 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Linear Codes for Hyperdimensional Computing
Mar 05, 2024

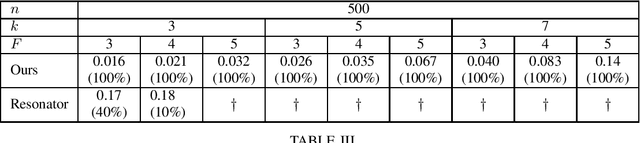
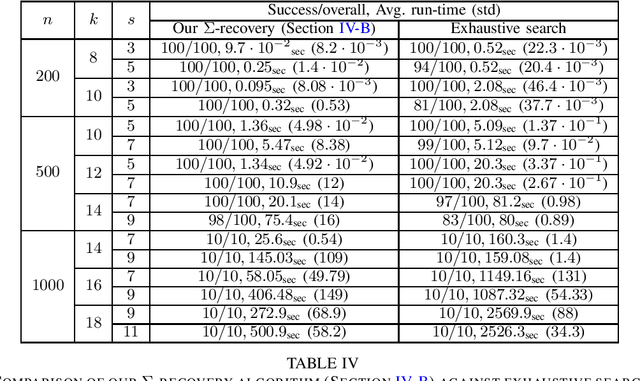
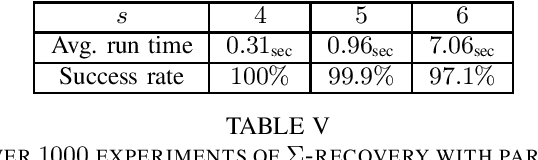
Hyperdimensional Computing (HDC) is an emerging computational paradigm for representing compositional information as high-dimensional vectors, and has a promising potential in applications ranging from machine learning to neuromorphic computing. One of the long-standing challenges in HDC is factoring a compositional representation to its constituent factors, also known as the recovery problem. In this paper we take a novel approach to solve the recovery problem, and propose the use of random linear codes. These codes are subspaces over the Boolean field, and are a well-studied topic in information theory with various applications in digital communication. We begin by showing that hyperdimensional encoding using random linear codes retains favorable properties of the prevalent (ordinary) random codes, and hence HD representations using the two methods have comparable information storage capabilities. We proceed to show that random linear codes offer a rich subcode structure that can be used to form key-value stores, which encapsulate most use cases of HDC. Most importantly, we show that under the framework we develop, random linear codes admit simple recovery algorithms to factor (either bundled or bound) compositional representations. The former relies on constructing certain linear equation systems over the Boolean field, the solution to which reduces the search space dramatically and strictly outperforms exhaustive search in many cases. The latter employs the subspace structure of these codes to achieve provably correct factorization. Both methods are strictly faster than the state-of-the-art resonator networks, often by an order of magnitude. We implemented our techniques in Python using a benchmark software library, and demonstrated promising experimental results.
Enhancing Long-Term Person Re-Identification Using Global, Local Body Part, and Head Streams
Mar 05, 2024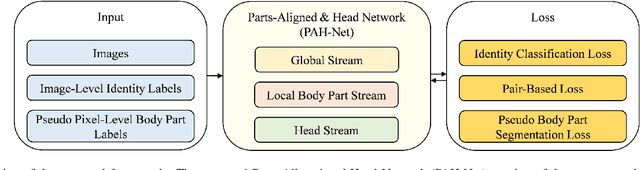
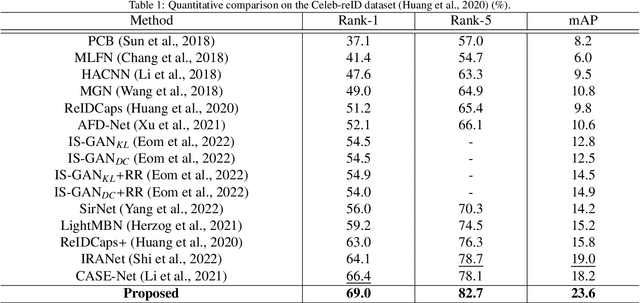
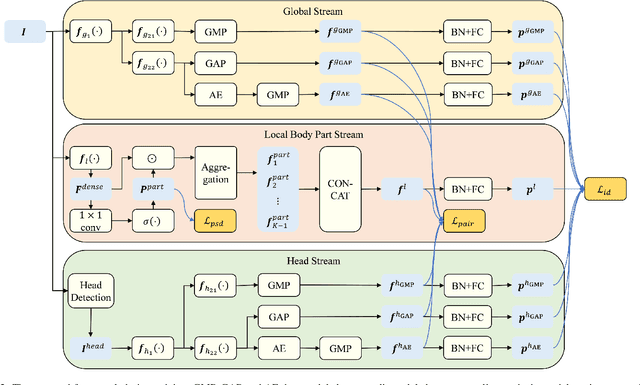
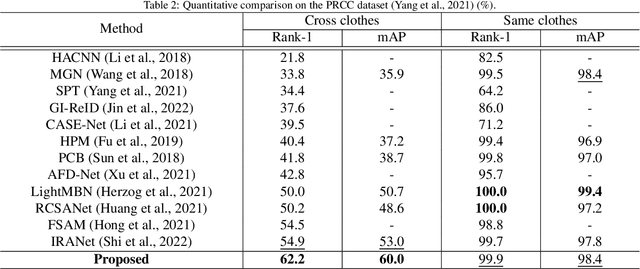
This work addresses the task of long-term person re-identification. Typically, person re-identification assumes that people do not change their clothes, which limits its applications to short-term scenarios. To overcome this limitation, we investigate long-term person re-identification, which considers both clothes-changing and clothes-consistent scenarios. In this paper, we propose a novel framework that effectively learns and utilizes both global and local information. The proposed framework consists of three streams: global, local body part, and head streams. The global and head streams encode identity-relevant information from an entire image and a cropped image of the head region, respectively. Both streams encode the most distinct, less distinct, and average features using the combinations of adversarial erasing, max pooling, and average pooling. The local body part stream extracts identity-related information for each body part, allowing it to be compared with the same body part from another image. Since body part annotations are not available in re-identification datasets, pseudo-labels are generated using clustering. These labels are then utilized to train a body part segmentation head in the local body part stream. The proposed framework is trained by backpropagating the weighted summation of the identity classification loss, the pair-based loss, and the pseudo body part segmentation loss. To demonstrate the effectiveness of the proposed method, we conducted experiments on three publicly available datasets (Celeb-reID, PRCC, and VC-Clothes). The experimental results demonstrate that the proposed method outperforms the previous state-of-the-art method.
* 16 pages
Knowledge Graphs as Context Sources for LLM-Based Explanations of Learning Recommendations
Mar 05, 2024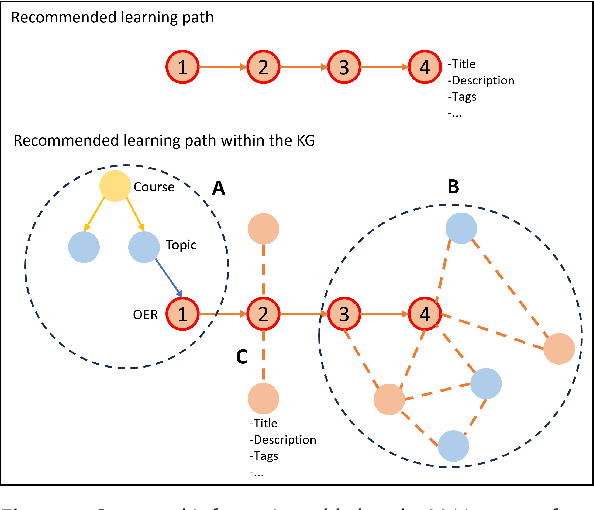
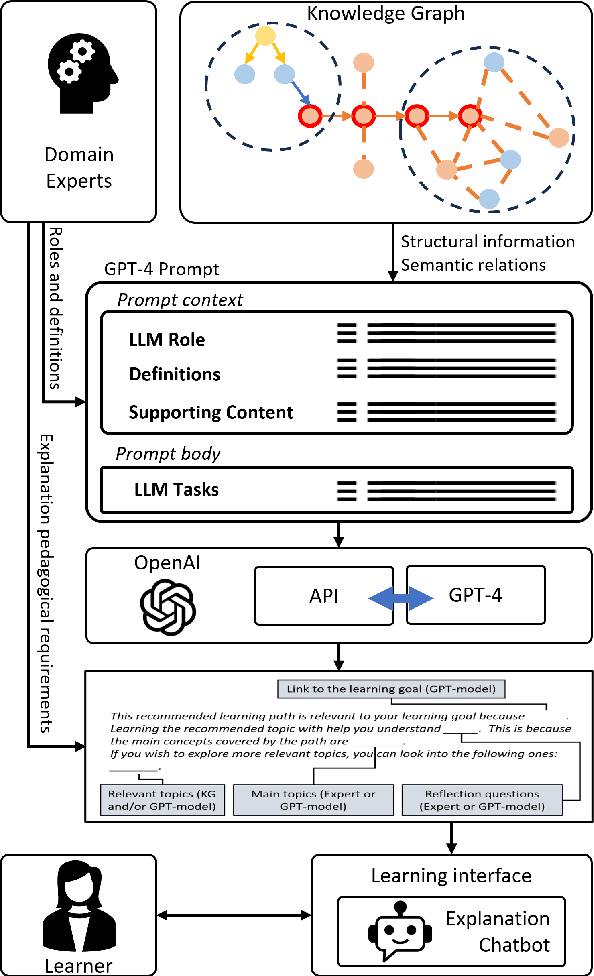
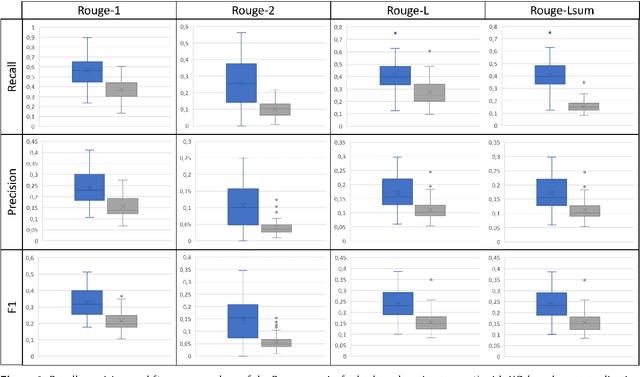
In the era of personalized education, the provision of comprehensible explanations for learning recommendations is of a great value to enhance the learner's understanding and engagement with the recommended learning content. Large language models (LLMs) and generative AI in general have recently opened new doors for generating human-like explanations, for and along learning recommendations. However, their precision is still far away from acceptable in a sensitive field like education. To harness the abilities of LLMs, while still ensuring a high level of precision towards the intent of the learners, this paper proposes an approach to utilize knowledge graphs (KG) as a source of factual context, for LLM prompts, reducing the risk of model hallucinations, and safeguarding against wrong or imprecise information, while maintaining an application-intended learning context. We utilize the semantic relations in the knowledge graph to offer curated knowledge about learning recommendations. With domain-experts in the loop, we design the explanation as a textual template, which is filled and completed by the LLM. Domain experts were integrated in the prompt engineering phase as part of a study, to ensure that explanations include information that is relevant to the learner. We evaluate our approach quantitatively using Rouge-N and Rouge-L measures, as well as qualitatively with experts and learners. Our results show an enhanced recall and precision of the generated explanations compared to those generated solely by the GPT model, with a greatly reduced risk of generating imprecise information in the final learning explanation.
Prediction Of Cryptocurrency Prices Using LSTM, SVM And Polynomial Regression
Mar 06, 2024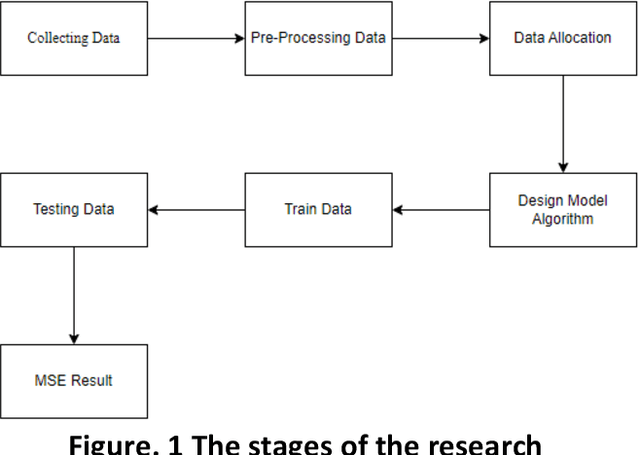
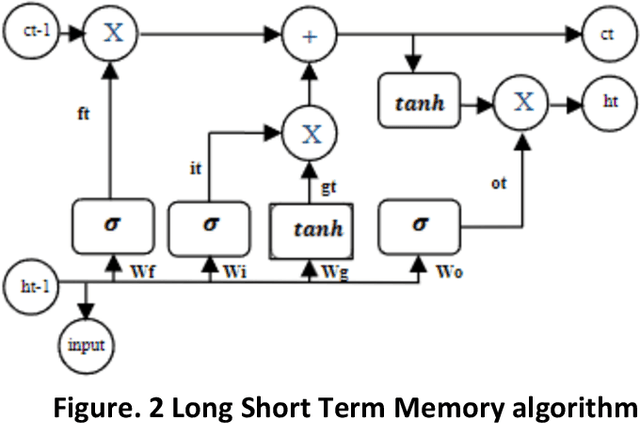
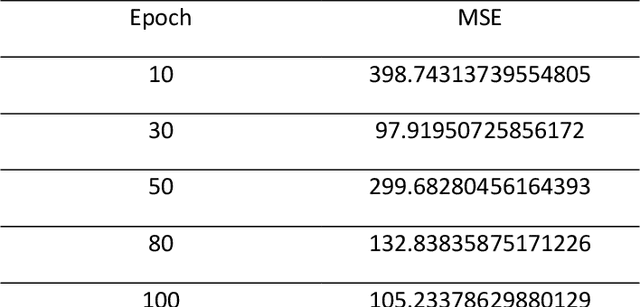
The rapid development of information technology, especially the Internet, has facilitated users with a quick and easy way to seek information. With these convenience offered by internet services, many individuals who initially invested in gold and precious metals are now shifting into digital investments in form of cryptocurrencies. However, investments in crypto coins are filled with uncertainties and fluctuation in daily basis. This risk posed as significant challenges for coin investors that could result in substantial investment losses. The uncertainty of the value of these crypto coins is a critical issue in the field of coin investment. Forecasting, is one of the methods used to predict the future value of these crypto coins. By utilizing the models of Long Short Term Memory, Support Vector Machine, and Polynomial Regression algorithm for forecasting, a performance comparison is conducted to determine which algorithm model is most suitable for predicting crypto currency prices. The mean square error is employed as a benchmark for the comparison. By applying those three constructed algorithm models, the Support Vector Machine uses a linear kernel to produce the smallest mean square error compared to the Long Short Term Memory and Polynomial Regression algorithm models, with a mean square error value of 0.02. Keywords: Cryptocurrency, Forecasting, Long Short Term Memory, Mean Square Error, Polynomial Regression, Support Vector Machine
Self-supervised Photographic Image Layout Representation Learning
Mar 06, 2024
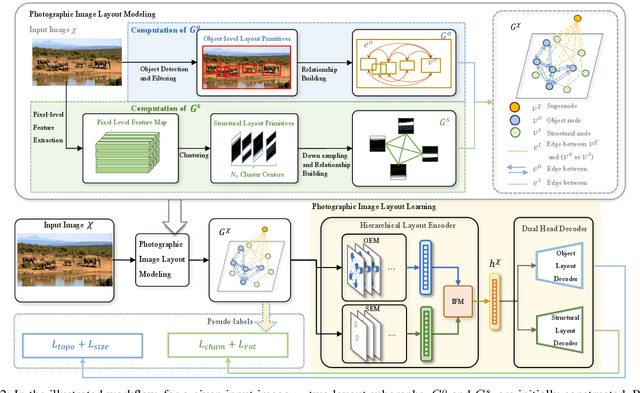
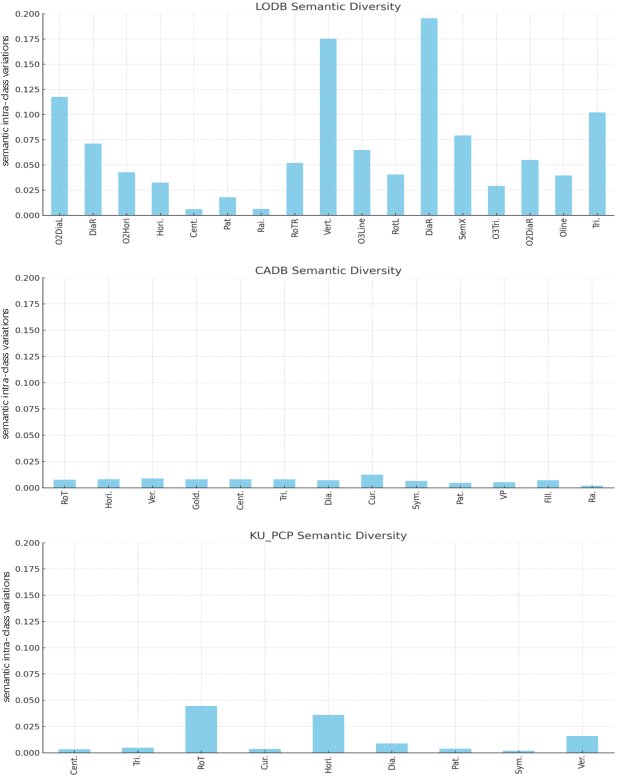

In the domain of image layout representation learning, the critical process of translating image layouts into succinct vector forms is increasingly significant across diverse applications, such as image retrieval, manipulation, and generation. Most approaches in this area heavily rely on costly labeled datasets and notably lack in adapting their modeling and learning methods to the specific nuances of photographic image layouts. This shortfall makes the learning process for photographic image layouts suboptimal. In our research, we directly address these challenges. We innovate by defining basic layout primitives that encapsulate various levels of layout information and by mapping these, along with their interconnections, onto a heterogeneous graph structure. This graph is meticulously engineered to capture the intricate layout information within the pixel domain explicitly. Advancing further, we introduce novel pretext tasks coupled with customized loss functions, strategically designed for effective self-supervised learning of these layout graphs. Building on this foundation, we develop an autoencoder-based network architecture skilled in compressing these heterogeneous layout graphs into precise, dimensionally-reduced layout representations. Additionally, we introduce the LODB dataset, which features a broader range of layout categories and richer semantics, serving as a comprehensive benchmark for evaluating the effectiveness of layout representation learning methods. Our extensive experimentation on this dataset demonstrates the superior performance of our approach in the realm of photographic image layout representation learning.
Discerning and Resolving Knowledge Conflicts through Adaptive Decoding with Contextual Information-Entropy Constraint
Feb 19, 2024Large language models internalize enormous parametric knowledge during pre-training. Concurrently, realistic applications necessitate external contextual knowledge to aid models on the underlying tasks. This raises a crucial dilemma known as knowledge conflicts, where the contextual knowledge clashes with the However, existing decoding works are specialized in resolving knowledge conflicts and could inadvertently deteriorate performance in absence of conflicts. In this paper, we propose an adaptive decoding method, termed as contextual information-entropy constraint decoding (COIECD), to discern whether the knowledge conflicts occur and resolve them. It can improve the model's faithfulness to conflicting context, and simultaneously maintain high performance among non- Our experiments show that COIECD exhibits strong performance and robustness over knowledge conflicts in realistic datasets. Code is available.
Neural Image Compression with Text-guided Encoding for both Pixel-level and Perceptual Fidelity
Mar 05, 2024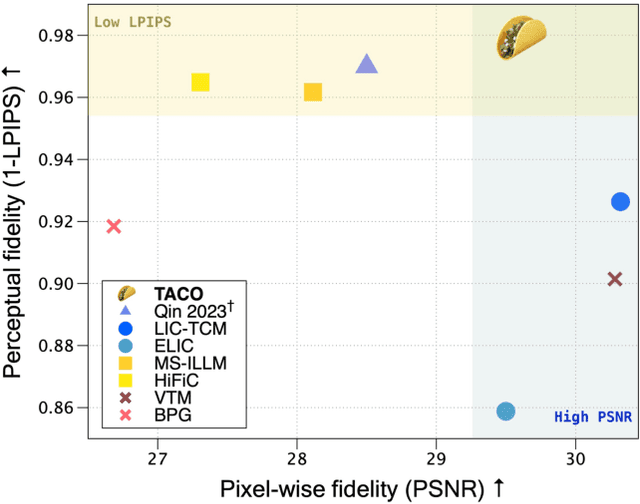
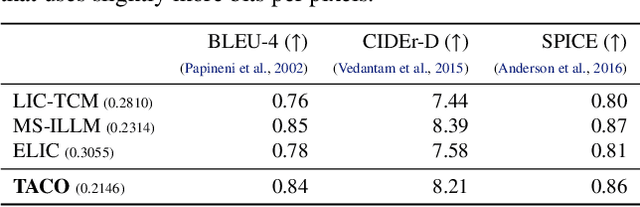

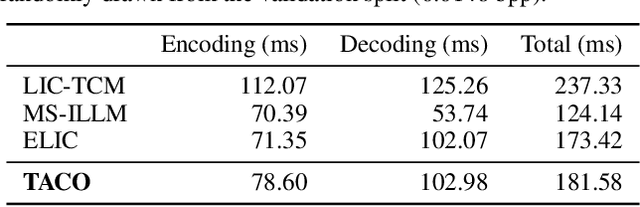
Recent advances in text-guided image compression have shown great potential to enhance the perceptual quality of reconstructed images. These methods, however, tend to have significantly degraded pixel-wise fidelity, limiting their practicality. To fill this gap, we develop a new text-guided image compression algorithm that achieves both high perceptual and pixel-wise fidelity. In particular, we propose a compression framework that leverages text information mainly by text-adaptive encoding and training with joint image-text loss. By doing so, we avoid decoding based on text-guided generative models -- known for high generative diversity -- and effectively utilize the semantic information of text at a global level. Experimental results on various datasets show that our method can achieve high pixel-level and perceptual quality, with either human- or machine-generated captions. In particular, our method outperforms all baselines in terms of LPIPS, with some room for even more improvements when we use more carefully generated captions.
Low Complexity Channel Estimation for RIS-Assisted THz Systems with Beam Split
Mar 05, 2024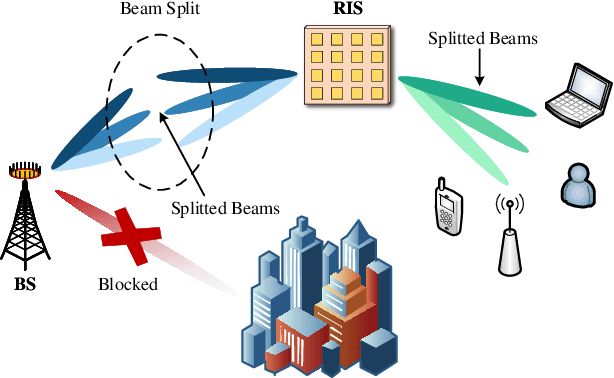
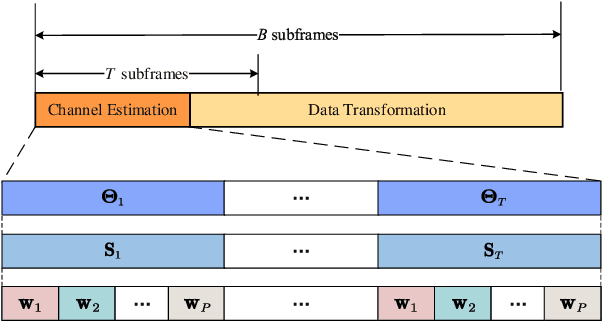
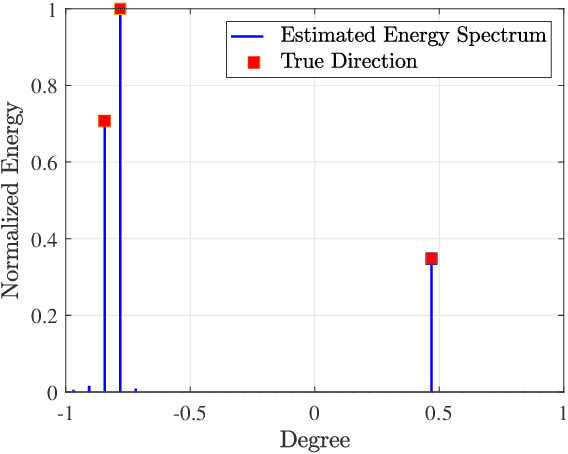
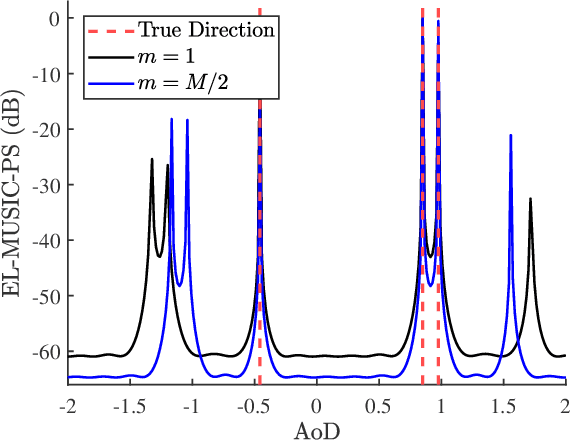
To support extremely high data rates, reconfigurable intelligent surface (RIS)-assisted terahertz (THz) communication is considered to be a promising technology for future sixth-generation networks. However, due to the typical employment of hybrid beamforming architecture in THz systems, as well as the passive nature of RIS which lacks the capability to process pilot signals, obtaining channel state information (CSI) is facing significant challenges. To accurately estimate the cascaded channel, we propose a novel low-complexity channel estimation scheme, which includes three steps. Specifically, we first estimate full CSI within a small subset of subcarriers (SCs). Then, we acquire angular information at base station and RIS based on the full CSI. Finally, we derive spatial directions and recover full-CSI for the remaining SCs. Theoretical analysis and simulation results demonstrate that the proposed scheme can achieve superior performance in terms of normalized mean-square-error and exhibit a lower computational complexity compared with the existing algorithms.
Information Complexity of Stochastic Convex Optimization: Applications to Generalization and Memorization
Feb 14, 2024In this work, we investigate the interplay between memorization and learning in the context of \emph{stochastic convex optimization} (SCO). We define memorization via the information a learning algorithm reveals about its training data points. We then quantify this information using the framework of conditional mutual information (CMI) proposed by Steinke and Zakynthinou (2020). Our main result is a precise characterization of the tradeoff between the accuracy of a learning algorithm and its CMI, answering an open question posed by Livni (2023). We show that, in the $L^2$ Lipschitz--bounded setting and under strong convexity, every learner with an excess error $\varepsilon$ has CMI bounded below by $\Omega(1/\varepsilon^2)$ and $\Omega(1/\varepsilon)$, respectively. We further demonstrate the essential role of memorization in learning problems in SCO by designing an adversary capable of accurately identifying a significant fraction of the training samples in specific SCO problems. Finally, we enumerate several implications of our results, such as a limitation of generalization bounds based on CMI and the incompressibility of samples in SCO problems.
Privacy-Enhancing Collaborative Information Sharing through Federated Learning -- A Case of the Insurance Industry
Feb 22, 2024The report demonstrates the benefits (in terms of improved claims loss modeling) of harnessing the value of Federated Learning (FL) to learn a single model across multiple insurance industry datasets without requiring the datasets themselves to be shared from one company to another. The application of FL addresses two of the most pressing concerns: limited data volume and data variety, which are caused by privacy concerns, the rarity of claim events, the lack of informative rating factors, etc.. During each round of FL, collaborators compute improvements on the model using their local private data, and these insights are combined to update a global model. Such aggregation of insights allows for an increase to the effectiveness in forecasting claims losses compared to models individually trained at each collaborator. Critically, this approach enables machine learning collaboration without the need for raw data to leave the compute infrastructure of each respective data owner. Additionally, the open-source framework, OpenFL, that is used in our experiments is designed so that it can be run using confidential computing as well as with additional algorithmic protections against leakage of information via the shared model updates. In such a way, FL is implemented as a privacy-enhancing collaborative learning technique that addresses the challenges posed by the sensitivity and privacy of data in traditional machine learning solutions. This paper's application of FL can also be expanded to other areas including fraud detection, catastrophe modeling, etc., that have a similar need to incorporate data privacy into machine learning collaborations. Our framework and empirical results provide a foundation for future collaborations among insurers, regulators, academic researchers, and InsurTech experts.