 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Private Adaptive Optimization with Side Information
Feb 12, 2022
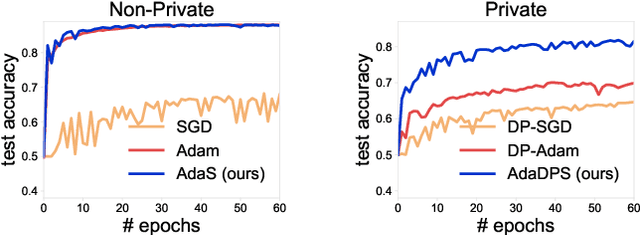

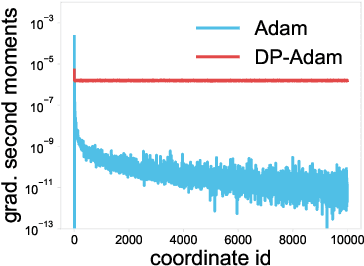
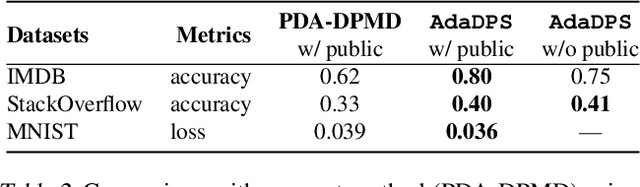
Adaptive optimization methods have become the default solvers for many machine learning tasks. Unfortunately, the benefits of adaptivity may degrade when training with differential privacy, as the noise added to ensure privacy reduces the effectiveness of the adaptive preconditioner. To this end, we propose AdaDPS, a general framework that uses non-sensitive side information to precondition the gradients, allowing the effective use of adaptive methods in private settings. We formally show AdaDPS reduces the amount of noise needed to achieve similar privacy guarantees, thereby improving optimization performance. Empirically, we leverage simple and readily available side information to explore the performance of AdaDPS in practice, comparing to strong baselines in both centralized and federated settings. Our results show that AdaDPS improves accuracy by 7.7% (absolute) on average -- yielding state-of-the-art privacy-utility trade-offs on large-scale text and image benchmarks.
Automated Driving Systems Data Acquisition and Processing Platform
Nov 24, 2022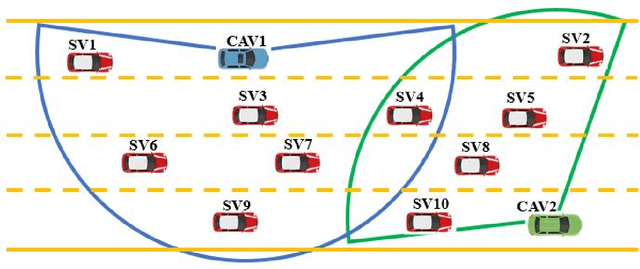
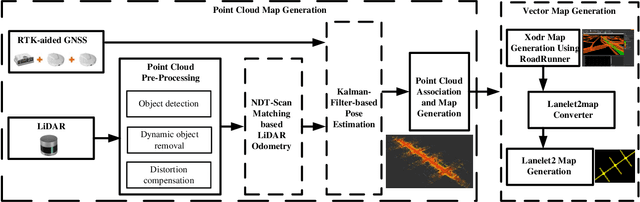
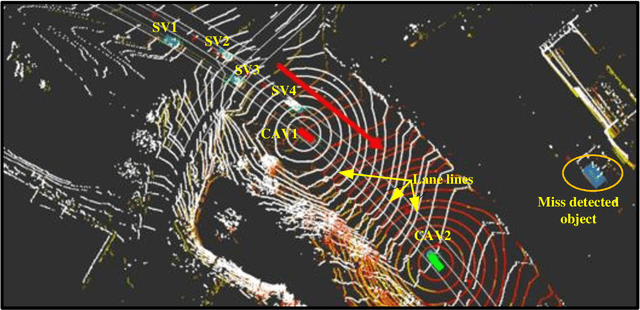
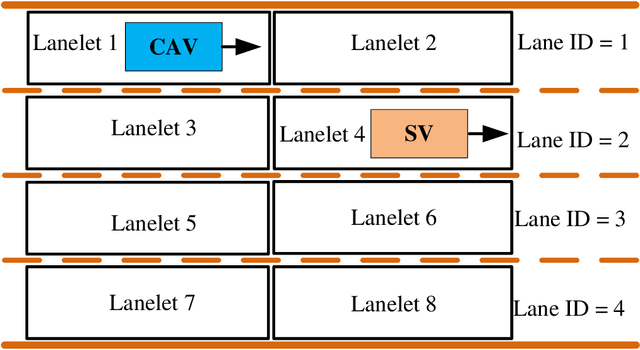
This paper presents an automated driving system (ADS) data acquisition and processing platform for vehicle trajectory extraction, reconstruction, and evaluation based on connected automated vehicle (CAV) cooperative perception. This platform presents a holistic pipeline from the raw advanced sensory data collection to data processing, which can process the sensor data from multiple CAVs and extract the objects' Identity (ID) number, position, speed, and orientation information in the map and Frenet coordinates. First, the ADS data acquisition and analytics platform are presented. Specifically, the experimental CAVs platform and sensor configuration are shown, and the processing software, including a deep-learning-based object detection algorithm using LiDAR information, a late fusion scheme to leverage cooperative perception to fuse the detected objects from multiple CAVs, and a multi-object tracking method is introduced. To further enhance the object detection and tracking results, high definition maps consisting of point cloud and vector maps are generated and forwarded to a world model to filter out the objects off the road and extract the objects' coordinates in Frenet coordinates and the lane information. In addition, a post-processing method is proposed to refine trajectories from the object tracking algorithms. Aiming to tackle the ID switch issue of the object tracking algorithm, a fuzzy-logic-based approach is proposed to detect the discontinuous trajectories of the same object. Finally, results, including object detection and tracking and a late fusion scheme, are presented, and the post-processing algorithm's improvements in noise level and outlier removal are discussed, confirming the functionality and effectiveness of the proposed holistic data collection and processing platform.
Bi-objective Optimization of Information Rate and Harvested Power in RIS-aided SWIPT Systems
Apr 24, 2022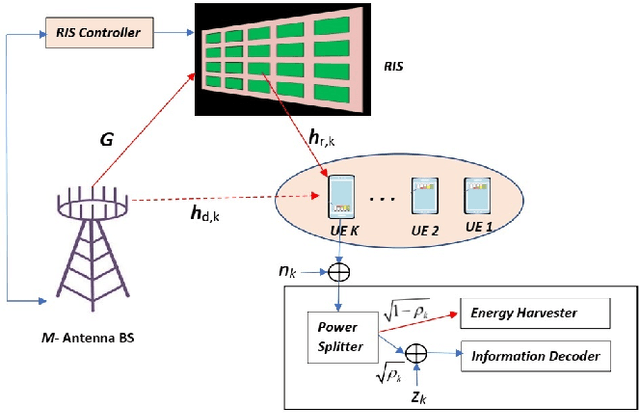
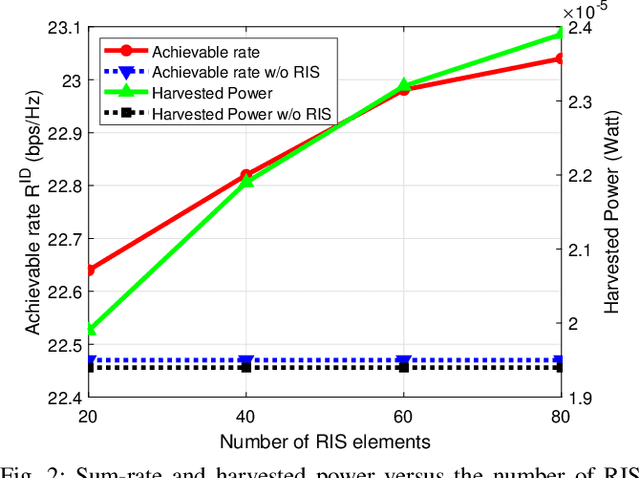
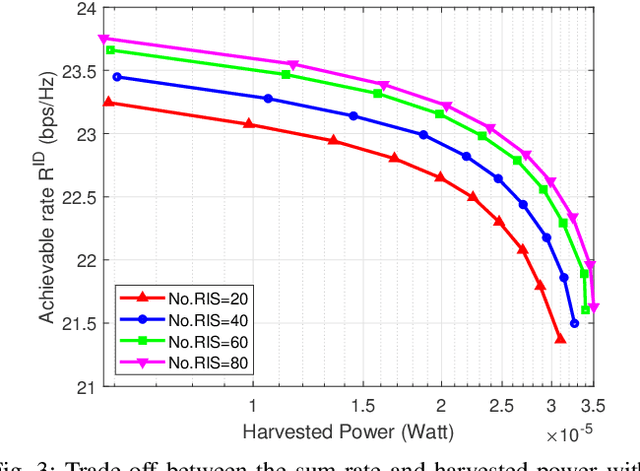
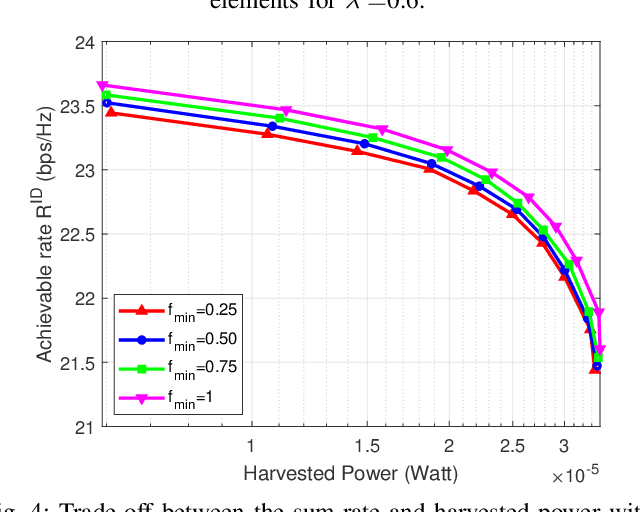
The problem of simultaneously optimizing the information rate and the harvested power in a reconfigurable intelligent surface (RIS)-aided multiple-input single-output downlink wireless network with simultaneous wireless information and power transfer (SWIPT) is addressed. The beamforming vectors, RIS reflection coefficients, and power split ratios are jointly optimized subject to maximum power constraints, minimum harvested power constraints, and realistic constraints on the RIS reflection coefficients. A practical algorithm is developed through an interplay of alternating optimization, sequential optimization, and pricing-based methods. Numerical results show that the deployment of RISs can significantly improve the information rate and the amount of harvested power.
TempCLR: Temporal Alignment Representation with Contrastive Learning
Dec 28, 2022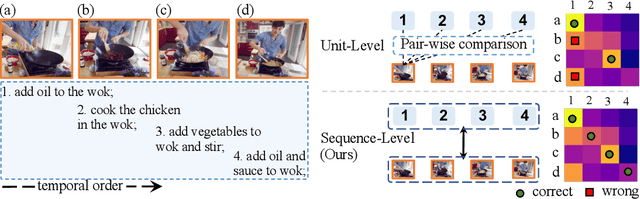
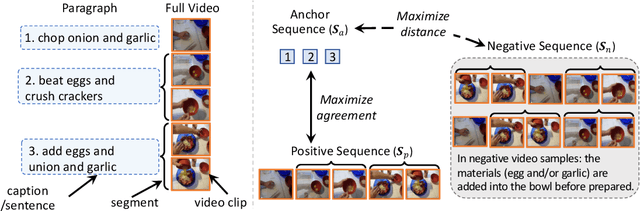
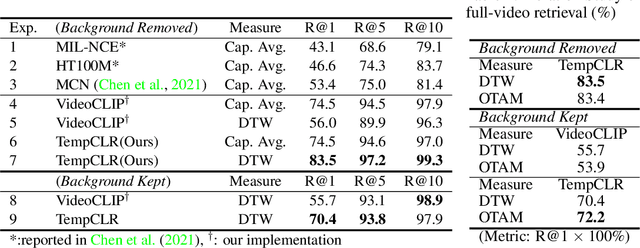
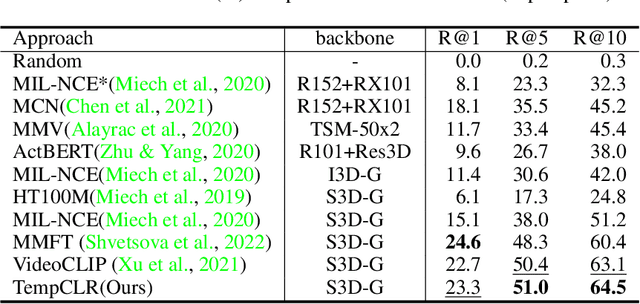
Video representation learning has been successful in video-text pre-training for zero-shot transfer, where each sentence is trained to be close to the paired video clips in a common feature space. For long videos, given a paragraph of description where the sentences describe different segments of the video, by matching all sentence-clip pairs, the paragraph and the full video are aligned implicitly. However, such unit-level similarity measure may ignore the global temporal context over a long time span, which inevitably limits the generalization ability. In this paper, we propose a contrastive learning framework TempCLR to compare the full video and the paragraph explicitly. As the video/paragraph is formulated as a sequence of clips/sentences, under the constraint of their temporal order, we use dynamic time warping to compute the minimum cumulative cost over sentence-clip pairs as the sequence-level distance. To explore the temporal dynamics, we break the consistency of temporal order by shuffling the video clips or sentences according to the temporal granularity. In this way, we obtain the representations for clips/sentences, which perceive the temporal information and thus facilitate the sequence alignment. In addition to pre-training on the video and paragraph, our approach can also generalize on the matching between different video instances. We evaluate our approach on video retrieval, action step localization, and few-shot action recognition, and achieve consistent performance gain over all three tasks. Detailed ablation studies are provided to justify the approach design.
Audiovisual Masked Autoencoders
Dec 09, 2022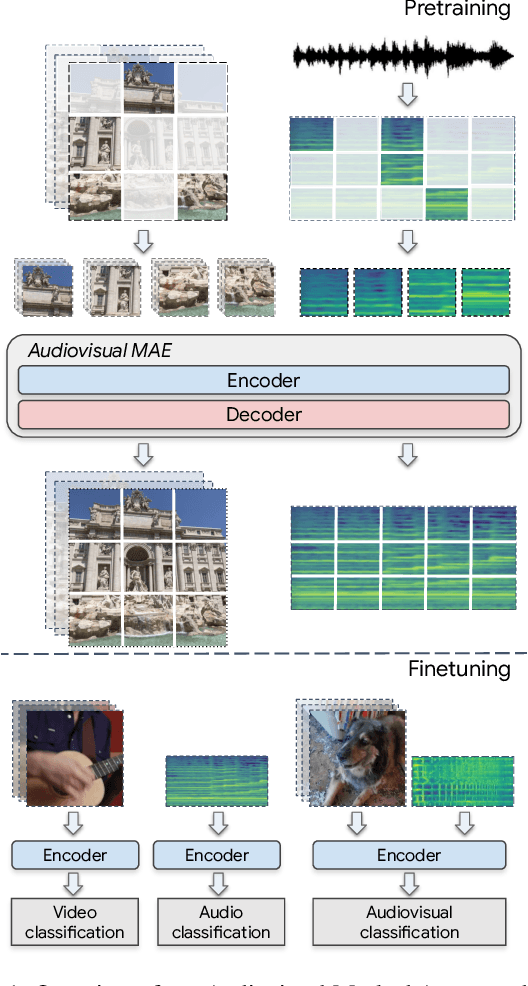
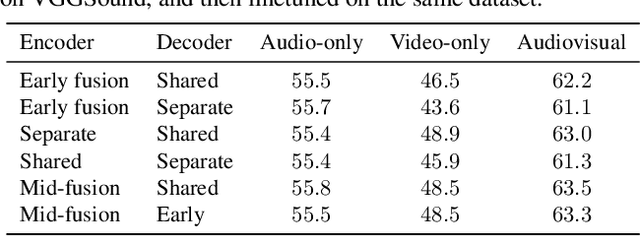
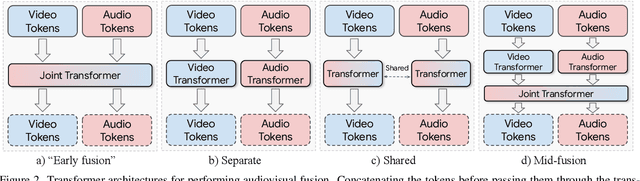
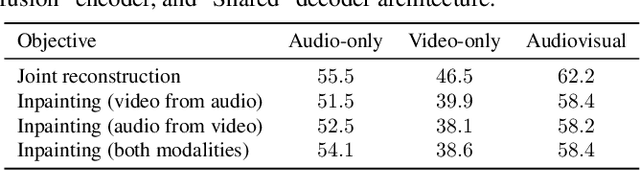
Can we leverage the audiovisual information already present in video to improve self-supervised representation learning? To answer this question, we study various pretraining architectures and objectives within the masked autoencoding framework, motivated by the success of similar methods in natural language and image understanding. We show that we can achieve significant improvements on audiovisual downstream classification tasks, surpassing the state-of-the-art on VGGSound and AudioSet. Furthermore, we can leverage our audiovisual pretraining scheme for multiple unimodal downstream tasks using a single audiovisual pretrained model. We additionally demonstrate the transferability of our representations, achieving state-of-the-art audiovisual results on Epic Kitchens without pretraining specifically for this dataset.
Multi-task Learning for Personal Health Mention Detection on Social Media
Dec 09, 2022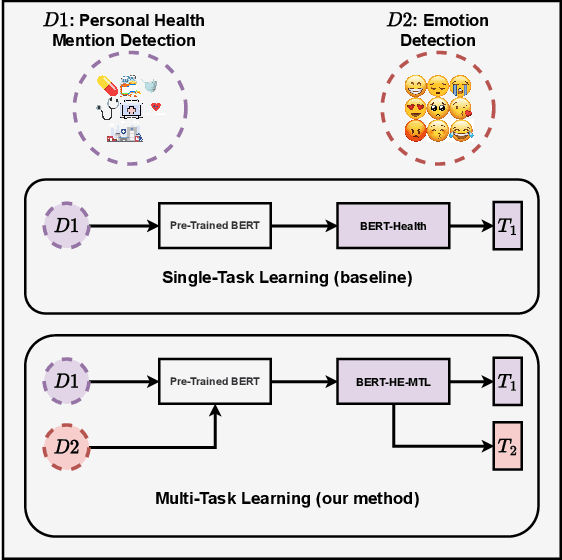
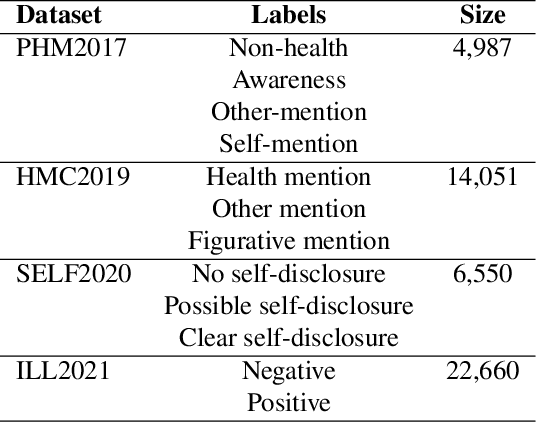
Detecting personal health mentions on social media is essential to complement existing health surveillance systems. However, annotating data for detecting health mentions at a large scale is a challenging task. This research employs a multitask learning framework to leverage available annotated data from a related task to improve the performance on the main task to detect personal health experiences mentioned in social media texts. Specifically, we focus on incorporating emotional information into our target task by using emotion detection as an auxiliary task. Our approach significantly improves a wide range of personal health mention detection tasks compared to a strong state-of-the-art baseline.
Sharing Linkable Learning Objects with the use of Metadata and a Taxonomy Assistant for Categorization
Dec 09, 2022In this work, a re-design of the Moodledata module functionalities is presented to share learning objects between e-learning content platforms, e.g., Moodle and G-Lorep, in a linkable object format. The e-learning courses content of the Drupal-based Content Management System G-Lorep for academic learning is exchanged designing an object incorporating metadata to support the reuse and the classification in its context. In such an Artificial Intelligence environment, the exchange of Linkable Learning Objects can be used for dialogue between Learning Systems to obtain information, especially with the use of semantic or structural similarity measures to enhance the existent Taxonomy Assistant for advanced automated classification.
MAViL: Masked Audio-Video Learners
Dec 15, 2022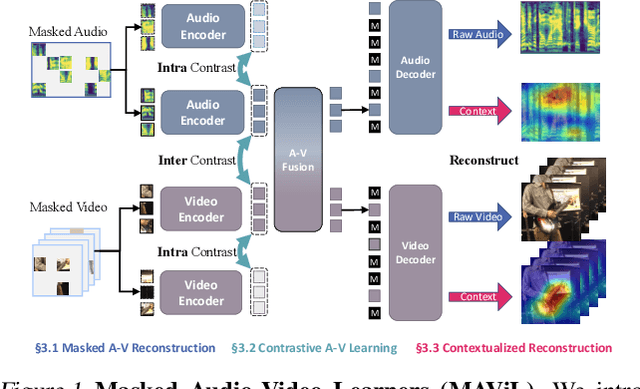



We present Masked Audio-Video Learners (MAViL) to train audio-visual representations. Our approach learns with three complementary forms of self-supervision: (1) reconstruction of masked audio and video input data, (2) intra- and inter-modal contrastive learning with masking, and (3) self-training by reconstructing joint audio-video contextualized features learned from the first two objectives. Pre-training with MAViL not only enables the model to perform well in audio-visual classification and retrieval tasks but also improves representations of each modality in isolation, without using information from the other modality for fine-tuning or inference. Empirically, MAViL sets a new state-of-the-art on AudioSet (53.1 mAP) and VGGSound (67.1% accuracy). For the first time, a self-supervised audio-visual model outperforms ones that use external supervision on these benchmarks. Code will be available soon.
Ungeneralizable Contextual Logistic Bandit in Credit Scoring
Dec 15, 2022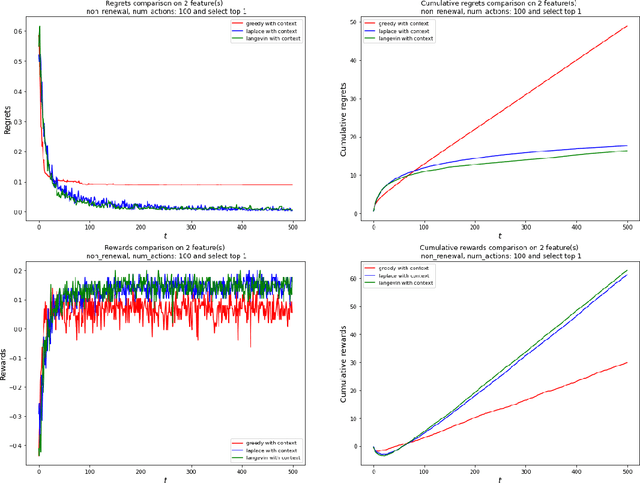
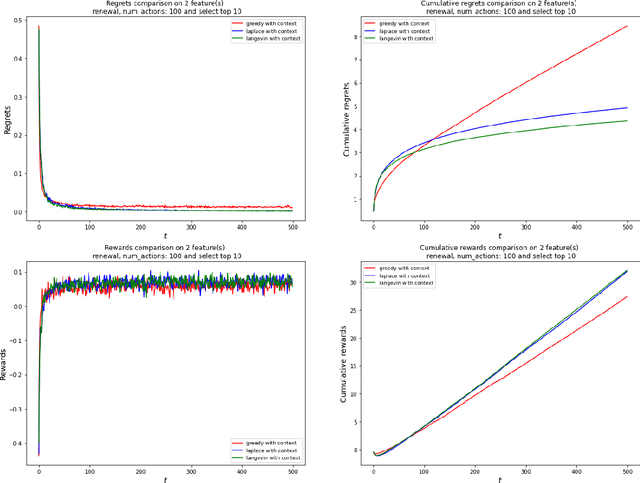
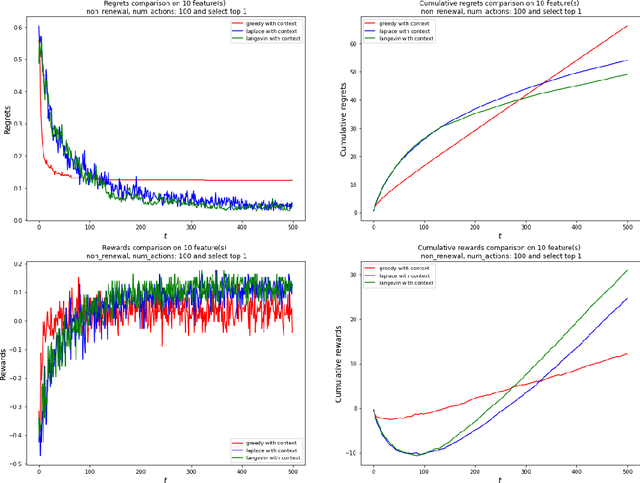
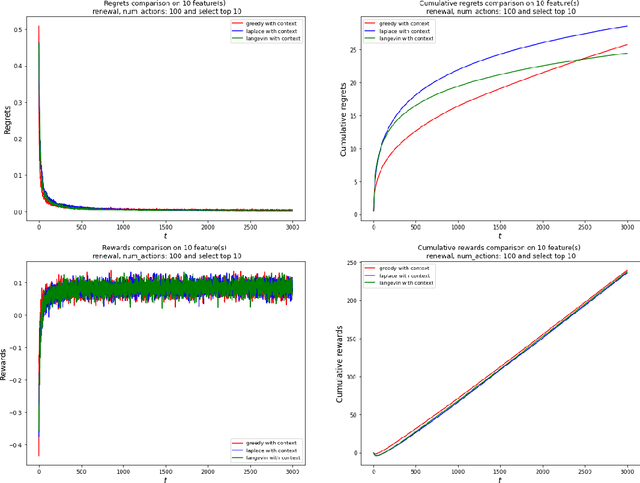
The application of reinforcement learning in credit scoring has created a unique setting for contextual logistic bandit that does not conform to the usual exploration-exploitation tradeoff but rather favors exploration-free algorithms. Through sufficient randomness in a pool of observable contexts, the reinforcement learning agent can simultaneously exploit an action with the highest reward while still learning more about the structure governing that environment. Thus, it is the case that greedy algorithms consistently outperform algorithms with efficient exploration, such as Thompson sampling. However, in a more pragmatic scenario in credit scoring, lenders can, to a degree, classify each borrower as a separate group, and learning about the characteristics of each group does not infer any information to another group. Through extensive simulations, we show that Thompson sampling dominates over greedy algorithms given enough timesteps which increase with the complexity of underlying features.
Multi-Level Association Rule Mining for Wireless Network Time Series Data
Dec 15, 2022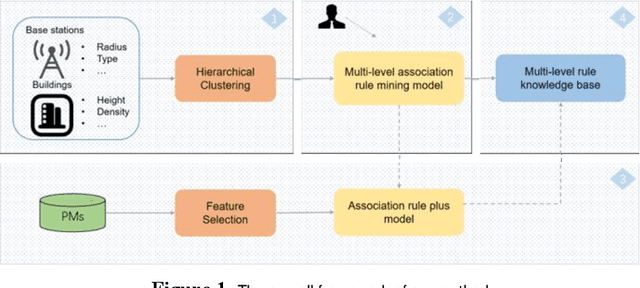
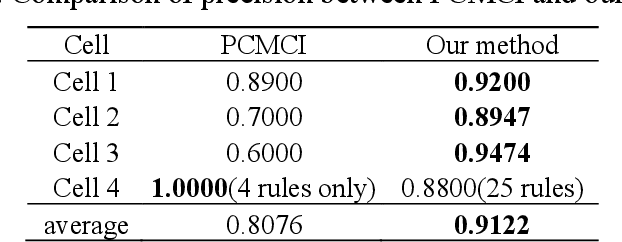
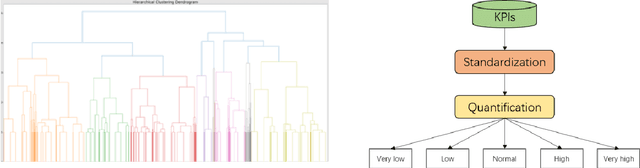
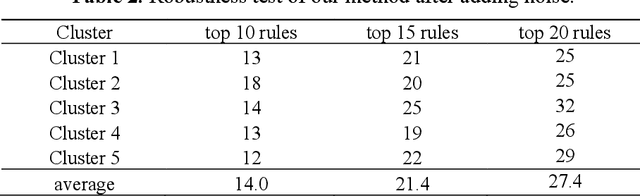
Key performance indicators(KPIs) are of great significance in the monitoring of wireless network service quality. The network service quality can be improved by adjusting relevant configuration parameters(CPs) of the base station. However, there are numerous CPs and different cells may affect each other, which bring great challenges to the association analysis of wireless network data. In this paper, we propose an adjustable multi-level association rule mining framework, which can quantitatively mine association rules at each level with environmental information, including engineering parameters and performance management(PMs), and it has interpretability at each level. Specifically, We first cluster similar cells, then quantify KPIs and CPs, and integrate expert knowledge into the association rule mining model, which improve the robustness of the model. The experimental results in real world dataset prove the effectiveness of our method.