 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Curriculum Learning Meets Weakly Supervised Modality Correlation Learning
Dec 15, 2022
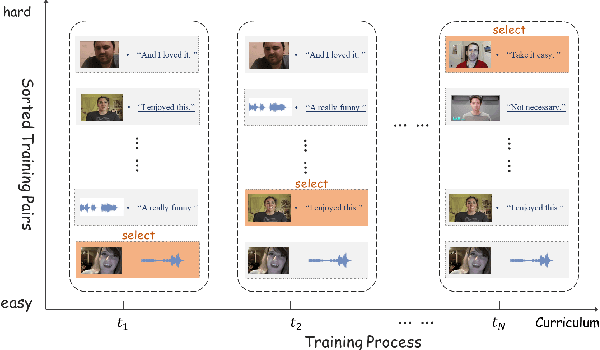
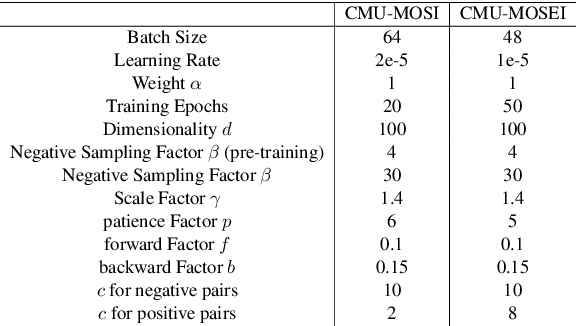
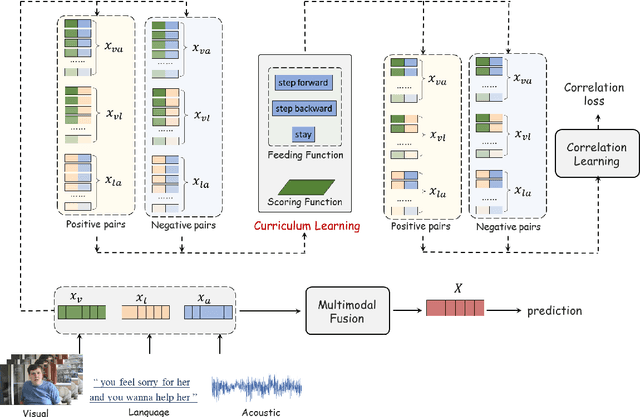
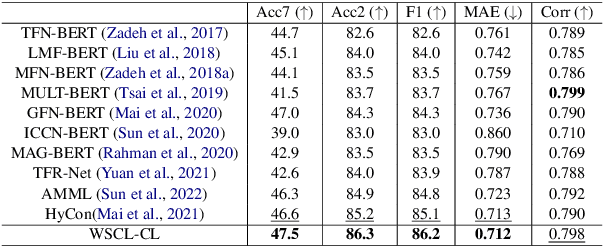
In the field of multimodal sentiment analysis (MSA), a few studies have leveraged the inherent modality correlation information stored in samples for self-supervised learning. However, they feed the training pairs in a random order without consideration of difficulty. Without human annotation, the generated training pairs of self-supervised learning often contain noise. If noisy or hard pairs are used for training at the easy stage, the model might be stuck in bad local optimum. In this paper, we inject curriculum learning into weakly supervised modality correlation learning. The weakly supervised correlation learning leverages the label information to generate scores for negative pairs to learn a more discriminative embedding space, where negative pairs are defined as two unimodal embeddings from different samples. To assist the correlation learning, we feed the training pairs to the model according to difficulty by the proposed curriculum learning, which consists of elaborately designed scoring and feeding functions. The scoring function computes the difficulty of pairs using pre-trained and current correlation predictors, where the pairs with large losses are defined as hard pairs. Notably, the hardest pairs are discarded in our algorithm, which are assumed as noisy pairs. Moreover, the feeding function takes the difference of correlation losses as feedback to determine the feeding actions (`stay', `step back', or `step forward'). The proposed method reaches state-of-the-art performance on MSA.
Using Navigational Information to Learn Visual Representations
Feb 10, 2022
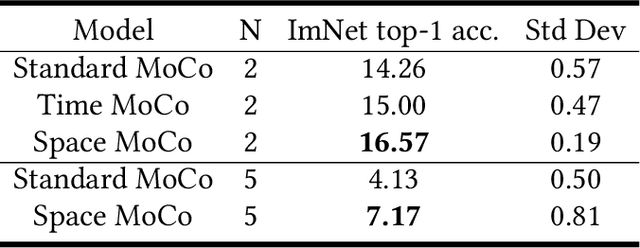
Children learn to build a visual representation of the world from unsupervised exploration and we hypothesize that a key part of this learning ability is the use of self-generated navigational information as a similarity label to drive a learning objective for self-supervised learning. The goal of this work is to exploit navigational information in a visual environment to provide performance in training that exceeds the state-of-the-art self-supervised training. Here, we show that using spatial and temporal information in the pretraining stage of contrastive learning can improve the performance of downstream classification relative to conventional contrastive learning approaches that use instance discrimination to discriminate between two alterations of the same image or two different images. We designed a pipeline to generate egocentric-vision images from a photorealistic ray-tracing environment (ThreeDWorld) and record relevant navigational information for each image. Modifying the Momentum Contrast (MoCo) model, we introduced spatial and temporal information to evaluate the similarity of two views in the pretraining stage instead of instance discrimination. This work reveals the effectiveness and efficiency of contextual information for improving representation learning. The work informs our understanding of the means by which children might learn to see the world without external supervision.
Few-shot Node Classification with Extremely Weak Supervision
Jan 06, 2023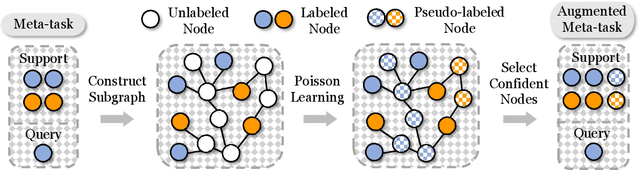
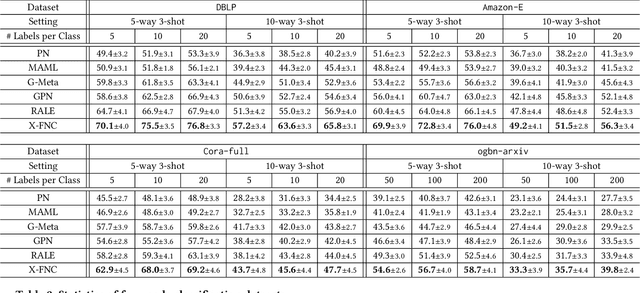
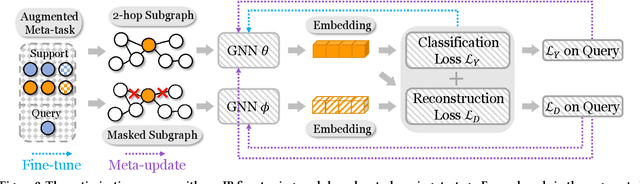
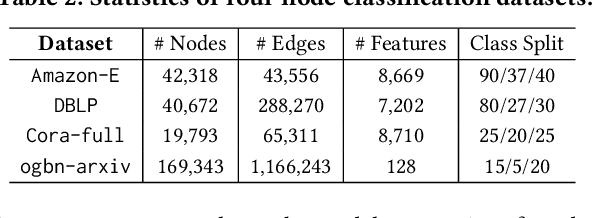
Few-shot node classification aims at classifying nodes with limited labeled nodes as references. Recent few-shot node classification methods typically learn from classes with abundant labeled nodes (i.e., meta-training classes) and then generalize to classes with limited labeled nodes (i.e., meta-test classes). Nevertheless, on real-world graphs, it is usually difficult to obtain abundant labeled nodes for many classes. In practice, each meta-training class can only consist of several labeled nodes, known as the extremely weak supervision problem. In few-shot node classification, with extremely limited labeled nodes for meta-training, the generalization gap between meta-training and meta-test will become larger and thus lead to suboptimal performance. To tackle this issue, we study a novel problem of few-shot node classification with extremely weak supervision and propose a principled framework X-FNC under the prevalent meta-learning framework. Specifically, our goal is to accumulate meta-knowledge across different meta-training tasks with extremely weak supervision and generalize such knowledge to meta-test tasks. To address the challenges resulting from extremely scarce labeled nodes, we propose two essential modules to obtain pseudo-labeled nodes as extra references and effectively learn from extremely limited supervision information. We further conduct extensive experiments on four node classification datasets with extremely weak supervision to validate the superiority of our framework compared to the state-of-the-art baselines.
Attention-LSTM for Multivariate Traffic State Prediction on Rural Roads
Jan 06, 2023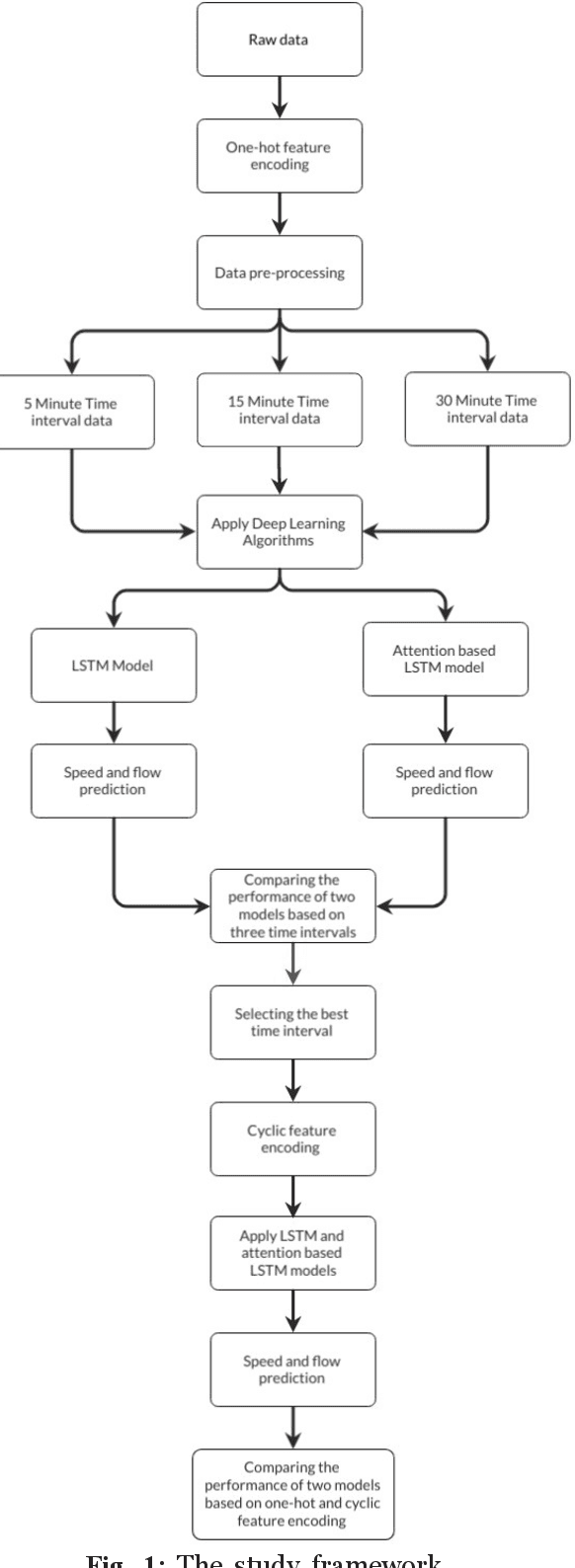
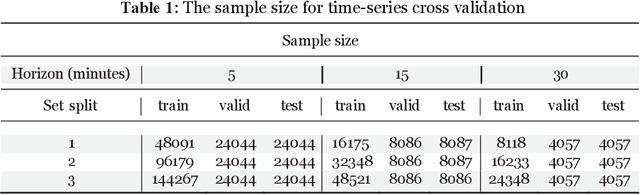
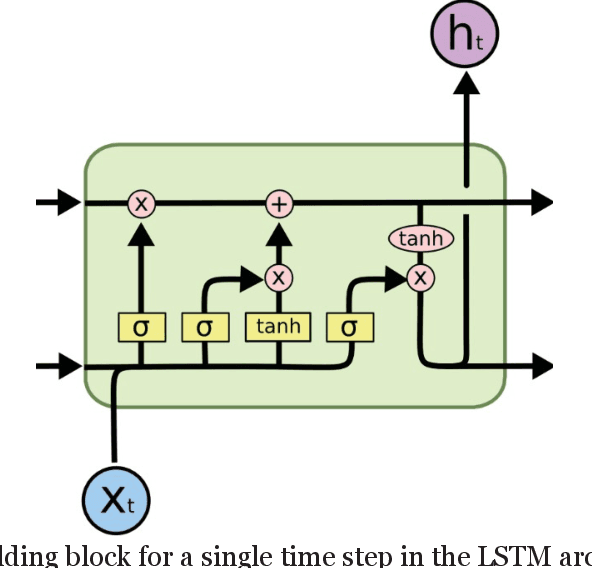
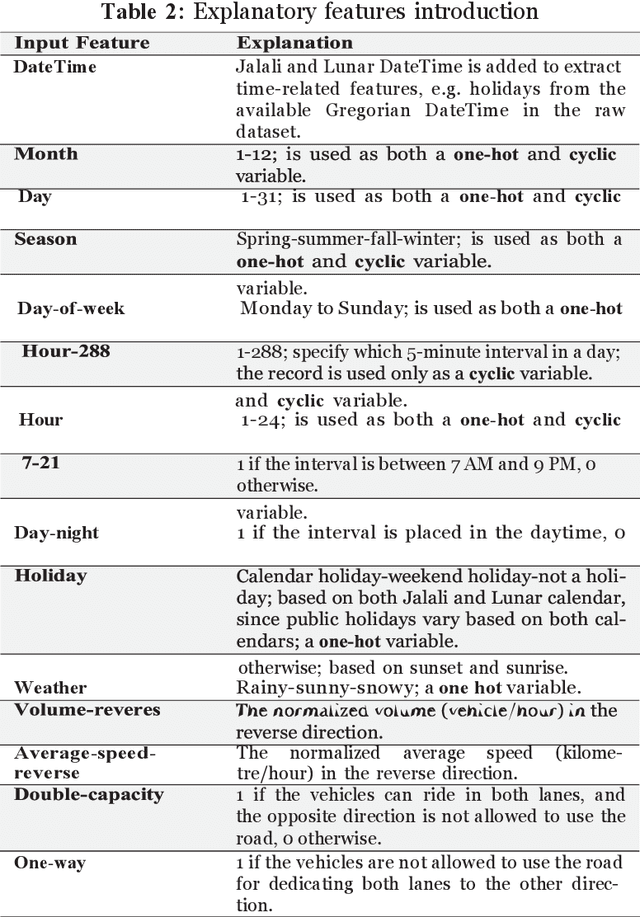
Accurate traffic volume and speed prediction have a wide range of applications in transportation. It can result in useful and timely information for both travellers and transportation decision-makers. In this study, an Attention based Long Sort-Term Memory model (A-LSTM) is proposed to simultaneously predict traffic volume and speed in a critical rural road segmentation which connects Tehran to Chalus, the most tourist destination city in Iran. Moreover, this study compares the results of the A-LSTM model with the Long Short-Term Memory (LSTM) model. Both models show acceptable performance in predicting speed and flow. However, the A-LSTM model outperforms the LSTM in 5 and 15-minute intervals. In contrast, there is no meaningful difference between the two models for the 30-minute time interval. By comparing the performance of the models based on different time horizons, the 15-minute horizon model outperforms the others by reaching the lowest Mean Square Error (MSE) loss of 0.0032, followed by the 30 and 5-minutes horizons with 0.004 and 0.0051, respectively. In addition, this study compares the results of the models based on two transformations of temporal categorical input variables, one-hot or cyclic, for the 15-minute time interval. The results demonstrate that both LSTM and A-LSTM with cyclic feature encoding outperform those with one-hot feature encoding.
Skeletal Video Anomaly Detection using Deep Learning: Survey, Challenges and Future Directions
Dec 31, 2022The existing methods for video anomaly detection mostly utilize videos containing identifiable facial and appearance-based features. The use of videos with identifiable faces raises privacy concerns, especially when used in a hospital or community-based setting. Appearance-based features can also be sensitive to pixel-based noise, straining the anomaly detection methods to model the changes in the background and making it difficult to focus on the actions of humans in the foreground. Structural information in the form of skeletons describing the human motion in the videos is privacy-protecting and can overcome some of the problems posed by appearance-based features. In this paper, we present a survey of privacy-protecting deep learning anomaly detection methods using skeletons extracted from videos. We present a novel taxonomy of algorithms based on the various learning approaches. We conclude that skeleton-based approaches for anomaly detection can be a plausible privacy-protecting alternative for video anomaly detection. Lastly, we identify major open research questions and provide guidelines to address them.
An end-to-end multi-scale network for action prediction in videos
Dec 31, 2022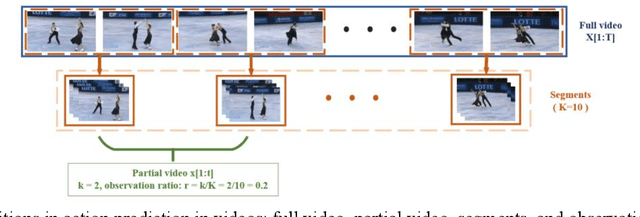
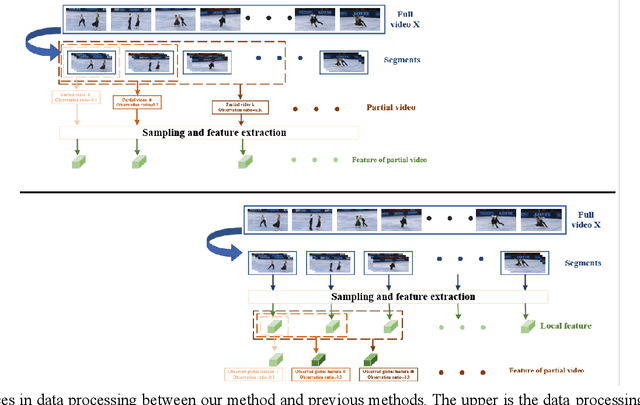
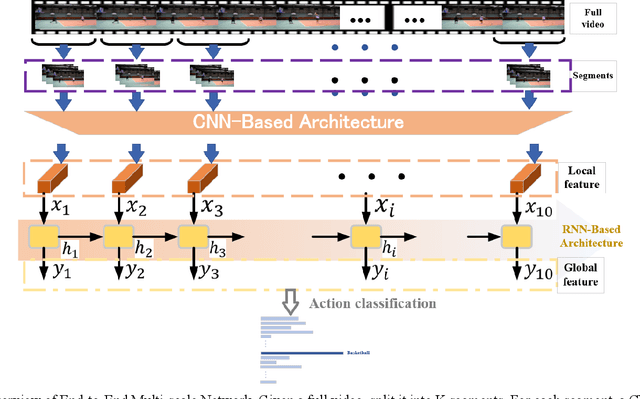
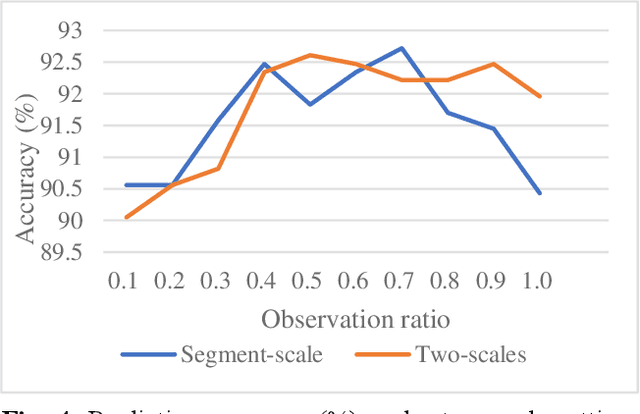
In this paper, we develop an efficient multi-scale network to predict action classes in partial videos in an end-to-end manner. Unlike most existing methods with offline feature generation, our method directly takes frames as input and further models motion evolution on two different temporal scales.Therefore, we solve the complexity problems of the two stages of modeling and the problem of insufficient temporal and spatial information of a single scale. Our proposed End-to-End MultiScale Network (E2EMSNet) is composed of two scales which are named segment scale and observed global scale. The segment scale leverages temporal difference over consecutive frames for finer motion patterns by supplying 2D convolutions. For observed global scale, a Long Short-Term Memory (LSTM) is incorporated to capture motion features of observed frames. Our model provides a simple and efficient modeling framework with a small computational cost. Our E2EMSNet is evaluated on three challenging datasets: BIT, HMDB51, and UCF101. The extensive experiments demonstrate the effectiveness of our method for action prediction in videos.
Voice Information Retrieval In Collaborative Information Seeking
Oct 05, 2021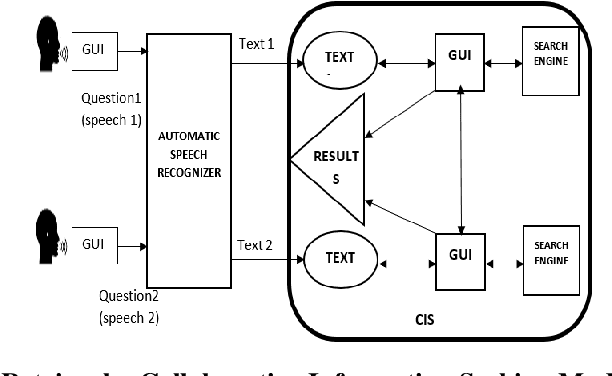
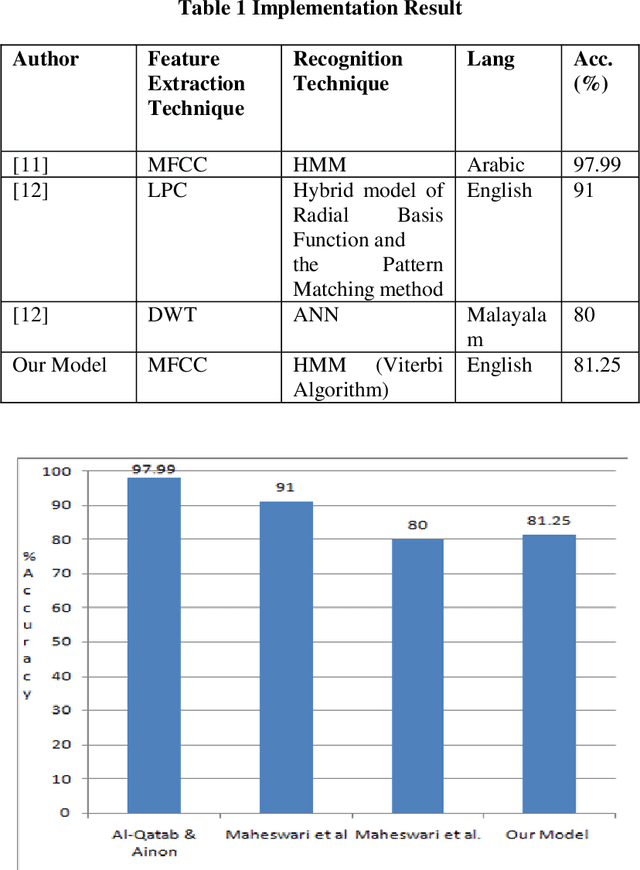
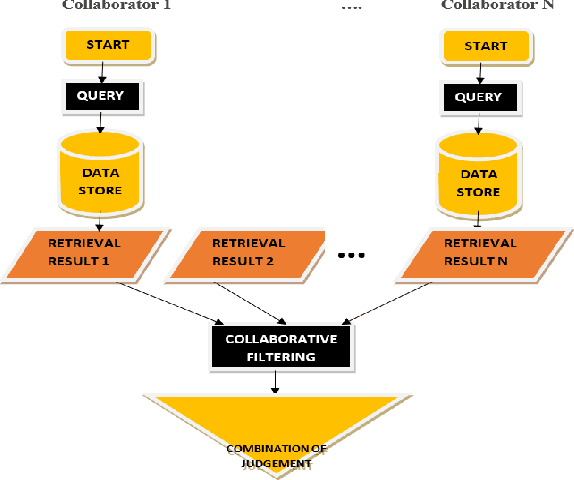
Voice information retrieval is a technique that provides Information Retrieval System with the capacity to transcribe spoken queries and use the text output for information search. CIS is a field of research that involves studying the situation, motivations, and methods for people working in a collaborative group for information seeking projects, as well as building a system for supporting such activities. Humans find it easier to communicate and express ideas via speech. Existing voice search like Google and other mainstream voice search does not support collaborative search. The spoken speeches passed through the ASR for feature extraction using MFCC and HMM, Viterbi algorithm precisely for pattern matching. The result of the ASR is then passed as input into CIS System, results is then filtered to have an aggregate result. The result from the simulation shows that our model was able to achieve 81.25% transcription accuracy.
On the Robustness of AlphaFold: A COVID-19 Case Study
Jan 12, 2023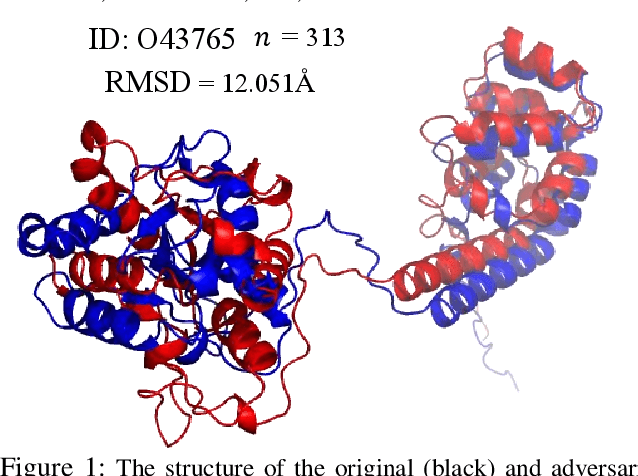
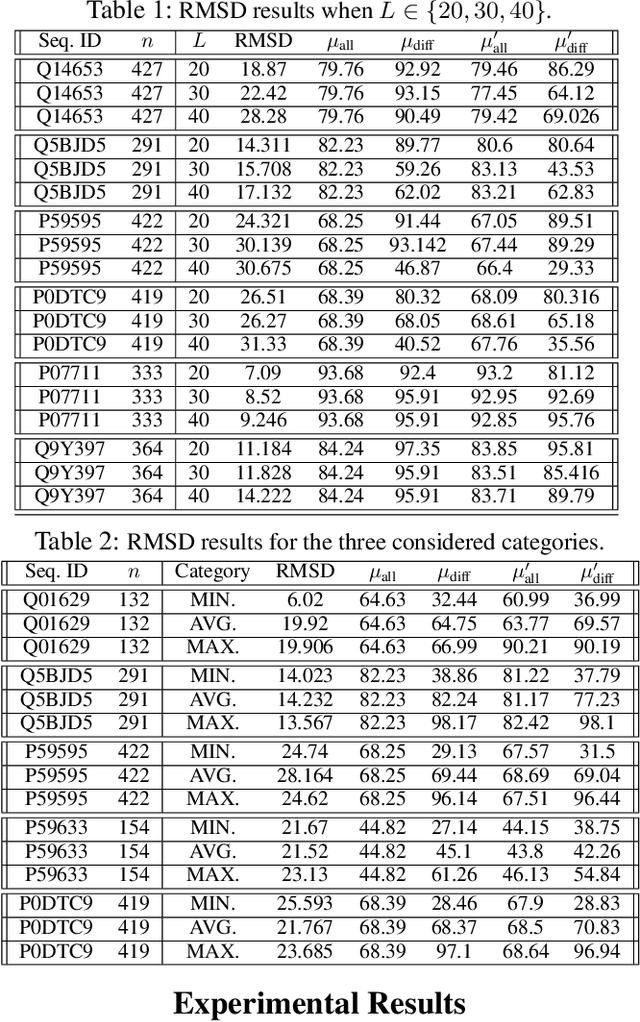
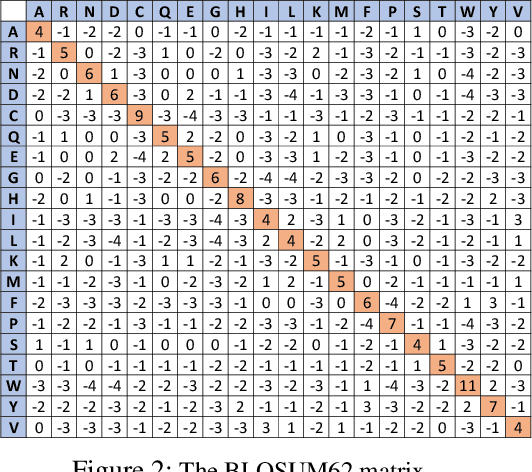

Protein folding neural networks (PFNNs) such as AlphaFold predict remarkably accurate structures of proteins compared to other approaches. However, the robustness of such networks has heretofore not been explored. This is particularly relevant given the broad social implications of such technologies and the fact that biologically small perturbations in the protein sequence do not generally lead to drastic changes in the protein structure. In this paper, we demonstrate that AlphaFold does not exhibit such robustness despite its high accuracy. This raises the challenge of detecting and quantifying the extent to which these predicted protein structures can be trusted. To measure the robustness of the predicted structures, we utilize (i) the root-mean-square deviation (RMSD) and (ii) the Global Distance Test (GDT) similarity measure between the predicted structure of the original sequence and the structure of its adversarially perturbed version. We prove that the problem of minimally perturbing protein sequences to fool protein folding neural networks is NP-complete. Based on the well-established BLOSUM62 sequence alignment scoring matrix, we generate adversarial protein sequences and show that the RMSD between the predicted protein structure and the structure of the original sequence are very large when the adversarial changes are bounded by (i) 20 units in the BLOSUM62 distance, and (ii) five residues (out of hundreds or thousands of residues) in the given protein sequence. In our experimental evaluation, we consider 111 COVID-19 proteins in the Universal Protein resource (UniProt), a central resource for protein data managed by the European Bioinformatics Institute, Swiss Institute of Bioinformatics, and the US Protein Information Resource. These result in an overall GDT similarity test score average of around 34%, demonstrating a substantial drop in the performance of AlphaFold.
Comparing Ordering Strategies For Process Discovery Using Synthesis Rules
Jan 04, 2023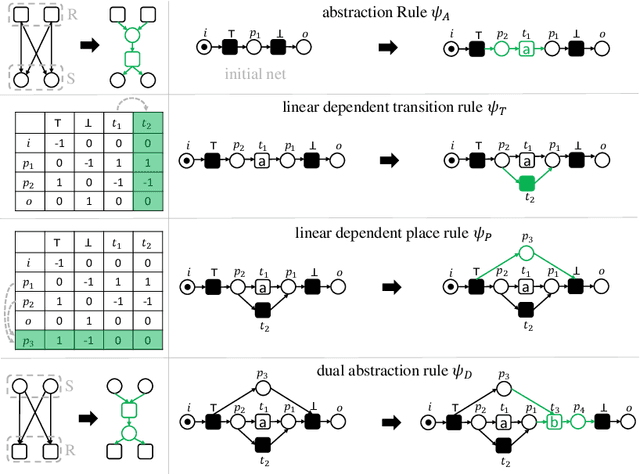
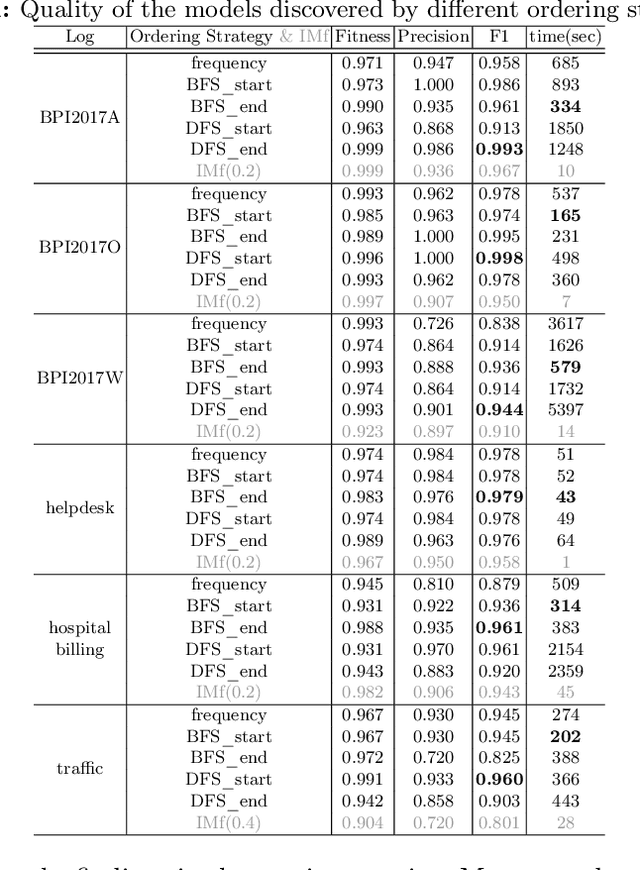

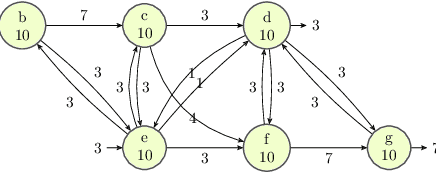
Process discovery aims to learn process models from observed behaviors, i.e., event logs, in the information systems.The discovered models serve as the starting point for process mining techniques that are used to address performance and compliance problems. Compared to the state-of-the-art Inductive Miner, the algorithm applying synthesis rules from the free-choice net theory discovers process models with more flexible (non-block) structures while ensuring the same desirable soundness and free-choiceness properties. Moreover, recent development in this line of work shows that the discovered models have compatible quality. Following the synthesis rules, the algorithm incrementally modifies an existing process model by adding the activities in the event log one at a time. As the applications of rules are highly dependent on the existing model structure, the model quality and computation time are significantly influenced by the order of adding activities. In this paper, we investigate the effect of different ordering strategies on the discovered models (w.r.t. fitness and precision) and the computation time using real-life event data. The results show that the proposed ordering strategy can improve the quality of the resulting process models while requiring less time compared to the ordering strategy solely based on the frequency of activities.
KIDS: kinematics-based (in)activity detection and segmentation in a sleep case study
Jan 04, 2023
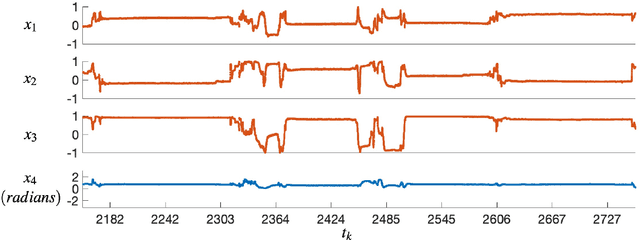
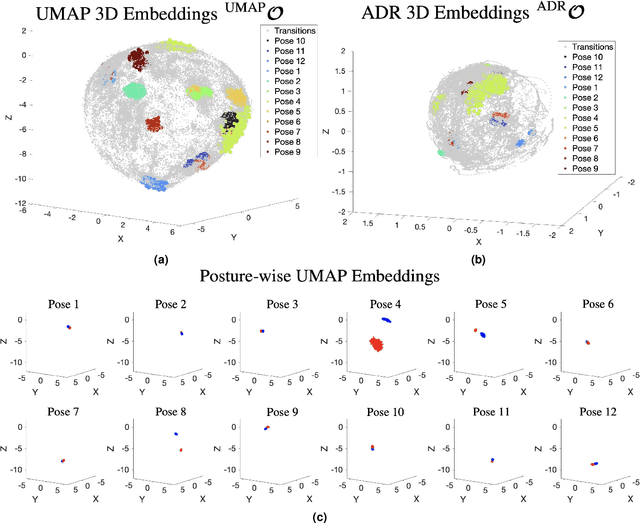
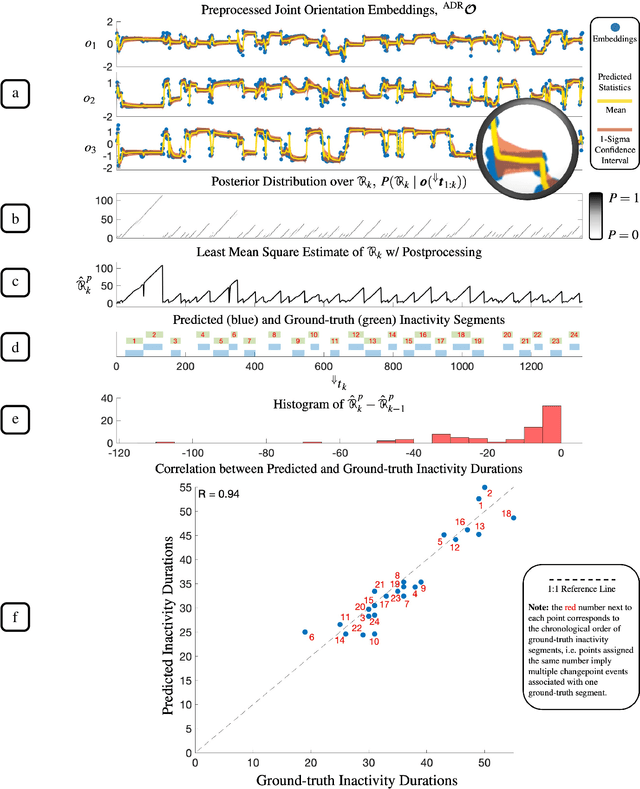
Sleep behaviour and in-bed movements contain rich information on the neurophysiological health of people, and have a direct link to the general well-being and quality of life. Standard clinical practices rely on polysomnography for sleep assessment; however, it is intrusive, performed in unfamiliar environments and requires trained personnel. Progress has been made on less invasive sensor technologies, such as actigraphy, but clinical validation raises concerns over their reliability and precision. Additionally, the field lacks a widely acceptable algorithm, with proposed approaches ranging from raw signal or feature thresholding to data-hungry classification models, many of which are unfamiliar to medical staff. This paper proposes an online Bayesian probabilistic framework for objective (in)activity detection and segmentation based on clinically meaningful joint kinematics, measured by a custom-made wearable sensor. Intuitive three-dimensional visualisations of kinematic timeseries were accomplished through dimension reduction based preprocessing, offering out-of-the-box framework explainability potentially useful for clinical monitoring and diagnosis. The proposed framework attained up to 99.2\% $F_1$-score and 0.96 Pearson's correlation coefficient in, respectively, the posture change detection and inactivity segmentation tasks. The work paves the way for a reliable home-based analysis of movements during sleep which would serve patient-centred longitudinal care plans.