 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Risk assessment and mitigation of e-scooter crashes with naturalistic driving data
Dec 24, 2022



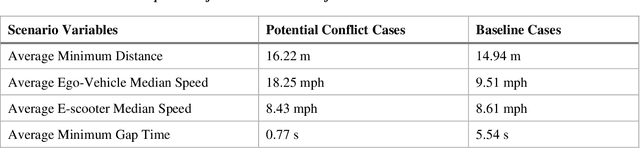
Recently, e-scooter-involved crashes have increased significantly but little information is available about the behaviors of on-road e-scooter riders. Most existing e-scooter crash research was based on retrospectively descriptive media reports, emergency room patient records, and crash reports. This paper presents a naturalistic driving study with a focus on e-scooter and vehicle encounters. The goal is to quantitatively measure the behaviors of e-scooter riders in different encounters to help facilitate crash scenario modeling, baseline behavior modeling, and the potential future development of in-vehicle mitigation algorithms. The data was collected using an instrumented vehicle and an e-scooter rider wearable system, respectively. A three-step data analysis process is developed. First, semi-automatic data labeling extracts e-scooter rider images and non-rider human images in similar environments to train an e-scooter-rider classifier. Then, a multi-step scene reconstruction pipeline generates vehicle and e-scooter trajectories in all encounters. The final step is to model e-scooter rider behaviors and e-scooter-vehicle encounter scenarios. A total of 500 vehicle to e-scooter interactions are analyzed. The variables pertaining to the same are also discussed in this paper.
Nothing Stands Alone: Relational Fake News Detection with Hypergraph Neural Networks
Dec 24, 2022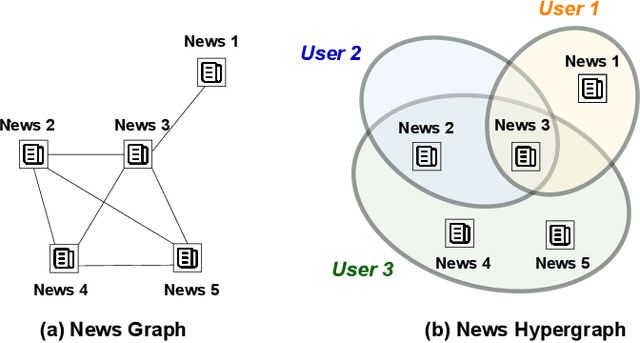
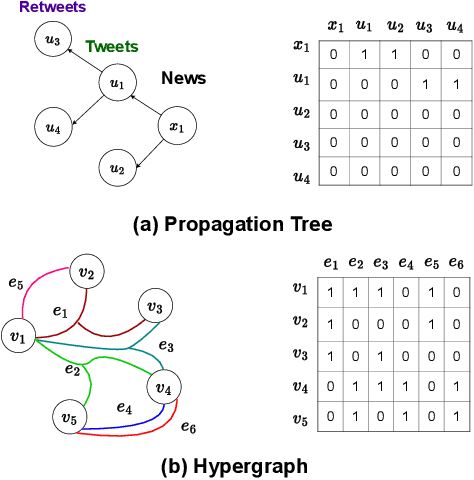
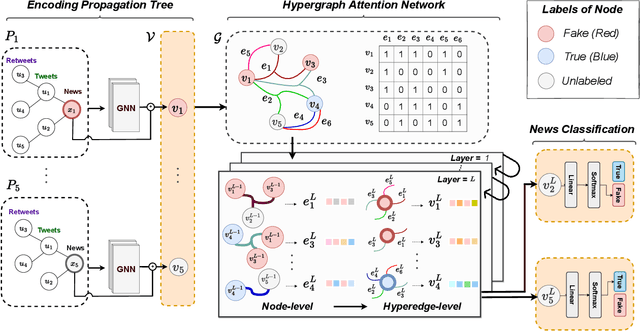
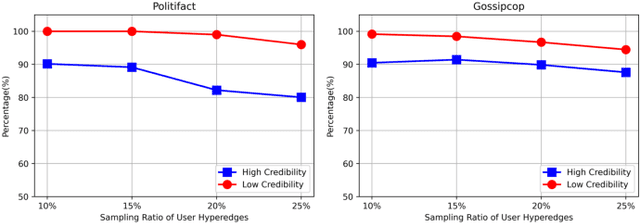
Nowadays, fake news easily propagates through online social networks and becomes a grand threat to individuals and society. Assessing the authenticity of news is challenging due to its elaborately fabricated contents, making it difficult to obtain large-scale annotations for fake news data. Due to such data scarcity issues, detecting fake news tends to fail and overfit in the supervised setting. Recently, graph neural networks (GNNs) have been adopted to leverage the richer relational information among both labeled and unlabeled instances. Despite their promising results, they are inherently focused on pairwise relations between news, which can limit the expressive power for capturing fake news that spreads in a group-level. For example, detecting fake news can be more effective when we better understand relations between news pieces shared among susceptible users. To address those issues, we propose to leverage a hypergraph to represent group-wise interaction among news, while focusing on important news relations with its dual-level attention mechanism. Experiments based on two benchmark datasets show that our approach yields remarkable performance and maintains the high performance even with a small subset of labeled news data.
Improving Fairness in Image Classification via Sketching
Oct 31, 2022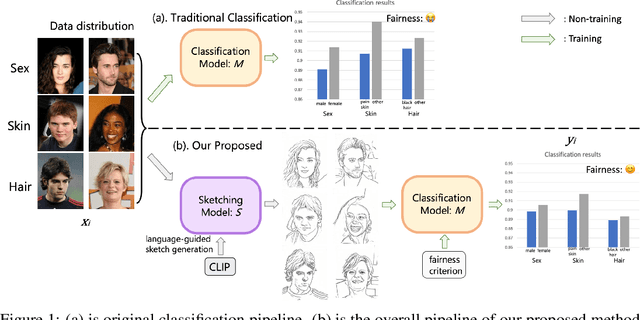


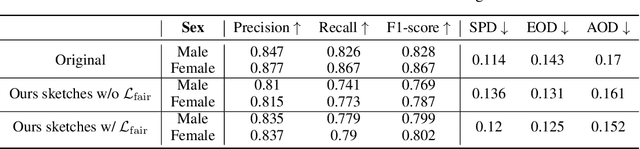
Fairness is a fundamental requirement for trustworthy and human-centered Artificial Intelligence (AI) system. However, deep neural networks (DNNs) tend to make unfair predictions when the training data are collected from different sub-populations with different attributes (i.e. color, sex, age), leading to biased DNN predictions. We notice that such a troubling phenomenon is often caused by data itself, which means that bias information is encoded to the DNN along with the useful information (i.e. class information, semantic information). Therefore, we propose to use sketching to handle this phenomenon. Without losing the utility of data, we explore the image-to-sketching methods that can maintain useful semantic information for the target classification while filtering out the useless bias information. In addition, we design a fair loss to further improve the model fairness. We evaluate our method through extensive experiments on both general scene dataset and medical scene dataset. Our results show that the desired image-to-sketching method improves model fairness and achieves satisfactory results among state-of-the-art.
Silence is Sweeter Than Speech: Self-Supervised Model Using Silence to Store Speaker Information
May 08, 2022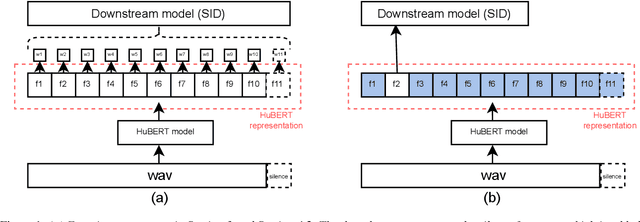
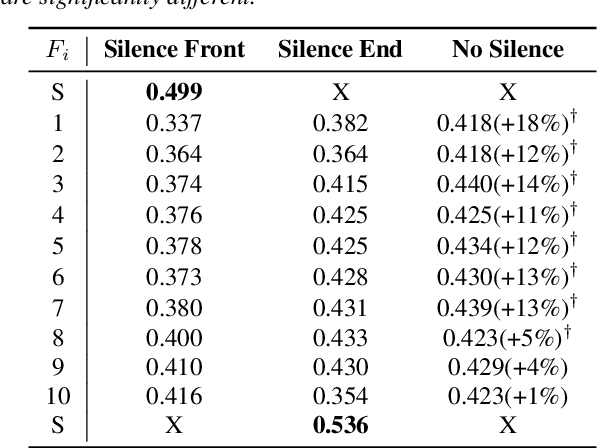
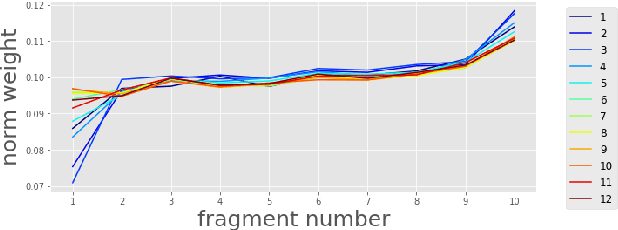
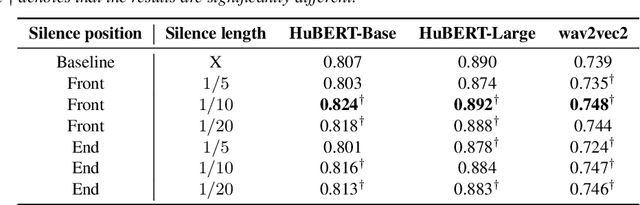
Self-Supervised Learning (SSL) has made great strides recently. SSL speech models achieve decent performance on a wide range of downstream tasks, suggesting that they extract different aspects of information from speech. However, how SSL models store various information in hidden representations without interfering is still poorly understood. Taking the recently successful SSL model, HuBERT, as an example, we explore how the SSL model processes and stores speaker information in the representation. We found that HuBERT stores speaker information in representations whose positions correspond to silences in a waveform. There are several pieces of evidence. (1) We find that the utterances with more silent parts in the waveforms have better Speaker Identification (SID) accuracy. (2) If we use the whole utterances for SID, the silence part always contributes more to the SID task. (3) If we only use the representation of a part of the utterance for SID, the silenced part has higher accuracy than the other parts. Our findings not only contribute to a better understanding of SSL models but also improve performance. By simply adding silence to the original waveform, HuBERT improved its accuracy on SID by nearly 2%.
Bayesian data fusion with shared priors
Dec 14, 2022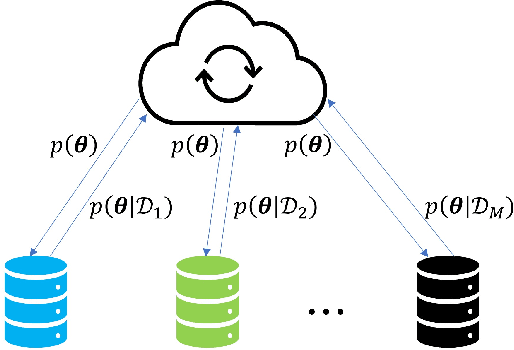

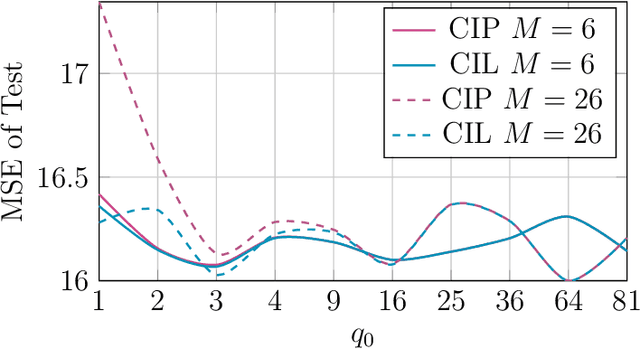
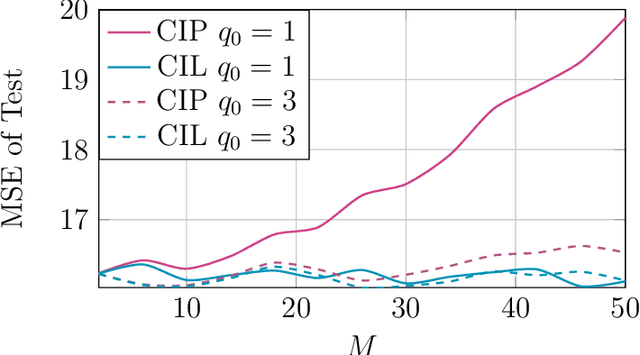
The integration of data and knowledge from several sources is known as data fusion. When data is available in a distributed fashion or when different sensors are used to infer a quantity of interest, data fusion becomes essential. In Bayesian settings, a priori information of the unknown quantities is available and, possibly, shared among the distributed estimators. When the local estimates are fused, such prior might be overused unless it is accounted for. This paper explores the effects of shared priors in Bayesian data fusion contexts, providing fusion rules and analysis to understand the performance of such fusion as a function of the number of collaborative agents and the uncertainty of the priors. Analytical results are corroborated through experiments in a variety of estimation and classification problems.
Building Multilingual Corpora for a Complex Named Entity Recognition and Classification Hierarchy using Wikipedia and DBpedia
Dec 14, 2022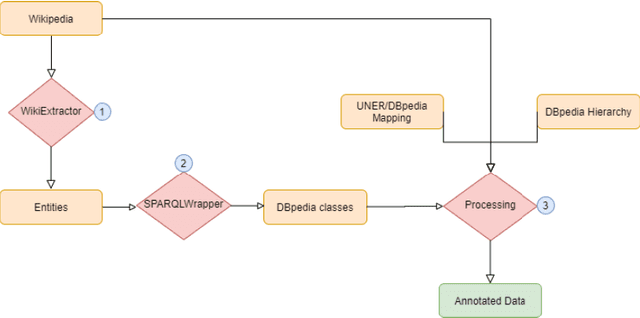
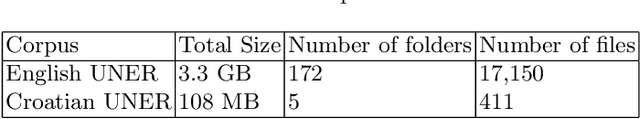
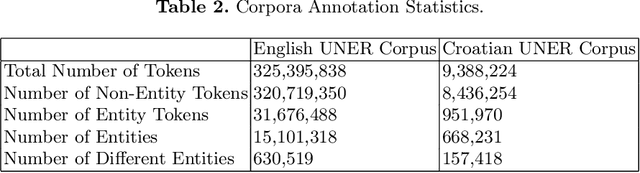
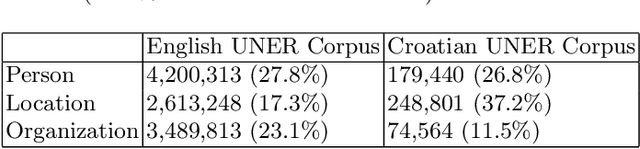
With the ever-growing popularity of the field of NLP, the demand for datasets in low resourced-languages follows suit. Following a previously established framework, in this paper, we present the UNER dataset, a multilingual and hierarchical parallel corpus annotated for named-entities. We describe in detail the developed procedure necessary to create this type of dataset in any language available on Wikipedia with DBpedia information. The three-step procedure extracts entities from Wikipedia articles, links them to DBpedia, and maps the DBpedia sets of classes to the UNER labels. This is followed by a post-processing procedure that significantly increases the number of identified entities in the final results. The paper concludes with a statistical and qualitative analysis of the resulting dataset.
Guided Hybrid Quantization for Object detection in Multimodal Remote Sensing Imagery via One-to-one Self-teaching
Dec 31, 2022
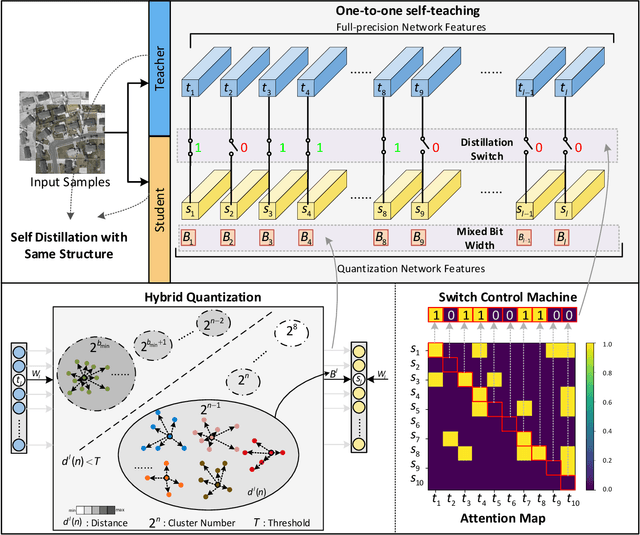
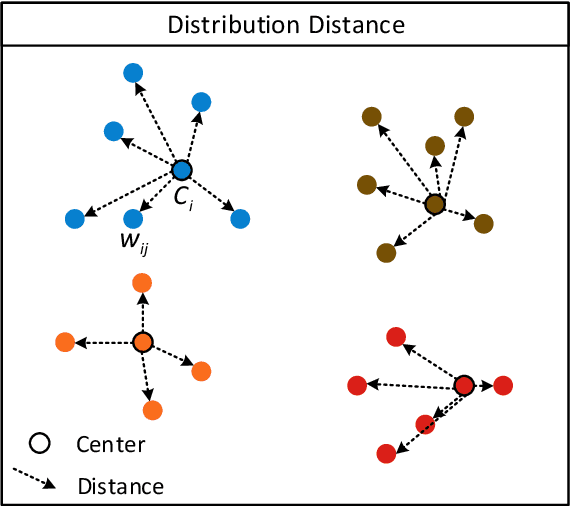
Considering the computation complexity, we propose a Guided Hybrid Quantization with One-to-one Self-Teaching (GHOST}) framework. More concretely, we first design a structure called guided quantization self-distillation (GQSD), which is an innovative idea for realizing lightweight through the synergy of quantization and distillation. The training process of the quantization model is guided by its full-precision model, which is time-saving and cost-saving without preparing a huge pre-trained model in advance. Second, we put forward a hybrid quantization (HQ) module to obtain the optimal bit width automatically under a constrained condition where a threshold for distribution distance between the center and samples is applied in the weight value search space. Third, in order to improve information transformation, we propose a one-to-one self-teaching (OST) module to give the student network a ability of self-judgment. A switch control machine (SCM) builds a bridge between the student network and teacher network in the same location to help the teacher to reduce wrong guidance and impart vital knowledge to the student. This distillation method allows a model to learn from itself and gain substantial improvement without any additional supervision. Extensive experiments on a multimodal dataset (VEDAI) and single-modality datasets (DOTA, NWPU, and DIOR) show that object detection based on GHOST outperforms the existing detectors. The tiny parameters (<9.7 MB) and Bit-Operations (BOPs) (<2158 G) compared with any remote sensing-based, lightweight or distillation-based algorithms demonstrate the superiority in the lightweight design domain. Our code and model will be released at https://github.com/icey-zhang/GHOST.
An Efficient Hierarchical Kriging Modeling Method for High-dimension Multi-fidelity Problems
Dec 31, 2022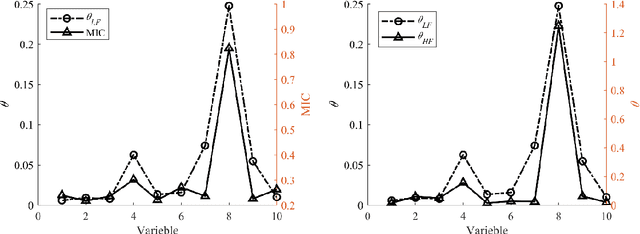

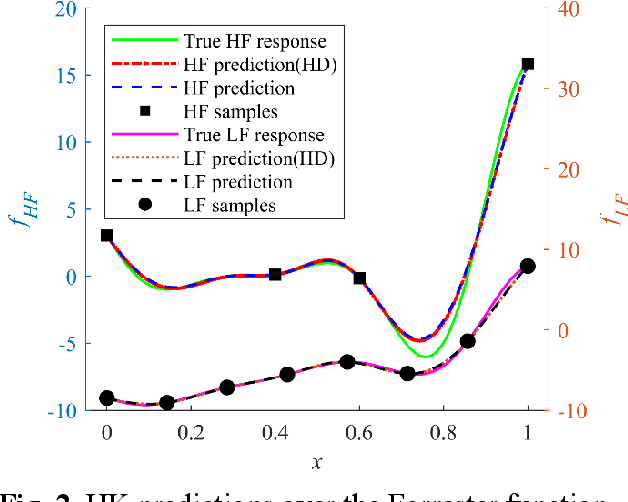
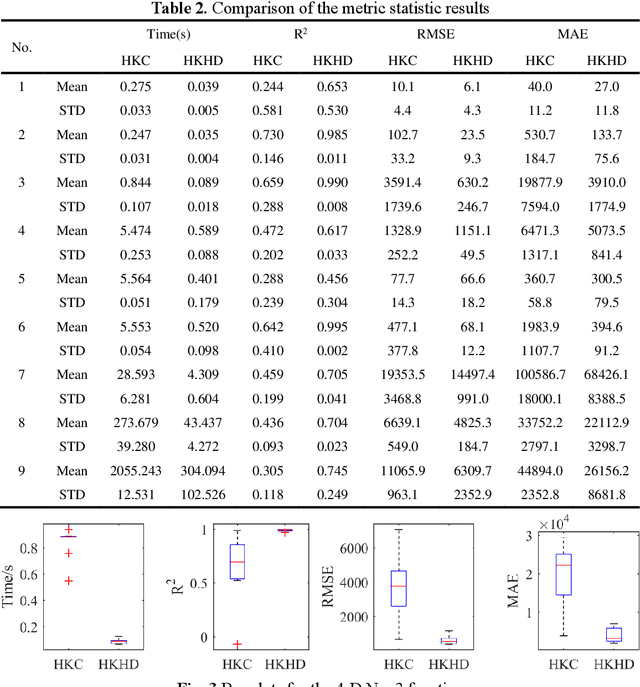
Multi-fidelity Kriging model is a promising technique in surrogate-based design as it can balance the model accuracy and cost of sample preparation by fusing low- and high-fidelity data. However, the cost for building a multi-fidelity Kriging model increases significantly with the increase of the problem dimension. To attack this issue, an efficient Hierarchical Kriging modeling method is proposed. In building the low-fidelity model, the maximal information coefficient is utilized to calculate the relative value of the hyperparameter. With this, the maximum likelihood estimation problem for determining the hyperparameters is transformed as a one-dimension optimization problem, which can be solved in an efficient manner and thus improve the modeling efficiency significantly. A local search is involved further to exploit the search space of hyperparameters to improve the model accuracy. The high-fidelity model is built in a similar manner with the hyperparameter of the low-fidelity model served as the relative value of the hyperparameter for high-fidelity model. The performance of the proposed method is compared with the conventional tuning strategy, by testing them over ten analytic problems and an engineering problem of modeling the isentropic efficiency of a compressor rotor. The empirical results demonstrate that the modeling time of the proposed method is reduced significantly without sacrificing the model accuracy. For the modeling of the isentropic efficiency of the compressor rotor, the cost saving associated with the proposed method is about 90% compared with the conventional strategy. Meanwhile, the proposed method achieves higher accuracy.
Identification of lung nodules CT scan using YOLOv5 based on convolution neural network
Dec 31, 2022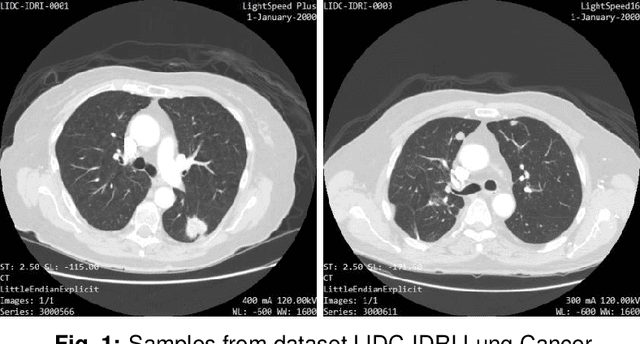

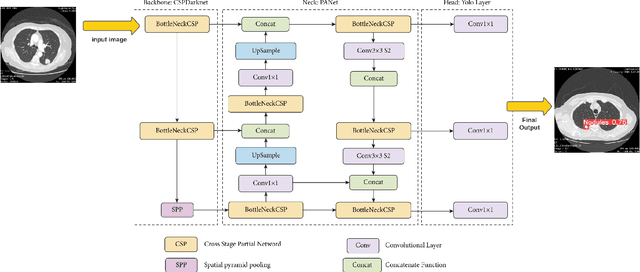
Purpose: The lung nodules localization in CT scan images is the most difficult task due to the complexity of the arbitrariness of shape, size, and texture of lung nodules. This is a challenge to be faced when coming to developing different solutions to improve detection systems. the deep learning approach showed promising results by using convolutional neural network (CNN), especially for image recognition and it's one of the most used algorithm in computer vision. Approach: we use (CNN) building blocks based on YOLOv5 (you only look once) to learn the features representations for nodule detection labels, in this paper, we introduce a method for detecting lung cancer localization. Chest X-rays and low-dose computed tomography are also possible screening methods, When it comes to recognizing nodules in radiography, computer-aided diagnostic (CAD) system based on (CNN) have demonstrated their worth. One-stage detector YOLOv5 trained on 280 annotated CT SCAN from a public dataset LIDC-IDRI based on segmented pulmonary nodules. Results: we analyze the predictions performance of the lung nodule locations, and demarcates the relevant CT scan regions. In lung nodule localization the accuracy is measured as mean average precision (mAP). the mAP takes into account how well the bounding boxes are fitting the labels as well as how accurate the predicted classes for those bounding boxes, the accuracy we got 92.27%. Conclusion: this study was to identify the nodule that were developing in the lungs of the participants. It was difficult to find information on lung nodules in medical literature.
Search Behavior Prediction: A Hypergraph Perspective
Nov 29, 2022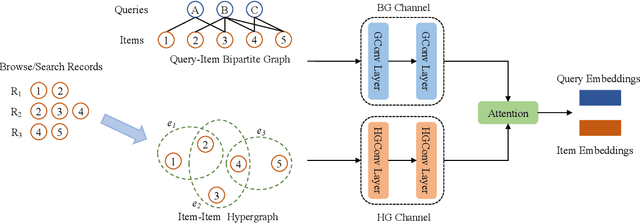
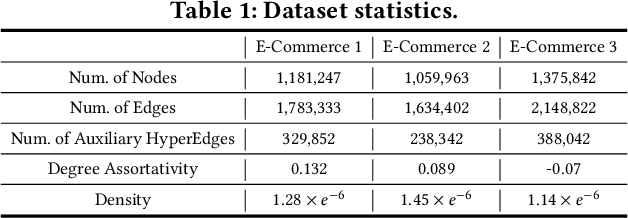
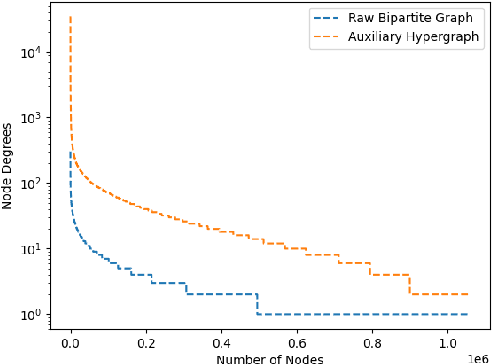
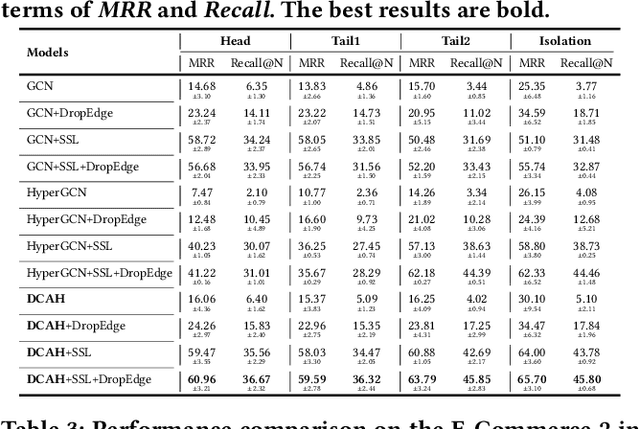
Although the bipartite shopping graphs are straightforward to model search behavior, they suffer from two challenges: 1) The majority of items are sporadically searched and hence have noisy/sparse query associations, leading to a \textit{long-tail} distribution. 2) Infrequent queries are more likely to link to popular items, leading to another hurdle known as \textit{disassortative mixing}. To address these two challenges, we go beyond the bipartite graph to take a hypergraph perspective, introducing a new paradigm that leverages \underline{auxiliary} information from anonymized customer engagement sessions to assist the \underline{main task} of query-item link prediction. This auxiliary information is available at web scale in the form of search logs. We treat all items appearing in the same customer session as a single hyperedge. The hypothesis is that items in a customer session are unified by a common shopping interest. With these hyperedges, we augment the original bipartite graph into a new \textit{hypergraph}. We develop a \textit{\textbf{D}ual-\textbf{C}hannel \textbf{A}ttention-Based \textbf{H}ypergraph Neural Network} (\textbf{DCAH}), which synergizes information from two potentially noisy sources (original query-item edges and item-item hyperedges). In this way, items on the tail are better connected due to the extra hyperedges, thereby enhancing their link prediction performance. We further integrate DCAH with self-supervised graph pre-training and/or DropEdge training, both of which effectively alleviate disassortative mixing. Extensive experiments on three proprietary E-Commerce datasets show that DCAH yields significant improvements of up to \textbf{24.6\% in mean reciprocal rank (MRR)} and \textbf{48.3\% in recall} compared to GNN-based baselines. Our source code is available at \url{https://github.com/amazon-science/dual-channel-hypergraph-neural-network}.