 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Knowledge Base Completion using Web-Based Question Answering and Multimodal Fusion
Nov 15, 2022
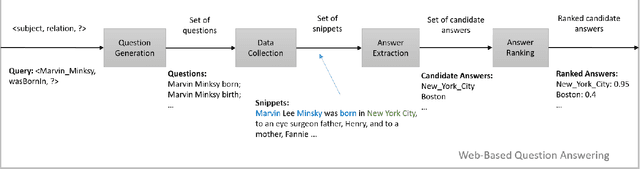
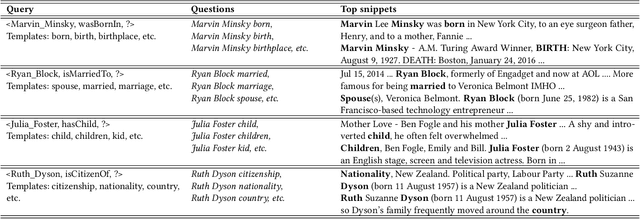
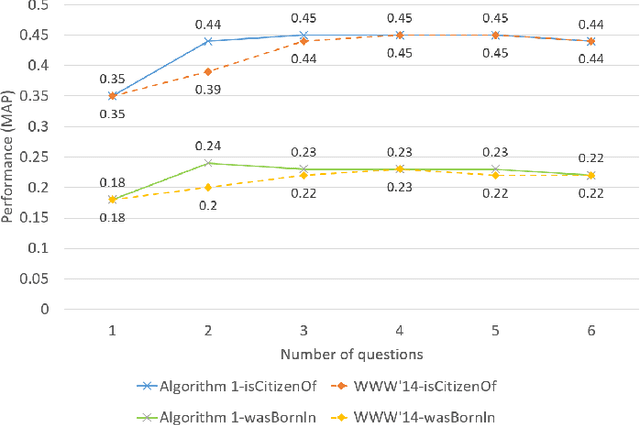

Over the past few years, large knowledge bases have been constructed to store massive amounts of knowledge. However, these knowledge bases are highly incomplete. To solve this problem, we propose a web-based question answering system system with multimodal fusion of unstructured and structured information, to fill in missing information for knowledge bases. To utilize unstructured information from the Web for knowledge base completion, we design a web-based question answering system using multimodal features and question templates to extract missing facts, which can achieve good performance with very few questions. To help improve extraction quality, the question answering system employs structured information from knowledge bases, such as entity types and entity-to-entity relatedness.
Generalized Delayed Feedback Model with Post-Click Information in Recommender Systems
Jun 01, 2022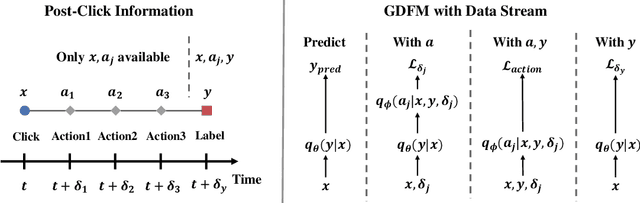
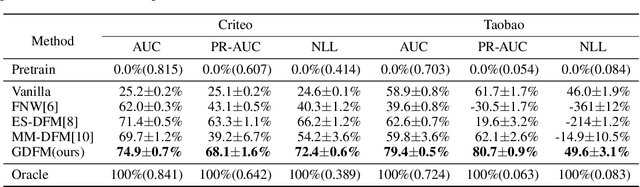
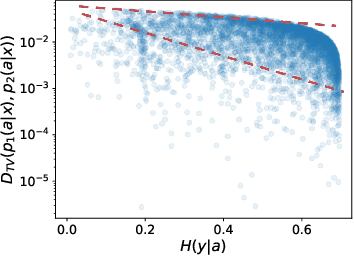
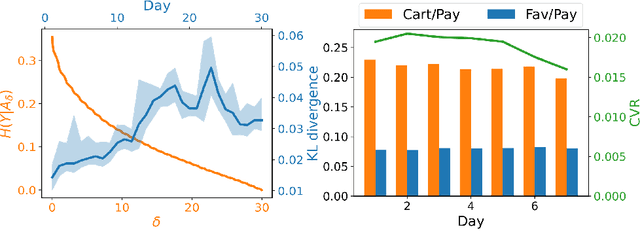
Predicting conversion rate (e.g., the probability that a user will purchase an item) is a fundamental problem in machine learning based recommender systems. However, accurate conversion labels are revealed after a long delay, which harms the timeliness of recommender systems. Previous literature concentrates on utilizing early conversions to mitigate such a delayed feedback problem. In this paper, we show that post-click user behaviors are also informative to conversion rate prediction and can be used to improve timeliness. We propose a generalized delayed feedback model (GDFM) that unifies both post-click behaviors and early conversions as stochastic post-click information, which could be utilized to train GDFM in a streaming manner efficiently. Based on GDFM, we further establish a novel perspective that the performance gap introduced by delayed feedback can be attributed to a temporal gap and a sampling gap. Inspired by our analysis, we propose to measure the quality of post-click information with a combination of temporal distance and sample complexity. The training objective is re-weighted accordingly to highlight informative and timely signals. We validate our analysis on public datasets, and experimental performance confirms the effectiveness of our method.
Multivariate Powered Dirichlet Hawkes Process
Dec 13, 2022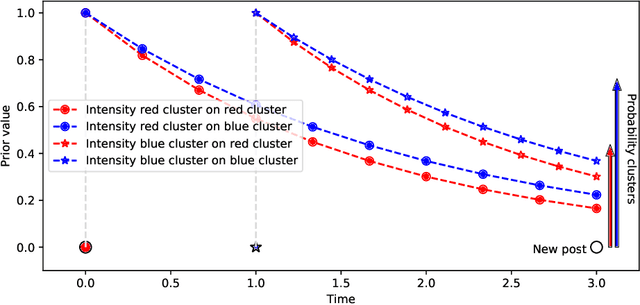
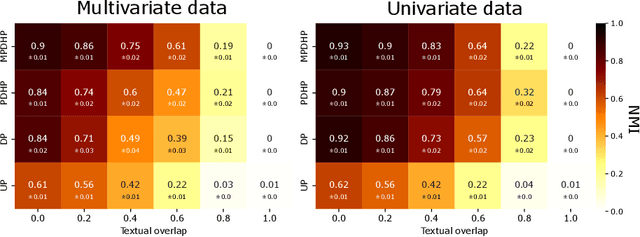
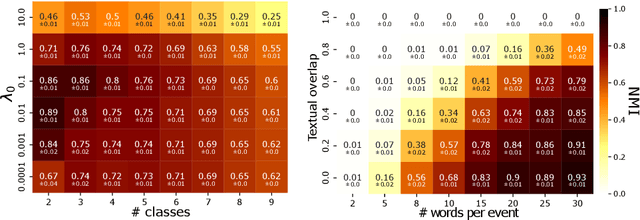
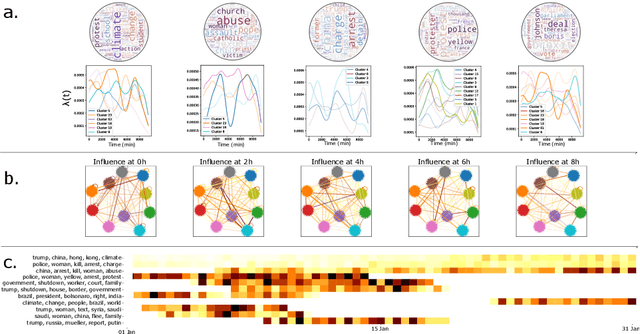
The publication time of a document carries a relevant information about its semantic content. The Dirichlet-Hawkes process has been proposed to jointly model textual information and publication dynamics. This approach has been used with success in several recent works, and extended to tackle specific challenging problems --typically for short texts or entangled publication dynamics. However, the prior in its current form does not allow for complex publication dynamics. In particular, inferred topics are independent from each other --a publication about finance is assumed to have no influence on publications about politics, for instance. In this work, we develop the Multivariate Powered Dirichlet-Hawkes Process (MPDHP), that alleviates this assumption. Publications about various topics can now influence each other. We detail and overcome the technical challenges that arise from considering interacting topics. We conduct a systematic evaluation of MPDHP on a range of synthetic datasets to define its application domain and limitations. Finally, we develop a use case of the MPDHP on Reddit data. At the end of this article, the interested reader will know how and when to use MPDHP, and when not to.
Distributed-Training-and-Execution Multi-Agent Reinforcement Learning for Power Control in HetNet
Dec 15, 2022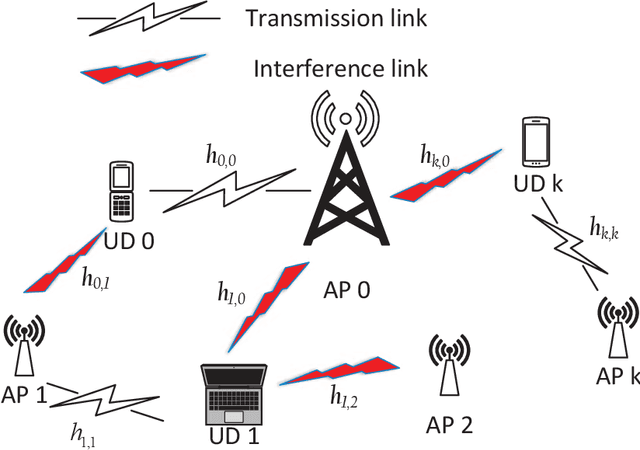
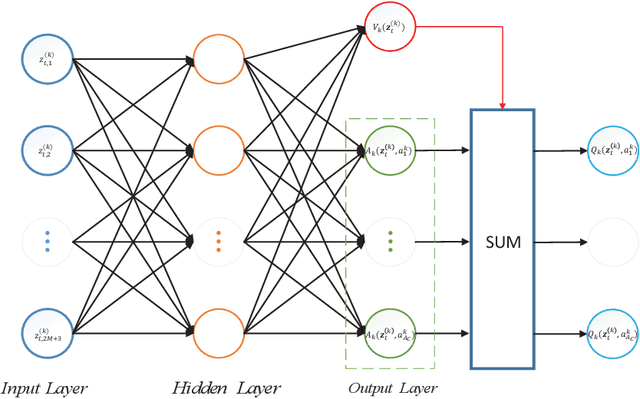
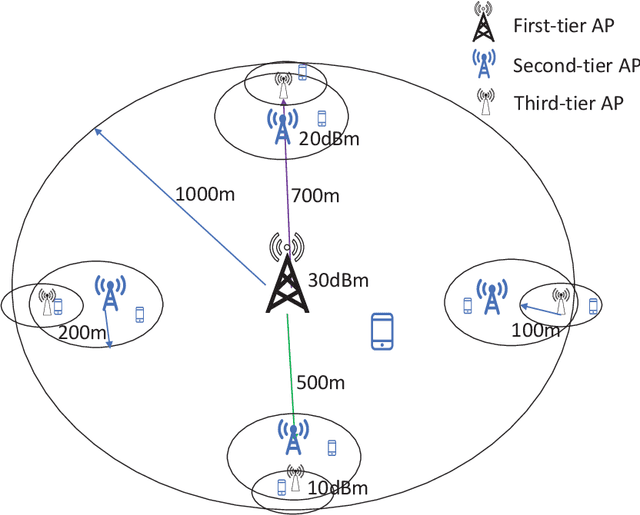
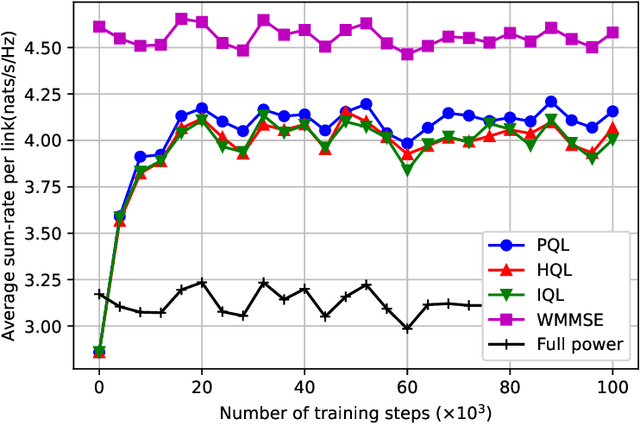
In heterogeneous networks (HetNets), the overlap of small cells and the macro cell causes severe cross-tier interference. Although there exist some approaches to address this problem, they usually require global channel state information, which is hard to obtain in practice, and get the sub-optimal power allocation policy with high computational complexity. To overcome these limitations, we propose a multi-agent deep reinforcement learning (MADRL) based power control scheme for the HetNet, where each access point makes power control decisions independently based on local information. To promote cooperation among agents, we develop a penalty-based Q learning (PQL) algorithm for MADRL systems. By introducing regularization terms in the loss function, each agent tends to choose an experienced action with high reward when revisiting a state, and thus the policy updating speed slows down. In this way, an agent's policy can be learned by other agents more easily, resulting in a more efficient collaboration process. We then implement the proposed PQL in the considered HetNet and compare it with other distributed-training-and-execution (DTE) algorithms. Simulation results show that our proposed PQL can learn the desired power control policy from a dynamic environment where the locations of users change episodically and outperform existing DTE MADRL algorithms.
QueryPose: Sparse Multi-Person Pose Regression via Spatial-Aware Part-Level Query
Dec 15, 2022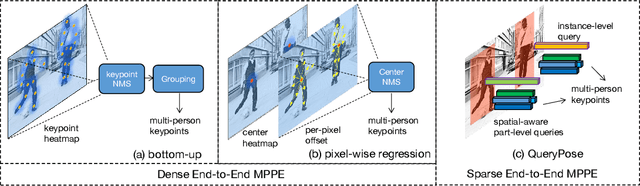
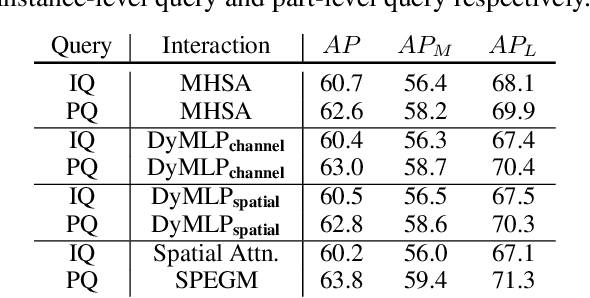
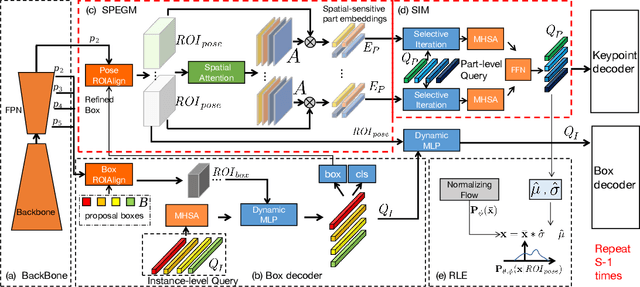
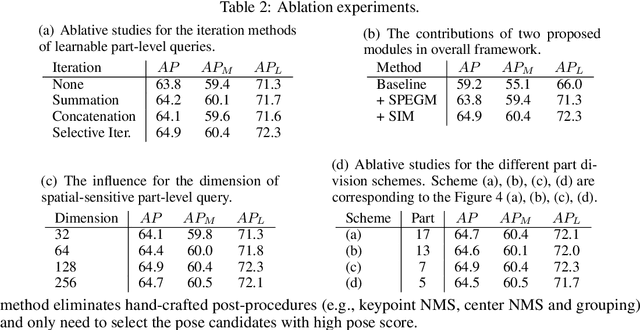
We propose a sparse end-to-end multi-person pose regression framework, termed QueryPose, which can directly predict multi-person keypoint sequences from the input image. The existing end-to-end methods rely on dense representations to preserve the spatial detail and structure for precise keypoint localization. However, the dense paradigm introduces complex and redundant post-processes during inference. In our framework, each human instance is encoded by several learnable spatial-aware part-level queries associated with an instance-level query. First, we propose the Spatial Part Embedding Generation Module (SPEGM) that considers the local spatial attention mechanism to generate several spatial-sensitive part embeddings, which contain spatial details and structural information for enhancing the part-level queries. Second, we introduce the Selective Iteration Module (SIM) to adaptively update the sparse part-level queries via the generated spatial-sensitive part embeddings stage-by-stage. Based on the two proposed modules, the part-level queries are able to fully encode the spatial details and structural information for precise keypoint regression. With the bipartite matching, QueryPose avoids the hand-designed post-processes and surpasses the existing dense end-to-end methods with 73.6 AP on MS COCO mini-val set and 72.7 AP on CrowdPose test set. Code is available at https://github.com/buptxyb666/QueryPose.
The Architectural Bottleneck Principle
Nov 11, 2022
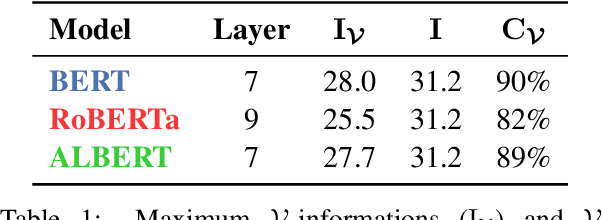
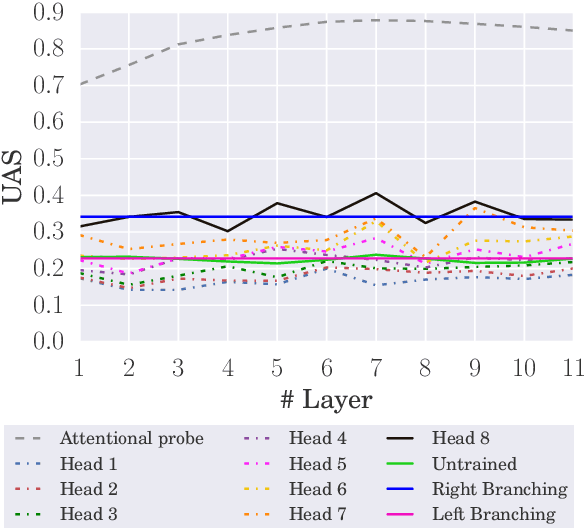
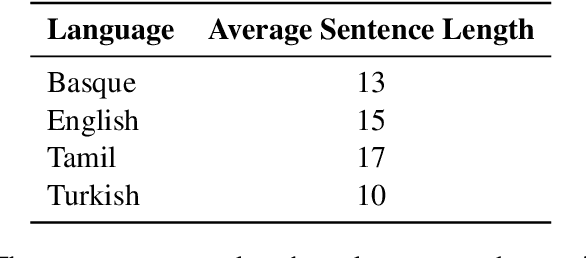
In this paper, we seek to measure how much information a component in a neural network could extract from the representations fed into it. Our work stands in contrast to prior probing work, most of which investigates how much information a model's representations contain. This shift in perspective leads us to propose a new principle for probing, the architectural bottleneck principle: In order to estimate how much information a given component could extract, a probe should look exactly like the component. Relying on this principle, we estimate how much syntactic information is available to transformers through our attentional probe, a probe that exactly resembles a transformer's self-attention head. Experimentally, we find that, in three models (BERT, ALBERT, and RoBERTa), a sentence's syntax tree is mostly extractable by our probe, suggesting these models have access to syntactic information while composing their contextual representations. Whether this information is actually used by these models, however, remains an open question.
Semantic-aware Message Broadcasting for Efficient Unsupervised Domain Adaptation
Dec 06, 2022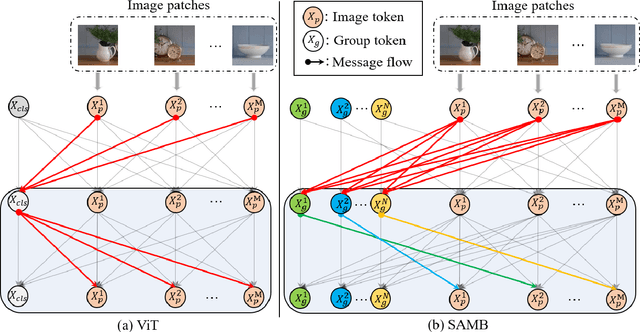
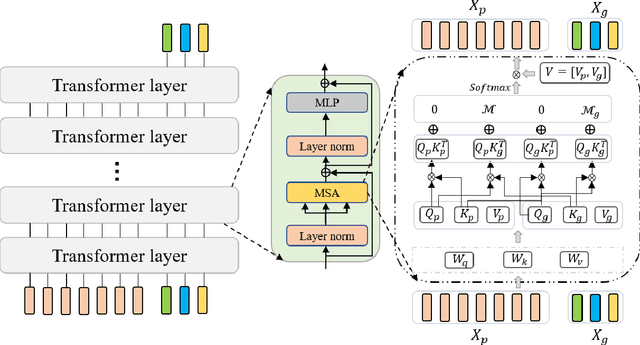

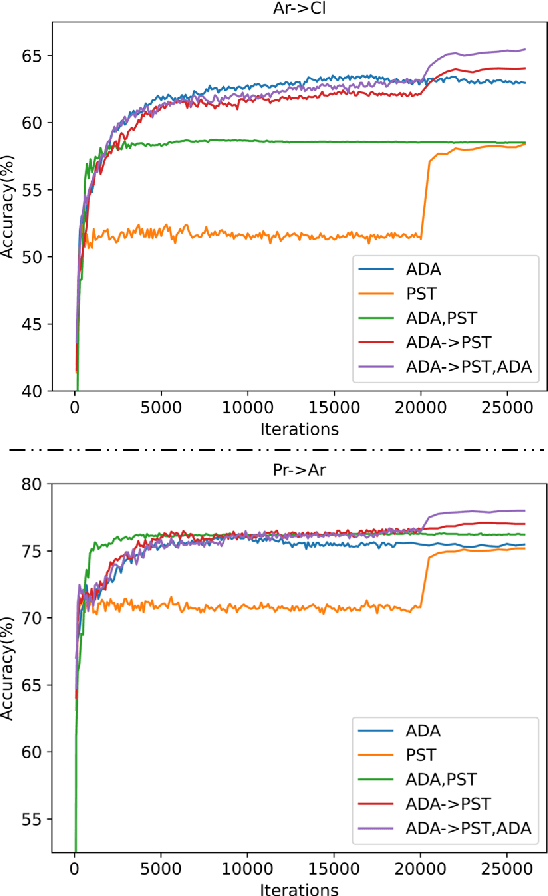
Vision transformer has demonstrated great potential in abundant vision tasks. However, it also inevitably suffers from poor generalization capability when the distribution shift occurs in testing (i.e., out-of-distribution data). To mitigate this issue, we propose a novel method, Semantic-aware Message Broadcasting (SAMB), which enables more informative and flexible feature alignment for unsupervised domain adaptation (UDA). Particularly, we study the attention module in the vision transformer and notice that the alignment space using one global class token lacks enough flexibility, where it interacts information with all image tokens in the same manner but ignores the rich semantics of different regions. In this paper, we aim to improve the richness of the alignment features by enabling semantic-aware adaptive message broadcasting. Particularly, we introduce a group of learned group tokens as nodes to aggregate the global information from all image tokens, but encourage different group tokens to adaptively focus on the message broadcasting to different semantic regions. In this way, our message broadcasting encourages the group tokens to learn more informative and diverse information for effective domain alignment. Moreover, we systematically study the effects of adversarial-based feature alignment (ADA) and pseudo-label based self-training (PST) on UDA. We find that one simple two-stage training strategy with the cooperation of ADA and PST can further improve the adaptation capability of the vision transformer. Extensive experiments on DomainNet, OfficeHome, and VisDA-2017 demonstrate the effectiveness of our methods for UDA.
Enabling AI-Generated Content (AIGC) Services in Wireless Edge Networks
Jan 09, 2023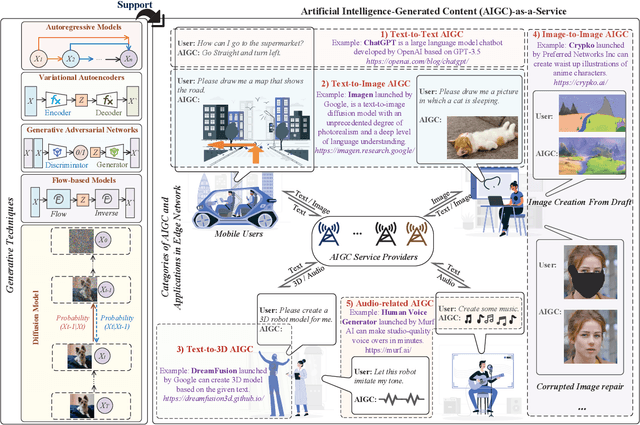
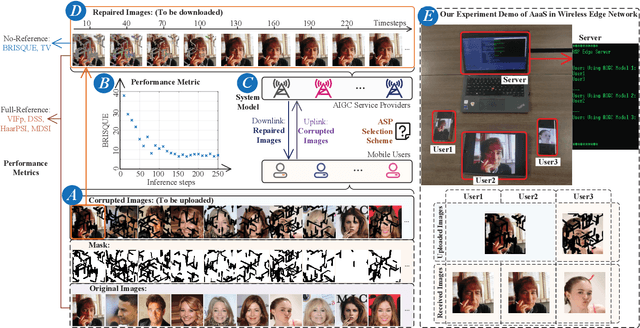
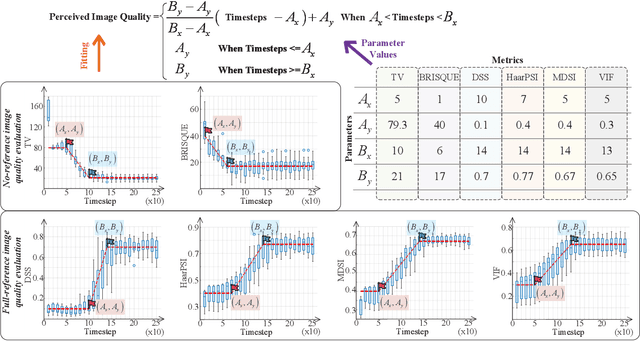
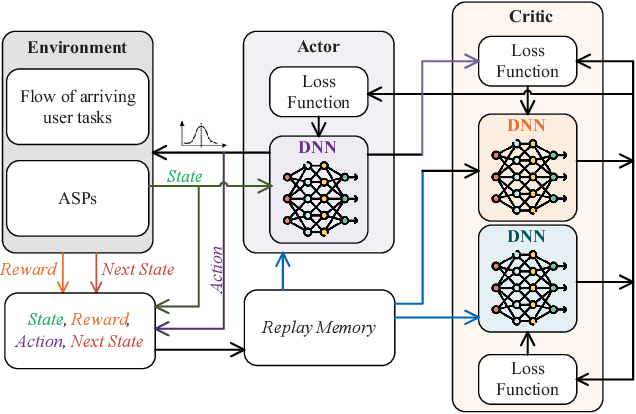
Artificial Intelligence-Generated Content (AIGC) refers to the use of AI to automate the information creation process while fulfilling the personalized requirements of users. However, due to the instability of AIGC models, e.g., the stochastic nature of diffusion models, the quality and accuracy of the generated content can vary significantly. In wireless edge networks, the transmission of incorrectly generated content may unnecessarily consume network resources. Thus, a dynamic AIGC service provider (ASP) selection scheme is required to enable users to connect to the most suited ASP, improving the users' satisfaction and quality of generated content. In this article, we first review the AIGC techniques and their applications in wireless networks. We then present the AIGC-as-a-service (AaaS) concept and discuss the challenges in deploying AaaS at the edge networks. Yet, it is essential to have performance metrics to evaluate the accuracy of AIGC services. Thus, we introduce several image-based perceived quality evaluation metrics. Then, we propose a general and effective model to illustrate the relationship between computational resources and user-perceived quality evaluation metrics. To achieve efficient AaaS and maximize the quality of generated content in wireless edge networks, we propose a deep reinforcement learning-enabled algorithm for optimal ASP selection. Simulation results show that the proposed algorithm can provide a higher quality of generated content to users and achieve fewer crashed tasks by comparing with four benchmarks, i.e., overloading-avoidance, random, round-robin policies, and the upper-bound schemes.
Removing Non-Stationary Knowledge From Pre-Trained Language Models for Entity-Level Sentiment Classification in Finance
Jan 09, 2023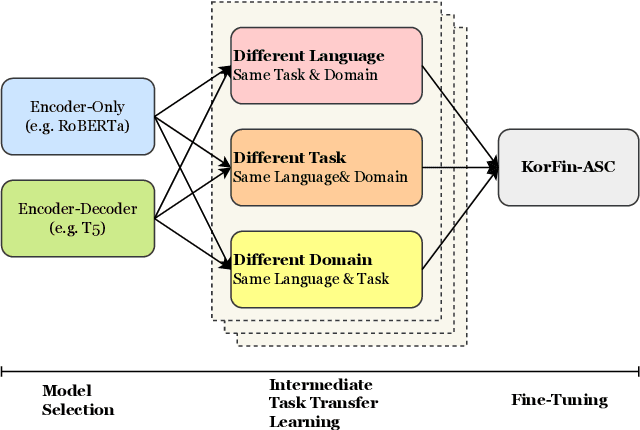

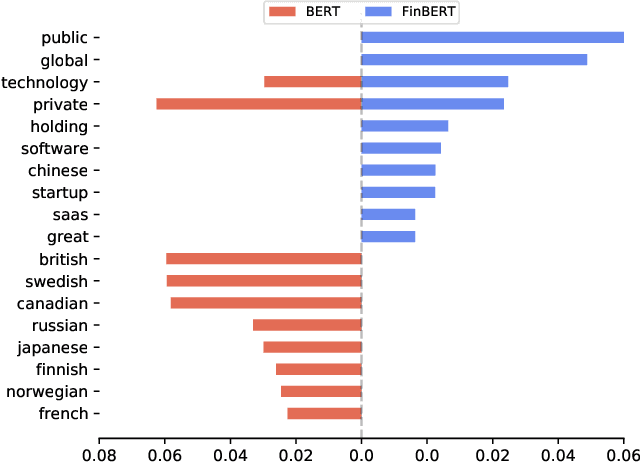
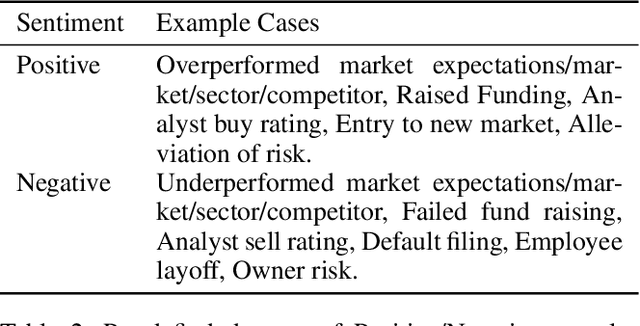
Extraction of sentiment signals from news text, stock message boards, and business reports, for stock movement prediction, has been a rising field of interest in finance. Building upon past literature, the most recent works attempt to better capture sentiment from sentences with complex syntactic structures by introducing aspect-level sentiment classification (ASC). Despite the growing interest, however, fine-grained sentiment analysis has not been fully explored in non-English literature due to the shortage of annotated finance-specific data. Accordingly, it is necessary for non-English languages to leverage datasets and pre-trained language models (PLM) of different domains, languages, and tasks to best their performance. To facilitate finance-specific ASC research in the Korean language, we build KorFinASC, a Korean aspect-level sentiment classification dataset for finance consisting of 12,613 human-annotated samples, and explore methods of intermediate transfer learning. Our experiments indicate that past research has been ignorant towards the potentially wrong knowledge of financial entities encoded during the training phase, which has overestimated the predictive power of PLMs. In our work, we use the term "non-stationary knowledge'' to refer to information that was previously correct but is likely to change, and present "TGT-Masking'', a novel masking pattern to restrict PLMs from speculating knowledge of the kind. Finally, through a series of transfer learning with TGT-Masking applied we improve 22.63% of classification accuracy compared to standalone models on KorFinASC.
Non-contact Respiratory Anomaly Detection using Infrared Light Wave Sensing
Jan 09, 2023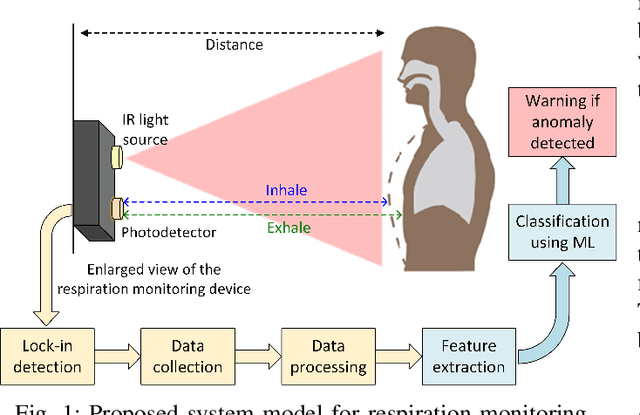
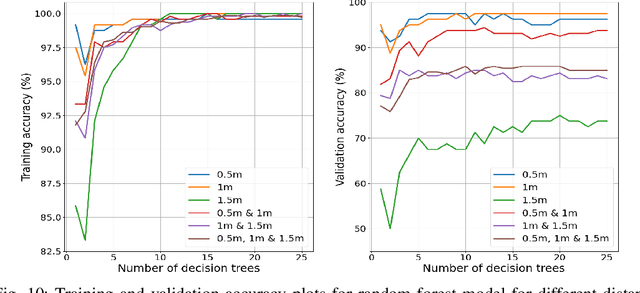
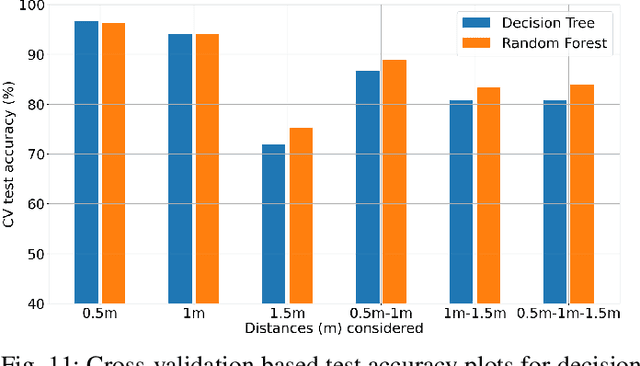

Human respiratory rate and its pattern convey important information about the physical and psychological states of the subject. Abnormal breathing can be a sign of fatal health issues which may lead to further diagnosis and treatment. Wireless light wave sensing (LWS) using incoherent infrared light turns out to be promising in human breathing monitoring in a safe, discreet, efficient and non-invasive way without raising any privacy concerns. The regular breathing patterns of each individual are unique, hence the respiration monitoring system needs to learn the subject's usual pattern in order to raise flags for breathing anomalies. Additionally, the system needs to be capable of validating that the collected data is a breathing waveform, since any faulty data generated due to external interruption or system malfunction should be discarded. In order to serve both of these needs, breathing data of normal and abnormal breathing were collected using infrared light wave sensing technology in this study. Two machine learning algorithms, decision tree and random forest, were applied to detect breathing anomalies and faulty data. Finally, model performance was evaluated using average classification accuracies found through cross-validation. The highest classification accuracy of 96.6% was achieved with the data collected at 0.5m distance using decision tree model. Ensemble models like random forest were found to perform better than a single model in classifying the data that were collected at multiple distances from the light wave sensing setup.