 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
FECAM: Frequency Enhanced Channel Attention Mechanism for Time Series Forecasting
Dec 02, 2022


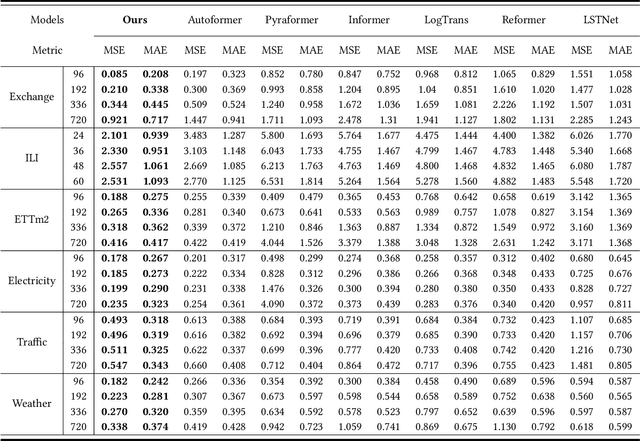
Time series forecasting is a long-standing challenge due to the real-world information is in various scenario (e.g., energy, weather, traffic, economics, earthquake warning). However some mainstream forecasting model forecasting result is derailed dramatically from ground truth. We believe it's the reason that model's lacking ability of capturing frequency information which richly contains in real world datasets. At present, the mainstream frequency information extraction methods are Fourier transform(FT) based. However, use of FT is problematic due to Gibbs phenomenon. If the values on both sides of sequences differ significantly, oscillatory approximations are observed around both sides and high frequency noise will be introduced. Therefore We propose a novel frequency enhanced channel attention that adaptively modelling frequency interdependencies between channels based on Discrete Cosine Transform which would intrinsically avoid high frequency noise caused by problematic periodity during Fourier Transform, which is defined as Gibbs Phenomenon. We show that this network generalize extremely effectively across six real-world datasets and achieve state-of-the-art performance, we further demonstrate that frequency enhanced channel attention mechanism module can be flexibly applied to different networks. This module can improve the prediction ability of existing mainstream networks, which reduces 35.99% MSE on LSTM, 10.01% on Reformer, 8.71% on Informer, 8.29% on Autoformer, 8.06% on Transformer, etc., at a slight computational cost ,with just a few line of code. Our codes and data are available at https://github.com/Zero-coder/FECAM.
RGB-D-based Stair Detection using Deep Learning for Autonomous Stair Climbing
Dec 09, 2022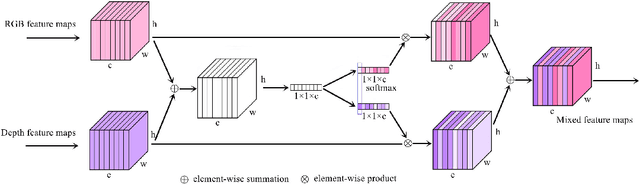
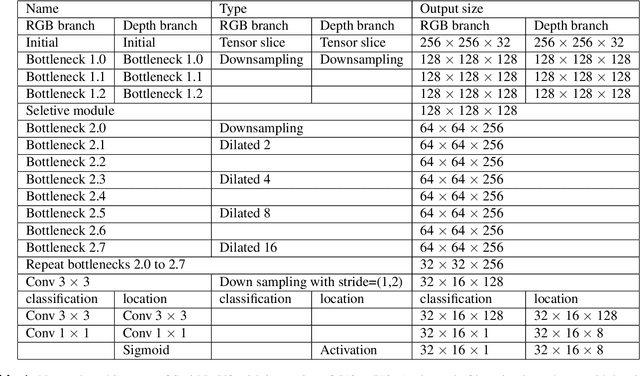
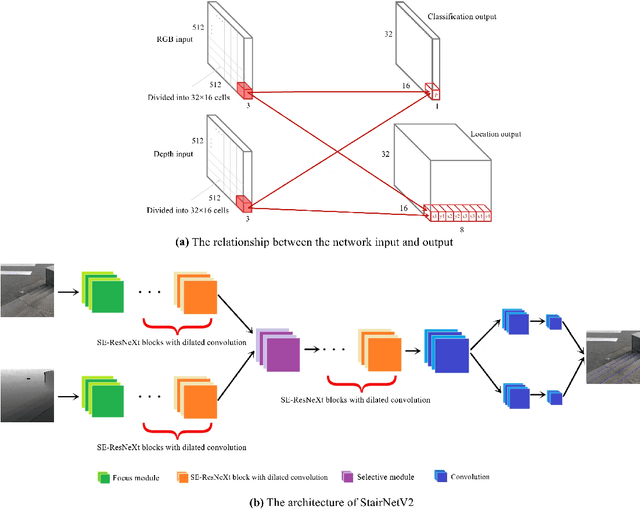
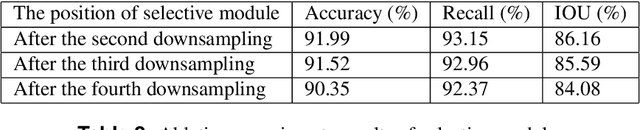
Stairs are common building structures in urban environments, and stair detection is an important part of environment perception for autonomous mobile robots. Most existing algorithms have difficulty combining the visual information from binocular sensors effectively and ensuring reliable detection at night and in the case of extremely fuzzy visual clues. To solve these problems, we propose a neural network architecture with RGB and depth map inputs. Specifically, we design a selective module, which can make the network learn the complementary relationship between the RGB map and the depth map and effectively combine the information from the RGB map and the depth map in different scenes. In addition, we design a line clustering algorithm for the postprocessing of detection results, which can make full use of the detection results to obtain the geometric stair parameters. Experiments on our dataset show that our method can achieve better accuracy and recall compared with existing state-of-the-art deep learning methods, which are 5.64% and 7.97%, respectively, and our method also has extremely fast detection speed. A lightweight version can achieve 300 + frames per second with the same resolution, which can meet the needs of most real-time detection scenes.
Moto: Enhancing Embedding with Multiple Joint Factors for Chinese Text Classification
Dec 09, 2022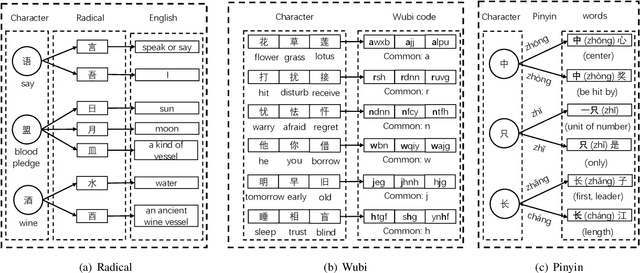
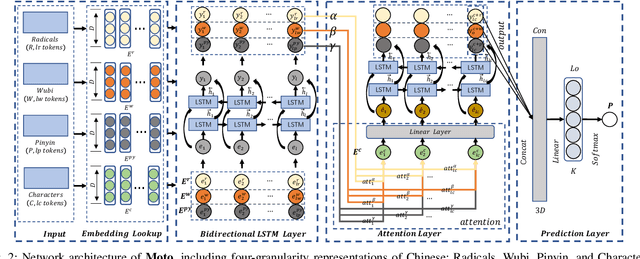
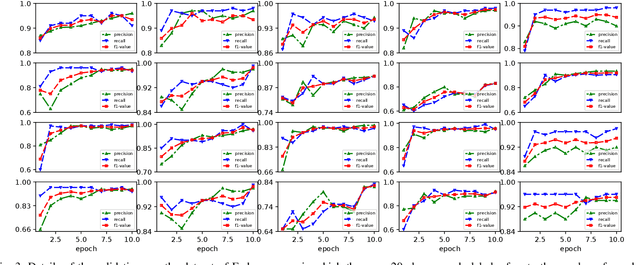
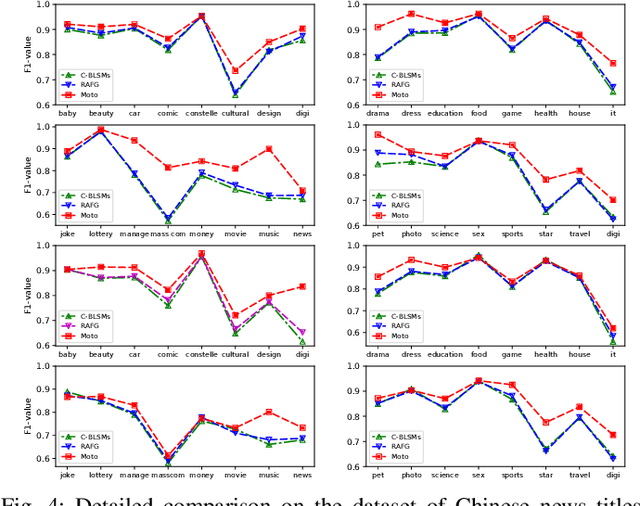
Recently, language representation techniques have achieved great performances in text classification. However, most existing representation models are specifically designed for English materials, which may fail in Chinese because of the huge difference between these two languages. Actually, few existing methods for Chinese text classification process texts at a single level. However, as a special kind of hieroglyphics, radicals of Chinese characters are good semantic carriers. In addition, Pinyin codes carry the semantic of tones, and Wubi reflects the stroke structure information, \textit{etc}. Unfortunately, previous researches neglected to find an effective way to distill the useful parts of these four factors and to fuse them. In our works, we propose a novel model called Moto: Enhancing Embedding with \textbf{M}ultiple J\textbf{o}int Fac\textbf{to}rs. Specifically, we design an attention mechanism to distill the useful parts by fusing the four-level information above more effectively. We conduct extensive experiments on four popular tasks. The empirical results show that our Moto achieves SOTA 0.8316 ($F_1$-score, 2.11\% improvement) on Chinese news titles, 96.38 (1.24\% improvement) on Fudan Corpus and 0.9633 (3.26\% improvement) on THUCNews.
DiffuPose: Monocular 3D Human Pose Estimation via Denoising Diffusion Probabilistic Model
Dec 09, 2022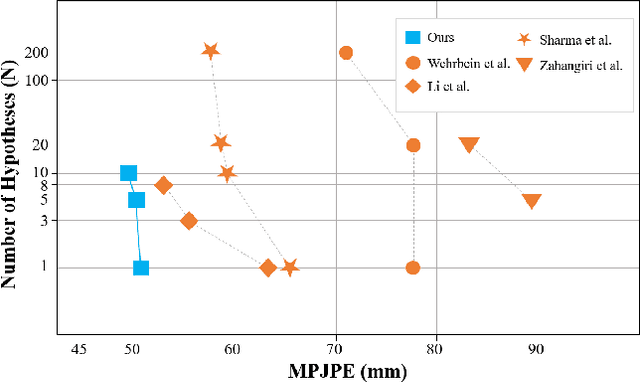
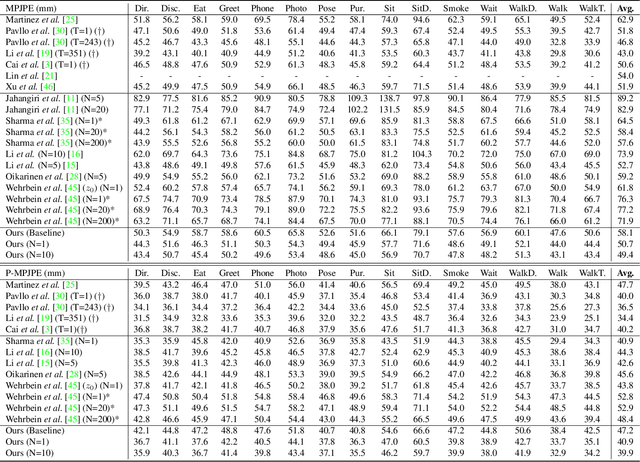
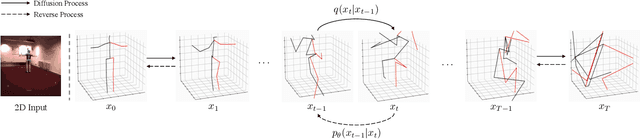
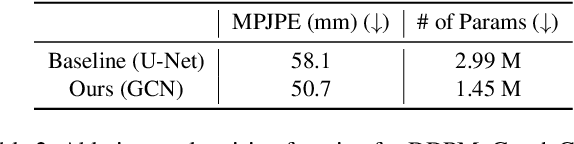
Thanks to the development of 2D keypoint detectors, monocular 3D human pose estimation (HPE) via 2D-to-3D uplifting approaches have achieved remarkable improvements. Still, monocular 3D HPE is a challenging problem due to the inherent depth ambiguities and occlusions. To handle this problem, many previous works exploit temporal information to mitigate such difficulties. However, there are many real-world applications where frame sequences are not accessible. This paper focuses on reconstructing a 3D pose from a single 2D keypoint detection. Rather than exploiting temporal information, we alleviate the depth ambiguity by generating multiple 3D pose candidates which can be mapped to an identical 2D keypoint. We build a novel diffusion-based framework to effectively sample diverse 3D poses from an off-the-shelf 2D detector. By considering the correlation between human joints by replacing the conventional denoising U-Net with graph convolutional network, our approach accomplishes further performance improvements. We evaluate our method on the widely adopted Human3.6M and HumanEva-I datasets. Comprehensive experiments are conducted to prove the efficacy of the proposed method, and they confirm that our model outperforms state-of-the-art multi-hypothesis 3D HPE methods.
Memories are One-to-Many Mapping Alleviators in Talking Face Generation
Dec 09, 2022
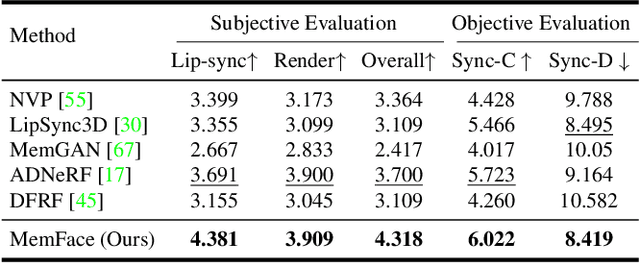
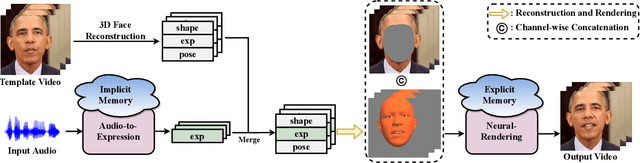
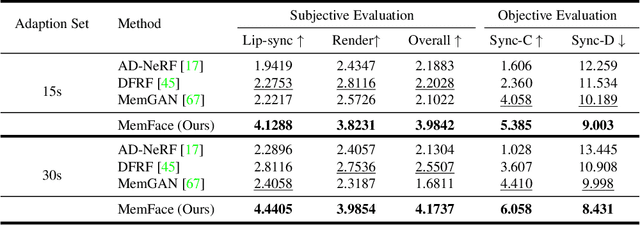
Talking face generation aims at generating photo-realistic video portraits of a target person driven by input audio. Due to its nature of one-to-many mapping from the input audio to the output video (e.g., one speech content may have multiple feasible visual appearances), learning a deterministic mapping like previous works brings ambiguity during training, and thus causes inferior visual results. Although this one-to-many mapping could be alleviated in part by a two-stage framework (i.e., an audio-to-expression model followed by a neural-rendering model), it is still insufficient since the prediction is produced without enough information (e.g., emotions, wrinkles, etc.). In this paper, we propose MemFace to complement the missing information with an implicit memory and an explicit memory that follow the sense of the two stages respectively. More specifically, the implicit memory is employed in the audio-to-expression model to capture high-level semantics in the audio-expression shared space, while the explicit memory is employed in the neural-rendering model to help synthesize pixel-level details. Our experimental results show that our proposed MemFace surpasses all the state-of-the-art results across multiple scenarios consistently and significantly.
Task-Oriented Communication for Edge Video Analytics
Nov 25, 2022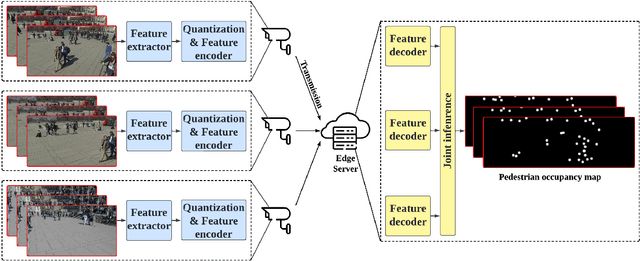
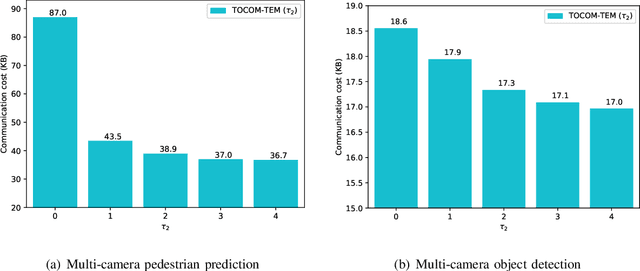
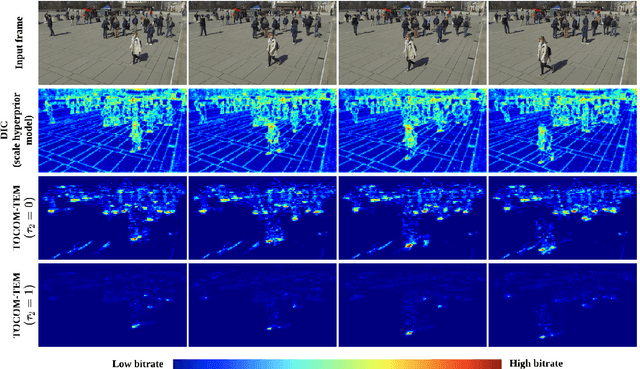
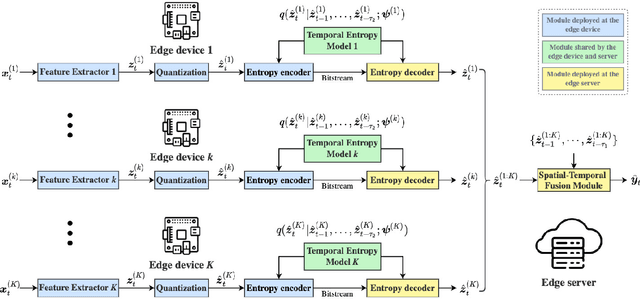
With the development of artificial intelligence (AI) techniques and the increasing popularity of camera-equipped devices, many edge video analytics applications are emerging, calling for the deployment of computation-intensive AI models at the network edge. Edge inference is a promising solution to move the computation-intensive workloads from low-end devices to a powerful edge server for video analytics, but the device-server communications will remain a bottleneck due to the limited bandwidth. This paper proposes a task-oriented communication framework for edge video analytics, where multiple devices collect the visual sensory data and transmit the informative features to an edge server for processing. To enable low-latency inference, this framework removes video redundancy in spatial and temporal domains and transmits minimal information that is essential for the downstream task, rather than reconstructing the videos at the edge server. Specifically, it extracts compact task-relevant features based on the deterministic information bottleneck (IB) principle, which characterizes a tradeoff between the informativeness of the features and the communication cost. As the features of consecutive frames are temporally correlated, we propose a temporal entropy model (TEM) to reduce the bitrate by taking the previous features as side information in feature encoding. To further improve the inference performance, we build a spatial-temporal fusion module at the server to integrate features of the current and previous frames for joint inference. Extensive experiments on video analytics tasks evidence that the proposed framework effectively encodes task-relevant information of video data and achieves a better rate-performance tradeoff than existing methods.
INO: Invariant Neural Operators for Learning Complex Physical Systems with Momentum Conservation
Dec 29, 2022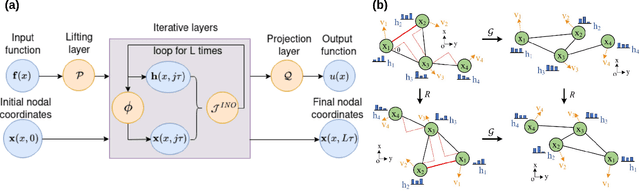
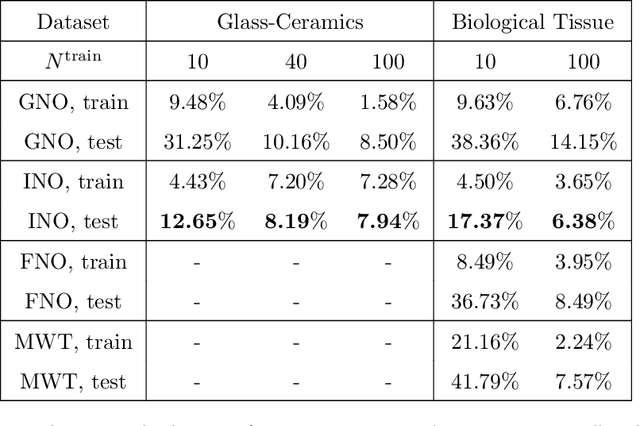
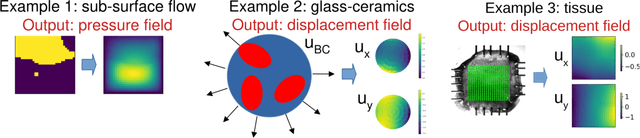
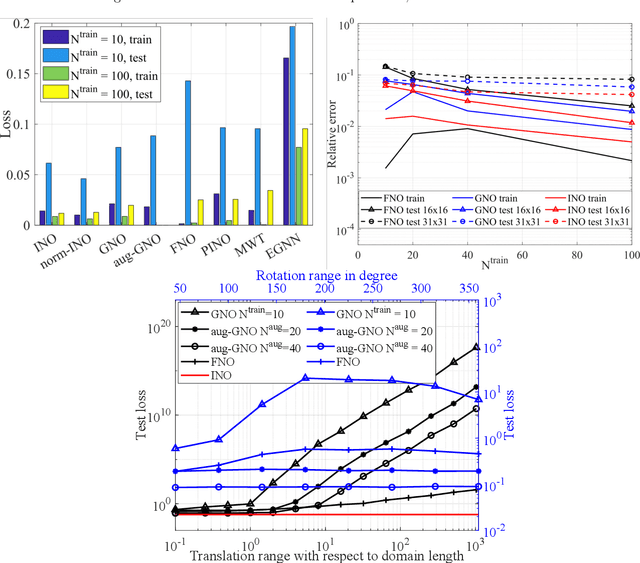
Neural operators, which emerge as implicit solution operators of hidden governing equations, have recently become popular tools for learning responses of complex real-world physical systems. Nevertheless, the majority of neural operator applications has thus far been data-driven, which neglects the intrinsic preservation of fundamental physical laws in data. In this paper, we introduce a novel integral neural operator architecture, to learn physical models with fundamental conservation laws automatically guaranteed. In particular, by replacing the frame-dependent position information with its invariant counterpart in the kernel space, the proposed neural operator is by design translation- and rotation-invariant, and consequently abides by the conservation laws of linear and angular momentums. As applications, we demonstrate the expressivity and efficacy of our model in learning complex material behaviors from both synthetic and experimental datasets, and show that, by automatically satisfying these essential physical laws, our learned neural operator is not only generalizable in handling translated and rotated datasets, but also achieves state-of-the-art accuracy and efficiency as compared to baseline neural operator models.
Multimodal Wildland Fire Smoke Detection
Dec 29, 2022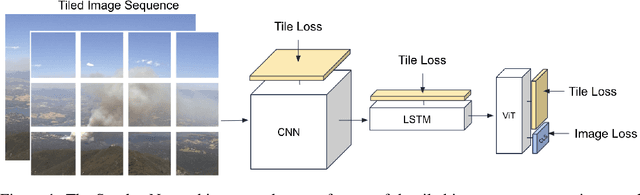
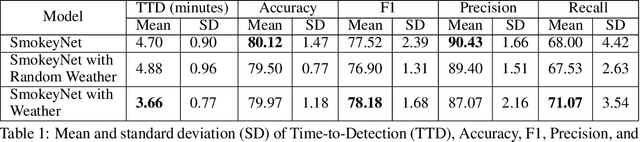
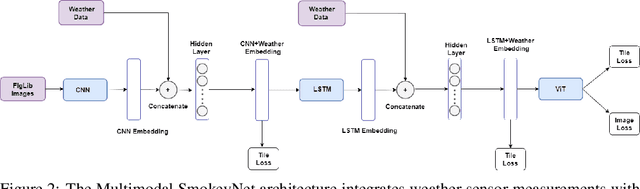
Research has shown that climate change creates warmer temperatures and drier conditions, leading to longer wildfire seasons and increased wildfire risks in the United States. These factors have in turn led to increases in the frequency, extent, and severity of wildfires in recent years. Given the danger posed by wildland fires to people, property, wildlife, and the environment, there is an urgency to provide tools for effective wildfire management. Early detection of wildfires is essential to minimizing potentially catastrophic destruction. In this paper, we present our work on integrating multiple data sources in SmokeyNet, a deep learning model using spatio-temporal information to detect smoke from wildland fires. Camera image data is integrated with weather sensor measurements and processed by SmokeyNet to create a multimodal wildland fire smoke detection system. We present our results comparing performance in terms of both accuracy and time-to-detection for multimodal data vs. a single data source. With a time-to-detection of only a few minutes, SmokeyNet can serve as an automated early notification system, providing a useful tool in the fight against destructive wildfires.
Do Bayesian Variational Autoencoders Know What They Don't Know?
Dec 29, 2022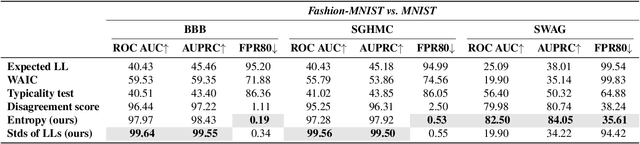
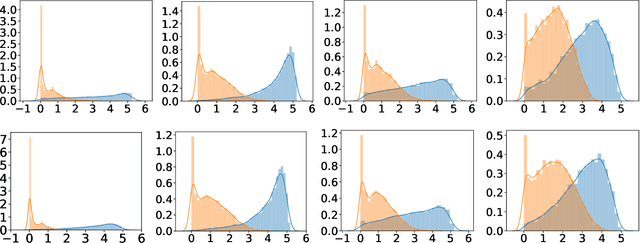
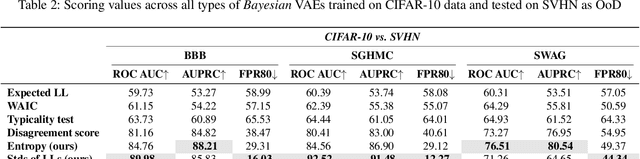
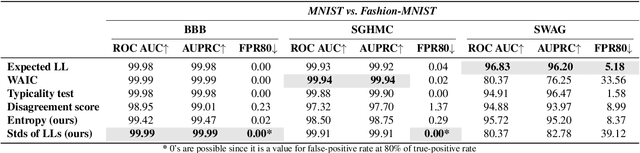
The problem of detecting the Out-of-Distribution (OoD) inputs is of paramount importance for Deep Neural Networks. It has been previously shown that even Deep Generative Models that allow estimating the density of the inputs may not be reliable and often tend to make over-confident predictions for OoDs, assigning to them a higher density than to the in-distribution data. This over-confidence in a single model can be potentially mitigated with Bayesian inference over the model parameters that take into account epistemic uncertainty. This paper investigates three approaches to Bayesian inference: stochastic gradient Markov chain Monte Carlo, Bayes by Backpropagation, and Stochastic Weight Averaging-Gaussian. The inference is implemented over the weights of the deep neural networks that parameterize the likelihood of the Variational Autoencoder. We empirically evaluate the approaches against several benchmarks that are often used for OoD detection: estimation of the marginal likelihood utilizing sampled model ensemble, typicality test, disagreement score, and Watanabe-Akaike Information Criterion. Finally, we introduce two simple scores that demonstrate the state-of-the-art performance.
DSI2I: Dense Style for Unpaired Image-to-Image Translation
Dec 29, 2022

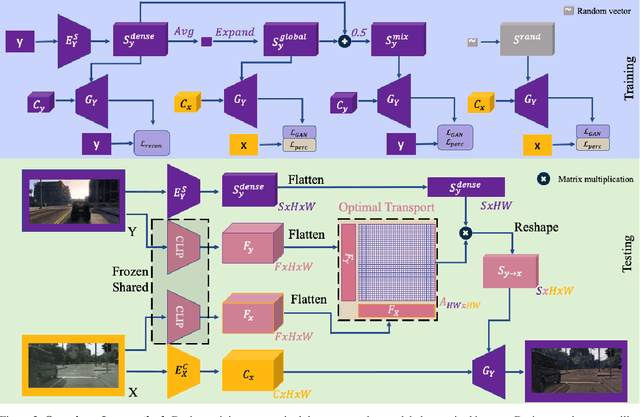

Unpaired exemplar-based image-to-image (UEI2I) translation aims to translate a source image to a target image domain with the style of a target image exemplar, without ground-truth input-translation pairs. Existing UEI2I methods represent style using either a global, image-level feature vector, or one vector per object instance/class but requiring knowledge of the scene semantics. Here, by contrast, we propose to represent style as a dense feature map, allowing for a finer-grained transfer to the source image without requiring any external semantic information. We then rely on perceptual and adversarial losses to disentangle our dense style and content representations, and exploit unsupervised cross-domain semantic correspondences to warp the exemplar style to the source content. We demonstrate the effectiveness of our method on two datasets using standard metrics together with a new localized style metric measuring style similarity in a class-wise manner. Our results evidence that the translations produced by our approach are more diverse and closer to the exemplars than those of the state-of-the-art methods while nonetheless preserving the source content.