 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
An end-to-end multi-scale network for action prediction in videos
Dec 31, 2022
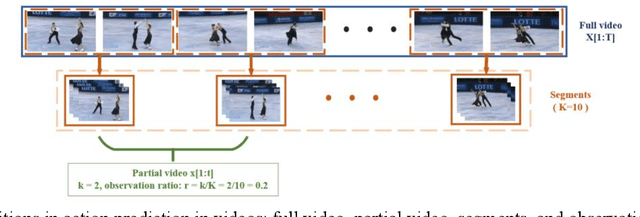
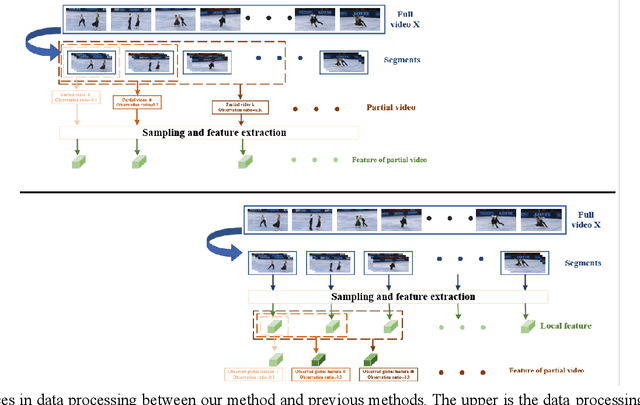
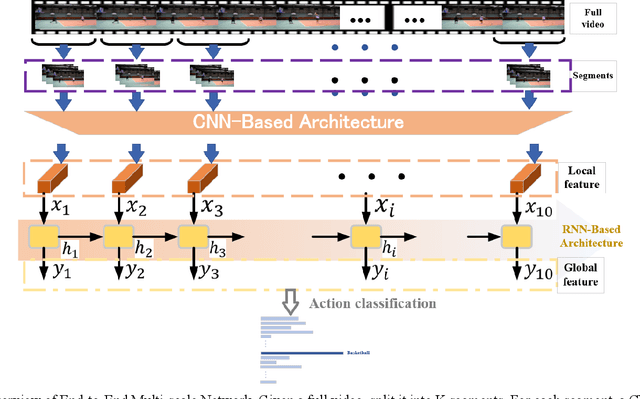
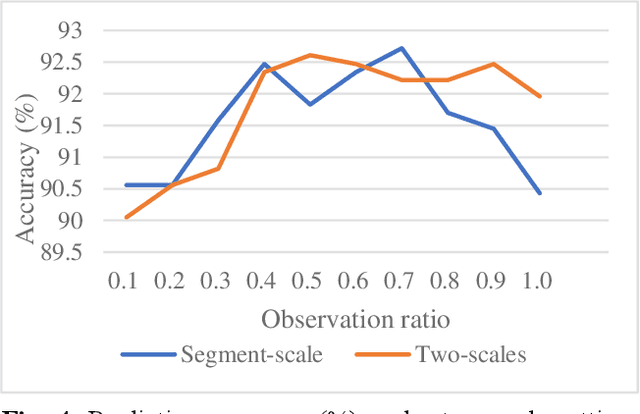
In this paper, we develop an efficient multi-scale network to predict action classes in partial videos in an end-to-end manner. Unlike most existing methods with offline feature generation, our method directly takes frames as input and further models motion evolution on two different temporal scales.Therefore, we solve the complexity problems of the two stages of modeling and the problem of insufficient temporal and spatial information of a single scale. Our proposed End-to-End MultiScale Network (E2EMSNet) is composed of two scales which are named segment scale and observed global scale. The segment scale leverages temporal difference over consecutive frames for finer motion patterns by supplying 2D convolutions. For observed global scale, a Long Short-Term Memory (LSTM) is incorporated to capture motion features of observed frames. Our model provides a simple and efficient modeling framework with a small computational cost. Our E2EMSNet is evaluated on three challenging datasets: BIT, HMDB51, and UCF101. The extensive experiments demonstrate the effectiveness of our method for action prediction in videos.
Distributed Filtering with Value of Information Censoring
Apr 01, 2022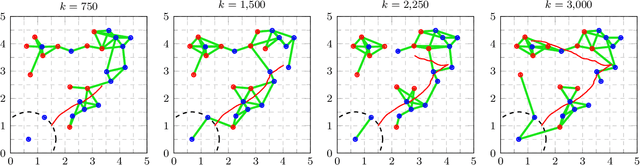
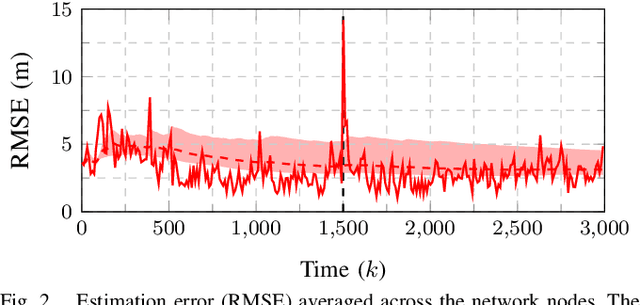
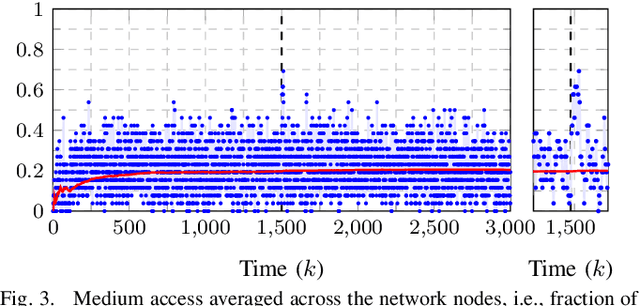
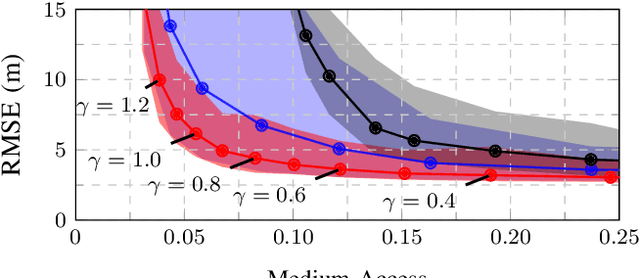
This work presents a distributed estimation algorithm that efficiently uses the available communication resources. The approach is based on Bayesian filtering that is distributed across a network by using the logarithmic opinion pool operator. Communication efficiency is achieved by having only agents with high Value of Information (VoI) share their estimates, and the algorithm provides a tunable trade-off between communication resources and estimation error. Under linear-Gaussian models the algorithm takes the form of a censored distributed Information filter, which guarantees the consistency of agent estimates. Importantly, consistent estimates are shown to play a crucial role in enabling the large reductions in communication usage provided by the VoI censoring approach. We verify the performance of the proposed method via complex simulations in a dynamic network topology and by experimental validation over a real ad-hoc wireless communication network. The results show the validity of using the proposed method to drastically reduce the communication costs of distributed estimation tasks.
Comparing Ordering Strategies For Process Discovery Using Synthesis Rules
Jan 04, 2023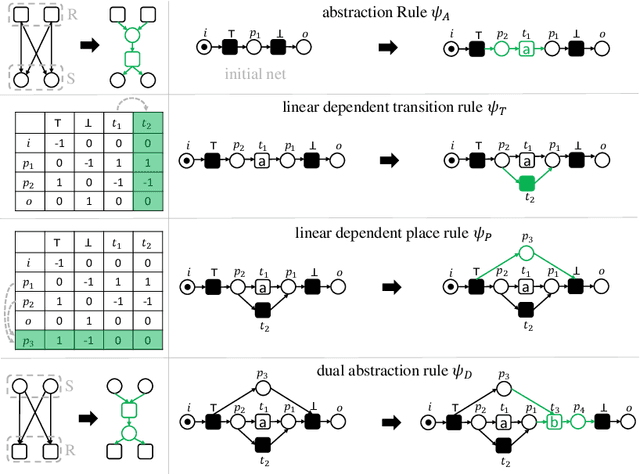
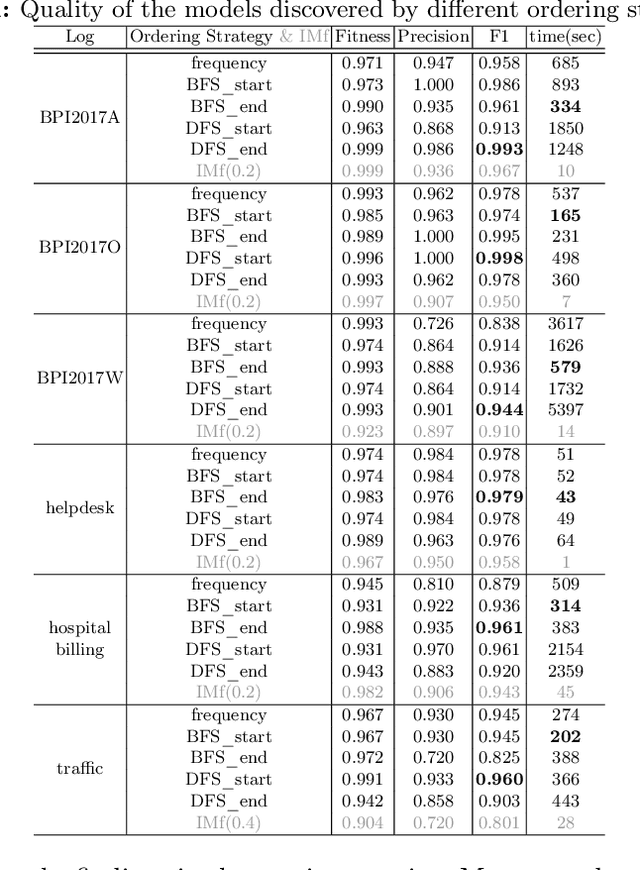

Process discovery aims to learn process models from observed behaviors, i.e., event logs, in the information systems.The discovered models serve as the starting point for process mining techniques that are used to address performance and compliance problems. Compared to the state-of-the-art Inductive Miner, the algorithm applying synthesis rules from the free-choice net theory discovers process models with more flexible (non-block) structures while ensuring the same desirable soundness and free-choiceness properties. Moreover, recent development in this line of work shows that the discovered models have compatible quality. Following the synthesis rules, the algorithm incrementally modifies an existing process model by adding the activities in the event log one at a time. As the applications of rules are highly dependent on the existing model structure, the model quality and computation time are significantly influenced by the order of adding activities. In this paper, we investigate the effect of different ordering strategies on the discovered models (w.r.t. fitness and precision) and the computation time using real-life event data. The results show that the proposed ordering strategy can improve the quality of the resulting process models while requiring less time compared to the ordering strategy solely based on the frequency of activities.
KIDS: kinematics-based (in)activity detection and segmentation in a sleep case study
Jan 04, 2023
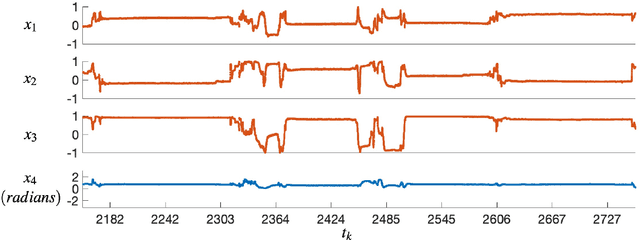
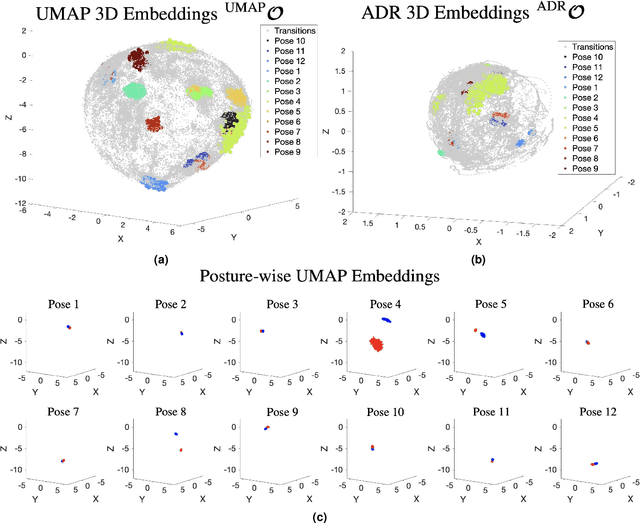
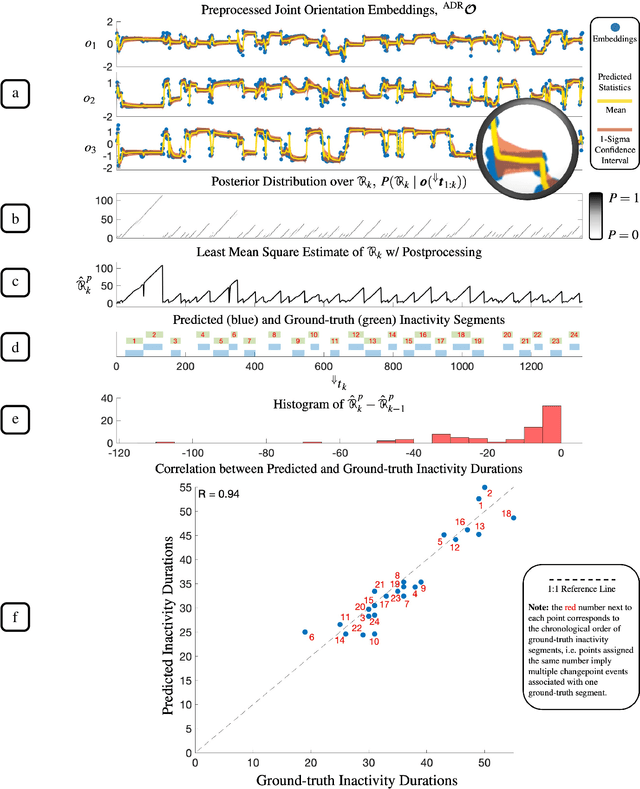
Sleep behaviour and in-bed movements contain rich information on the neurophysiological health of people, and have a direct link to the general well-being and quality of life. Standard clinical practices rely on polysomnography for sleep assessment; however, it is intrusive, performed in unfamiliar environments and requires trained personnel. Progress has been made on less invasive sensor technologies, such as actigraphy, but clinical validation raises concerns over their reliability and precision. Additionally, the field lacks a widely acceptable algorithm, with proposed approaches ranging from raw signal or feature thresholding to data-hungry classification models, many of which are unfamiliar to medical staff. This paper proposes an online Bayesian probabilistic framework for objective (in)activity detection and segmentation based on clinically meaningful joint kinematics, measured by a custom-made wearable sensor. Intuitive three-dimensional visualisations of kinematic timeseries were accomplished through dimension reduction based preprocessing, offering out-of-the-box framework explainability potentially useful for clinical monitoring and diagnosis. The proposed framework attained up to 99.2\% $F_1$-score and 0.96 Pearson's correlation coefficient in, respectively, the posture change detection and inactivity segmentation tasks. The work paves the way for a reliable home-based analysis of movements during sleep which would serve patient-centred longitudinal care plans.
UNAEN: Unsupervised Abnomality Extraction Network for MRI Motion Artifact Reduction
Jan 04, 2023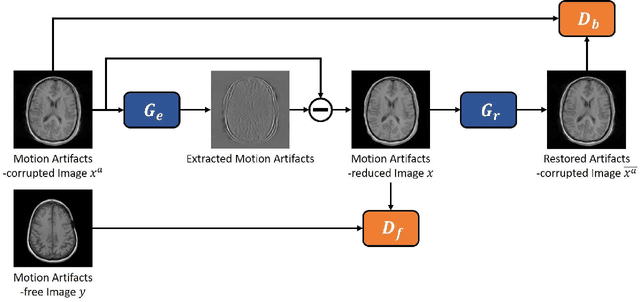
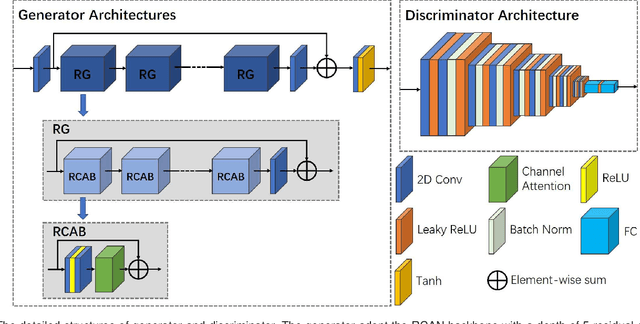
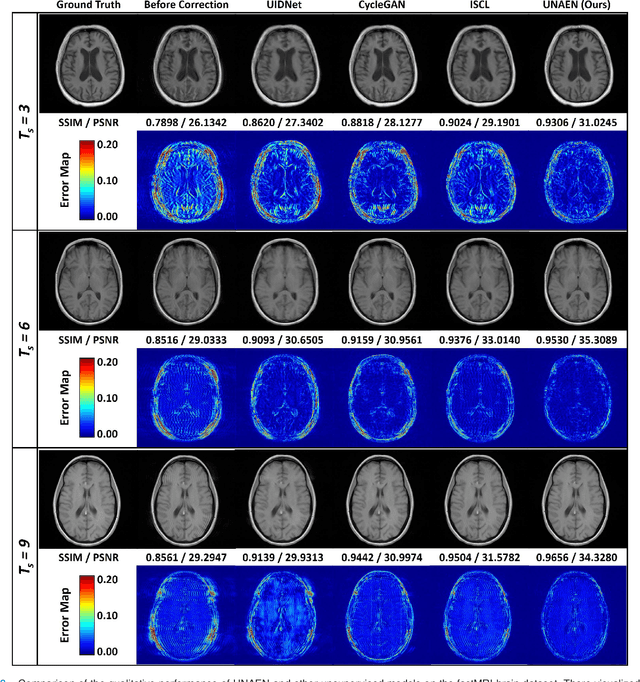
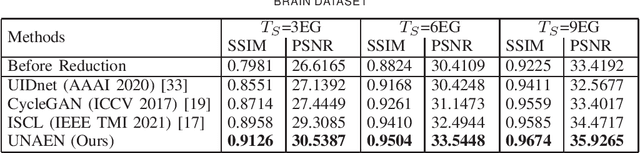
Motion artifact reduction is one of the most concerned problems in magnetic resonance imaging. As a promising solution, deep learning-based methods have been widely investigated for artifact reduction tasks in MRI. As a retrospective processing method, neural network does not cost additional acquisition time or require new acquisition equipment, and seems to work better than traditional artifact reduction methods. In the previous study, training such models require the paired motion-corrupted and motion-free MR images. However, it is extremely tough or even impossible to obtain these images in reality because patients have difficulty in maintaining the same state during two image acquisition, which makes the training in a supervised manner impractical. In this work, we proposed a new unsupervised abnomality extraction network (UNAEN) to alleviate this problem. Our network realizes the transition from artifact domain to motion-free domain by processing the abnormal information introduced by artifact in unpaired MR images. Different from directly generating artifact reduction results from motion-corrupted MR images, we adopted the strategy of abnomality extraction to indirectly correct the impact of artifact in MR images by learning the deep features. Experimental results show that our method is superior to state-of-the-art networks and can potentially be applied in real clinical settings.
NaQ: Leveraging Narrations as Queries to Supervise Episodic Memory
Jan 02, 2023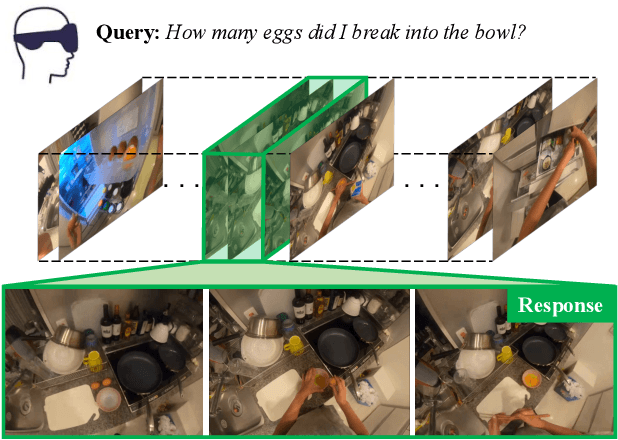
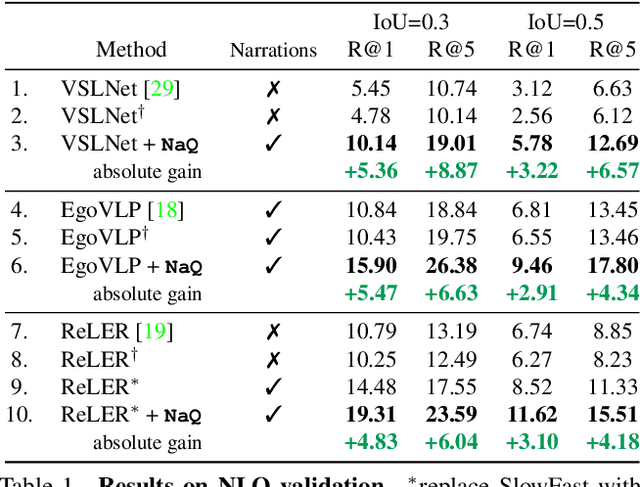

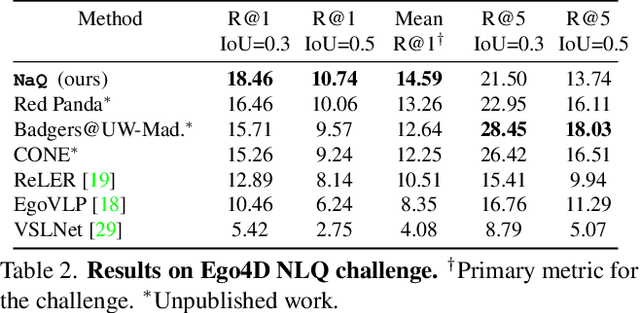
Searching long egocentric videos with natural language queries (NLQ) has compelling applications in augmented reality and robotics, where a fluid index into everything that a person (agent) has seen before could augment human memory and surface relevant information on demand. However, the structured nature of the learning problem (free-form text query inputs, localized video temporal window outputs) and its needle-in-a-haystack nature makes it both technically challenging and expensive to supervise. We introduce Narrations-as-Queries (NaQ), a data augmentation strategy that transforms standard video-text narrations into training data for a video query localization model. Validating our idea on the Ego4D benchmark, we find it has tremendous impact in practice. NaQ improves multiple top models by substantial margins (even doubling their accuracy), and yields the very best results to date on the Ego4D NLQ challenge, soundly outperforming all challenge winners in the CVPR and ECCV 2022 competitions and topping the current public leaderboard. Beyond achieving the state-of-the-art for NLQ, we also demonstrate unique properties of our approach such as gains on long-tail object queries, and the ability to perform zero-shot and few-shot NLQ.
Statistical Machine Translation for Indic Languages
Jan 02, 2023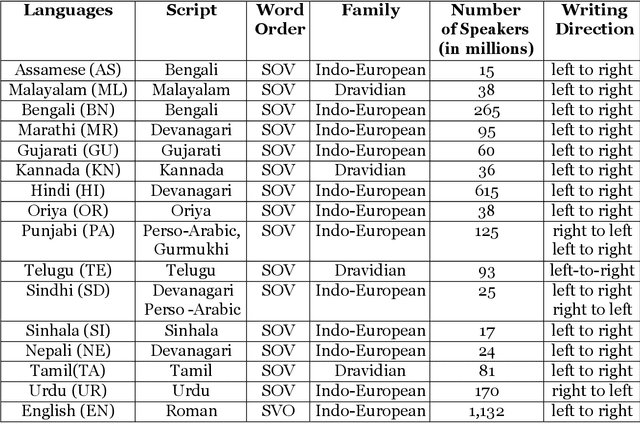

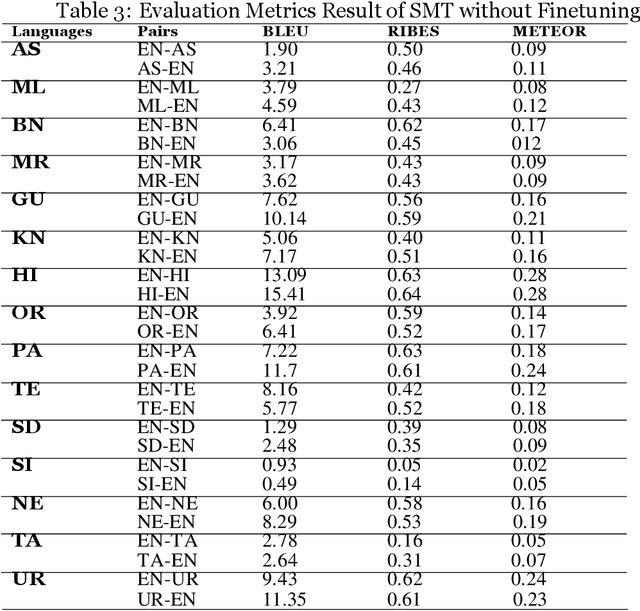
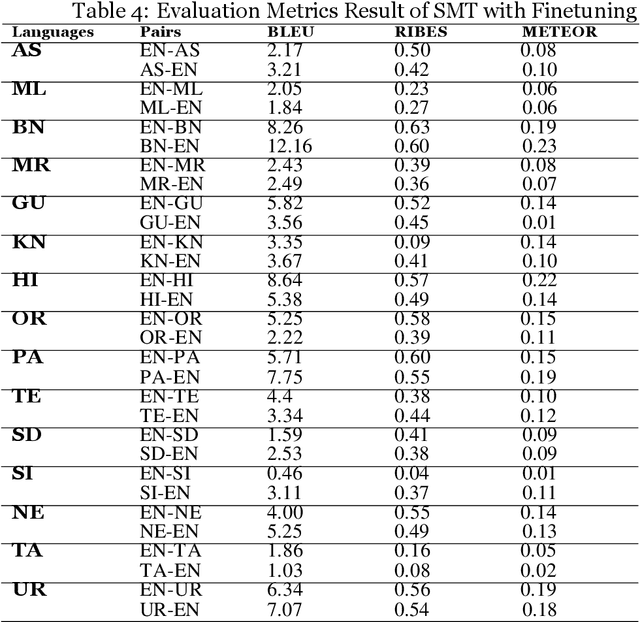
Machine Translation (MT) system generally aims at automatic representation of source language into target language retaining the originality of context using various Natural Language Processing (NLP) techniques. Among various NLP methods, Statistical Machine Translation(SMT). SMT uses probabilistic and statistical techniques to analyze information and conversion. This paper canvasses about the development of bilingual SMT models for translating English to fifteen low-resource Indian Languages (ILs) and vice versa. At the outset, all 15 languages are briefed with a short description related to our experimental need. Further, a detailed analysis of Samanantar and OPUS dataset for model building, along with standard benchmark dataset (Flores-200) for fine-tuning and testing, is done as a part of our experiment. Different preprocessing approaches are proposed in this paper to handle the noise of the dataset. To create the system, MOSES open-source SMT toolkit is explored. Distance reordering is utilized with the aim to understand the rules of grammar and context-dependent adjustments through a phrase reordering categorization framework. In our experiment, the quality of the translation is evaluated using standard metrics such as BLEU, METEOR, and RIBES
Ranking Differential Privacy
Jan 02, 2023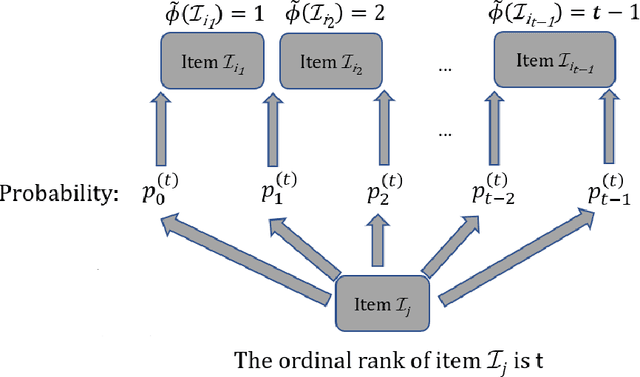
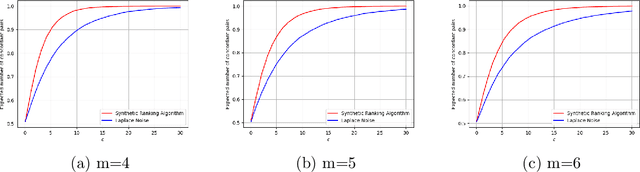
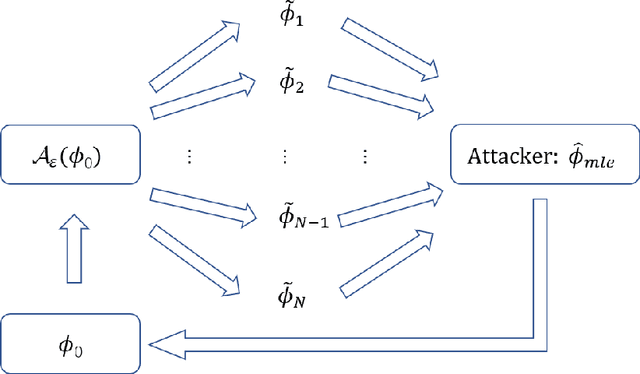
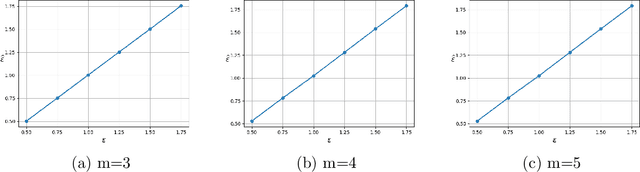
Rankings are widely collected in various real-life scenarios, leading to the leakage of personal information such as users' preferences on videos or news. To protect rankings, existing works mainly develop privacy protection on a single ranking within a set of ranking or pairwise comparisons of a ranking under the $\epsilon$-differential privacy. This paper proposes a novel notion called $\epsilon$-ranking differential privacy for protecting ranks. We establish the connection between the Mallows model (Mallows, 1957) and the proposed $\epsilon$-ranking differential privacy. This allows us to develop a multistage ranking algorithm to generate synthetic rankings while satisfying the developed $\epsilon$-ranking differential privacy. Theoretical results regarding the utility of synthetic rankings in the downstream tasks, including the inference attack and the personalized ranking tasks, are established. For the inference attack, we quantify how $\epsilon$ affects the estimation of the true ranking based on synthetic rankings. For the personalized ranking task, we consider varying privacy preferences among users and quantify how their privacy preferences affect the consistency in estimating the optimal ranking function. Extensive numerical experiments are carried out to verify the theoretical results and demonstrate the effectiveness of the proposed synthetic ranking algorithm.
Curriculum Learning Meets Weakly Supervised Modality Correlation Learning
Dec 15, 2022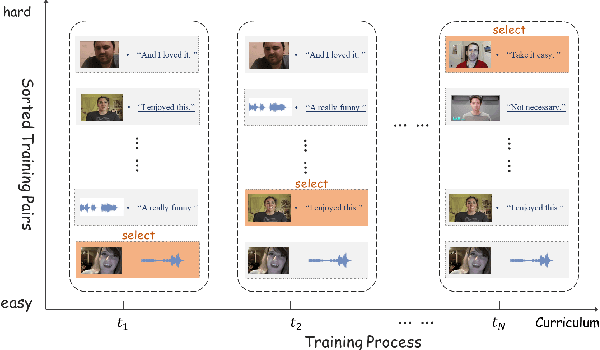
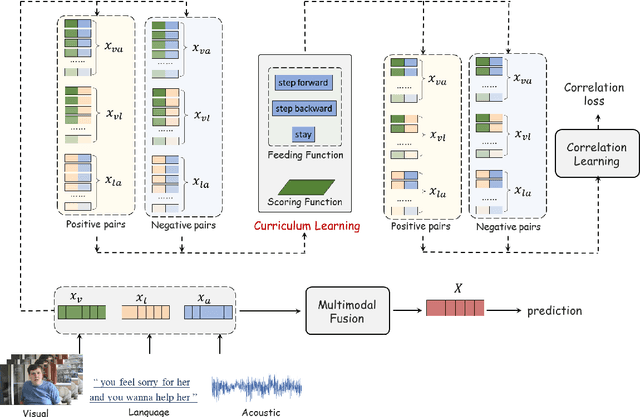
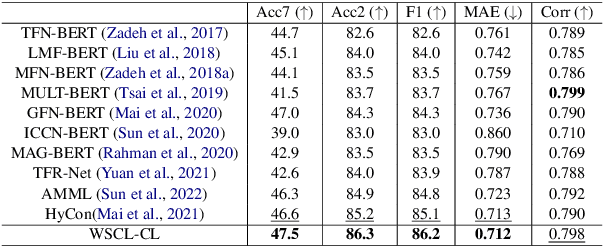
In the field of multimodal sentiment analysis (MSA), a few studies have leveraged the inherent modality correlation information stored in samples for self-supervised learning. However, they feed the training pairs in a random order without consideration of difficulty. Without human annotation, the generated training pairs of self-supervised learning often contain noise. If noisy or hard pairs are used for training at the easy stage, the model might be stuck in bad local optimum. In this paper, we inject curriculum learning into weakly supervised modality correlation learning. The weakly supervised correlation learning leverages the label information to generate scores for negative pairs to learn a more discriminative embedding space, where negative pairs are defined as two unimodal embeddings from different samples. To assist the correlation learning, we feed the training pairs to the model according to difficulty by the proposed curriculum learning, which consists of elaborately designed scoring and feeding functions. The scoring function computes the difficulty of pairs using pre-trained and current correlation predictors, where the pairs with large losses are defined as hard pairs. Notably, the hardest pairs are discarded in our algorithm, which are assumed as noisy pairs. Moreover, the feeding function takes the difference of correlation losses as feedback to determine the feeding actions (`stay', `step back', or `step forward'). The proposed method reaches state-of-the-art performance on MSA.
Research of an optimization model for servicing a network of ATMs and information payment terminals
Oct 18, 2022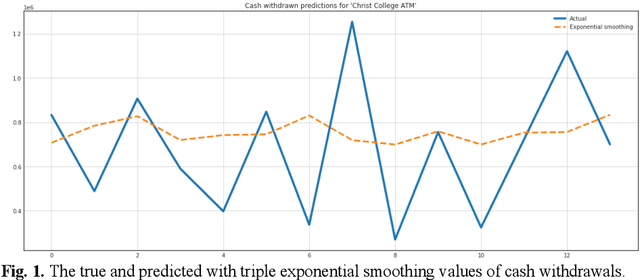
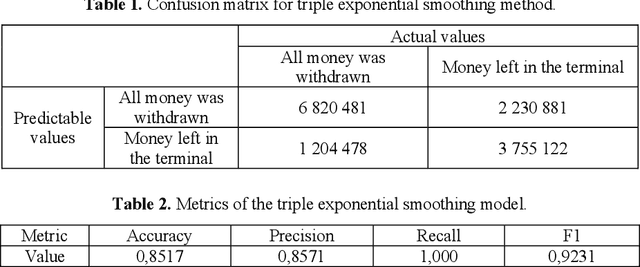
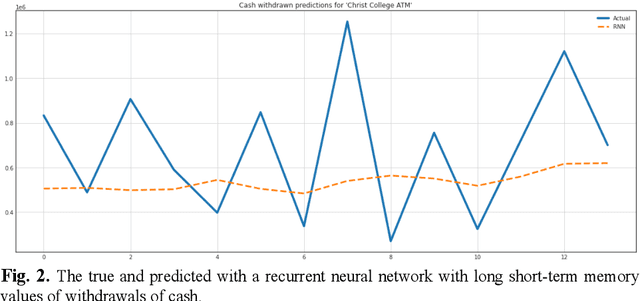

The steadily high demand for cash contributes to the expansion of the network of Bank payment terminals. To optimize the amount of cash in payment terminals, it is necessary to minimize the cost of servicing them and ensure that there are no excess funds in the network. The purpose of this work is to create a cash management system in the network of payment terminals. The article discusses the solution to the problem of determining the optimal amount of funds to be loaded into the terminals, and the effective frequency of collection, which allows to get additional income by investing the released funds. The paper presents the results of predicting daily cash withdrawals at ATMs using a triple exponential smoothing model, a recurrent neural network with long short-term memory, and a model of singular spectrum analysis. These forecasting models allowed us to obtain a sufficient level of correct forecasts with good accuracy and completeness. The results of forecasting cash withdrawals were used to build a discrete optimal control model, which was used to develop an optimal schedule for adding funds to the payment terminal. It is proved that the efficiency and reliability of the proposed model is higher than that of the classical Baumol-Tobin inventory management model: when tested on the time series of three ATMs, the discrete optimal control model did not allow exhaustion of funds and allowed to earn on average 30% more than the classical model.