 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Multi-subgoal Robot Navigation in Crowds with History Information and Interactions
May 04, 2022
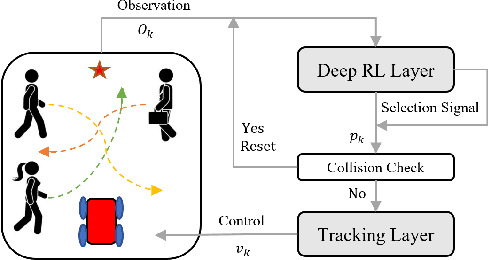
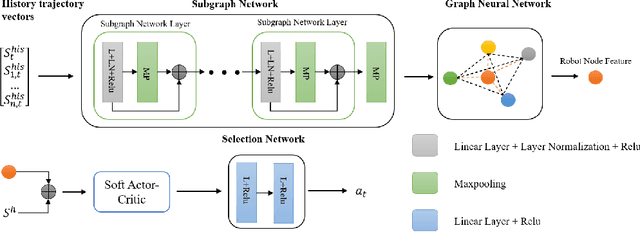
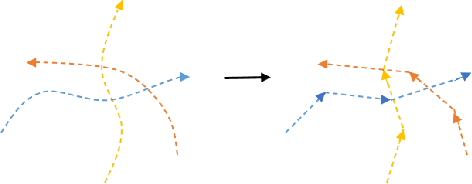
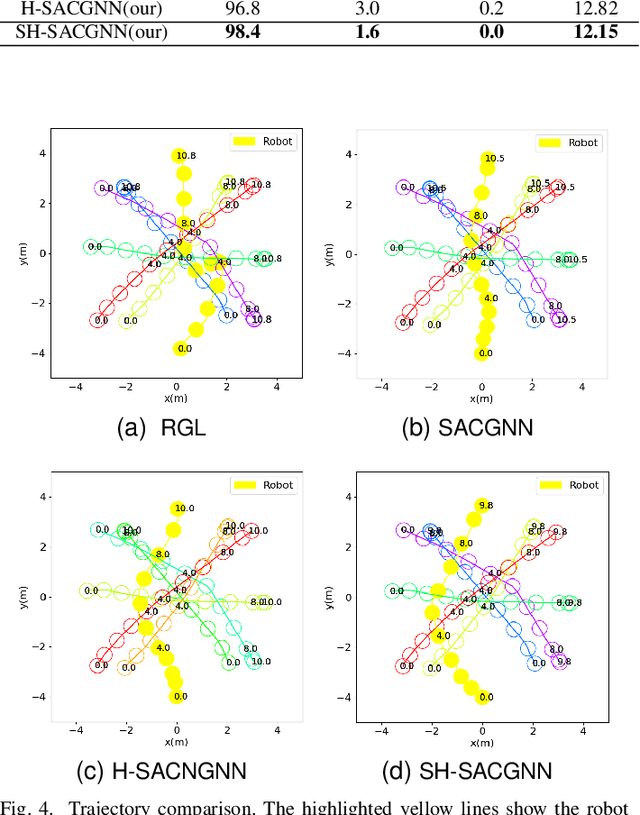
Robot navigation in dynamic environments shared with humans is an important but challenging task, which suffers from performance deterioration as the crowd grows. In this paper, multi-subgoal robot navigation approach based on deep reinforcement learning is proposed, which can reason about more comprehensive relationships among all agents (robot and humans). Specifically, the next position point is planned for the robot by introducing history information and interactions in our work. Firstly, based on subgraph network, the history information of all agents is aggregated before encoding interactions through a graph neural network, so as to improve the ability of the robot to anticipate the future scenarios implicitly. Further consideration, in order to reduce the probability of unreliable next position points, the selection module is designed after policy network in the reinforcement learning framework. In addition, the next position point generated from the selection module satisfied the task requirements better than that obtained directly from the policy network. The experiments demonstrate that our approach outperforms state-of-the-art approaches in terms of both success rate and collision rate, especially in crowded human environments.
A Recursively Recurrent Neural Network (R2N2) Architecture for Learning Iterative Algorithms
Nov 22, 2022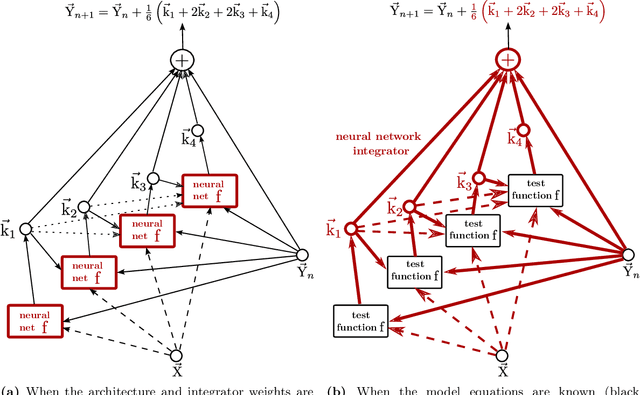
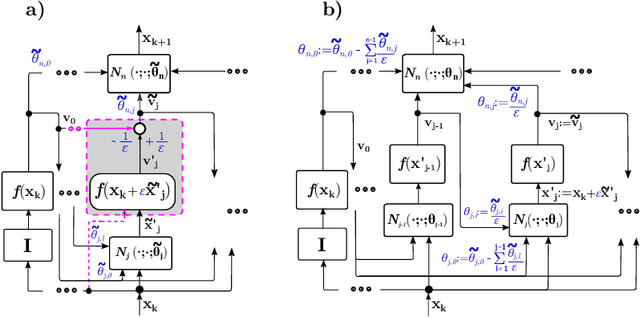
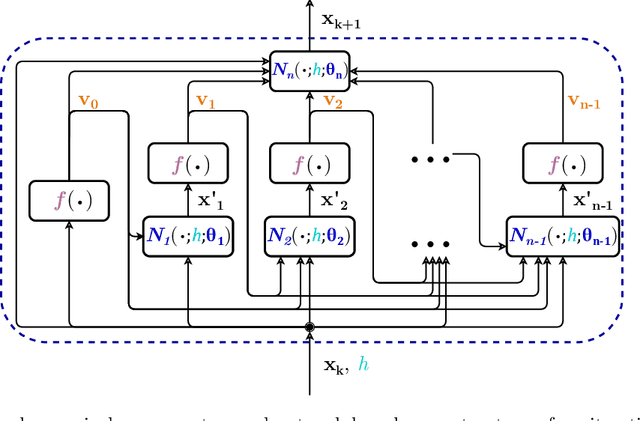
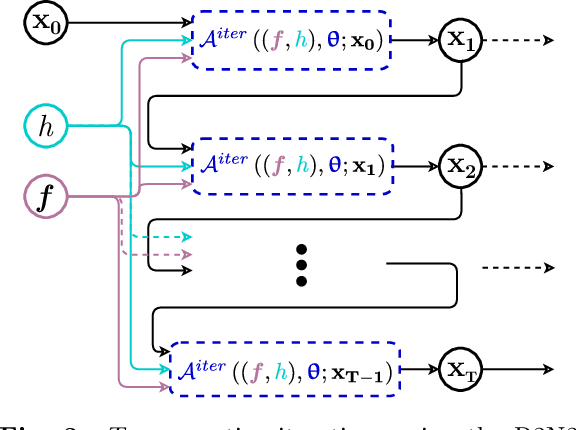
Meta-learning of numerical algorithms for a given task consist of the data-driven identification and adaptation of an algorithmic structure and the associated hyperparameters. To limit the complexity of the meta-learning problem, neural architectures with a certain inductive bias towards favorable algorithmic structures can, and should, be used. We generalize our previously introduced Runge-Kutta neural network to a recursively recurrent neural network (R2N2) superstructure for the design of customized iterative algorithms. In contrast to off-the-shelf deep learning approaches, it features a distinct division into modules for generation of information and for the subsequent assembly of this information towards a solution. Local information in the form of a subspace is generated by subordinate, inner, iterations of recurrent function evaluations starting at the current outer iterate. The update to the next outer iterate is computed as a linear combination of these evaluations, reducing the residual in this space, and constitutes the output of the network. We demonstrate that regular training of the weight parameters inside the proposed superstructure on input/output data of various computational problem classes yields iterations similar to Krylov solvers for linear equation systems, Newton-Krylov solvers for nonlinear equation systems, and Runge-Kutta integrators for ordinary differential equations. Due to its modularity, the superstructure can be readily extended with functionalities needed to represent more general classes of iterative algorithms traditionally based on Taylor series expansions.
XKD: Cross-modal Knowledge Distillation with Domain Alignment for Video Representation Learning
Nov 29, 2022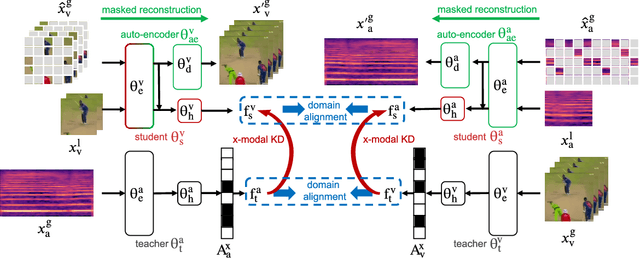
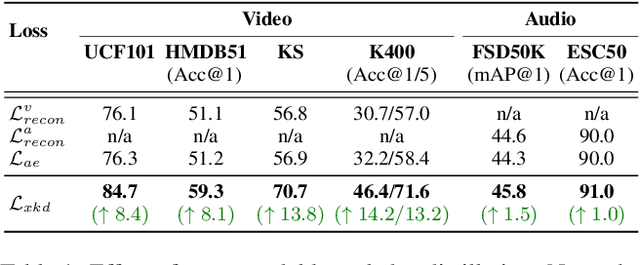
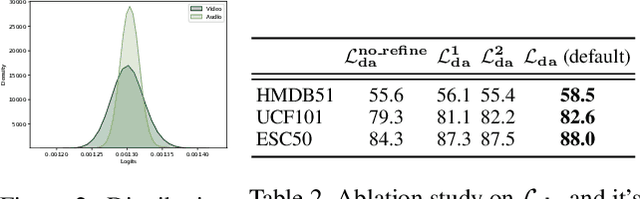

We present XKD, a novel self-supervised framework to learn meaningful representations from unlabelled video clips. XKD is trained with two pseudo tasks. First, masked data reconstruction is performed to learn modality-specific representations. Next, self-supervised cross-modal knowledge distillation is performed between the two modalities through teacher-student setups to learn complementary information. To identify the most effective information to transfer and also to tackle the domain gap between audio and visual modalities which could hinder knowledge transfer, we introduce a domain alignment strategy for effective cross-modal distillation. Lastly, to develop a general-purpose solution capable of handling both audio and visual streams, a modality-agnostic variant of our proposed framework is introduced, which uses the same backbone for both audio and visual modalities. Our proposed cross-modal knowledge distillation improves linear evaluation top-1 accuracy of video action classification by 8.4% on UCF101, 8.1% on HMDB51, 13.8% on Kinetics-Sound, and 14.2% on Kinetics400. Additionally, our modality-agnostic variant shows promising results in developing a general-purpose network capable of handling different data streams. The code is released on the project website.
Relational Sentence Embedding for Flexible Semantic Matching
Dec 17, 2022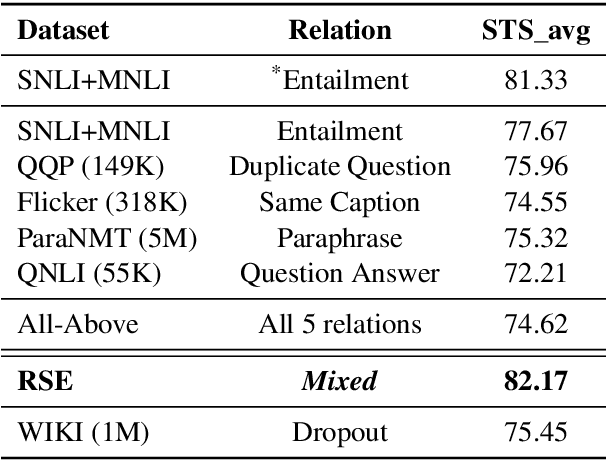
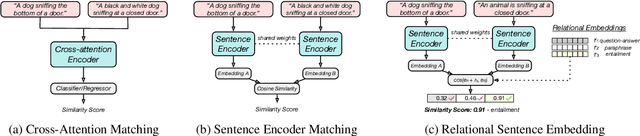
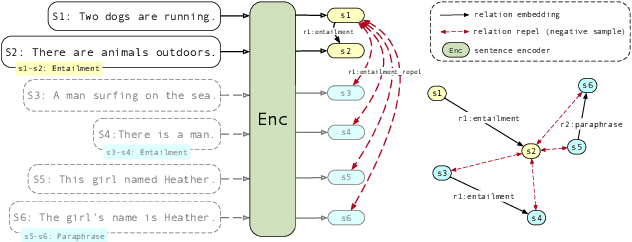
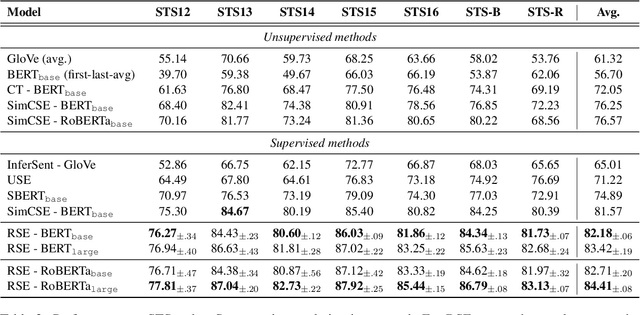
We present Relational Sentence Embedding (RSE), a new paradigm to further discover the potential of sentence embeddings. Prior work mainly models the similarity between sentences based on their embedding distance. Because of the complex semantic meanings conveyed, sentence pairs can have various relation types, including but not limited to entailment, paraphrasing, and question-answer. It poses challenges to existing embedding methods to capture such relational information. We handle the problem by learning associated relational embeddings. Specifically, a relation-wise translation operation is applied to the source sentence to infer the corresponding target sentence with a pre-trained Siamese-based encoder. The fine-grained relational similarity scores can be computed from learned embeddings. We benchmark our method on 19 datasets covering a wide range of tasks, including semantic textual similarity, transfer, and domain-specific tasks. Experimental results show that our method is effective and flexible in modeling sentence relations and outperforms a series of state-of-the-art sentence embedding methods. https://github.com/BinWang28/RSE
HyPe: Better Pre-trained Language Model Fine-tuning with Hidden Representation Perturbation
Dec 17, 2022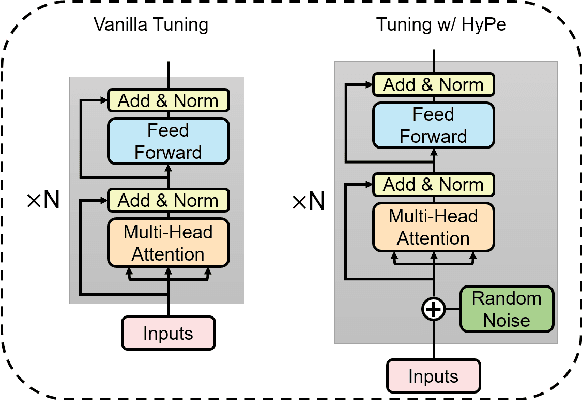
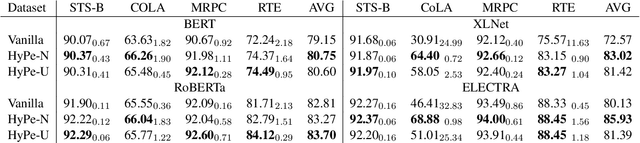

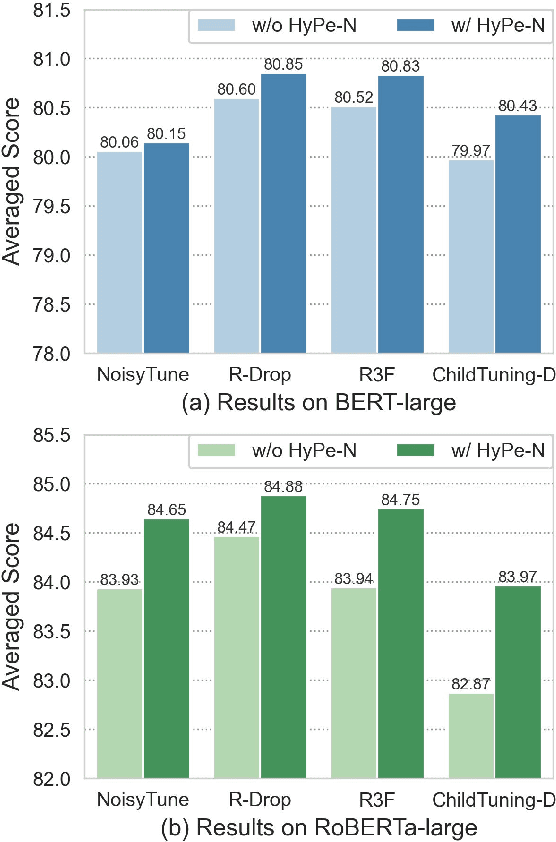
Language models with the Transformers structure have shown great performance in natural language processing. However, there still poses problems when fine-tuning pre-trained language models on downstream tasks, such as over-fitting or representation collapse. In this work, we propose HyPe, a simple yet effective fine-tuning technique to alleviate such problems by perturbing hidden representations of Transformers layers. Unlike previous works that only add noise to inputs or parameters, we argue that the hidden representations of Transformers layers convey more diverse and meaningful language information. Therefore, making the Transformers layers more robust to hidden representation perturbations can further benefit the fine-tuning of PLMs en bloc. We conduct extensive experiments and analyses on GLUE and other natural language inference datasets. Results demonstrate that HyPe outperforms vanilla fine-tuning and enhances generalization of hidden representations from different layers. In addition, HyPe acquires negligible computational overheads, and is better than and compatible with previous state-of-the-art fine-tuning techniques.
Alignment-Enriched Tuning for Patch-Level Pre-trained Document Image Models
Dec 01, 2022
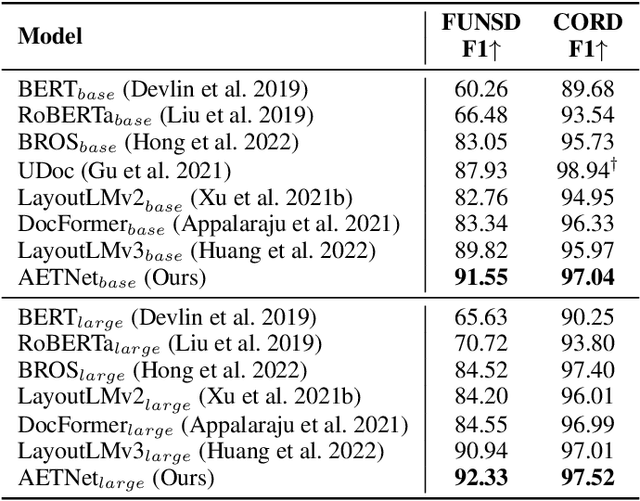
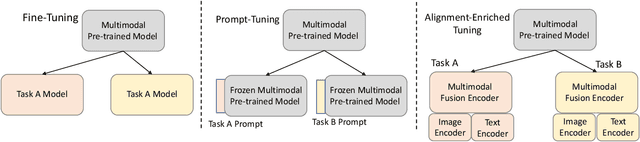

Alignment between image and text has shown promising improvements on patch-level pre-trained document image models. However, investigating more effective or finer-grained alignment techniques during pre-training requires a large amount of computation cost and time. Thus, a question naturally arises: Could we fine-tune the pre-trained models adaptive to downstream tasks with alignment objectives and achieve comparable or better performance? In this paper, we propose a new model architecture with alignment-enriched tuning (dubbed AETNet) upon pre-trained document image models, to adapt downstream tasks with the joint task-specific supervised and alignment-aware contrastive objective. Specifically, we introduce an extra visual transformer as the alignment-ware image encoder and an extra text transformer as the alignment-ware text encoder before multimodal fusion. We consider alignment in the following three aspects: 1) document-level alignment by leveraging the cross-modal and intra-modal contrastive loss; 2) global-local alignment for modeling localized and structural information in document images; and 3) local-level alignment for more accurate patch-level information. Experiments on various downstream tasks show that AETNet can achieve state-of-the-art performance on various downstream tasks. Notably, AETNet consistently outperforms state-of-the-art pre-trained models, such as LayoutLMv3 with fine-tuning techniques, on three different downstream tasks.
Integrated Communication and Positioning Design in RIS-empowered OFDM System: a Correlation Dispersion Scheme
Dec 01, 2022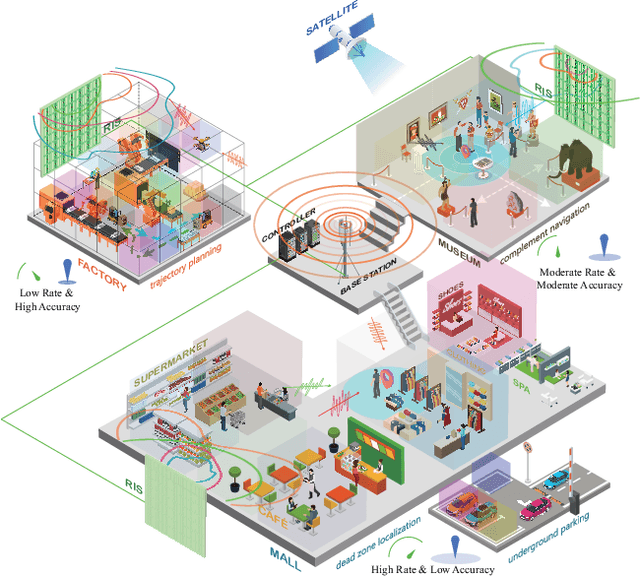
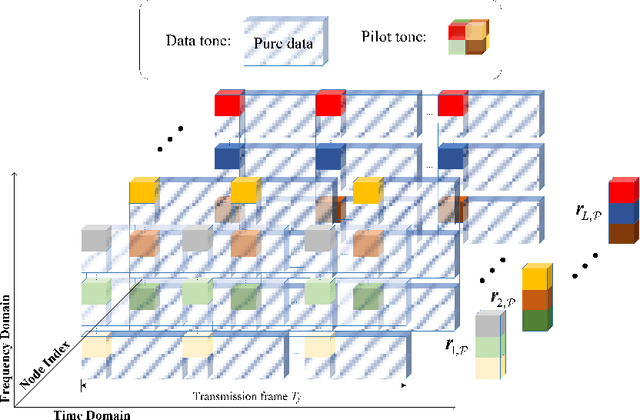
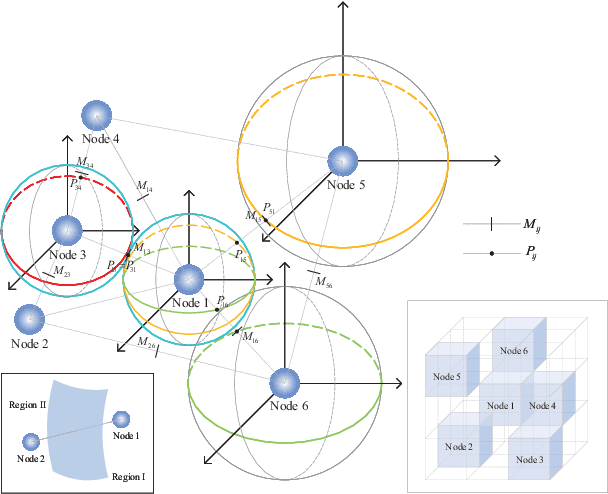
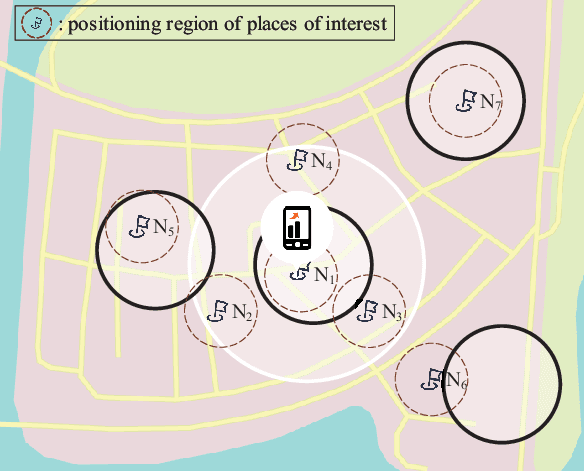
In this paper, we propose a novel integrated communication and positioning design for orthogonal frequency division multiplexing system aided by a reconfigurable intelligent surface (RIS) in indoor circumstances. The channel frequency responses on pilots (CFROPs) of places of interest are used for online mapping with the offline CFROP database. We transform the objective of minimizing the similarity of different CFROPs into creating a differentiated database by optimizing the phase coefficients of RIS. Imperfect channel state information is considered due to time-varying caused by the two-stage mapping. We formulate a universal optimization problem for maximizing either the average or the minimum virtual distance of CFROPs. The communication service requirements are converted as constraints. A moderate case is discussed to reduce computational complexity with minor accuracy loss. A special property called correlation dispersion is analyzed. It is capable of eliminating the spatial consistency that incurs inaccuracy to traditional positioning methods. The property and the moderate case complement each other well with clear and logical physical interpretation. The particular characteristic makes our design outperform others especially in high-level-noise environments. It works even better when the prior information of user's potential location is available. The validity of our design is confirmed by numerical results.
Explainable Artificial Intelligence for Improved Modeling of Processes
Dec 01, 2022In modern business processes, the amount of data collected has increased substantially in recent years. Because this data can potentially yield valuable insights, automated knowledge extraction based on process mining has been proposed, among other techniques, to provide users with intuitive access to the information contained therein. At present, the majority of technologies aim to reconstruct explicit business process models. These are directly interpretable but limited concerning the integration of diverse and real-valued information sources. On the other hand, Machine Learning (ML) benefits from the vast amount of data available and can deal with high-dimensional sources, yet it has rarely been applied to being used in processes. In this contribution, we evaluate the capability of modern Transformer architectures as well as more classical ML technologies of modeling process regularities, as can be quantitatively evaluated by their prediction capability. In addition, we demonstrate the capability of attentional properties and feature relevance determination by highlighting features that are crucial to the processes' predictive abilities. We demonstrate the efficacy of our approach using five benchmark datasets and show that the ML models are capable of predicting critical outcomes and that the attention mechanisms or XAI components offer new insights into the underlying processes.
* 12 pages, 3 tables, 3 figures. Published in IDEAL 2022: https://link.springer.com/chapter/10.1007/978-3-031-21753-1_31
Pivotal Role of Language Modeling in Recommender Systems: Enriching Task-specific and Task-agnostic Representation Learning
Dec 13, 2022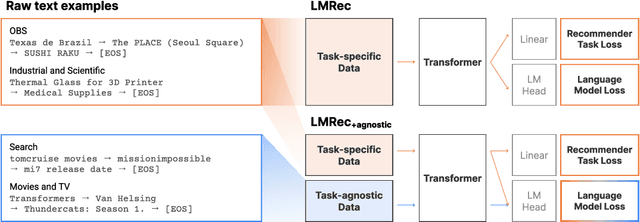
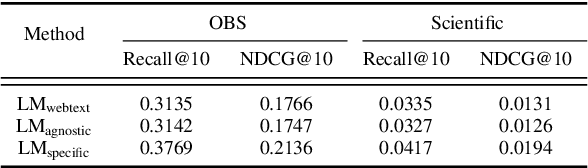

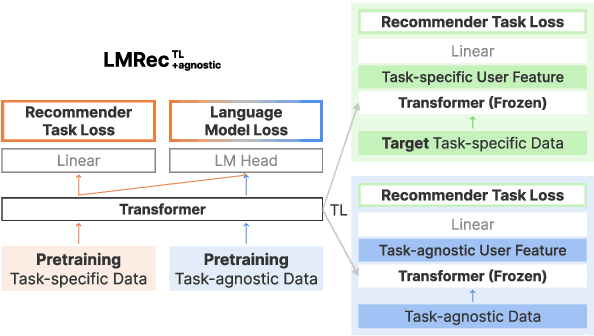
Recent studies have proposed unified user modeling frameworks that leverage user behavior data from various applications. Many of them benefit from utilizing users' behavior sequences as plain texts, representing rich information in any domain or system without losing generality. Hence, a question arises: Can language modeling for user history corpus help improve recommender systems? While its versatile usability has been widely investigated in many domains, its applications to recommender systems still remain underexplored. We show that language modeling applied directly to task-specific user histories achieves excellent results on diverse recommendation tasks. Also, leveraging additional task-agnostic user histories delivers significant performance benefits. We further demonstrate that our approach can provide promising transfer learning capabilities for a broad spectrum of real-world recommender systems, even on unseen domains and services.
Progressively Dual Prior Guided Few-shot Semantic Segmentation
Nov 20, 2022
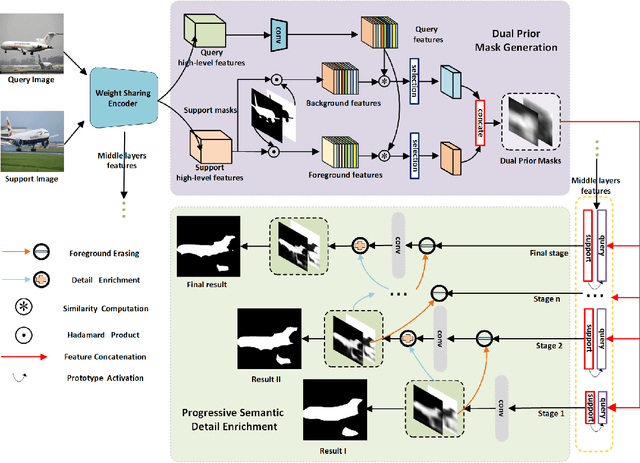
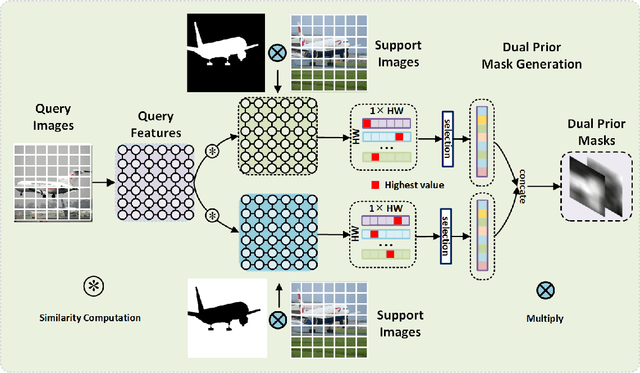
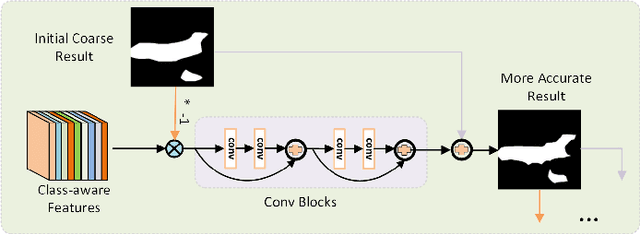
Few-shot semantic segmentation task aims at performing segmentation in query images with a few annotated support samples. Currently, few-shot segmentation methods mainly focus on leveraging foreground information without fully utilizing the rich background information, which could result in wrong activation of foreground-like background regions with the inadaptability to dramatic scene changes of support-query image pairs. Meanwhile, the lack of detail mining mechanism could cause coarse parsing results without some semantic components or edge areas since prototypes have limited ability to cope with large object appearance variance. To tackle these problems, we propose a progressively dual prior guided few-shot semantic segmentation network. Specifically, a dual prior mask generation (DPMG) module is firstly designed to suppress the wrong activation in foreground-background comparison manner by regarding background as assisted refinement information. With dual prior masks refining the location of foreground area, we further propose a progressive semantic detail enrichment (PSDE) module which forces the parsing model to capture the hidden semantic details by iteratively erasing the high-confidence foreground region and activating details in the rest region with a hierarchical structure. The collaboration of DPMG and PSDE formulates a novel few-shot segmentation network that can be learned in an end-to-end manner. Comprehensive experiments on PASCAL-5i and MS COCO powerfully demonstrate that our proposed algorithm achieves the great performance.