 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Discovery of partial differential equations from highly noisy and sparse data with physics-informed information criterion
Aug 05, 2022
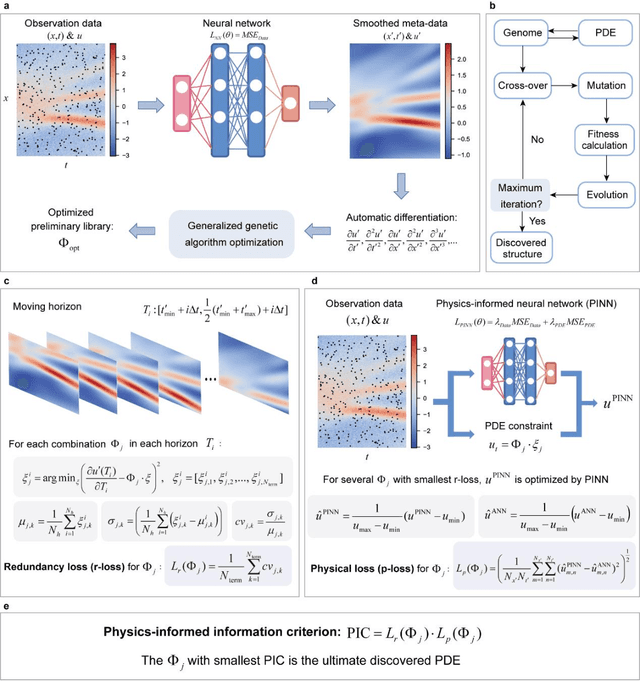
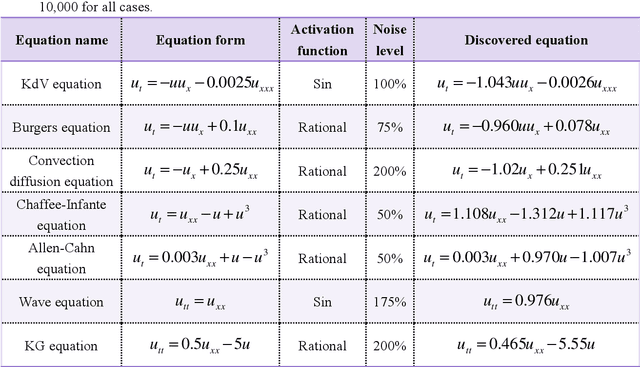
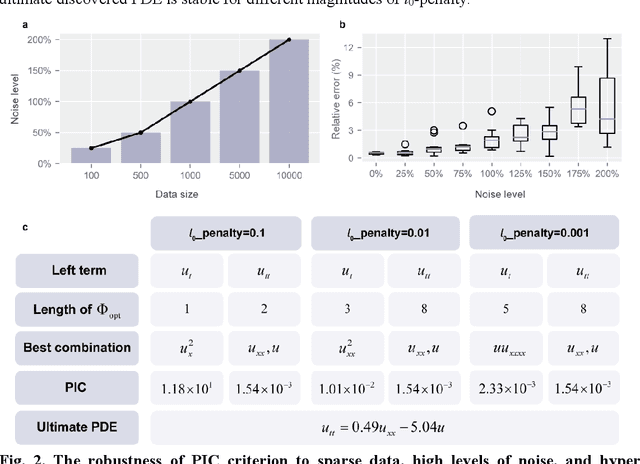

Data-driven discovery of PDEs has made tremendous progress recently, and many canonical PDEs have been discovered successfully for proof-of-concept. However, determining the most proper PDE without prior references remains challenging in terms of practical applications. In this work, a physics-informed information criterion (PIC) is proposed to measure the parsimony and precision of the discovered PDE synthetically. The proposed PIC achieves state-of-the-art robustness to highly noisy and sparse data on seven canonical PDEs from different physical scenes, which confirms its ability to handle difficult situations. The PIC is also employed to discover unrevealed macroscale governing equations from microscopic simulation data in an actual physical scene. The results show that the discovered macroscale PDE is precise and parsimonious, and satisfies underlying symmetries, which facilitates understanding and simulation of the physical process. The proposition of PIC enables practical applications of PDE discovery in discovering unrevealed governing equations in broader physical scenes.
Targeted Phishing Campaigns using Large Scale Language Models
Dec 30, 2022In this research, we aim to explore the potential of natural language models (NLMs) such as GPT-3 and GPT-2 to generate effective phishing emails. Phishing emails are fraudulent messages that aim to trick individuals into revealing sensitive information or taking actions that benefit the attackers. We propose a framework for evaluating the performance of NLMs in generating these types of emails based on various criteria, including the quality of the generated text, the ability to bypass spam filters, and the success rate of tricking individuals. Our evaluations show that NLMs are capable of generating phishing emails that are difficult to detect and that have a high success rate in tricking individuals, but their effectiveness varies based on the specific NLM and training data used. Our research indicates that NLMs could have a significant impact on the prevalence of phishing attacks and emphasizes the need for further study on the ethical and security implications of using NLMs for malicious purposes.
Heterogeneous Synthetic Learner for Panel Data
Dec 30, 2022
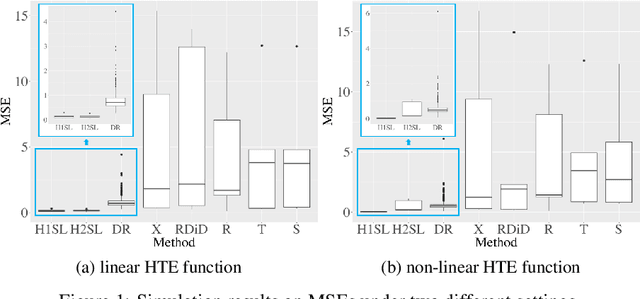
In the new era of personalization, learning the heterogeneous treatment effect (HTE) becomes an inevitable trend with numerous applications. Yet, most existing HTE estimation methods focus on independently and identically distributed observations and cannot handle the non-stationarity and temporal dependency in the common panel data setting. The treatment evaluators developed for panel data, on the other hand, typically ignore the individualized information. To fill the gap, in this paper, we initialize the study of HTE estimation in panel data. Under different assumptions for HTE identifiability, we propose the corresponding heterogeneous one-side and two-side synthetic learner, namely H1SL and H2SL, by leveraging the state-of-the-art HTE estimator for non-panel data and generalizing the synthetic control method that allows flexible data generating process. We establish the convergence rates of the proposed estimators. The superior performance of the proposed methods over existing ones is demonstrated by extensive numerical studies.
Memory Augmented Lookup Dictionary based Language Modeling for Automatic Speech Recognition
Dec 30, 2022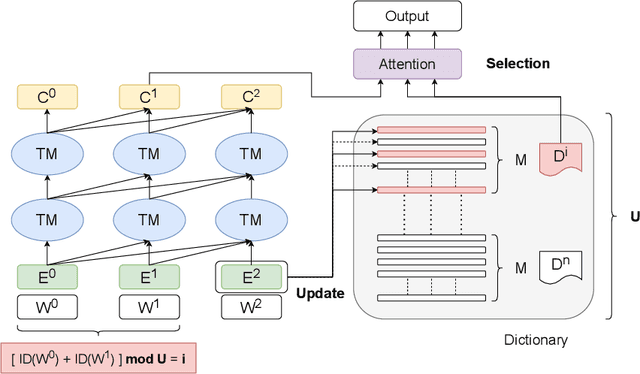
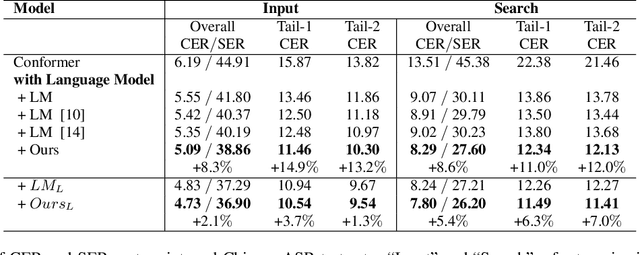
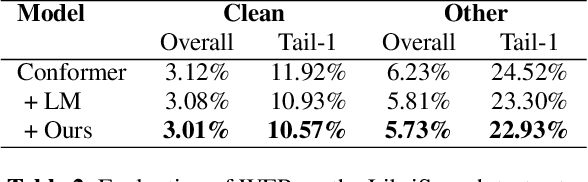
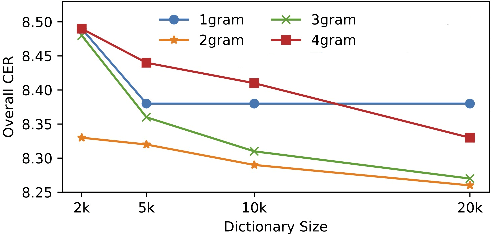
Recent studies have shown that using an external Language Model (LM) benefits the end-to-end Automatic Speech Recognition (ASR). However, predicting tokens that appear less frequently in the training set is still quite challenging. The long-tail prediction problems have been widely studied in many applications, but only been addressed by a few studies for ASR and LMs. In this paper, we propose a new memory augmented lookup dictionary based Transformer architecture for LM. The newly introduced lookup dictionary incorporates rich contextual information in training set, which is vital to correctly predict long-tail tokens. With intensive experiments on Chinese and English data sets, our proposed method is proved to outperform the baseline Transformer LM by a great margin on both word/character error rate and tail tokens error rate. This is achieved without impact on the decoding efficiency. Overall, we demonstrate the effectiveness of our proposed method in boosting the ASR decoding performance, especially for long-tail tokens.
Why do Nearest Neighbor Language Models Work?
Jan 07, 2023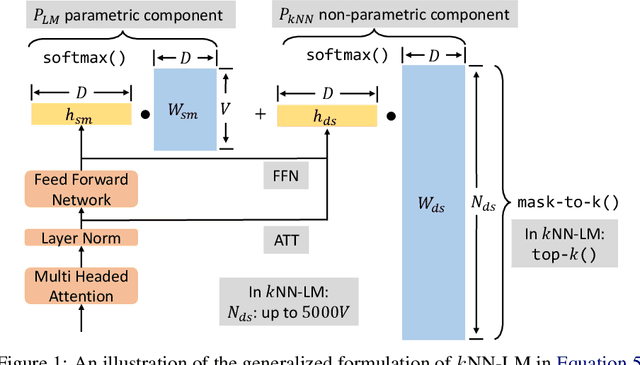


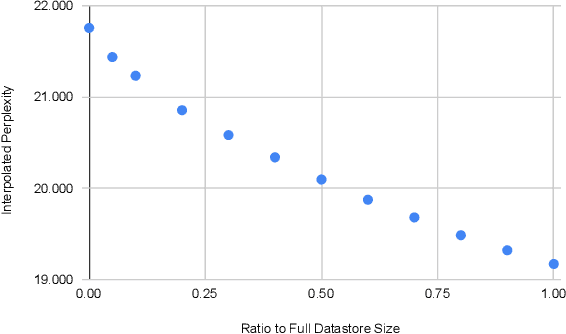
Language models (LMs) compute the probability of a text by sequentially computing a representation of an already-seen context and using this representation to predict the next word. Currently, most LMs calculate these representations through a neural network consuming the immediate previous context. However recently, retrieval-augmented LMs have shown to improve over standard neural LMs, by accessing information retrieved from a large datastore, in addition to their standard, parametric, next-word prediction. In this paper, we set out to understand why retrieval-augmented language models, and specifically why k-nearest neighbor language models (kNN-LMs) perform better than standard parametric LMs, even when the k-nearest neighbor component retrieves examples from the same training set that the LM was originally trained on. To this end, we perform a careful analysis of the various dimensions over which kNN-LM diverges from standard LMs, and investigate these dimensions one by one. Empirically, we identify three main reasons why kNN-LM performs better than standard LMs: using a different input representation for predicting the next tokens, approximate kNN search, and the importance of softmax temperature for the kNN distribution. Further, we incorporate these insights into the model architecture or the training procedure of the standard parametric LM, improving its results without the need for an explicit retrieval component. The code is available at https://github.com/frankxu2004/knnlm-why.
MDL-based Compressing Sequential Rules
Dec 20, 2022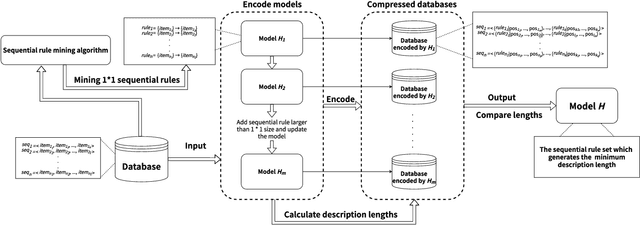
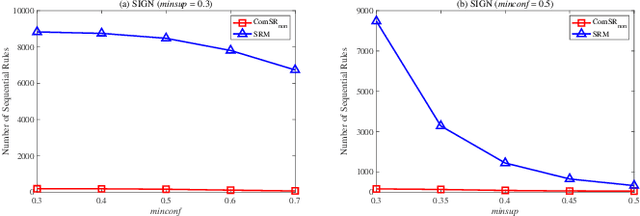
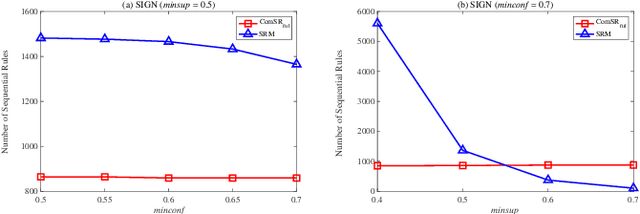
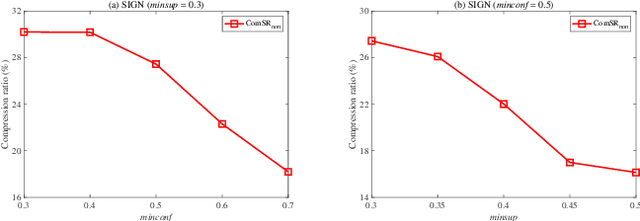
Nowadays, with the rapid development of the Internet, the era of big data has come. The Internet generates huge amounts of data every day. However, extracting meaningful information from massive data is like looking for a needle in a haystack. Data mining techniques can provide various feasible methods to solve this problem. At present, many sequential rule mining (SRM) algorithms are presented to find sequential rules in databases with sequential characteristics. These rules help people extract a lot of meaningful information from massive amounts of data. How can we achieve compression of mined results and reduce data size to save storage space and transmission time? Until now, there has been little research on the compression of SRM. In this paper, combined with the Minimum Description Length (MDL) principle and under the two metrics (support and confidence), we introduce the problem of compression of SRM and also propose a solution named ComSR for MDL-based compressing of sequential rules based on the designed sequential rule coding scheme. To our knowledge, we are the first to use sequential rules to encode an entire database. A heuristic method is proposed to find a set of compact and meaningful sequential rules as much as possible. ComSR has two trade-off algorithms, ComSR_non and ComSR_ful, based on whether the database can be completely compressed. Experiments done on a real dataset with different thresholds show that a set of compact and meaningful sequential rules can be found. This shows that the proposed method works.
Towards Sequence Utility Maximization under Utility Occupancy Measure
Dec 20, 2022

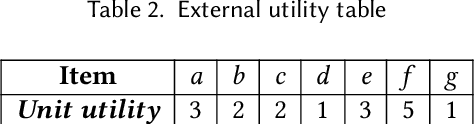

The discovery of utility-driven patterns is a useful and difficult research topic. It can extract significant and interesting information from specific and varied databases, increasing the value of the services provided. In practice, the measure of utility is often used to demonstrate the importance, profit, or risk of an object or a pattern. In the database, although utility is a flexible criterion for each pattern, it is a more absolute criterion due to the neglect of utility sharing. This leads to the derived patterns only exploring partial and local knowledge from a database. Utility occupancy is a recently proposed model that considers the problem of mining with high utility but low occupancy. However, existing studies are concentrated on itemsets that do not reveal the temporal relationship of object occurrences. Therefore, this paper towards sequence utility maximization. We first define utility occupancy on sequence data and raise the problem of High Utility-Occupancy Sequential Pattern Mining (HUOSPM). Three dimensions, including frequency, utility, and occupancy, are comprehensively evaluated in HUOSPM. An algorithm called Sequence Utility Maximization with Utility occupancy measure (SUMU) is proposed. Furthermore, two data structures for storing related information about a pattern, Utility-Occupancy-List-Chain (UOL-Chain) and Utility-Occupancy-Table (UO-Table) with six associated upper bounds, are designed to improve efficiency. Empirical experiments are carried out to evaluate the novel algorithm's efficiency and effectiveness. The influence of different upper bounds and pruning strategies is analyzed and discussed. The comprehensive results suggest that the work of our algorithm is intelligent and effective.
The Architectural Bottleneck Principle
Nov 11, 2022
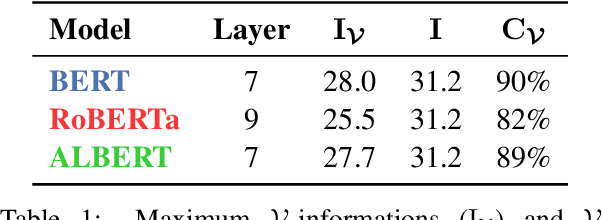
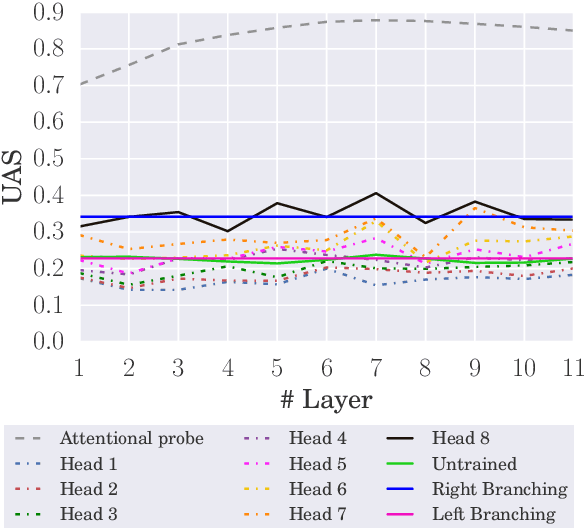
In this paper, we seek to measure how much information a component in a neural network could extract from the representations fed into it. Our work stands in contrast to prior probing work, most of which investigates how much information a model's representations contain. This shift in perspective leads us to propose a new principle for probing, the architectural bottleneck principle: In order to estimate how much information a given component could extract, a probe should look exactly like the component. Relying on this principle, we estimate how much syntactic information is available to transformers through our attentional probe, a probe that exactly resembles a transformer's self-attention head. Experimentally, we find that, in three models (BERT, ALBERT, and RoBERTa), a sentence's syntax tree is mostly extractable by our probe, suggesting these models have access to syntactic information while composing their contextual representations. Whether this information is actually used by these models, however, remains an open question.
The Distributed Information Bottleneck reveals the explanatory structure of complex systems
Apr 15, 2022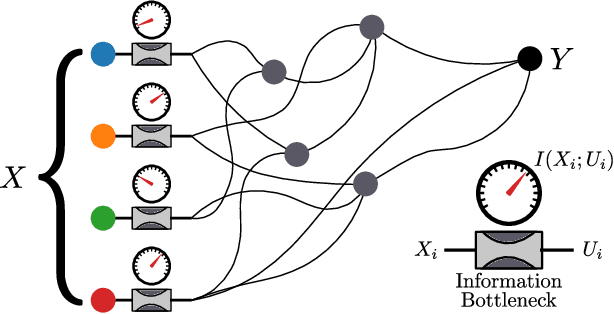
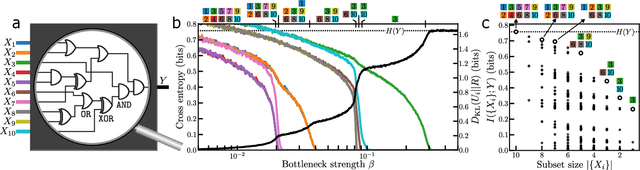
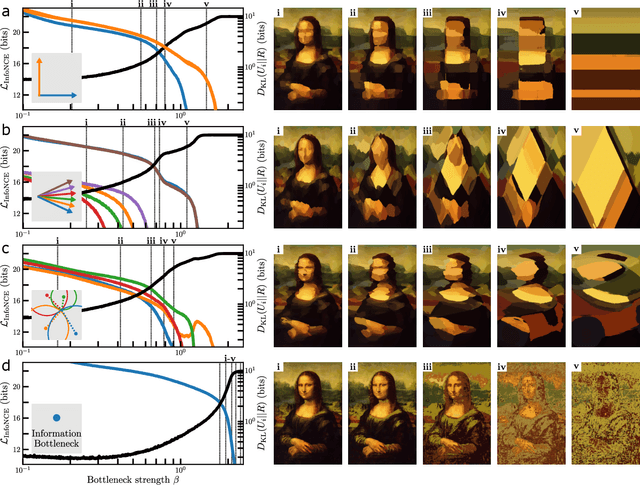
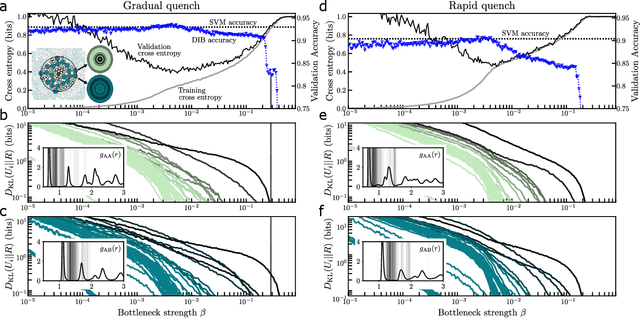
The fruits of science are relationships made comprehensible, often by way of approximation. While deep learning is an extremely powerful way to find relationships in data, its use in science has been hindered by the difficulty of understanding the learned relationships. The Information Bottleneck (IB) is an information theoretic framework for understanding a relationship between an input and an output in terms of a trade-off between the fidelity and complexity of approximations to the relationship. Here we show that a crucial modification -- distributing bottlenecks across multiple components of the input -- opens fundamentally new avenues for interpretable deep learning in science. The Distributed Information Bottleneck throttles the downstream complexity of interactions between the components of the input, deconstructing a relationship into meaningful approximations found through deep learning without requiring custom-made datasets or neural network architectures. Applied to a complex system, the approximations illuminate aspects of the system's nature by restricting -- and monitoring -- the information about different components incorporated into the approximation. We demonstrate the Distributed IB's explanatory utility in systems drawn from applied mathematics and condensed matter physics. In the former, we deconstruct a Boolean circuit into approximations that isolate the most informative subsets of input components without requiring exhaustive search. In the latter, we localize information about future plastic rearrangement in the static structure of a sheared glass, and find the information to be more or less diffuse depending on the system's preparation. By way of a principled scheme of approximations, the Distributed IB brings much-needed interpretability to deep learning and enables unprecedented analysis of information flow through a system.
How Data Scientists Review the Scholarly Literature
Jan 10, 2023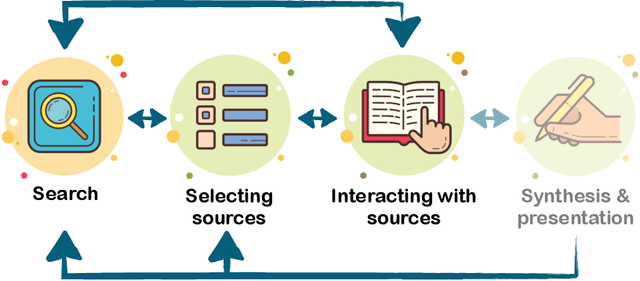
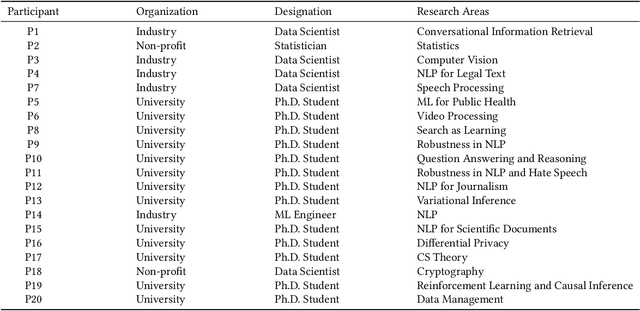
Keeping up with the research literature plays an important role in the workflow of scientists - allowing them to understand a field, formulate the problems they focus on, and develop the solutions that they contribute, which in turn shape the nature of the discipline. In this paper, we examine the literature review practices of data scientists. Data science represents a field seeing an exponential rise in papers, and increasingly drawing on and being applied in numerous diverse disciplines. Recent efforts have seen the development of several tools intended to help data scientists cope with a deluge of research and coordinated efforts to develop AI tools intended to uncover the research frontier. Despite these trends indicative of the information overload faced by data scientists, no prior work has examined the specific practices and challenges faced by these scientists in an interdisciplinary field with evolving scholarly norms. In this paper, we close this gap through a set of semi-structured interviews and think-aloud protocols of industry and academic data scientists (N = 20). Our results while corroborating other knowledge workers' practices uncover several novel findings: individuals (1) are challenged in seeking and sensemaking of papers beyond their disciplinary bubbles, (2) struggle to understand papers in the face of missing details and mathematical content, (3) grapple with the deluge by leveraging the knowledge context in code, blogs, and talks, and (4) lean on their peers online and in-person. Furthermore, we outline future directions likely to help data scientists cope with the burgeoning research literature.