 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Coordinating Cross-modal Distillation for Molecular Property Prediction
Nov 30, 2022
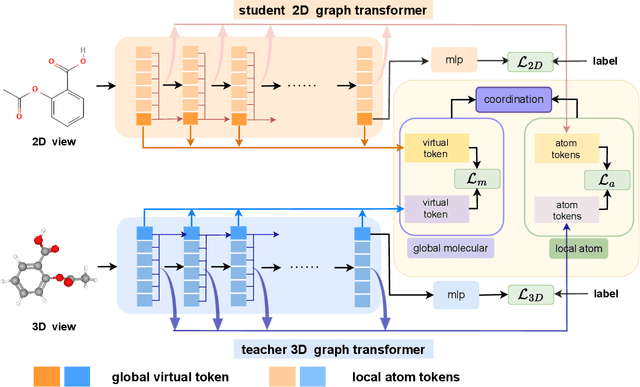
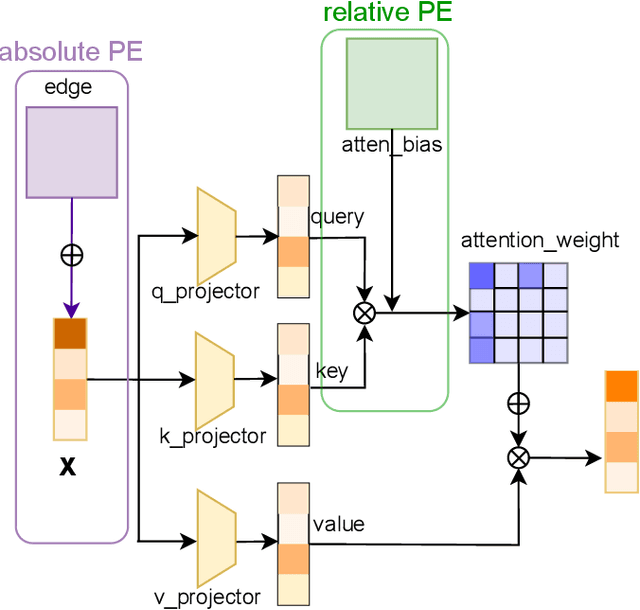
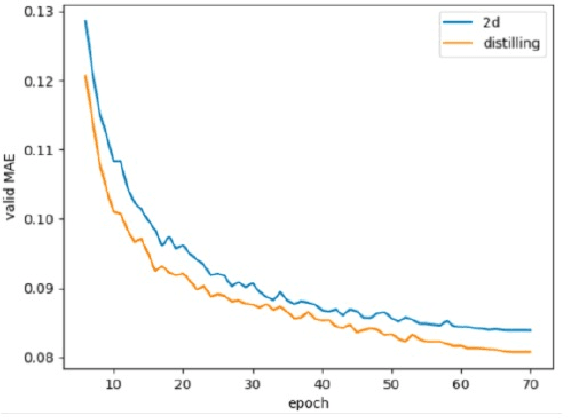
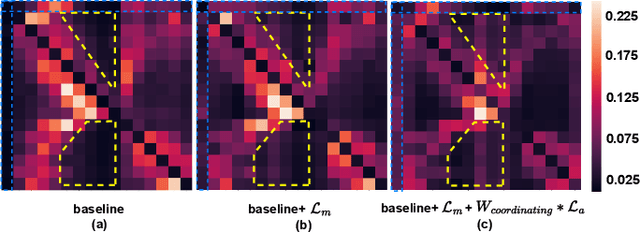
In recent years, molecular graph representation learning (GRL) has drawn much more attention in molecular property prediction (MPP) problems. The existing graph methods have demonstrated that 3D geometric information is significant for better performance in MPP. However, accurate 3D structures are often costly and time-consuming to obtain, limiting the large-scale application of GRL. It is an intuitive solution to train with 3D to 2D knowledge distillation and predict with only 2D inputs. But some challenging problems remain open for 3D to 2D distillation. One is that the 3D view is quite distinct from the 2D view, and the other is that the gradient magnitudes of atoms in distillation are discrepant and unstable due to the variable molecular size. To address these challenging problems, we exclusively propose a distillation framework that contains global molecular distillation and local atom distillation. We also provide a theoretical insight to justify how to coordinate atom and molecular information, which tackles the drawback of variable molecular size for atom information distillation. Experimental results on two popular molecular datasets demonstrate that our proposed model achieves superior performance over other methods. Specifically, on the largest MPP dataset PCQM4Mv2 served as an "ImageNet Large Scale Visual Recognition Challenge" in the field of graph ML, the proposed method achieved a 6.9% improvement compared with the best works. And we obtained fourth place with the MAE of 0.0734 on the test-challenge set for OGB-LSC 2022 Graph Regression Task. We will release the code soon.
Towards True Lossless Sparse Communication in Multi-Agent Systems
Nov 30, 2022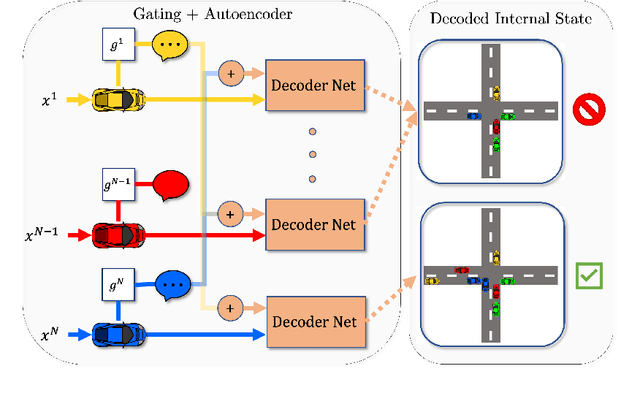
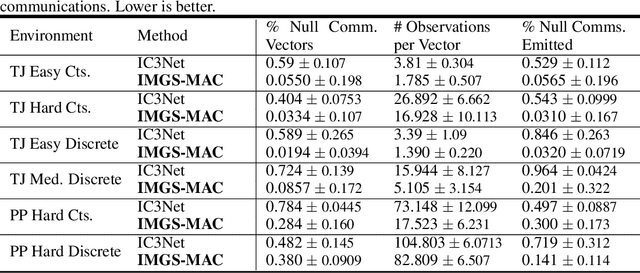
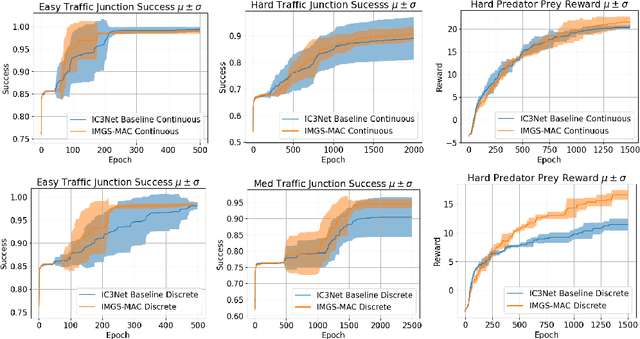

Communication enables agents to cooperate to achieve their goals. Learning when to communicate, i.e., sparse (in time) communication, and whom to message is particularly important when bandwidth is limited. Recent work in learning sparse individualized communication, however, suffers from high variance during training, where decreasing communication comes at the cost of decreased reward, particularly in cooperative tasks. We use the information bottleneck to reframe sparsity as a representation learning problem, which we show naturally enables lossless sparse communication at lower budgets than prior art. In this paper, we propose a method for true lossless sparsity in communication via Information Maximizing Gated Sparse Multi-Agent Communication (IMGS-MAC). Our model uses two individualized regularization objectives, an information maximization autoencoder and sparse communication loss, to create informative and sparse communication. We evaluate the learned communication `language' through direct causal analysis of messages in non-sparse runs to determine the range of lossless sparse budgets, which allow zero-shot sparsity, and the range of sparse budgets that will inquire a reward loss, which is minimized by our learned gating function with few-shot sparsity. To demonstrate the efficacy of our results, we experiment in cooperative multi-agent tasks where communication is essential for success. We evaluate our model with both continuous and discrete messages. We focus our analysis on a variety of ablations to show the effect of message representations, including their properties, and lossless performance of our model.
Intent-aware Multi-source Contrastive Alignment for Tag-enhanced Recommendation
Nov 11, 2022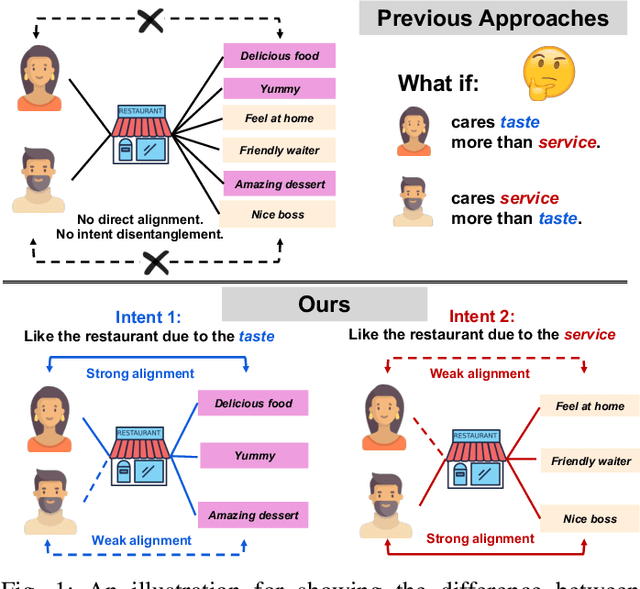
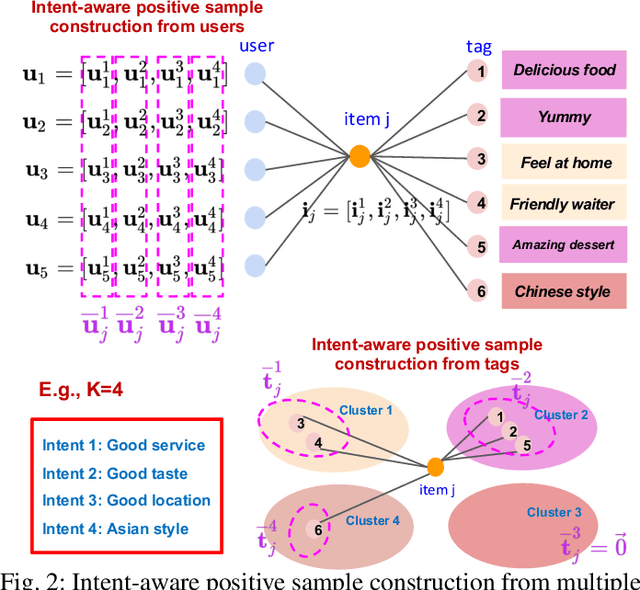
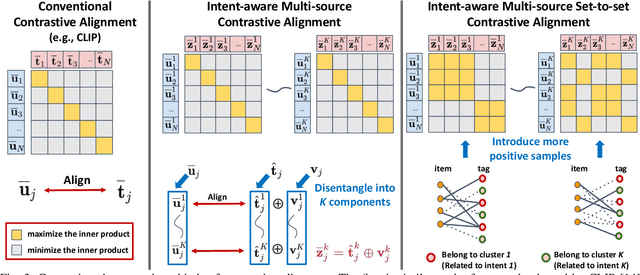
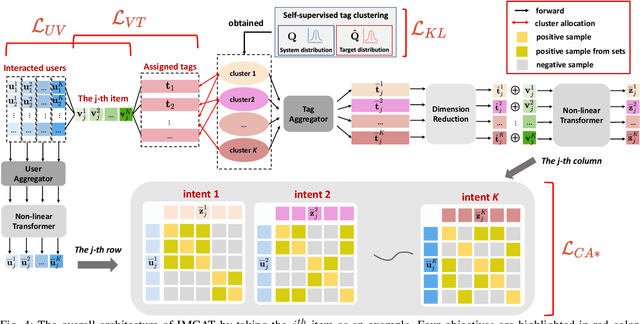
To offer accurate and diverse recommendation services, recent methods use auxiliary information to foster the learning process of user and item representations. Many SOTA methods fuse different sources of information (user, item, knowledge graph, tags, etc.) into a graph and use Graph Neural Networks to introduce the auxiliary information through the message passing paradigm. In this work, we seek an alternative framework that is light and effective through self-supervised learning across different sources of information, particularly for the commonly accessible item tag information. We use a self-supervision signal to pair users with the auxiliary information associated with the items they have interacted with before. To achieve the pairing, we create a proxy training task. For a given item, the model predicts the correct pairing between the representations obtained from the users that have interacted with this item and the assigned tags. This design provides an efficient solution, using the auxiliary information directly to enhance the quality of user and item embeddings. User behavior in recommendation systems is driven by the complex interactions of many factors behind the decision-making processes. To make the pairing process more fine-grained and avoid embedding collapse, we propose an intent-aware self-supervised pairing process where we split the user embeddings into multiple sub-embedding vectors. Each sub-embedding vector captures a specific user intent via self-supervised alignment with a particular cluster of tags. We integrate our designed framework with various recommendation models, demonstrating its flexibility and compatibility. Through comparison with numerous SOTA methods on seven real-world datasets, we show that our method can achieve better performance while requiring less training time. This indicates the potential of applying our approach on web-scale datasets.
Integrated Sensing and Communication: Joint Pilot and Transmission Design
Nov 23, 2022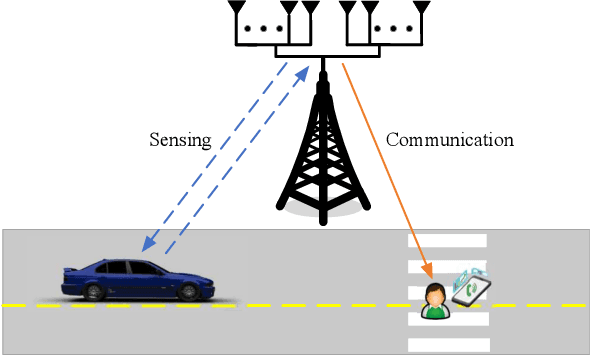
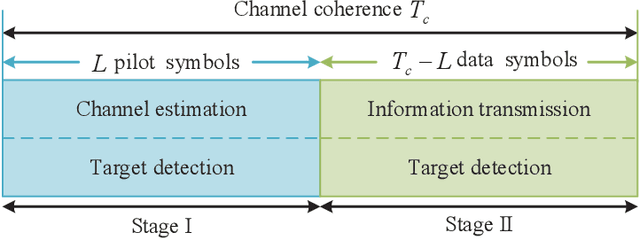
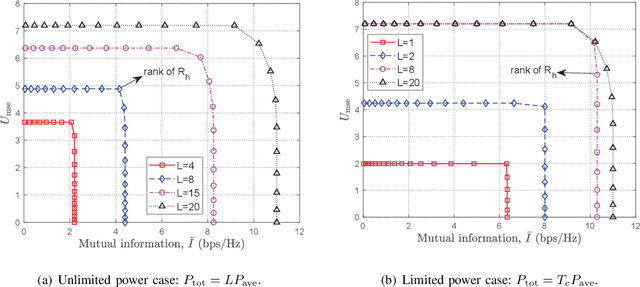
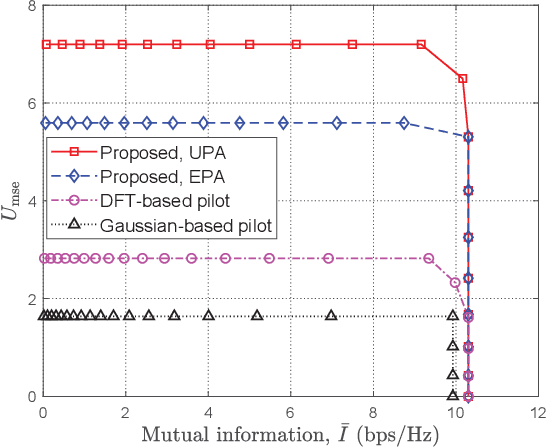
This paper studies a communication-centric integrated sensing and communication (ISAC) system, where a multi-antenna base station (BS) simultaneously performs downlink communication and target detection. A novel target detection and information transmission protocol is proposed, where the BS executes the channel estimation and beamforming successively and meanwhile jointly exploits the pilot sequences in the channel estimation stage and user information in the transmission stage to assist target detection. We investigate the joint design of pilot matrix, training duration, and transmit beamforming to maximize the probability of target detection, subject to the minimum achievable rate required by the user. However, designing the optimal pilot matrix is rather challenging since there is no closed-form expression of the detection probability with respect to the pilot matrix. To tackle this difficulty, we resort to designing the pilot matrix based on the information-theoretic criterion to maximize the mutual information (MI) between the received observations and BS-target channel coefficients for target detection. We first derive the optimal pilot matrix for both channel estimation and target detection, and then propose an unified pilot matrix structure to balance minimizing the channel estimation error (MSE) and maximizing MI. Based on the proposed structure, a low-complexity successive refinement algorithm is proposed. Simulation results demonstrate that the proposed pilot matrix structure can well balance the MSE-MI and the Rate-MI tradeoffs, and show the significant region improvement of our proposed design as compared to other benchmark schemes. Furthermore, it is unveiled that as the communication channel is more correlated, the Rate-MI region can be further enlarged.
Dynamic Graph Node Classification via Time Augmentation
Dec 07, 2022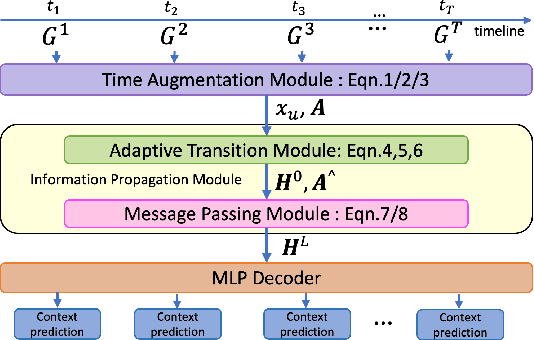
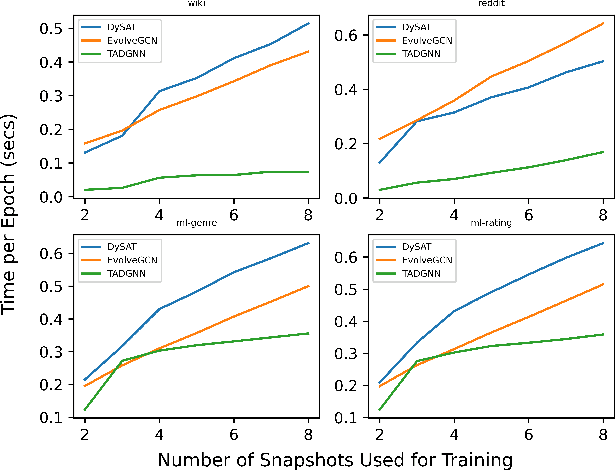

Node classification for graph-structured data aims to classify nodes whose labels are unknown. While studies on static graphs are prevalent, few studies have focused on dynamic graph node classification. Node classification on dynamic graphs is challenging for two reasons. First, the model needs to capture both structural and temporal information, particularly on dynamic graphs with a long history and require large receptive fields. Second, model scalability becomes a significant concern as the size of the dynamic graph increases. To address these problems, we propose the Time Augmented Dynamic Graph Neural Network (TADGNN) framework. TADGNN consists of two modules: 1) a time augmentation module that captures the temporal evolution of nodes across time structurally, creating a time-augmented spatio-temporal graph, and 2) an information propagation module that learns the dynamic representations for each node across time using the constructed time-augmented graph. We perform node classification experiments on four dynamic graph benchmarks. Experimental results demonstrate that TADGNN framework outperforms several static and dynamic state-of-the-art (SOTA) GNN models while demonstrating superior scalability. We also conduct theoretical and empirical analyses to validate the efficiency of the proposed method. Our code is available at https://sites.google.com/view/tadgnn.
Recurrent Vision Transformers for Object Detection with Event Cameras
Dec 11, 2022
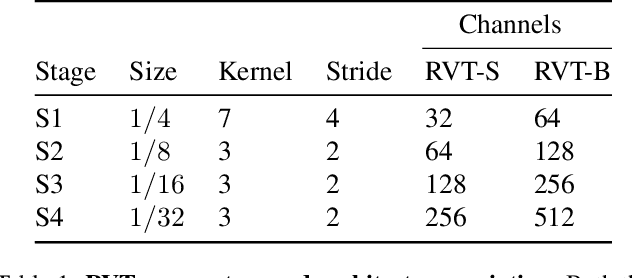
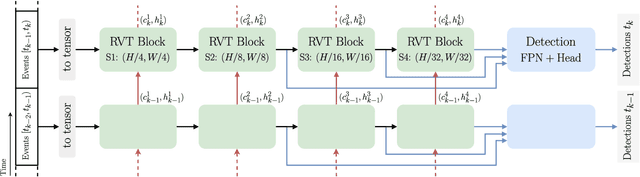
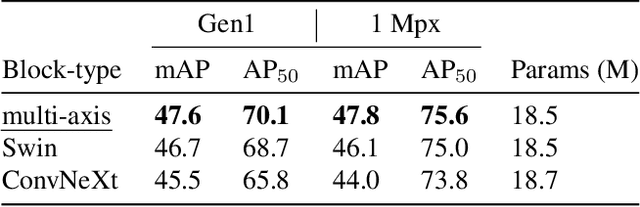
We present Recurrent Vision Transformers (RVTs), a novel backbone for object detection with event cameras. Event cameras provide visual information with sub-millisecond latency at a high-dynamic range and with strong robustness against motion blur. These unique properties offer great potential for low-latency object detection and tracking in time-critical scenarios. Prior work in event-based vision has achieved outstanding detection performance but at the cost of substantial inference time, typically beyond 40 milliseconds. By revisiting the high-level design of recurrent vision backbones, we reduce inference time by a factor of 5 while retaining similar performance. To achieve this, we explore a multi-stage design that utilizes three key concepts in each stage: First, a convolutional prior that can be regarded as a conditional positional embedding. Second, local- and dilated global self-attention for spatial feature interaction. Third, recurrent temporal feature aggregation to minimize latency while retaining temporal information. RVTs can be trained from scratch to reach state-of-the-art performance on event-based object detection - achieving an mAP of 47.5% on the Gen1 automotive dataset. At the same time, RVTs offer fast inference (13 ms on a T4 GPU) and favorable parameter efficiency (5 times fewer than prior art). Our study brings new insights into effective design choices that could be fruitful for research beyond event-based vision.
Efficient Relation-aware Neighborhood Aggregation in Graph Neural Networks via Tensor Decomposition
Dec 11, 2022
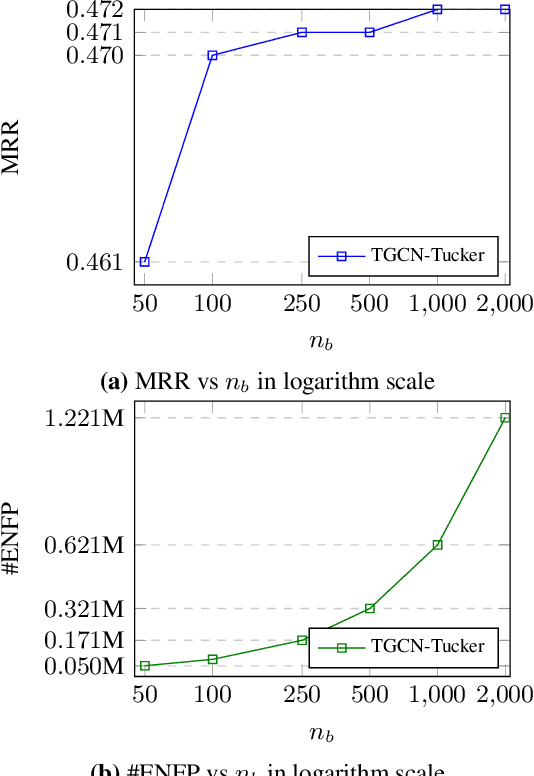
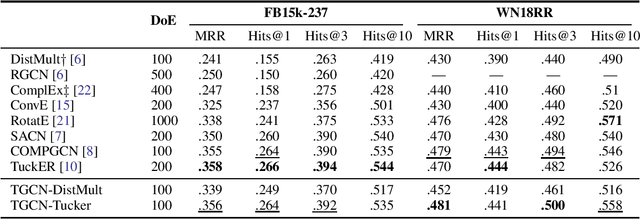
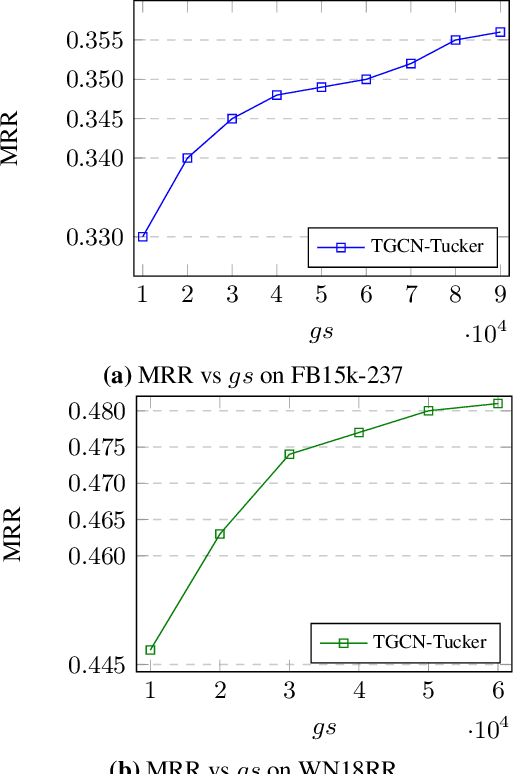
Numerous models have tried to effectively embed knowledge graphs in low dimensions. Among the state-of-the-art methods, Graph Neural Network (GNN) models provide structure-aware representations of knowledge graphs. However, they often utilize the information of relations and their interactions with entities inefficiently. Moreover, most state-of-the-art knowledge graph embedding models suffer from scalability issues because of assigning high-dimensional embeddings to entities and relations. To address the above limitations, we propose a scalable general knowledge graph encoder that adaptively involves a powerful tensor decomposition method in the aggregation function of RGCN, a well-known relational GNN model. Specifically, the parameters of a low-rank core projection tensor, used to transform neighborhood entities in the encoder, are shared across relations to benefit from multi-task learning and incorporate relations information effectively. Besides, we propose a low-rank estimation of the core tensor using CP decomposition to compress the model, which is also applicable, as a regularization method, to other similar linear models. We evaluated our model on knowledge graph completion as a common downstream task. We train our model for using a new loss function based on contrastive learning, which relieves the training limitation of the 1-N method on huge graphs. We improved RGCN performance on FB15-237 by 0.42% with considerably lower dimensionality of embeddings.
CREPE: Open-Domain Question Answering with False Presuppositions
Nov 30, 2022


Information seeking users often pose questions with false presuppositions, especially when asking about unfamiliar topics. Most existing question answering (QA) datasets, in contrast, assume all questions have well defined answers. We introduce CREPE, a QA dataset containing a natural distribution of presupposition failures from online information-seeking forums. We find that 25% of questions contain false presuppositions, and provide annotations for these presuppositions and their corrections. Through extensive baseline experiments, we show that adaptations of existing open-domain QA models can find presuppositions moderately well, but struggle when predicting whether a presupposition is factually correct. This is in large part due to difficulty in retrieving relevant evidence passages from a large text corpus. CREPE provides a benchmark to study question answering in the wild, and our analyses provide avenues for future work in better modeling and further studying the task.
Riemannian Optimization for Variance Estimation in Linear Mixed Models
Dec 18, 2022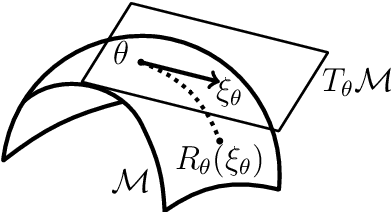
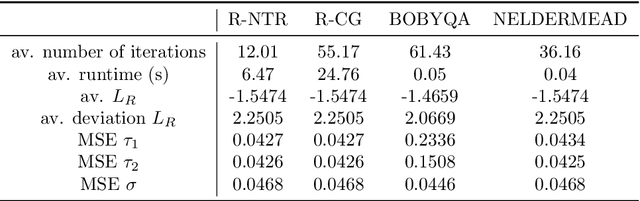

Variance parameter estimation in linear mixed models is a challenge for many classical nonlinear optimization algorithms due to the positive-definiteness constraint of the random effects covariance matrix. We take a completely novel view on parameter estimation in linear mixed models by exploiting the intrinsic geometry of the parameter space. We formulate the problem of residual maximum likelihood estimation as an optimization problem on a Riemannian manifold. Based on the introduced formulation, we give geometric higher-order information on the problem via the Riemannian gradient and the Riemannian Hessian. Based on that, we test our approach with Riemannian optimization algorithms numerically. Our approach yields a higher quality of the variance parameter estimates compared to existing approaches.
Category-Level 6D Object Pose Estimation with Flexible Vector-Based Rotation Representation
Dec 09, 2022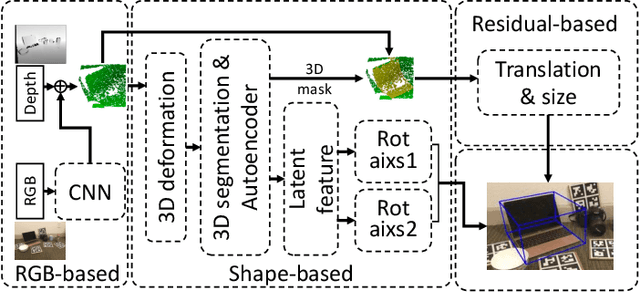
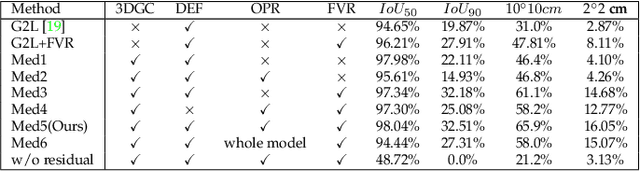
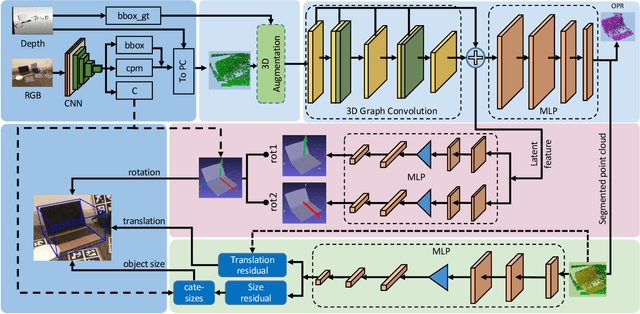
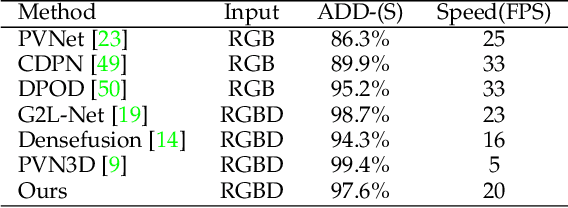
In this paper, we propose a novel 3D graph convolution based pipeline for category-level 6D pose and size estimation from monocular RGB-D images. The proposed method leverages an efficient 3D data augmentation and a novel vector-based decoupled rotation representation. Specifically, we first design an orientation-aware autoencoder with 3D graph convolution for latent feature learning. The learned latent feature is insensitive to point shift and size thanks to the shift and scale-invariance properties of the 3D graph convolution. Then, to efficiently decode the rotation information from the latent feature, we design a novel flexible vector-based decomposable rotation representation that employs two decoders to complementarily access the rotation information. The proposed rotation representation has two major advantages: 1) decoupled characteristic that makes the rotation estimation easier; 2) flexible length and rotated angle of the vectors allow us to find a more suitable vector representation for specific pose estimation task. Finally, we propose a 3D deformation mechanism to increase the generalization ability of the pipeline. Extensive experiments show that the proposed pipeline achieves state-of-the-art performance on category-level tasks. Further, the experiments demonstrate that the proposed rotation representation is more suitable for the pose estimation tasks than other rotation representations.