 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
MDL-based Compressing Sequential Rules
Dec 20, 2022
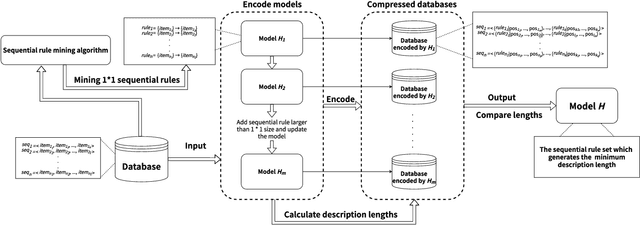
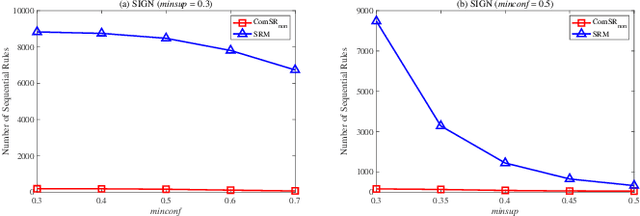
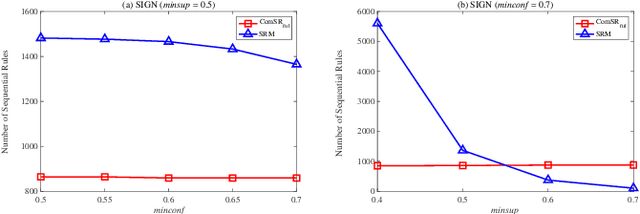
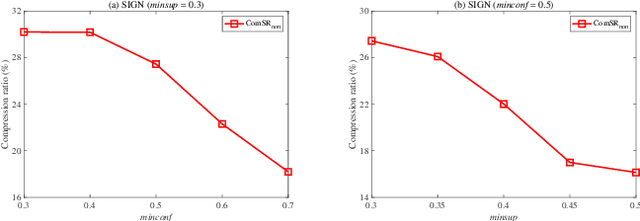
Nowadays, with the rapid development of the Internet, the era of big data has come. The Internet generates huge amounts of data every day. However, extracting meaningful information from massive data is like looking for a needle in a haystack. Data mining techniques can provide various feasible methods to solve this problem. At present, many sequential rule mining (SRM) algorithms are presented to find sequential rules in databases with sequential characteristics. These rules help people extract a lot of meaningful information from massive amounts of data. How can we achieve compression of mined results and reduce data size to save storage space and transmission time? Until now, there has been little research on the compression of SRM. In this paper, combined with the Minimum Description Length (MDL) principle and under the two metrics (support and confidence), we introduce the problem of compression of SRM and also propose a solution named ComSR for MDL-based compressing of sequential rules based on the designed sequential rule coding scheme. To our knowledge, we are the first to use sequential rules to encode an entire database. A heuristic method is proposed to find a set of compact and meaningful sequential rules as much as possible. ComSR has two trade-off algorithms, ComSR_non and ComSR_ful, based on whether the database can be completely compressed. Experiments done on a real dataset with different thresholds show that a set of compact and meaningful sequential rules can be found. This shows that the proposed method works.
Enabling AI-Generated Content (AIGC) Services in Wireless Edge Networks
Jan 09, 2023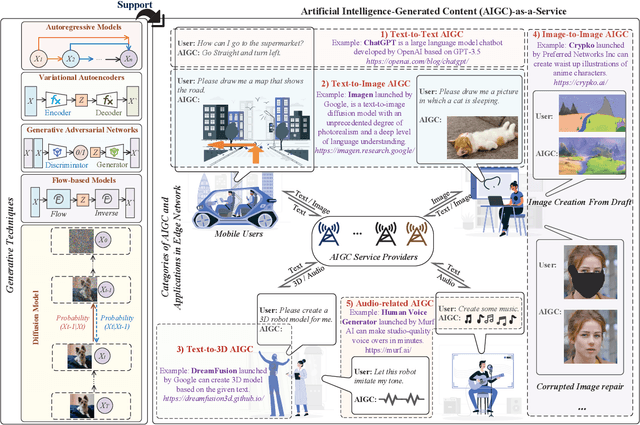
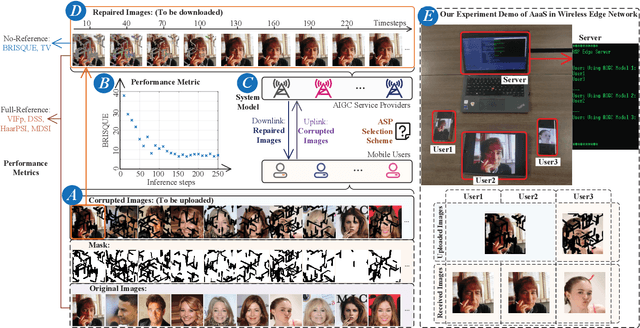
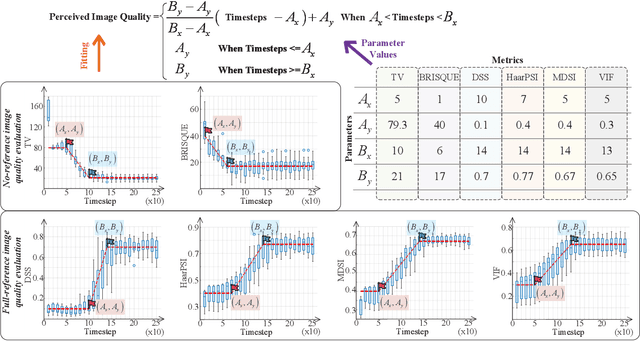
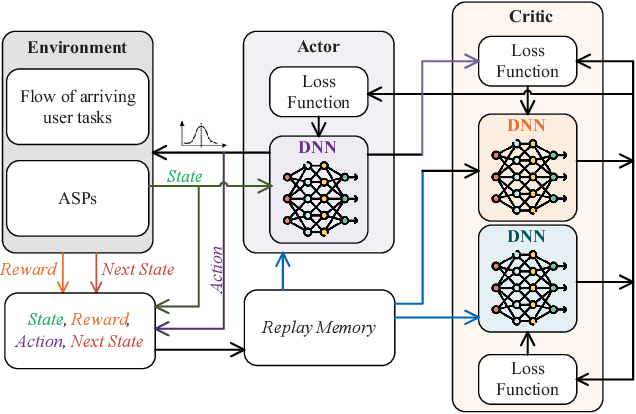
Artificial Intelligence-Generated Content (AIGC) refers to the use of AI to automate the information creation process while fulfilling the personalized requirements of users. However, due to the instability of AIGC models, e.g., the stochastic nature of diffusion models, the quality and accuracy of the generated content can vary significantly. In wireless edge networks, the transmission of incorrectly generated content may unnecessarily consume network resources. Thus, a dynamic AIGC service provider (ASP) selection scheme is required to enable users to connect to the most suited ASP, improving the users' satisfaction and quality of generated content. In this article, we first review the AIGC techniques and their applications in wireless networks. We then present the AIGC-as-a-service (AaaS) concept and discuss the challenges in deploying AaaS at the edge networks. Yet, it is essential to have performance metrics to evaluate the accuracy of AIGC services. Thus, we introduce several image-based perceived quality evaluation metrics. Then, we propose a general and effective model to illustrate the relationship between computational resources and user-perceived quality evaluation metrics. To achieve efficient AaaS and maximize the quality of generated content in wireless edge networks, we propose a deep reinforcement learning-enabled algorithm for optimal ASP selection. Simulation results show that the proposed algorithm can provide a higher quality of generated content to users and achieve fewer crashed tasks by comparing with four benchmarks, i.e., overloading-avoidance, random, round-robin policies, and the upper-bound schemes.
Removing Non-Stationary Knowledge From Pre-Trained Language Models for Entity-Level Sentiment Classification in Finance
Jan 09, 2023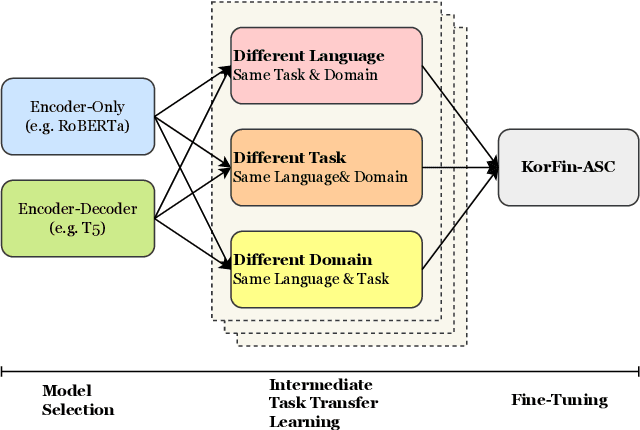

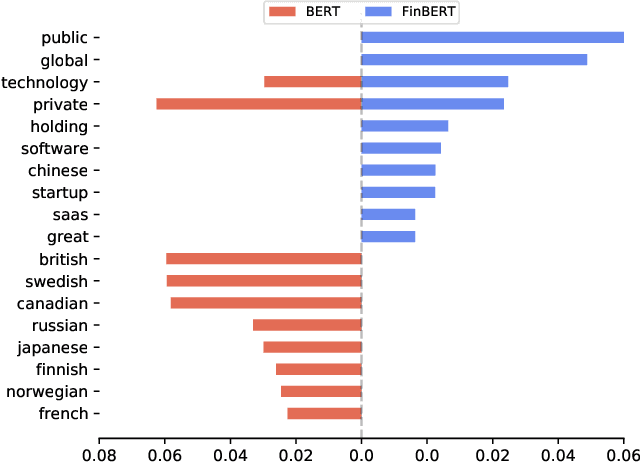
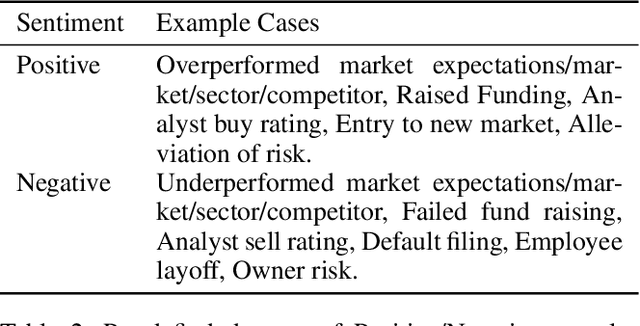
Extraction of sentiment signals from news text, stock message boards, and business reports, for stock movement prediction, has been a rising field of interest in finance. Building upon past literature, the most recent works attempt to better capture sentiment from sentences with complex syntactic structures by introducing aspect-level sentiment classification (ASC). Despite the growing interest, however, fine-grained sentiment analysis has not been fully explored in non-English literature due to the shortage of annotated finance-specific data. Accordingly, it is necessary for non-English languages to leverage datasets and pre-trained language models (PLM) of different domains, languages, and tasks to best their performance. To facilitate finance-specific ASC research in the Korean language, we build KorFinASC, a Korean aspect-level sentiment classification dataset for finance consisting of 12,613 human-annotated samples, and explore methods of intermediate transfer learning. Our experiments indicate that past research has been ignorant towards the potentially wrong knowledge of financial entities encoded during the training phase, which has overestimated the predictive power of PLMs. In our work, we use the term "non-stationary knowledge'' to refer to information that was previously correct but is likely to change, and present "TGT-Masking'', a novel masking pattern to restrict PLMs from speculating knowledge of the kind. Finally, through a series of transfer learning with TGT-Masking applied we improve 22.63% of classification accuracy compared to standalone models on KorFinASC.
Non-contact Respiratory Anomaly Detection using Infrared Light Wave Sensing
Jan 09, 2023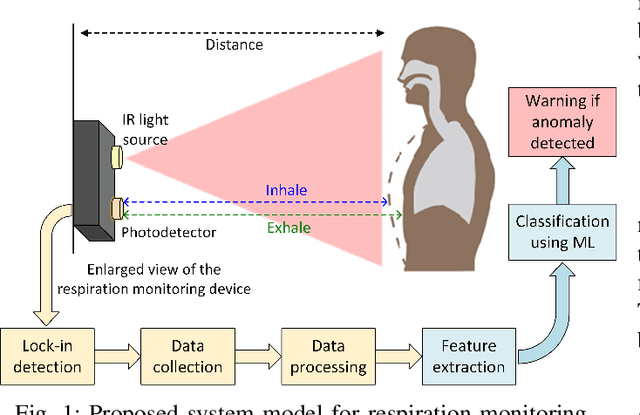
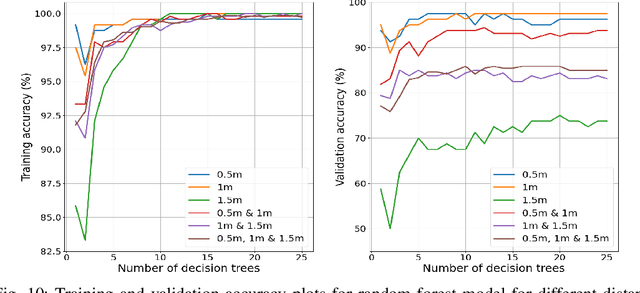
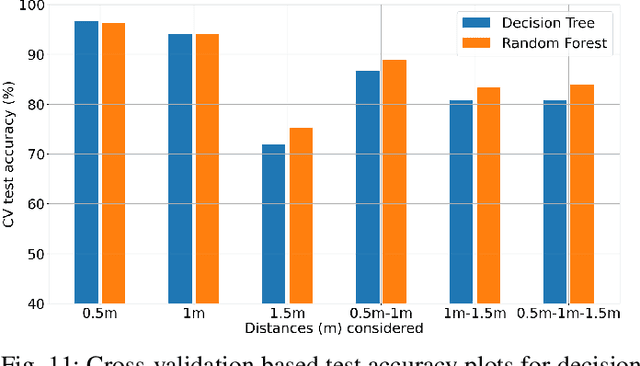

Human respiratory rate and its pattern convey important information about the physical and psychological states of the subject. Abnormal breathing can be a sign of fatal health issues which may lead to further diagnosis and treatment. Wireless light wave sensing (LWS) using incoherent infrared light turns out to be promising in human breathing monitoring in a safe, discreet, efficient and non-invasive way without raising any privacy concerns. The regular breathing patterns of each individual are unique, hence the respiration monitoring system needs to learn the subject's usual pattern in order to raise flags for breathing anomalies. Additionally, the system needs to be capable of validating that the collected data is a breathing waveform, since any faulty data generated due to external interruption or system malfunction should be discarded. In order to serve both of these needs, breathing data of normal and abnormal breathing were collected using infrared light wave sensing technology in this study. Two machine learning algorithms, decision tree and random forest, were applied to detect breathing anomalies and faulty data. Finally, model performance was evaluated using average classification accuracies found through cross-validation. The highest classification accuracy of 96.6% was achieved with the data collected at 0.5m distance using decision tree model. Ensemble models like random forest were found to perform better than a single model in classifying the data that were collected at multiple distances from the light wave sensing setup.
Targeted Phishing Campaigns using Large Scale Language Models
Dec 30, 2022In this research, we aim to explore the potential of natural language models (NLMs) such as GPT-3 and GPT-2 to generate effective phishing emails. Phishing emails are fraudulent messages that aim to trick individuals into revealing sensitive information or taking actions that benefit the attackers. We propose a framework for evaluating the performance of NLMs in generating these types of emails based on various criteria, including the quality of the generated text, the ability to bypass spam filters, and the success rate of tricking individuals. Our evaluations show that NLMs are capable of generating phishing emails that are difficult to detect and that have a high success rate in tricking individuals, but their effectiveness varies based on the specific NLM and training data used. Our research indicates that NLMs could have a significant impact on the prevalence of phishing attacks and emphasizes the need for further study on the ethical and security implications of using NLMs for malicious purposes.
Heterogeneous Synthetic Learner for Panel Data
Dec 30, 2022
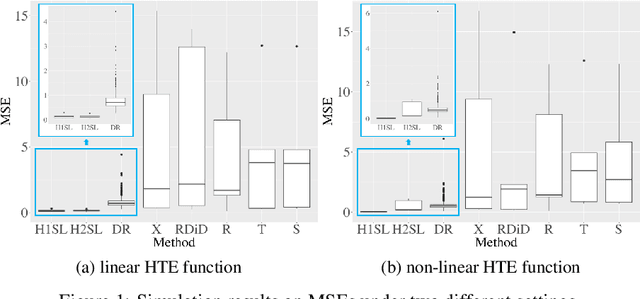
In the new era of personalization, learning the heterogeneous treatment effect (HTE) becomes an inevitable trend with numerous applications. Yet, most existing HTE estimation methods focus on independently and identically distributed observations and cannot handle the non-stationarity and temporal dependency in the common panel data setting. The treatment evaluators developed for panel data, on the other hand, typically ignore the individualized information. To fill the gap, in this paper, we initialize the study of HTE estimation in panel data. Under different assumptions for HTE identifiability, we propose the corresponding heterogeneous one-side and two-side synthetic learner, namely H1SL and H2SL, by leveraging the state-of-the-art HTE estimator for non-panel data and generalizing the synthetic control method that allows flexible data generating process. We establish the convergence rates of the proposed estimators. The superior performance of the proposed methods over existing ones is demonstrated by extensive numerical studies.
Memory Augmented Lookup Dictionary based Language Modeling for Automatic Speech Recognition
Dec 30, 2022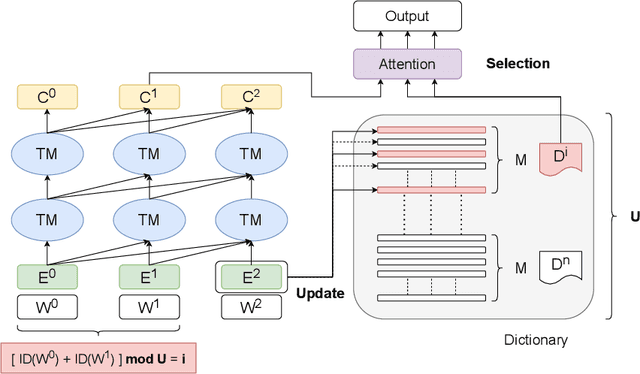
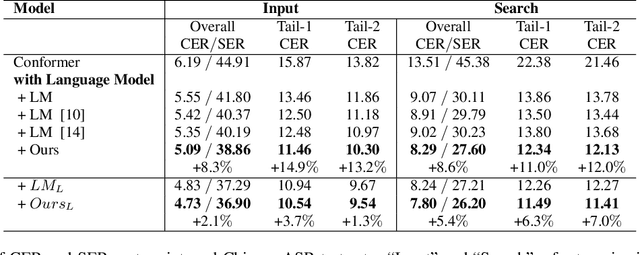
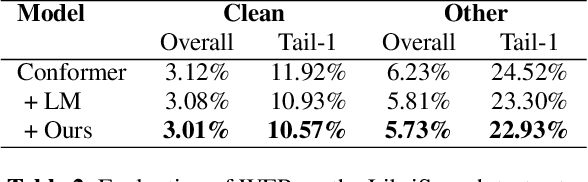
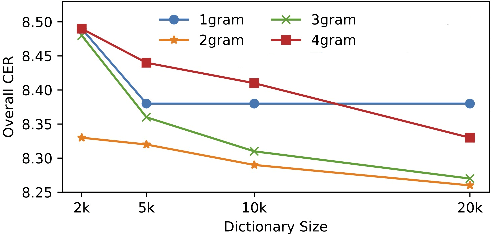
Recent studies have shown that using an external Language Model (LM) benefits the end-to-end Automatic Speech Recognition (ASR). However, predicting tokens that appear less frequently in the training set is still quite challenging. The long-tail prediction problems have been widely studied in many applications, but only been addressed by a few studies for ASR and LMs. In this paper, we propose a new memory augmented lookup dictionary based Transformer architecture for LM. The newly introduced lookup dictionary incorporates rich contextual information in training set, which is vital to correctly predict long-tail tokens. With intensive experiments on Chinese and English data sets, our proposed method is proved to outperform the baseline Transformer LM by a great margin on both word/character error rate and tail tokens error rate. This is achieved without impact on the decoding efficiency. Overall, we demonstrate the effectiveness of our proposed method in boosting the ASR decoding performance, especially for long-tail tokens.
MINTIME: Multi-Identity Size-Invariant Video Deepfake Detection
Dec 07, 2022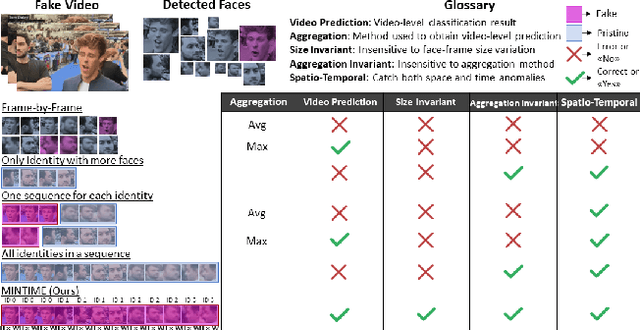
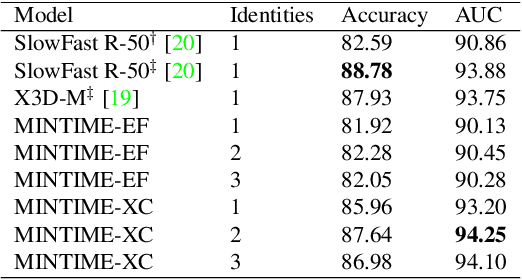
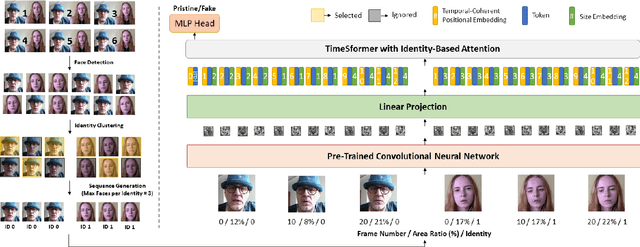

In this paper, we introduce MINTIME, a video deepfake detection approach that captures spatial and temporal anomalies and handles instances of multiple people in the same video and variations in face sizes. Previous approaches disregard such information either by using simple a-posteriori aggregation schemes, i.e., average or max operation, or using only one identity for the inference, i.e., the largest one. On the contrary, the proposed approach builds on a Spatio-Temporal TimeSformer combined with a Convolutional Neural Network backbone to capture spatio-temporal anomalies from the face sequences of multiple identities depicted in a video. This is achieved through an Identity-aware Attention mechanism that attends to each face sequence independently based on a masking operation and facilitates video-level aggregation. In addition, two novel embeddings are employed: (i) the Temporal Coherent Positional Embedding that encodes each face sequence's temporal information and (ii) the Size Embedding that encodes the size of the faces as a ratio to the video frame size. These extensions allow our system to adapt particularly well in the wild by learning how to aggregate information of multiple identities, which is usually disregarded by other methods in the literature. It achieves state-of-the-art results on the ForgeryNet dataset with an improvement of up to 14% AUC in videos containing multiple people and demonstrates ample generalization capabilities in cross-forgery and cross-dataset settings. The code is publicly available at https://github.com/davide-coccomini/MINTIME-Multi-Identity-size-iNvariant-TIMEsformer-for-Video-Deepfake-Detection.
Gradient Domain Weighted Guided Image Filtering
Nov 30, 2022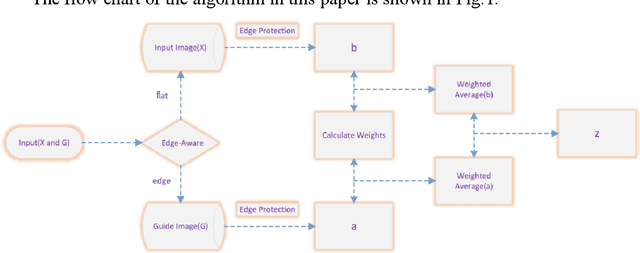
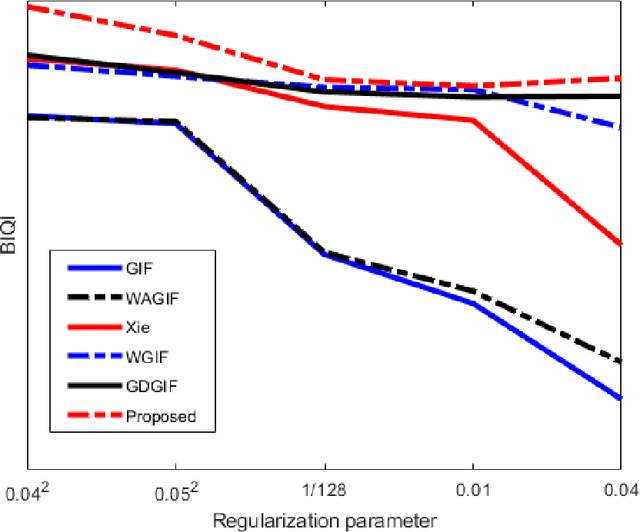


As an excellent local filter, guided image filters are subject to halo artifacts. In this paper, the algorithm uses gradient information to accurately determine the edge of the image, and uses the weighted information to further accurately distinguish the flat area and edge area of the image. As a result, the edges of the image are sharper and the level of blur in flat areas is reduced, avoiding halo artifacts caused by excessive blurring near edges. Experiments show that the proposed algorithm can better suppress halo artifacts at the edges. The proposed algorithm has good performance in both image denoising and image detail enhancement.
Why do Nearest Neighbor Language Models Work?
Jan 07, 2023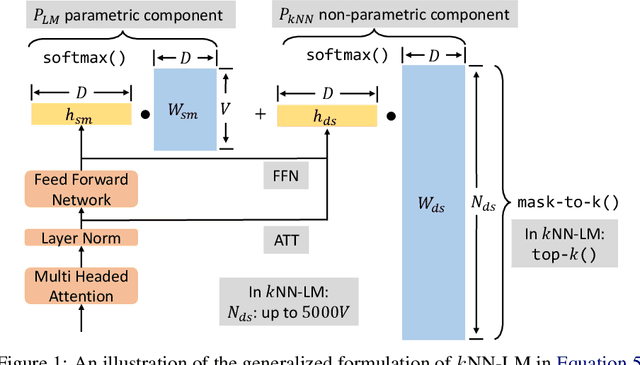


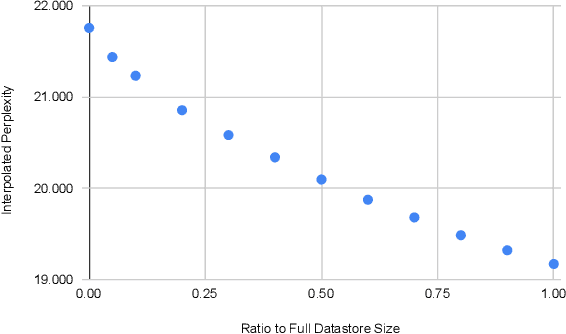
Language models (LMs) compute the probability of a text by sequentially computing a representation of an already-seen context and using this representation to predict the next word. Currently, most LMs calculate these representations through a neural network consuming the immediate previous context. However recently, retrieval-augmented LMs have shown to improve over standard neural LMs, by accessing information retrieved from a large datastore, in addition to their standard, parametric, next-word prediction. In this paper, we set out to understand why retrieval-augmented language models, and specifically why k-nearest neighbor language models (kNN-LMs) perform better than standard parametric LMs, even when the k-nearest neighbor component retrieves examples from the same training set that the LM was originally trained on. To this end, we perform a careful analysis of the various dimensions over which kNN-LM diverges from standard LMs, and investigate these dimensions one by one. Empirically, we identify three main reasons why kNN-LM performs better than standard LMs: using a different input representation for predicting the next tokens, approximate kNN search, and the importance of softmax temperature for the kNN distribution. Further, we incorporate these insights into the model architecture or the training procedure of the standard parametric LM, improving its results without the need for an explicit retrieval component. The code is available at https://github.com/frankxu2004/knnlm-why.