 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Predicting dominant hand from spatiotemporal context varying physiological data
Dec 08, 2022
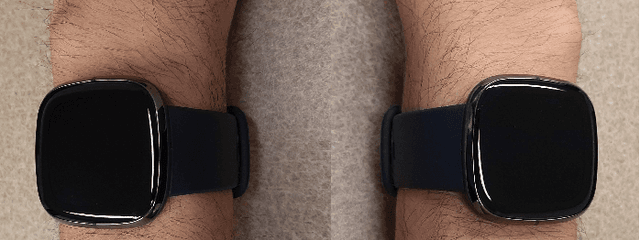
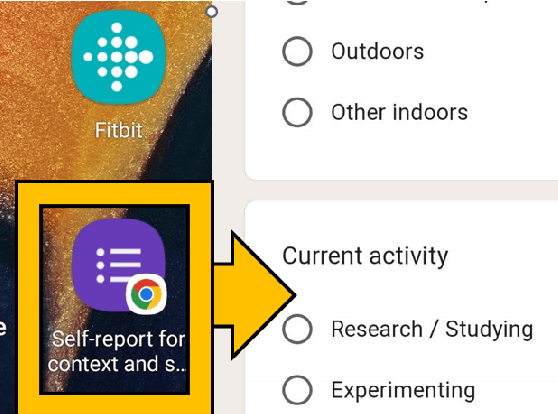
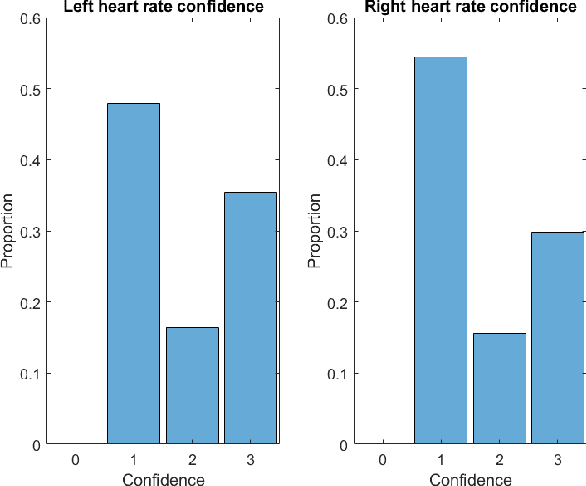
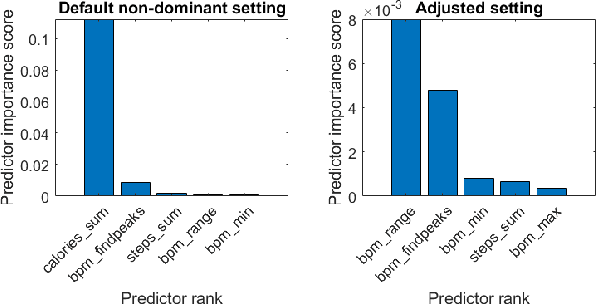
Health metrics from wrist-worn devices demand an automatic dominant hand prediction to keep an accurate operation. The prediction would improve reliability, enhance the consumer experience, and encourage further development of healthcare applications. This paper aims to evaluate the use of physiological and spatiotemporal context information from a two-hand experiment to predict the wrist placement of a commercial smartwatch. The main contribution is a methodology to obtain an effective model and features from low sample rate physiological sensors and a self-reported context survey. Results show an effective dominant hand prediction using data from a single subject under real-life conditions.
Secure SWIPT in STAR-RIS Aided Downlink MISO Rate-Splitting Multiple Access Networks
Nov 16, 2022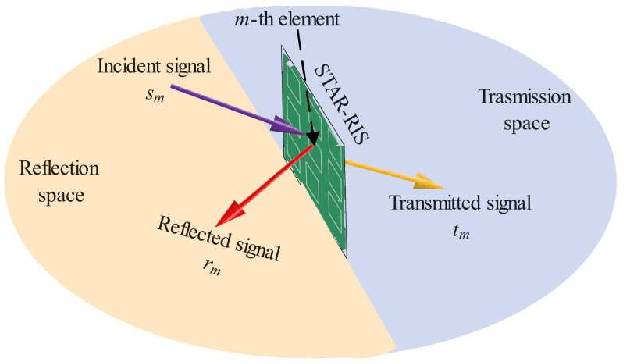
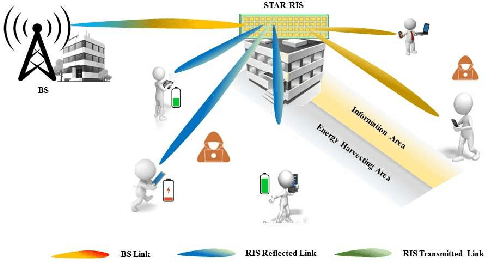

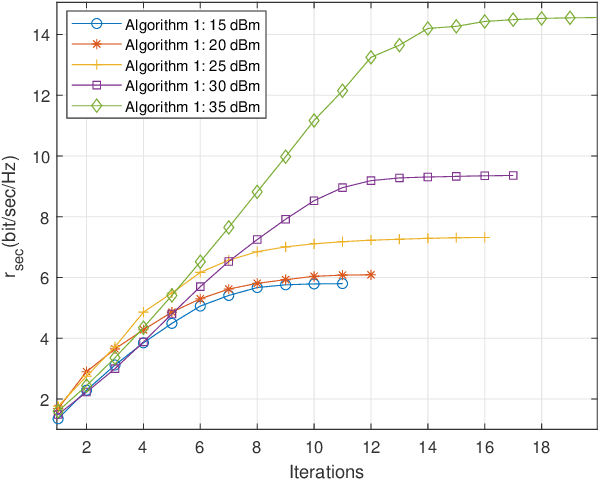
Recently, simultaneously transmitting and reflecting reconfigurable intelligent surfaces (STAR-RISs) have emerged as a novel technology that facilitates sustainable communication by providing 360 coverage and new degrees-of-freedom (DoF) for manipulating signal propagation as well as simultaneous wireless information and power transfer (SWIPT). Inspired by these applications, this paper presents a novel STAR-RIS-aided secure SWIPT system for downlink multiple input single output (MISO) Rate-Splitting multiple access (RSMA) networks. The transmitter concurrently communicates with the information receivers (IRs) and sends energy to untrusted energy receivers (UERs). UERs are also able to wiretap the IR streams. The paper assumes that the channel state information (CSI) of the IRs is known at the transmitter. However, only imperfect CSI (ICSI) for the UERs is available at the transmitter. The paper aims to maximize the achievable worst-case sum secrecy rate (WCSSR) of the IRs under a total transmit power constraint, a sum energy constraint for the UERs, and constraints on the transmission and reflection coefficients by jointly optimizing the precoders and the transmission and reflection beamforming at the STAR-RIS. The formulated problem is non-convex with intricately coupled variables, and to tackle this challenge a suboptimal two-step iterative algorithm based on the sequential parametric convex approximation (SPCA) method is proposed. Specifically, the precoders and the transmission and reflection beamforming vectors are optimized alternatingly. Simulations are conducted to show that the proposed RSMA-based algorithm in a STAR-RIS aided network can improve the secrecy of the confidential information and the overall spectral efficiency.
Measuring the Mixing of Contextual Information in the Transformer
Mar 08, 2022
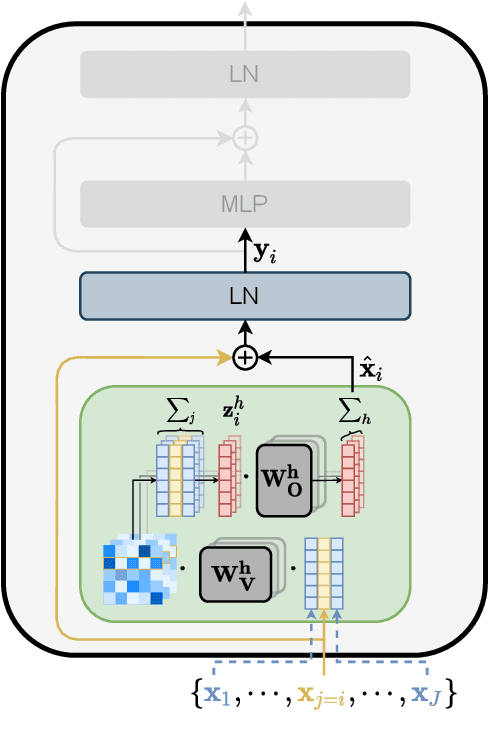
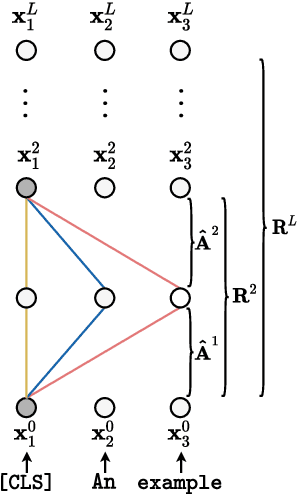

The Transformer architecture aggregates input information through the self-attention mechanism, but there is no clear understanding of how this information is mixed across the entire model. Additionally, recent works have demonstrated that attention weights alone are not enough to describe the flow of information. In this paper, we consider the whole attention block --multi-head attention, residual connection, and layer normalization-- and define a metric to measure token-to-token interactions within each layer, considering the characteristics of the representation space. Then, we aggregate layer-wise interpretations to provide input attribution scores for model predictions. Experimentally, we show that our method, ALTI (Aggregation of Layer-wise Token-to-token Interactions), provides faithful explanations and outperforms similar aggregation methods.
TempCLR: Temporal Alignment Representation with Contrastive Learning
Dec 28, 2022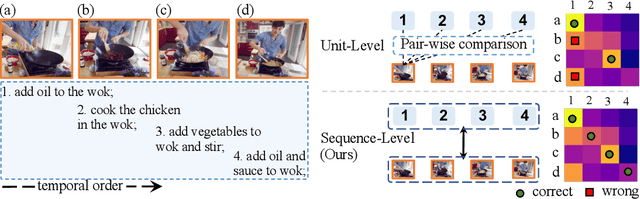
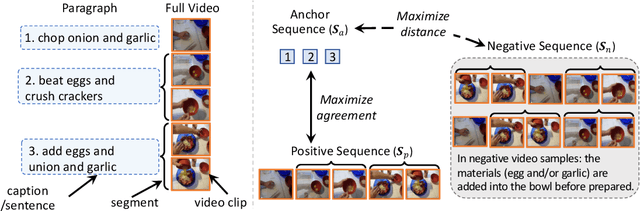
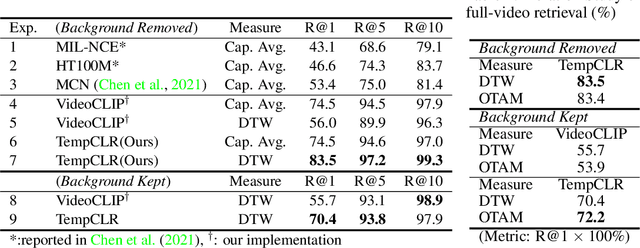
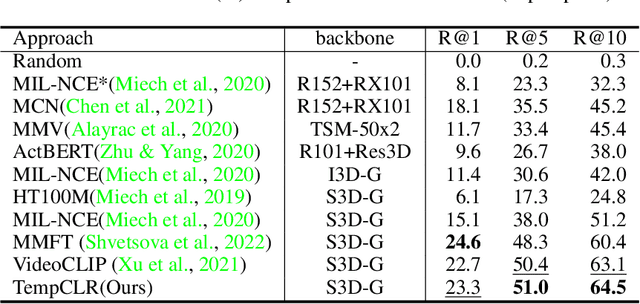
Video representation learning has been successful in video-text pre-training for zero-shot transfer, where each sentence is trained to be close to the paired video clips in a common feature space. For long videos, given a paragraph of description where the sentences describe different segments of the video, by matching all sentence-clip pairs, the paragraph and the full video are aligned implicitly. However, such unit-level similarity measure may ignore the global temporal context over a long time span, which inevitably limits the generalization ability. In this paper, we propose a contrastive learning framework TempCLR to compare the full video and the paragraph explicitly. As the video/paragraph is formulated as a sequence of clips/sentences, under the constraint of their temporal order, we use dynamic time warping to compute the minimum cumulative cost over sentence-clip pairs as the sequence-level distance. To explore the temporal dynamics, we break the consistency of temporal order by shuffling the video clips or sentences according to the temporal granularity. In this way, we obtain the representations for clips/sentences, which perceive the temporal information and thus facilitate the sequence alignment. In addition to pre-training on the video and paragraph, our approach can also generalize on the matching between different video instances. We evaluate our approach on video retrieval, action step localization, and few-shot action recognition, and achieve consistent performance gain over all three tasks. Detailed ablation studies are provided to justify the approach design.
Band Relevance Factor (BRF): a novel automatic frequency band selection method based on vibration analysis for rotating machinery
Dec 04, 2022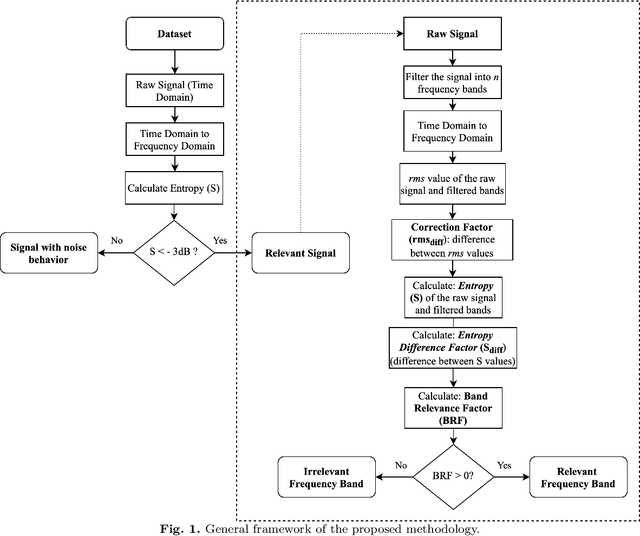
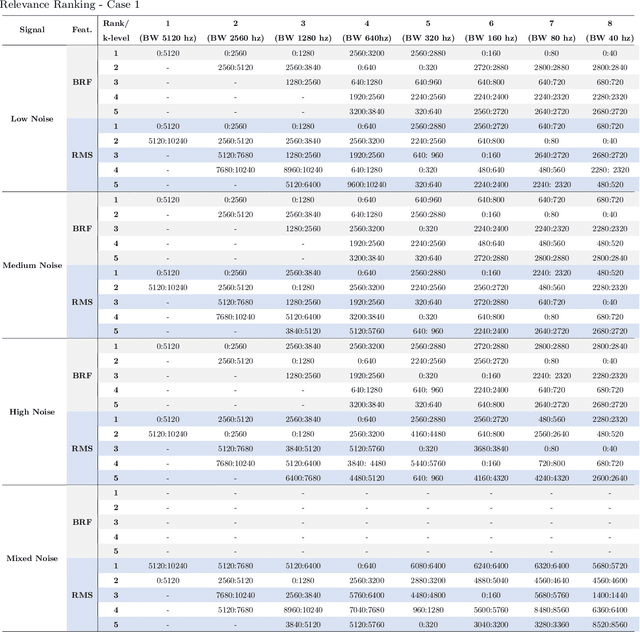

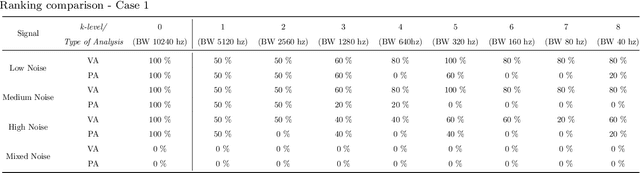
The monitoring of rotating machinery has now become a fundamental activity in the industry, given the high criticality in production processes. Extracting useful information from relevant signals is a key factor for effective monitoring: studies in the areas of Informative Frequency Band selection (IFB) and Feature Extraction/Selection have demonstrated to be effective approaches. However, in general, typical methods in such areas focuses on identifying bands where impulsive excitations are present or on analyzing the relevance of the features after its signal extraction: both approaches lack in terms of procedure automation and efficiency. Typically, the approaches presented in the literature fail to identify frequencies relevant for the vibration analysis of a rotating machinery; moreover, with such approaches features can be extracted from irrelevant bands, leading to additional complexity in the analysis. To overcome such problems, the present study proposes a new approach called Band Relevance Factor (BRF). BRF aims to perform an automatic selection of all relevant frequency bands for a vibration analysis of a rotating machine based on spectral entropy. The results are presented through a relevance ranking and can be visually analyzed through a heatmap. The effectiveness of the approach is validated in a synthetically created dataset and two real dataset, showing that the BRF is able to identify the bands that present relevant information for the analysis of rotating machinery.
DSNet: a simple yet efficient network with dual-stream attention for lesion segmentation
Dec 14, 2022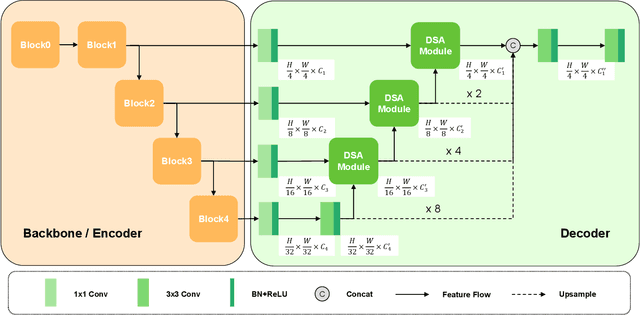
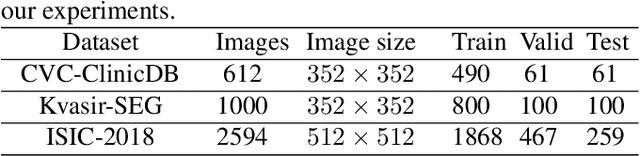
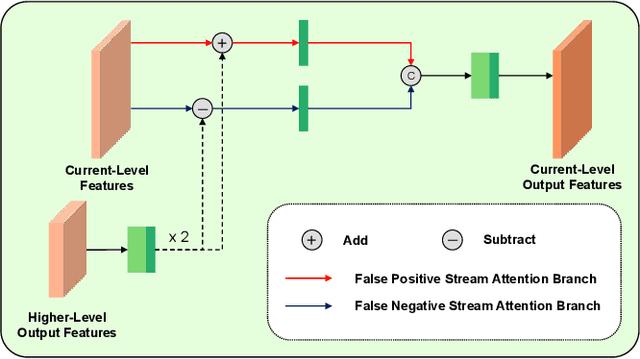
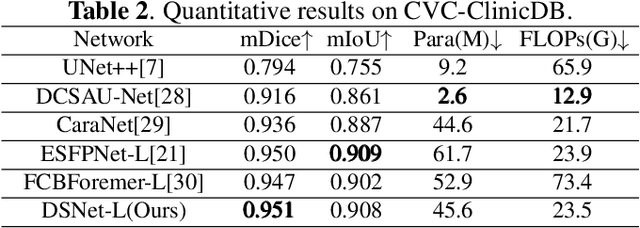
Lesion segmentation requires both speed and accuracy. In this paper, we propose a simple yet efficient network DSNet, which consists of a encoder based on Transformer and a convolutional neural network(CNN)-based distinct pyramid decoder containing three dual-stream attention (DSA) modules. Specifically, the DSA module fuses features from two adjacent levels through the false positive stream attention (FPSA) branch and the false negative stream attention (FNSA) branch to obtain features with diversified contextual information. We compare our method with various state-of-the-art (SOTA) lesion segmentation methods with several public datasets, including CVC-ClinicDB, Kvasir-SEG, and ISIC-2018 Task 1. The experimental results show that our method achieves SOTA performance in terms of mean Dice coefficient (mDice) and mean Intersection over Union (mIoU) with low model complexity and memory consumption.
Distributed Linear Bandits under Communication Constraints
Nov 04, 2022We consider distributed linear bandits where $M$ agents learn collaboratively to minimize the overall cumulative regret incurred by all agents. Information exchange is facilitated by a central server, and both the uplink and downlink communications are carried over channels with fixed capacity, which limits the amount of information that can be transmitted in each use of the channels. We investigate the regret-communication trade-off by (i) establishing information-theoretic lower bounds on the required communications (in terms of bits) for achieving a sublinear regret order; (ii) developing an efficient algorithm that achieves the minimum sublinear regret order offered by centralized learning using the minimum order of communications dictated by the information-theoretic lower bounds. For sparse linear bandits, we show a variant of the proposed algorithm offers better regret-communication trade-off by leveraging the sparsity of the problem.
MHCCL: Masked Hierarchical Cluster-wise Contrastive Learning for Multivariate Time Series
Dec 02, 2022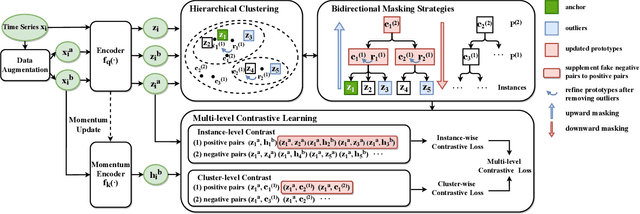
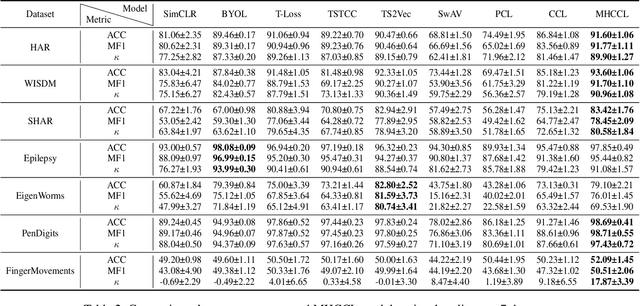
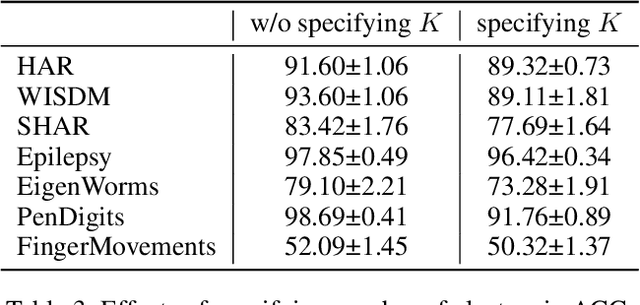
Learning semantic-rich representations from raw unlabeled time series data is critical for downstream tasks such as classification and forecasting. Contrastive learning has recently shown its promising representation learning capability in the absence of expert annotations. However, existing contrastive approaches generally treat each instance independently, which leads to false negative pairs that share the same semantics. To tackle this problem, we propose MHCCL, a Masked Hierarchical Cluster-wise Contrastive Learning model, which exploits semantic information obtained from the hierarchical structure consisting of multiple latent partitions for multivariate time series. Motivated by the observation that fine-grained clustering preserves higher purity while coarse-grained one reflects higher-level semantics, we propose a novel downward masking strategy to filter out fake negatives and supplement positives by incorporating the multi-granularity information from the clustering hierarchy. In addition, a novel upward masking strategy is designed in MHCCL to remove outliers of clusters at each partition to refine prototypes, which helps speed up the hierarchical clustering process and improves the clustering quality. We conduct experimental evaluations on seven widely-used multivariate time series datasets. The results demonstrate the superiority of MHCCL over the state-of-the-art approaches for unsupervised time series representation learning.
RGB-D based Stair Detection using Deep Learning for Autonomous Stair Climbing
Dec 02, 2022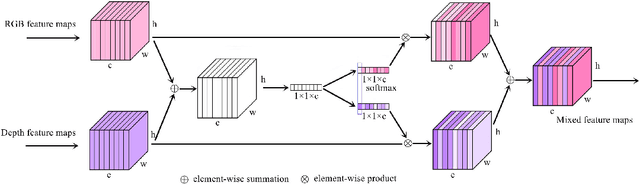
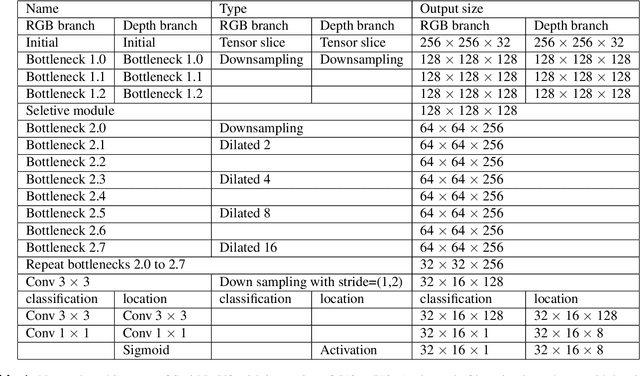
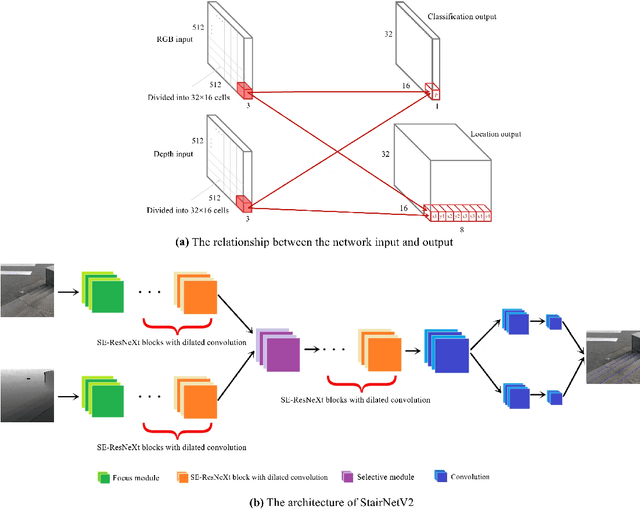
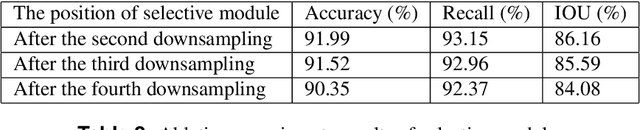
Stairs are common building structures in urban environment, and stair detection is an important part of environment perception for autonomous mobile robots. Most existing algorithms have difficulty combining the visual information from binocular sensors effectively and ensuring reliable detection at night and in the case of extremely fuzzy visual clues. To solve these problems, we propose a neural network architecture with inputs of both RGB map and depth map. Specifically, we design the selective module which can make the network learn the complementary relationship between RGB map and depth map and effectively combine the information from RGB map and depth map in different scenes. In addition, we also design a line clustering algorithm for the post-processing of detection results, which can make full use of the detection results to obtain the geometric parameters of stairs. Experiments on our dataset show that our method can achieve better accuracy and recall compared with the previous state-of-the-art deep learning method, which are 5.64% and 7.97%, respectively. Our method also has extremely fast detection speed, and a lightweight version can achieve 300 + frames per second with the same resolution, which can meet the needs of most real-time detection scenes.
Geometry-Aware Network for Domain Adaptive Semantic Segmentation
Dec 02, 2022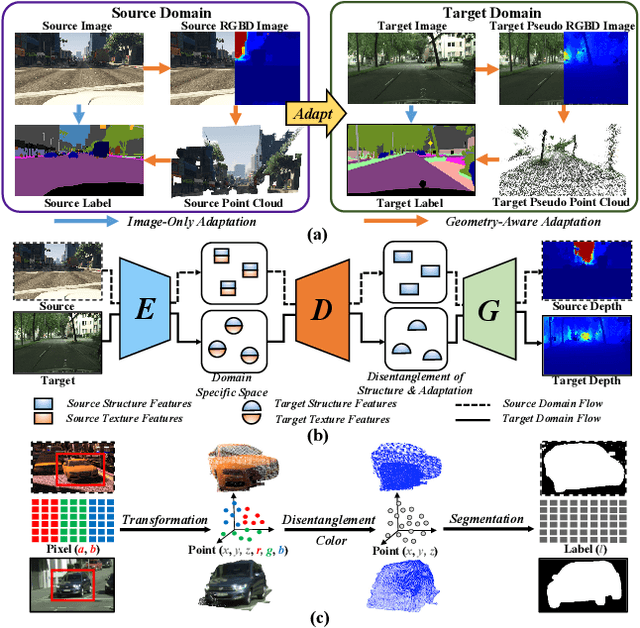

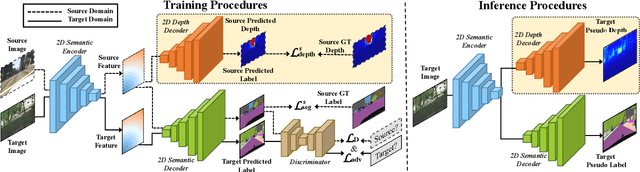

Measuring and alleviating the discrepancies between the synthetic (source) and real scene (target) data is the core issue for domain adaptive semantic segmentation. Though recent works have introduced depth information in the source domain to reinforce the geometric and semantic knowledge transfer, they cannot extract the intrinsic 3D information of objects, including positions and shapes, merely based on 2D estimated depth. In this work, we propose a novel Geometry-Aware Network for Domain Adaptation (GANDA), leveraging more compact 3D geometric point cloud representations to shrink the domain gaps. In particular, we first utilize the auxiliary depth supervision from the source domain to obtain the depth prediction in the target domain to accomplish structure-texture disentanglement. Beyond depth estimation, we explicitly exploit 3D topology on the point clouds generated from RGB-D images for further coordinate-color disentanglement and pseudo-labels refinement in the target domain. Moreover, to improve the 2D classifier in the target domain, we perform domain-invariant geometric adaptation from source to target and unify the 2D semantic and 3D geometric segmentation results in two domains. Note that our GANDA is plug-and-play in any existing UDA framework. Qualitative and quantitative results demonstrate that our model outperforms state-of-the-arts on GTA5->Cityscapes and SYNTHIA->Cityscapes.