 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Self-Supervised Object Segmentation with a Cut-and-Pasting GAN
Jan 01, 2023
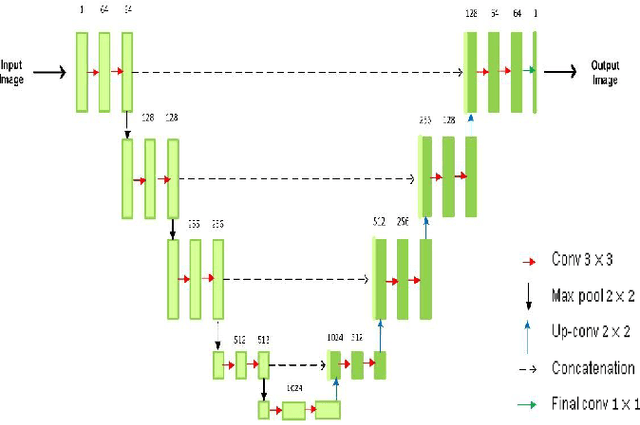
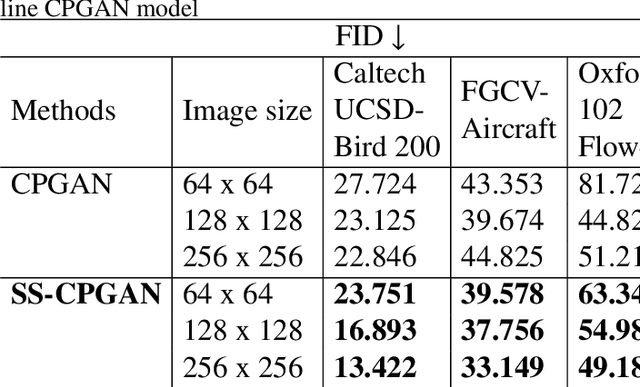
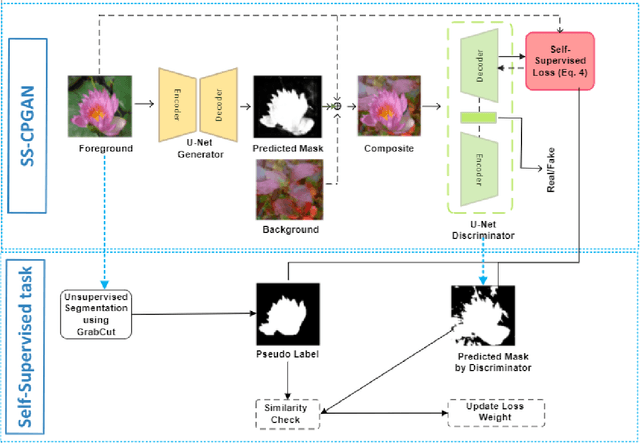
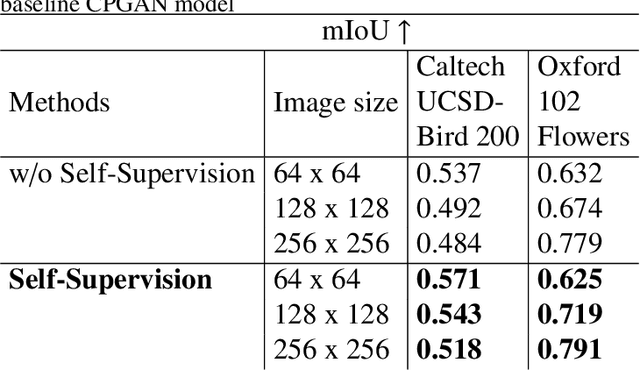
This paper proposes a novel self-supervised based Cut-and-Paste GAN to perform foreground object segmentation and generate realistic composite images without manual annotations. We accomplish this goal by a simple yet effective self-supervised approach coupled with the U-Net based discriminator. The proposed method extends the ability of the standard discriminators to learn not only the global data representations via classification (real/fake) but also learn semantic and structural information through pseudo labels created using the self-supervised task. The proposed method empowers the generator to create meaningful masks by forcing it to learn informative per-pixel as well as global image feedback from the discriminator. Our experiments demonstrate that our proposed method significantly outperforms the state-of-the-art methods on the standard benchmark datasets.
Linguistic-style-aware Neural Networks for Fake News Detection
Jan 07, 2023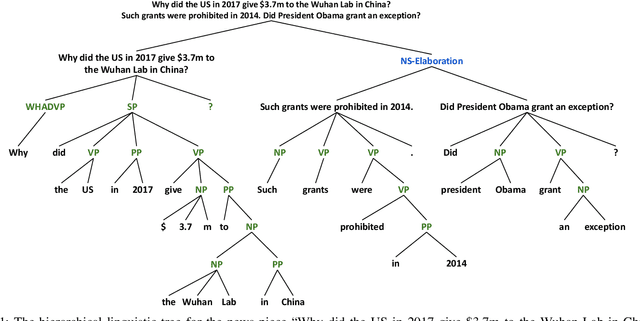
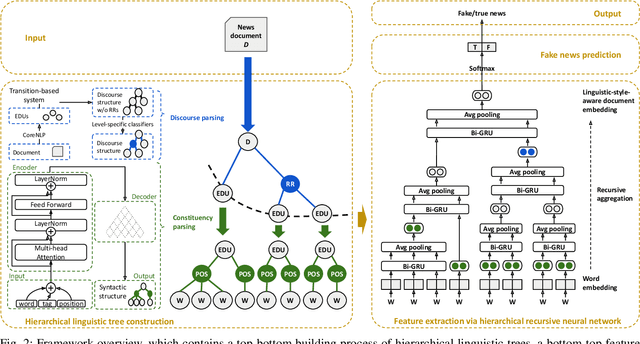
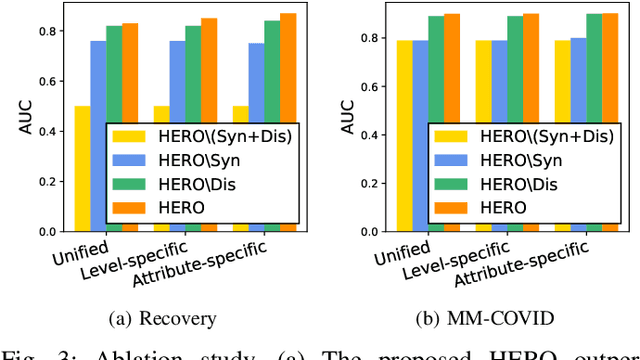
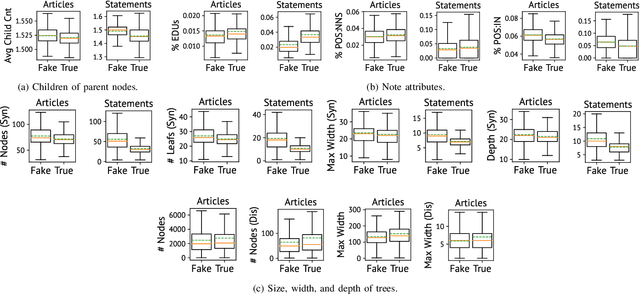
We propose the hierarchical recursive neural network (HERO) to predict fake news by learning its linguistic style, which is distinguishable from the truth, as psychological theories reveal. We first generate the hierarchical linguistic tree of news documents; by doing so, we translate each news document's linguistic style into its writer's usage of words and how these words are recursively structured as phrases, sentences, paragraphs, and, ultimately, the document. By integrating the hierarchical linguistic tree with the neural network, the proposed method learns and classifies the representation of news documents by capturing their locally sequential and globally recursive structures that are linguistically meaningful. It is the first work offering the hierarchical linguistic tree and the neural network preserving the tree information to our best knowledge. Experimental results based on public real-world datasets demonstrate the proposed method's effectiveness, which can outperform state-of-the-art techniques in classifying short and long news documents. We also examine the differential linguistic style of fake news and the truth and observe some patterns of fake news. The code and data have been publicly available.
On the Effect of Information Asymmetry in Human-AI Teams
May 03, 2022
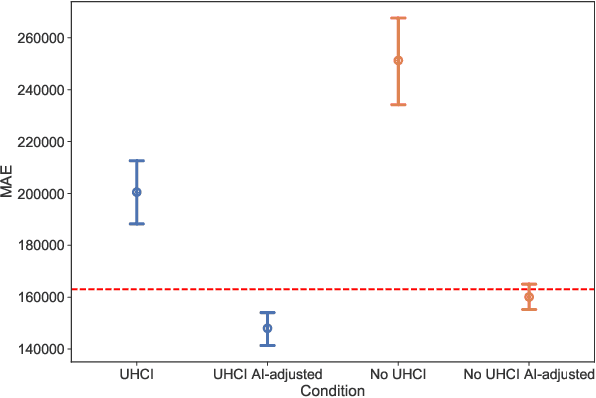
Over the last years, the rising capabilities of artificial intelligence (AI) have improved human decision-making in many application areas. Teaming between AI and humans may even lead to complementary team performance (CTP), i.e., a level of performance beyond the ones that can be reached by AI or humans individually. Many researchers have proposed using explainable AI (XAI) to enable humans to rely on AI advice appropriately and thereby reach CTP. However, CTP is rarely demonstrated in previous work as often the focus is on the design of explainability, while a fundamental prerequisite -- the presence of complementarity potential between humans and AI -- is often neglected. Therefore, we focus on the existence of this potential for effective human-AI decision-making. Specifically, we identify information asymmetry as an essential source of complementarity potential, as in many real-world situations, humans have access to different contextual information. By conducting an online experiment, we demonstrate that humans can use such contextual information to adjust the AI's decision, finally resulting in CTP.
Multi-scale multi-modal micro-expression recognition algorithm based on transformer
Jan 11, 2023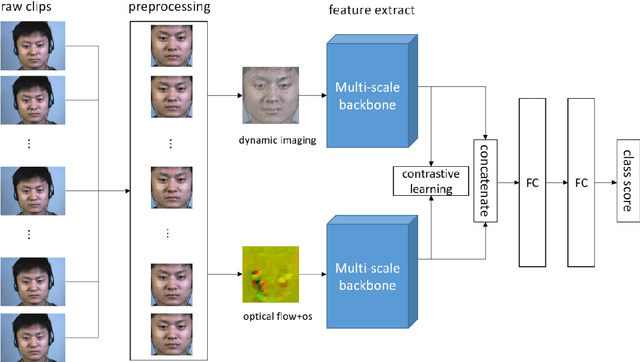

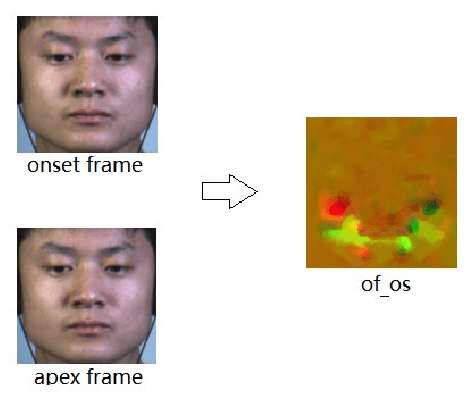
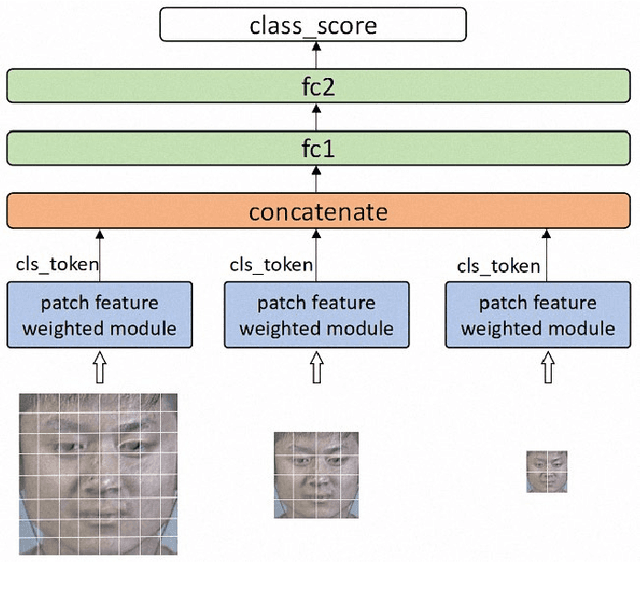
A micro-expression is a spontaneous unconscious facial muscle movement that can reveal the true emotions people attempt to hide. Although manual methods have made good progress and deep learning is gaining prominence. Due to the short duration of micro-expression and different scales of expressed in facial regions, existing algorithms cannot extract multi-modal multi-scale facial region features while taking into account contextual information to learn underlying features. Therefore, in order to solve the above problems, a multi-modal multi-scale algorithm based on transformer network is proposed in this paper, aiming to fully learn local multi-grained features of micro-expressions through two modal features of micro-expressions - motion features and texture features. To obtain local area features of the face at different scales, we learned patch features at different scales for both modalities, and then fused multi-layer multi-headed attention weights to obtain effective features by weighting the patch features, and combined cross-modal contrastive learning for model optimization. We conducted comprehensive experiments on three spontaneous datasets, and the results show the accuracy of the proposed algorithm in single measurement SMIC database is up to 78.73% and the F1 value on CASMEII of the combined database is up to 0.9071, which is at the leading level.
GraVIS: Grouping Augmented Views from Independent Sources for Dermatology Analysis
Jan 11, 2023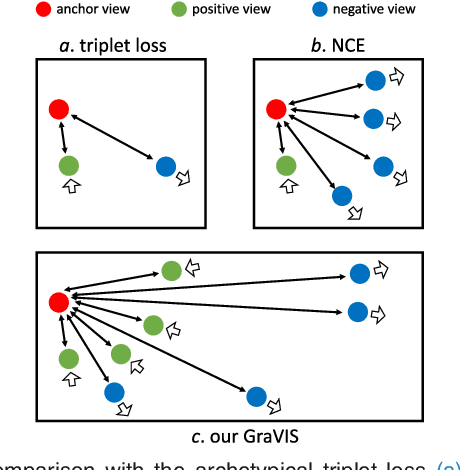
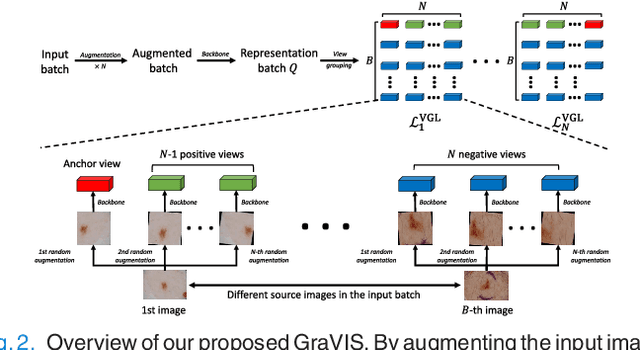
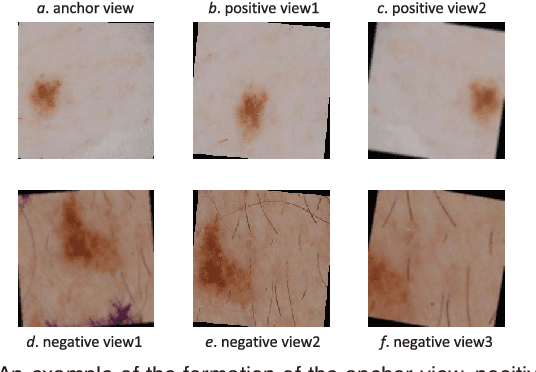
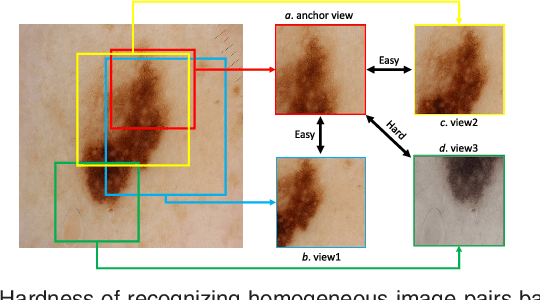
Self-supervised representation learning has been extremely successful in medical image analysis, as it requires no human annotations to provide transferable representations for downstream tasks. Recent self-supervised learning methods are dominated by noise-contrastive estimation (NCE, also known as contrastive learning), which aims to learn invariant visual representations by contrasting one homogeneous image pair with a large number of heterogeneous image pairs in each training step. Nonetheless, NCE-based approaches still suffer from one major problem that is one homogeneous pair is not enough to extract robust and invariant semantic information. Inspired by the archetypical triplet loss, we propose GraVIS, which is specifically optimized for learning self-supervised features from dermatology images, to group homogeneous dermatology images while separating heterogeneous ones. In addition, a hardness-aware attention is introduced and incorporated to address the importance of homogeneous image views with similar appearance instead of those dissimilar homogeneous ones. GraVIS significantly outperforms its transfer learning and self-supervised learning counterparts in both lesion segmentation and disease classification tasks, sometimes by 5 percents under extremely limited supervision. More importantly, when equipped with the pre-trained weights provided by GraVIS, a single model could achieve better results than winners that heavily rely on ensemble strategies in the well-known ISIC 2017 challenge.
PromptonomyViT: Multi-Task Prompt Learning Improves Video Transformers using Synthetic Scene Data
Dec 08, 2022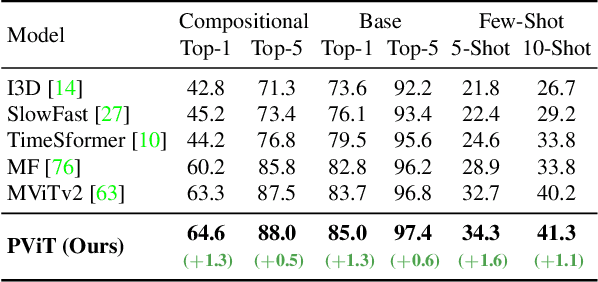
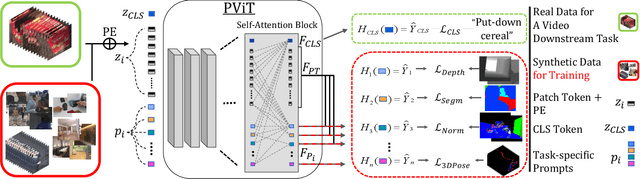
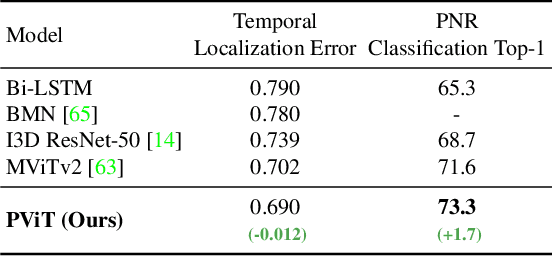

Action recognition models have achieved impressive results by incorporating scene-level annotations, such as objects, their relations, 3D structure, and more. However, obtaining annotations of scene structure for videos requires a significant amount of effort to gather and annotate, making these methods expensive to train. In contrast, synthetic datasets generated by graphics engines provide powerful alternatives for generating scene-level annotations across multiple tasks. In this work, we propose an approach to leverage synthetic scene data for improving video understanding. We present a multi-task prompt learning approach for video transformers, where a shared video transformer backbone is enhanced by a small set of specialized parameters for each task. Specifically, we add a set of ``task prompts'', each corresponding to a different task, and let each prompt predict task-related annotations. This design allows the model to capture information shared among synthetic scene tasks as well as information shared between synthetic scene tasks and a real video downstream task throughout the entire network. We refer to this approach as ``Promptonomy'', since the prompts model a task-related structure. We propose the PromptonomyViT model (PViT), a video transformer that incorporates various types of scene-level information from synthetic data using the ``Promptonomy'' approach. PViT shows strong performance improvements on multiple video understanding tasks and datasets.
Semi-Supervised Heterogeneous Graph Learning with Multi-level Data Augmentation
Nov 30, 2022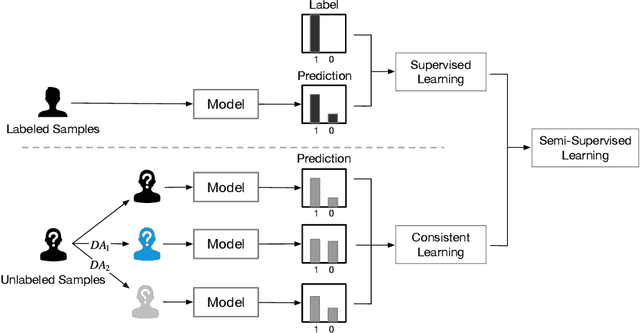


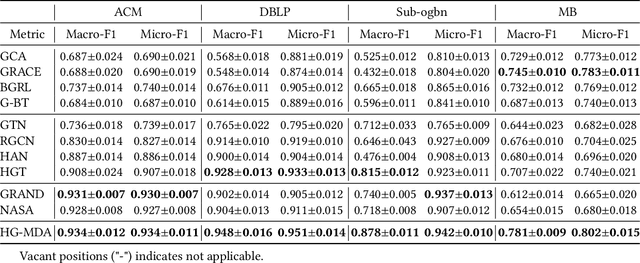
In recent years, semi-supervised graph learning with data augmentation (DA) is currently the most commonly used and best-performing method to enhance model robustness in sparse scenarios with few labeled samples. Differing from homogeneous graph, DA in heterogeneous graph has greater challenges: heterogeneity of information requires DA strategies to effectively handle heterogeneous relations, which considers the information contribution of different types of neighbors and edges to the target nodes. Furthermore, over-squashing of information is caused by the negative curvature that formed by the non-uniformity distribution and strong clustering in complex graph. To address these challenges, this paper presents a novel method named Semi-Supervised Heterogeneous Graph Learning with Multi-level Data Augmentation (HG-MDA). For the problem of heterogeneity of information in DA, node and topology augmentation strategies are proposed for the characteristics of heterogeneous graph. And meta-relation-based attention is applied as one of the indexes for selecting augmented nodes and edges. For the problem of over-squashing of information, triangle based edge adding and removing are designed to alleviate the negative curvature and bring the gain of topology. Finally, the loss function consists of the cross-entropy loss for labeled data and the consistency regularization for unlabeled data. In order to effectively fuse the prediction results of various DA strategies, the sharpening is used. Existing experiments on public datasets, i.e., ACM, DBLP, OGB, and industry dataset MB show that HG-MDA outperforms current SOTA models. Additionly, HG-MDA is applied to user identification in internet finance scenarios, helping the business to add 30% key users, and increase loans and balances by 3.6%, 11.1%, and 9.8%.
Towards Deeper and Better Multi-view Feature Fusion for 3D Semantic Segmentation
Dec 13, 20223D point clouds are rich in geometric structure information, while 2D images contain important and continuous texture information. Combining 2D information to achieve better 3D semantic segmentation has become mainstream in 3D scene understanding. Albeit the success, it still remains elusive how to fuse and process the cross-dimensional features from these two distinct spaces. Existing state-of-the-art usually exploit bidirectional projection methods to align the cross-dimensional features and realize both 2D & 3D semantic segmentation tasks. However, to enable bidirectional mapping, this framework often requires a symmetrical 2D-3D network structure, thus limiting the network's flexibility. Meanwhile, such dual-task settings may distract the network easily and lead to over-fitting in the 3D segmentation task. As limited by the network's inflexibility, fused features can only pass through a decoder network, which affects model performance due to insufficient depth. To alleviate these drawbacks, in this paper, we argue that despite its simplicity, projecting unidirectionally multi-view 2D deep semantic features into the 3D space aligned with 3D deep semantic features could lead to better feature fusion. On the one hand, the unidirectional projection enforces our model focused more on the core task, i.e., 3D segmentation; on the other hand, unlocking the bidirectional to unidirectional projection enables a deeper cross-domain semantic alignment and enjoys the flexibility to fuse better and complicated features from very different spaces. In joint 2D-3D approaches, our proposed method achieves superior performance on the ScanNetv2 benchmark for 3D semantic segmentation.
Network Slicing via Transfer Learning aided Distributed Deep Reinforcement Learning
Jan 09, 2023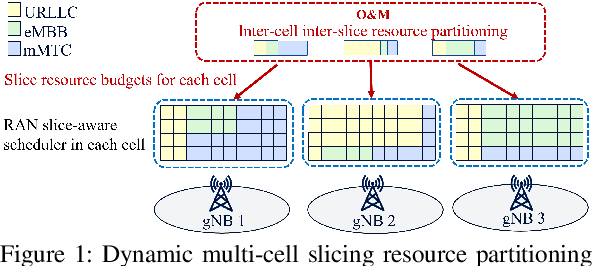
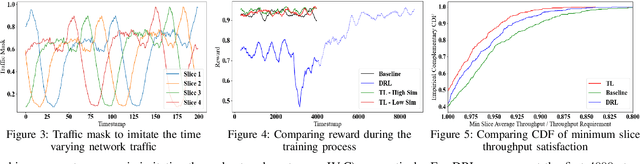
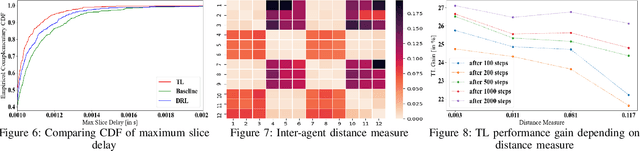
Deep reinforcement learning (DRL) has been increasingly employed to handle the dynamic and complex resource management in network slicing. The deployment of DRL policies in real networks, however, is complicated by heterogeneous cell conditions. In this paper, we propose a novel transfer learning (TL) aided multi-agent deep reinforcement learning (MADRL) approach with inter-agent similarity analysis for inter-cell inter-slice resource partitioning. First, we design a coordinated MADRL method with information sharing to intelligently partition resource to slices and manage inter-cell interference. Second, we propose an integrated TL method to transfer the learned DRL policies among different local agents for accelerating the policy deployment. The method is composed of a new domain and task similarity measurement approach and a new knowledge transfer approach, which resolves the problem of from whom to transfer and how to transfer. We evaluated the proposed solution with extensive simulations in a system-level simulator and show that our approach outperforms the state-of-the-art solutions in terms of performance, convergence speed and sample efficiency. Moreover, by applying TL, we achieve an additional gain over 27% higher than the coordinate MADRL approach without TL.
A Specific Task-oriented Semantic Image Communication System for substation patrol inspection
Jan 09, 2023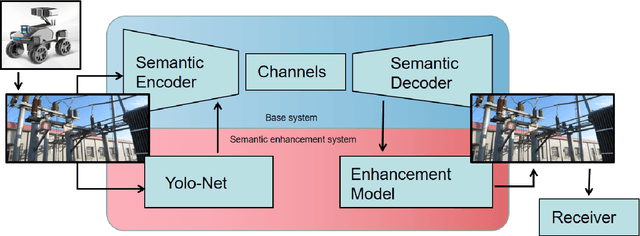
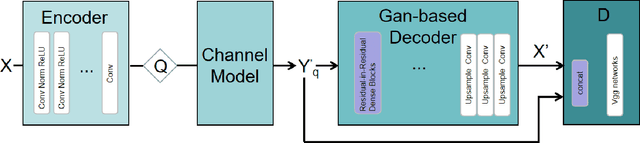
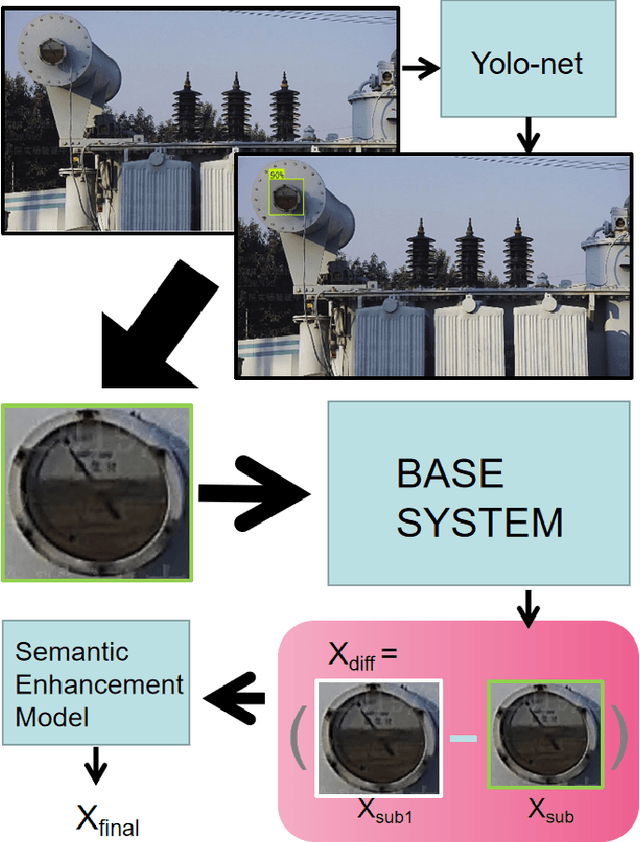
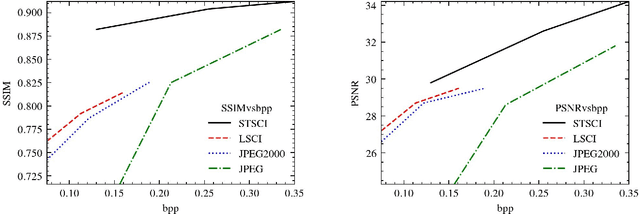
Intelligent inspection robots are widely used in substation patrol inspection, which can help check potential safety hazards by patrolling the substation and sending back scene images. However, when patrolling some marginal areas with weak signal, the scene images cannot be sucessfully transmissted to be used for hidden danger elimination, which greatly reduces the quality of robots'daily work. To solve such problem, a Specific Task-oriented Semantic Communication System for Imag-STSCI is designed, which involves the semantic features extraction, transmission, restoration and enhancement to get clearer images sent by intelligent robots under weak signals. Inspired by that only some specific details of the image are needed in such substation patrol inspection task, we proposed a new paradigm of semantic enhancement in such specific task to ensure the clarity of key semantic information when facing a lower bit rate or a low signal-to-noise ratio situation. Across the reality-based simulation, experiments show our STSCI can generally surpass traditional image-compression-based and channel-codingbased or other semantic communication system in the substation patrol inspection task with a lower bit rate even under a low signal-to-noise ratio situation.