 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Effectiveness of Delivered Information Trade Study
Mar 14, 2022

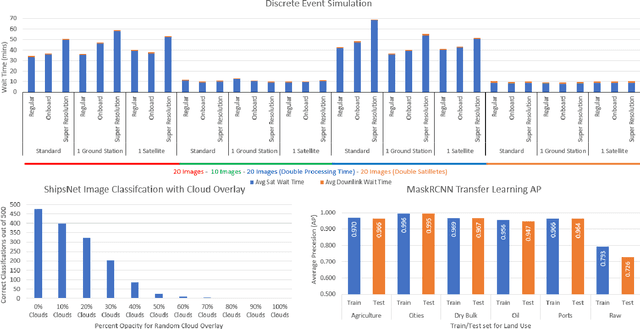

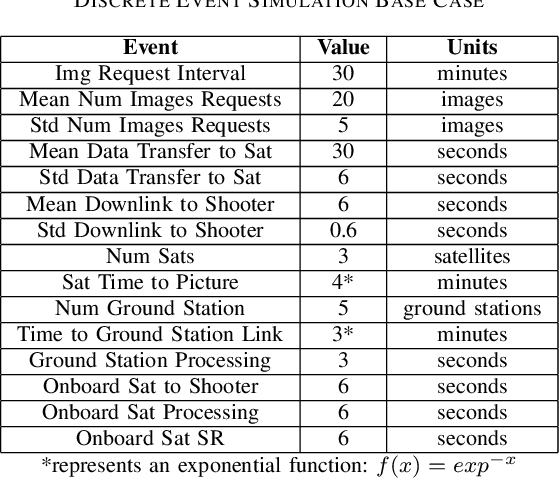
The sensor to shooter timeline is affected by two main variables: satellite positioning and asset positioning. Speeding up satellite positioning by adding more sensors or by decreasing processing time is important only if there is a prepared shooter, otherwise the main source of time is getting the shooter into position. However, the intelligence community should work towards the exploitation of sensors to the highest speed and effectiveness possible. Achieving a high effectiveness while keeping speed high is a tradeoff that must be considered in the sensor to shooter timeline. In this paper we investigate two main ideas, increasing the effectiveness of satellite imagery through image manipulation and how on-board image manipulation would affect the sensor to shooter timeline. We cover these ideas in four scenarios: Discrete Event Simulation of onboard processing versus ground station processing, quality of information with cloud cover removal, information improvement with super resolution, and data reduction with image to caption. This paper will show how image manipulation techniques such as Super Resolution, Cloud Removal, and Image to Caption will improve the quality of delivered information in addition to showing how those processes effect the sensor to shooter timeline.
Multi-Sem Fusion: Multimodal Semantic Fusion for 3D Object Detection
Dec 10, 2022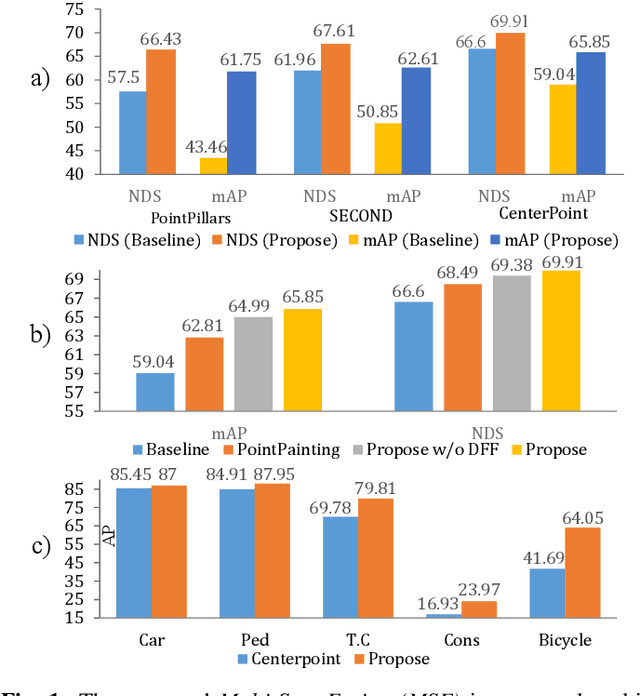
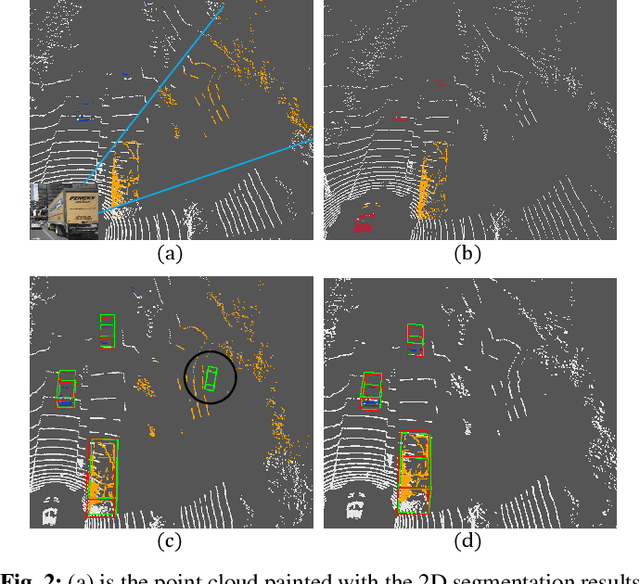
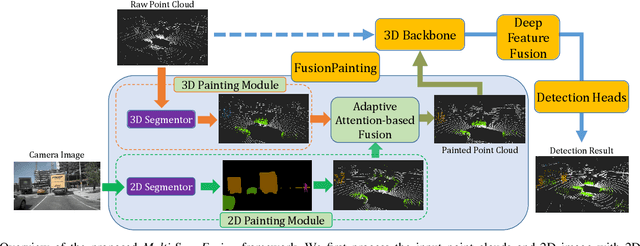
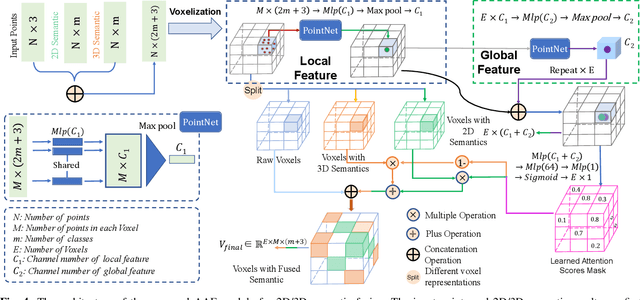
LiDAR-based 3D Object detectors have achieved impressive performances in many benchmarks, however, multisensors fusion-based techniques are promising to further improve the results. PointPainting, as a recently proposed framework, can add the semantic information from the 2D image into the 3D LiDAR point by the painting operation to boost the detection performance. However, due to the limited resolution of 2D feature maps, severe boundary-blurring effect happens during re-projection of 2D semantic segmentation into the 3D point clouds. To well handle this limitation, a general multimodal fusion framework MSF has been proposed to fuse the semantic information from both the 2D image and 3D points scene parsing results. Specifically, MSF includes three main modules. First, SOTA off-the-shelf 2D/3D semantic segmentation approaches are employed to generate the parsing results for 2D images and 3D point clouds. The 2D semantic information is further re-projected into the 3D point clouds with calibrated parameters. To handle the misalignment between the 2D and 3D parsing results, an AAF module is proposed to fuse them by learning an adaptive fusion score. Then the point cloud with the fused semantic label is sent to the following 3D object detectors. Furthermore, we propose a DFF module to aggregate deep features in different levels to boost the final detection performance. The effectiveness of the framework has been verified on two public large-scale 3D object detection benchmarks by comparing with different baselines. The experimental results show that the proposed fusion strategies can significantly improve the detection performance compared to the methods using only point clouds and the methods using only 2D semantic information. Most importantly, the proposed approach significantly outperforms other approaches and sets new SOTA results on the nuScenes testing benchmark.
Logical Message Passing Networks with One-hop Inference on Atomic Formulas
Jan 21, 2023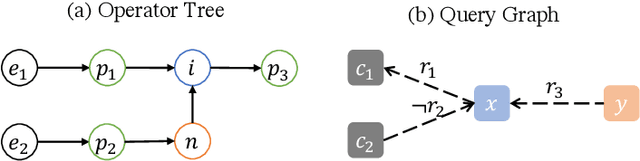
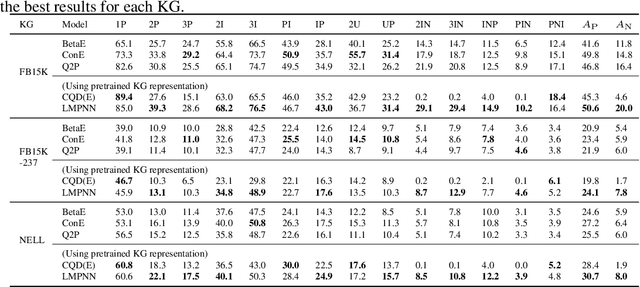
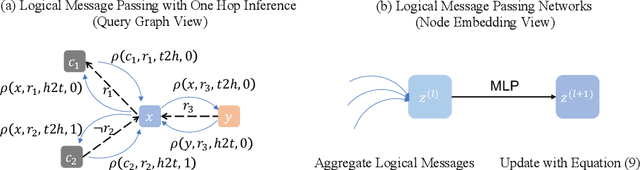
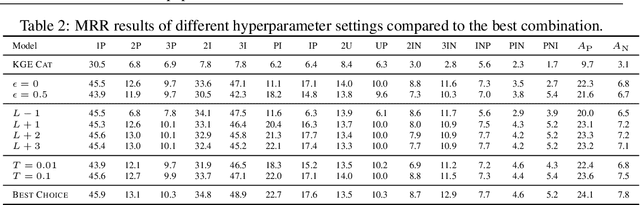
Complex Query Answering (CQA) over Knowledge Graphs (KGs) has attracted a lot of attention to potentially support many applications. Given that KGs are usually incomplete, neural models are proposed to answer logical queries by parameterizing set operators with complex neural networks. However, such methods usually train neural set operators with a large number of entity and relation embeddings from zero, where whether and how the embeddings or the neural set operators contribute to the performance remains not clear. In this paper, we propose a simple framework for complex query answering that decomposes the KG embeddings from neural set operators. We propose to represent the complex queries in the query graph. On top of the query graph, we propose the Logical Message Passing Neural Network (LMPNN) that connects the \textit{local} one-hop inferences on atomic formulas to the \textit{global} logical reasoning for complex query answering. We leverage existing effective KG embeddings to conduct one-hop inferences on atomic formulas, the results of which are regarded as the messages passed in LMPNN. The reasoning process over the overall logical formulas is turned into the forward pass of LMPNN that incrementally aggregates local information to predict the answers' embeddings finally. The complex logical inference across different types of queries will then be learned from training examples based on the LMPNN architecture. Theoretically, our query-graph representation is more general than the prevailing operator-tree formulation, so our approach applies to a broader range of complex KG queries. Empirically, our approach yields a new state-of-the-art neural CQA model. Our research bridges the gap between complex KG query answering tasks and the long-standing achievements of knowledge graph representation learning.
E$^3$Pose: Energy-Efficient Edge-assisted Multi-camera System for Multi-human 3D Pose Estimation
Jan 21, 2023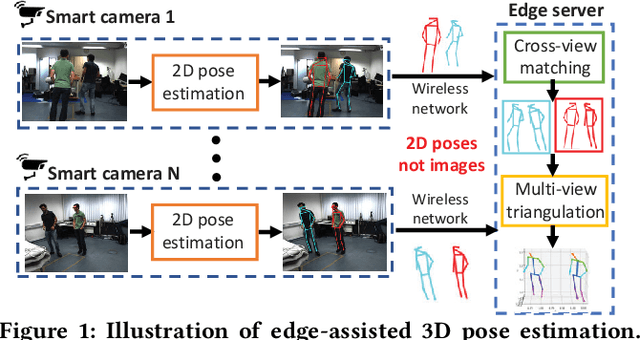
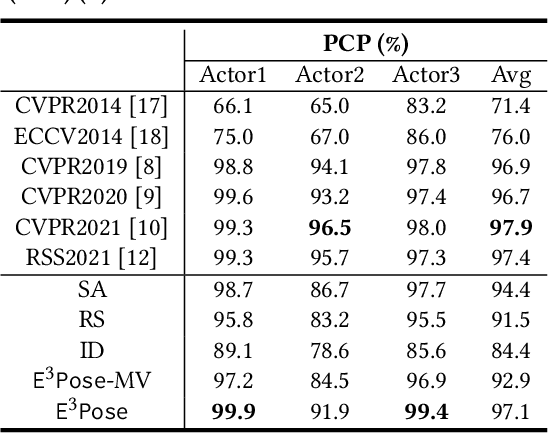
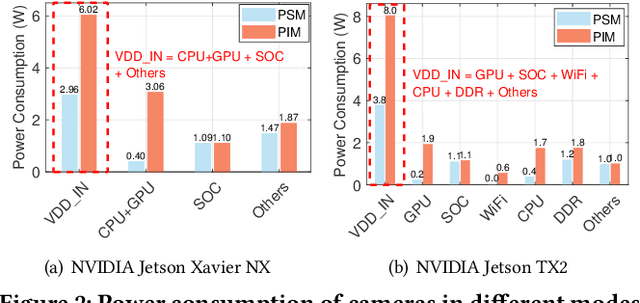
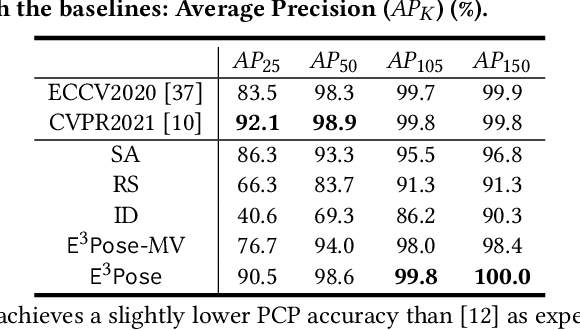
Multi-human 3D pose estimation plays a key role in establishing a seamless connection between the real world and the virtual world. Recent efforts adopted a two-stage framework that first builds 2D pose estimations in multiple camera views from different perspectives and then synthesizes them into 3D poses. However, the focus has largely been on developing new computer vision algorithms on the offline video datasets without much consideration on the energy constraints in real-world systems with flexibly-deployed and battery-powered cameras. In this paper, we propose an energy-efficient edge-assisted multiple-camera system, dubbed E$^3$Pose, for real-time multi-human 3D pose estimation, based on the key idea of adaptive camera selection. Instead of always employing all available cameras to perform 2D pose estimations as in the existing works, E$^3$Pose selects only a subset of cameras depending on their camera view qualities in terms of occlusion and energy states in an adaptive manner, thereby reducing the energy consumption (which translates to extended battery lifetime) and improving the estimation accuracy. To achieve this goal, E$^3$Pose incorporates an attention-based LSTM to predict the occlusion information of each camera view and guide camera selection before cameras are selected to process the images of a scene, and runs a camera selection algorithm based on the Lyapunov optimization framework to make long-term adaptive selection decisions. We build a prototype of E$^3$Pose on a 5-camera testbed, demonstrate its feasibility and evaluate its performance. Our results show that a significant energy saving (up to 31.21%) can be achieved while maintaining a high 3D pose estimation accuracy comparable to state-of-the-art methods.
DETR4D: Direct Multi-View 3D Object Detection with Sparse Attention
Dec 15, 2022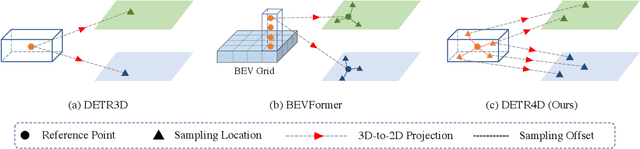
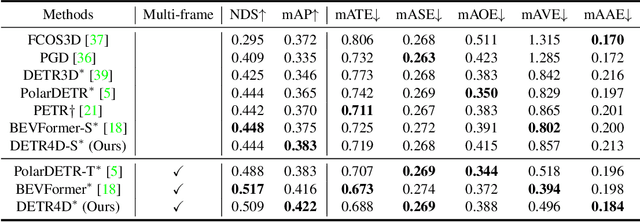
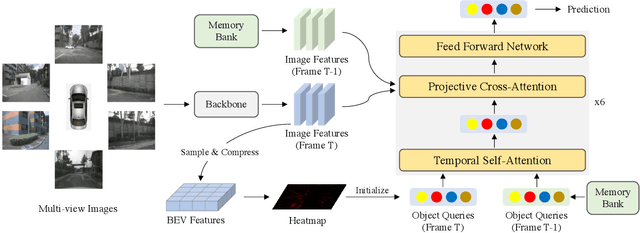
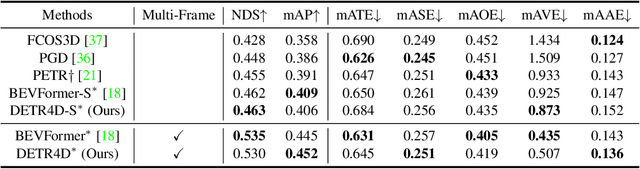
3D object detection with surround-view images is an essential task for autonomous driving. In this work, we propose DETR4D, a Transformer-based framework that explores sparse attention and direct feature query for 3D object detection in multi-view images. We design a novel projective cross-attention mechanism for query-image interaction to address the limitations of existing methods in terms of geometric cue exploitation and information loss for cross-view objects. In addition, we introduce a heatmap generation technique that bridges 3D and 2D spaces efficiently via query initialization. Furthermore, unlike the common practice of fusing intermediate spatial features for temporal aggregation, we provide a new perspective by introducing a novel hybrid approach that performs cross-frame fusion over past object queries and image features, enabling efficient and robust modeling of temporal information. Extensive experiments on the nuScenes dataset demonstrate the effectiveness and efficiency of the proposed DETR4D.
Digital Twin Based Beam Prediction: Can we Train in the Digital World and Deploy in Reality?
Jan 18, 2023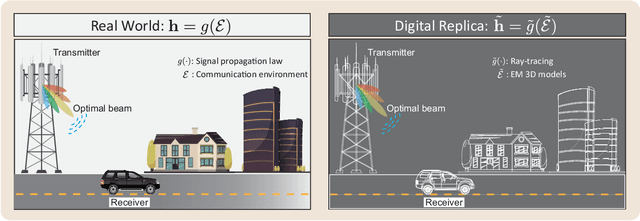
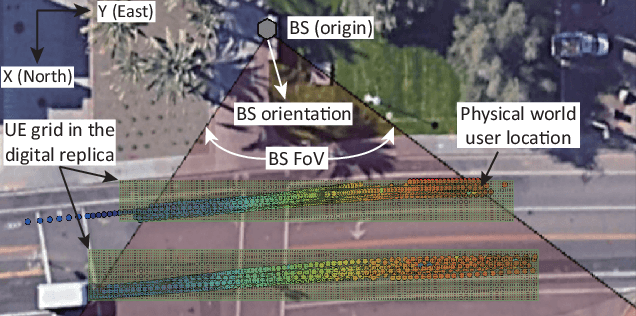
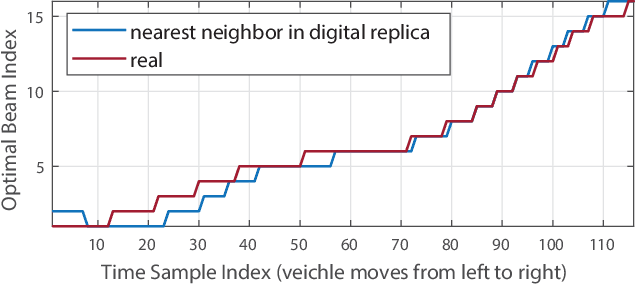
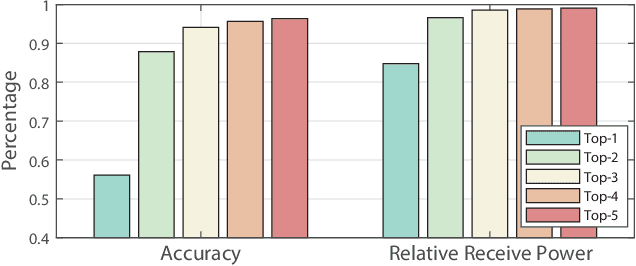
Realizing the potential gains of large-scale MIMO systems requires the accurate estimation of their channels or the fine adjustment of their narrow beams. This, however, is typically associated with high channel acquisition/beam sweeping overhead that scales with the number of antennas. Machine and deep learning represent promising approaches to overcome these challenges thanks to their powerful ability to learn from prior observations and side information. Training machine and deep learning models, however, requires large-scale datasets that are expensive to collect in deployed systems. To address this challenge, we propose a novel direction that utilizes digital replicas of the physical world to reduce or even eliminate the MIMO channel acquisition overhead. In the proposed digital twin aided communication, 3D models that approximate the real-world communication environment are constructed and accurate ray-tracing is utilized to simulate the site-specific channels. These channels can then be used to aid various communication tasks. Further, we propose to use machine learning to approximate the digital replicas and reduce the ray tracing computational cost. To evaluate the proposed digital twin based approach, we conduct a case study focusing on the position-aided beam prediction task. The results show that a learning model trained solely with the data generated by the digital replica can achieve relatively good performance on the real-world data. Moreover, a small number of real-world data points can quickly achieve near-optimal performance, overcoming the modeling mismatches between the physical and digital worlds and significantly reducing the data acquisition overhead.
Graphix-T5: Mixing Pre-Trained Transformers with Graph-Aware Layers for Text-to-SQL Parsing
Jan 18, 2023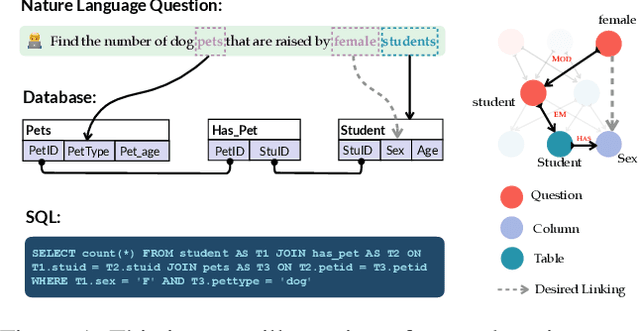
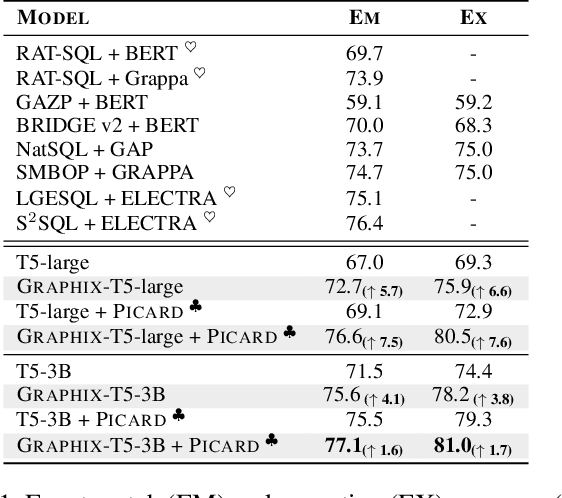
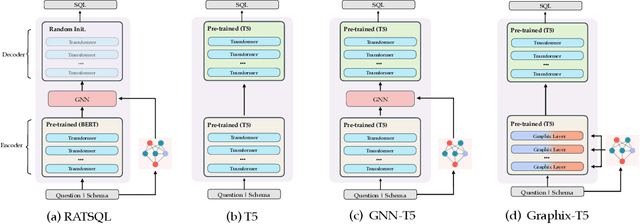
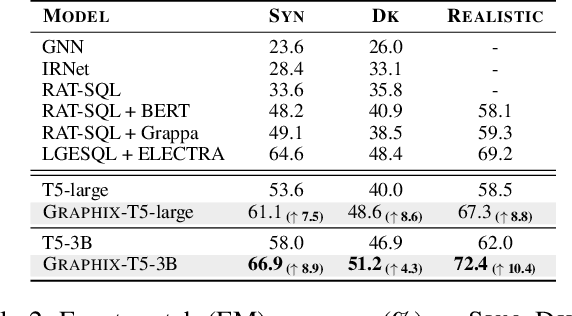
The task of text-to-SQL parsing, which aims at converting natural language questions into executable SQL queries, has garnered increasing attention in recent years, as it can assist end users in efficiently extracting vital information from databases without the need for technical background. One of the major challenges in text-to-SQL parsing is domain generalization, i.e., how to generalize well to unseen databases. Recently, the pre-trained text-to-text transformer model, namely T5, though not specialized for text-to-SQL parsing, has achieved state-of-the-art performance on standard benchmarks targeting domain generalization. In this work, we explore ways to further augment the pre-trained T5 model with specialized components for text-to-SQL parsing. Such components are expected to introduce structural inductive bias into text-to-SQL parsers thus improving model's capacity on (potentially multi-hop) reasoning, which is critical for generating structure-rich SQLs. To this end, we propose a new architecture GRAPHIX-T5, a mixed model with the standard pre-trained transformer model augmented by some specially-designed graph-aware layers. Extensive experiments and analysis demonstrate the effectiveness of GRAPHIX-T5 across four text-to-SQL benchmarks: SPIDER, SYN, REALISTIC and DK. GRAPHIX-T5 surpass all other T5-based parsers with a significant margin, achieving new state-of-the-art performance. Notably, GRAPHIX-T5-large reach performance superior to the original T5-large by 5.7% on exact match (EM) accuracy and 6.6% on execution accuracy (EX). This even outperforms the T5-3B by 1.2% on EM and 1.5% on EX.
Understanding the Role of Human Intuition on Reliance in Human-AI Decision-Making with Explanations
Jan 18, 2023
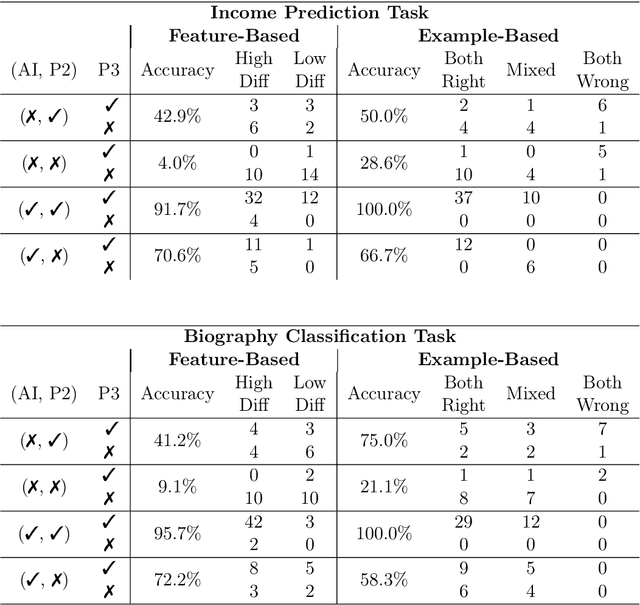
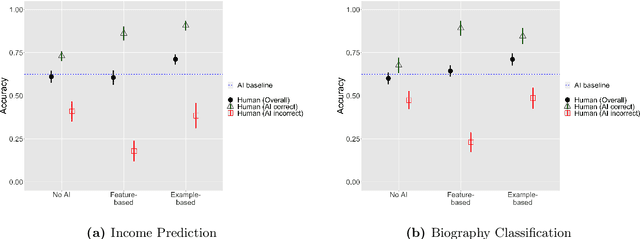
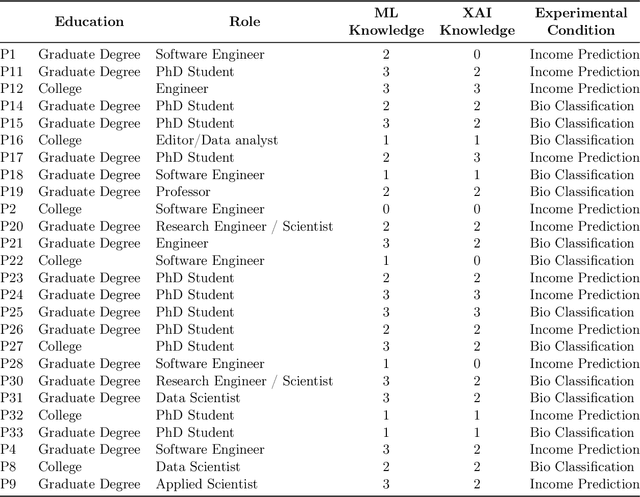
AI explanations are often mentioned as a way to improve human-AI decision-making. Yet, empirical studies have not found consistent evidence of explanations' effectiveness and, on the contrary, suggest that they can increase overreliance when the AI system is wrong. While many factors may affect reliance on AI support, one important factor is how decision-makers reconcile their own intuition -- which may be based on domain knowledge, prior task experience, or pattern recognition -- with the information provided by the AI system to determine when to override AI predictions. We conduct a think-aloud, mixed-methods study with two explanation types (feature- and example-based) for two prediction tasks to explore how decision-makers' intuition affects their use of AI predictions and explanations, and ultimately their choice of when to rely on AI. Our results identify three types of intuition involved in reasoning about AI predictions and explanations: intuition about the task outcome, features, and AI limitations. Building on these, we summarize three observed pathways for decision-makers to apply their own intuition and override AI predictions. We use these pathways to explain why (1) the feature-based explanations we used did not improve participants' decision outcomes and increased their overreliance on AI, and (2) the example-based explanations we used improved decision-makers' performance over feature-based explanations and helped achieve complementary human-AI performance. Overall, our work identifies directions for further development of AI decision-support systems and explanation methods that help decision-makers effectively apply their intuition to achieve appropriate reliance on AI.
SantaCoder: don't reach for the stars!
Jan 09, 2023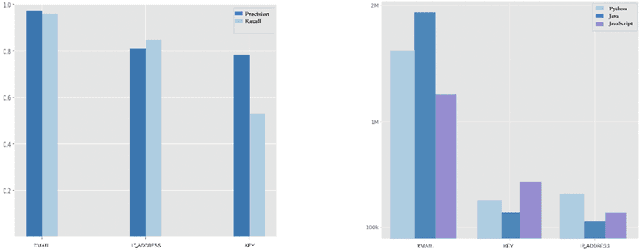



The BigCode project is an open-scientific collaboration working on the responsible development of large language models for code. This tech report describes the progress of the collaboration until December 2022, outlining the current state of the Personally Identifiable Information (PII) redaction pipeline, the experiments conducted to de-risk the model architecture, and the experiments investigating better preprocessing methods for the training data. We train 1.1B parameter models on the Java, JavaScript, and Python subsets of The Stack and evaluate them on the MultiPL-E text-to-code benchmark. We find that more aggressive filtering of near-duplicates can further boost performance and, surprisingly, that selecting files from repositories with 5+ GitHub stars deteriorates performance significantly. Our best model outperforms previous open-source multilingual code generation models (InCoder-6.7B and CodeGen-Multi-2.7B) in both left-to-right generation and infilling on the Java, JavaScript, and Python portions of MultiPL-E, despite being a substantially smaller model. All models are released under an OpenRAIL license at https://hf.co/bigcode.
OA-BEV: Bringing Object Awareness to Bird's-Eye-View Representation for Multi-Camera 3D Object Detection
Jan 13, 2023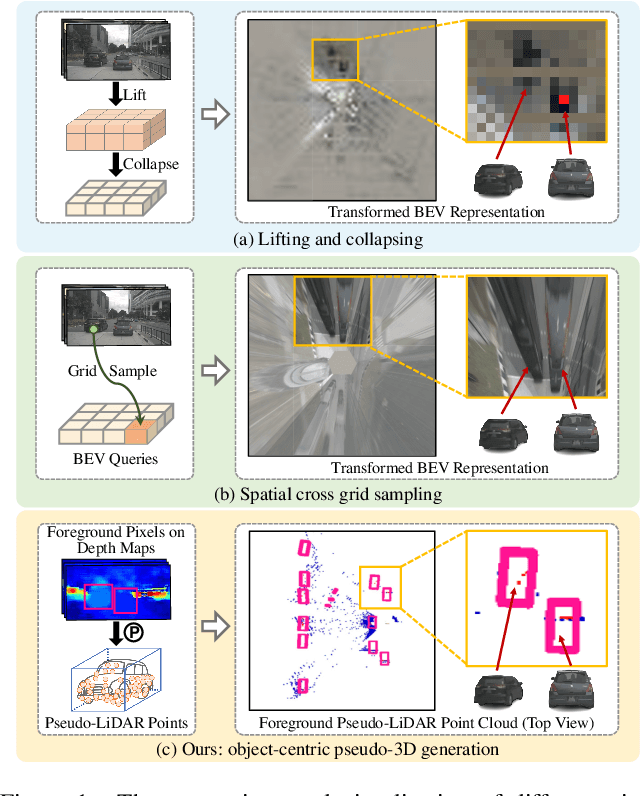
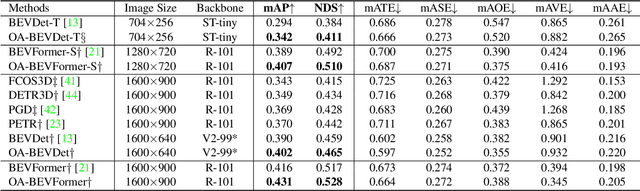
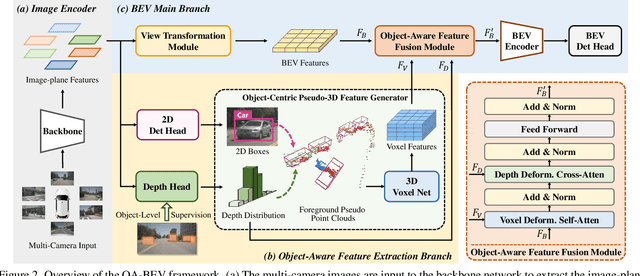
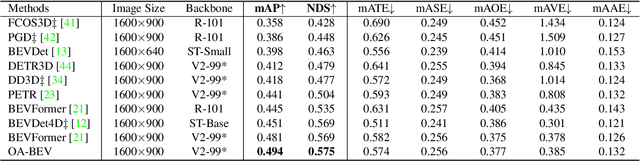
The recent trend for multi-camera 3D object detection is through the unified bird's-eye view (BEV) representation. However, directly transforming features extracted from the image-plane view to BEV inevitably results in feature distortion, especially around the objects of interest, making the objects blur into the background. To this end, we propose OA-BEV, a network that can be plugged into the BEV-based 3D object detection framework to bring out the objects by incorporating object-aware pseudo-3D features and depth features. Such features contain information about the object's position and 3D structures. First, we explicitly guide the network to learn the depth distribution by object-level supervision from each 3D object's center. Then, we select the foreground pixels by a 2D object detector and project them into 3D space for pseudo-voxel feature encoding. Finally, the object-aware depth features and pseudo-voxel features are incorporated into the BEV representation with a deformable attention mechanism. We conduct extensive experiments on the nuScenes dataset to validate the merits of our proposed OA-BEV. Our method achieves consistent improvements over the BEV-based baselines in terms of both average precision and nuScenes detection score. Our codes will be published.