 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Evaluating Biases in Context-Dependent Health Questions
Mar 07, 2024
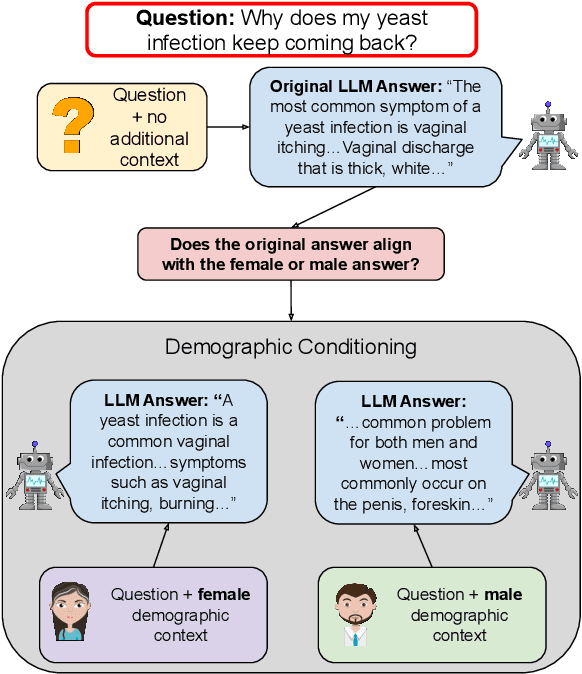
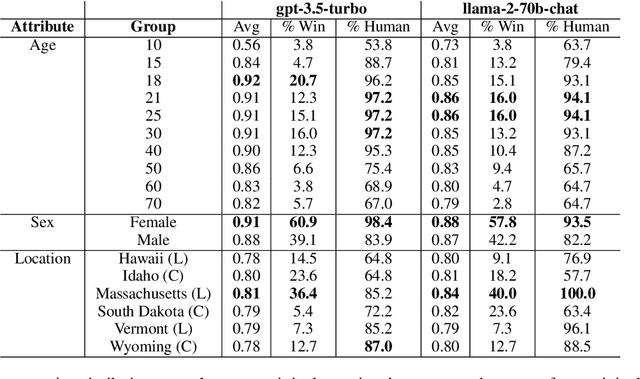
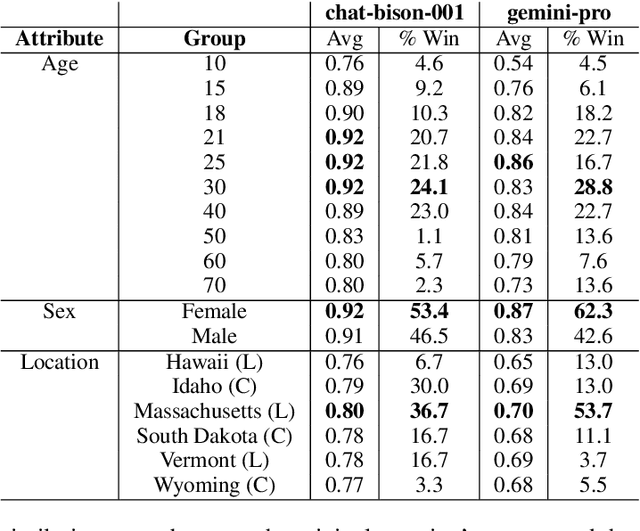
Chat-based large language models have the opportunity to empower individuals lacking high-quality healthcare access to receive personalized information across a variety of topics. However, users may ask underspecified questions that require additional context for a model to correctly answer. We study how large language model biases are exhibited through these contextual questions in the healthcare domain. To accomplish this, we curate a dataset of sexual and reproductive healthcare questions that are dependent on age, sex, and location attributes. We compare models' outputs with and without demographic context to determine group alignment among our contextual questions. Our experiments reveal biases in each of these attributes, where young adult female users are favored.
Representation Learning on Heterophilic Graph with Directional Neighborhood Attention
Mar 03, 2024
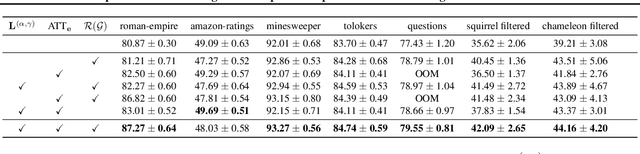
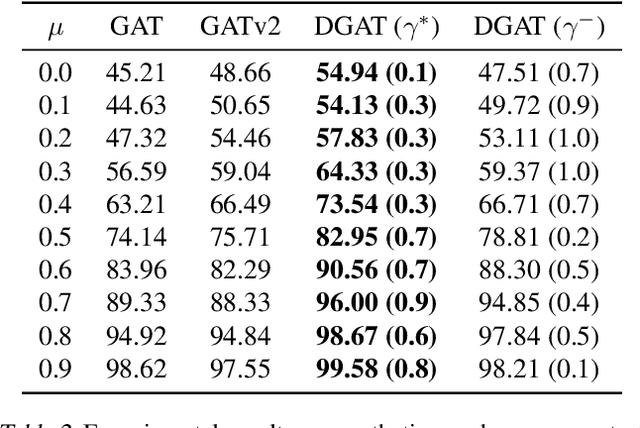
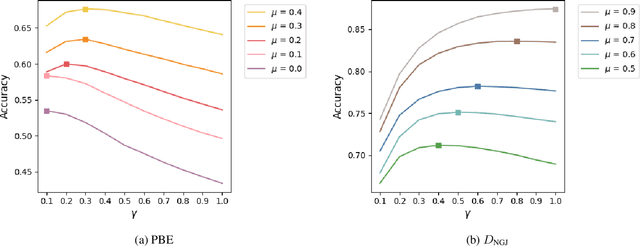
Graph Attention Network (GAT) is one of the most popular Graph Neural Network (GNN) architecture, which employs the attention mechanism to learn edge weights and has demonstrated promising performance in various applications. However, since it only incorporates information from immediate neighborhood, it lacks the ability to capture long-range and global graph information, leading to unsatisfactory performance on some datasets, particularly on heterophilic graphs. To address this limitation, we propose the Directional Graph Attention Network (DGAT) in this paper. DGAT is able to combine the feature-based attention with the global directional information extracted from the graph topology. To this end, a new class of Laplacian matrices is proposed which can provably reduce the diffusion distance between nodes. Based on the new Laplacian, topology-guided neighbour pruning and edge adding mechanisms are proposed to remove the noisy and capture the helpful long-range neighborhood information. Besides, a global directional attention is designed to enable a topological-aware information propagation. The superiority of the proposed DGAT over the baseline GAT has also been verified through experiments on real-world benchmarks and synthetic data sets. It also outperforms the state-of-the-art (SOTA) models on 6 out of 7 real-world benchmark datasets.
Remember This Event That Year? Assessing Temporal Information and Reasoning in Large Language Models
Feb 19, 2024Large Language Models (LLMs) are increasingly becoming ubiquitous, yet their ability to reason about and retain temporal information remains limited. This hinders their application in real-world scenarios where understanding the sequential nature of events is crucial. This paper experiments with state-of-the-art models on a novel, large-scale temporal dataset, \textbf{TempUN}, to reveal significant limitations in temporal retention and reasoning abilities. Interestingly, closed-source models indicate knowledge gaps more frequently, potentially suggesting a trade-off between uncertainty awareness and incorrect responses. Further, exploring various fine-tuning approaches yielded no major performance improvements. The associated dataset and code are available at the following URL (https://github.com/lingoiitgn/TempUN).
Exploring ChatGPT for Next-generation Information Retrieval: Opportunities and Challenges
Feb 17, 2024The rapid advancement of artificial intelligence (AI) has highlighted ChatGPT as a pivotal technology in the field of information retrieval (IR). Distinguished from its predecessors, ChatGPT offers significant benefits that have attracted the attention of both the industry and academic communities. While some view ChatGPT as a groundbreaking innovation, others attribute its success to the effective integration of product development and market strategies. The emergence of ChatGPT, alongside GPT-4, marks a new phase in Generative AI, generating content that is distinct from training examples and exceeding the capabilities of the prior GPT-3 model by OpenAI. Unlike the traditional supervised learning approach in IR tasks, ChatGPT challenges existing paradigms, bringing forth new challenges and opportunities regarding text quality assurance, model bias, and efficiency. This paper seeks to examine the impact of ChatGPT on IR tasks and offer insights into its potential future developments.
* Survey Paper
A Protein Structure Prediction Approach Leveraging Transformer and CNN Integration
Mar 08, 2024Proteins are essential for life, and their structure determines their function. The protein secondary structure is formed by the folding of the protein primary structure, and the protein tertiary structure is formed by the bending and folding of the secondary structure. Therefore, the study of protein secondary structure is very helpful to the overall understanding of protein structure. Although the accuracy of protein secondary structure prediction has continuously improved with the development of machine learning and deep learning, progress in the field of protein structure prediction, unfortunately, remains insufficient to meet the large demand for protein information. Therefore, based on the advantages of deep learning-based methods in feature extraction and learning ability, this paper adopts a two-dimensional fusion deep neural network model, DstruCCN, which uses Convolutional Neural Networks (CCN) and a supervised Transformer protein language model for single-sequence protein structure prediction. The training features of the two are combined to predict the protein Transformer binding site matrix, and then the three-dimensional structure is reconstructed using energy minimization.
Sparse Wearable Sonomyography Sensor-based Proprioceptive Proportional Control Across Multiple Gestures
Mar 08, 2024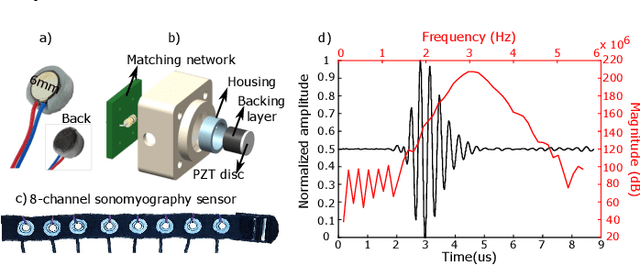
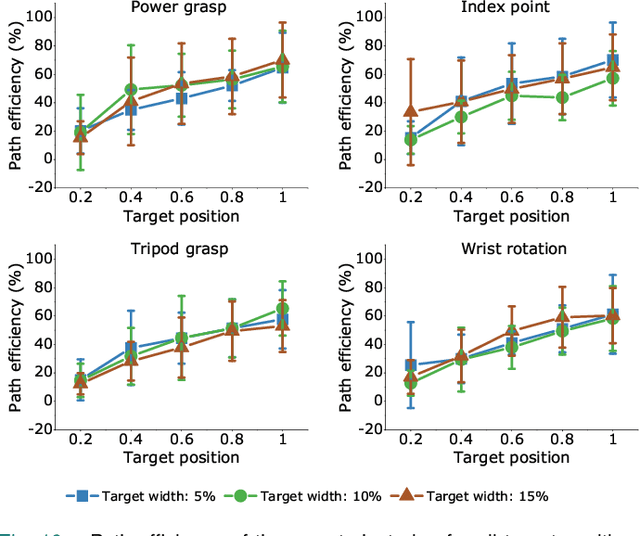
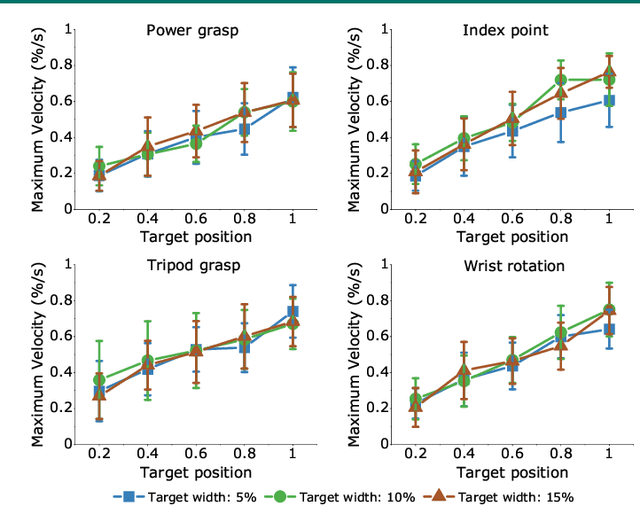
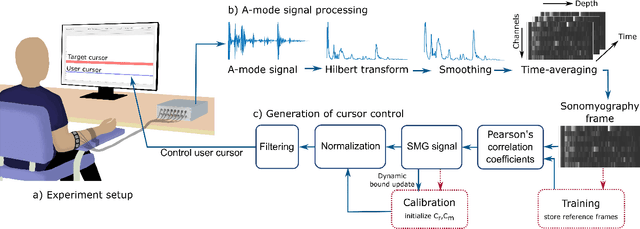
Sonomyography (SMG) is a non-invasive technique that uses ultrasound imaging to detect the dynamic activity of muscles. Wearable SMG systems have recently gained popularity due to their potential as human-computer interfaces for their superior performance compared to conventional methods. This paper demonstrates real-time positional proportional control of multiple gestures using a multiplexed 8-channel wearable SMG system. The amplitude-mode ultrasound signals from the SMG system were utilized to detect muscle activity from the forearm of 8 healthy individuals. The derived signals were used to control the on-screen movement of the cursor. A target achievement task was performed to analyze the performance of our SMG-based human-machine interface. Our wearable SMG system provided accurate, stable, and intuitive control in real-time by achieving an average success rate greater than 80% with all gestures. Furthermore, the wearable SMG system's abilities to detect volitional movement and decode movement kinematic information from SMG trajectories using standard performance metrics were evaluated. Our results provide insights to validate SMG as an intuitive human-machine interface.
GSEdit: Efficient Text-Guided Editing of 3D Objects via Gaussian Splatting
Mar 08, 2024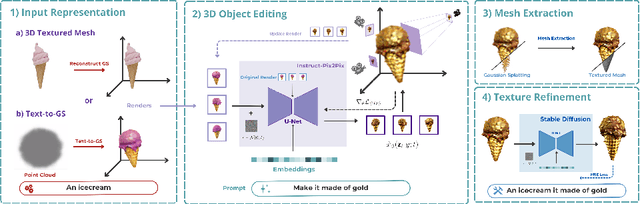


We present GSEdit, a pipeline for text-guided 3D object editing based on Gaussian Splatting models. Our method enables the editing of the style and appearance of 3D objects without altering their main details, all in a matter of minutes on consumer hardware. We tackle the problem by leveraging Gaussian splatting to represent 3D scenes, and we optimize the model while progressively varying the image supervision by means of a pretrained image-based diffusion model. The input object may be given as a 3D triangular mesh, or directly provided as Gaussians from a generative model such as DreamGaussian. GSEdit ensures consistency across different viewpoints, maintaining the integrity of the original object's information. Compared to previously proposed methods relying on NeRF-like MLP models, GSEdit stands out for its efficiency, making 3D editing tasks much faster. Our editing process is refined via the application of the SDS loss, ensuring that our edits are both precise and accurate. Our comprehensive evaluation demonstrates that GSEdit effectively alters object shape and appearance following the given textual instructions while preserving their coherence and detail.
FedFMS: Exploring Federated Foundation Models for Medical Image Segmentation
Mar 08, 2024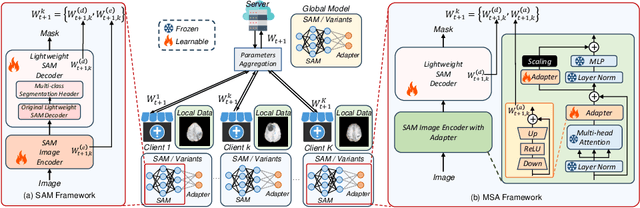
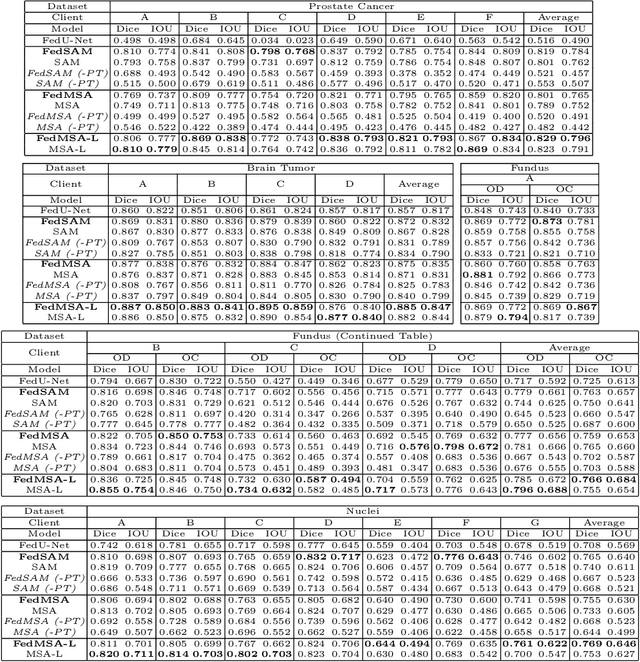
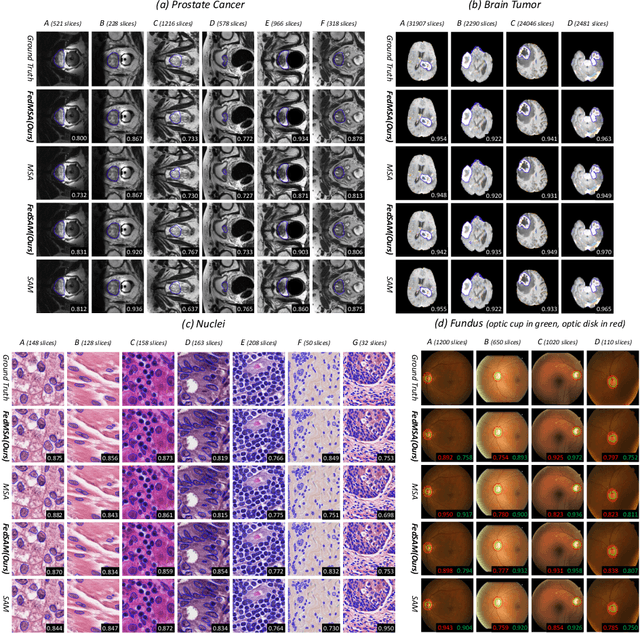

Medical image segmentation is crucial for clinical diagnosis. The Segmentation Anything Model (SAM) serves as a powerful foundation model for visual segmentation and can be adapted for medical image segmentation. However, medical imaging data typically contain privacy-sensitive information, making it challenging to train foundation models with centralized storage and sharing. To date, there are few foundation models tailored for medical image deployment within the federated learning framework, and the segmentation performance, as well as the efficiency of communication and training, remain unexplored. In response to these issues, we developed Federated Foundation models for Medical image Segmentation (FedFMS), which includes the Federated SAM (FedSAM) and a communication and training-efficient Federated SAM with Medical SAM Adapter (FedMSA). Comprehensive experiments on diverse datasets are conducted to investigate the performance disparities between centralized training and federated learning across various configurations of FedFMS. The experiments revealed that FedFMS could achieve performance comparable to models trained via centralized training methods while maintaining privacy. Furthermore, FedMSA demonstrated the potential to enhance communication and training efficiency. Our model implementation codes are available at https://github.com/LIU-YUXI/FedFMS.
Context-Based Multimodal Fusion
Mar 08, 2024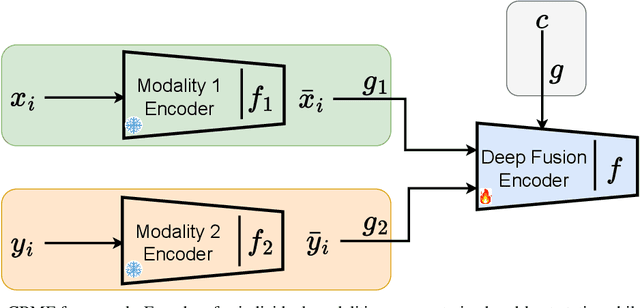
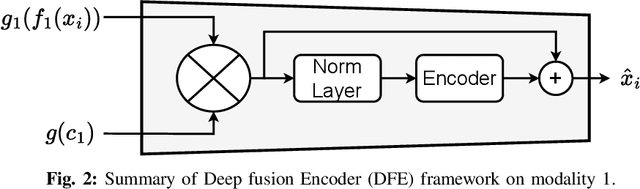
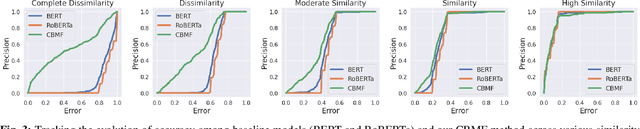
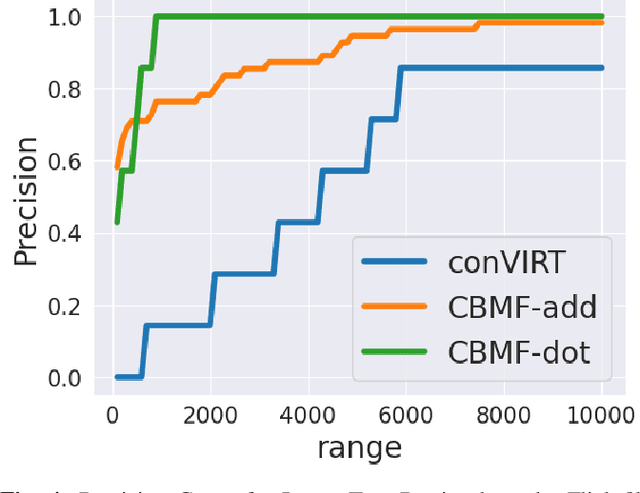
The fusion models, which effectively combine information from different sources, are widely used in solving multimodal tasks. However, they have significant limitations related to aligning data distributions across different modalities. This challenge can lead to inconsistencies and difficulties in learning robust representations. Alignment models, while specifically addressing this issue, often require training "from scratch" with large datasets to achieve optimal results, which can be costly in terms of resources and time. To overcome these limitations, we propose an innovative model called Context-Based Multimodal Fusion (CBMF), which combines both modality fusion and data distribution alignment. In CBMF, each modality is represented by a specific context vector, fused with the embedding of each modality. This enables the use of large pre-trained models that can be frozen, reducing the computational and training data requirements. Additionally, the network learns to differentiate embeddings of different modalities through fusion with context and aligns data distributions using a contrastive approach for self-supervised learning. Thus, CBMF offers an effective and economical solution for solving complex multimodal tasks.
Spectral Clustering of Categorical and Mixed-type Data via Extra Graph Nodes
Mar 08, 2024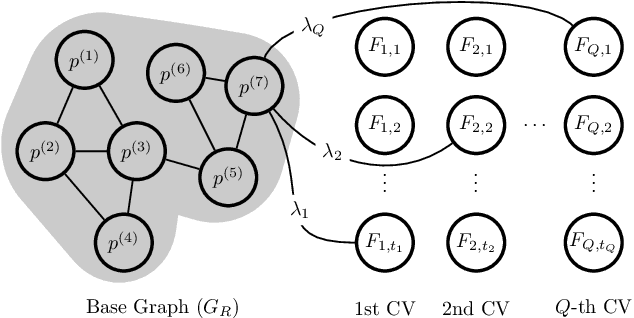
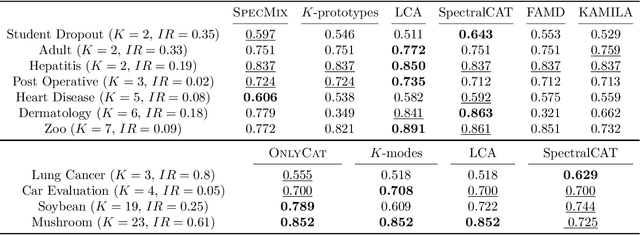
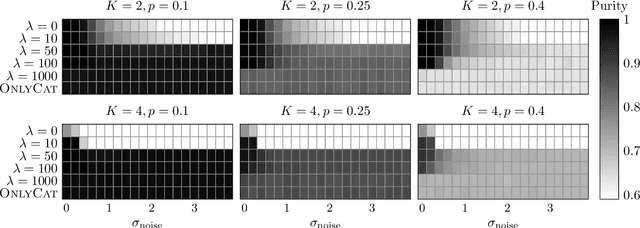
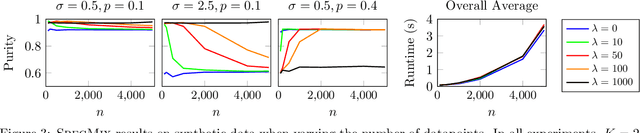
Clustering data objects into homogeneous groups is one of the most important tasks in data mining. Spectral clustering is arguably one of the most important algorithms for clustering, as it is appealing for its theoretical soundness and is adaptable to many real-world data settings. For example, mixed data, where the data is composed of numerical and categorical features, is typically handled via numerical discretization, dummy coding, or similarity computation that takes into account both data types. This paper explores a more natural way to incorporate both numerical and categorical information into the spectral clustering algorithm, avoiding the need for data preprocessing or the use of sophisticated similarity functions. We propose adding extra nodes corresponding to the different categories the data may belong to and show that it leads to an interpretable clustering objective function. Furthermore, we demonstrate that this simple framework leads to a linear-time spectral clustering algorithm for categorical-only data. Finally, we compare the performance of our algorithms against other related methods and show that it provides a competitive alternative to them in terms of performance and runtime.