 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Learning Dual-Fused Modality-Aware Representations for RGBD Tracking
Nov 15, 2022

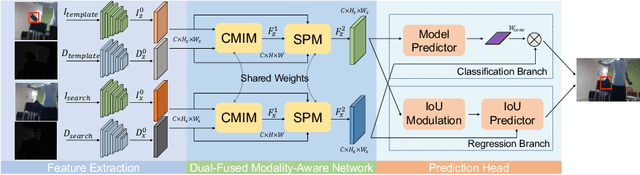
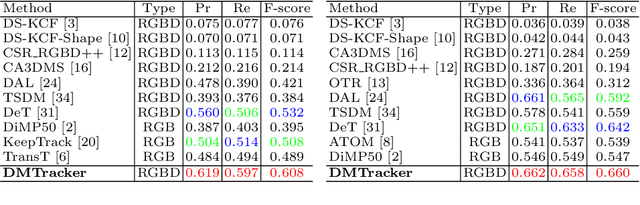

With the development of depth sensors in recent years, RGBD object tracking has received significant attention. Compared with the traditional RGB object tracking, the addition of the depth modality can effectively solve the target and background interference. However, some existing RGBD trackers use the two modalities separately and thus some particularly useful shared information between them is ignored. On the other hand, some methods attempt to fuse the two modalities by treating them equally, resulting in the missing of modality-specific features. To tackle these limitations, we propose a novel Dual-fused Modality-aware Tracker (termed DMTracker) which aims to learn informative and discriminative representations of the target objects for robust RGBD tracking. The first fusion module focuses on extracting the shared information between modalities based on cross-modal attention. The second aims at integrating the RGB-specific and depth-specific information to enhance the fused features. By fusing both the modality-shared and modality-specific information in a modality-aware scheme, our DMTracker can learn discriminative representations in complex tracking scenes. Experiments show that our proposed tracker achieves very promising results on challenging RGBD benchmarks.
Automatic Velocity Picking Using a Multi-Information Fusion Deep Semantic Segmentation Network
May 07, 2022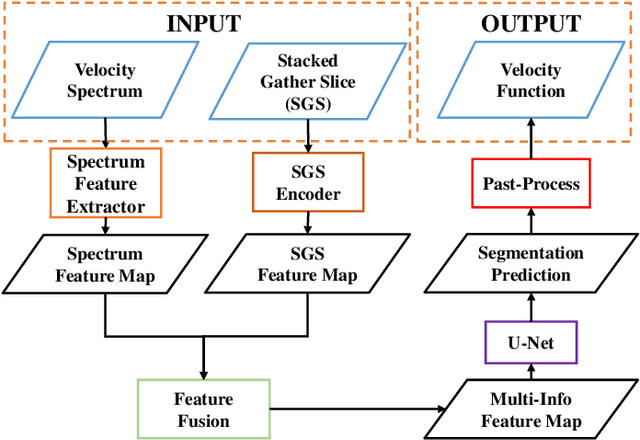

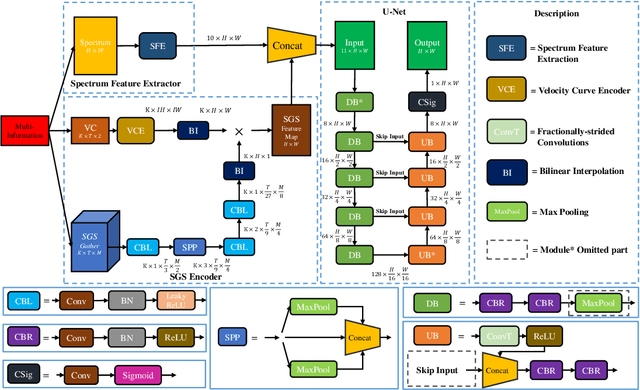
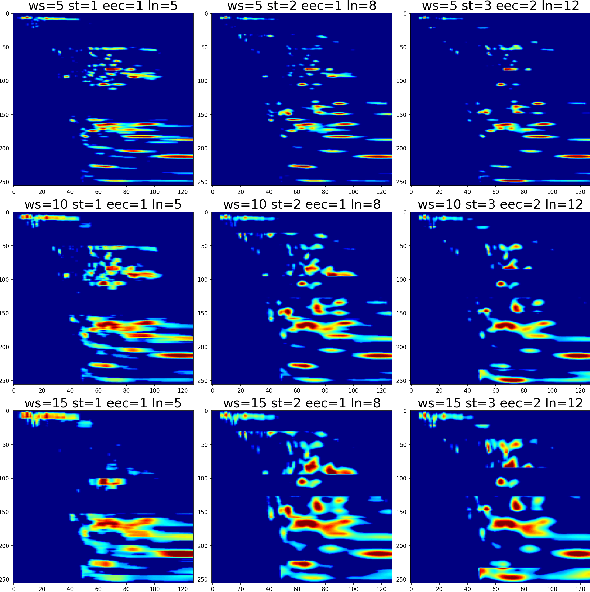
Velocity picking, a critical step in seismic data processing, has been studied for decades. Although manual picking can produce accurate normal moveout (NMO) velocities from the velocity spectra of prestack gathers, it is time-consuming and becomes infeasible with the emergence of large amount of seismic data. Numerous automatic velocity picking methods have thus been developed. In recent years, deep learning (DL) methods have produced good results on the seismic data with medium and high signal-to-noise ratios (SNR). Unfortunately, it still lacks a picking method to automatically generate accurate velocities in the situations of low SNR. In this paper, we propose a multi-information fusion network (MIFN) to estimate stacking velocity from the fusion information of velocity spectra and stack gather segments (SGS). In particular, we transform the velocity picking problem into a semantic segmentation problem based on the velocity spectrum images. Meanwhile, the information provided by SGS is used as a prior in the network to assist segmentation. The experimental results on two field datasets show that the picking results of MIFN are stable and accurate for the scenarios with medium and high SNR, and it also performs well in low SNR scenarios.
Cap4Video: What Can Auxiliary Captions Do for Text-Video Retrieval?
Dec 31, 2022
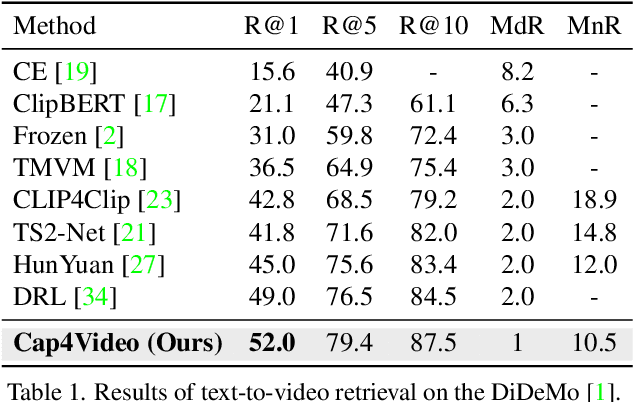
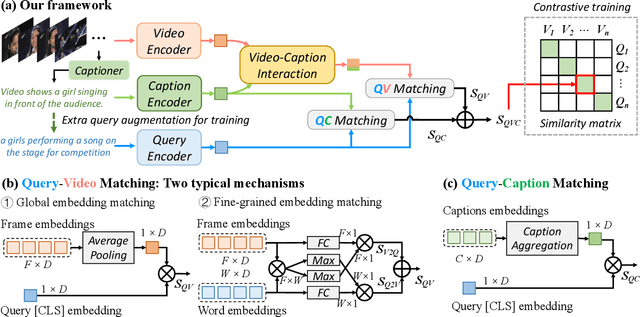
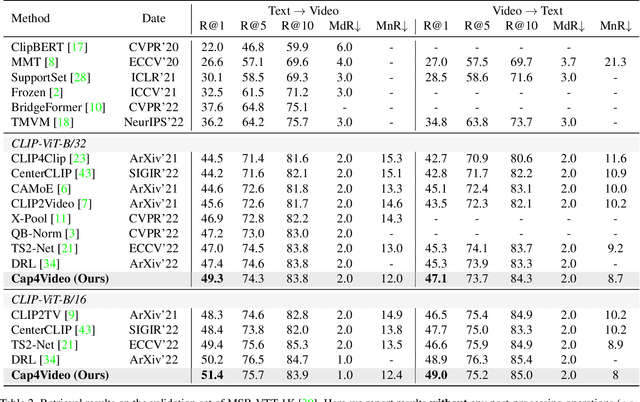
Most existing text-video retrieval methods focus on cross-modal matching between the visual content of offline videos and textual query sentences. However, in real scenarios, online videos are frequently accompanied by relevant text information such as titles, tags, and even subtitles, which can be utilized to match textual queries. This inspires us to generate associated captions from offline videos to help with existing text-video retrieval methods. To do so, we propose to use the zero-shot video captioner with knowledge of pre-trained web-scale models (e.g., CLIP and GPT-2) to generate captions for offline videos without any training. Given the captions, one question naturally arises: what can auxiliary captions do for text-video retrieval? In this paper, we present a novel framework Cap4Video, which makes use of captions from three aspects: i) Input data: The video and captions can form new video-caption pairs as data augmentation for training. ii) Feature interaction: We perform feature interaction between video and caption to yield enhanced video representations. iii) Output score: The Query-Caption matching branch can be complementary to the original Query-Video matching branch for text-video retrieval. We conduct thorough ablation studies to demonstrate the effectiveness of our method. Without any post-processing, our Cap4Video achieves state-of-the-art performance on MSR-VTT (51.4%), VATEX (66.6%), MSVD (51.8%), and DiDeMo (52.0%).
Tracking Passengers and Baggage Items using Multiple Overhead Cameras at Security Checkpoints
Dec 31, 2022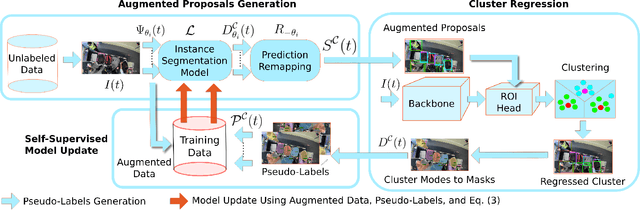


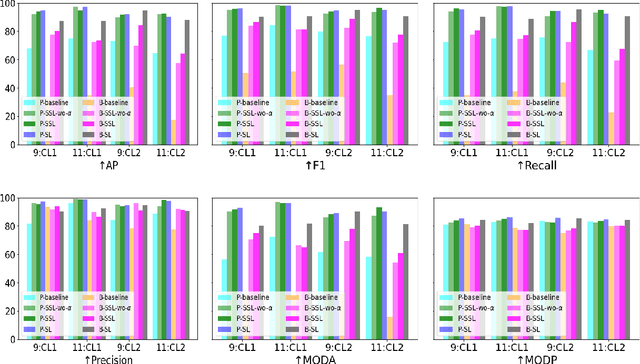
We introduce a novel framework to track multiple objects in overhead camera videos for airport checkpoint security scenarios where targets correspond to passengers and their baggage items. We propose a Self-Supervised Learning (SSL) technique to provide the model information about instance segmentation uncertainty from overhead images. Our SSL approach improves object detection by employing a test-time data augmentation and a regression-based, rotation-invariant pseudo-label refinement technique. Our pseudo-label generation method provides multiple geometrically-transformed images as inputs to a Convolutional Neural Network (CNN), regresses the augmented detections generated by the network to reduce localization errors, and then clusters them using the mean-shift algorithm. The self-supervised detector model is used in a single-camera tracking algorithm to generate temporal identifiers for the targets. Our method also incorporates a multi-view trajectory association mechanism to maintain consistent temporal identifiers as passengers travel across camera views. An evaluation of detection, tracking, and association performances on videos obtained from multiple overhead cameras in a realistic airport checkpoint environment demonstrates the effectiveness of the proposed approach. Our results show that self-supervision improves object detection accuracy by up to $42\%$ without increasing the inference time of the model. Our multi-camera association method achieves up to $89\%$ multi-object tracking accuracy with an average computation time of less than $15$ ms.
* 12 pages, 12 figures. arXiv admin note: text overlap with arXiv:2007.07924
Contextual Bandits and Optimistically Universal Learning
Dec 31, 2022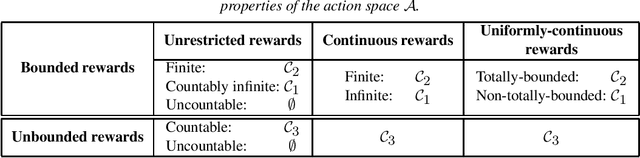
We consider the contextual bandit problem on general action and context spaces, where the learner's rewards depend on their selected actions and an observable context. This generalizes the standard multi-armed bandit to the case where side information is available, e.g., patients' records or customers' history, which allows for personalized treatment. We focus on consistency -- vanishing regret compared to the optimal policy -- and show that for large classes of non-i.i.d. contexts, consistency can be achieved regardless of the time-invariant reward mechanism, a property known as universal consistency. Precisely, we first give necessary and sufficient conditions on the context-generating process for universal consistency to be possible. Second, we show that there always exists an algorithm that guarantees universal consistency whenever this is achievable, called an optimistically universal learning rule. Interestingly, for finite action spaces, learnable processes for universal learning are exactly the same as in the full-feedback setting of supervised learning, previously studied in the literature. In other words, learning can be performed with partial feedback without any generalization cost. The algorithms balance a trade-off between generalization (similar to structural risk minimization) and personalization (tailoring actions to specific contexts). Lastly, we consider the case of added continuity assumptions on rewards and show that these lead to universal consistency for significantly larger classes of data-generating processes.
Domain-general Crowd Counting in Unseen Scenarios
Dec 05, 2022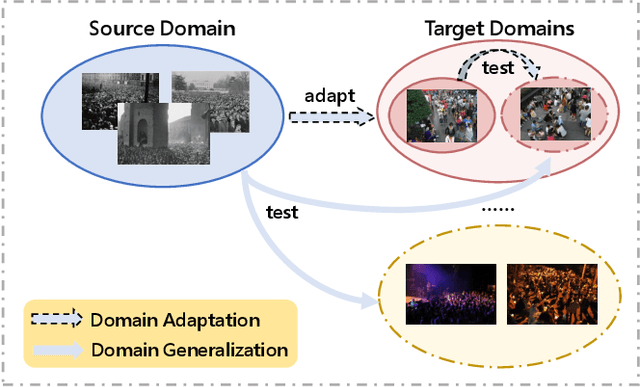
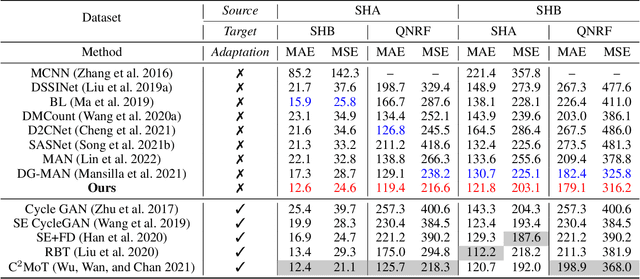
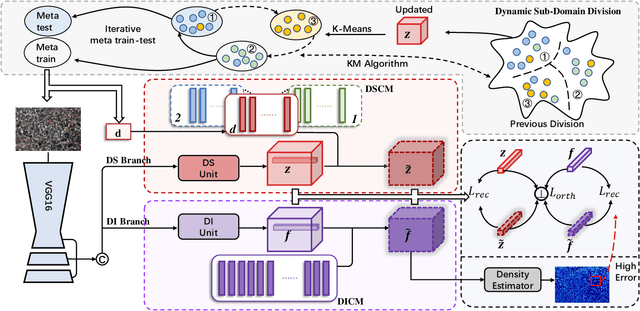
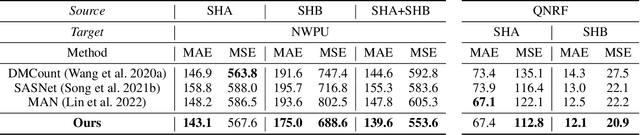
Domain shift across crowd data severely hinders crowd counting models to generalize to unseen scenarios. Although domain adaptive crowd counting approaches close this gap to a certain extent, they are still dependent on the target domain data to adapt (e.g. finetune) their models to the specific domain. In this paper, we aim to train a model based on a single source domain which can generalize well on any unseen domain. This falls into the realm of domain generalization that remains unexplored in crowd counting. We first introduce a dynamic sub-domain division scheme which divides the source domain into multiple sub-domains such that we can initiate a meta-learning framework for domain generalization. The sub-domain division is dynamically refined during the meta-learning. Next, in order to disentangle domain-invariant information from domain-specific information in image features, we design the domain-invariant and -specific crowd memory modules to re-encode image features. Two types of losses, i.e. feature reconstruction and orthogonal losses, are devised to enable this disentanglement. Extensive experiments on several standard crowd counting benchmarks i.e. SHA, SHB, QNRF, and NWPU, show the strong generalizability of our method.
Automatic Anomalies Detection in Hydraulic Devices
Dec 05, 2022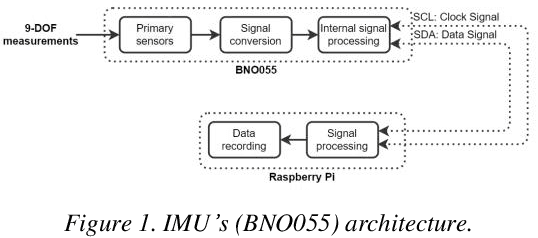

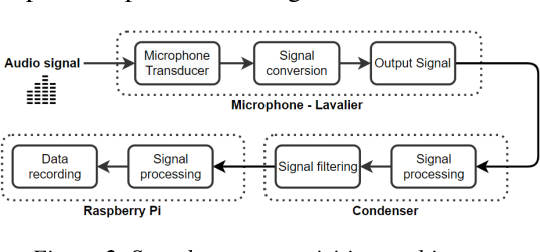

Nowadays, the applications of hydraulic systems are present in a wide variety of devices in both industrial and everyday environments. The implementation and usage of hydraulic systems have been well documented; however, today, this still faces a challenge, the integration of tools that allow more accurate information about the functioning and operation of these systems for proactive decision-making. In industrial applications, many sensors and methods exist to measure and determine the status of process variables (e.g., flow, pressure, force). Nevertheless, little has been done to have systems that can provide users with device-health information related to hydraulic devices integrated into the machinery. Implementing artificial intelligence (AI) technologies and machine learning (ML) models in hydraulic system components has been identified as a solution to the challenge many industries currently face: optimizing processes and carrying them out more safely and efficiently. This paper presents a solution for the characterization and estimation of anomalies in one of the most versatile and used devices in hydraulic systems, cylinders. AI and ML models were implemented to determine the current operating status of these hydraulic components and whether they are working correctly or if a failure mode or abnormal condition is present.
An Unpaired Cross-modality Segmentation Framework Using Data Augmentation and Hybrid Convolutional Networks for Segmenting Vestibular Schwannoma and Cochlea
Nov 28, 2022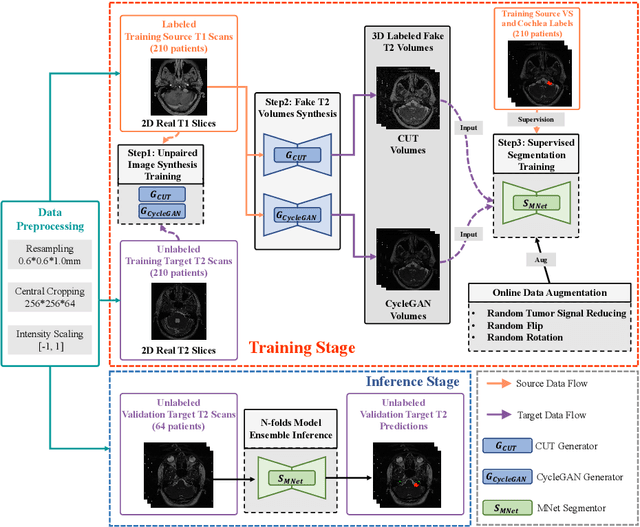
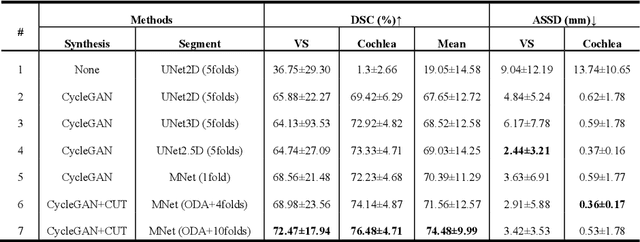
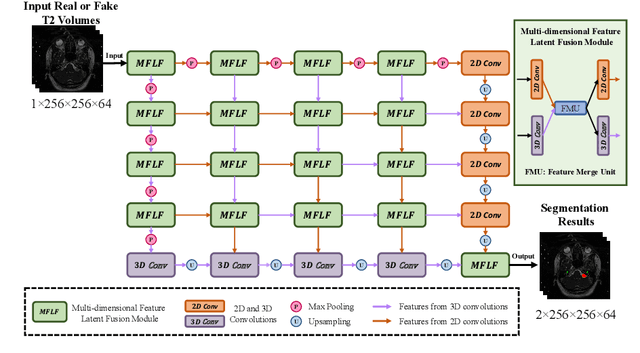
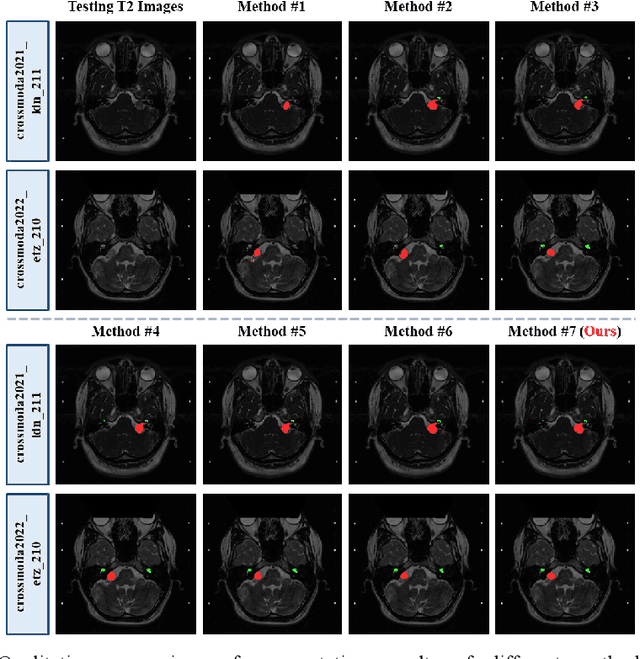
The crossMoDA challenge aims to automatically segment the vestibular schwannoma (VS) tumor and cochlea regions of unlabeled high-resolution T2 scans by leveraging labeled contrast-enhanced T1 scans. The 2022 edition extends the segmentation task by including multi-institutional scans. In this work, we proposed an unpaired cross-modality segmentation framework using data augmentation and hybrid convolutional networks. Considering heterogeneous distributions and various image sizes for multi-institutional scans, we apply the min-max normalization for scaling the intensities of all scans between -1 and 1, and use the voxel size resampling and center cropping to obtain fixed-size sub-volumes for training. We adopt two data augmentation methods for effectively learning the semantic information and generating realistic target domain scans: generative and online data augmentation. For generative data augmentation, we use CUT and CycleGAN to generate two groups of realistic T2 volumes with different details and appearances for supervised segmentation training. For online data augmentation, we design a random tumor signal reducing method for simulating the heterogeneity of VS tumor signals. Furthermore, we utilize an advanced hybrid convolutional network with multi-dimensional convolutions to adaptively learn sparse inter-slice information and dense intra-slice information for accurate volumetric segmentation of VS tumor and cochlea regions in anisotropic scans. On the crossMoDA2022 validation dataset, our method produces promising results and achieves the mean DSC values of 72.47% and 76.48% and ASSD values of 3.42 mm and 0.53 mm for VS tumor and cochlea regions, respectively.
Teaching Matters: Investigating the Role of Supervision in Vision Transformers
Dec 07, 2022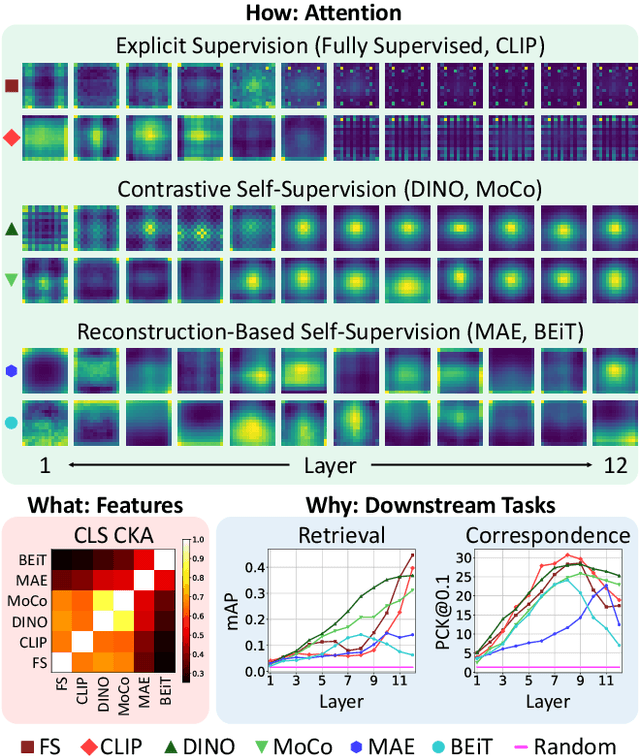
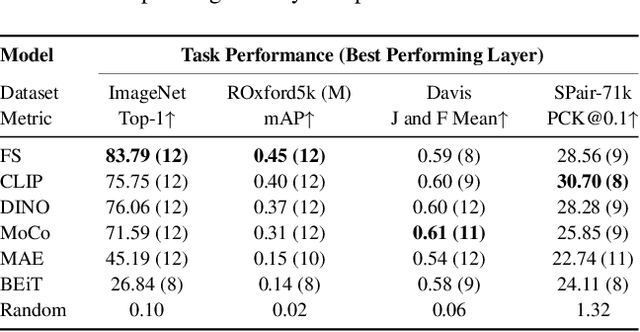

Vision Transformers (ViTs) have gained significant popularity in recent years and have proliferated into many applications. However, it is not well explored how varied their behavior is under different learning paradigms. We compare ViTs trained through different methods of supervision, and show that they learn a diverse range of behaviors in terms of their attention, representations, and downstream performance. We also discover ViT behaviors that are consistent across supervision, including the emergence of Offset Local Attention Heads. These are self-attention heads that attend to a token adjacent to the current token with a fixed directional offset, a phenomenon that to the best of our knowledge has not been highlighted in any prior work. Our analysis shows that ViTs are highly flexible and learn to process local and global information in different orders depending on their training method. We find that contrastive self-supervised methods learn features that are competitive with explicitly supervised features, and they can even be superior for part-level tasks. We also find that the representations of reconstruction-based models show non-trivial similarity to contrastive self-supervised models. Finally, we show how the "best" layer for a given task varies by both supervision method and task, further demonstrating the differing order of information processing in ViTs.
Towards Automatic Cetacean Photo-Identification: A Framework for Fine-Grain, Few-Shot Learning in Marine Ecology
Dec 07, 2022

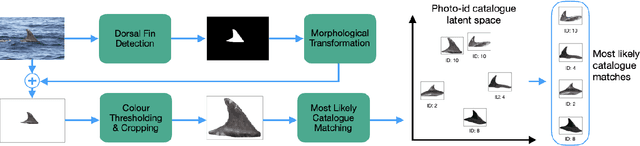
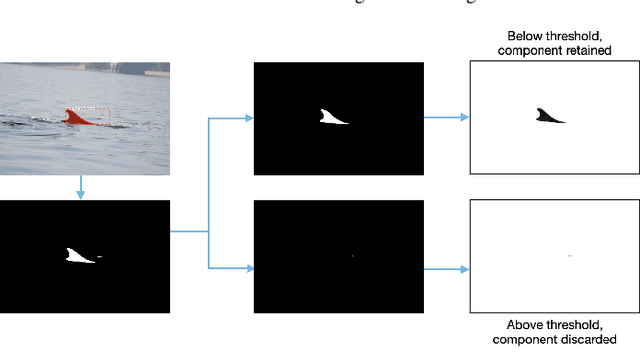
Photo-identification (photo-id) is one of the main non-invasive capture-recapture methods utilised by marine researchers for monitoring cetacean (dolphin, whale, and porpoise) populations. This method has historically been performed manually resulting in high workload and cost due to the vast number of images collected. Recently automated aids have been developed to help speed-up photo-id, although they are often disjoint in their processing and do not utilise all available identifying information. Work presented in this paper aims to create a fully automatic photo-id aid capable of providing most likely matches based on all available information without the need for data pre-processing such as cropping. This is achieved through a pipeline of computer vision models and post-processing techniques aimed at detecting cetaceans in unedited field imagery before passing them downstream for individual level catalogue matching. The system is capable of handling previously uncatalogued individuals and flagging these for investigation thanks to catalogue similarity comparison. We evaluate the system against multiple real-life photo-id catalogues, achieving mAP@IOU[0.5] = 0.91, 0.96 for the task of dorsal fin detection on catalogues from Tanzania and the UK respectively and 83.1, 97.5% top-10 accuracy for the task of individual classification on catalogues from the UK and USA.