 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Memory Augmented Lookup Dictionary based Language Modeling for Automatic Speech Recognition
Dec 30, 2022
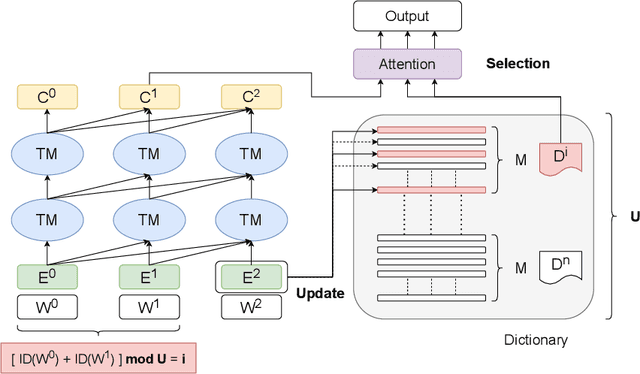
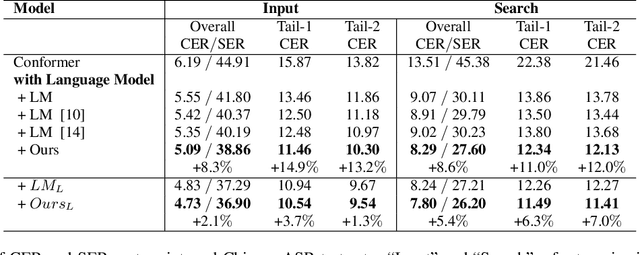
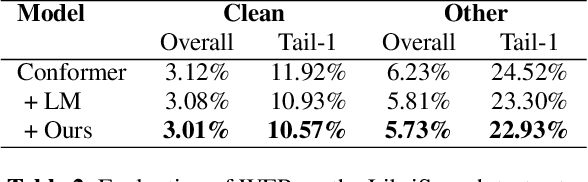
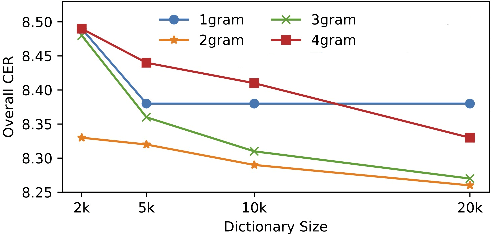
Recent studies have shown that using an external Language Model (LM) benefits the end-to-end Automatic Speech Recognition (ASR). However, predicting tokens that appear less frequently in the training set is still quite challenging. The long-tail prediction problems have been widely studied in many applications, but only been addressed by a few studies for ASR and LMs. In this paper, we propose a new memory augmented lookup dictionary based Transformer architecture for LM. The newly introduced lookup dictionary incorporates rich contextual information in training set, which is vital to correctly predict long-tail tokens. With intensive experiments on Chinese and English data sets, our proposed method is proved to outperform the baseline Transformer LM by a great margin on both word/character error rate and tail tokens error rate. This is achieved without impact on the decoding efficiency. Overall, we demonstrate the effectiveness of our proposed method in boosting the ASR decoding performance, especially for long-tail tokens.
MINTIME: Multi-Identity Size-Invariant Video Deepfake Detection
Dec 07, 2022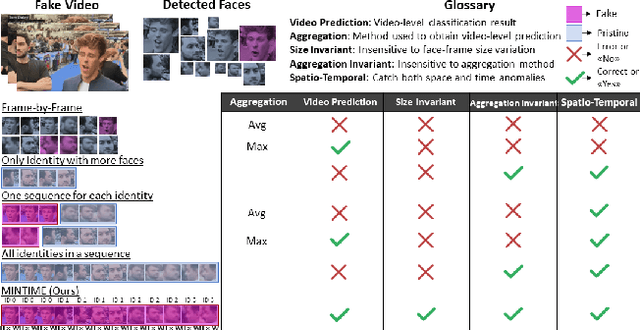
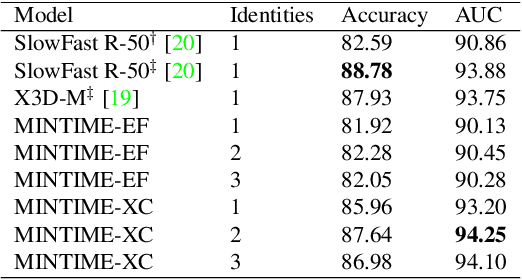
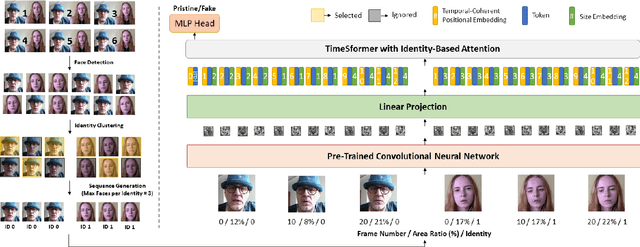

In this paper, we introduce MINTIME, a video deepfake detection approach that captures spatial and temporal anomalies and handles instances of multiple people in the same video and variations in face sizes. Previous approaches disregard such information either by using simple a-posteriori aggregation schemes, i.e., average or max operation, or using only one identity for the inference, i.e., the largest one. On the contrary, the proposed approach builds on a Spatio-Temporal TimeSformer combined with a Convolutional Neural Network backbone to capture spatio-temporal anomalies from the face sequences of multiple identities depicted in a video. This is achieved through an Identity-aware Attention mechanism that attends to each face sequence independently based on a masking operation and facilitates video-level aggregation. In addition, two novel embeddings are employed: (i) the Temporal Coherent Positional Embedding that encodes each face sequence's temporal information and (ii) the Size Embedding that encodes the size of the faces as a ratio to the video frame size. These extensions allow our system to adapt particularly well in the wild by learning how to aggregate information of multiple identities, which is usually disregarded by other methods in the literature. It achieves state-of-the-art results on the ForgeryNet dataset with an improvement of up to 14% AUC in videos containing multiple people and demonstrates ample generalization capabilities in cross-forgery and cross-dataset settings. The code is publicly available at https://github.com/davide-coccomini/MINTIME-Multi-Identity-size-iNvariant-TIMEsformer-for-Video-Deepfake-Detection.
Rho-Tau Bregman Information and the Geometry of Annealing Paths
Sep 15, 2022


Markov Chain Monte Carlo methods for sampling from complex distributions and estimating normalization constants often simulate samples from a sequence of intermediate distributions along an annealing path, which bridges between a tractable initial distribution and a target density of interest. Prior work has constructed annealing paths using quasi-arithmetic means, and interpreted the resulting intermediate densities as minimizing an expected divergence to the endpoints. We provide a comprehensive analysis of this 'centroid' property using Bregman divergences under a monotonic embedding of the density function, thereby associating common divergences such as Amari's and Renyi's ${\alpha}$-divergences, ${(\alpha,\beta)}$-divergences, and the Jensen-Shannon divergence with intermediate densities along an annealing path. Our analysis highlights the interplay between parametric families, quasi-arithmetic means, and divergence functions using the rho-tau Bregman divergence framework of Zhang 2004;2013.
Gradient Domain Weighted Guided Image Filtering
Nov 30, 2022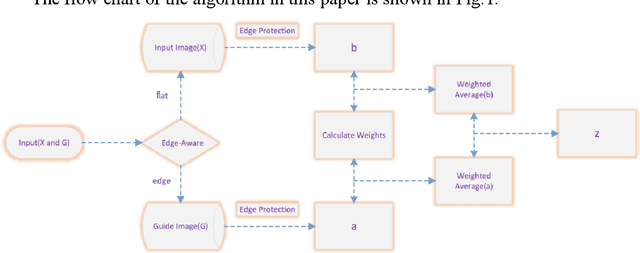
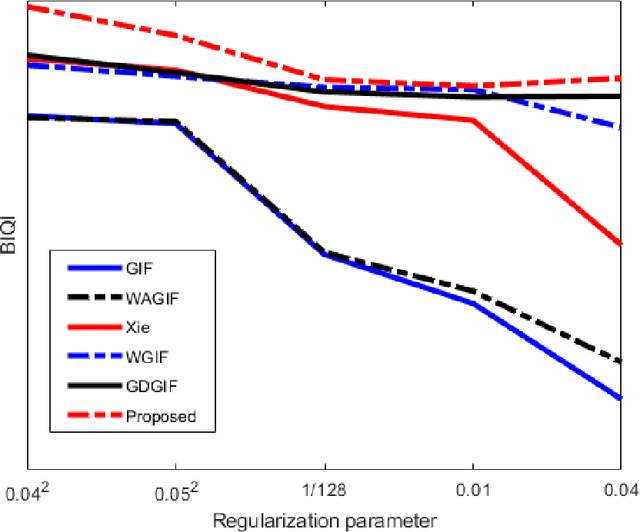


As an excellent local filter, guided image filters are subject to halo artifacts. In this paper, the algorithm uses gradient information to accurately determine the edge of the image, and uses the weighted information to further accurately distinguish the flat area and edge area of the image. As a result, the edges of the image are sharper and the level of blur in flat areas is reduced, avoiding halo artifacts caused by excessive blurring near edges. Experiments show that the proposed algorithm can better suppress halo artifacts at the edges. The proposed algorithm has good performance in both image denoising and image detail enhancement.
CompactIE: Compact Facts in Open Information Extraction
May 05, 2022
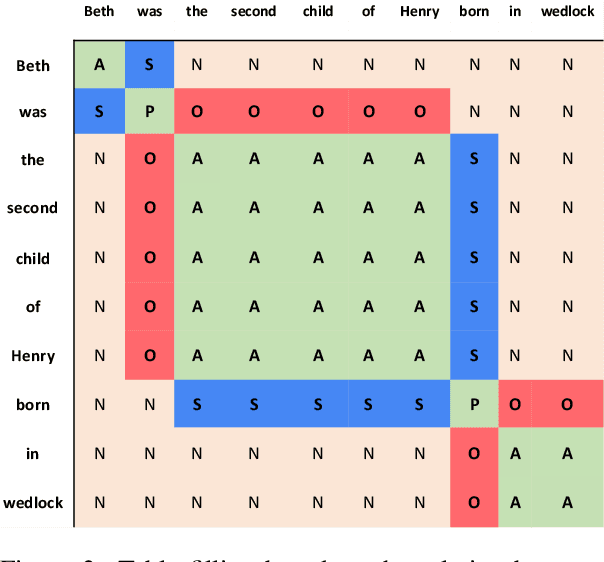

A major drawback of modern neural OpenIE systems and benchmarks is that they prioritize high coverage of information in extractions over compactness of their constituents. This severely limits the usefulness of OpenIE extractions in many downstream tasks. The utility of extractions can be improved if extractions are compact and share constituents. To this end, we study the problem of identifying compact extractions with neural-based methods. We propose CompactIE, an OpenIE system that uses a novel pipelined approach to produce compact extractions with overlapping constituents. It first detects constituents of the extractions and then links them to build extractions. We train our system on compact extractions obtained by processing existing benchmarks. Our experiments on CaRB and Wire57 datasets indicate that CompactIE finds 1.5x-2x more compact extractions than previous systems, with high precision, establishing a new state-of-the-art performance in OpenIE.
Deep Supervised Information Bottleneck Hashing for Cross-modal Retrieval based Computer-aided Diagnosis
May 06, 2022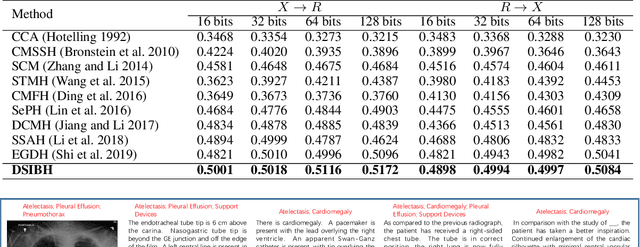
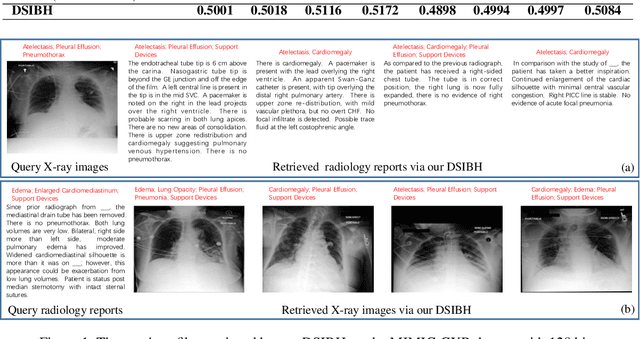
Mapping X-ray images, radiology reports, and other medical data as binary codes in the common space, which can assist clinicians to retrieve pathology-related data from heterogeneous modalities (i.e., hashing-based cross-modal medical data retrieval), provides a new view to promot computeraided diagnosis. Nevertheless, there remains a barrier to boost medical retrieval accuracy: how to reveal the ambiguous semantics of medical data without the distraction of superfluous information. To circumvent this drawback, we propose Deep Supervised Information Bottleneck Hashing (DSIBH), which effectively strengthens the discriminability of hash codes. Specifically, the Deep Deterministic Information Bottleneck (Yu, Yu, and Principe 2021) for single modality is extended to the cross-modal scenario. Benefiting from this, the superfluous information is reduced, which facilitates the discriminability of hash codes. Experimental results demonstrate the superior accuracy of the proposed DSIBH compared with state-of-the-arts in cross-modal medical data retrieval tasks.
* 7 pages, 1 figure
Why do Nearest Neighbor Language Models Work?
Jan 07, 2023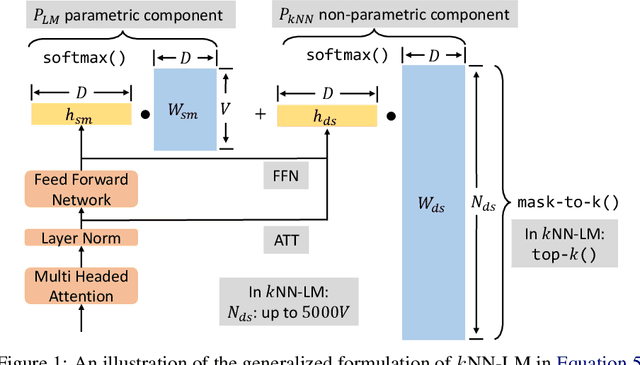


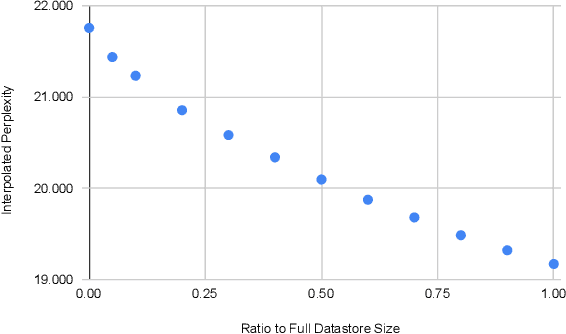
Language models (LMs) compute the probability of a text by sequentially computing a representation of an already-seen context and using this representation to predict the next word. Currently, most LMs calculate these representations through a neural network consuming the immediate previous context. However recently, retrieval-augmented LMs have shown to improve over standard neural LMs, by accessing information retrieved from a large datastore, in addition to their standard, parametric, next-word prediction. In this paper, we set out to understand why retrieval-augmented language models, and specifically why k-nearest neighbor language models (kNN-LMs) perform better than standard parametric LMs, even when the k-nearest neighbor component retrieves examples from the same training set that the LM was originally trained on. To this end, we perform a careful analysis of the various dimensions over which kNN-LM diverges from standard LMs, and investigate these dimensions one by one. Empirically, we identify three main reasons why kNN-LM performs better than standard LMs: using a different input representation for predicting the next tokens, approximate kNN search, and the importance of softmax temperature for the kNN distribution. Further, we incorporate these insights into the model architecture or the training procedure of the standard parametric LM, improving its results without the need for an explicit retrieval component. The code is available at https://github.com/frankxu2004/knnlm-why.
XKD: Cross-modal Knowledge Distillation with Domain Alignment for Video Representation Learning
Dec 12, 2022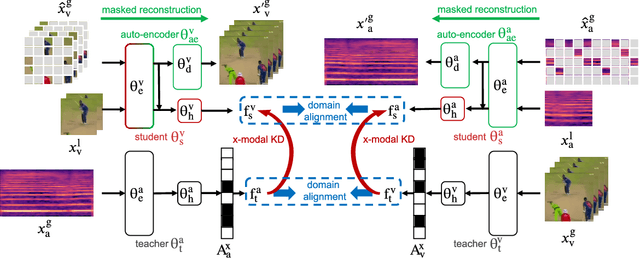
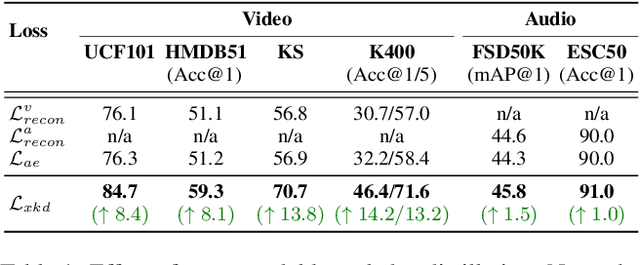
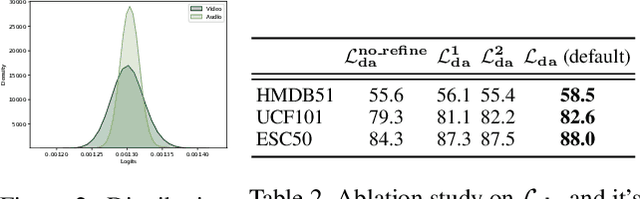

We present XKD, a novel self-supervised framework to learn meaningful representations from unlabelled video clips. XKD is trained with two pseudo tasks. First, masked data reconstruction is performed to learn modality-specific representations. Next, self-supervised cross-modal knowledge distillation is performed between the two modalities through teacher-student setups to learn complementary information. To identify the most effective information to transfer and also to tackle the domain gap between audio and visual modalities which could hinder knowledge transfer, we introduce a domain alignment strategy for effective cross-modal distillation. Lastly, to develop a general-purpose solution capable of handling both audio and visual streams, a modality-agnostic variant of our proposed framework is introduced, which uses the same backbone for both audio and visual modalities. Our proposed cross-modal knowledge distillation improves linear evaluation top-1 accuracy of video action classification by 8.4% on UCF101, 8.1% on HMDB51, 13.8% on Kinetics-Sound, and 14.2% on Kinetics400. Additionally, our modality-agnostic variant shows promising results in developing a general-purpose network capable of handling different data streams. The code is released on the project website.
Memories are One-to-Many Mapping Alleviators in Talking Face Generation
Dec 12, 2022
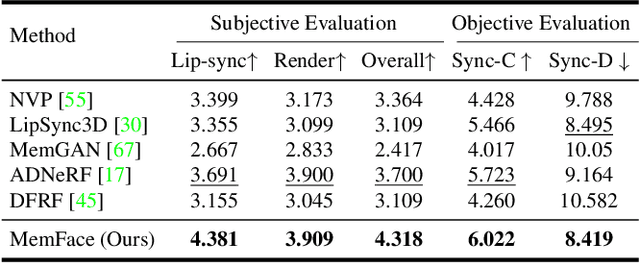
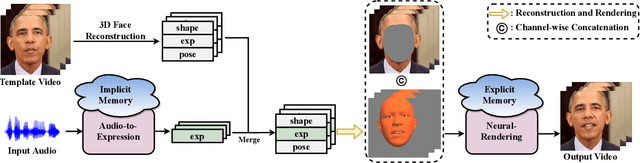
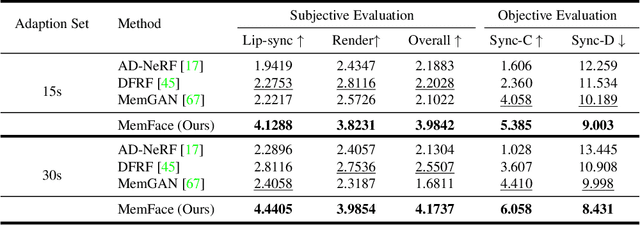
Talking face generation aims at generating photo-realistic video portraits of a target person driven by input audio. Due to its nature of one-to-many mapping from the input audio to the output video (e.g., one speech content may have multiple feasible visual appearances), learning a deterministic mapping like previous works brings ambiguity during training, and thus causes inferior visual results. Although this one-to-many mapping could be alleviated in part by a two-stage framework (i.e., an audio-to-expression model followed by a neural-rendering model), it is still insufficient since the prediction is produced without enough information (e.g., emotions, wrinkles, etc.). In this paper, we propose MemFace to complement the missing information with an implicit memory and an explicit memory that follow the sense of the two stages respectively. More specifically, the implicit memory is employed in the audio-to-expression model to capture high-level semantics in the audio-expression shared space, while the explicit memory is employed in the neural-rendering model to help synthesize pixel-level details. Our experimental results show that our proposed MemFace surpasses all the state-of-the-art results across multiple scenarios consistently and significantly.
BigText-QA: Question Answering over a Large-Scale Hybrid Knowledge Graph
Dec 12, 2022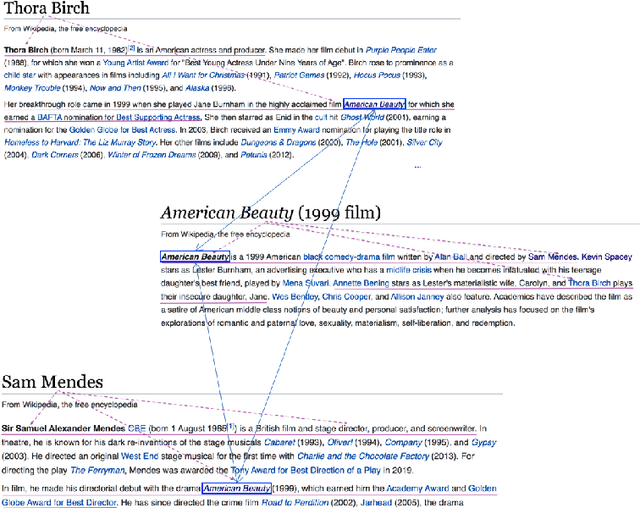

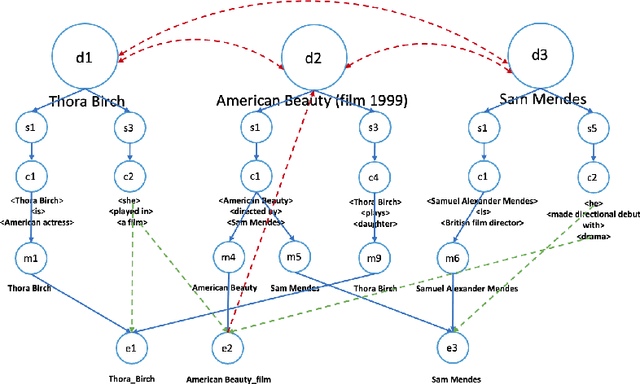

Answering complex questions over textual resources remains a challenging problem$\unicode{x2013}$especially when interpreting the fine-grained relationships among multiple entities that occur within a natural-language question or clue. Curated knowledge bases (KBs), such as YAGO, DBpedia, Freebase and Wikidata, have been widely used in this context and gained great acceptance for question-answering (QA) applications in the past decade. While current KBs offer a concise representation of structured knowledge, they lack the variety of formulations and semantic nuances as well as the context of information provided by the natural-language sources. With BigText-QA, we aim to develop an integrated QA system which is able to answer questions based on a more redundant form of a knowledge graph (KG) that organizes both structured and unstructured (i.e., "hybrid") knowledge in a unified graphical representation. BigText-QA thereby is able to combine the best of both worlds$\unicode{x2013}$a canonical set of named entities, mapped to a structured background KB (such as YAGO or Wikidata), as well as an open set of textual clauses providing highly diversified relational paraphrases with rich context information.