 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Incorporating Polar Field Data for Improved Solar Flare Prediction
Dec 04, 2022
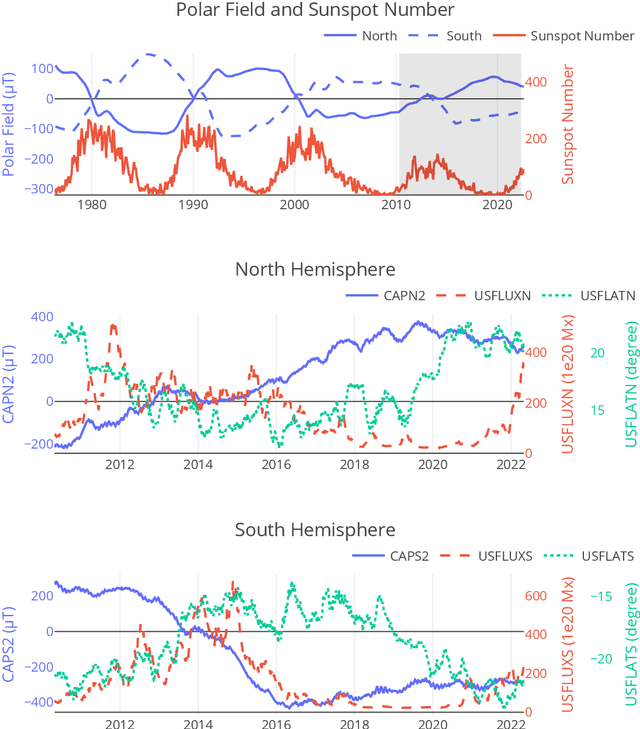
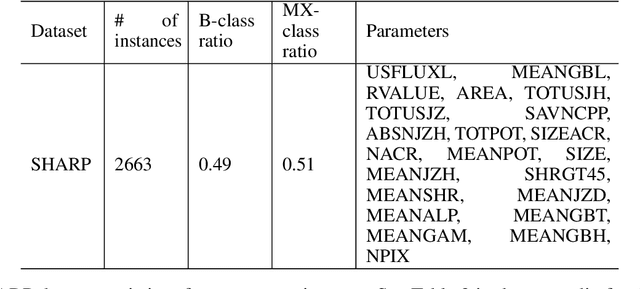
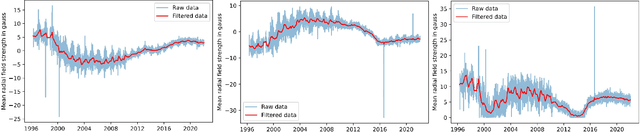
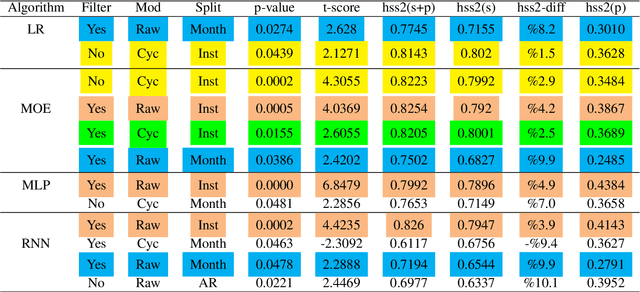
In this paper, we consider incorporating data associated with the sun's north and south polar field strengths to improve solar flare prediction performance using machine learning models. When used to supplement local data from active regions on the photospheric magnetic field of the sun, the polar field data provides global information to the predictor. While such global features have been previously proposed for predicting the next solar cycle's intensity, in this paper we propose using them to help classify individual solar flares. We conduct experiments using HMI data employing four different machine learning algorithms that can exploit polar field information. Additionally, we propose a novel probabilistic mixture of experts model that can simply and effectively incorporate polar field data and provide on-par prediction performance with state-of-the-art solar flare prediction algorithms such as the Recurrent Neural Network (RNN). Our experimental results indicate the usefulness of the polar field data for solar flare prediction, which can improve Heidke Skill Score (HSS2) by as much as 10.1%.
FreeVC: Towards High-Quality Text-Free One-Shot Voice Conversion
Oct 27, 2022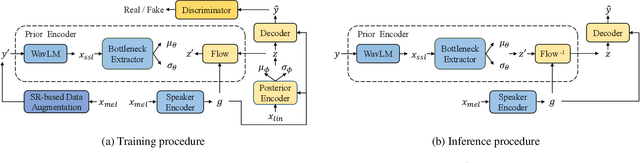
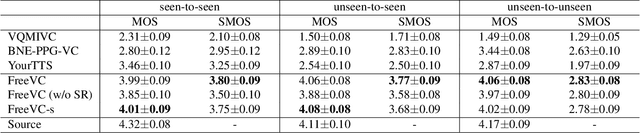
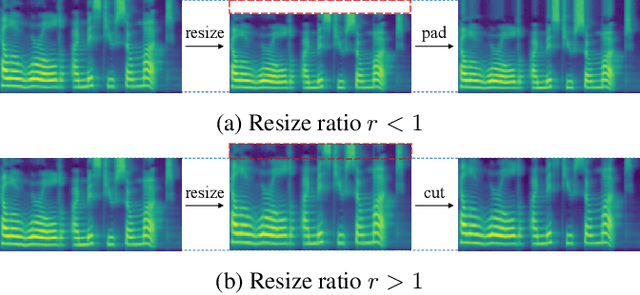
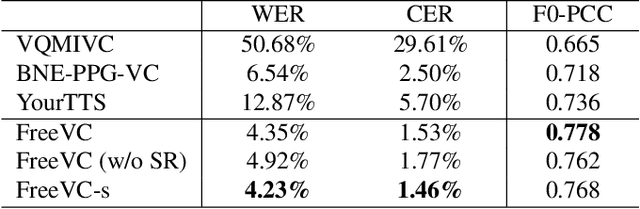
Voice conversion (VC) can be achieved by first extracting source content information and target speaker information, and then reconstructing waveform with these information. However, current approaches normally either extract dirty content information with speaker information leaked in, or demand a large amount of annotated data for training. Besides, the quality of reconstructed waveform can be degraded by the mismatch between conversion model and vocoder. In this paper, we adopt the end-to-end framework of VITS for high-quality waveform reconstruction, and propose strategies for clean content information extraction without text annotation. We disentangle content information by imposing an information bottleneck to WavLM features, and propose the spectrogram-resize based data augmentation to improve the purity of extracted content information. Experimental results show that the proposed method outperforms the latest VC models trained with annotated data and has greater robustness.
SATVSR: Scenario Adaptive Transformer for Cross Scenarios Video Super-Resolution
Nov 16, 2022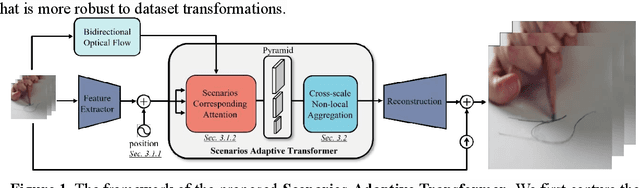

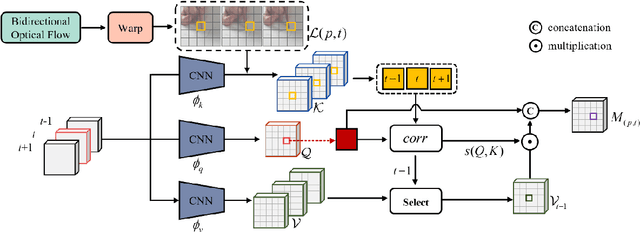

Video Super-Resolution (VSR) aims to recover sequences of high-resolution (HR) frames from low-resolution (LR) frames. Previous methods mainly utilize temporally adjacent frames to assist the reconstruction of target frames. However, in the real world, there is a lot of irrelevant information in adjacent frames of videos with fast scene switching, these VSR methods cannot adaptively distinguish and select useful information. In contrast, with a transformer structure suitable for temporal tasks, we devise a novel adaptive scenario video super-resolution method. Specifically, we use optical flow to label the patches in each video frame, only calculate the attention of patches with the same label. Then select the most relevant label among them to supplement the spatial-temporal information of the target frame. This design can directly make the supplementary information come from the same scene as much as possible. We further propose a cross-scale feature aggregation module to better handle the scale variation problem. Compared with other video super-resolution methods, our method not only achieves significant performance gains on single-scene videos but also has better robustness on cross-scene datasets.
Mimicking non-ideal instrument behavior for hologram processing using neural style translation
Jan 07, 2023

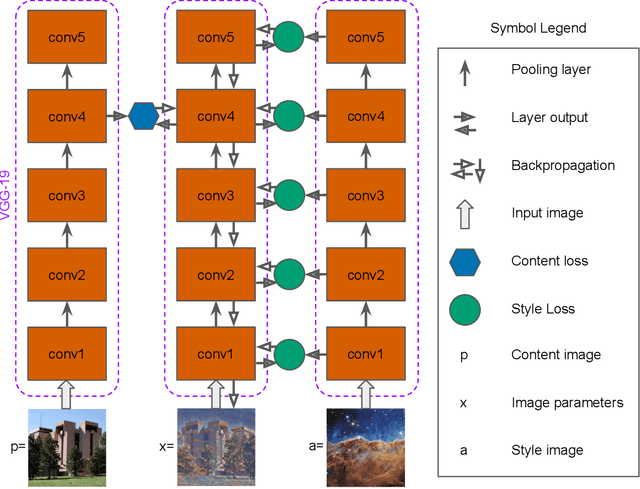
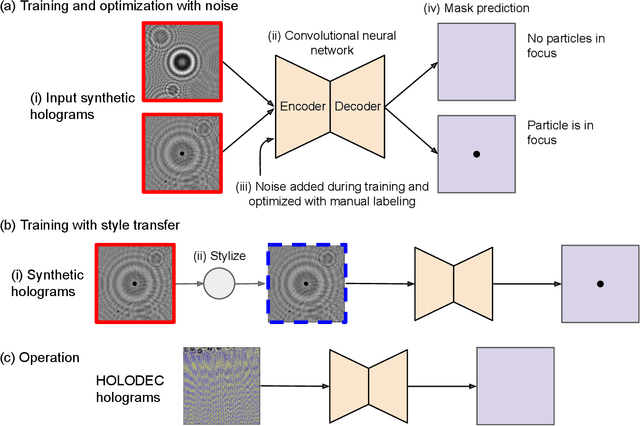
Holographic cloud probes provide unprecedented information on cloud particle density, size and position. Each laser shot captures particles within a large volume, where images can be computationally refocused to determine particle size and shape. However, processing these holograms, either with standard methods or with machine learning (ML) models, requires considerable computational resources, time and occasional human intervention. ML models are trained on simulated holograms obtained from the physical model of the probe since real holograms have no absolute truth labels. Using another processing method to produce labels would be subject to errors that the ML model would subsequently inherit. Models perform well on real holograms only when image corruption is performed on the simulated images during training, thereby mimicking non-ideal conditions in the actual probe (Schreck et. al, 2022). Optimizing image corruption requires a cumbersome manual labeling effort. Here we demonstrate the application of the neural style translation approach (Gatys et. al, 2016) to the simulated holograms. With a pre-trained convolutional neural network (VGG-19), the simulated holograms are ``stylized'' to resemble the real ones obtained from the probe, while at the same time preserving the simulated image ``content'' (e.g. the particle locations and sizes). Two image similarity metrics concur that the stylized images are more like real holograms than the synthetic ones. With an ML model trained to predict particle locations and shapes on the stylized data sets, we observed comparable performance on both simulated and real holograms, obviating the need to perform manual labeling. The described approach is not specific to hologram images and could be applied in other domains for capturing noise and imperfections in observational instruments to make simulated data more like real world observations.
Transformer and GAN Based Super-Resolution Reconstruction Network for Medical Images
Dec 26, 2022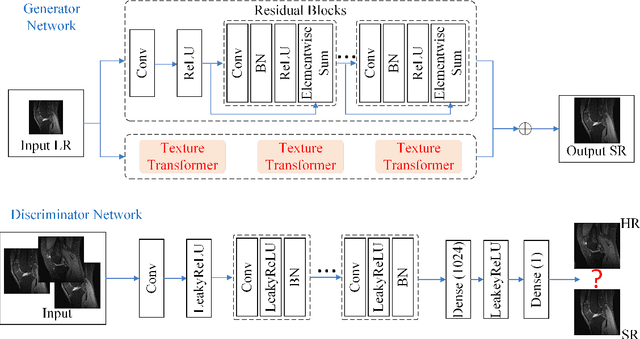
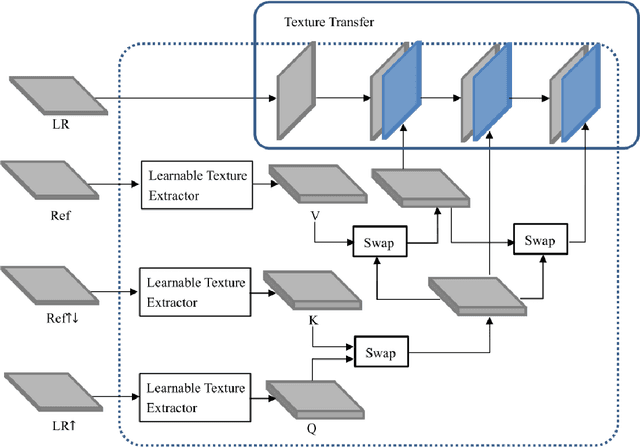
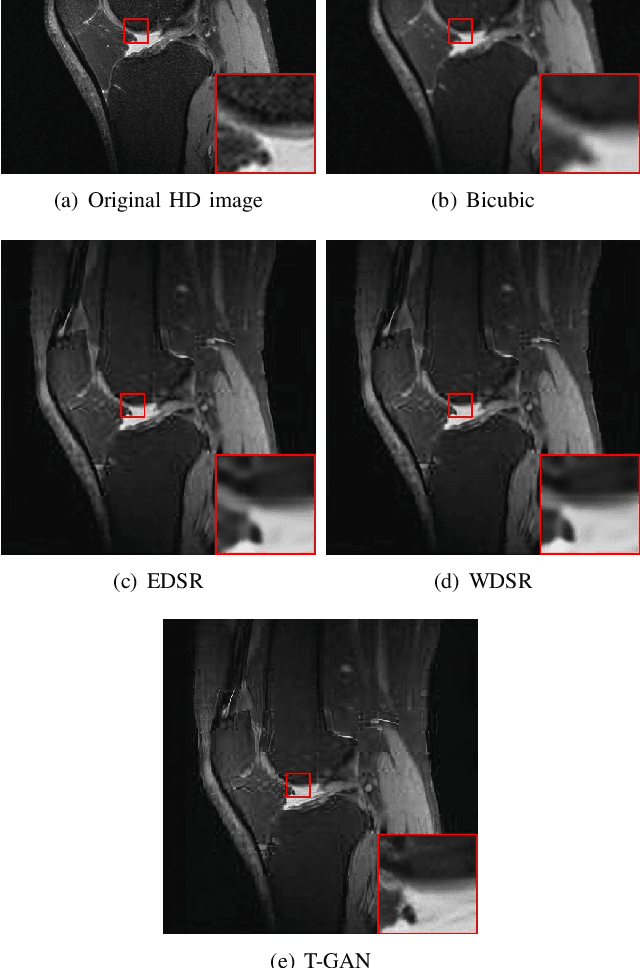
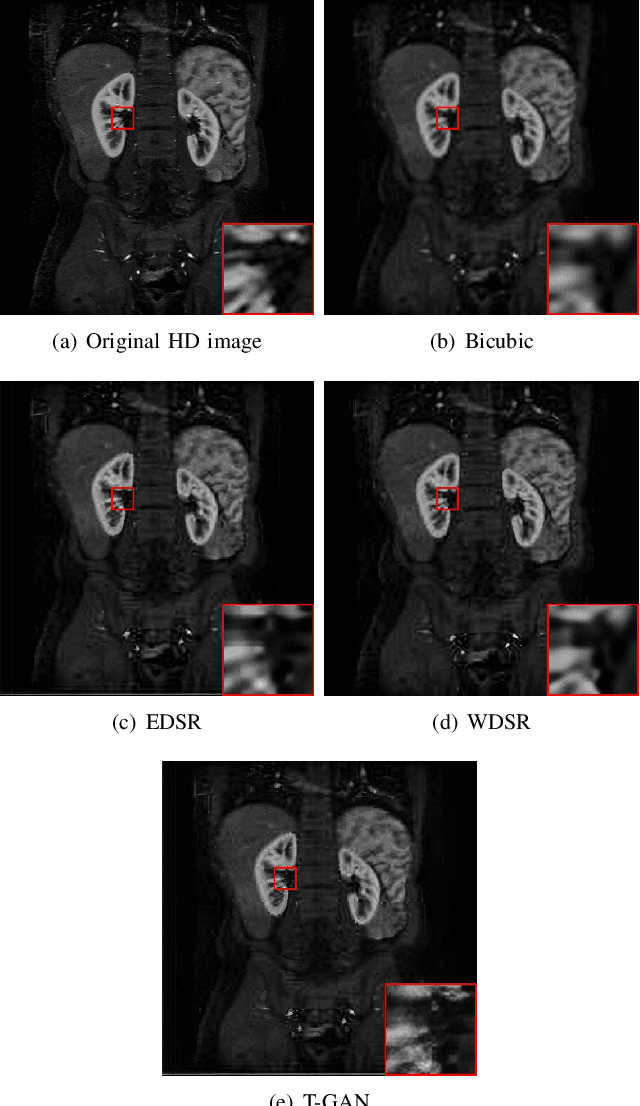
Because of the necessity to obtain high-quality images with minimal radiation doses, such as in low-field magnetic resonance imaging, super-resolution reconstruction in medical imaging has become more popular (MRI). However, due to the complexity and high aesthetic requirements of medical imaging, image super-resolution reconstruction remains a difficult challenge. In this paper, we offer a deep learning-based strategy for reconstructing medical images from low resolutions utilizing Transformer and Generative Adversarial Networks (T-GAN). The integrated system can extract more precise texture information and focus more on important locations through global image matching after successfully inserting Transformer into the generative adversarial network for picture reconstruction. Furthermore, we weighted the combination of content loss, adversarial loss, and adversarial feature loss as the final multi-task loss function during the training of our proposed model T-GAN. In comparison to established measures like PSNR and SSIM, our suggested T-GAN achieves optimal performance and recovers more texture features in super-resolution reconstruction of MRI scanned images of the knees and belly.
Link-level simulator for 5G localization
Dec 26, 2022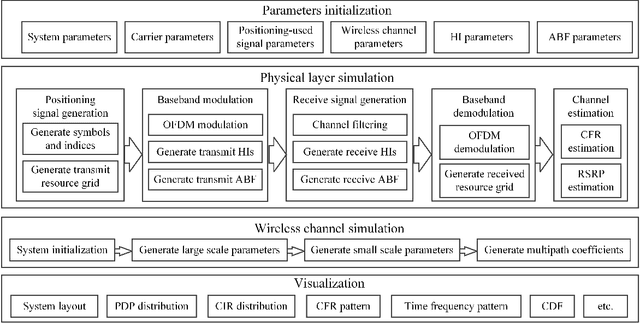
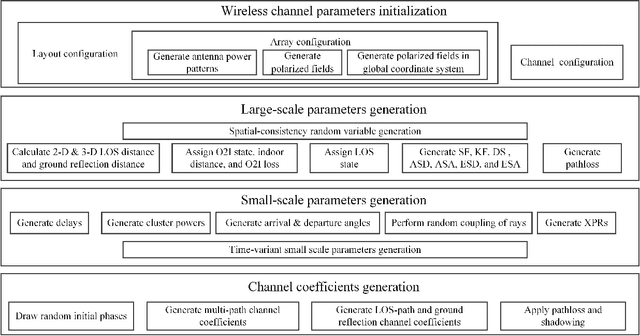
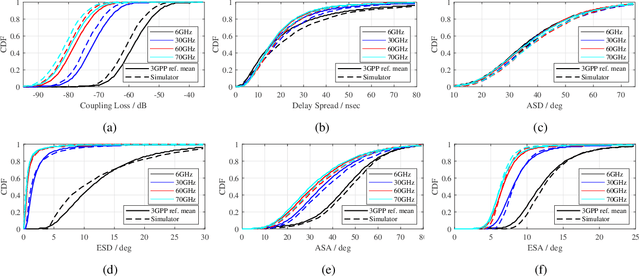
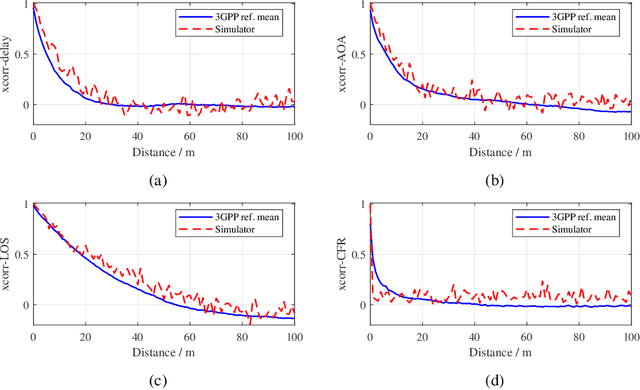
Channel-state-information-based localization in 5G networks has been a promising way to obtain highly accurate positions compared to previous communication networks. However, there is no unified and effective platform to support the research on 5G localization algorithms. This paper releases a link-level simulator for 5G localization, which can depict realistic physical behaviors of the 5G positioning signal transmission. Specifically, we first develop a simulation architecture considering more elaborate parameter configuration and physical-layer processing. The architecture supports the link modeling at sub-6GHz and millimeter-wave (mmWave) frequency bands. Subsequently, the critical physical-layer components that determine the localization performance are designed and integrated. In particular, a lightweight new-radio channel model and hardware impairment functions that significantly limit the parameter estimation accuracy are developed. Finally, we present three application cases to evaluate the simulator, i.e. two-dimensional mobile terminal localization, mmWave beam sweeping, and beamforming-based angle estimation. The numerical results in the application cases present the performance diversity of localization algorithms in various impairment conditions.
Robust Sum-Rate Maximization in Transmissive RMS Transceiver-Enabled SWIPT Networks
Dec 10, 2022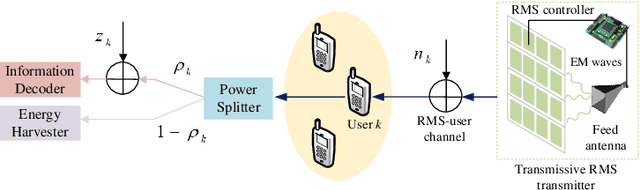
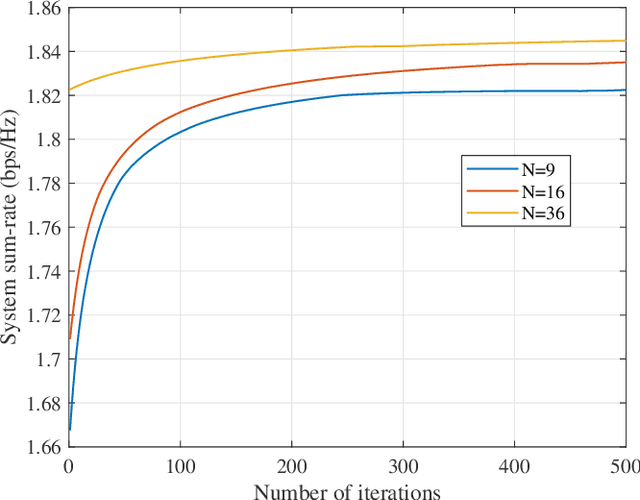
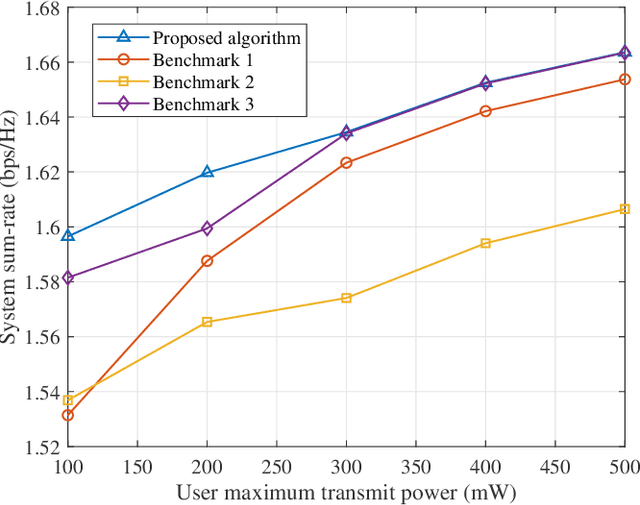
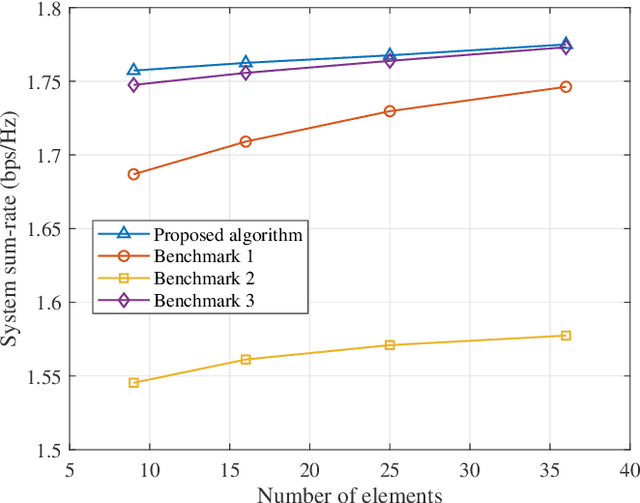
In this paper, we propose a state-of-the-art downlink communication transceiver design for transmissive reconfigurable metasurface (RMS)-enabled simultaneous wireless information and power transfer (SWIPT) networks. Specifically, a feed antenna is deployed in the transmissive RMS-based transceiver, which can be used to implement beamforming. According to the relationship between wavelength and propagation distance, the spatial propagation models of plane and spherical waves are built. Then, in the case of imperfect channel state information (CSI), we formulate a robust system sum-rate maximization problem that jointly optimizes RMS transmissive coefficient, transmit power allocation, and power splitting ratio design while taking account of the non-linear energy harvesting model and outage probability criterion. Since the coupling of optimization variables, the whole optimization problem is non-convex and cannot be solved directly. Therefore, the alternating optimization (AO) framework is implemented to decompose the non-convex original problem. In detail, the whole problem is divided into three sub-problems to solve. For the non-convexity of the objective function, successive convex approximation (SCA) is used to transform it, and penalty function method and difference-of-convex (DC) programming are applied to deal with the non-convex constraints. Finally, we alternately solve the three sub-problems until the entire optimization problem converges. Numerical results show that our proposed algorithm has convergence and better performance than other benchmark algorithms.
E2FIF: Push the limit of Binarized Deep Imagery Super-resolution using End-to-end Full-precision Information Flow
Jul 14, 2022
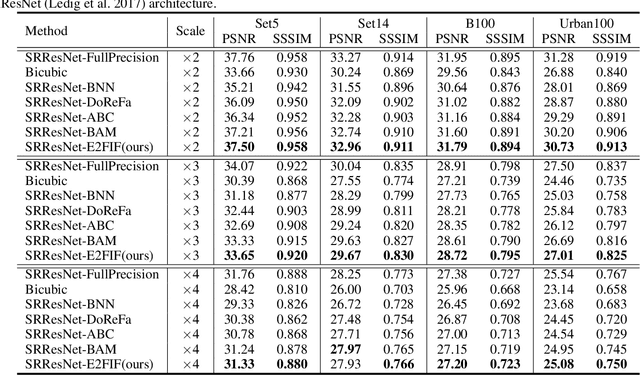
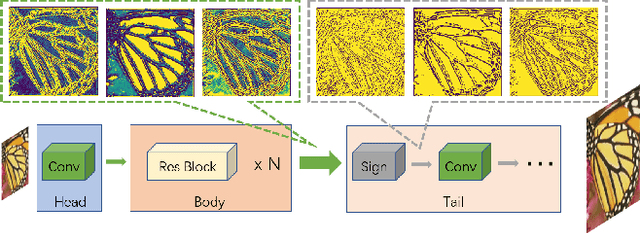
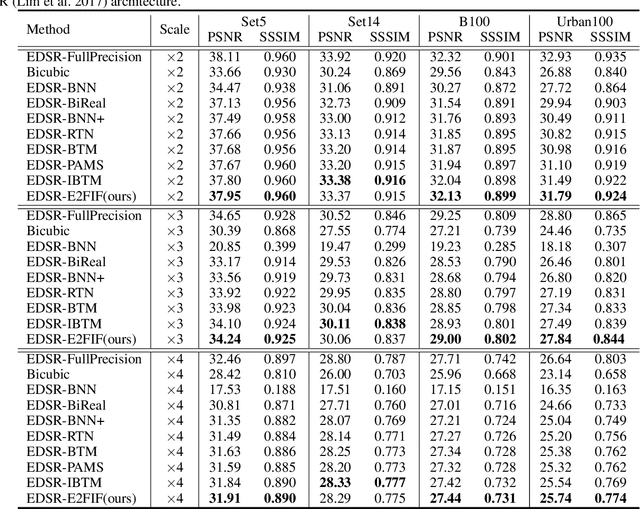
Binary neural network (BNN) provides a promising solution to deploy parameter-intensive deep single image super-resolution (SISR) models onto real devices with limited storage and computational resources. To achieve comparable performance with the full-precision counterpart, most existing BNNs for SISR mainly focus on compensating the information loss incurred by binarizing weights and activations in the network through better approximations to the binarized convolution. In this study, we revisit the difference between BNNs and their full-precision counterparts and argue that the key for good generalization performance of BNNs lies on preserving a complete full-precision information flow as well as an accurate gradient flow passing through each binarized convolution layer. Inspired by this, we propose to introduce a full-precision skip connection or its variant over each binarized convolution layer across the entire network, which can increase the forward expressive capability and the accuracy of back-propagated gradient, thus enhancing the generalization performance. More importantly, such a scheme is applicable to any existing BNN backbones for SISR without introducing any additional computation cost. To testify its efficacy, we evaluate it using four different backbones for SISR on four benchmark datasets and report obviously superior performance over existing BNNs and even some 4-bit competitors.
Event-based Monocular Dense Depth Estimation with Recurrent Transformers
Dec 06, 2022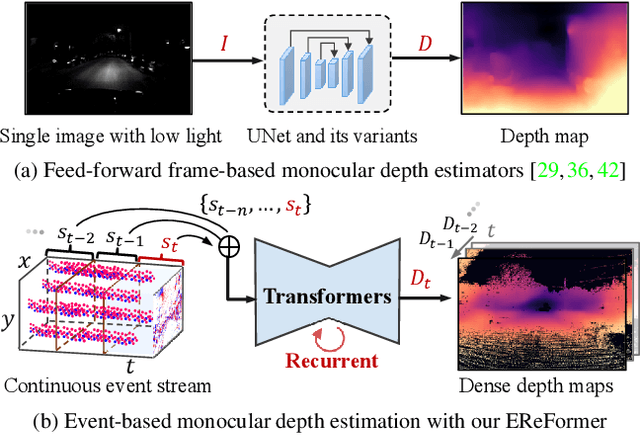
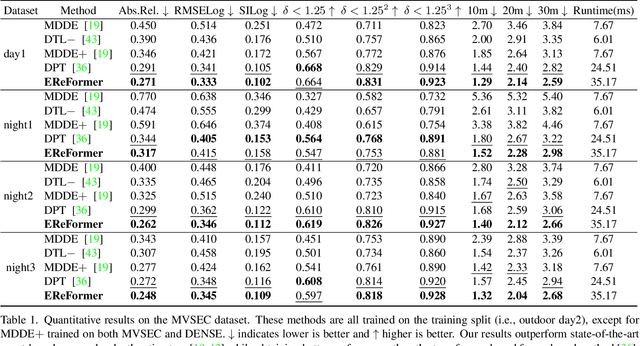
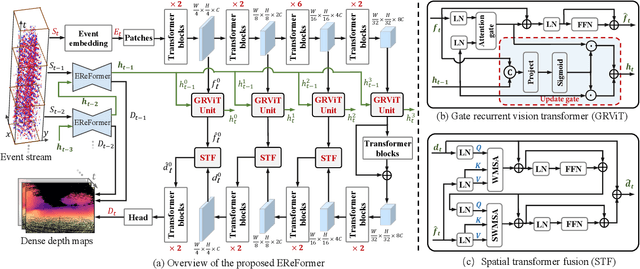
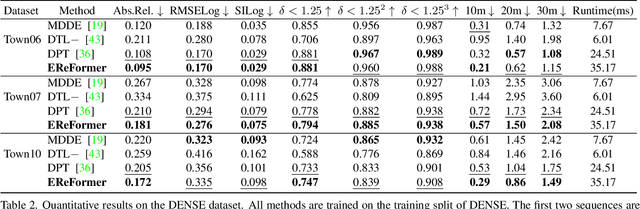
Event cameras, offering high temporal resolutions and high dynamic ranges, have brought a new perspective to address common challenges (e.g., motion blur and low light) in monocular depth estimation. However, how to effectively exploit the sparse spatial information and rich temporal cues from asynchronous events remains a challenging endeavor. To this end, we propose a novel event-based monocular depth estimator with recurrent transformers, namely EReFormer, which is the first pure transformer with a recursive mechanism to process continuous event streams. Technically, for spatial modeling, a novel transformer-based encoder-decoder with a spatial transformer fusion module is presented, having better global context information modeling capabilities than CNN-based methods. For temporal modeling, we design a gate recurrent vision transformer unit that introduces a recursive mechanism into transformers, improving temporal modeling capabilities while alleviating the expensive GPU memory cost. The experimental results show that our EReFormer outperforms state-of-the-art methods by a margin on both synthetic and real-world datasets. We hope that our work will attract further research to develop stunning transformers in the event-based vision community. Our open-source code can be found in the supplemental material.
How would Stance Detection Techniques Evolve after the Launch of ChatGPT?
Dec 30, 2022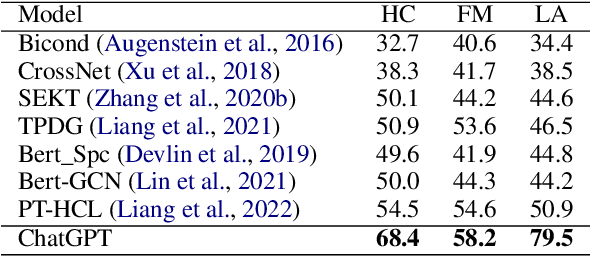
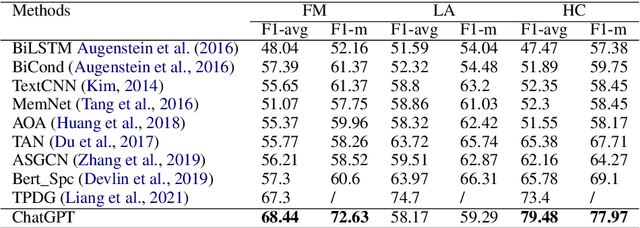
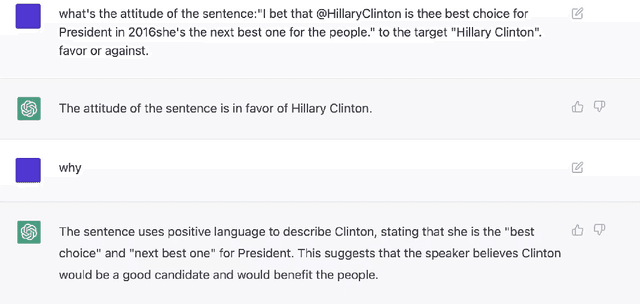
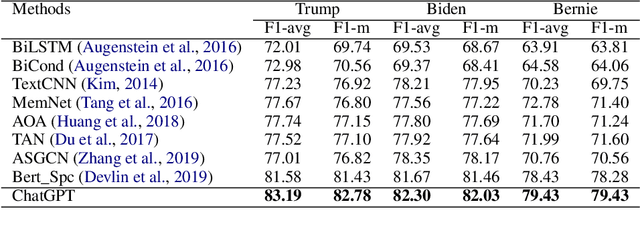
Stance detection refers to the task of extracting the standpoint (Favor, Against or Neither) towards a target in given texts. Such research gains increasing attention with the proliferation of social media contents. The conventional framework of handling stance detection is converting it into text classification tasks. Deep learning models have already replaced rule-based models and traditional machine learning models in solving such problems. Current deep neural networks are facing two main challenges which are insufficient labeled data and information in social media posts and the unexplainable nature of deep learning models. A new pre-trained language model chatGPT was launched on Nov 30, 2022. For the stance detection tasks, our experiments show that ChatGPT can achieve SOTA or similar performance for commonly used datasets including SemEval-2016 and P-Stance. At the same time, ChatGPT can provide explanation for its own prediction, which is beyond the capability of any existing model. The explanations for the cases it cannot provide classification results are especially useful. ChatGPT has the potential to be the best AI model for stance detection tasks in NLP, or at least change the research paradigm of this field. ChatGPT also opens up the possibility of building explanatory AI for stance detection.