 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Interdisciplinary Discovery of Nanomaterials Based on Convolutional Neural Networks
Dec 06, 2022
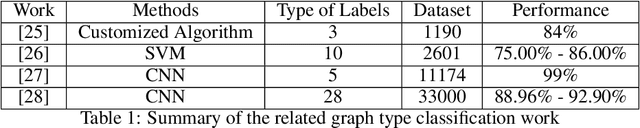
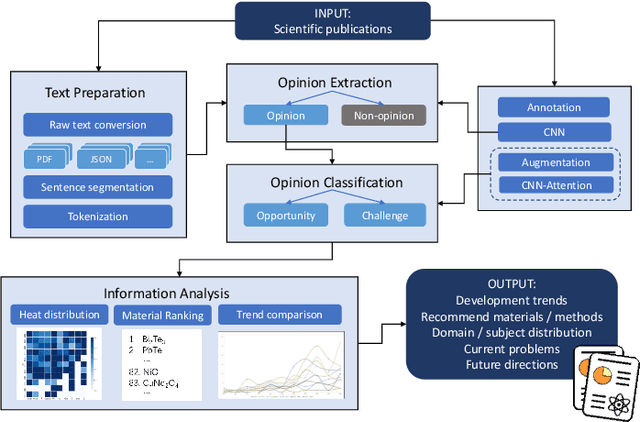
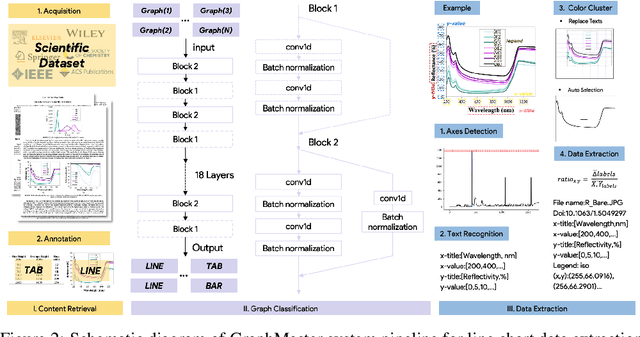
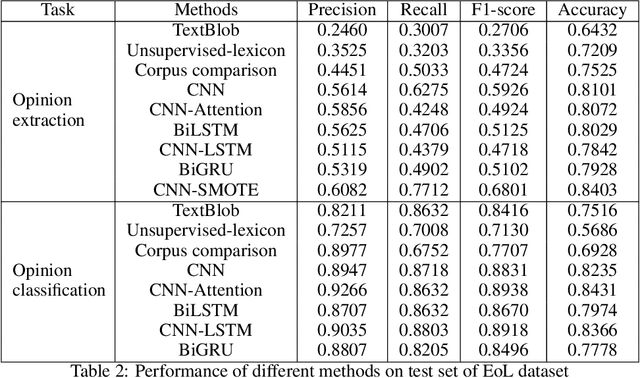
The material science literature contains up-to-date and comprehensive scientific knowledge of materials. However, their content is unstructured and diverse, resulting in a significant gap in providing sufficient information for material design and synthesis. To this end, we used natural language processing (NLP) and computer vision (CV) techniques based on convolutional neural networks (CNN) to discover valuable experimental-based information about nanomaterials and synthesis methods in energy-material-related publications. Our first system, TextMaster, extracts opinions from texts and classifies them into challenges and opportunities, achieving 94% and 92% accuracy, respectively. Our second system, GraphMaster, realizes data extraction of tables and figures from publications with 98.3\% classification accuracy and 4.3% data extraction mean square error. Our results show that these systems could assess the suitability of materials for a certain application by evaluation of synthesis insights and case analysis with detailed references. This work offers a fresh perspective on mining knowledge from scientific literature, providing a wide swatch to accelerate nanomaterial research through CNN.
McNet: Fuse Multiple Cues for Multichannel Speech Enhancement
Nov 16, 2022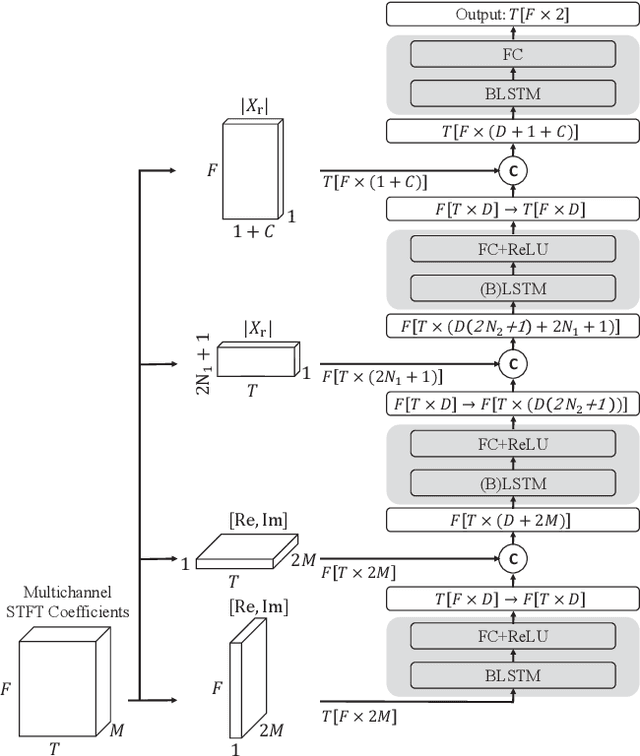
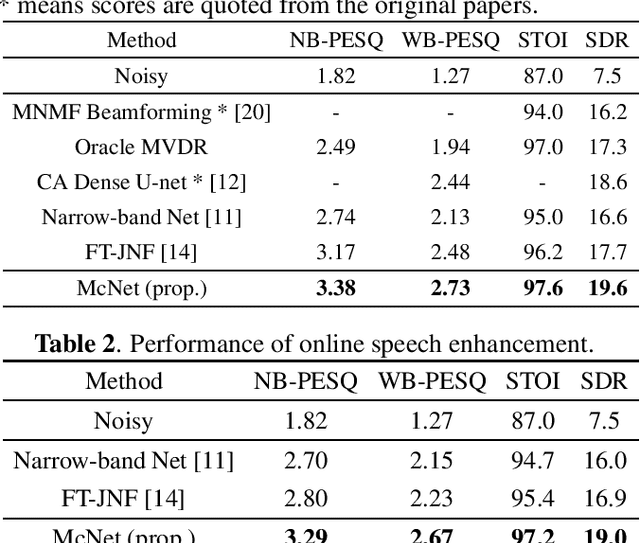
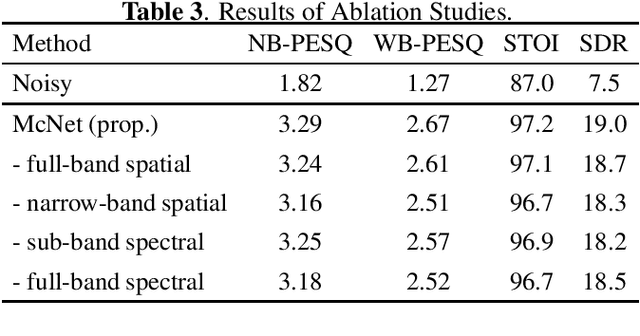
In multichannel speech enhancement, both spectral and spatial information are vital for discriminating between speech and noise. How to fully exploit these two types of information and their temporal dynamics remains an interesting research problem. As a solution to this problem, this paper proposes a multi-cue fusion network named McNet, which cascades four modules to respectively exploit the full-band spatial, narrow-band spatial, sub-band spectral, and full-band spectral information. Experiments show that each module in the proposed network has its unique contribution and, as a whole, notably outperforms other state-of-the-art methods.
PrivacyProber: Assessment and Detection of Soft-Biometric Privacy-Enhancing Techniques
Nov 16, 2022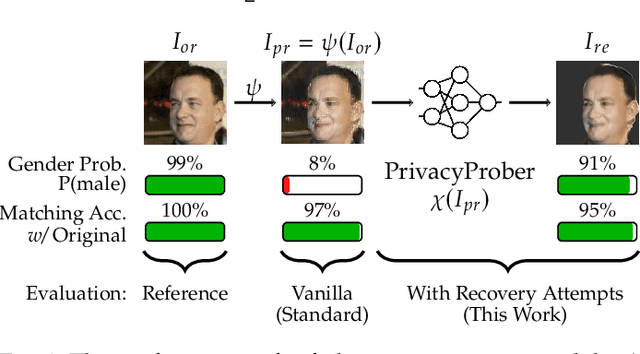

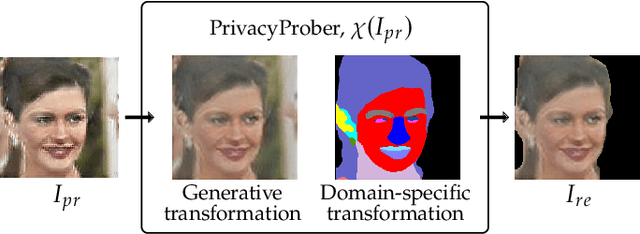
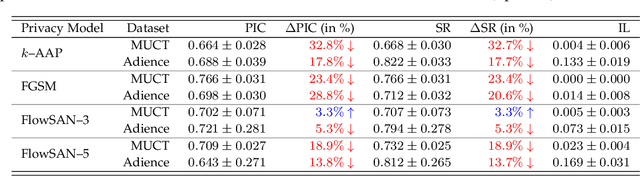
Soft-biometric privacy-enhancing techniques represent machine learning methods that aim to: (i) mitigate privacy concerns associated with face recognition technology by suppressing selected soft-biometric attributes in facial images (e.g., gender, age, ethnicity) and (ii) make unsolicited extraction of sensitive personal information infeasible. Because such techniques are increasingly used in real-world applications, it is imperative to understand to what extent the privacy enhancement can be inverted and how much attribute information can be recovered from privacy-enhanced images. While these aspects are critical, they have not been investigated in the literature. We, therefore, study the robustness of several state-of-the-art soft-biometric privacy-enhancing techniques to attribute recovery attempts. We propose PrivacyProber, a high-level framework for restoring soft-biometric information from privacy-enhanced facial images, and apply it for attribute recovery in comprehensive experiments on three public face datasets, i.e., LFW, MUCT and Adience. Our experiments show that the proposed framework is able to restore a considerable amount of suppressed information, regardless of the privacy-enhancing technique used, but also that there are significant differences between the considered privacy models. These results point to the need for novel mechanisms that can improve the robustness of existing privacy-enhancing techniques and secure them against potential adversaries trying to restore suppressed information.
Supermodular f-divergences and bounds on lossy compression and generalization error with mutual f-information
Jun 27, 2022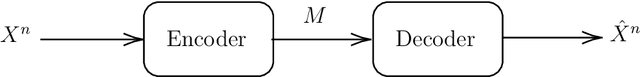
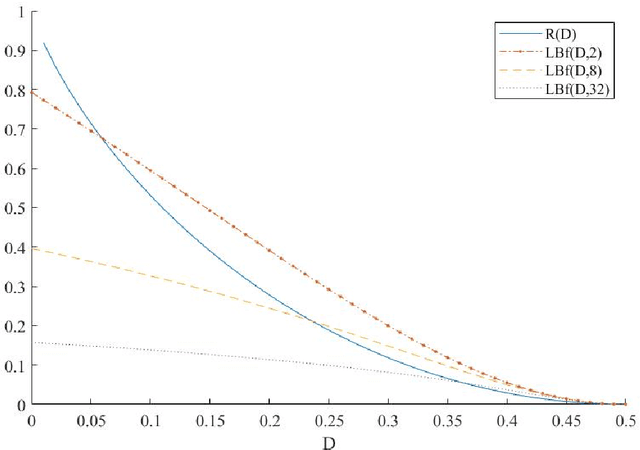
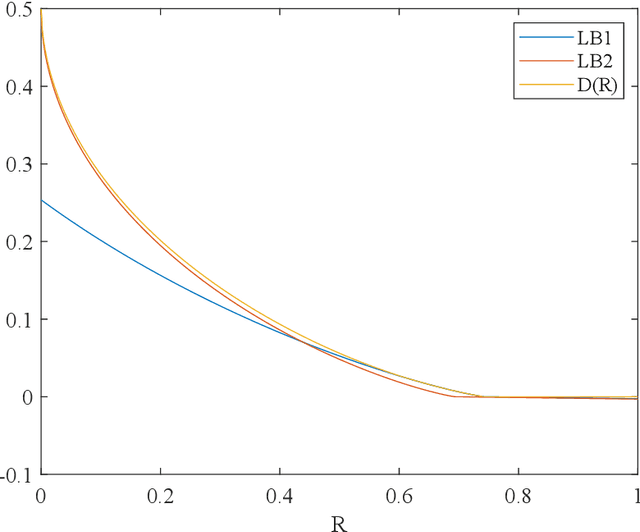
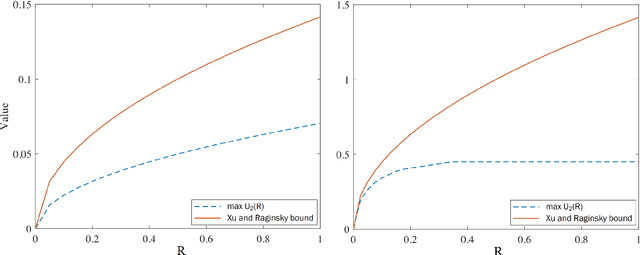
In this paper, we introduce super-modular $\mf$-divergences and provide three applications for them: (i) we introduce Sanov's upper bound on the tail probability of sum of independent random variables based on super-modular $\mf$-divergence and show that our generalized Sanov's bound strictly improves over ordinary one, (ii) we consider the lossy compression problem which studies the set of achievable rates for a given distortion and code length. We extend the rate-distortion function using mutual $\mf$-information and provide new and strictly better bounds on achievable rates in the finite blocklength regime using super-modular $\mf$-divergences, and (iii) we provide a connection between the generalization error of algorithms with bounded input/output mutual $\mf$-information and a generalized rate-distortion problem. This connection allows us to bound the generalization error of learning algorithms using lower bounds on the rate-distortion function. Our bound is based on a new lower bound on the rate-distortion function that (for some examples) strictly improves over previously best-known bounds. Moreover, super-modular $\mf$-divergences are utilized to reduce the dimension of the problem and obtain single-letter bounds.
Single-Image Super-Resolution Reconstruction based on the Differences of Neighboring Pixels
Dec 28, 2022The deep learning technique was used to increase the performance of single image super-resolution (SISR). However, most existing CNN-based SISR approaches primarily focus on establishing deeper or larger networks to extract more significant high-level features. Usually, the pixel-level loss between the target high-resolution image and the estimated image is used, but the neighbor relations between pixels in the image are seldom used. On the other hand, according to observations, a pixel's neighbor relationship contains rich information about the spatial structure, local context, and structural knowledge. Based on this fact, in this paper, we utilize pixel's neighbor relationships in a different perspective, and we propose the differences of neighboring pixels to regularize the CNN by constructing a graph from the estimated image and the ground-truth image. The proposed method outperforms the state-of-the-art methods in terms of quantitative and qualitative evaluation of the benchmark datasets. Keywords: Super-resolution, Convolutional Neural Networks, Deep Learning
Learning Representations for Masked Facial Recovery
Dec 28, 2022The pandemic of these very recent years has led to a dramatic increase in people wearing protective masks in public venues. This poses obvious challenges to the pervasive use of face recognition technology that now is suffering a decline in performance. One way to address the problem is to revert to face recovery methods as a preprocessing step. Current approaches to face reconstruction and manipulation leverage the ability to model the face manifold, but tend to be generic. We introduce a method that is specific for the recovery of the face image from an image of the same individual wearing a mask. We do so by designing a specialized GAN inversion method, based on an appropriate set of losses for learning an unmasking encoder. With extensive experiments, we show that the approach is effective at unmasking face images. In addition, we also show that the identity information is preserved sufficiently well to improve face verification performance based on several face recognition benchmark datasets.
Deep Riemannian Networks for EEG Decoding
Dec 21, 2022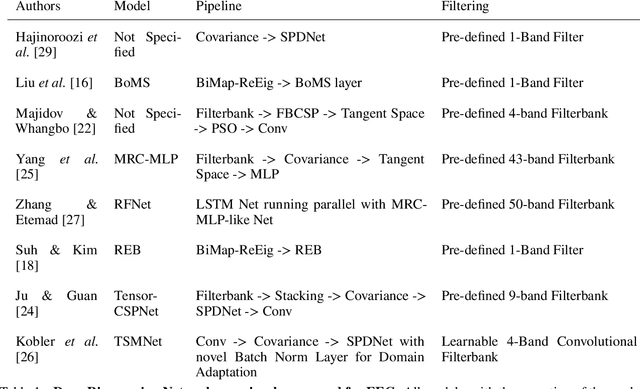
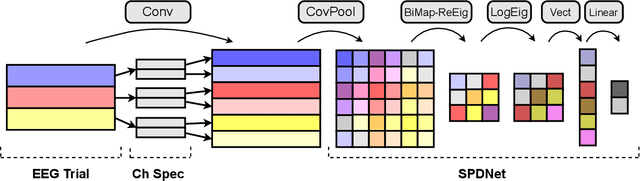
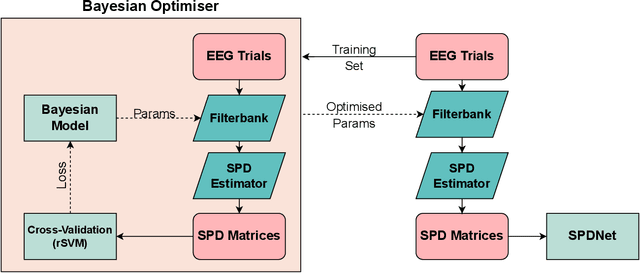

State-of-the-art performance in electroencephalography (EEG) decoding tasks is currently often achieved with either Deep-Learning or Riemannian-Geometry-based decoders. Recently, there is growing interest in Deep Riemannian Networks (DRNs) possibly combining the advantages of both previous classes of methods. However, there are still a range of topics where additional insight is needed to pave the way for a more widespread application of DRNs in EEG. These include architecture design questions such as network size and end-to-end ability as well as model training questions. How these factors affect model performance has not been explored. Additionally, it is not clear how the data within these networks is transformed, and whether this would correlate with traditional EEG decoding. Our study aims to lay the groundwork in the area of these topics through the analysis of DRNs for EEG with a wide range of hyperparameters. Networks were tested on two public EEG datasets and compared with state-of-the-art ConvNets. Here we propose end-to-end EEG SPDNet (EE(G)-SPDNet), and we show that this wide, end-to-end DRN can outperform the ConvNets, and in doing so use physiologically plausible frequency regions. We also show that the end-to-end approach learns more complex filters than traditional band-pass filters targeting the classical alpha, beta, and gamma frequency bands of the EEG, and that performance can benefit from channel specific filtering approaches. Additionally, architectural analysis revealed areas for further improvement due to the possible loss of Riemannian specific information throughout the network. Our study thus shows how to design and train DRNs to infer task-related information from the raw EEG without the need of handcrafted filterbanks and highlights the potential of end-to-end DRNs such as EE(G)-SPDNet for high-performance EEG decoding.
GenSyn: A Multi-stage Framework for Generating Synthetic Microdata using Macro Data Sources
Dec 08, 2022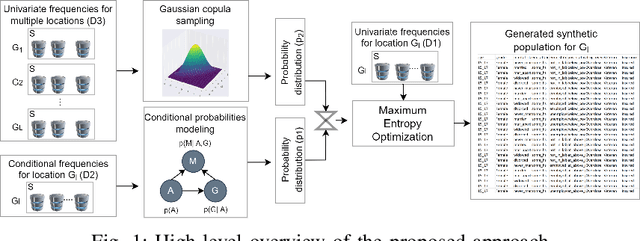
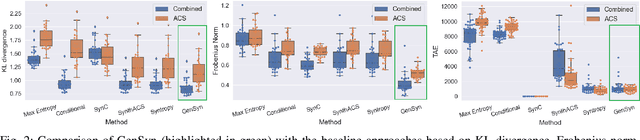
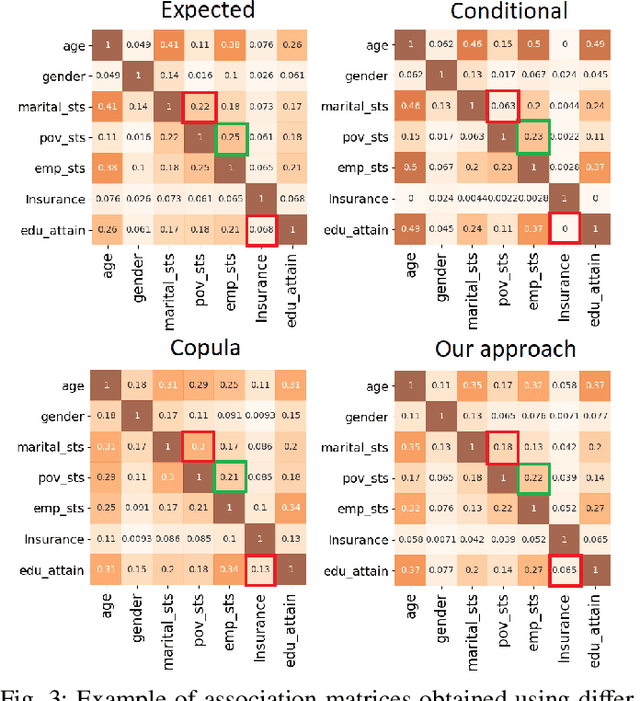
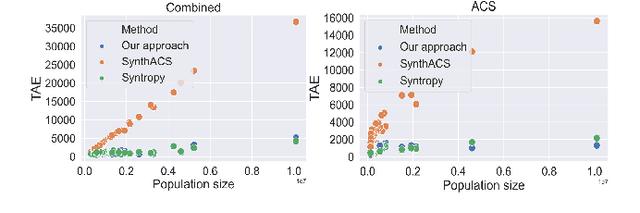
Individual-level data (microdata) that characterizes a population, is essential for studying many real-world problems. However, acquiring such data is not straightforward due to cost and privacy constraints, and access is often limited to aggregated data (macro data) sources. In this study, we examine synthetic data generation as a tool to extrapolate difficult-to-obtain high-resolution data by combining information from multiple easier-to-obtain lower-resolution data sources. In particular, we introduce a framework that uses a combination of univariate and multivariate frequency tables from a given target geographical location in combination with frequency tables from other auxiliary locations to generate synthetic microdata for individuals in the target location. Our method combines the estimation of a dependency graph and conditional probabilities from the target location with the use of a Gaussian copula to leverage the available information from the auxiliary locations. We perform extensive testing on two real-world datasets and demonstrate that our approach outperforms prior approaches in preserving the overall dependency structure of the data while also satisfying the constraints defined on the different variables.
RLSEP: Learning Label Ranks for Multi-label Classification
Dec 08, 2022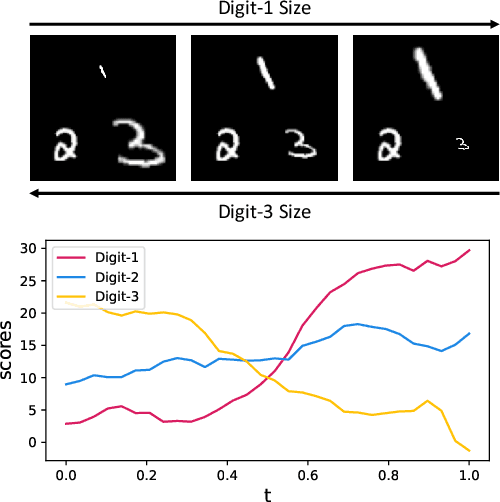
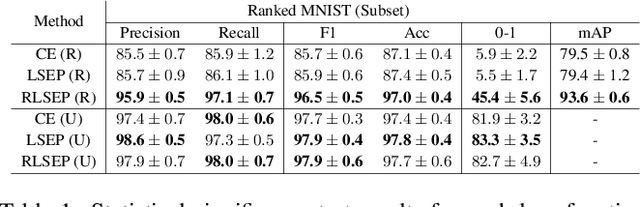

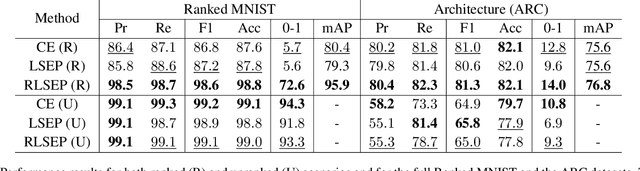
Multi-label ranking maps instances to a ranked set of predicted labels from multiple possible classes. The ranking approach for multi-label learning problems received attention for its success in multi-label classification, with one of the well-known approaches being pairwise label ranking. However, most existing methods assume that only partial information about the preference relation is known, which is inferred from the partition of labels into a positive and negative set, then treat labels with equal importance. In this paper, we focus on the unique challenge of ranking when the order of the true label set is provided. We propose a novel dedicated loss function to optimize models by incorporating penalties for incorrectly ranked pairs, and make use of the ranking information present in the input. Our method achieves the best reported performance measures on both synthetic and real world ranked datasets and shows improvements on overall ranking of labels. Our experimental results demonstrate that our approach is generalizable to a variety of multi-label classification and ranking tasks, while revealing a calibration towards a certain ranking ordering.
Algebraic Learning: Towards Interpretable Information Modeling
Mar 13, 2022
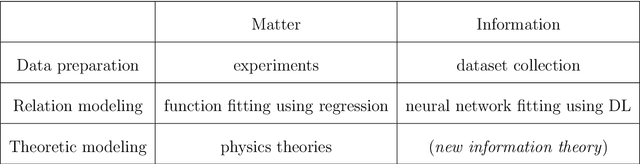
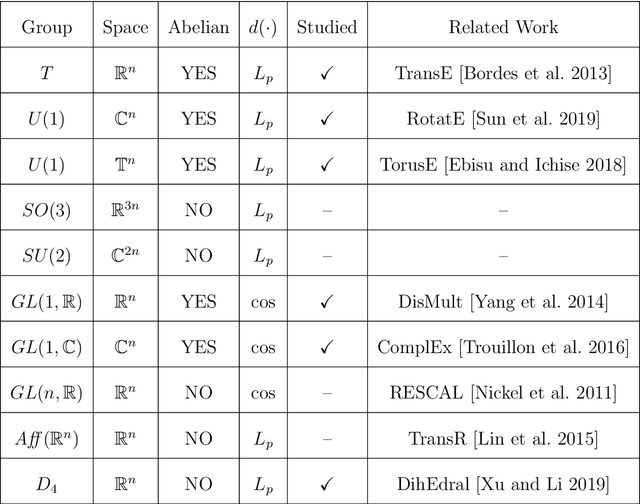
Along with the proliferation of digital data collected using sensor technologies and a boost of computing power, Deep Learning (DL) based approaches have drawn enormous attention in the past decade due to their impressive performance in extracting complex relations from raw data and representing valuable information. Meanwhile, though, rooted in its notorious black-box nature, the appreciation of DL has been highly debated due to the lack of interpretability. On the one hand, DL only utilizes statistical features contained in raw data while ignoring human knowledge of the underlying system, which results in both data inefficiency and trust issues; on the other hand, a trained DL model does not provide to researchers any extra insight about the underlying system beyond its output, which, however, is the essence of most fields of science, e.g. physics and economics. This thesis addresses the issue of interpretability in general information modeling and endeavors to ease the problem from two scopes. Firstly, a problem-oriented perspective is applied to incorporate knowledge into modeling practice, where interesting mathematical properties emerge naturally which cast constraints on modeling. Secondly, given a trained model, various methods could be applied to extract further insights about the underlying system. These two pathways are termed as guided model design and secondary measurements. Remarkably, a novel scheme emerges for the modeling practice in statistical learning: Algebraic Learning (AgLr). Instead of being restricted to the discussion of any specific model, AgLr starts from idiosyncrasies of a learning task itself and studies the structure of a legitimate model class. This novel scheme demonstrates the noteworthy value of abstract algebra for general AI, which has been overlooked in recent progress, and could shed further light on interpretable information modeling.