 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Private Adaptive Optimization with Side Information
Feb 12, 2022
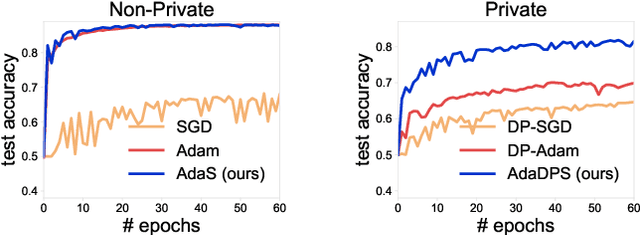

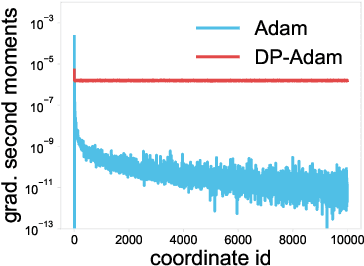
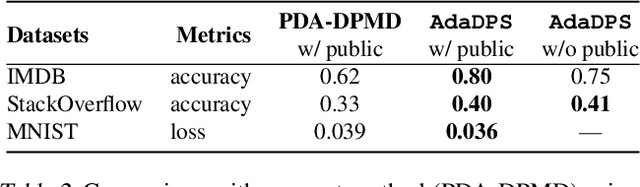
Adaptive optimization methods have become the default solvers for many machine learning tasks. Unfortunately, the benefits of adaptivity may degrade when training with differential privacy, as the noise added to ensure privacy reduces the effectiveness of the adaptive preconditioner. To this end, we propose AdaDPS, a general framework that uses non-sensitive side information to precondition the gradients, allowing the effective use of adaptive methods in private settings. We formally show AdaDPS reduces the amount of noise needed to achieve similar privacy guarantees, thereby improving optimization performance. Empirically, we leverage simple and readily available side information to explore the performance of AdaDPS in practice, comparing to strong baselines in both centralized and federated settings. Our results show that AdaDPS improves accuracy by 7.7% (absolute) on average -- yielding state-of-the-art privacy-utility trade-offs on large-scale text and image benchmarks.
Trajectory Smoothing Using GNSS/PDR Integration Via Factor Graph Optimization in Urban Canyons
Dec 29, 2022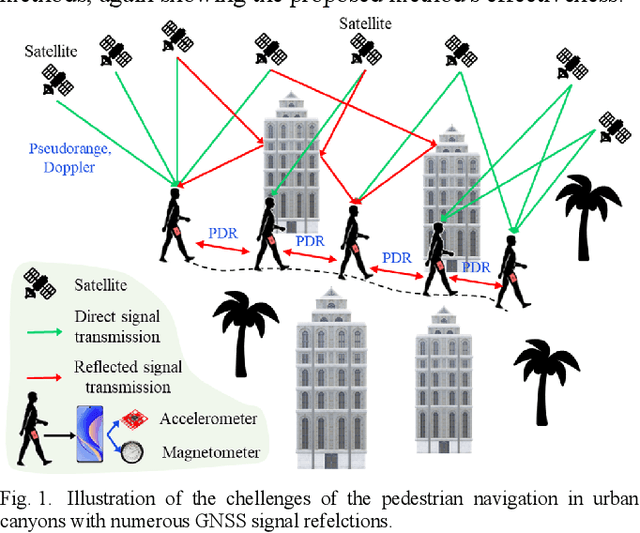

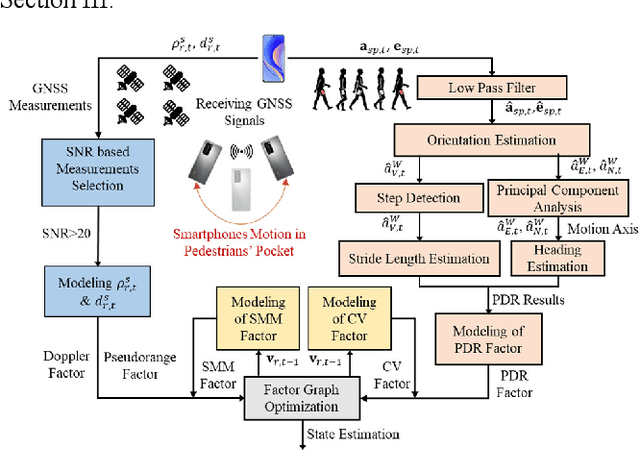
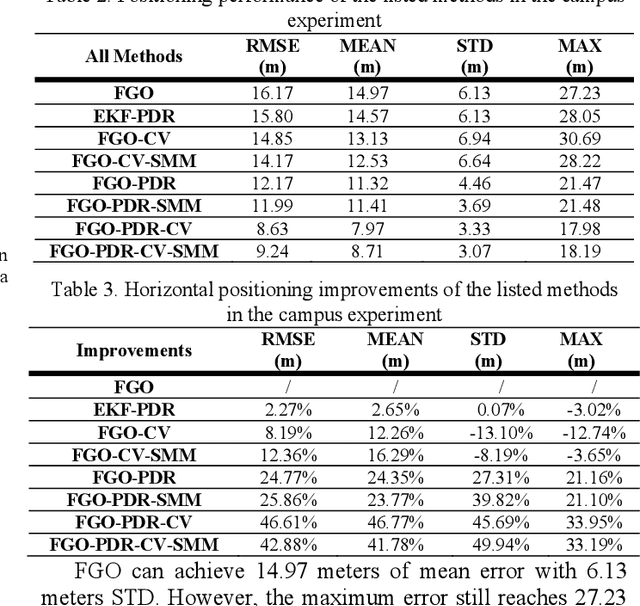
Accurate and smooth global navigation satellite system (GNSS) positioning for pedestrians in urban canyons is still a challenge due to the multipath effects and the non-light-of-sight (NLOS) receptions caused by the reflections from surrounding buildings. The recently developed factor graph optimization (FGO) based GNSS positioning method opened a new window for improving urban GNSS positioning by effectively exploiting the measurement redundancy from the historical information to resist the outlier measurements. Unfortunately, the FGO-based GNSS standalone positioning is still challenged in highly urbanized areas. As an extension of the previous FGO-based GNSS positioning method, this paper exploits the potential of the pedestrian dead reckoning (PDR) model in FGO to improve the GNSS standalone positioning performance in urban canyons. Specifically, the relative motion of the pedestrian is estimated based on the raw acceleration measurements from the onboard smartphone inertial measurement unit (IMU) via the PDR algorithm. Then the raw GNSS pseudorange, Doppler measurements, and relative motion from PDR are integrated using the FGO. Given the context of pedestrian navigation with a small acceleration most of the time, a novel soft motion model is proposed to smooth the states involved in the factor graph model. The effectiveness of the proposed method is verified step-by-step through two datasets collected in dense urban canyons of Hong Kong using smartphone-level GNSS receivers. The comparison between the conventional extended Kalman filter, several existing methods, and FGO-based integration is presented. The results reveal that the existing FGO-based GNSS standalone positioning is highly complementary to the PDR's relative motion estimation. Both improved positioning accuracy and trajectory smoothness are obtained with the help of the proposed method.
Speech Enhancement with Fullband-Subband Cross-Attention Network
Nov 10, 2022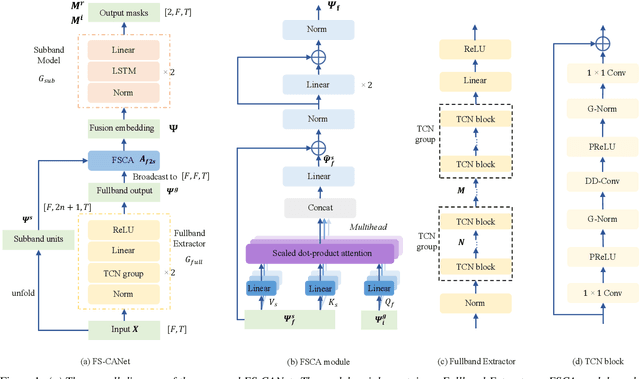
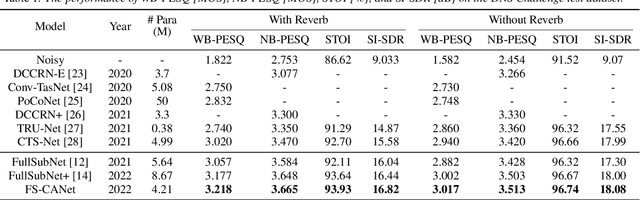
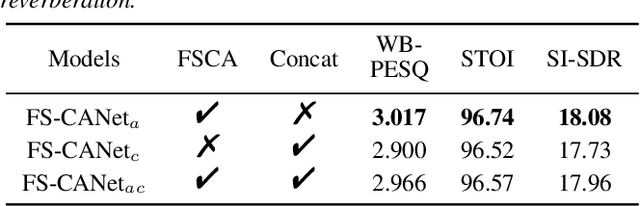
FullSubNet has shown its promising performance on speech enhancement by utilizing both fullband and subband information. However, the relationship between fullband and subband in FullSubNet is achieved by simply concatenating the output of fullband model and subband units. It only supplements the subband units with a small quantity of global information and has not considered the interaction between fullband and subband. This paper proposes a fullband-subband cross-attention (FSCA) module to interactively fuse the global and local information and applies it to FullSubNet. This new framework is called as FS-CANet. Moreover, different from FullSubNet, the proposed FS-CANet optimize the fullband extractor by temporal convolutional network (TCN) blocks to further reduce the model size. Experimental results on DNS Challenge - Interspeech 2021 dataset show that the proposed FS-CANet outperforms other state-of-the-art speech enhancement approaches, and demonstrate the effectiveness of fullband-subband cross-attention.
Watching the News: Towards VideoQA Models that can Read
Nov 10, 2022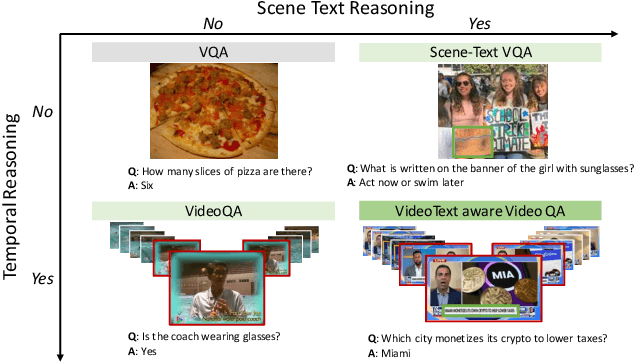
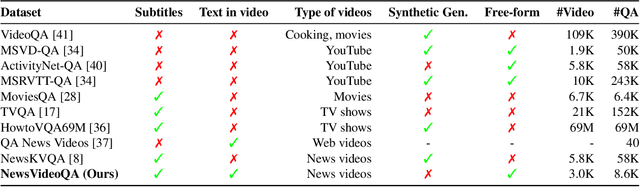

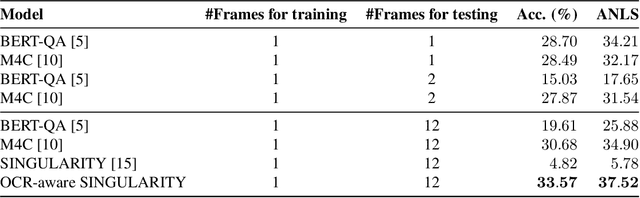
Video Question Answering methods focus on commonsense reasoning and visual cognition of objects or persons and their interactions over time. Current VideoQA approaches ignore the textual information present in the video. Instead, we argue that textual information is complementary to the action and provides essential contextualisation cues to the reasoning process. To this end, we propose a novel VideoQA task that requires reading and understanding the text in the video. To explore this direction, we focus on news videos and require QA systems to comprehend and answer questions about the topics presented by combining visual and textual cues in the video. We introduce the ``NewsVideoQA'' dataset that comprises more than $8,600$ QA pairs on $3,000+$ news videos obtained from diverse news channels from around the world. We demonstrate the limitations of current Scene Text VQA and VideoQA methods and propose ways to incorporate scene text information into VideoQA methods.
Perturbation-Recovery Method for Recommendation
Nov 17, 2022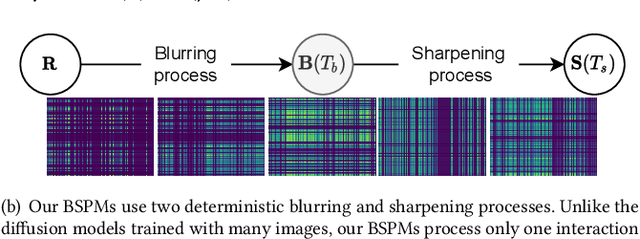

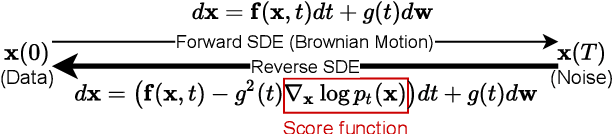

Collaborative filtering is one of the most influential recommender system types. Various methods have been proposed for collaborative filtering, ranging from matrix factorization to graph convolutional methods. Being inspired by recent successes of GF-CF and diffusion models, we present a novel concept of blurring-sharpening process model (BSPM). Diffusion models and BSPMs share the same processing philosophy in that new information is discovered (e.g., a new image is generated in the case of diffusion models) while original information is first perturbed and then recovered to its original form. However, diffusion models and our BSPMs deal with different types of information, and their optimal perturbation and recovery processes have a fundamental discrepancy. Therefore, our BSPMs have different forms from diffusion models. In addition, our concept not only theoretically subsumes many existing collaborative filtering models but also outperforms them in terms of Recall and NDCG in the three benchmark datasets, Gowalla, Yelp2018, and Amazon-book. Our model marks the best accuracy in them. In addition, the processing time of our method is one of the shortest cases ever in collaborative filtering. Our proposed concept has much potential in the future to be enhanced by designing better blurring (i.e., perturbation) and sharpening (i.e., recovery) processes than what we use in this paper.
A Spreader Ranking Algorithm for Extremely Low-budget Influence Maximization in Social Networks using Community Bridge Nodes
Nov 17, 2022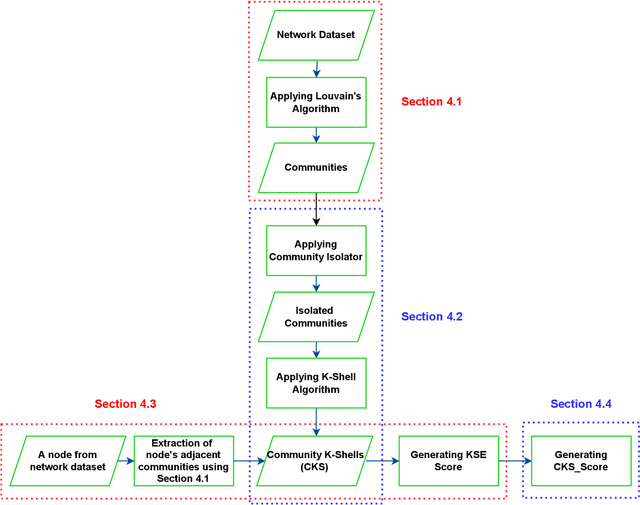
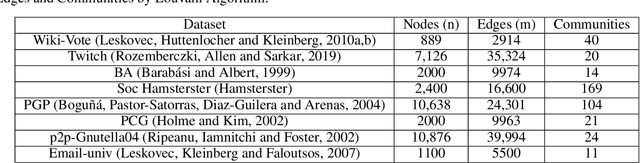
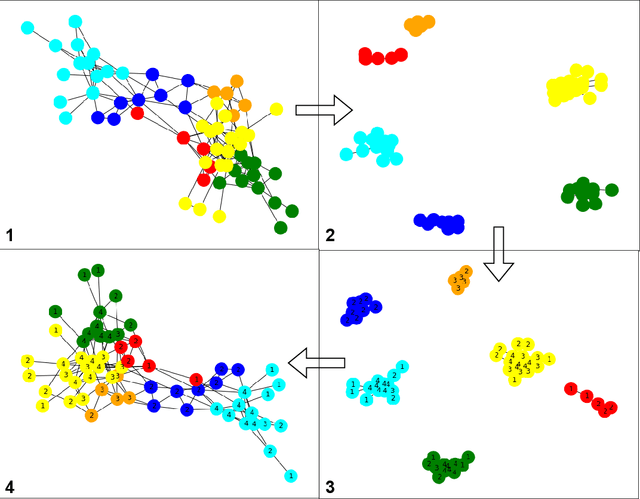
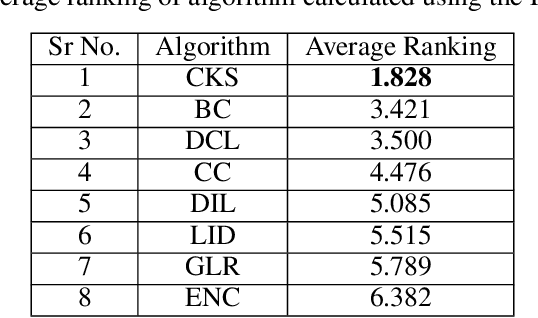
In recent years, social networking platforms have gained significant popularity among the masses like connecting with people and propagating ones thoughts and opinions. This has opened the door to user-specific advertisements and recommendations on these platforms, bringing along a significant focus on Influence Maximisation (IM) on social networks due to its wide applicability in target advertising, viral marketing, and personalized recommendations. The aim of IM is to identify certain nodes in the network which can help maximize the spread of certain information through a diffusion cascade. While several works have been proposed for IM, most were inefficient in exploiting community structures to their full extent. In this work, we propose a community structures-based approach, which employs a K-Shell algorithm in order to generate a score for the connections between seed nodes and communities for low-budget scenarios. Further, our approach employs entropy within communities to ensure the proper spread of information within the communities. We choose the Independent Cascade (IC) model to simulate information spread and evaluate it on four evaluation metrics. We validate our proposed approach on eight publicly available networks and find that it significantly outperforms the baseline approaches on these metrics, while still being relatively efficient.
Can Retriever-Augmented Language Models Reason? The Blame Game Between the Retriever and the Language Model
Dec 18, 2022The emergence of large pretrained models has enabled language models to achieve superior performance in common NLP tasks, including language modeling and question answering, compared to previous static word representation methods. Augmenting these models with a retriever to retrieve the related text and documents as supporting information has shown promise in effectively solving NLP problems in a more interpretable way given that the additional knowledge is injected explicitly rather than being captured in the models' parameters. In spite of the recent progress, our analysis on retriever-augmented language models shows that this class of language models still lack reasoning over the retrieved documents. In this paper, we study the strengths and weaknesses of different retriever-augmented language models such as REALM, kNN-LM, FiD, ATLAS, and Flan-T5 in reasoning over the selected documents in different tasks. In particular, we analyze the reasoning failures of each of these models and study how the models' failures in reasoning are rooted in the retriever module as well as the language model.
Task Preferences across Languages on Community Question Answering Platforms
Dec 18, 2022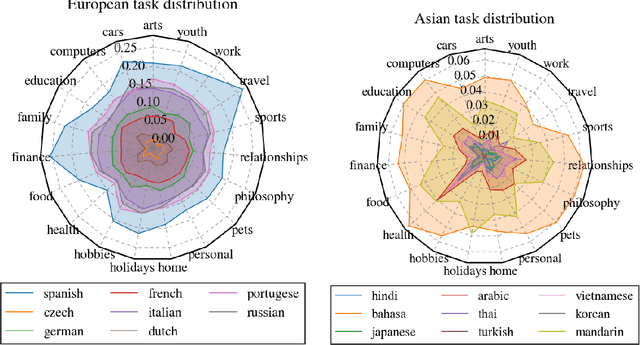
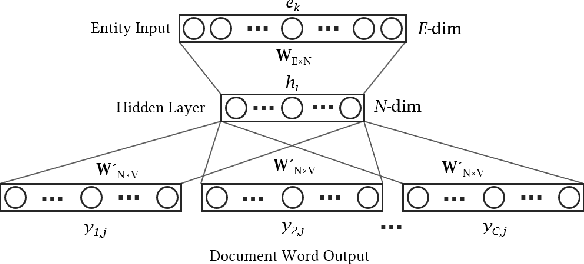
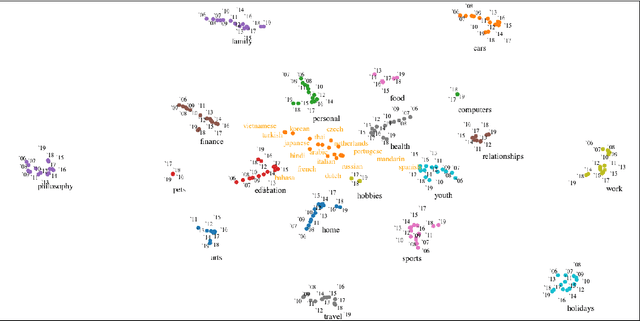
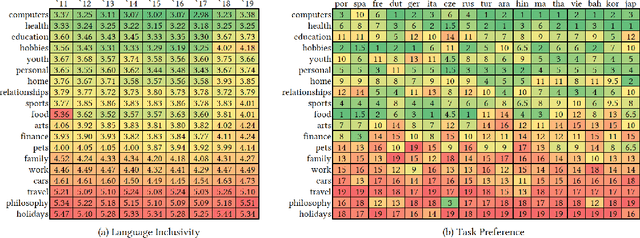
With the steady emergence of community question answering (CQA) platforms like Quora, StackExchange, and WikiHow, users now have an unprecedented access to information on various kind of queries and tasks. Moreover, the rapid proliferation and localization of these platforms spanning geographic and linguistic boundaries offer a unique opportunity to study the task requirements and preferences of users in different socio-linguistic groups. In this study, we implement an entity-embedding model trained on a large longitudinal dataset of multi-lingual and task-oriented question-answer pairs to uncover and quantify the (i) prevalence and distribution of various online tasks across linguistic communities, and (ii) emerging and receding trends in task popularity over time in these communities. Our results show that there exists substantial variance in task preference as well as popularity trends across linguistic communities on the platform. Findings from this study will help Q&A platforms better curate and personalize content for non-English users, while also offering valuable insights to businesses looking to target non-English speaking communities online.
Learning Visualization Policies of Augmented Reality for Human-Robot Collaboration
Nov 13, 2022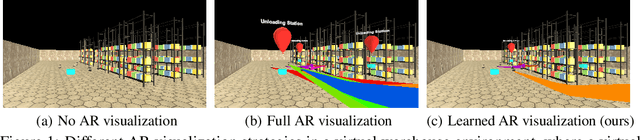
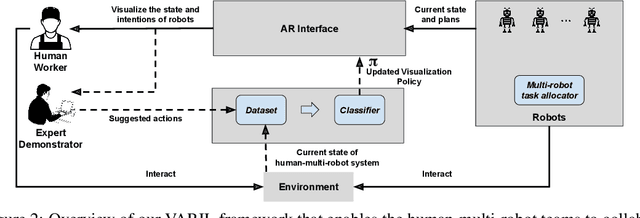
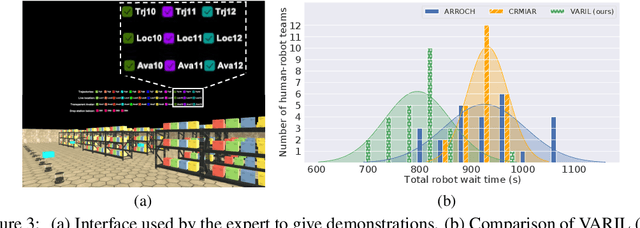

In human-robot collaboration domains, augmented reality (AR) technologies have enabled people to visualize the state of robots. Current AR-based visualization policies are designed manually, which requires a lot of human efforts and domain knowledge. When too little information is visualized, human users find the AR interface not useful; when too much information is visualized, they find it difficult to process the visualized information. In this paper, we develop a framework, called VARIL, that enables AR agents to learn visualization policies (what to visualize, when, and how) from demonstrations. We created a Unity-based platform for simulating warehouse environments where human-robot teammates collaborate on delivery tasks. We have collected a dataset that includes demonstrations of visualizing robots' current and planned behaviors. Results from experiments with real human participants show that, compared with competitive baselines from the literature, our learned visualization strategies significantly increase the efficiency of human-robot teams, while reducing the distraction level of human users. VARIL has been demonstrated in a built-in-lab mock warehouse.
Automated Gadget Discovery in Science
Dec 24, 2022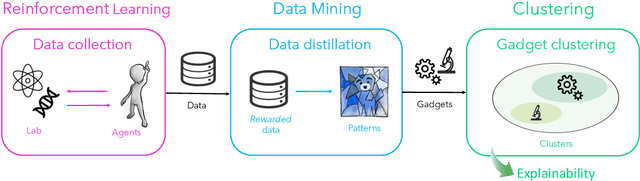

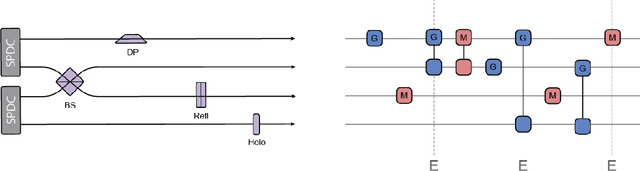

In recent years, reinforcement learning (RL) has become increasingly successful in its application to science and the process of scientific discovery in general. However, while RL algorithms learn to solve increasingly complex problems, interpreting the solutions they provide becomes ever more challenging. In this work, we gain insights into an RL agent's learned behavior through a post-hoc analysis based on sequence mining and clustering. Specifically, frequent and compact subroutines, used by the agent to solve a given task, are distilled as gadgets and then grouped by various metrics. This process of gadget discovery develops in three stages: First, we use an RL agent to generate data, then, we employ a mining algorithm to extract gadgets and finally, the obtained gadgets are grouped by a density-based clustering algorithm. We demonstrate our method by applying it to two quantum-inspired RL environments. First, we consider simulated quantum optics experiments for the design of high-dimensional multipartite entangled states where the algorithm finds gadgets that correspond to modern interferometer setups. Second, we consider a circuit-based quantum computing environment where the algorithm discovers various gadgets for quantum information processing, such as quantum teleportation. This approach for analyzing the policy of a learned agent is agent and environment agnostic and can yield interesting insights into any agent's policy.