 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Estimators of Entropy and Information via Inference in Probabilistic Models
Apr 13, 2022

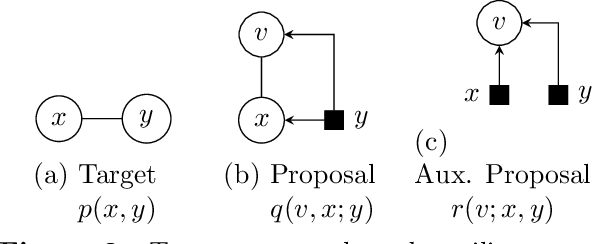
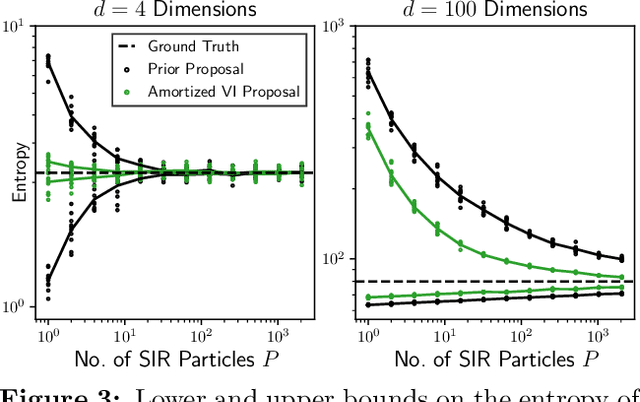
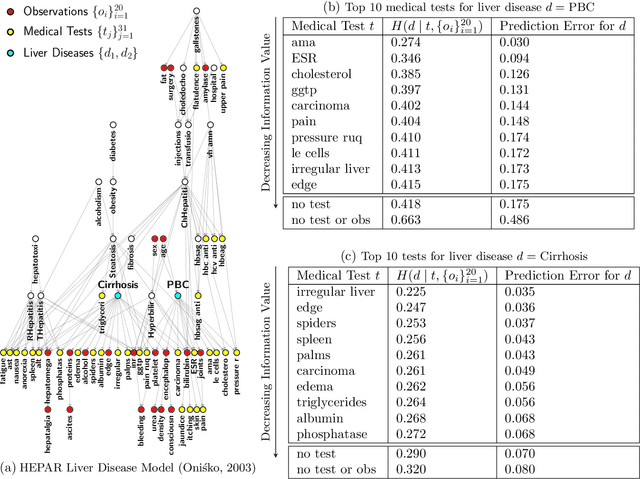
Estimating information-theoretic quantities such as entropy and mutual information is central to many problems in statistics and machine learning, but challenging in high dimensions. This paper presents estimators of entropy via inference (EEVI), which deliver upper and lower bounds on many information quantities for arbitrary variables in a probabilistic generative model. These estimators use importance sampling with proposal distribution families that include amortized variational inference and sequential Monte Carlo, which can be tailored to the target model and used to squeeze true information values with high accuracy. We present several theoretical properties of EEVI and demonstrate scalability and efficacy on two problems from the medical domain: (i) in an expert system for diagnosing liver disorders, we rank medical tests according to how informative they are about latent diseases, given a pattern of observed symptoms and patient attributes; and (ii) in a differential equation model of carbohydrate metabolism, we find optimal times to take blood glucose measurements that maximize information about a diabetic patient's insulin sensitivity, given their meal and medication schedule.
Unsupervised Domain Adaptation for Cardiac Segmentation: Towards Structure Mutual Information Maximization
Apr 20, 2022

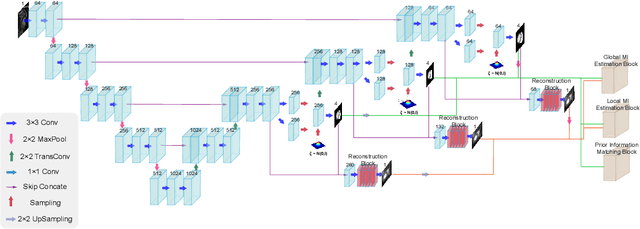
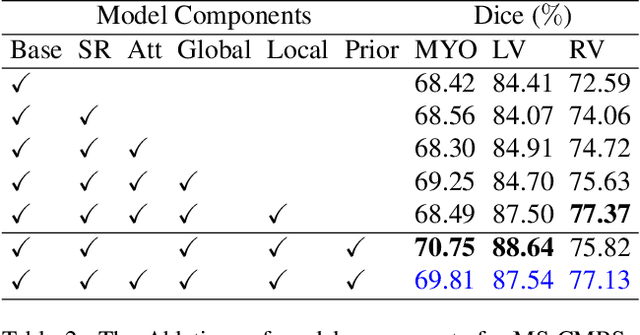
Unsupervised domain adaptation approaches have recently succeeded in various medical image segmentation tasks. The reported works often tackle the domain shift problem by aligning the domain-invariant features and minimizing the domain-specific discrepancies. That strategy works well when the difference between a specific domain and between different domains is slight. However, the generalization ability of these models on diverse imaging modalities remains a significant challenge. This paper introduces UDA-VAE++, an unsupervised domain adaptation framework for cardiac segmentation with a compact loss function lower bound. To estimate this new lower bound, we develop a novel Structure Mutual Information Estimation (SMIE) block with a global estimator, a local estimator, and a prior information matching estimator to maximize the mutual information between the reconstruction and segmentation tasks. Specifically, we design a novel sequential reparameterization scheme that enables information flow and variance correction from the low-resolution latent space to the high-resolution latent space. Comprehensive experiments on benchmark cardiac segmentation datasets demonstrate that our model outperforms previous state-of-the-art qualitatively and quantitatively. The code is available at https://github.com/LOUEY233/Toward-Mutual-Information}{https://github.com/LOUEY233/Toward-Mutual-Information
Attract me to Buy: Advertisement Copywriting Generation with Multimodal Multi-structured Information
May 07, 2022

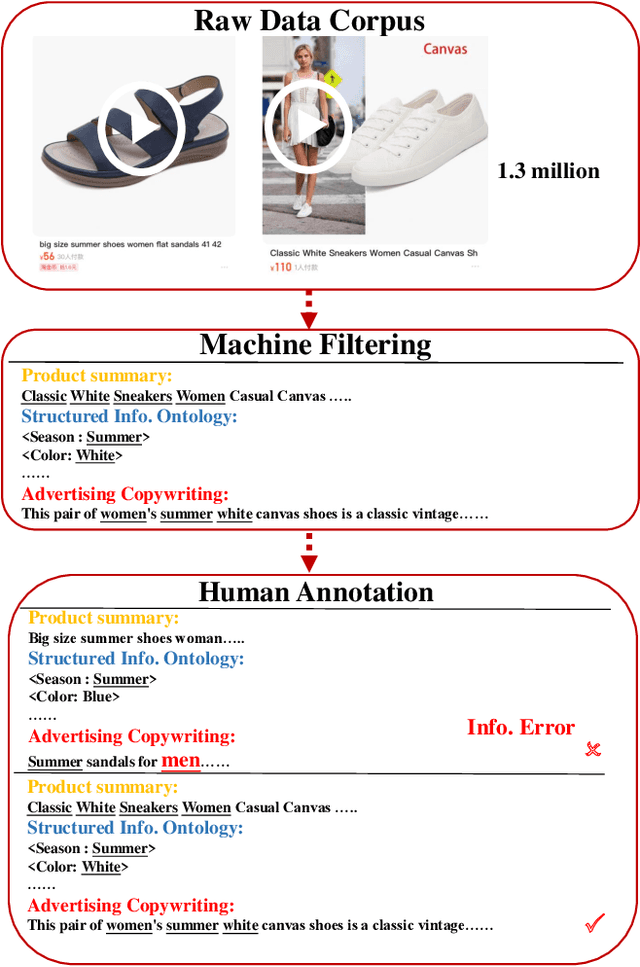
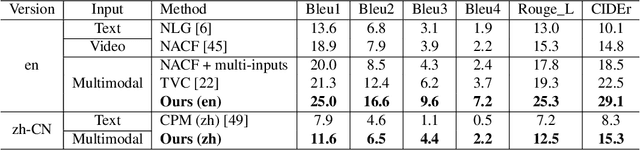
Recently, online shopping has gradually become a common way of shopping for people all over the world. Wonderful merchandise advertisements often attract more people to buy. These advertisements properly integrate multimodal multi-structured information of commodities, such as visual spatial information and fine-grained structure information. However, traditional multimodal text generation focuses on the conventional description of what existed and happened, which does not match the requirement of advertisement copywriting in the real world. Because advertisement copywriting has a vivid language style and higher requirements of faithfulness. Unfortunately, there is a lack of reusable evaluation frameworks and a scarcity of datasets. Therefore, we present a dataset, E-MMAD (e-commercial multimodal multi-structured advertisement copywriting), which requires, and supports much more detailed information in text generation. Noticeably, it is one of the largest video captioning datasets in this field. Accordingly, we propose a baseline method and faithfulness evaluation metric on the strength of structured information reasoning to solve the demand in reality on this dataset. It surpasses the previous methods by a large margin on all metrics. The dataset and method are coming soon on \url{https://e-mmad.github.io/e-mmad.net/index.html}.
Localization & Mapping Requirements for Level 2+ Autonomous Vehicles
Jan 05, 2023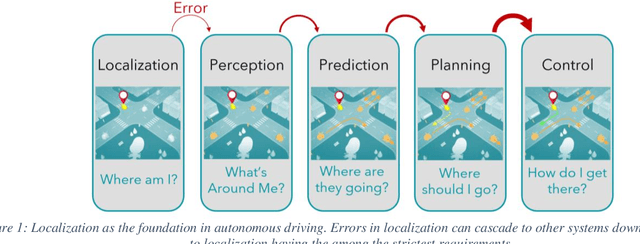
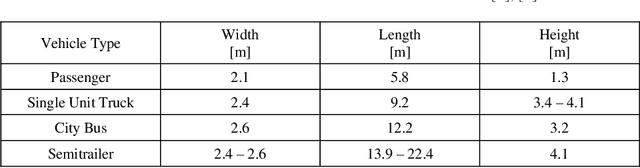
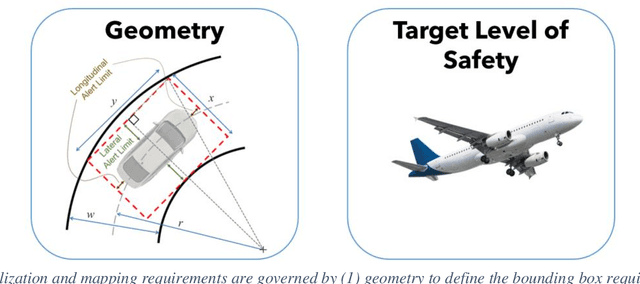
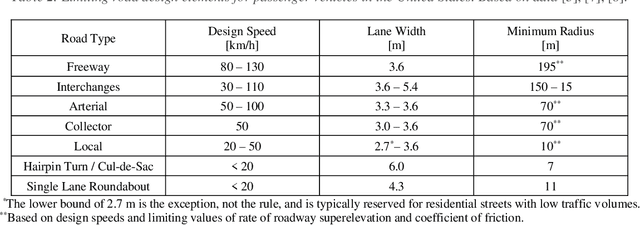
Autonomous vehicles are being deployed with a spectrum of capability, extending from driver assistance features for the highway in personal vehicles (SAE Level 2+) to fully autonomous fleet ride sharing services operating in complex city environments (SAE Level 4+). This spectrum of autonomy often operates in different physical environments with different degrees of assumed driver in-the-loop oversight and hence have very different system and subsystem requirements. At the heart of SAE Level 2 to 5 systems is localization and mapping, which ranges from road determination for feature geofencing or high-level routing, through lane determination for advanced driver assistance, to where-in-lane positioning for full vehicle control. We assess localization and mapping requirements for different levels of autonomy and supported features. This work provides a framework for system decomposition, including the level of redundancy needed to achieve the target level of safety. We examine several representative autonomous and assistance features and make recommendations on positioning requirements as well map georeferencing and information integrity.
Attention-Aware Anime Line Drawing Colorization
Jan 05, 2023
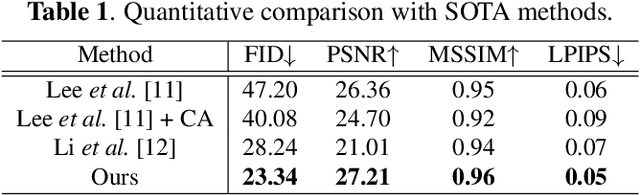
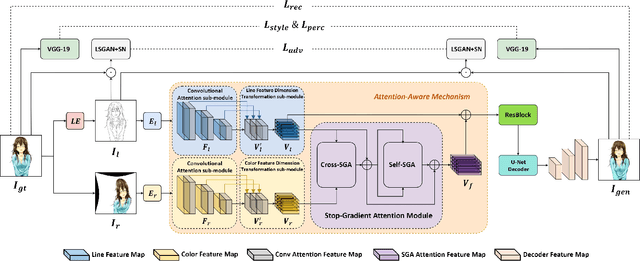

Automatic colorization of anime line drawing has attracted much attention in recent years since it can substantially benefit the animation industry. User-hint based methods are the mainstream approach for line drawing colorization, while reference-based methods offer a more intuitive approach. Nevertheless, although reference-based methods can improve feature aggregation of the reference image and the line drawing, the colorization results are not compelling in terms of color consistency or semantic correspondence. In this paper, we introduce an attention-based model for anime line drawing colorization, in which a channel-wise and spatial-wise Convolutional Attention module is used to improve the ability of the encoder for feature extraction and key area perception, and a Stop-Gradient Attention module with cross-attention and self-attention is used to tackle the cross-domain long-range dependency problem. Extensive experiments show that our method outperforms other SOTA methods, with more accurate line structure and semantic color information.
Deep Latent Variable Models for Semi-supervised Paraphrase Generation
Jan 05, 2023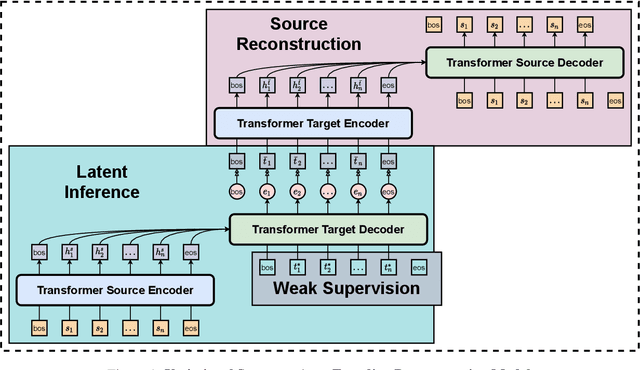
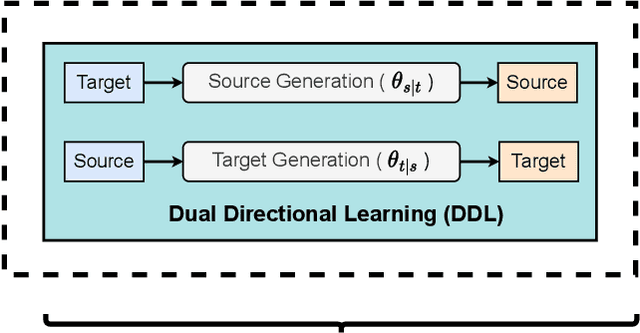
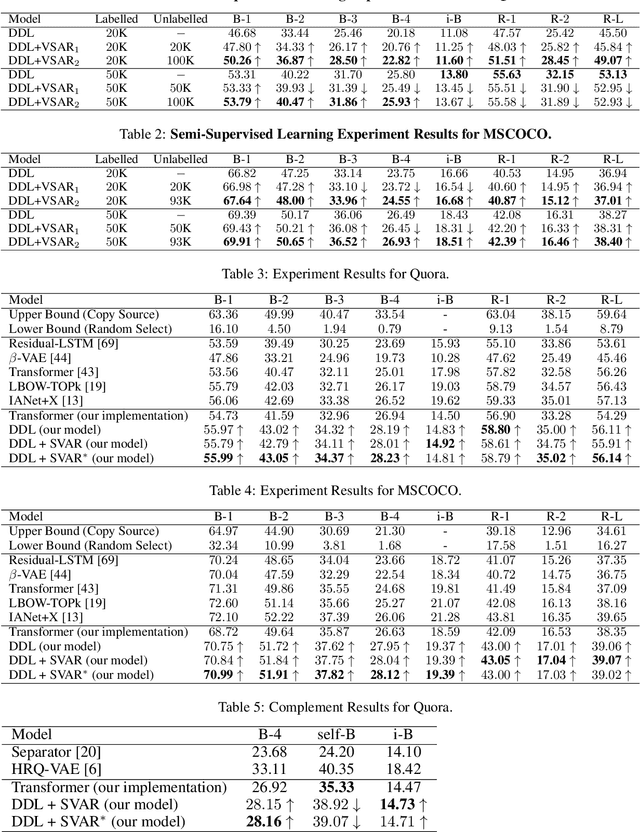
This paper explores deep latent variable models for semi-supervised paraphrase generation, where the missing target pair is modelled as a latent paraphrase sequence. We present a novel unsupervised model named variational sequence auto-encoding reconstruction (VSAR), which performs latent sequence inference given an observed text. To leverage information from text pairs, we introduce a supervised model named dual directional learning (DDL). Combining VSAR with DDL (DDL+VSAR) enables us to conduct semi-supervised learning; however, the combined model suffers from a cold-start problem. To combat this issue, we propose to deal with better weight initialisation, leading to a two-stage training scheme named knowledge reinforced training. Our empirical evaluations suggest that the combined model yields competitive performance against the state-of-the-art supervised baselines on complete data. Furthermore, in scenarios where only a fraction of the labelled pairs are available, our combined model consistently outperforms the strong supervised model baseline (DDL and Transformer) by a significant margin.
Open-Set Face Identification on Few-Shot Gallery by Fine-Tuning
Jan 05, 2023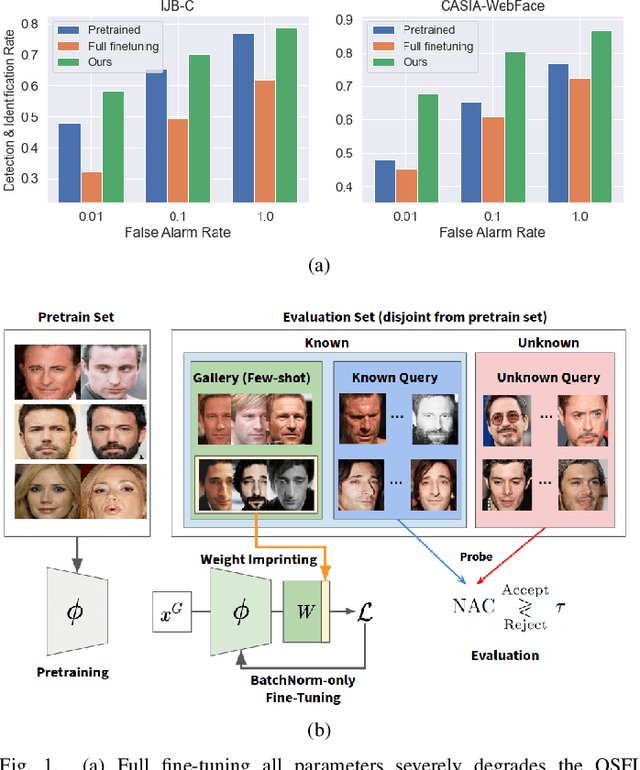
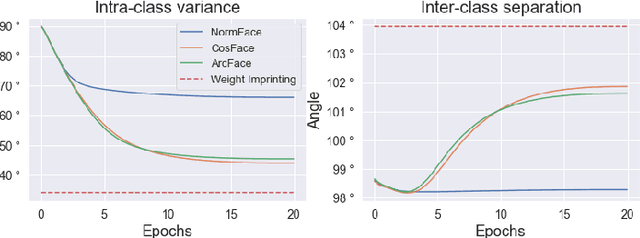
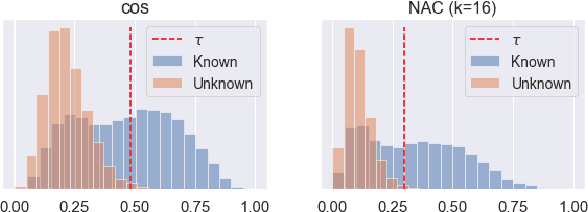
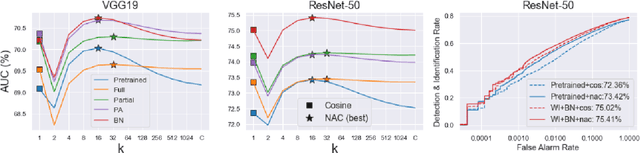
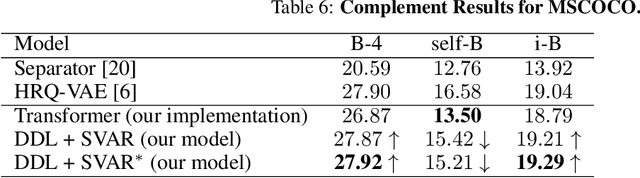
In this paper, we focus on addressing the open-set face identification problem on a few-shot gallery by fine-tuning. The problem assumes a realistic scenario for face identification, where only a small number of face images is given for enrollment and any unknown identity must be rejected during identification. We observe that face recognition models pretrained on a large dataset and naively fine-tuned models perform poorly for this task. Motivated by this issue, we propose an effective fine-tuning scheme with classifier weight imprinting and exclusive BatchNorm layer tuning. For further improvement of rejection accuracy on unknown identities, we propose a novel matcher called Neighborhood Aware Cosine (NAC) that computes similarity based on neighborhood information. We validate the effectiveness of the proposed schemes thoroughly on large-scale face benchmarks across different convolutional neural network architectures. The source code for this project is available at: https://github.com/1ho0jin1/OSFI-by-FineTuning
k-Sliced Mutual Information: A Quantitative Study of Scalability with Dimension
Jun 17, 2022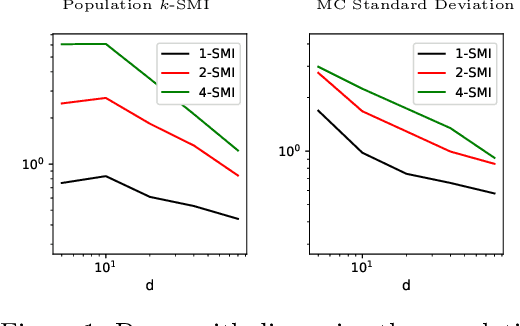

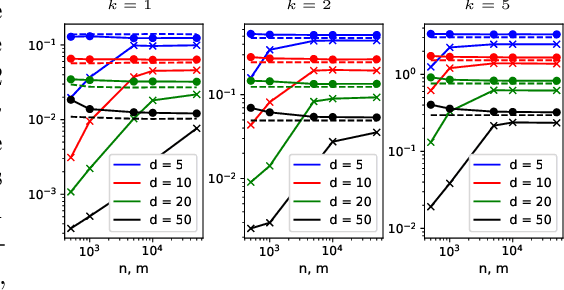

Sliced mutual information (SMI) is defined as an average of mutual information (MI) terms between one-dimensional random projections of the random variables. It serves as a surrogate measure of dependence to classic MI that preserves many of its properties but is more scalable to high dimensions. However, a quantitative characterization of how SMI itself and estimation rates thereof depend on the ambient dimension, which is crucial to the understanding of scalability, remain obscure. This works extends the original SMI definition to $k$-SMI, which considers projections to $k$-dimensional subspaces, and provides a multifaceted account on its dependence on dimension. Using a new result on the continuity of differential entropy in the 2-Wasserstein metric, we derive sharp bounds on the error of Monte Carlo (MC)-based estimates of $k$-SMI, with explicit dependence on $k$ and the ambient dimension, revealing their interplay with the number of samples. We then combine the MC integrator with the neural estimation framework to provide an end-to-end $k$-SMI estimator, for which optimal convergence rates are established. We also explore asymptotics of the population $k$-SMI as dimension grows, providing Gaussian approximation results with a residual that decays under appropriate moment bounds. Our theory is validated with numerical experiments and is applied to sliced InfoGAN, which altogether provide a comprehensive quantitative account of the scalability question of $k$-SMI, including SMI as a special case when $k=1$.
Multi-Target Decision Making under Conditions of Severe Uncertainty
Dec 13, 2022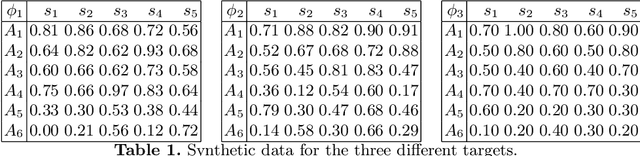
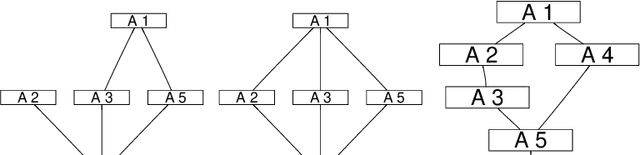

The quality of consequences in a decision making problem under (severe) uncertainty must often be compared among different targets (goals, objectives) simultaneously. In addition, the evaluations of a consequence's performance under the various targets often differ in their scale of measurement, classically being either purely ordinal or perfectly cardinal. In this paper, we transfer recent developments from abstract decision theory with incomplete preferential and probabilistic information to this multi-target setting and show how -- by exploiting the (potentially) partial cardinal and partial probabilistic information -- more informative orders for comparing decisions can be given than the Pareto order. We discuss some interesting properties of the proposed orders between decision options and show how they can be concretely computed by linear optimization. We conclude the paper by demonstrating our framework in an artificial (but quite real-world) example in the context of comparing algorithms under different performance measures.
Self-Supervised Object Segmentation with a Cut-and-Pasting GAN
Jan 01, 2023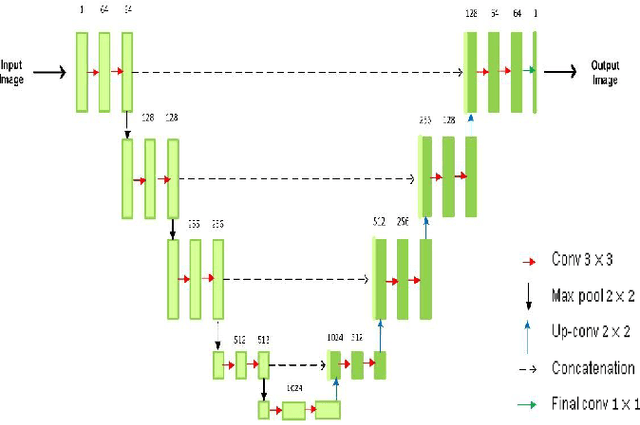
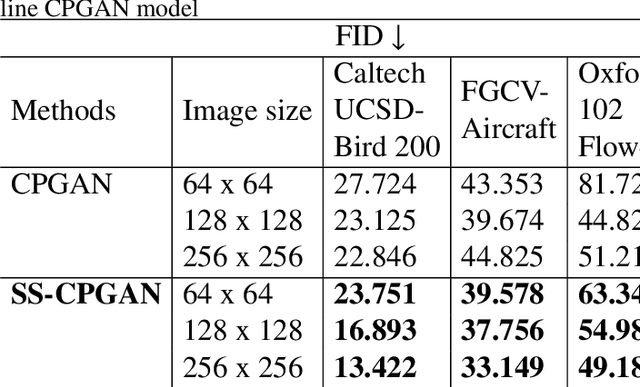
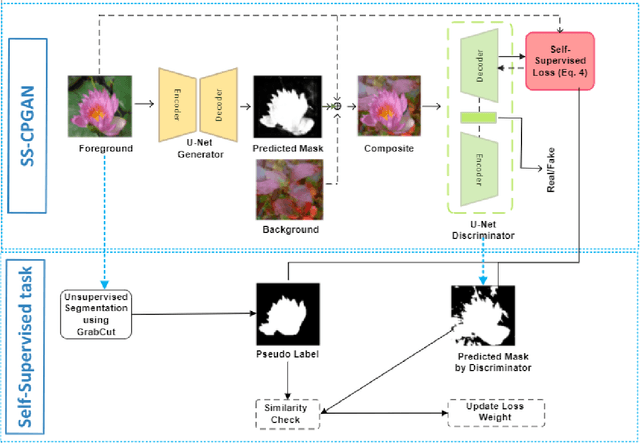
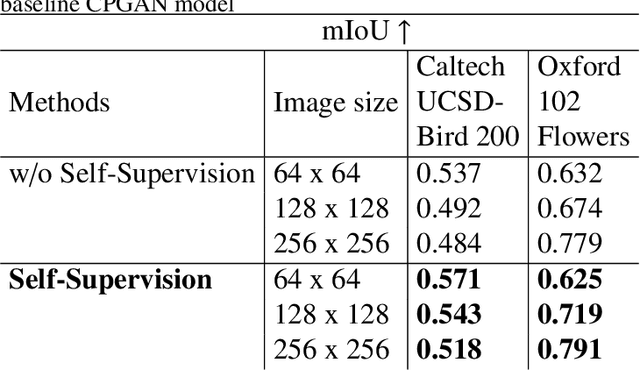
This paper proposes a novel self-supervised based Cut-and-Paste GAN to perform foreground object segmentation and generate realistic composite images without manual annotations. We accomplish this goal by a simple yet effective self-supervised approach coupled with the U-Net based discriminator. The proposed method extends the ability of the standard discriminators to learn not only the global data representations via classification (real/fake) but also learn semantic and structural information through pseudo labels created using the self-supervised task. The proposed method empowers the generator to create meaningful masks by forcing it to learn informative per-pixel as well as global image feedback from the discriminator. Our experiments demonstrate that our proposed method significantly outperforms the state-of-the-art methods on the standard benchmark datasets.