the generative adversarial network for picture reconstruction. Furthermore, we weighted the combination of content loss, adversarial loss, and adversarial feature loss as the final multi-task loss function during the training of our proposed model T-GAN. In comparison to established measures like PSNR and SSIM, our suggested T-GAN achieves optimal performance and recovers more texture features in super-resolution reconstruction of MRI scanned images of the knees and belly.
Learning Dual-Fused Modality-Aware Representations for RGBD Tracking
Nov 15, 2022
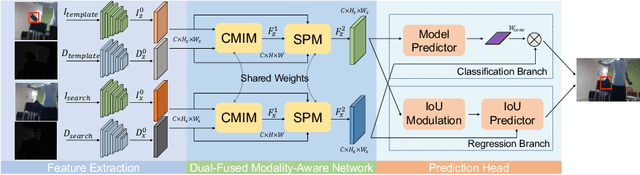
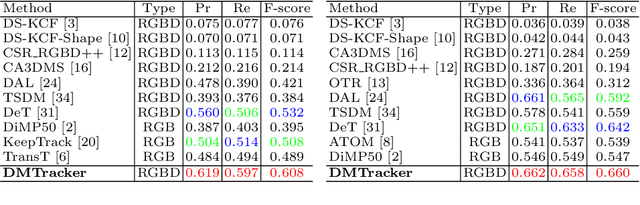

With the development of depth sensors in recent years, RGBD object tracking has received significant attention. Compared with the traditional RGB object tracking, the addition of the depth modality can effectively solve the target and background interference. However, some existing RGBD trackers use the two modalities separately and thus some particularly useful shared information between them is ignored. On the other hand, some methods attempt to fuse the two modalities by treating them equally, resulting in the missing of modality-specific features. To tackle these limitations, we propose a novel Dual-fused Modality-aware Tracker (termed DMTracker) which aims to learn informative and discriminative representations of the target objects for robust RGBD tracking. The first fusion module focuses on extracting the shared information between modalities based on cross-modal attention. The second aims at integrating the RGB-specific and depth-specific information to enhance the fused features. By fusing both the modality-shared and modality-specific information in a modality-aware scheme, our DMTracker can learn discriminative representations in complex tracking scenes. Experiments show that our proposed tracker achieves very promising results on challenging RGBD benchmarks.
Peekaboo: Text to Image Diffusion Models are Zero-Shot Segmentors
Nov 23, 2022
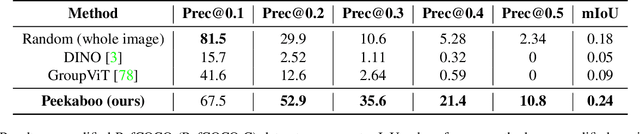


Recent diffusion-based generative models combined with vision-language models are capable of creating realistic images from natural language prompts. While these models are trained on large internet-scale datasets, such pre-trained models are not directly introduced to any semantic localization or grounding. Most current approaches for localization or grounding rely on human-annotated localization information in the form of bounding boxes or segmentation masks. The exceptions are a few unsupervised methods that utilize architectures or loss functions geared towards localization, but they need to be trained separately. In this work, we explore how off-the-shelf diffusion models, trained with no exposure to such localization information, are capable of grounding various semantic phrases with no segmentation-specific re-training. An inference time optimization process is introduced, that is capable of generating segmentation masks conditioned on natural language. We evaluate our proposal Peekaboo for unsupervised semantic segmentation on the Pascal VOC dataset. In addition, we evaluate for referring segmentation on the RefCOCO dataset. In summary, we present a first zero-shot, open-vocabulary, unsupervised (no localization information), semantic grounding technique leveraging diffusion-based generative models with no re-training. Our code will be released publicly.
SERENGETI: Massively Multilingual Language Models for Africa
Dec 21, 2022
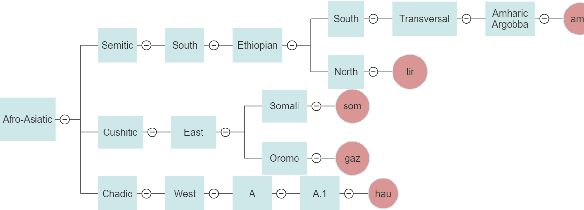
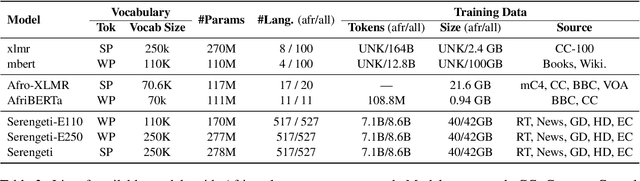
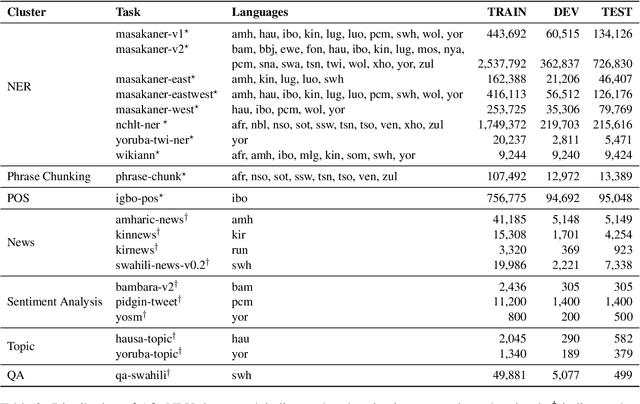
Multilingual language models (MLMs) acquire valuable, generalizable linguistic information during pretraining and have advanced the state of the art on task-specific finetuning. So far, only ~ 28 out of ~2,000 African languages are covered in existing language models. We ameliorate this limitation by developing SERENGETI, a set of massively multilingual language model that covers 517 African languages and language varieties. We evaluate our novel models on eight natural language understanding tasks across 20 datasets, comparing to four MLMs that each cover any number of African languages. SERENGETI outperforms other models on 11 datasets across the eights tasks and achieves 82.27 average F-1. We also perform error analysis on our models' performance and show the influence of mutual intelligibility when the models are applied under zero-shot settings. We will publicly release our models for research.
GMM-IL: Image Classification using Incrementally Learnt, Independent Probabilistic Models for Small Sample Sizes
Dec 01, 2022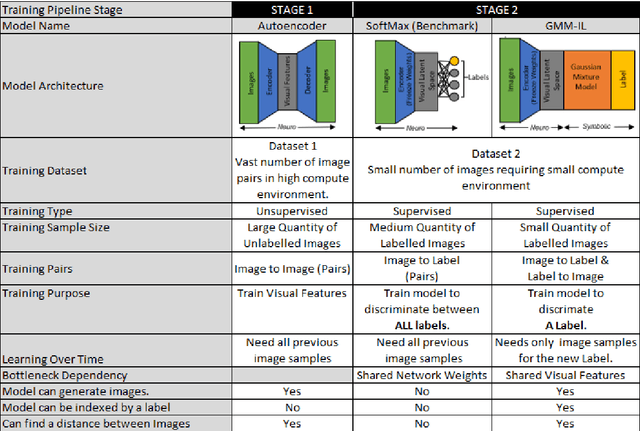
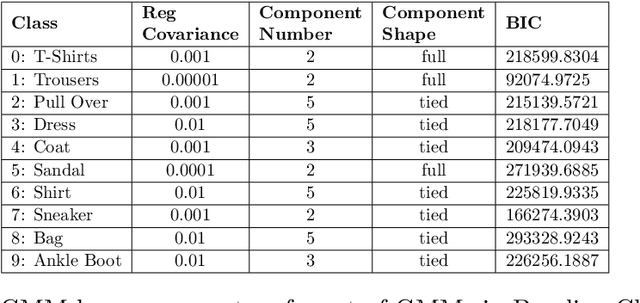
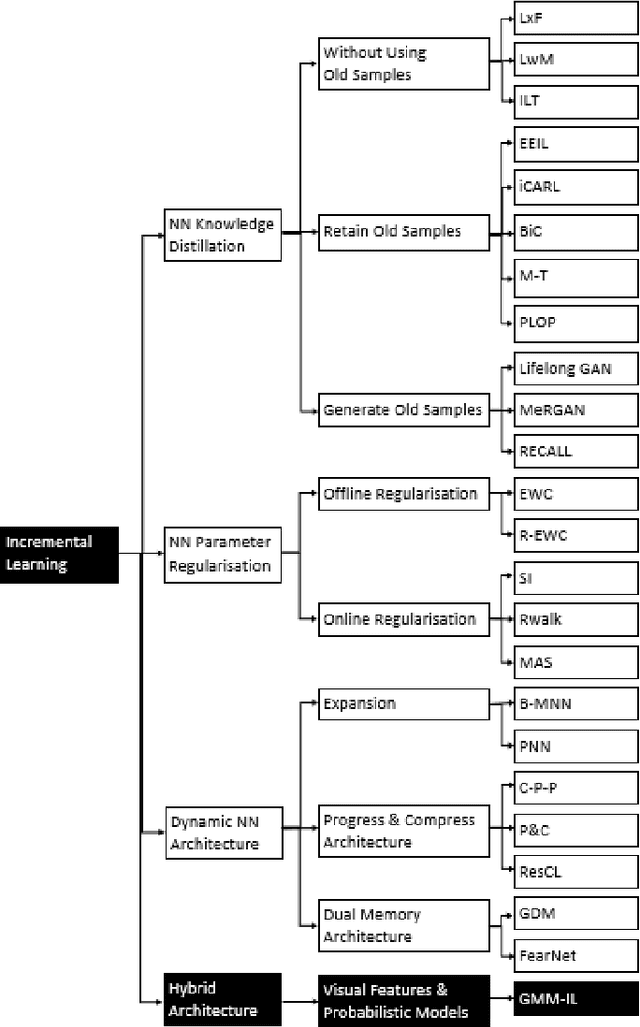
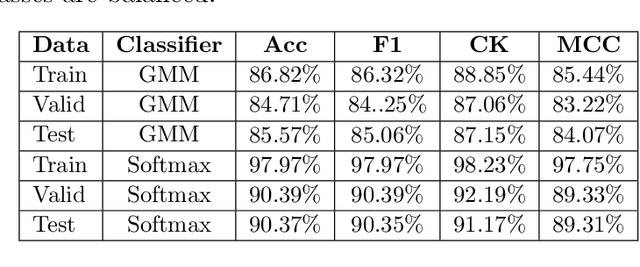
Current deep learning classifiers, carry out supervised learning and store class discriminatory information in a set of shared network weights. These weights cannot be easily altered to incrementally learn additional classes, since the classification weights all require retraining to prevent old class information from being lost and also require the previous training data to be present. We present a novel two stage architecture which couples visual feature learning with probabilistic models to represent each class in the form of a Gaussian Mixture Model. By using these independent class representations within our classifier, we outperform a benchmark of an equivalent network with a Softmax head, obtaining increased accuracy for sample sizes smaller than 12 and increased weighted F1 score for 3 imbalanced class profiles in that sample range. When learning new classes our classifier exhibits no catastrophic forgetting issues and only requires the new classes' training images to be present. This enables a database of growing classes over time which can be visually indexed and reasoned over.
A new weighted ensemble model for phishing detection based on feature selection
Dec 15, 2022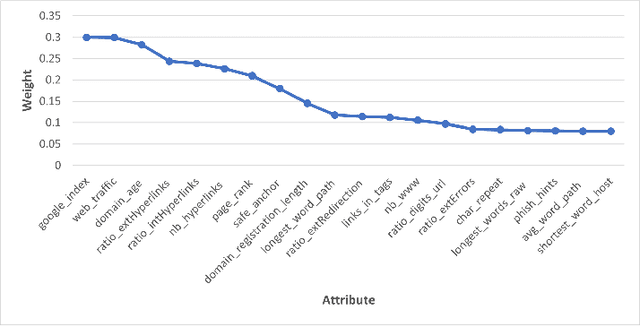
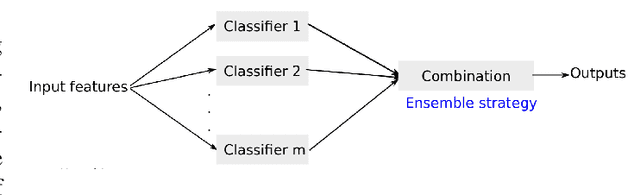
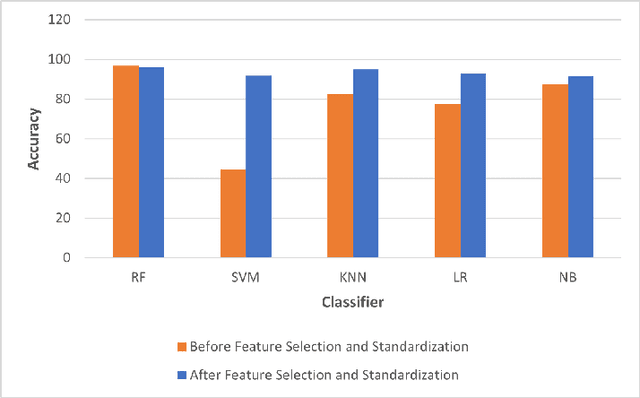
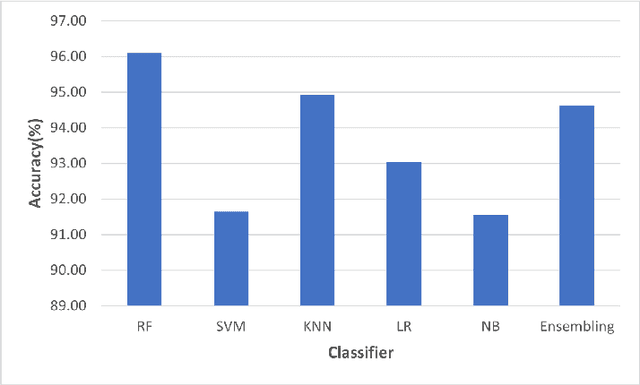
A phishing attack is a sort of cyber assault in which the attacker sends fake communications to entice a human victim to provide personal information or credentials. Phishing website identification can assist visitors in avoiding becoming victims of these assaults. The phishing problem is increasing day by day, and there is no single solution that can properly mitigate all vulnerabilities, thus many techniques are used. In this paper, We have proposed an ensemble model that combines multiple base models with a voting technique based on the weights. Moreover, we applied feature selection methods and standardization on the dataset effectively and compared the result before and after applying any feature selection.
On Implicit Bias in Overparameterized Bilevel Optimization
Dec 28, 2022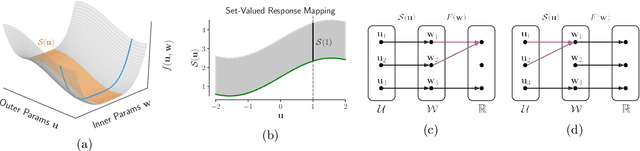
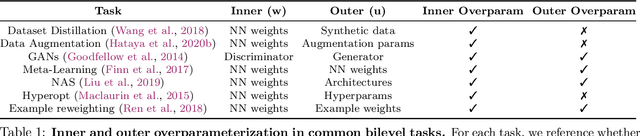
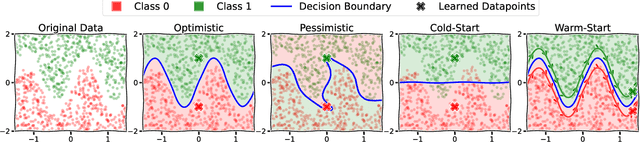
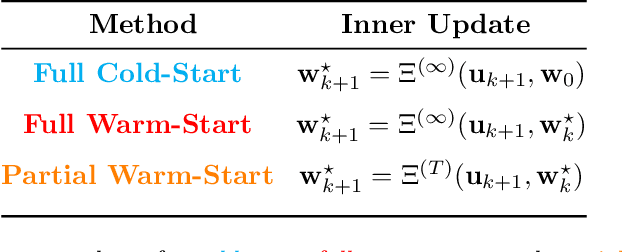
Many problems in machine learning involve bilevel optimization (BLO), including hyperparameter optimization, meta-learning, and dataset distillation. Bilevel problems consist of two nested sub-problems, called the outer and inner problems, respectively. In practice, often at least one of these sub-problems is overparameterized. In this case, there are many ways to choose among optima that achieve equivalent objective values. Inspired by recent studies of the implicit bias induced by optimization algorithms in single-level optimization, we investigate the implicit bias of gradient-based algorithms for bilevel optimization. We delineate two standard BLO methods -- cold-start and warm-start -- and show that the converged solution or long-run behavior depends to a large degree on these and other algorithmic choices, such as the hypergradient approximation. We also show that the inner solutions obtained by warm-start BLO can encode a surprising amount of information about the outer objective, even when the outer parameters are low-dimensional. We believe that implicit bias deserves as central a role in the study of bilevel optimization as it has attained in the study of single-level neural net optimization.
Towards Disentangling Relevance and Bias in Unbiased Learning to Rank
Dec 28, 2022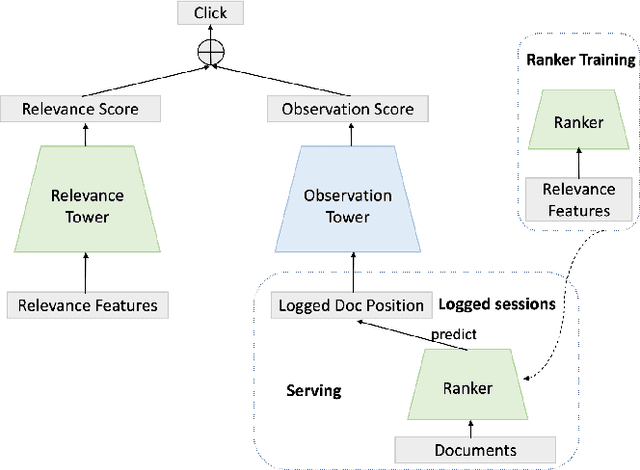
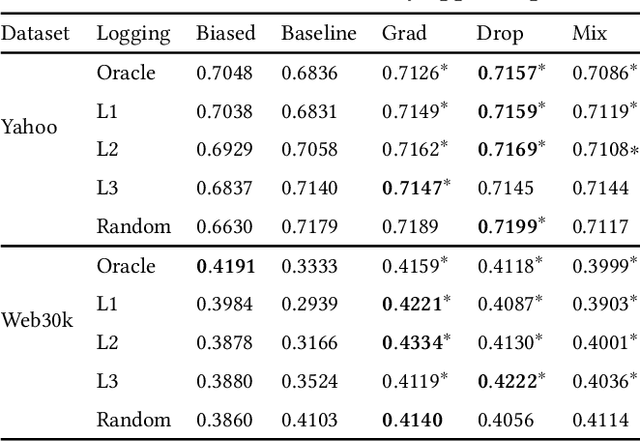
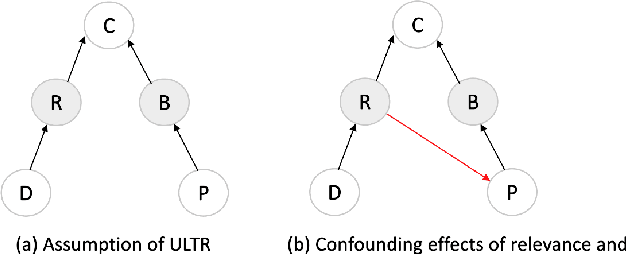
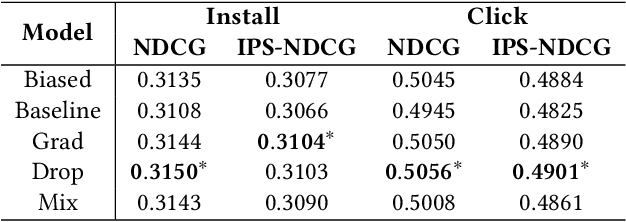
Unbiased learning to rank (ULTR) studies the problem of mitigating various biases from implicit user feedback data such as clicks, and has been receiving considerable attention recently. A popular ULTR approach for real-world applications uses a two-tower architecture, where click modeling is factorized into a relevance tower with regular input features, and a bias tower with bias-relevant inputs such as the position of a document. A successful factorization will allow the relevance tower to be exempt from biases. In this work, we identify a critical issue that existing ULTR methods ignored - the bias tower can be confounded with the relevance tower via the underlying true relevance. In particular, the positions were determined by the logging policy, i.e., the previous production model, which would possess relevance information. We give both theoretical analysis and empirical results to show the negative effects on relevance tower due to such a correlation. We then propose three methods to mitigate the negative confounding effects by better disentangling relevance and bias. Empirical results on both controlled public datasets and a large-scale industry dataset show the effectiveness of the proposed approaches.
X-MAS: Extremely Large-Scale Multi-Modal Sensor Dataset for Outdoor Surveillance in Real Environments
Dec 30, 2022
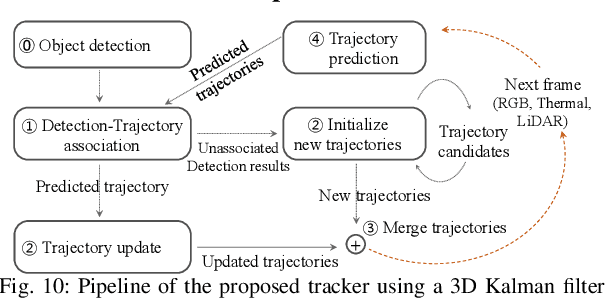
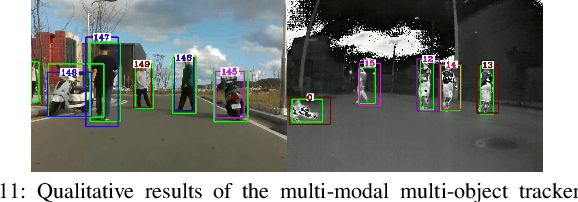
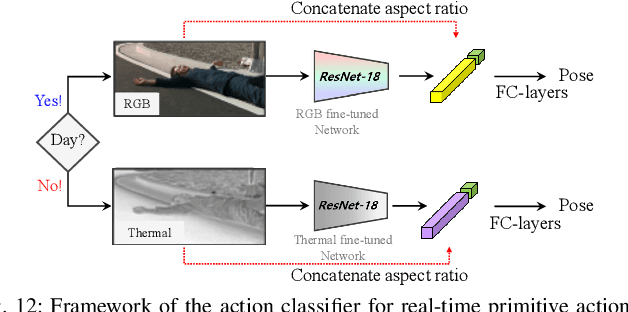
In robotics and computer vision communities, extensive studies have been widely conducted regarding surveillance tasks, including human detection, tracking, and motion recognition with a camera. Additionally, deep learning algorithms are widely utilized in the aforementioned tasks as in other computer vision tasks. Existing public datasets are insufficient to develop learning-based methods that handle various surveillance for outdoor and extreme situations such as harsh weather and low illuminance conditions. Therefore, we introduce a new large-scale outdoor surveillance dataset named eXtremely large-scale Multi-modAl Sensor dataset (X-MAS) containing more than 500,000 image pairs and the first-person view data annotated by well-trained annotators. Moreover, a single pair contains multi-modal data (e.g. an IR image, an RGB image, a thermal image, a depth image, and a LiDAR scan). This is the first large-scale first-person view outdoor multi-modal dataset focusing on surveillance tasks to the best of our knowledge. We present an overview of the proposed dataset with statistics and present methods of exploiting our dataset with deep learning-based algorithms. The latest information on the dataset and our study are available at https://github.com/lge-robot-navi, and the dataset will be available for download through a server.
Machine Learning and Thermography Applied to the Detection and Classification of Cracks in Building
Dec 30, 2022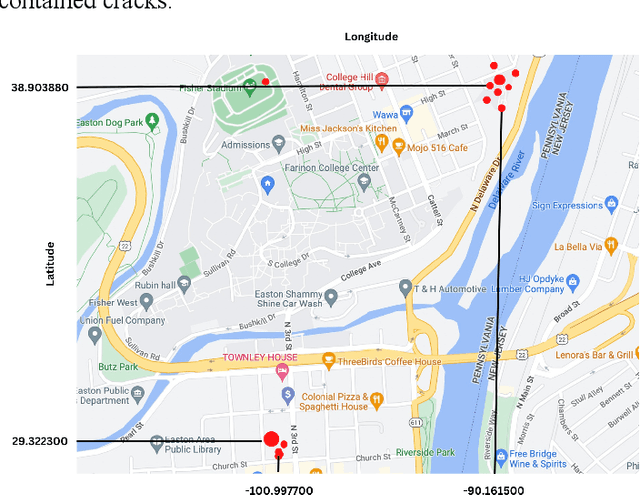
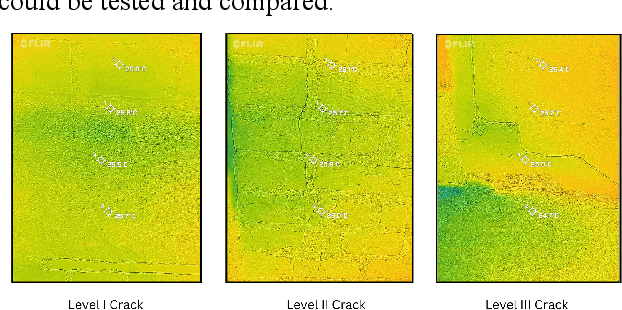

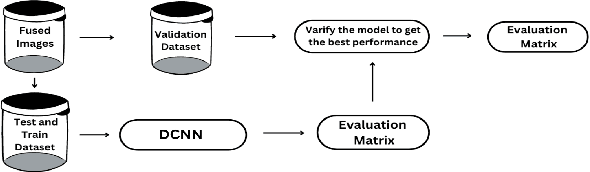
Due to the environmental impacts caused by the construction industry, repurposing existing buildings and making them more energy-efficient has become a high-priority issue. However, a legitimate concern of land developers is associated with the buildings' state of conservation. For that reason, infrared thermography has been used as a powerful tool to characterize these buildings' state of conservation by detecting pathologies, such as cracks and humidity. Thermal cameras detect the radiation emitted by any material and translate it into temperature-color-coded images. Abnormal temperature changes may indicate the presence of pathologies, however, reading thermal images might not be quite simple. This research project aims to combine infrared thermography and machine learning (ML) to help stakeholders determine the viability of reusing existing buildings by identifying their pathologies and defects more efficiently and accurately. In this particular phase of this research project, we've used an image classification machine learning model of Convolutional Neural Networks (DCNN) to differentiate three levels of cracks in one particular building. The model's accuracy was compared between the MSX and thermal images acquired from two distinct thermal cameras and fused images (formed through multisource information) to test the influence of the input data and network on the detection results.