 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
MECCH: Metapath Context Convolution-based Heterogeneous Graph Neural Networks
Nov 23, 2022


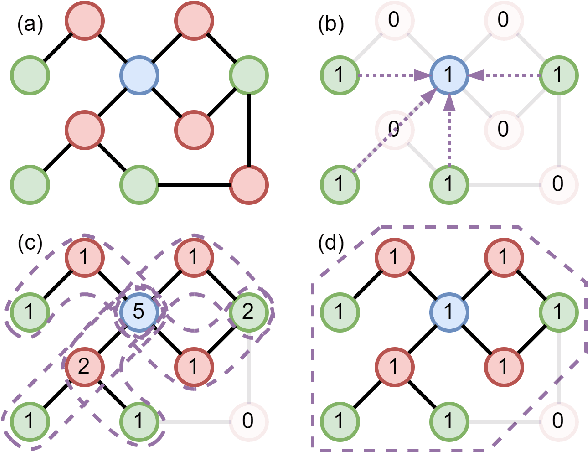

Heterogeneous graph neural networks (HGNNs) were proposed for representation learning on structural data with multiple types of nodes and edges. Researchers have developed metapath-based HGNNs to deal with the over-smoothing problem of relation-based HGNNs. However, existing metapath-based models suffer from either information loss or high computation costs. To address these problems, we design a new Metapath Context Convolution-based Heterogeneous Graph Neural Network (MECCH). Specifically, MECCH applies three novel components after feature preprocessing to extract comprehensive information from the input graph efficiently: (1) metapath context construction, (2) metapath context encoder, and (3) convolutional metapath fusion. Experiments on five real-world heterogeneous graph datasets for node classification and link prediction show that MECCH achieves superior prediction accuracy compared with state-of-the-art baselines with improved computational efficiency.
Search Behavior Prediction: A Hypergraph Perspective
Nov 29, 2022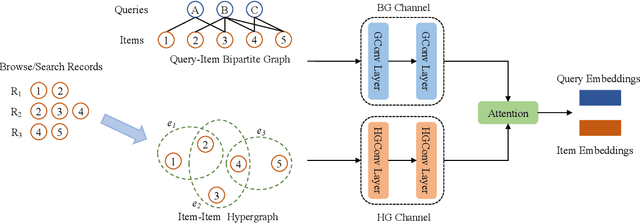
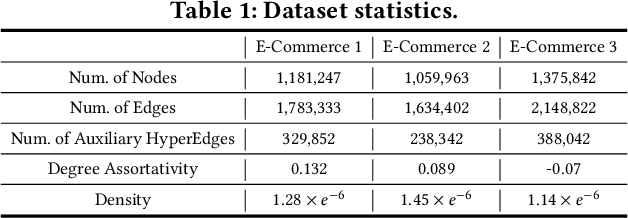
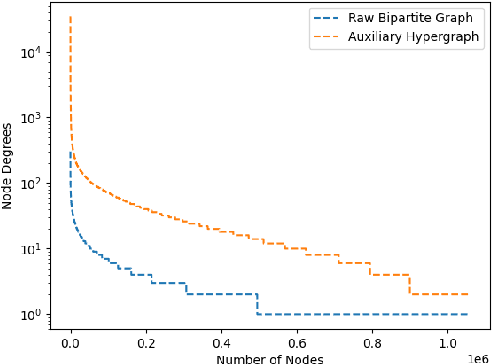
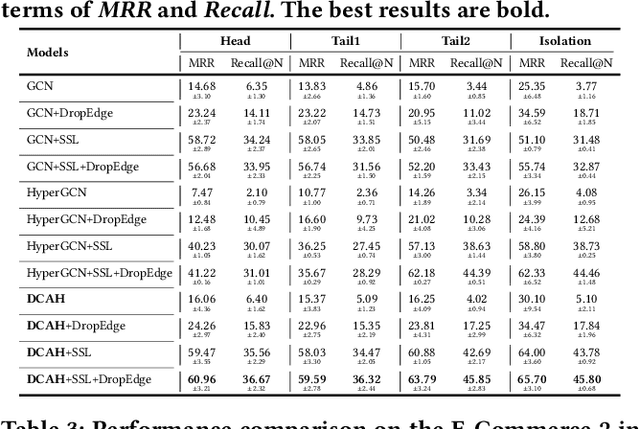
Although the bipartite shopping graphs are straightforward to model search behavior, they suffer from two challenges: 1) The majority of items are sporadically searched and hence have noisy/sparse query associations, leading to a \textit{long-tail} distribution. 2) Infrequent queries are more likely to link to popular items, leading to another hurdle known as \textit{disassortative mixing}. To address these two challenges, we go beyond the bipartite graph to take a hypergraph perspective, introducing a new paradigm that leverages \underline{auxiliary} information from anonymized customer engagement sessions to assist the \underline{main task} of query-item link prediction. This auxiliary information is available at web scale in the form of search logs. We treat all items appearing in the same customer session as a single hyperedge. The hypothesis is that items in a customer session are unified by a common shopping interest. With these hyperedges, we augment the original bipartite graph into a new \textit{hypergraph}. We develop a \textit{\textbf{D}ual-\textbf{C}hannel \textbf{A}ttention-Based \textbf{H}ypergraph Neural Network} (\textbf{DCAH}), which synergizes information from two potentially noisy sources (original query-item edges and item-item hyperedges). In this way, items on the tail are better connected due to the extra hyperedges, thereby enhancing their link prediction performance. We further integrate DCAH with self-supervised graph pre-training and/or DropEdge training, both of which effectively alleviate disassortative mixing. Extensive experiments on three proprietary E-Commerce datasets show that DCAH yields significant improvements of up to \textbf{24.6\% in mean reciprocal rank (MRR)} and \textbf{48.3\% in recall} compared to GNN-based baselines. Our source code is available at \url{https://github.com/amazon-science/dual-channel-hypergraph-neural-network}.
Adaptive Momentum-Based Policy Gradient with Second-Order Information
May 17, 2022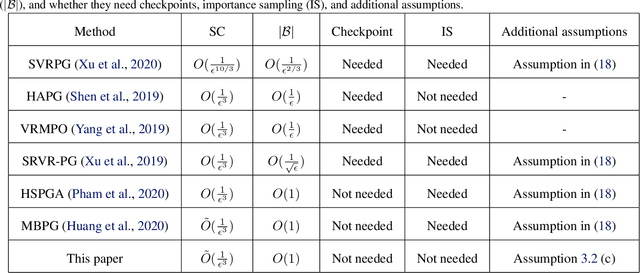
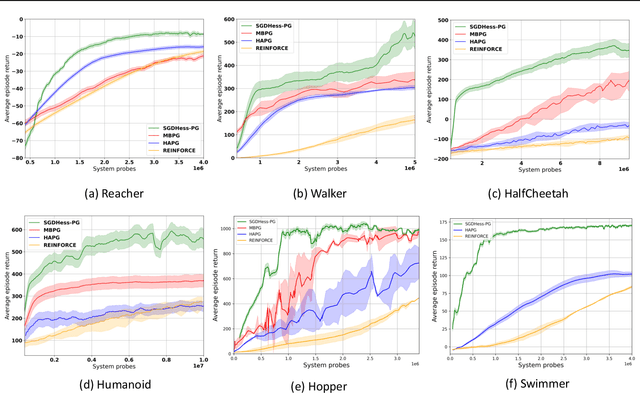
The variance reduced gradient estimators for policy gradient methods has been one of the main focus of research in the reinforcement learning in recent years as they allow acceleration of the estimation process. We propose a variance reduced policy gradient method, called SGDHess-PG, which incorporates second-order information into stochastic gradient descent (SGD) using momentum with an adaptive learning rate. SGDHess-PG algorithm can achieve $\epsilon$-approximate first-order stationary point with $\tilde{O}(\epsilon^{-3})$ number of trajectories, while using a batch size of $O(1)$ at each iteration. Unlike most previous work, our proposed algorithm does not require importance sampling techniques which can compromise the advantage of variance reduction process. Our extensive experimental results show the effectiveness of the proposed algorithm on various control tasks and its advantage over the state of the art in practice.
Timing-Based Backpropagation in Spiking Neural Networks Without Single-Spike Restrictions
Nov 29, 2022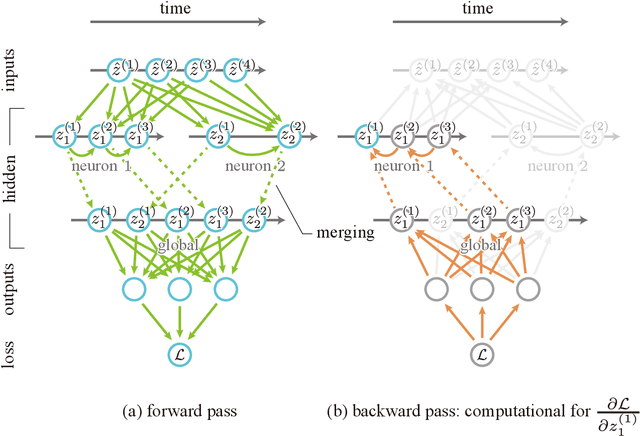
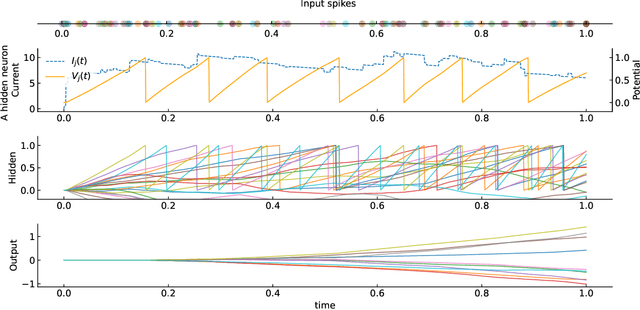
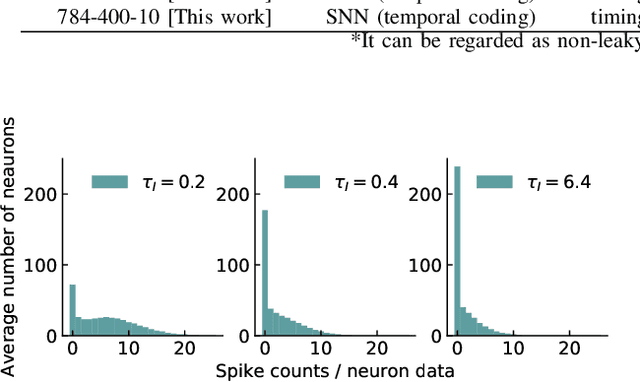
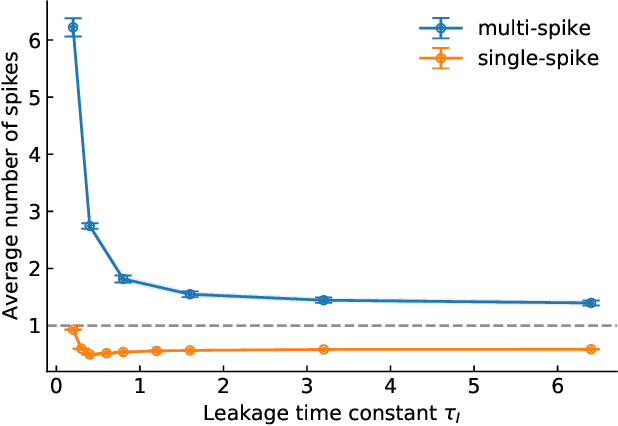
We propose a novel backpropagation algorithm for training spiking neural networks (SNNs) that encodes information in the relative multiple spike timing of individual neurons without single-spike restrictions. The proposed algorithm inherits the advantages of conventional timing-based methods in that it computes accurate gradients with respect to spike timing, which promotes ideal temporal coding. Unlike conventional methods where each neuron fires at most once, the proposed algorithm allows each neuron to fire multiple times. This extension naturally improves the computational capacity of SNNs. Our SNN model outperformed comparable SNN models and achieved as high accuracy as non-convolutional artificial neural networks. The spike count property of our networks was altered depending on the time constant of the postsynaptic current and the membrane potential. Moreover, we found that there existed the optimal time constant with the maximum test accuracy. That was not seen in conventional SNNs with single-spike restrictions on time-to-fast-spike (TTFS) coding. This result demonstrates the computational properties of SNNs that biologically encode information into the multi-spike timing of individual neurons. Our code would be publicly available.
Every Node Counts: Improving the Training of Graph Neural Networks on Node Classification
Nov 29, 2022
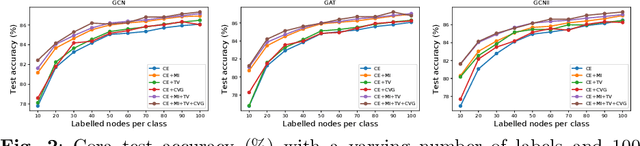

Graph Neural Networks (GNNs) are prominent in handling sparse and unstructured data efficiently and effectively. Specifically, GNNs were shown to be highly effective for node classification tasks, where labelled information is available for only a fraction of the nodes. Typically, the optimization process, through the objective function, considers only labelled nodes while ignoring the rest. In this paper, we propose novel objective terms for the training of GNNs for node classification, aiming to exploit all the available data and improve accuracy. Our first term seeks to maximize the mutual information between node and label features, considering both labelled and unlabelled nodes in the optimization process. Our second term promotes anisotropic smoothness in the prediction maps. Lastly, we propose a cross-validating gradients approach to enhance the learning from labelled data. Our proposed objectives are general and can be applied to various GNNs and require no architectural modifications. Extensive experiments demonstrate our approach using popular GNNs like GCN, GAT and GCNII, reading a consistent and significant accuracy improvement on 10 real-world node classification datasets.
Neural Subgraph Explorer: Reducing Noisy Information via Target-Oriented Syntax Graph Pruning
May 23, 2022
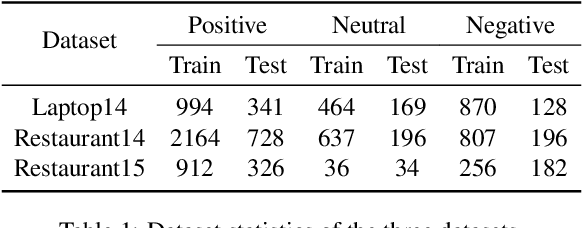
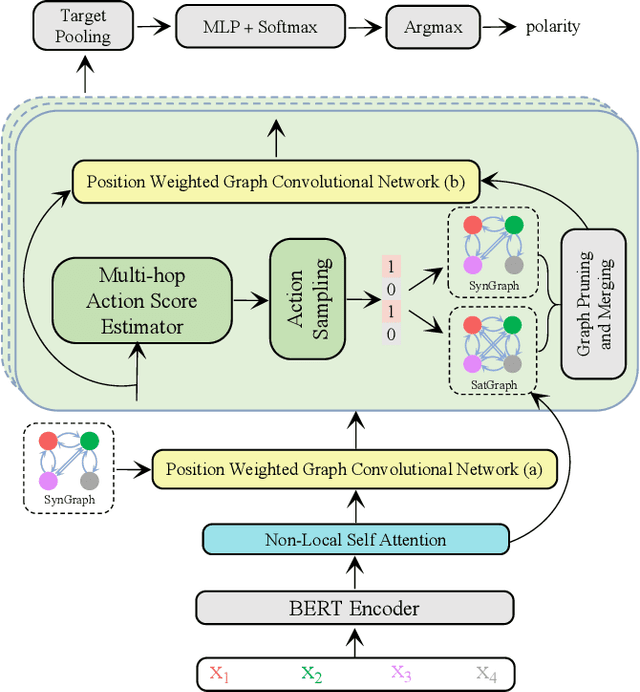
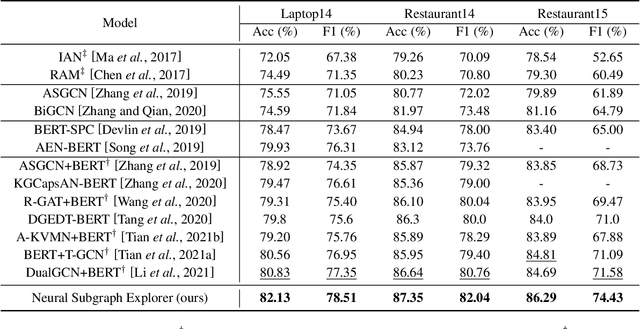
Recent years have witnessed the emerging success of leveraging syntax graphs for the target sentiment classification task. However, we discover that existing syntax-based models suffer from two issues: noisy information aggregation and loss of distant correlations. In this paper, we propose a novel model termed Neural Subgraph Explorer, which (1) reduces the noisy information via pruning target-irrelevant nodes on the syntax graph; (2) introduces beneficial first-order connections between the target and its related words into the obtained graph. Specifically, we design a multi-hop actions score estimator to evaluate the value of each word regarding the specific target. The discrete action sequence is sampled through Gumble-Softmax and then used for both of the syntax graph and the self-attention graph. To introduce the first-order connections between the target and its relevant words, the two pruned graphs are merged. Finally, graph convolution is conducted on the obtained unified graph to update the hidden states. And this process is stacked with multiple layers. To our knowledge, this is the first attempt of target-oriented syntax graph pruning in this task. Experimental results demonstrate the superiority of our model, which achieves new state-of-the-art performance.
Span Classification with Structured Information for Disfluency Detection in Spoken Utterances
Mar 30, 2022

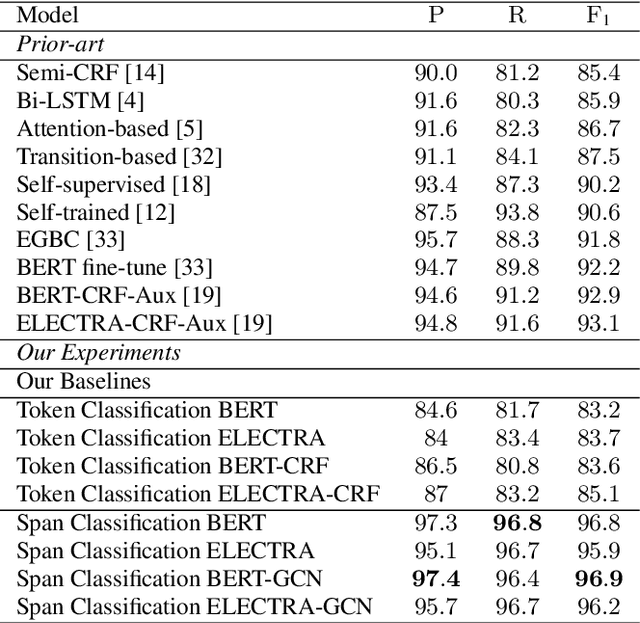
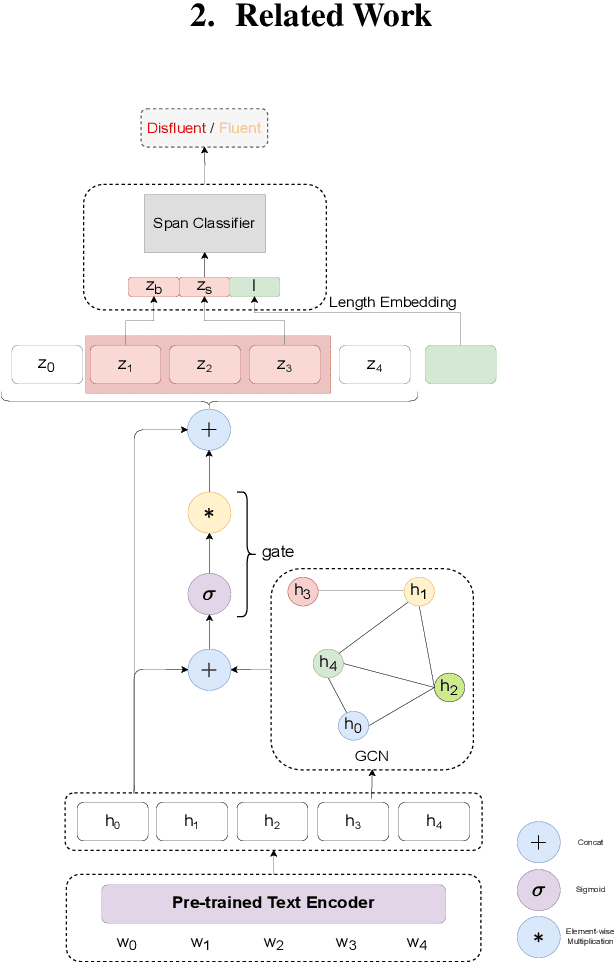
Existing approaches in disfluency detection focus on solving a token-level classification task for identifying and removing disfluencies in text. Moreover, most works focus on leveraging only contextual information captured by the linear sequences in text, thus ignoring the structured information in text which is efficiently captured by dependency trees. In this paper, building on the span classification paradigm of entity recognition, we propose a novel architecture for detecting disfluencies in transcripts from spoken utterances, incorporating both contextual information through transformers and long-distance structured information captured by dependency trees, through graph convolutional networks (GCNs). Experimental results show that our proposed model achieves state-of-the-art results on the widely used English Switchboard for disfluency detection and outperforms prior-art by a significant margin. We make all our codes publicly available on GitHub (https://github.com/Sreyan88/Disfluency-Detection-with-Span-Classification)
Not Just Plain Text! Fuel Document-Level Relation Extraction with Explicit Syntax Refinement and Subsentence Modeling
Nov 10, 2022

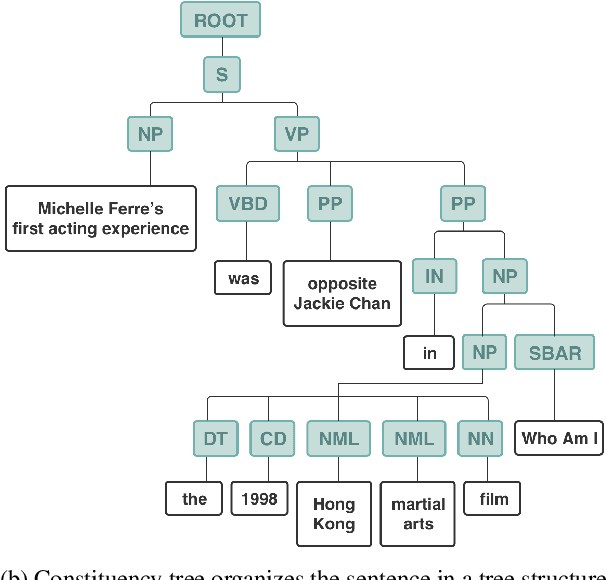
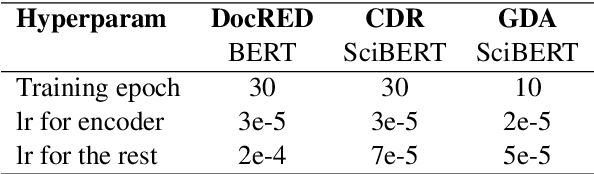
Document-level relation extraction (DocRE) aims to identify semantic labels among entities within a single document. One major challenge of DocRE is to dig decisive details regarding a specific entity pair from long text. However, in many cases, only a fraction of text carries required information, even in the manually labeled supporting evidence. To better capture and exploit instructive information, we propose a novel expLicit syntAx Refinement and Subsentence mOdeliNg based framework (LARSON). By introducing extra syntactic information, LARSON can model subsentences of arbitrary granularity and efficiently screen instructive ones. Moreover, we incorporate refined syntax into text representations which further improves the performance of LARSON. Experimental results on three benchmark datasets (DocRED, CDR, and GDA) demonstrate that LARSON significantly outperforms existing methods.
Wukong-Reader: Multi-modal Pre-training for Fine-grained Visual Document Understanding
Dec 19, 2022
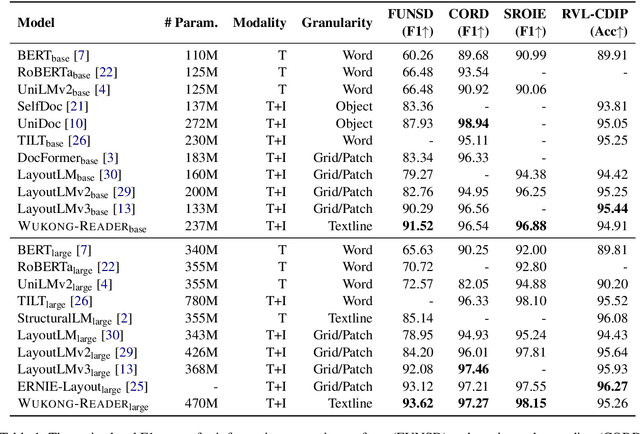
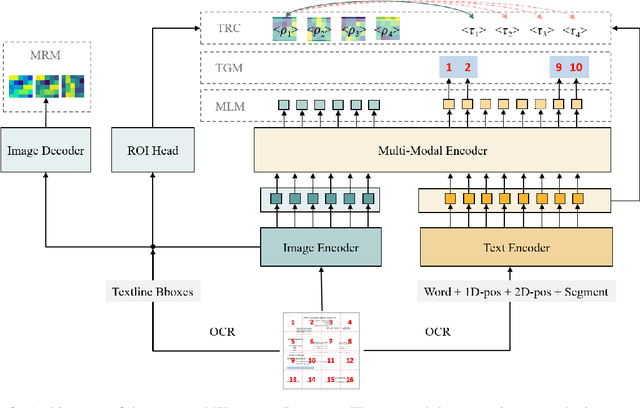
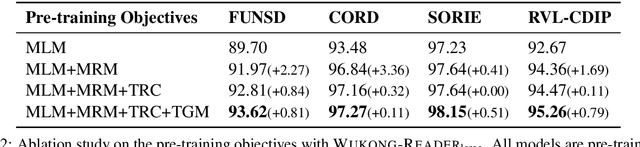
Unsupervised pre-training on millions of digital-born or scanned documents has shown promising advances in visual document understanding~(VDU). While various vision-language pre-training objectives are studied in existing solutions, the document textline, as an intrinsic granularity in VDU, has seldom been explored so far. A document textline usually contains words that are spatially and semantically correlated, which can be easily obtained from OCR engines. In this paper, we propose Wukong-Reader, trained with new pre-training objectives to leverage the structural knowledge nested in document textlines. We introduce textline-region contrastive learning to achieve fine-grained alignment between the visual regions and texts of document textlines. Furthermore, masked region modeling and textline-grid matching are also designed to enhance the visual and layout representations of textlines. Experiments show that our Wukong-Reader has superior performance on various VDU tasks such as information extraction. The fine-grained alignment over textlines also empowers Wukong-Reader with promising localization ability.
Speaking Style Conversion With Discrete Self-Supervised Units
Dec 19, 2022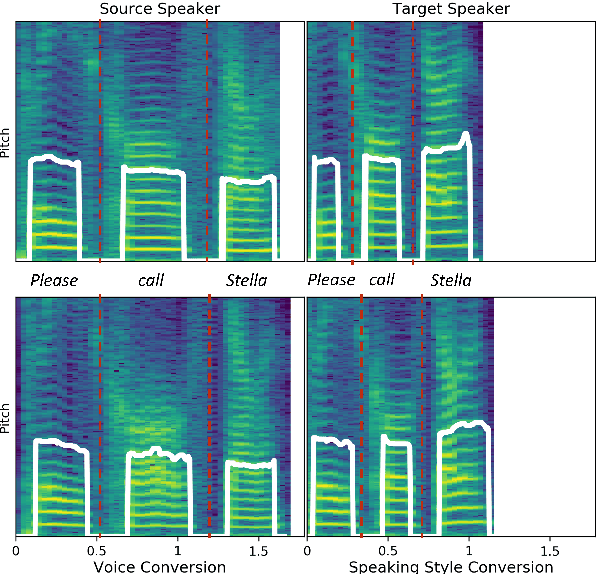
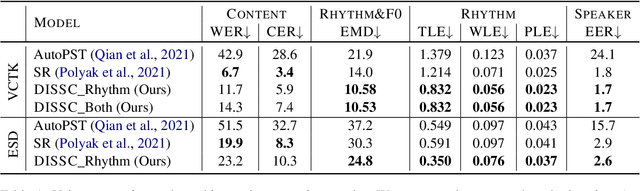
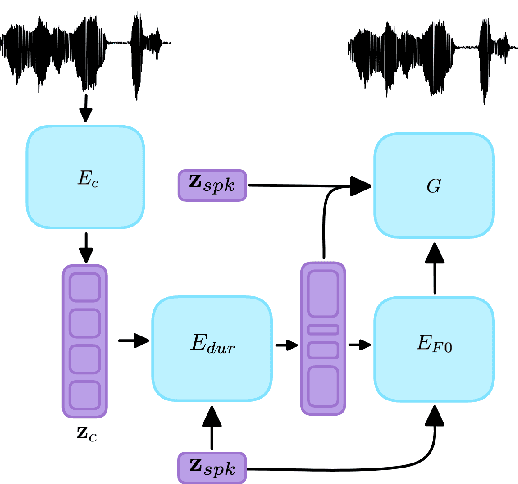
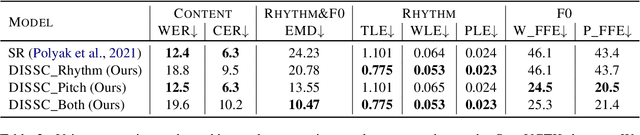
Voice Conversion (VC) is the task of making a spoken utterance by one speaker sound as if uttered by a different speaker, while keeping other aspects like content unchanged. Current VC methods, focus primarily on spectral features like timbre, while ignoring the unique speaking style of people which often impacts prosody. In this study, we introduce a method for converting not only the timbre, but also prosodic information (i.e., rhythm and pitch changes) to those of the target speaker. The proposed approach is based on a pretrained, self-supervised, model for encoding speech to discrete units, which make it simple, effective, and easy to optimise. We consider the many-to-many setting with no paired data. We introduce a suite of quantitative and qualitative evaluation metrics for this setup, and empirically demonstrate the proposed approach is significantly superior to the evaluated baselines. Code and samples can be found under https://pages.cs.huji.ac.il/adiyoss-lab/dissc/ .