 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Lightweight Salient Object Detection in Optical Remote Sensing Images via Semantic Matching and Edge Alignment
Jan 07, 2023
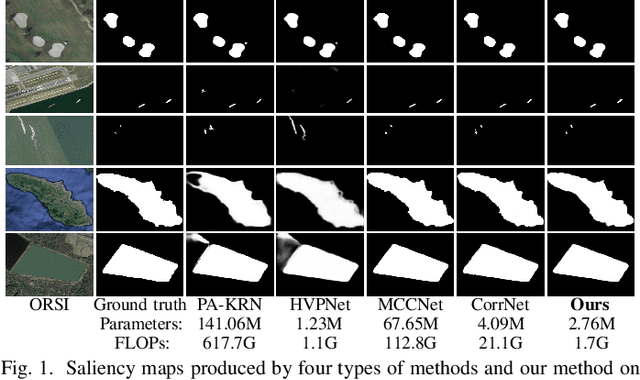
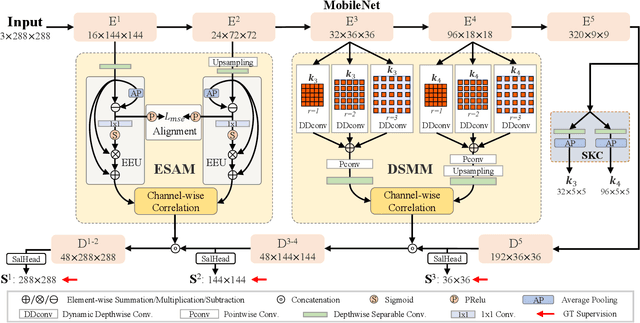
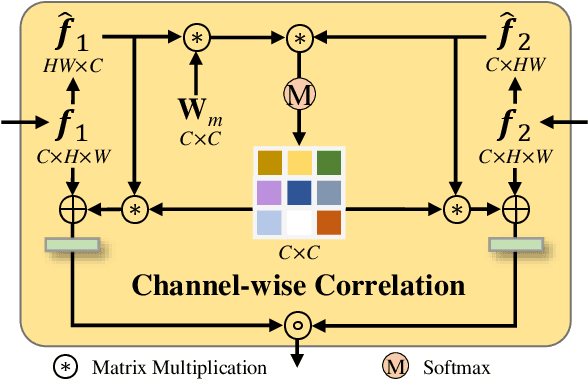

Recently, relying on convolutional neural networks (CNNs), many methods for salient object detection in optical remote sensing images (ORSI-SOD) are proposed. However, most methods ignore the huge parameters and computational cost brought by CNNs, and only a few pay attention to the portability and mobility. To facilitate practical applications, in this paper, we propose a novel lightweight network for ORSI-SOD based on semantic matching and edge alignment, termed SeaNet. Specifically, SeaNet includes a lightweight MobileNet-V2 for feature extraction, a dynamic semantic matching module (DSMM) for high-level features, an edge self-alignment module (ESAM) for low-level features, and a portable decoder for inference. First, the high-level features are compressed into semantic kernels. Then, semantic kernels are used to activate salient object locations in two groups of high-level features through dynamic convolution operations in DSMM. Meanwhile, in ESAM, cross-scale edge information extracted from two groups of low-level features is self-aligned through L2 loss and used for detail enhancement. Finally, starting from the highest-level features, the decoder infers salient objects based on the accurate locations and fine details contained in the outputs of the two modules. Extensive experiments on two public datasets demonstrate that our lightweight SeaNet not only outperforms most state-of-the-art lightweight methods but also yields comparable accuracy with state-of-the-art conventional methods, while having only 2.76M parameters and running with 1.7G FLOPs for 288x288 inputs. Our code and results are available at https://github.com/MathLee/SeaNet.
Providing Location Information at Edge Networks: A Federated Learning-Based Approach
May 17, 2022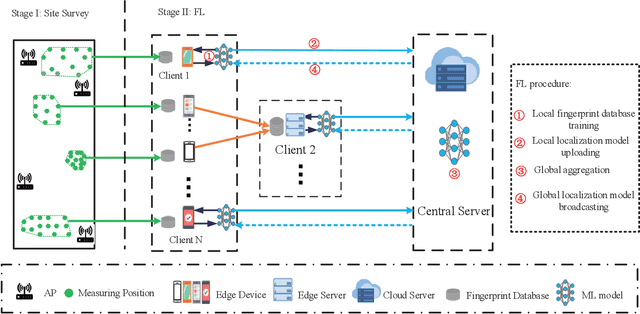
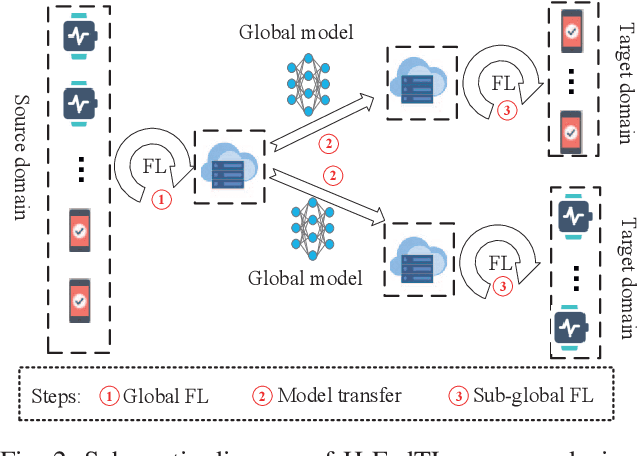
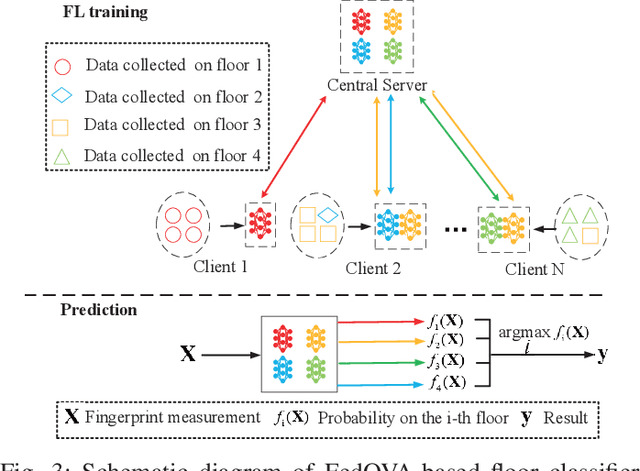
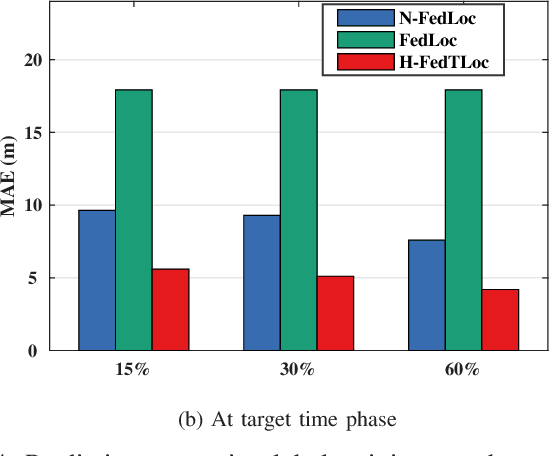
Recently, the development of mobile edge computing has enabled exhilarating edge artificial intelligence (AI) with fast response and low communication cost. The location information of edge devices is essential to support the edge AI in many scenarios, like smart home, intelligent transportation systems and integrated health care. Taking advantages of deep learning intelligence, the centralized machine learning (ML)-based positioning technique has received heated attention from both academia and industry. However, some potential issues, such as location information leakage and huge data traffic, limit its application. Fortunately, a newly emerging privacy-preserving distributed ML mechanism, named federated learning (FL), is expected to alleviate these concerns. In this article, we illustrate a framework of FL-based localization system as well as the involved entities at edge networks. Moreover, the advantages of such system are elaborated. On practical implementation of it, we investigate the field-specific issues associated with system-level solutions, which are further demonstrated over a real-word database. Moreover, future challenging open problems in this field are outlined.
Hard Sample Aware Network for Contrastive Deep Graph Clustering
Dec 16, 2022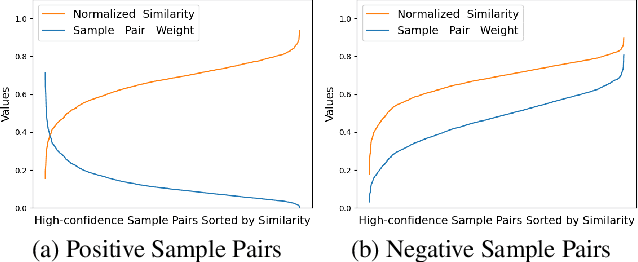
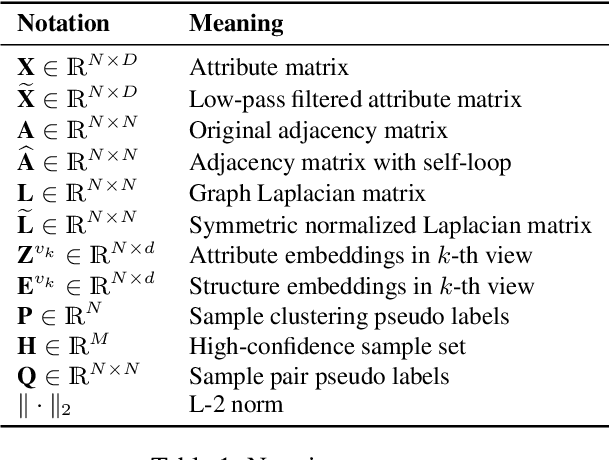
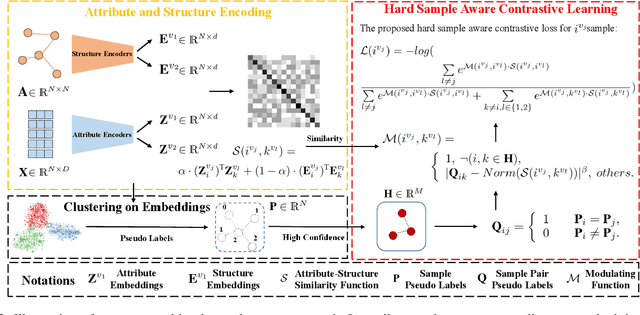
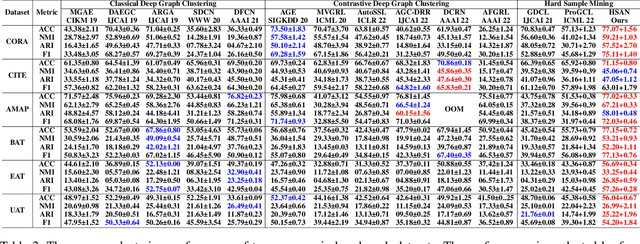
Contrastive deep graph clustering, which aims to divide nodes into disjoint groups via contrastive mechanisms, is a challenging research spot. Among the recent works, hard sample mining-based algorithms have achieved great attention for their promising performance. However, we find that the existing hard sample mining methods have two problems as follows. 1) In the hardness measurement, the important structural information is overlooked for similarity calculation, degrading the representativeness of the selected hard negative samples. 2) Previous works merely focus on the hard negative sample pairs while neglecting the hard positive sample pairs. Nevertheless, samples within the same cluster but with low similarity should also be carefully learned. To solve the problems, we propose a novel contrastive deep graph clustering method dubbed Hard Sample Aware Network (HSAN) by introducing a comprehensive similarity measure criterion and a general dynamic sample weighing strategy. Concretely, in our algorithm, the similarities between samples are calculated by considering both the attribute embeddings and the structure embeddings, better revealing sample relationships and assisting hardness measurement. Moreover, under the guidance of the carefully collected high-confidence clustering information, our proposed weight modulating function will first recognize the positive and negative samples and then dynamically up-weight the hard sample pairs while down-weighting the easy ones. In this way, our method can mine not only the hard negative samples but also the hard positive sample, thus improving the discriminative capability of the samples further. Extensive experiments and analyses demonstrate the superiority and effectiveness of our proposed method.
Self-supervised Graph Representation Learning for Black Market Account Detection
Dec 06, 2022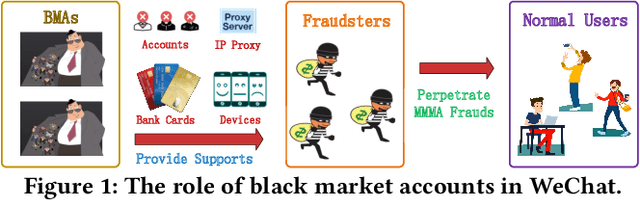
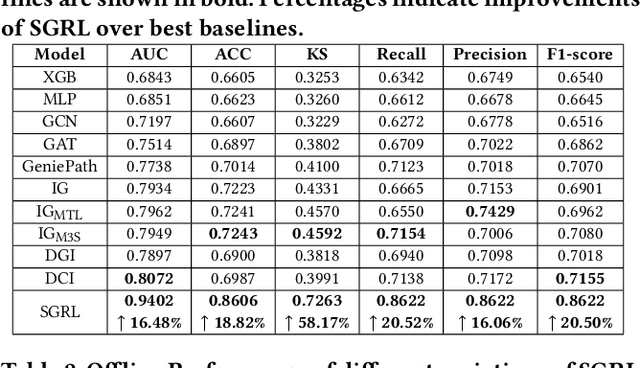
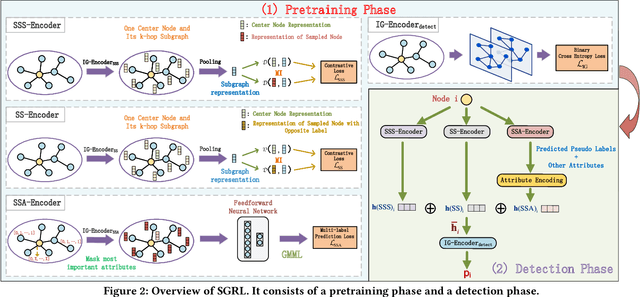
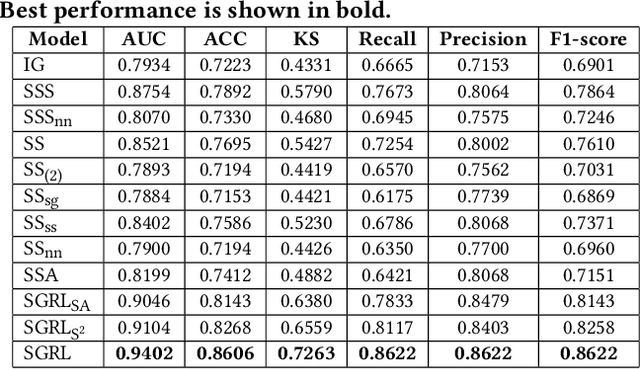
Nowadays, Multi-purpose Messaging Mobile App (MMMA) has become increasingly prevalent. MMMAs attract fraudsters and some cybercriminals provide support for frauds via black market accounts (BMAs). Compared to fraudsters, BMAs are not directly involved in frauds and are more difficult to detect. This paper illustrates our BMA detection system SGRL (Self-supervised Graph Representation Learning) used in WeChat, a representative MMMA with over a billion users. We tailor Graph Neural Network and Graph Self-supervised Learning in SGRL for BMA detection. The workflow of SGRL contains a pretraining phase that utilizes structural information, node attribute information and available human knowledge, and a lightweight detection phase. In offline experiments, SGRL outperforms state-of-the-art methods by 16.06%-58.17% on offline evaluation measures. We deploy SGRL in the online environment to detect BMAs on the billion-scale WeChat graph, and it exceeds the alternative by 7.27% on the online evaluation measure. In conclusion, SGRL can alleviate label reliance, generalize well to unseen data, and effectively detect BMAs in WeChat.
Reducing Sequence Length Learning Impacts on Transformer Models
Dec 16, 2022
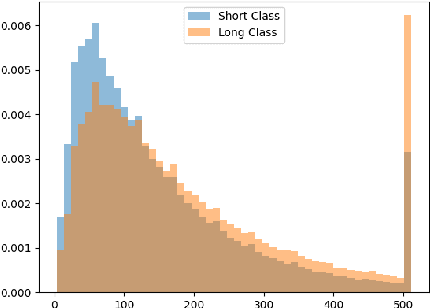


Classification algorithms using Transformer architectures can be affected by the sequence length learning problem whenever observations from different classes have a different length distribution. This problem brings models to use sequence length as a predictive feature instead of relying on important textual information. Even if most public datasets are not affected by this problem, privately corpora for fields such as medicine and insurance may carry this data bias. This poses challenges throughout the value chain given their usage in a machine learning application. In this paper, we empirically expose this problem and present approaches to minimize its impacts.
Label Mask AutoEncoder(L-MAE): A Pure Transformer Method to Augment Semantic Segmentation Datasets
Nov 21, 2022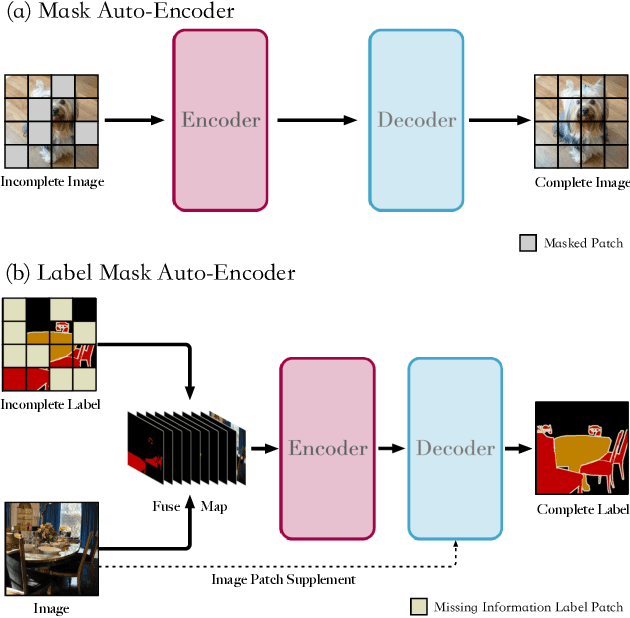
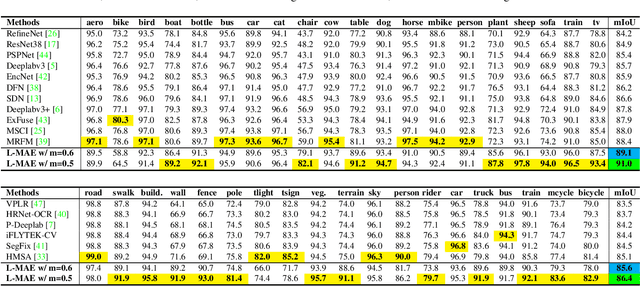

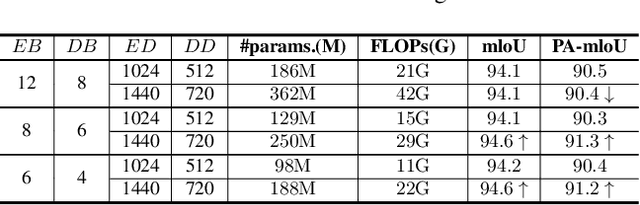
Semantic segmentation models based on the conventional neural network can achieve remarkable performance in such tasks, while the dataset is crucial to the training model process. Significant progress in expanding datasets has been made in semi-supervised semantic segmentation recently. However, completing the pixel-level information remains challenging due to possible missing in a label. Inspired by Mask AutoEncoder, we present a simple yet effective Pixel-Level completion method, Label Mask AutoEncoder(L-MAE), that fully uses the existing information in the label to predict results. The proposed model adopts the fusion strategy that stacks the label and the corresponding image, namely Fuse Map. Moreover, since some of the image information is lost when masking the Fuse Map, direct reconstruction may lead to poor performance. Our proposed Image Patch Supplement algorithm can supplement the missing information, as the experiment shows, an average of 4.1% mIoU can be improved. The Pascal VOC2012 dataset (224 crop size, 20 classes) and the Cityscape dataset (448 crop size, 19 classes) are used in the comparative experiments. With the Mask Ratio setting to 50%, in terms of the prediction region, the proposed model achieves 91.0% and 86.4% of mIoU on Pascal VOC 2012 and Cityscape, respectively, outperforming other current supervised semantic segmentation models. Our code and models are available at https://github.com/jjrccop/Label-Mask-Auto-Encoder.
PD-Quant: Post-Training Quantization based on Prediction Difference Metric
Dec 14, 2022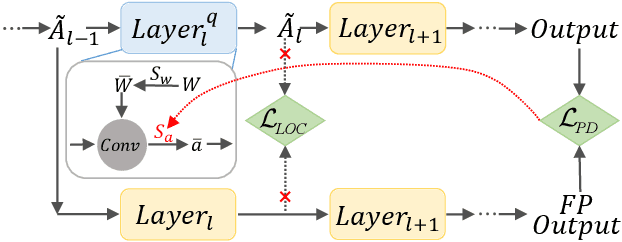
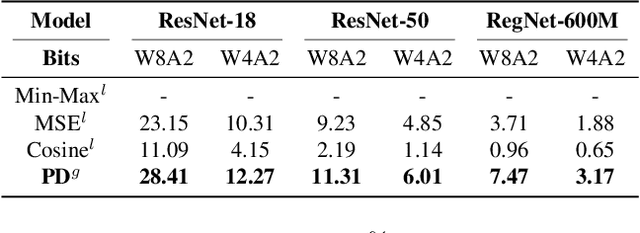
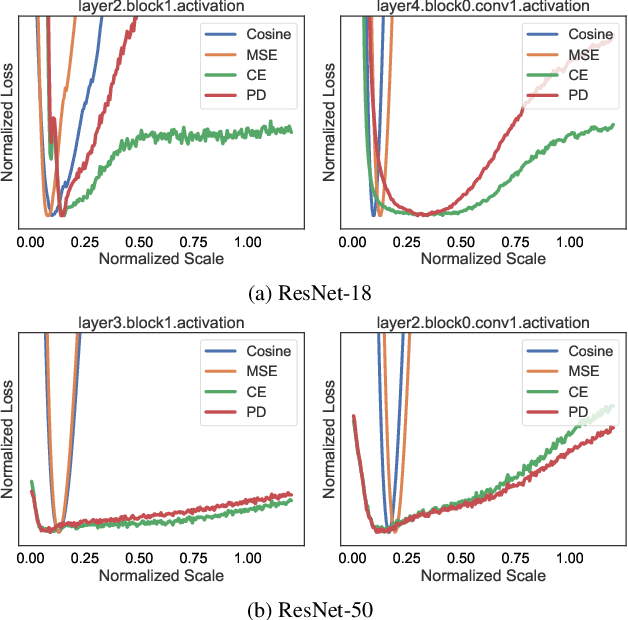
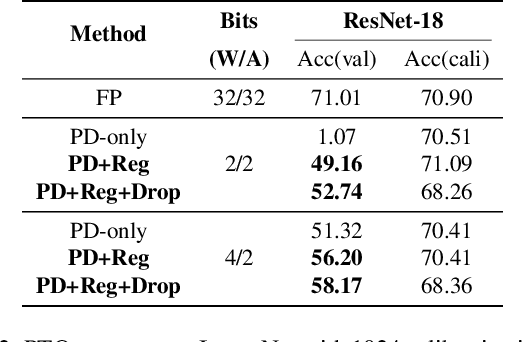
As a neural network compression technique, post-training quantization (PTQ) transforms a pre-trained model into a quantized model using a lower-precision data type. However, the prediction accuracy will decrease because of the quantization noise, especially in extremely low-bit settings. How to determine the appropriate quantization parameters (e.g., scaling factors and rounding of weights) is the main problem facing now. Many existing methods determine the quantization parameters by minimizing the distance between features before and after quantization. Using this distance as the metric to optimize the quantization parameters only considers local information. We analyze the problem of minimizing local metrics and indicate that it would not result in optimal quantization parameters. Furthermore, the quantized model suffers from overfitting due to the small number of calibration samples in PTQ. In this paper, we propose PD-Quant to solve the problems. PD-Quant uses the information of differences between network prediction before and after quantization to determine the quantization parameters. To mitigate the overfitting problem, PD-Quant adjusts the distribution of activations in PTQ. Experiments show that PD-Quant leads to better quantization parameters and improves the prediction accuracy of quantized models, especially in low-bit settings. For example, PD-Quant pushes the accuracy of ResNet-18 up to 53.08% and RegNetX-600MF up to 40.92% in weight 2-bit activation 2-bit. The code will be released at https://github.com/hustvl/PD-Quant.
Good helper is around you: Attention-driven Masked Image Modeling
Dec 01, 2022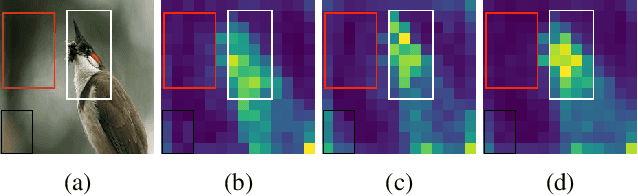

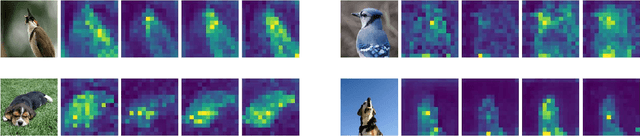
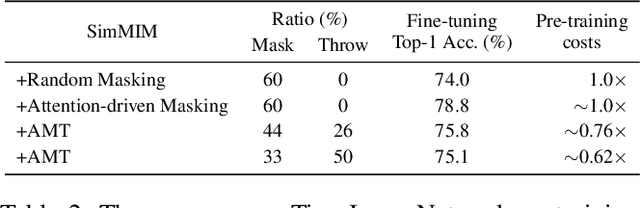
It has been witnessed that masked image modeling (MIM) has shown a huge potential in self-supervised learning in the past year. Benefiting from the universal backbone vision transformer, MIM learns self-supervised visual representations through masking a part of patches of the image while attempting to recover the missing pixels. Most previous works mask patches of the image randomly, which underutilizes the semantic information that is beneficial to visual representation learning. On the other hand, due to the large size of the backbone, most previous works have to spend much time on pre-training. In this paper, we propose \textbf{Attention-driven Masking and Throwing Strategy} (AMT), which could solve both problems above. We first leverage the self-attention mechanism to obtain the semantic information of the image during the training process automatically without using any supervised methods. Masking strategy can be guided by that information to mask areas selectively, which is helpful for representation learning. Moreover, a redundant patch throwing strategy is proposed, which makes learning more efficient. As a plug-and-play module for masked image modeling, AMT improves the linear probing accuracy of MAE by $2.9\% \sim 5.9\%$ on CIFAR-10/100, STL-10, Tiny ImageNet, and ImageNet-1K, and obtains an improved performance with respect to fine-tuning accuracy of MAE and SimMIM. Moreover, this design also achieves superior performance on downstream detection and segmentation tasks. Code is available at https://github.com/guijiejie/AMT.
Online Active Learning for Soft Sensor Development using Semi-Supervised Autoencoders
Dec 26, 2022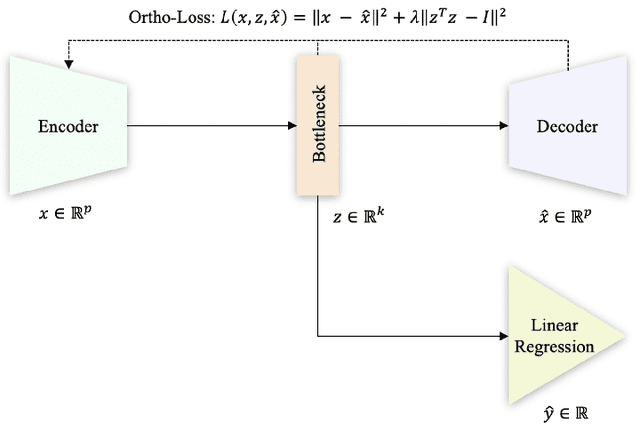
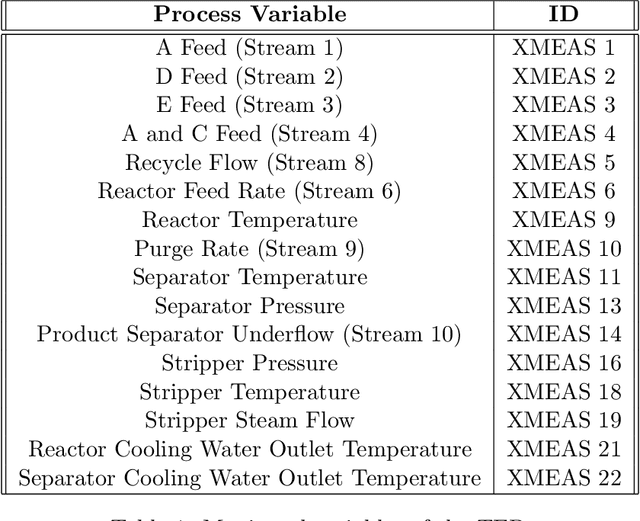
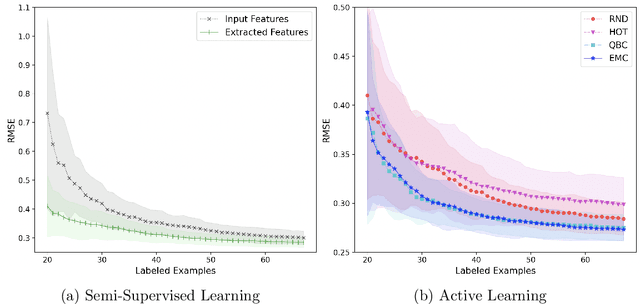
Data-driven soft sensors are extensively used in industrial and chemical processes to predict hard-to-measure process variables whose real value is difficult to track during routine operations. The regression models used by these sensors often require a large number of labeled examples, yet obtaining the label information can be very expensive given the high time and cost required by quality inspections. In this context, active learning methods can be highly beneficial as they can suggest the most informative labels to query. However, most of the active learning strategies proposed for regression focus on the offline setting. In this work, we adapt some of these approaches to the stream-based scenario and show how they can be used to select the most informative data points. We also demonstrate how to use a semi-supervised architecture based on orthogonal autoencoders to learn salient features in a lower dimensional space. The Tennessee Eastman Process is used to compare the predictive performance of the proposed approaches.
A Clustering-guided Contrastive Fusion for Multi-view Representation Learning
Jan 05, 2023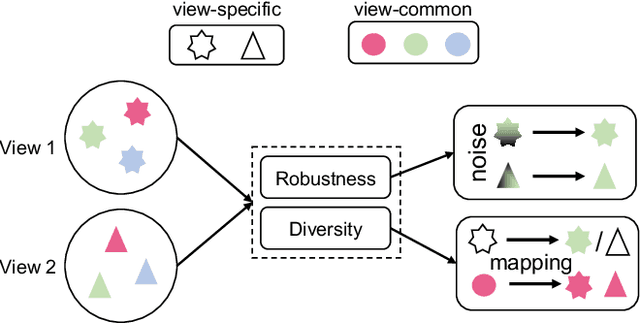
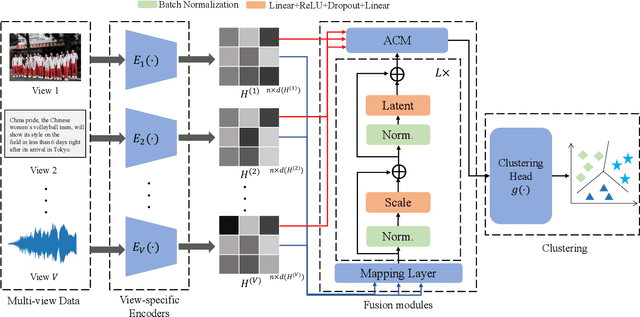
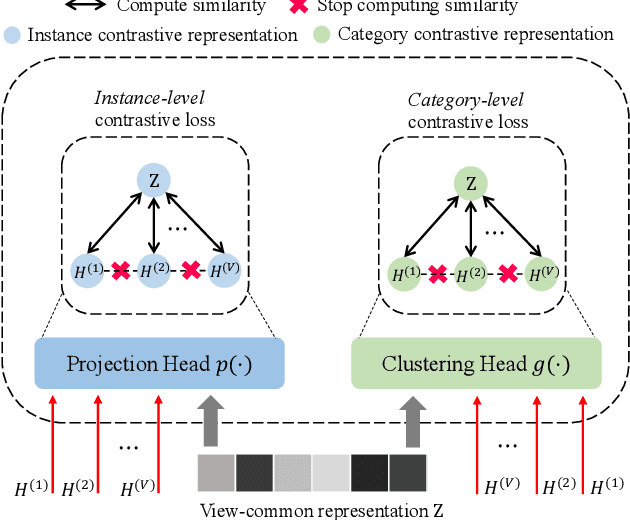
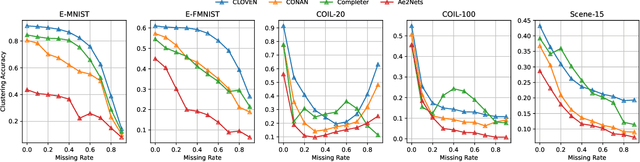
The past two decades have seen increasingly rapid advances in the field of multi-view representation learning due to it extracting useful information from diverse domains to facilitate the development of multi-view applications. However, the community faces two challenges: i) how to learn robust representations from a large amount of unlabeled data to against noise or incomplete views setting, and ii) how to balance view consistency and complementary for various downstream tasks. To this end, we utilize a deep fusion network to fuse view-specific representations into the view-common representation, extracting high-level semantics for obtaining robust representation. In addition, we employ a clustering task to guide the fusion network to prevent it from leading to trivial solutions. For balancing consistency and complementary, then, we design an asymmetrical contrastive strategy that aligns the view-common representation and each view-specific representation. These modules are incorporated into a unified method known as CLustering-guided cOntrastiVE fusioN (CLOVEN). We quantitatively and qualitatively evaluate the proposed method on five datasets, demonstrating that CLOVEN outperforms 11 competitive multi-view learning methods in clustering and classification. In the incomplete view scenario, our proposed method resists noise interference better than those of our competitors. Furthermore, the visualization analysis shows that CLOVEN can preserve the intrinsic structure of view-specific representation while also improving the compactness of view-commom representation. Our source code will be available soon at https://github.com/guanzhou-ke/cloven.