 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
CGI-Stereo: Accurate and Real-Time Stereo Matching via Context and Geometry Interaction
Jan 07, 2023

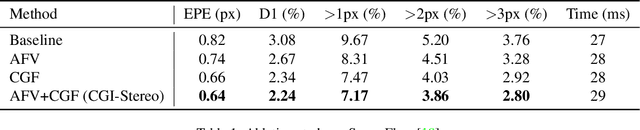
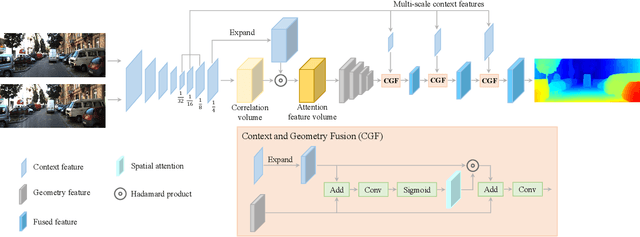
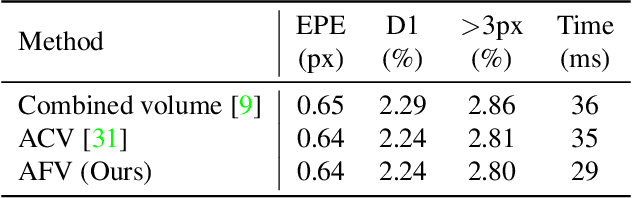
In this paper, we propose CGI-Stereo, a novel neural network architecture that can concurrently achieve real-time performance, state-of-the-art accuracy, and strong generalization ability. The core of our CGI-Stereo is a Context and Geometry Fusion (CGF) block which adaptively fuses context and geometry information for more accurate and efficient cost aggregation and meanwhile provides feedback to feature learning to guide more effective contextual feature extraction. The proposed CGF can be easily embedded into many existing stereo matching networks, such as PSMNet, GwcNet and ACVNet. The resulting networks are improved in accuracy by a large margin. Specially, the model which integrates our CGF with ACVNet could rank 1st on the KITTI 2012 leaderboard among all the published methods. We further propose an informative and concise cost volume, named Attention Feature Volume (AFV), which exploits a correlation volume as attention weights to filter a feature volume. Based on CGF and AFV, the proposed CGI-Stereo outperforms all other published real-time methods on KITTI benchmarks and shows better generalization ability than other real-time methods. The code is available at https://github.com/gangweiX/CGI-Stereo.
Radio technologies for environment-aware wireless communications
Nov 30, 2022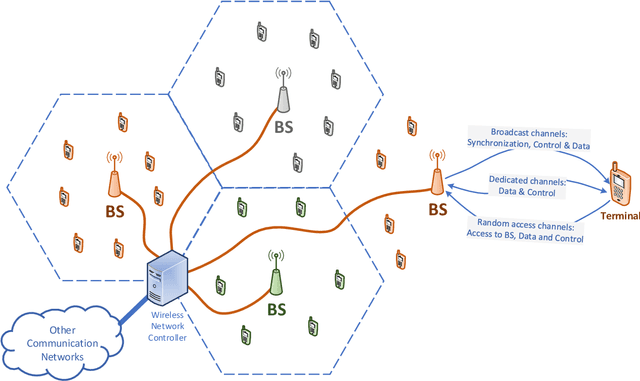
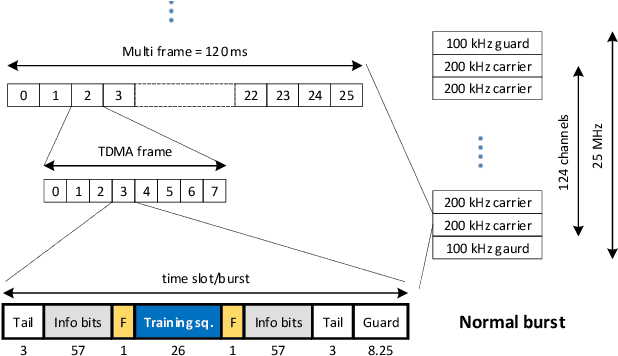
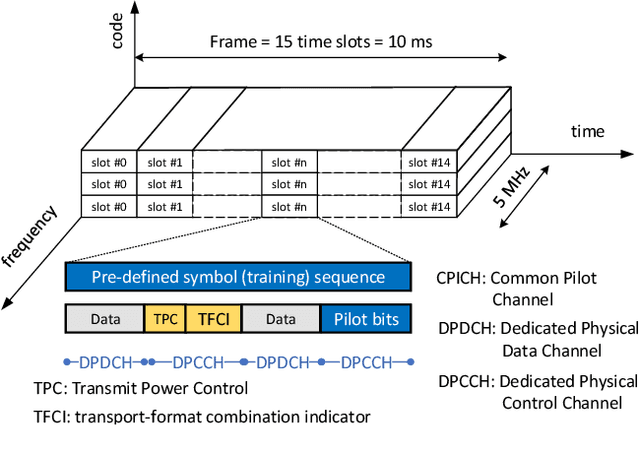
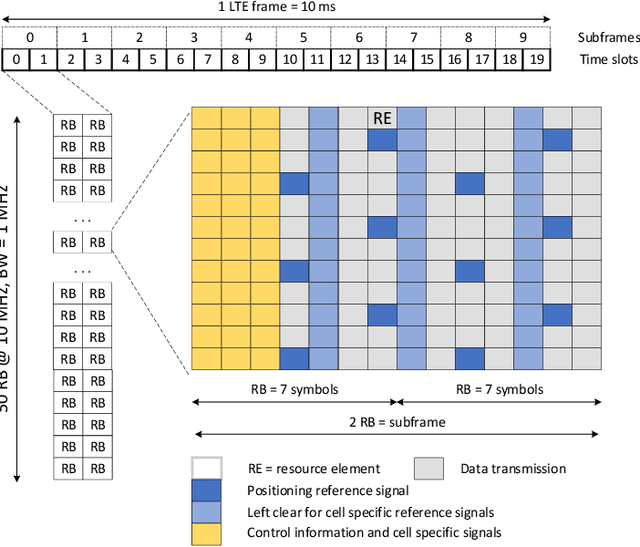
In this paper, we critically review the potential of today's terrestrial wireless communication systems including wireless cellular technologies (GSM, UMTS, LTE, NR), wireless local area networks (WLANs), and wireless sensor networks (WSNs), for estimating channel state information (CSI), the ratio between training and information symbols and the rate of channel variation, and the potential use of CSI in environment aware wireless communications. The research reveals, that early communication systems provide means for narrowband channel estimation and the CSI is only available as channel attenuation based on signal level measurements. By increasing the spectral bandwidth of communications, the CSI is estimated in some form of channel impulse response (CIR) in almost all currently used radio technologies, but this information is generally not available outside the communication systems. Also, the CSI is estimated only for the channel with active communications. The new radio technology (NR) offers the possibility of estimating the CIR for non-active channels as well, and thus the possibility of initiating environmentally aware wireless communications.
Tracking by Associating Clips
Dec 20, 2022The tracking-by-detection paradigm today has become the dominant method for multi-object tracking and works by detecting objects in each frame and then performing data association across frames. However, its sequential frame-wise matching property fundamentally suffers from the intermediate interruptions in a video, such as object occlusions, fast camera movements, and abrupt light changes. Moreover, it typically overlooks temporal information beyond the two frames for matching. In this paper, we investigate an alternative by treating object association as clip-wise matching. Our new perspective views a single long video sequence as multiple short clips, and then the tracking is performed both within and between the clips. The benefits of this new approach are two folds. First, our method is robust to tracking error accumulation or propagation, as the video chunking allows bypassing the interrupted frames, and the short clip tracking avoids the conventional error-prone long-term track memory management. Second, the multiple frame information is aggregated during the clip-wise matching, resulting in a more accurate long-range track association than the current frame-wise matching. Given the state-of-the-art tracking-by-detection tracker, QDTrack, we showcase how the tracking performance improves with our new tracking formulation. We evaluate our proposals on two tracking benchmarks, TAO and MOT17 that have complementary characteristics and challenges each other.
AnnoBERT: Effectively Representing Multiple Annotators' Label Choices to Improve Hate Speech Detection
Dec 20, 2022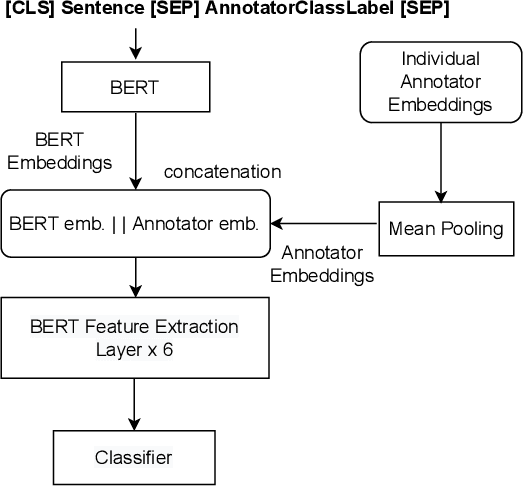

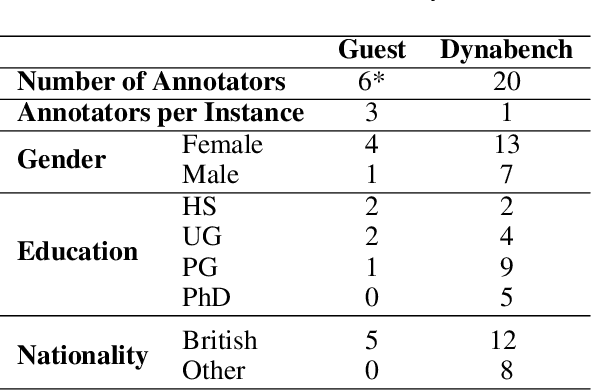
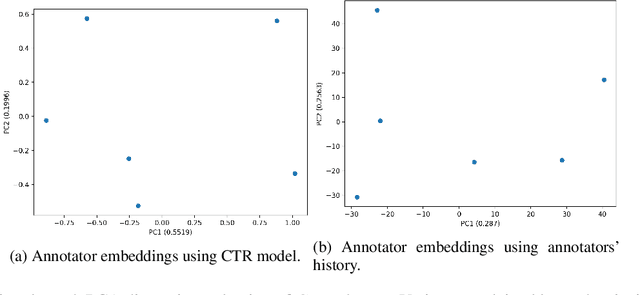
Supervised approaches generally rely on majority-based labels. However, it is hard to achieve high agreement among annotators in subjective tasks such as hate speech detection. Existing neural network models principally regard labels as categorical variables, while ignoring the semantic information in diverse label texts. In this paper, we propose AnnoBERT, a first-of-its-kind architecture integrating annotator characteristics and label text with a transformer-based model to detect hate speech, with unique representations based on each annotator's characteristics via Collaborative Topic Regression (CTR) and integrate label text to enrich textual representations. During training, the model associates annotators with their label choices given a piece of text; during evaluation, when label information is not available, the model predicts the aggregated label given by the participating annotators by utilising the learnt association. The proposed approach displayed an advantage in detecting hate speech, especially in the minority class and edge cases with annotator disagreement. Improvement in the overall performance is the largest when the dataset is more label-imbalanced, suggesting its practical value in identifying real-world hate speech, as the volume of hate speech in-the-wild is extremely small on social media, when compared with normal (non-hate) speech. Through ablation studies, we show the relative contributions of annotator embeddings and label text to the model performance, and tested a range of alternative annotator embeddings and label text combinations.
* accepted at ICWSM 2023
Improving Keyphrase Extraction with Data Augmentation and Information Filtering
Sep 11, 2022


Keyphrase extraction is one of the essential tasks for document understanding in NLP. While the majority of the prior works are dedicated to the formal setting, e.g., books, news or web-blogs, informal texts such as video transcripts are less explored. To address this limitation, in this work we present a novel corpus and method for keyphrase extraction from the transcripts of the videos streamed on the Behance platform. More specifically, in this work, a novel data augmentation is proposed to enrich the model with the background knowledge about the keyphrase extraction task from other domains. Extensive experiments on the proposed dataset dataset show the effectiveness of the introduced method.
Multi-Task Learning for Sparsity Pattern Heterogeneity: A Discrete Optimization Approach
Dec 16, 2022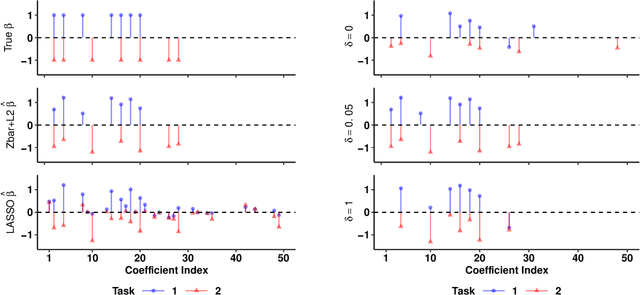

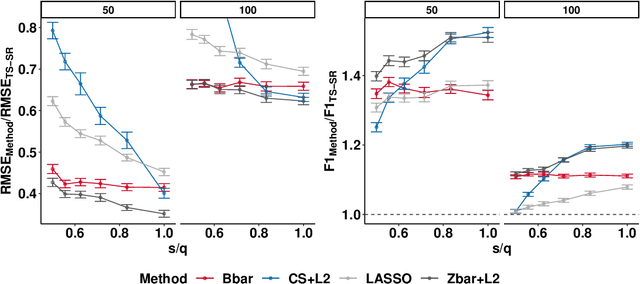
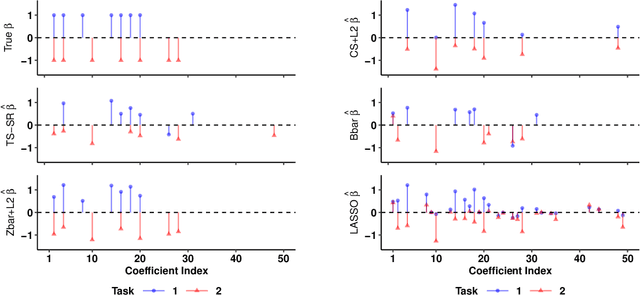
We extend best-subset selection to linear Multi-Task Learning (MTL), where a set of linear models are jointly trained on a collection of datasets (``tasks''). Allowing the regression coefficients of tasks to have different sparsity patterns (i.e., different supports), we propose a modeling framework for MTL that encourages models to share information across tasks, for a given covariate, through separately 1) shrinking the coefficient supports together, and/or 2) shrinking the coefficient values together. This allows models to borrow strength during variable selection even when the coefficient values differ markedly between tasks. We express our modeling framework as a Mixed-Integer Program, and propose efficient and scalable algorithms based on block coordinate descent and combinatorial local search. We show our estimator achieves statistically optimal prediction rates. Importantly, our theory characterizes how our estimator leverages the shared support information across tasks to achieve better variable selection performance. We evaluate the performance of our method in simulations and two biology applications. Our proposed approaches outperform other sparse MTL methods in variable selection and prediction accuracy. Interestingly, penalties that shrink the supports together often outperform penalties that shrink the coefficient values together. We will release an R package implementing our methods.
Information-driven Path Planning for Hybrid Aerial Underwater Vehicles
Apr 08, 2022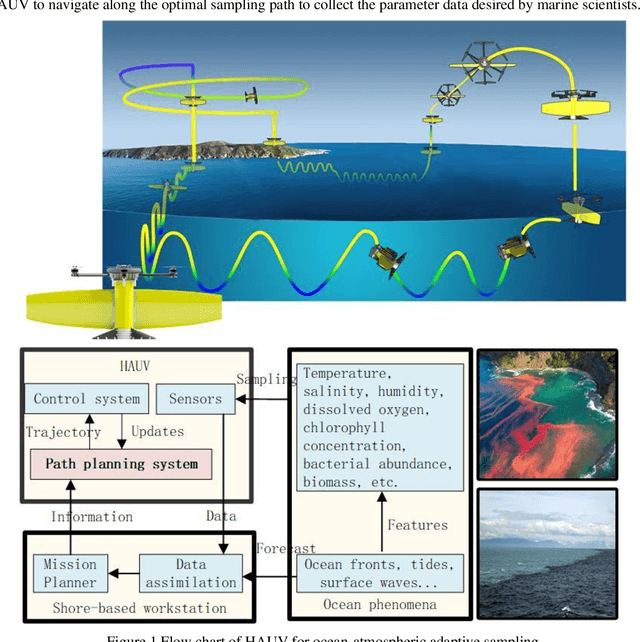
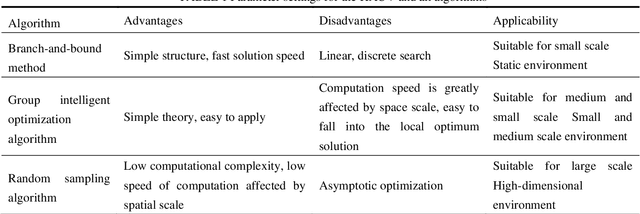

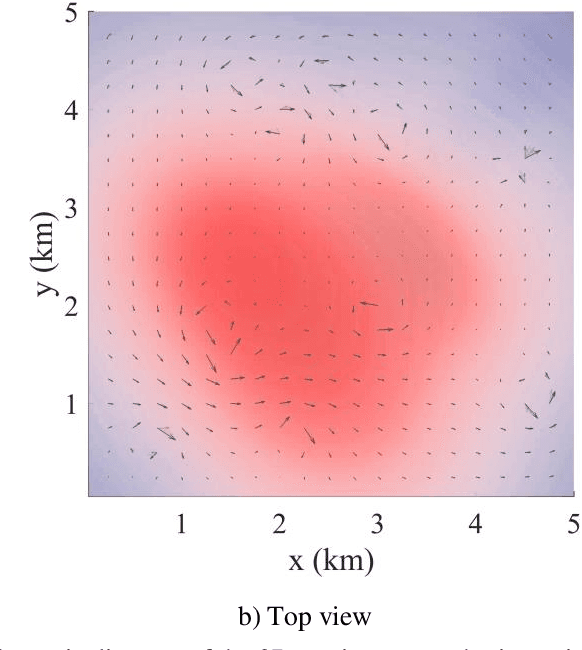
This paper presents a novel Rapidly-exploring Adaptive Sampling Tree (RAST) algorithm for the adaptive sampling mission of a hybrid aerial underwater vehicle (HAUV) in an air-sea 3D environment. This algorithm innovatively combines the tournament-based point selection sampling strategy, the information heuristic search process and the framework of Rapidly-exploring Random Tree (RRT) algorithm. Hence can guide the vehicle to the region of interest to scientists for sampling and generate a collision-free path for maximizing information collection by the HAUV under the constraints of environmental effects of currents or wind and limited budget. The simulation results show that the fast search adaptive sampling tree algorithm has higher optimization performance, faster solution speed and better stability than the Rapidly-exploring Information Gathering Tree (RIGT) algorithm and the particle swarm optimization (PSO) algorithm.
PrivacyProber: Assessment and Detection of Soft-Biometric Privacy-Enhancing Techniques
Nov 22, 2022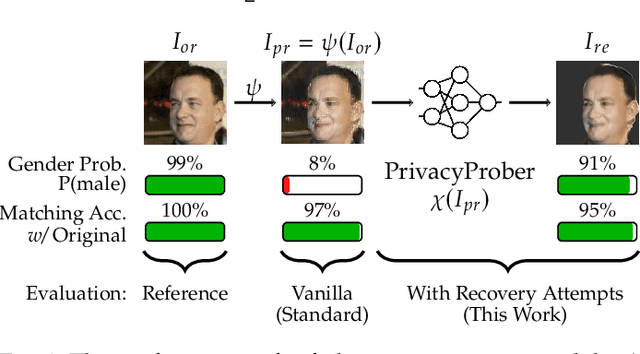

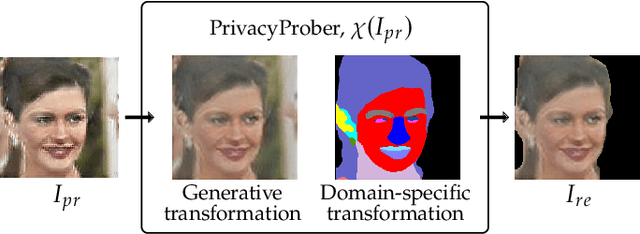
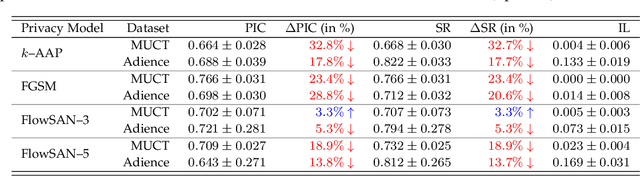
Soft-biometric privacy-enhancing techniques represent machine learning methods that aim to: (i) mitigate privacy concerns associated with face recognition technology by suppressing selected soft-biometric attributes in facial images (e.g., gender, age, ethnicity) and (ii) make unsolicited extraction of sensitive personal information infeasible. Because such techniques are increasingly used in real-world applications, it is imperative to understand to what extent the privacy enhancement can be inverted and how much attribute information can be recovered from privacy-enhanced images. While these aspects are critical, they have not been investigated in the literature. We, therefore, study the robustness of several state-of-the-art soft-biometric privacy-enhancing techniques to attribute recovery attempts. We propose PrivacyProber, a high-level framework for restoring soft-biometric information from privacy-enhanced facial images, and apply it for attribute recovery in comprehensive experiments on three public face datasets, i.e., LFW, MUCT and Adience. Our experiments show that the proposed framework is able to restore a considerable amount of suppressed information, regardless of the privacy-enhancing technique used, but also that there are significant differences between the considered privacy models. These results point to the need for novel mechanisms that can improve the robustness of existing privacy-enhancing techniques and secure them against potential adversaries trying to restore suppressed information.
An Attention-based Multi-Scale Feature Learning Network for Multimodal Medical Image Fusion
Dec 09, 2022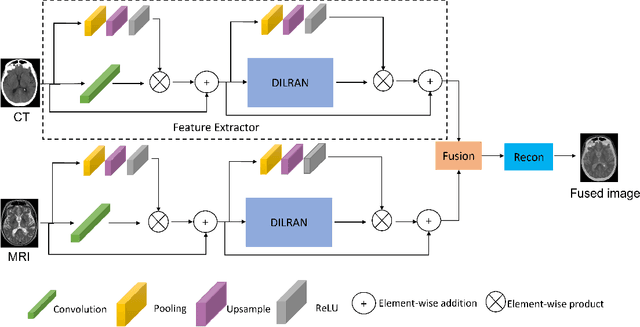
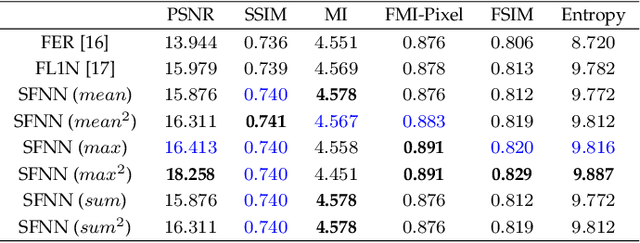
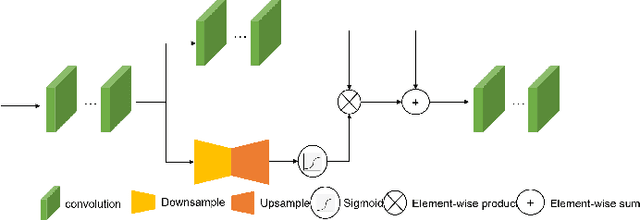
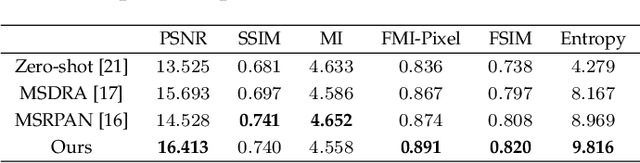
Medical images play an important role in clinical applications. Multimodal medical images could provide rich information about patients for physicians to diagnose. The image fusion technique is able to synthesize complementary information from multimodal images into a single image. This technique will prevent radiologists switch back and forth between different images and save lots of time in the diagnostic process. In this paper, we introduce a novel Dilated Residual Attention Network for the medical image fusion task. Our network is capable to extract multi-scale deep semantic features. Furthermore, we propose a novel fixed fusion strategy termed Softmax-based weighted strategy based on the Softmax weights and matrix nuclear norm. Extensive experiments show our proposed network and fusion strategy exceed the state-of-the-art performance compared with reference image fusion methods on four commonly used fusion metrics.
Adaptive Context Selection for Polyp Segmentation
Jan 12, 2023Accurate polyp segmentation is of great significance for the diagnosis and treatment of colorectal cancer. However, it has always been very challenging due to the diverse shape and size of polyp. In recent years, state-of-the-art methods have achieved significant breakthroughs in this task with the help of deep convolutional neural networks. However, few algorithms explicitly consider the impact of the size and shape of the polyp and the complex spatial context on the segmentation performance, which results in the algorithms still being powerless for complex samples. In fact, segmentation of polyps of different sizes relies on different local and global contextual information for regional contrast reasoning. To tackle these issues, we propose an adaptive context selection based encoder-decoder framework which is composed of Local Context Attention (LCA) module, Global Context Module (GCM) and Adaptive Selection Module (ASM). Specifically, LCA modules deliver local context features from encoder layers to decoder layers, enhancing the attention to the hard region which is determined by the prediction map of previous layer. GCM aims to further explore the global context features and send to the decoder layers. ASM is used for adaptive selection and aggregation of context features through channel-wise attention. Our proposed approach is evaluated on the EndoScene and Kvasir-SEG Datasets, and shows outstanding performance compared with other state-of-the-art methods. The code is available at https://github.com/ReaFly/ACSNet.