 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Predicting Drivers' Route Trajectories in Last-Mile Delivery Using A Pair-wise Attention-based Pointer Neural Network
Jan 10, 2023
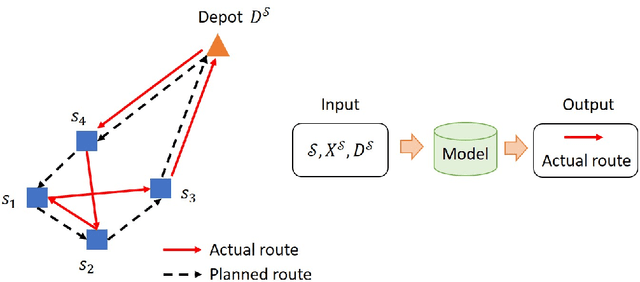
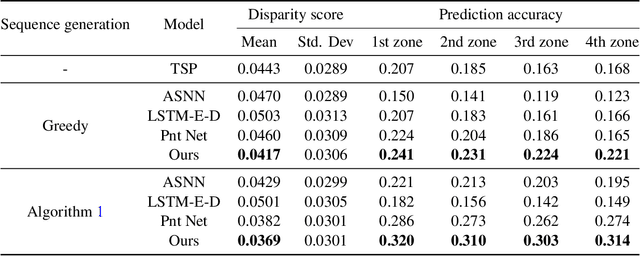
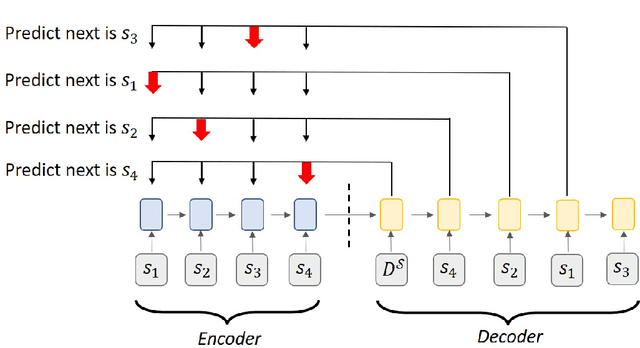
In last-mile delivery, drivers frequently deviate from planned delivery routes because of their tacit knowledge of the road and curbside infrastructure, customer availability, and other characteristics of the respective service areas. Hence, the actual stop sequences chosen by an experienced human driver may be potentially preferable to the theoretical shortest-distance routing under real-life operational conditions. Thus, being able to predict the actual stop sequence that a human driver would follow can help to improve route planning in last-mile delivery. This paper proposes a pair-wise attention-based pointer neural network for this prediction task using drivers' historical delivery trajectory data. In addition to the commonly used encoder-decoder architecture for sequence-to-sequence prediction, we propose a new attention mechanism based on an alternative specific neural network to capture the local pair-wise information for each pair of stops. To further capture the global efficiency of the route, we propose a new iterative sequence generation algorithm that is used after model training to identify the first stop of a route that yields the lowest operational cost. Results from an extensive case study on real operational data from Amazon's last-mile delivery operations in the US show that our proposed method can significantly outperform traditional optimization-based approaches and other machine learning methods (such as the Long Short-Term Memory encoder-decoder and the original pointer network) in finding stop sequences that are closer to high-quality routes executed by experienced drivers in the field. Compared to benchmark models, the proposed model can increase the average prediction accuracy of the first four stops from around 0.2 to 0.312, and reduce the disparity between the predicted route and the actual route by around 15%.
On the Robustness of AlphaFold: A COVID-19 Case Study
Jan 10, 2023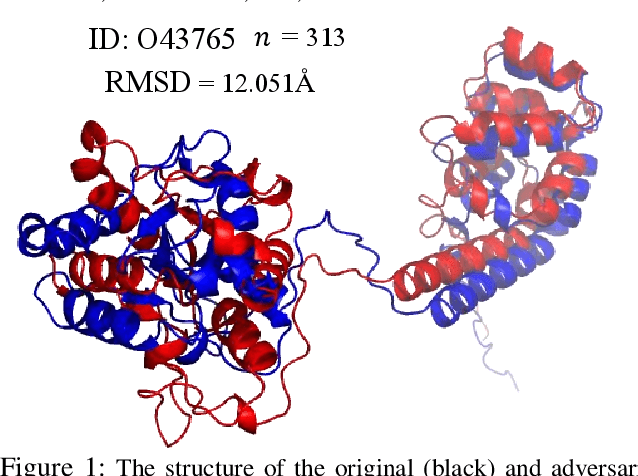
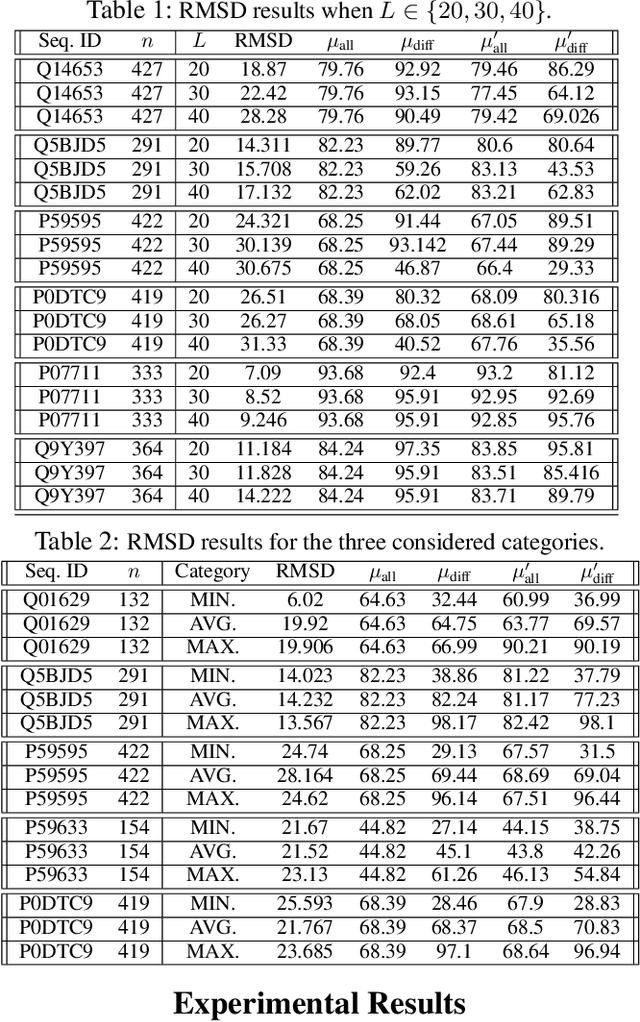
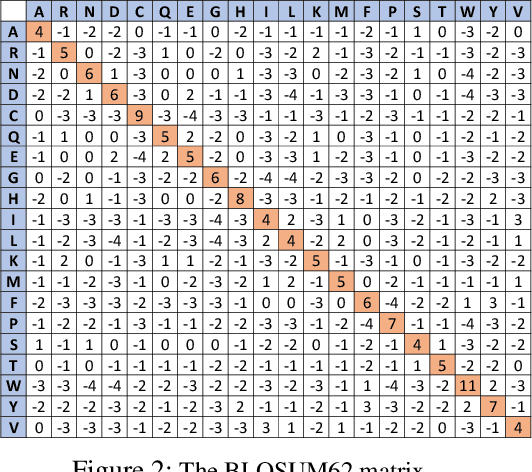

Protein folding neural networks (PFNNs) such as AlphaFold predict remarkably accurate structures of proteins compared to other approaches. However, the robustness of such networks has heretofore not been explored. This is particularly relevant given the broad social implications of such technologies and the fact that biologically small perturbations in the protein sequence do not generally lead to drastic changes in the protein structure. In this paper, we demonstrate that AlphaFold does not exhibit such robustness despite its high accuracy. This raises the challenge of detecting and quantifying the extent to which these predicted protein structures can be trusted. To measure the robustness of the predicted structures, we utilize (i) the root-mean-square deviation (RMSD) and (ii) the Global Distance Test (GDT) similarity measure between the predicted structure of the original sequence and the structure of its adversarially perturbed version. We prove that the problem of minimally perturbing protein sequences to fool protein folding neural networks is NP-complete. Based on the well-established BLOSUM62 sequence alignment scoring matrix, we generate adversarial protein sequences and show that the RMSD between the predicted protein structure and the structure of the original sequence are very large when the adversarial changes are bounded by (i) 20 units in the BLOSUM62 distance, and (ii) five residues (out of hundreds or thousands of residues) in the given protein sequence. In our experimental evaluation, we consider 111 COVID-19 proteins in the Universal Protein resource (UniProt), a central resource for protein data managed by the European Bioinformatics Institute, Swiss Institute of Bioinformatics, and the US Protein Information Resource. These result in an overall GDT similarity test score average of around 34%, demonstrating a substantial drop in the performance of AlphaFold.
In Quest of Ground Truth: Learning Confident Models and Estimating Uncertainty in the Presence of Annotator Noise
Jan 02, 2023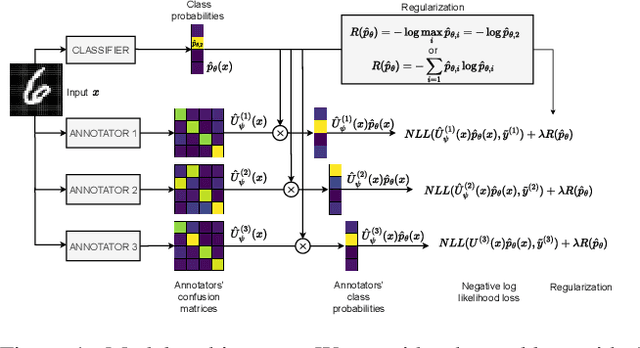
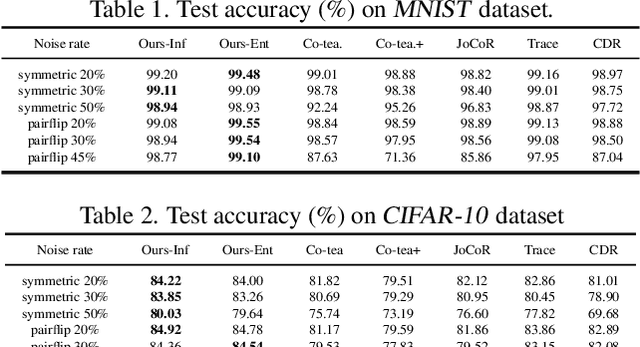
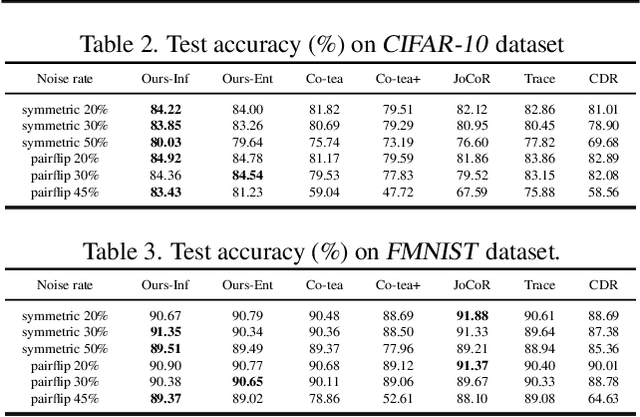
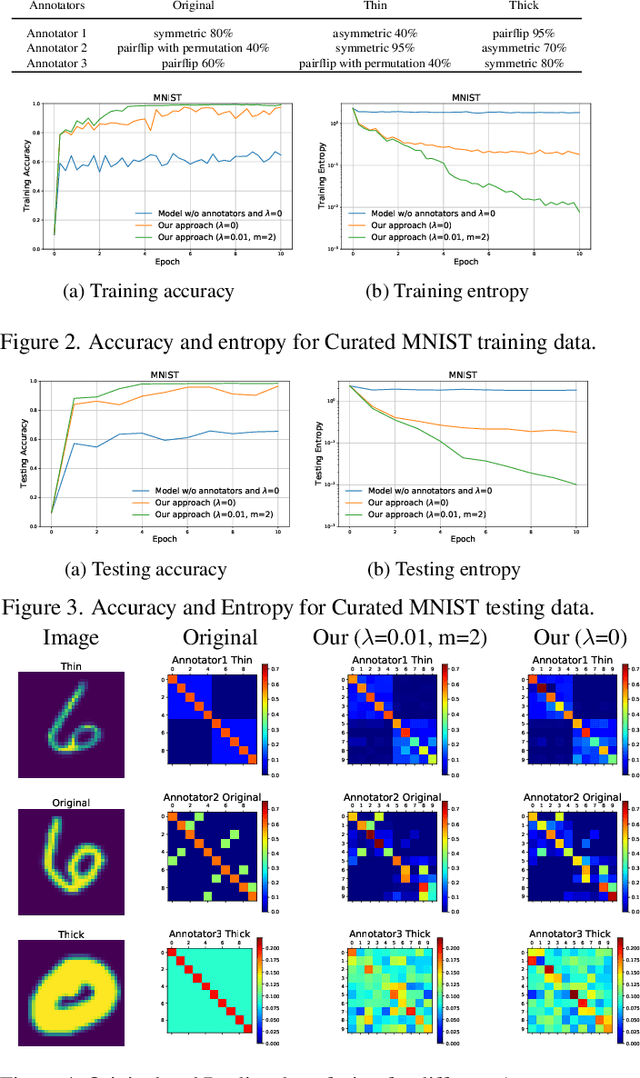
The performance of the Deep Learning (DL) models depends on the quality of labels. In some areas, the involvement of human annotators may lead to noise in the data. When these corrupted labels are blindly regarded as the ground truth (GT), DL models suffer from performance deficiency. This paper presents a method that aims to learn a confident model in the presence of noisy labels. This is done in conjunction with estimating the uncertainty of multiple annotators. We robustly estimate the predictions given only the noisy labels by adding entropy or information-based regularizer to the classifier network. We conduct our experiments on a noisy version of MNIST, CIFAR-10, and FMNIST datasets. Our empirical results demonstrate the robustness of our method as it outperforms or performs comparably to other state-of-the-art (SOTA) methods. In addition, we evaluated the proposed method on the curated dataset, where the noise type and level of various annotators depend on the input image style. We show that our approach performs well and is adept at learning annotators' confusion. Moreover, we demonstrate how our model is more confident in predicting GT than other baselines. Finally, we assess our approach for segmentation problem and showcase its effectiveness with experiments.
Understanding the main failure scenarios of subsea blowout preventers systems: An approach through Latent Semantic Analysis
Jan 02, 2023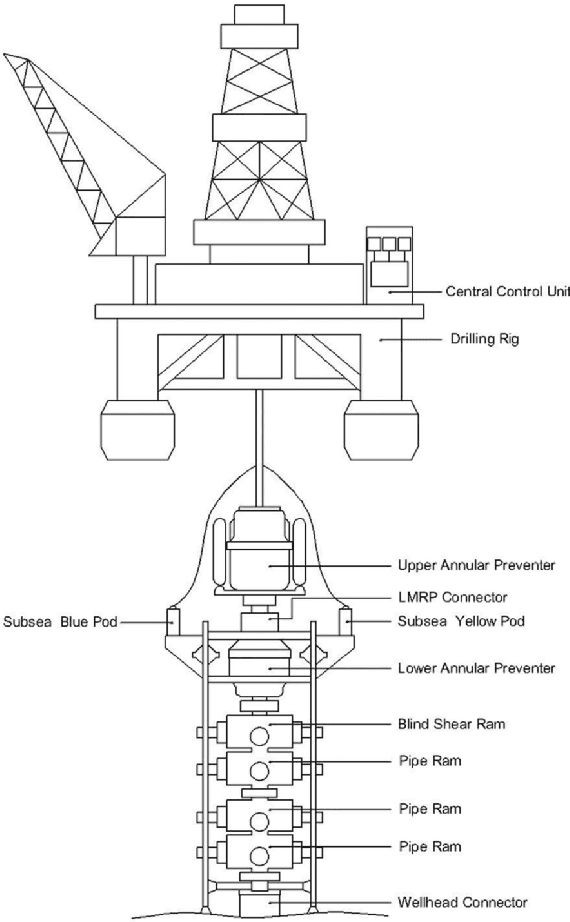
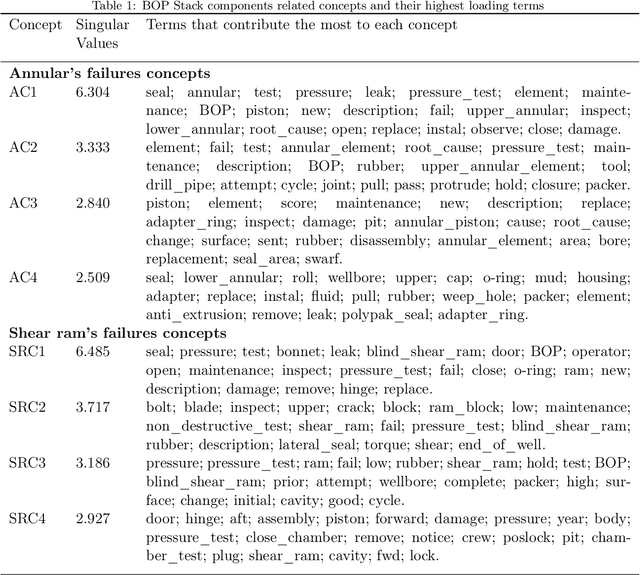
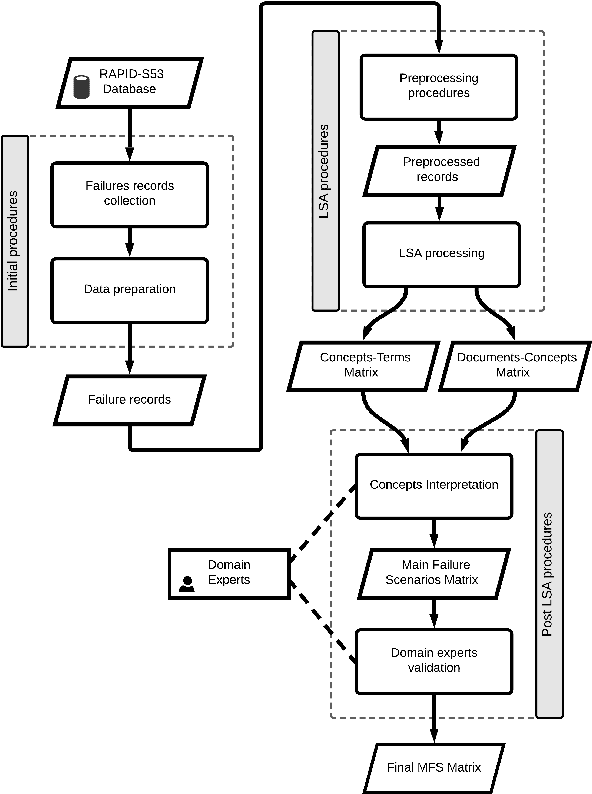
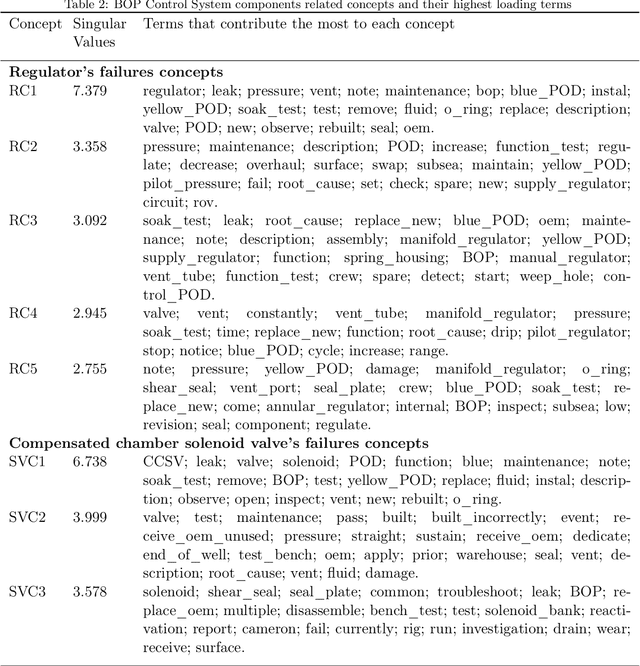
The blowout preventer (BOP) system is one of the most important well safety barriers during the drilling phase because it can prevent the development of blowout events. This paper investigates BOP system's main failures using an LSA-based methodology. A total of 1312 failure records from companies worldwide were collected from the International Association of Drilling Contractors' RAPID-S53 database. The database contains recordings of halted drilling operations due to BOP system's failures and component's function deviations. The main failure scenarios of the components annular preventer, shear rams preventer, compensated chamber solenoid valve, and hydraulic regulators were identified using the proposed methodology. The scenarios contained valuable information about corrective maintenance procedures, such as frequently observed failure modes, detection methods used, suspected causes, and corrective actions. The findings highlighted that the major failures of the components under consideration were leakages caused by damaged elastomeric seals. The majority of the failures were detected during function and pressure tests with the BOP system in the rig. This study provides an alternative safety analysis that contributes to understanding blowout preventer system's critical component failures by applying a methodology based on a well-established text mining technique and analyzing failure records from an international database.
Situation-Aware Deep Reinforcement Learning for Autonomous Nonlinear Mobility Control in Cyber-Physical Loitering Munition Systems
Dec 31, 2022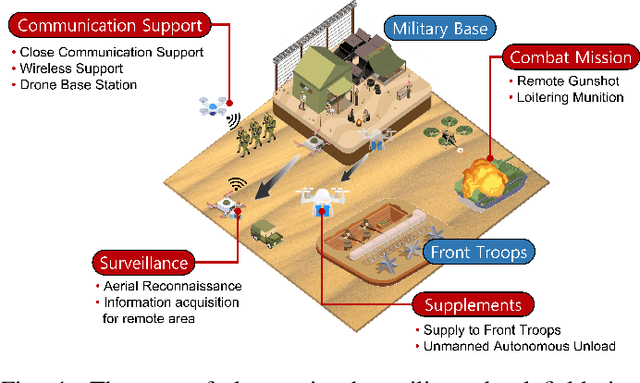
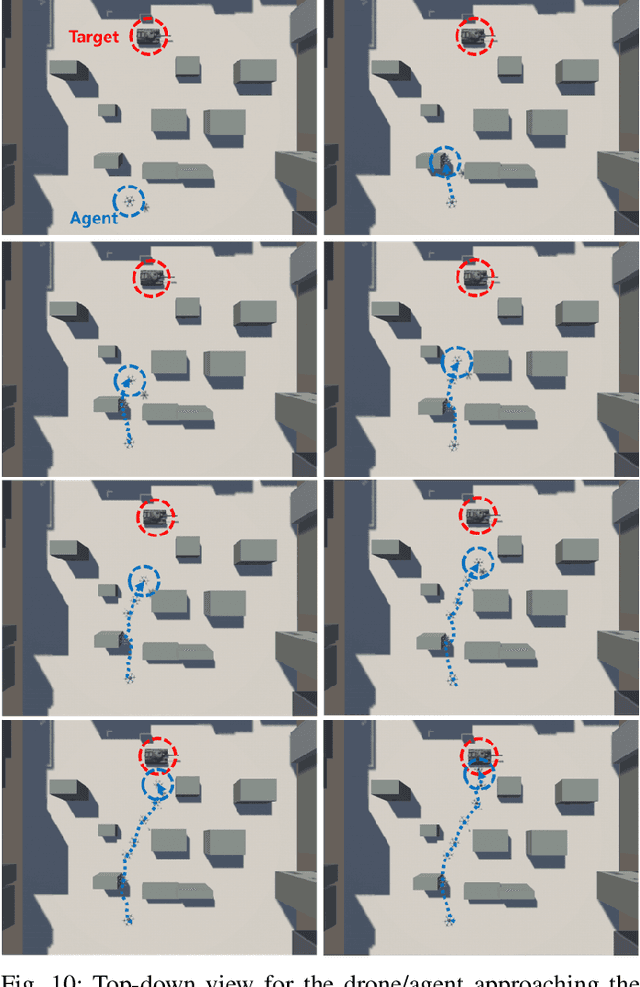

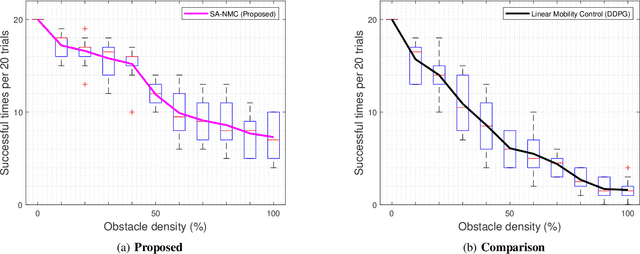
According to the rapid development of drone technologies, drones are widely used in many applications including military domains. In this paper, a novel situation-aware DRL- based autonomous nonlinear drone mobility control algorithm in cyber-physical loitering munition applications. On the battlefield, the design of DRL-based autonomous control algorithm is not straightforward because real-world data gathering is generally not available. Therefore, the approach in this paper is that cyber-physical virtual environment is constructed with Unity environment. Based on the virtual cyber-physical battlefield scenarios, a DRL-based automated nonlinear drone mobility control algorithm can be designed, evaluated, and visualized. Moreover, many obstacles exist which is harmful for linear trajectory control in real-world battlefield scenarios. Thus, our proposed autonomous nonlinear drone mobility control algorithm utilizes situation-aware components those are implemented with a Raycast function in Unity virtual scenarios. Based on the gathered situation-aware information, the drone can autonomously and nonlinearly adjust its trajectory during flight. Therefore, this approach is obviously beneficial for avoiding obstacles in obstacle-deployed battlefields. Our visualization-based performance evaluation shows that the proposed algorithm is superior from the other linear mobility control algorithms.
Semantic Table Detection with LayoutLMv3
Nov 25, 2022

This paper presents an application of the LayoutLMv3 model for semantic table detection on financial documents from the IIIT-AR-13K dataset. The motivation behind this paper's experiment was that LayoutLMv3's official paper had no results for table detection using semantic information. We concluded that our approach did not improve the model's table detection capabilities, for which we can give several possible reasons. Either the model's weights were unsuitable for our purpose, or we needed to invest more time in optimising the model's hyperparameters. It is also possible that semantic information does not improve a model's table detection accuracy.
Faithful and Consistent Graph Neural Network Explanations with Rationale Alignment
Jan 07, 2023
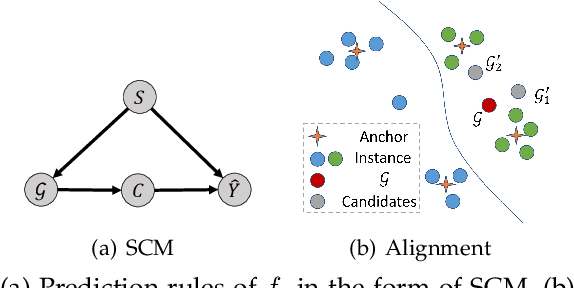
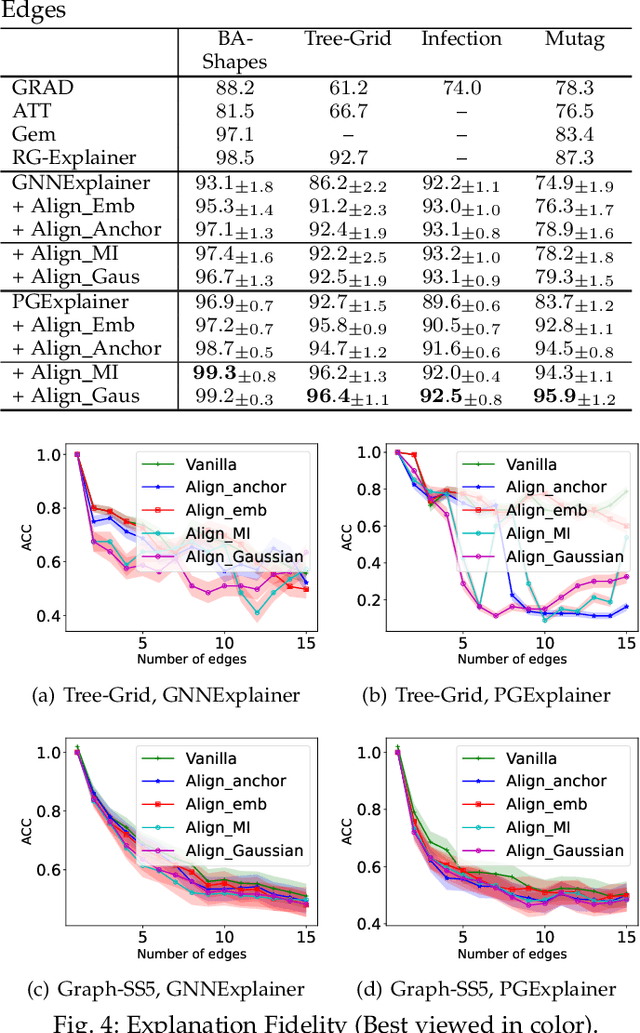
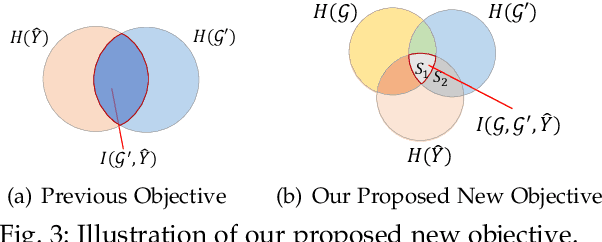
Uncovering rationales behind predictions of graph neural networks (GNNs) has received increasing attention over recent years. Instance-level GNN explanation aims to discover critical input elements, like nodes or edges, that the target GNN relies upon for making predictions. %These identified sub-structures can provide interpretations of GNN's behavior. Though various algorithms are proposed, most of them formalize this task by searching the minimal subgraph which can preserve original predictions. However, an inductive bias is deep-rooted in this framework: several subgraphs can result in the same or similar outputs as the original graphs. Consequently, they have the danger of providing spurious explanations and failing to provide consistent explanations. Applying them to explain weakly-performed GNNs would further amplify these issues. To address this problem, we theoretically examine the predictions of GNNs from the causality perspective. Two typical reasons for spurious explanations are identified: confounding effect of latent variables like distribution shift, and causal factors distinct from the original input. Observing that both confounding effects and diverse causal rationales are encoded in internal representations, \tianxiang{we propose a new explanation framework with an auxiliary alignment loss, which is theoretically proven to be optimizing a more faithful explanation objective intrinsically. Concretely for this alignment loss, a set of different perspectives are explored: anchor-based alignment, distributional alignment based on Gaussian mixture models, mutual-information-based alignment, etc. A comprehensive study is conducted both on the effectiveness of this new framework in terms of explanation faithfulness/consistency and on the advantages of these variants.
Lightweight Salient Object Detection in Optical Remote Sensing Images via Semantic Matching and Edge Alignment
Jan 07, 2023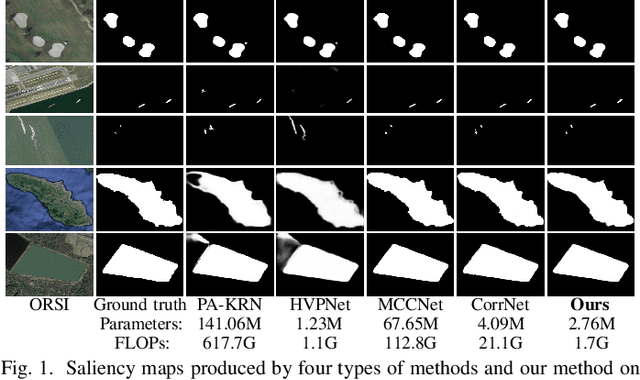
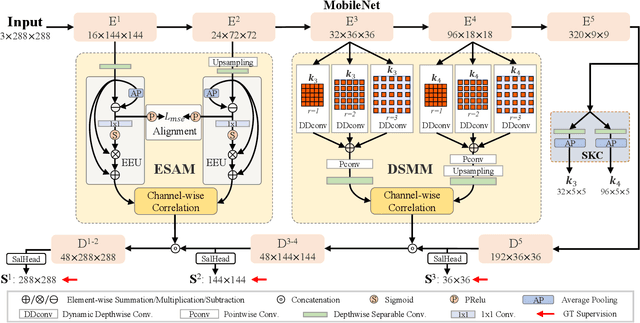
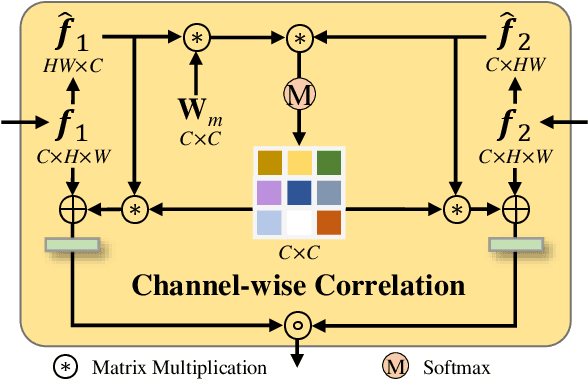

Recently, relying on convolutional neural networks (CNNs), many methods for salient object detection in optical remote sensing images (ORSI-SOD) are proposed. However, most methods ignore the huge parameters and computational cost brought by CNNs, and only a few pay attention to the portability and mobility. To facilitate practical applications, in this paper, we propose a novel lightweight network for ORSI-SOD based on semantic matching and edge alignment, termed SeaNet. Specifically, SeaNet includes a lightweight MobileNet-V2 for feature extraction, a dynamic semantic matching module (DSMM) for high-level features, an edge self-alignment module (ESAM) for low-level features, and a portable decoder for inference. First, the high-level features are compressed into semantic kernels. Then, semantic kernels are used to activate salient object locations in two groups of high-level features through dynamic convolution operations in DSMM. Meanwhile, in ESAM, cross-scale edge information extracted from two groups of low-level features is self-aligned through L2 loss and used for detail enhancement. Finally, starting from the highest-level features, the decoder infers salient objects based on the accurate locations and fine details contained in the outputs of the two modules. Extensive experiments on two public datasets demonstrate that our lightweight SeaNet not only outperforms most state-of-the-art lightweight methods but also yields comparable accuracy with state-of-the-art conventional methods, while having only 2.76M parameters and running with 1.7G FLOPs for 288x288 inputs. Our code and results are available at https://github.com/MathLee/SeaNet.
Hybrid Transformer Based Feature Fusion for Self-Supervised Monocular Depth Estimation
Nov 20, 2022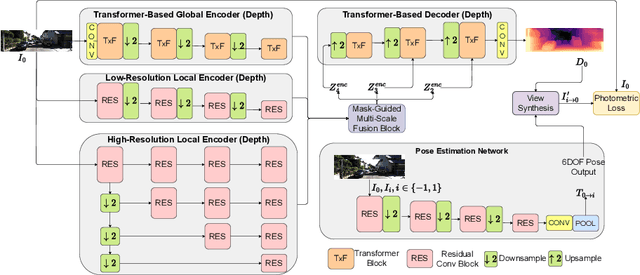
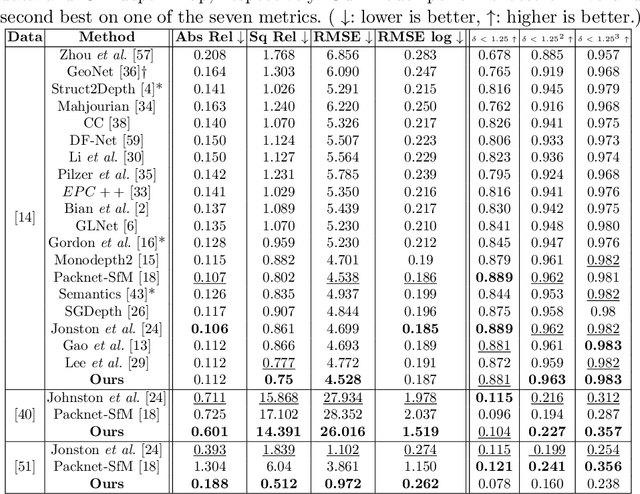
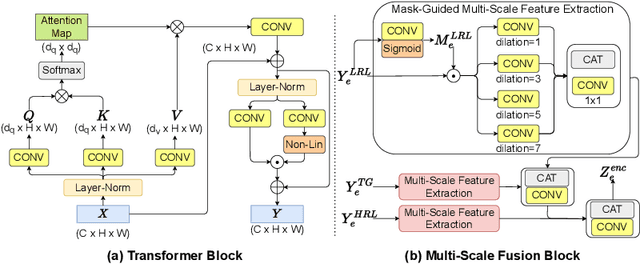

With an unprecedented increase in the number of agents and systems that aim to navigate the real world using visual cues and the rising impetus for 3D Vision Models, the importance of depth estimation is hard to understate. While supervised methods remain the gold standard in the domain, the copious amount of paired stereo data required to train such models makes them impractical. Most State of the Art (SOTA) works in the self-supervised and unsupervised domain employ a ResNet-based encoder architecture to predict disparity maps from a given input image which are eventually used alongside a camera pose estimator to predict depth without direct supervision. The fully convolutional nature of ResNets makes them susceptible to capturing per-pixel local information only, which is suboptimal for depth prediction. Our key insight for doing away with this bottleneck is to use Vision Transformers, which employ self-attention to capture the global contextual information present in an input image. Our model fuses per-pixel local information learned using two fully convolutional depth encoders with global contextual information learned by a transformer encoder at different scales. It does so using a mask-guided multi-stream convolution in the feature space to achieve state-of-the-art performance on most standard benchmarks.
ViT2Hash: Unsupervised Information-Preserving Hashing
Jan 14, 2022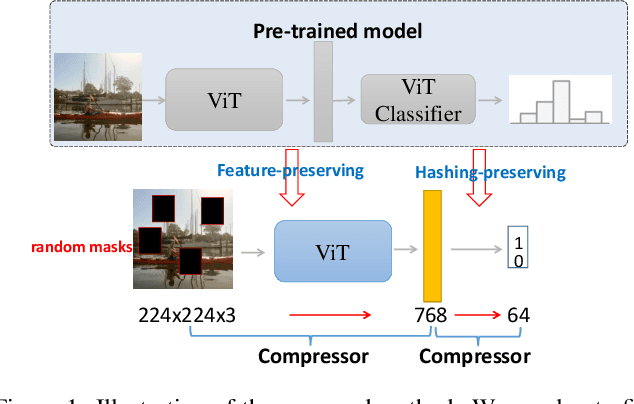
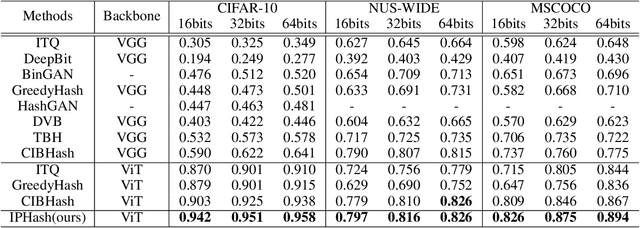
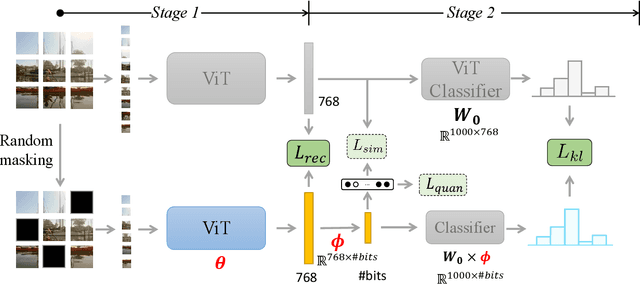
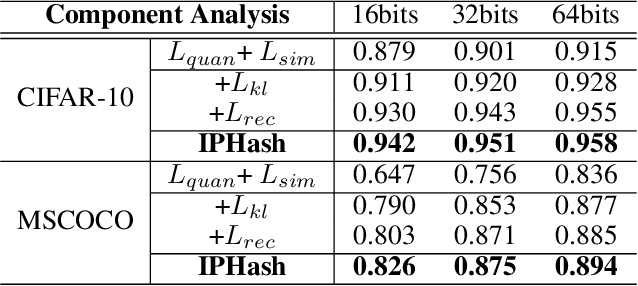
Unsupervised image hashing, which maps images into binary codes without supervision, is a compressor with a high compression rate. Hence, how to preserving meaningful information of the original data is a critical problem. Inspired by the large-scale vision pre-training model, known as ViT, which has shown significant progress for learning visual representations, in this paper, we propose a simple information-preserving compressor to finetune the ViT model for the target unsupervised hashing task. Specifically, from pixels to continuous features, we first propose a feature-preserving module, using the corrupted image as input to reconstruct the original feature from the pre-trained ViT model and the complete image, so that the feature extractor can focus on preserving the meaningful information of original data. Secondly, from continuous features to hash codes, we propose a hashing-preserving module, which aims to keep the semantic information from the pre-trained ViT model by using the proposed Kullback-Leibler divergence loss. Besides, the quantization loss and the similarity loss are added to minimize the quantization error. Our method is very simple and achieves a significantly higher degree of MAP on three benchmark image datasets.