 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
DRG-Net: Interactive Joint Learning of Multi-lesion Segmentation and Classification for Diabetic Retinopathy Grading
Dec 30, 2022
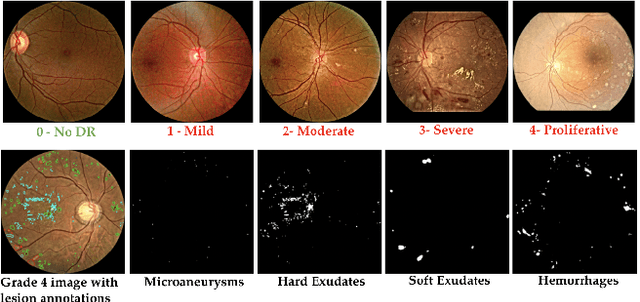
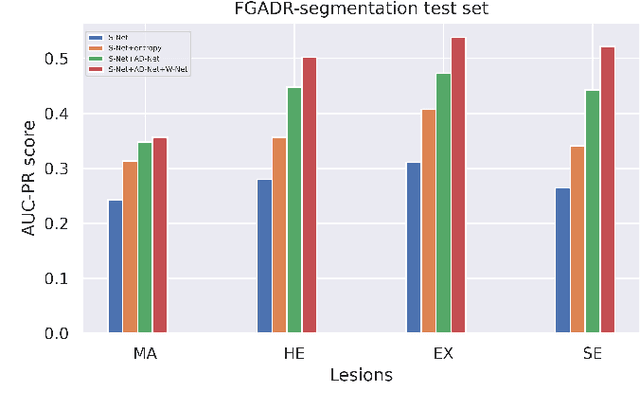
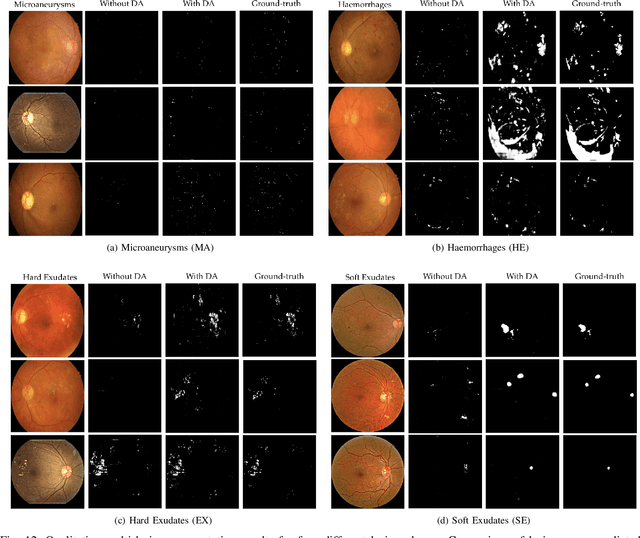
Diabetic Retinopathy (DR) is a leading cause of vision loss in the world, and early DR detection is necessary to prevent vision loss and support an appropriate treatment. In this work, we leverage interactive machine learning and introduce a joint learning framework, termed DRG-Net, to effectively learn both disease grading and multi-lesion segmentation. Our DRG-Net consists of two modules: (i) DRG-AI-System to classify DR Grading, localize lesion areas, and provide visual explanations; (ii) DRG-Expert-Interaction to receive feedback from user-expert and improve the DRG-AI-System. To deal with sparse data, we utilize transfer learning mechanisms to extract invariant feature representations by using Wasserstein distance and adversarial learning-based entropy minimization. Besides, we propose a novel attention strategy at both low- and high-level features to automatically select the most significant lesion information and provide explainable properties. In terms of human interaction, we further develop DRG-Net as a tool that enables expert users to correct the system's predictions, which may then be used to update the system as a whole. Moreover, thanks to the attention mechanism and loss functions constraint between lesion features and classification features, our approach can be robust given a certain level of noise in the feedback of users. We have benchmarked DRG-Net on the two largest DR datasets, i.e., IDRID and FGADR, and compared it to various state-of-the-art deep learning networks. In addition to outperforming other SOTA approaches, DRG-Net is effectively updated using user feedback, even in a weakly-supervised manner.
DGFont++: Robust Deformable Generative Networks for Unsupervised Font Generation
Dec 30, 2022
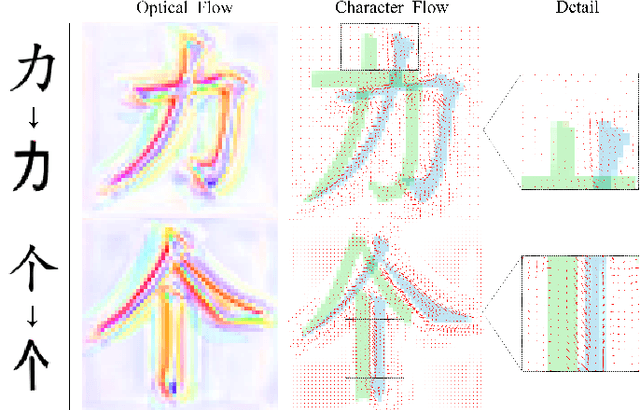


Automatic font generation without human experts is a practical and significant problem, especially for some languages that consist of a large number of characters. Existing methods for font generation are often in supervised learning. They require a large number of paired data, which are labor-intensive and expensive to collect. In contrast, common unsupervised image-to-image translation methods are not applicable to font generation, as they often define style as the set of textures and colors. In this work, we propose a robust deformable generative network for unsupervised font generation (abbreviated as DGFont++). We introduce a feature deformation skip connection (FDSC) to learn local patterns and geometric transformations between fonts. The FDSC predicts pairs of displacement maps and employs the predicted maps to apply deformable convolution to the low-level content feature maps. The outputs of FDSC are fed into a mixer to generate final results. Moreover, we introduce contrastive self-supervised learning to learn a robust style representation for fonts by understanding the similarity and dissimilarities of fonts. To distinguish different styles, we train our model with a multi-task discriminator, which ensures that each style can be discriminated independently. In addition to adversarial loss, another two reconstruction losses are adopted to constrain the domain-invariant characteristics between generated images and content images. Taking advantage of FDSC and the adopted loss functions, our model is able to maintain spatial information and generates high-quality character images in an unsupervised manner. Experiments demonstrate that our model is able to generate character images of higher quality than state-of-the-art methods.
Alleviating neighbor bias: augmenting graph self-supervise learning with structural equivalent positive samples
Dec 08, 2022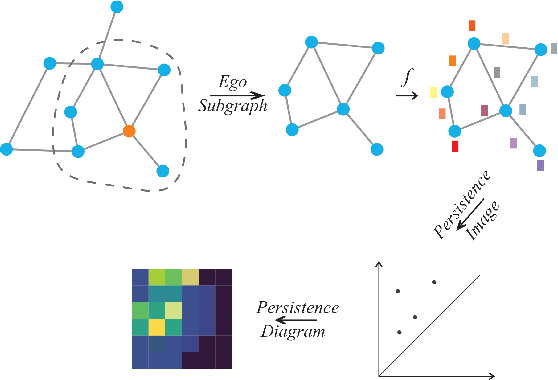
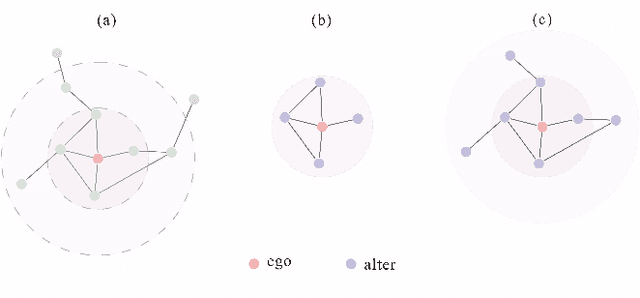
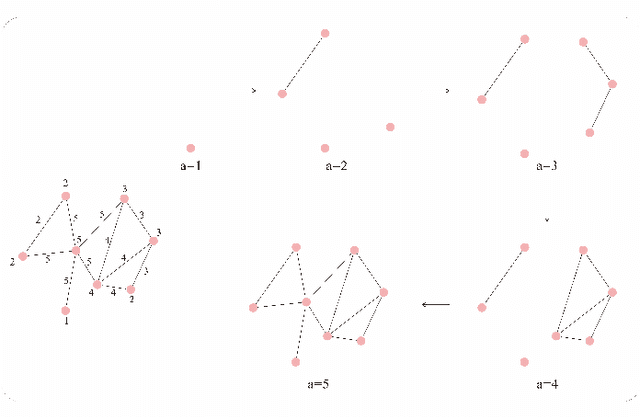
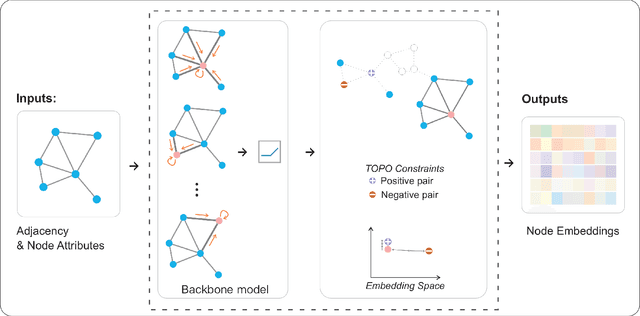
In recent years, using a self-supervised learning framework to learn the general characteristics of graphs has been considered a promising paradigm for graph representation learning. The core of self-supervised learning strategies for graph neural networks lies in constructing suitable positive sample selection strategies. However, existing GNNs typically aggregate information from neighboring nodes to update node representations, leading to an over-reliance on neighboring positive samples, i.e., homophilous samples; while ignoring long-range positive samples, i.e., positive samples that are far apart on the graph but structurally equivalent samples, a problem we call "neighbor bias." This neighbor bias can reduce the generalization performance of GNNs. In this paper, we argue that the generalization properties of GNNs should be determined by combining homogeneous samples and structurally equivalent samples, which we call the "GC combination hypothesis." Therefore, we propose a topological signal-driven self-supervised method. It uses a topological information-guided structural equivalence sampling strategy. First, we extract multiscale topological features using persistent homology. Then we compute the structural equivalence of node pairs based on their topological features. In particular, we design a topological loss function to pull in non-neighboring node pairs with high structural equivalence in the representation space to alleviate neighbor bias. Finally, we use the joint training mechanism to adjust the effect of structural equivalence on the model to fit datasets with different characteristics. We conducted experiments on the node classification task across seven graph datasets. The results show that the model performance can be effectively improved using a strategy of topological signal enhancement.
Bio-Inspired, Task-Free Continual Learning through Activity Regularization
Dec 08, 2022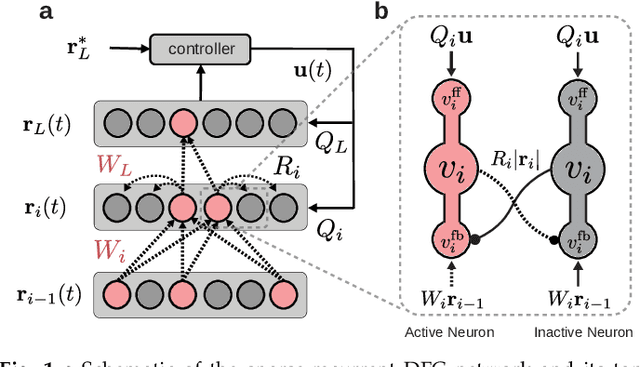
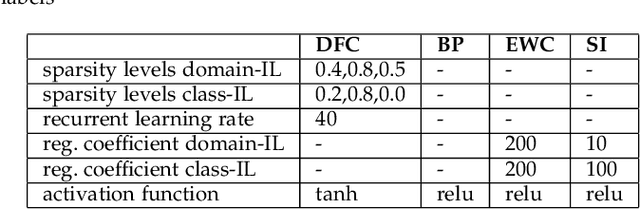
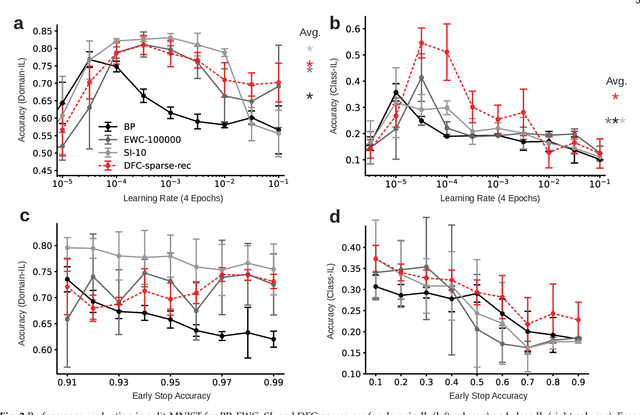
The ability to sequentially learn multiple tasks without forgetting is a key skill of biological brains, whereas it represents a major challenge to the field of deep learning. To avoid catastrophic forgetting, various continual learning (CL) approaches have been devised. However, these usually require discrete task boundaries. This requirement seems biologically implausible and often limits the application of CL methods in the real world where tasks are not always well defined. Here, we take inspiration from neuroscience, where sparse, non-overlapping neuronal representations have been suggested to prevent catastrophic forgetting. As in the brain, we argue that these sparse representations should be chosen on the basis of feed forward (stimulus-specific) as well as top-down (context-specific) information. To implement such selective sparsity, we use a bio-plausible form of hierarchical credit assignment known as Deep Feedback Control (DFC) and combine it with a winner-take-all sparsity mechanism. In addition to sparsity, we introduce lateral recurrent connections within each layer to further protect previously learned representations. We evaluate the new sparse-recurrent version of DFC on the split-MNIST computer vision benchmark and show that only the combination of sparsity and intra-layer recurrent connections improves CL performance with respect to standard backpropagation. Our method achieves similar performance to well-known CL methods, such as Elastic Weight Consolidation and Synaptic Intelligence, without requiring information about task boundaries. Overall, we showcase the idea of adopting computational principles from the brain to derive new, task-free learning algorithms for CL.
Generative Model Based Highly Efficient Semantic Communication Approach for Image Transmission
Nov 18, 2022

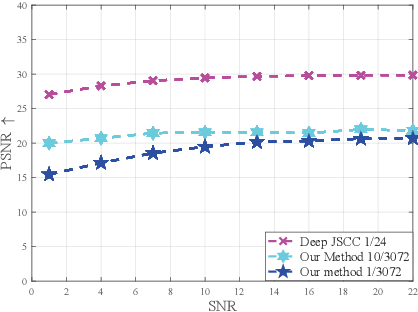
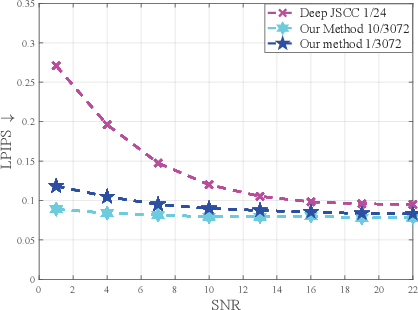
Deep learning (DL) based semantic communication methods have been explored to transmit images efficiently in recent years. In this paper, we propose a generative model based semantic communication to further improve the efficiency of image transmission and protect private information. In particular, the transmitter extracts the interpretable latent representation from the original image by a generative model exploiting the GAN inversion method. We also employ a privacy filter and a knowledge base to erase private information and replace it with natural features in the knowledge base. The simulation results indicate that our proposed method achieves comparable quality of received images while significantly reducing communication costs compared to the existing methods.
Drone-based Volume Estimation in Indoor Environments
Nov 15, 2022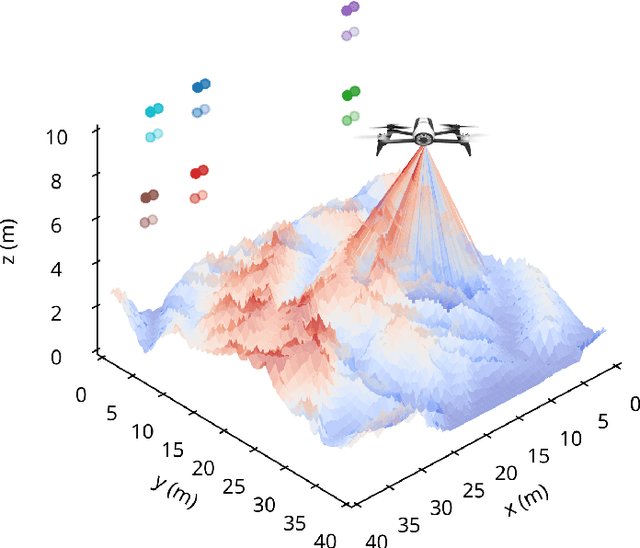
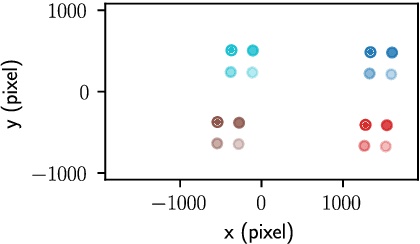
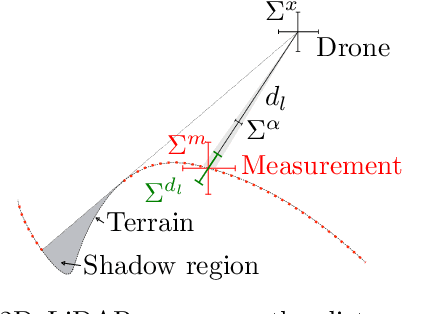
Volume estimation in large indoor spaces is an important challenge in robotic inspection of industrial warehouses. We propose an approach for volume estimation for autonomous systems using visual features for indoor localization and surface reconstruction from 2D-LiDAR measurements. A Gaussian Process-based model incorporates information collected from measurements given statistical prior information about the terrain, from which the volume estimate is computed. Our algorithm finds feasible trajectories which minimize the uncertainty of the volume estimate. We show results in simulation for the surface reconstruction and volume estimate of topographic data.
Modeling Global Distribution for Federated Learning with Label Distribution Skew
Dec 17, 2022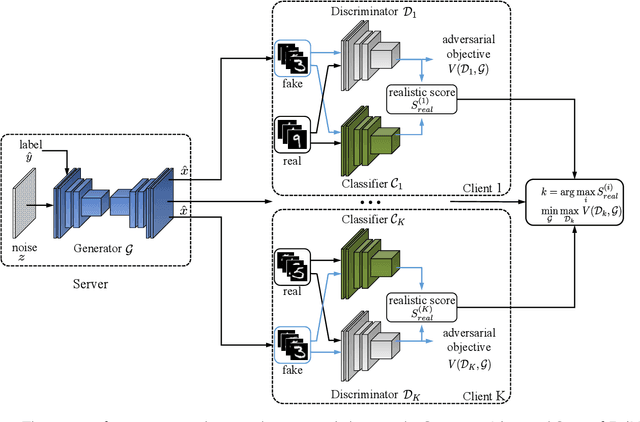
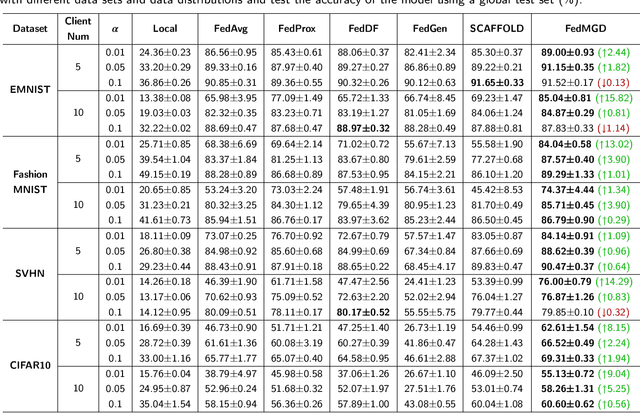
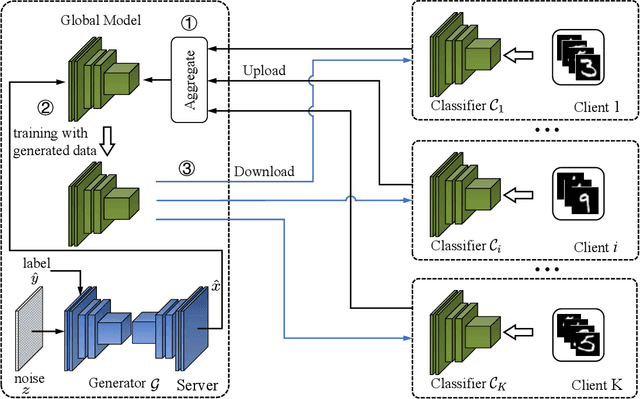
Federated learning achieves joint training of deep models by connecting decentralized data sources, which can significantly mitigate the risk of privacy leakage. However, in a more general case, the distributions of labels among clients are different, called ``label distribution skew''. Directly applying conventional federated learning without consideration of label distribution skew issue significantly hurts the performance of the global model. To this end, we propose a novel federated learning method, named FedMGD, to alleviate the performance degradation caused by the label distribution skew issue. It introduces a global Generative Adversarial Network to model the global data distribution without access to local datasets, so the global model can be trained using the global information of data distribution without privacy leakage. The experimental results demonstrate that our proposed method significantly outperforms the state-of-the-art on several public benchmarks. Code is available at \url{https://github.com/Sheng-T/FedMGD}.
Measuring the Mixing of Contextual Information in the Transformer
Mar 08, 2022
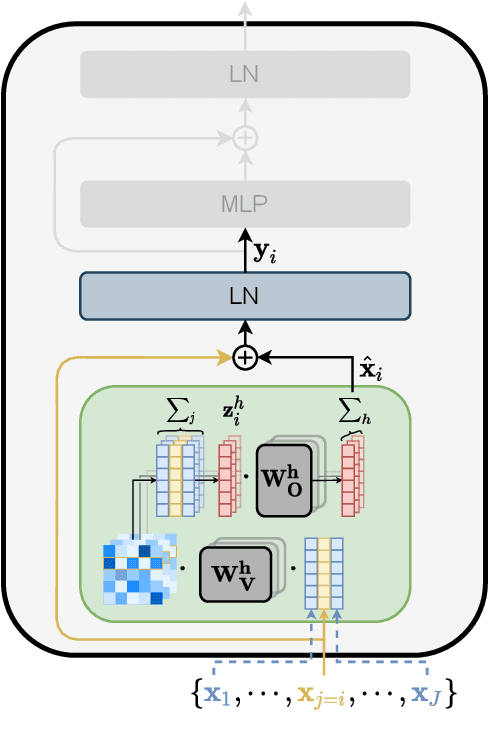
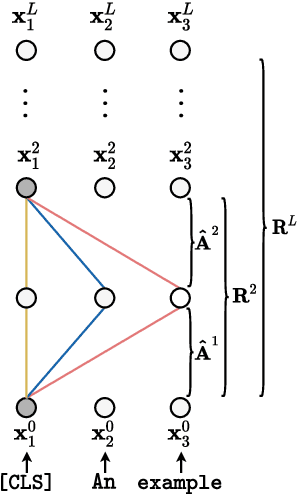

The Transformer architecture aggregates input information through the self-attention mechanism, but there is no clear understanding of how this information is mixed across the entire model. Additionally, recent works have demonstrated that attention weights alone are not enough to describe the flow of information. In this paper, we consider the whole attention block --multi-head attention, residual connection, and layer normalization-- and define a metric to measure token-to-token interactions within each layer, considering the characteristics of the representation space. Then, we aggregate layer-wise interpretations to provide input attribution scores for model predictions. Experimentally, we show that our method, ALTI (Aggregation of Layer-wise Token-to-token Interactions), provides faithful explanations and outperforms similar aggregation methods.
Word Order Matters when you Increase Masking
Nov 08, 2022

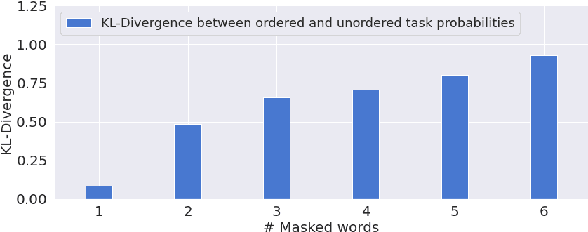

Word order, an essential property of natural languages, is injected in Transformer-based neural language models using position encoding. However, recent experiments have shown that explicit position encoding is not always useful, since some models without such feature managed to achieve state-of-the art performance on some tasks. To understand better this phenomenon, we examine the effect of removing position encodings on the pre-training objective itself (i.e., masked language modelling), to test whether models can reconstruct position information from co-occurrences alone. We do so by controlling the amount of masked tokens in the input sentence, as a proxy to affect the importance of position information for the task. We find that the necessity of position information increases with the amount of masking, and that masked language models without position encodings are not able to reconstruct this information on the task. These findings point towards a direct relationship between the amount of masking and the ability of Transformers to capture order-sensitive aspects of language using position encoding.
A Light Touch Approach to Teaching Transformers Multi-view Geometry
Nov 28, 2022
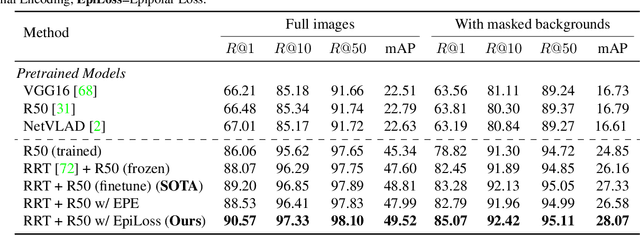
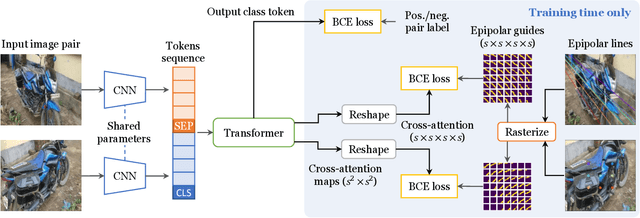
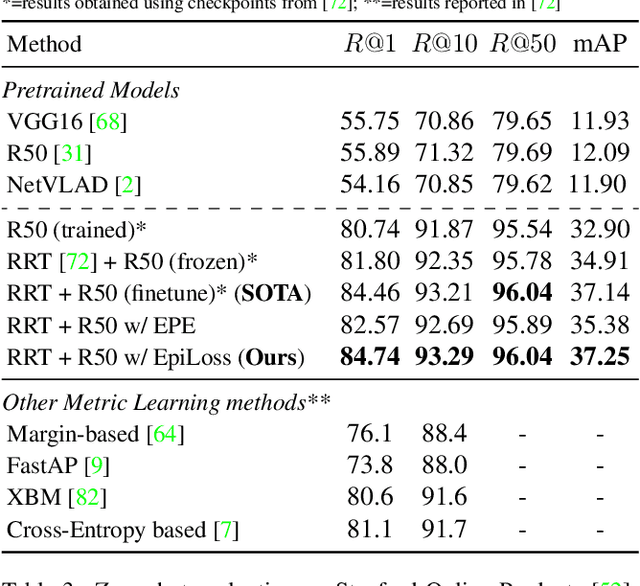
Transformers are powerful visual learners, in large part due to their conspicuous lack of manually-specified priors. This flexibility can be problematic in tasks that involve multiple-view geometry, due to the near-infinite possible variations in 3D shapes and viewpoints (requiring flexibility), and the precise nature of projective geometry (obeying rigid laws). To resolve this conundrum, we propose a "light touch" approach, guiding visual Transformers to learn multiple-view geometry but allowing them to break free when needed. We achieve this by using epipolar lines to guide the Transformer's cross-attention maps, penalizing attention values outside the epipolar lines and encouraging higher attention along these lines since they contain geometrically plausible matches. Unlike previous methods, our proposal does not require any camera pose information at test-time. We focus on pose-invariant object instance retrieval, where standard Transformer networks struggle, due to the large differences in viewpoint between query and retrieved images. Experimentally, our method outperforms state-of-the-art approaches at object retrieval, without needing pose information at test-time.